(13)Hive调优——动态分区导致的小文件问题
前言
动态分区指的是:分区的字段值是基于查询结果自动推断出来的,核心语法就是insert+select。 具体内容指路文章:
https://blog.csdn.net/SHWAITME/article/details/136111924?spm=1001.2014.3001.5501文章浏览阅读483次,点赞15次,收藏8次。Hive的相关概念——分区表、分桶表https://blog.csdn.net/SHWAITME/article/details/136111924?spm=1001.2014.3001.5501
0 问题现象
现象:报错errorr如下:
[Error 20004]: Fatal error occurred when node tried to create
too many dynamic partitions. The maximum number of dynamic
partitions is controlled by hive.exec.max.dynamic.partitions and
hive.exec.max.dynamic.partitions.pernode. Maximum was setto: 100原因: Hive对其创建的动态分区数量实施限制,总结而言:每个执行MR的节点能创建动态分区的个数上限为100个(默认),所有执行MR的节点能创建动态分区的个数上限为1000个动态分区(默认),相关参数如下:
#在每个执行MR的节点上,最大可以创建多少个动态分区,默认值为100
hive.exec.max.dynamic.partitions.pernode=100;#在所有执行MR的节点上,最大一共可以创建多少个动态分区,默认1000
hive.exec.max.dynamic.partitions=1000;#整个MR Job中,最大可以创建多少个HDFS 文件,默认100000
hive.exec.max.created.files=100000;实际生产环境中,上述参数可以调整。
1 问题解决
解决方案一:调整动态分区数
set hive.exec.dynamic.partition=true;
在每个执行MR的节点上,最大可以创建256个动态分区(默认值为100)
set hive.exec.max.dynamic.partitions.pernode=256;
#在所有执行MR的节点上,最大一共可以创建2048个动态分区(默认值为1000)
set hive.exec.max.dynamic.partitions=2048;
虽然配置了上述参数,但是不能保证小文件的问题彻底解决,有时候还需要设置reduce数。 mapred.reduce.tasks的计算公式可以为:
dynamic.partitions(总) / dynamic.partitions.pernode (分节点)<= mapred.reduce.tasks
根据上述例子,得到 2048/256 = 8,如果mapred.reduce.tasks小于8就会报错,所以可以手动设置 set mapred.reduce.tasks=10;
方案一弊端:小文件剧增
上述方案增加了动态分区的数量,虽然暂时不报错了,但是引出更棘手的问题,动态分区会产生大量小文件,因为当整个MR job启动K个reduce Instance,N个目标分区,极端情况下会产生K* N个小文件。整个MR Job中,默认创建hdfs文件数的上限为100000个(参数hive.exec.max.created.files = 100000)。
假设输入的数据量为1T,我们开启了2000 个MapReduce任务去读取,假设动态分区数总数为100个,也就是说:hdfs上一共有100个分区,每个分区下的小文件数量都是2000个。此时小文件数量=ReduceTask数量 * 分区数,即2000*100=200000个,
直接超出创建hdfs文件数的上限数(参数hive.exec.max.created.files = 100000)。例如生产环境执行下列sql进行数据插入时,动态分区会有产生小文件的风险:
insert overwrite table testA partition(dt)
select *
from testB那么动态分区造成小文件应该如何避免和优化呢?
解决方案二:distribute by
distribute by 是用来解决数据分发问题的,根据指定的分区字段值,可以控制数据分发到对应的reduce中去【HASH的方式,类似于spark中的repartition】。分区编号 =分区字段值的hash值 % reduce数,即【distribute by dt】 操作可以将同一分区的数据直接发到同一个reduce中。
执行sql后,由原来100个分区,每个分区下2000个小文件的局面改造成:100个分区,每个分区下只有一个文件。相关sql如下:
insert overwrite table test partition(dt)
select *
from table
distribute by dt方案二弊端:数据倾斜
经过上述操作,又引来了一个新的问题,假设这100个分区的数据分布不均匀的,有的redcue数据很多有几百个G,有的只有几兆,这样导致个别reduce会卡在99%,拖慢整体的HQL执行效率。因此可以采用随机数,将数据相对均衡地发送到每个reducer来解决该问题,使每个reduce任务处理的数据大体一致。
解决方案三:distribute by命令
(1)设定每个reduce处理的数据量来控制hdfs上最终生成的文件数。
假设给每个redcue任务分配10G数据量,则对于1T的数据总共会启动102个左右的reduceTask,相关sql如下:
#每个reduce处理数据量
set hive.exec.reducers.bytes.per.reducer=1024*10*1000*1000; ---10Ginsert overwrite table test partition(dt)
select *
from table
distribute by rand()(2)rand()函数来控制hdfs上最终生成多少个文件【强烈推荐】
insert overwrite table test partition(dt)
select *
from table
distribute by cast(rand()*100 as int);#--cast(rand()*100 as int) 生成 0-100之间的随机整数ps:通过 distribute by cast( rand() * N as int) 来控制落地文件数, 其中 cast( rand() * N as int) 可以生成0-N之间的随机整数。
ps:更多的Hive小文件问题及解决方案见文章:
Hive的小文件问题-CSDN博客文章浏览阅读409次,点赞7次,收藏12次。Hive的小文件问题https://blog.csdn.net/SHWAITME/article/details/136108785
2 思考
Hive底层需要限制动态分区的数量的原因是? 动态分区会在短时间内创建大量的分区,可能会占用大量的资源,主要会有以下两方面的瓶颈:
- 内存方面
在Insert数据插入场景下,每个动态目录分区写入器(File Writer)至少会打开一个文件,对于parquert或者orc格式的文件,在写入的时候会首先写到缓冲区中,而这些缓冲区是按照分区来维护的,在运行的时候所需的内存大小会随着分区数增加而累积增加。导致OOM的mapper或者reducer,可能是由于打开的文件写入器的数量。如常见的错误:Error: GC overhead limit exceeded,针对该问题,可以调整的参数有:
#增加每个mapper的内存分配,即增大mapreduce.map.memory.mb和mapreduce.map.java.opts,这样所有文件写入器(filewriter)缓冲区对应的内存会更充沛。(1)map任务的物理内存分配值,常见设置为1GB,2GB,4GB等。
mapreduce.map.memory.mb (2)map任务的Java堆栈大小设置,一般设置为<= map任务的物理内存的75%
mapreduce.map.java.opts- 文件句柄
如果分区数过多,那么每个分区都会打开对应的文件句柄写入数据,可能会导致系统文件句柄占用过多,影响系统其他应用运行。因此hive又提出了一个hive.exec.max.created.files参数来控制整个mr 任务的创建文件数量的上限值(默认是100000个)
3 小结
上述阐述hive动态分区产生小文件的最佳解决方案:distribute by cast( rand() * N as int) = 【distribute by + rand随机数】,两者互相配合,控制数据相对均衡(解决数据倾斜)的发往到指定数量的reducer中,严格控制hdfs上落地文件数目。(HQL)
但是对于使用SparkSQL的用户来说,SparkSQL中的repartition算子可以解决这一问题,repartition和distribute by的作用一致 (控制数据发往指定分区)
spark小文件具体的解决方案待补充~
参考文章:
Hive/Spark小文件解决方案(企业级实战)
Hive Distribute by 应用之动态分区小文件过多问题优化_distribute by cast(rand() * 99 as int)-CSDN博客
相关文章:
(13)Hive调优——动态分区导致的小文件问题
前言 动态分区指的是:分区的字段值是基于查询结果自动推断出来的,核心语法就是insertselect。 具体内容指路文章: https://blog.csdn.net/SHWAITME/article/details/136111924?spm1001.2014.3001.5501文章浏览阅读483次,点赞15次…...

【linux】使用g++调试内存泄露:AddressSanitizer
1、简介 AddressSanitizer(又名 ASan)是 C/C++ 的内存错误检测器。它可以用来检测: 释放后使用(悬空指针) 堆缓冲区溢出 堆栈缓冲区溢出 全局缓冲区溢出 在作用域之后使用 初始化顺序错误 内存泄漏这个工具非常快,只将被检测的程序速度减慢约2倍,而Valgrind将会是程序…...

第三百五十七回
文章目录 1. 概念介绍2. 使用方法2.1 List2.2 Map2.3 Set 3. 示例代码4. 内容总结 我们在上一章回中介绍了"convert包"相关的内容,本章回中将介绍collection.闲话休提,让我们一起Talk Flutter吧。 1. 概念介绍 我们在本章回中介绍的内容是col…...

新版Java面试专题视频教程——框架篇
新版Java面试专题视频教程——框架篇 框架篇 01-框架篇介绍02-Spring-单例bean是线程安全的吗03-Spring-AOP相关面试题04-Spring-事务失效的场景05-Spring-bean的生命周期5.1 BeanDefinition 06-Spring-bean的循环依赖(循环引用)6.1 一般对象的循环依…...

网络爬虫实战 | 上传以及下载处理后的文件
详细代码在文尾 以实现爬虫一个简单的(SimFIR (doctrp.top))网址为例,需要遵循几个步骤: 1. 分析网页结构 首先,需要分析该网页的结构,了解图片是如何存储和组织的。这通常涉及查看网页的HTML源代码,可能还包括CSS和JavaScript文件。检查图片URL的模式,看看是否有规律…...

Linux--shell编程中有关while循环的详细内容
文章关于while循环的内容目录 一、while循环 二、无限循环 三、case语句 四、跳出循环 五、break 六、continue 一、w…...

回归测试与重新测试
软件开发是一个充满挑战的旅程,在这条道路上始终伴随着错误和不确定性的挑战。然而,真正将卓越软件与其他软件区分开来的是管理和解决这些挑战的效率,这就是结构良好的测试计划变得至关重要的地方,该计划的核心在于两个基本实践&a…...
java 版本企业招标投标管理系统源码+多个行业+tbms+及时准确+全程电子化
项目说明 随着公司的快速发展,企业人员和经营规模不断壮大,公司对内部招采管理的提升提出了更高的要求。在企业里建立一个公平、公开、公正的采购环境,最大限度控制采购成本至关重要。符合国家电子招投标法律法规及相关规范,以及审…...

详解动态内存管理!
目录 编辑 1.为什么要用动态内存分配 2.malloc和free 2.1 malloc 2.2 free 3.calloc和realloc 3.1 calloc 3.2 realloc 4.常见的动态内存的错误 4.1 对NULL的解引用操作 4.2 对动态内存开辟空间的越界访问 4.3 对非动态内存开辟空间用free释放 4.4 使用free释放动…...

iocp简单例子
下方代码中,没有写注释的地方,说明与icop网络无关也就是它们都不重要,重要的位置全部都有注释,复制下方代码就可以运行看效果 iocp带网络的例子: 客户端: 客户端只有一个main,只有socket相关函…...
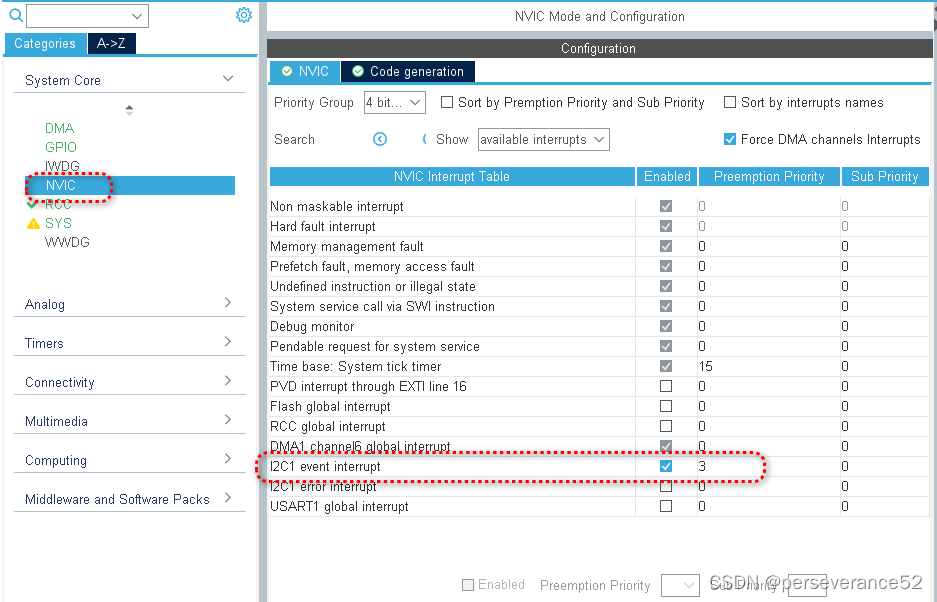
HAL STM32 HW I2C DMA + SSD1306/SH1106驱动示例
HAL STM32 HW I2C DMA SSD1306/SH1106驱动示例 📍硬件I2C DMA驱动参考:https://blog.csdn.net/weixin_45065888/article/details/118225993 🔖本工程基于STM32F103VCT6,驱动程序独立,可以移植到任意STM32型号上使用。…...
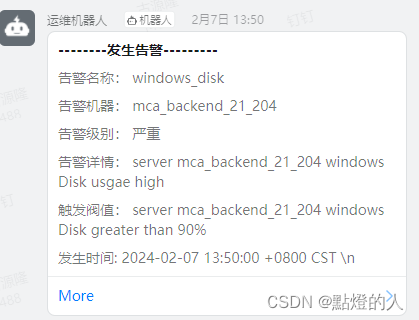
grafana配置钉钉告警模版(一)
1、配置钉钉告警模版 创建钉钉告警模版,然后在创建钉钉告警时调用模版。 定义发送内容具体代码 my_text_alert_list 是模版名称后面再配置钉钉告警时需要调用。 {{/* 定义消息体片段 */}} {{ define "my_text_alert_list" }}{{ range . }}告警名称&…...
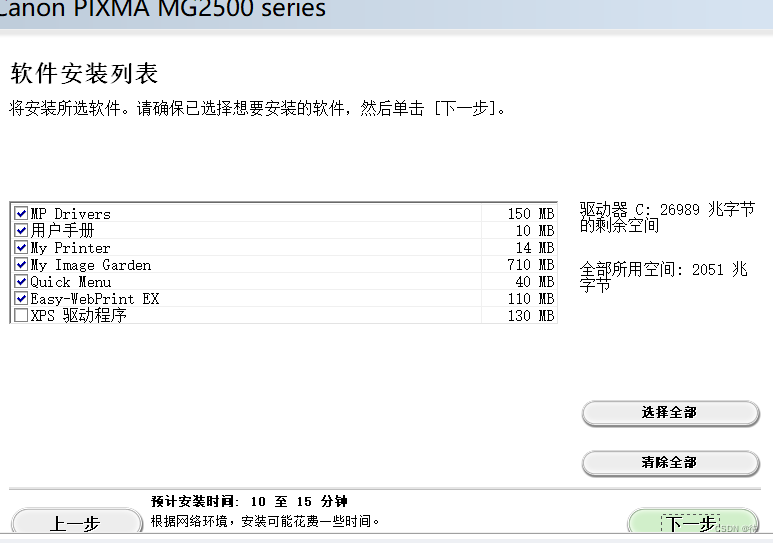
佳能2580的下载手册
凡是和电子产品有关的产品其内部都开始不断地进行内卷,在不断地内卷背后,意味着科技更新和换代,自己也入手了一台佳能2580的打印机,一台相对比较老式的打印机,以此不断地自己想要进行打印的需要。 下载的基础步骤&…...

YOLO-World:实时开放词汇目标检测
paper:https://arxiv.org/pdf/2401.17270.pdf Github:GitHub - AILab-CVC/YOLO-World: Real-Time Open-Vocabulary Object Detection online demo:https://huggingface.co/spaces/stevengrove/YOLO-World 目录 0. 摘要 1. 引言 2. 相关工…...

Unity中关于群组的一些组件
前言 在游戏开发环境中,UI组件是构建玩家交互界面的基础。以下是一些常见UI组件的详细解释和它们适用的场景,方便我们更好地理解和使用这些工具。 1. Graphic Raycaster Graphic Raycaster组件是游戏UI交互的核心。在Unity等游戏引擎中,当玩…...
面向对象详解,面向对象的三大特征:封装、继承、多态
文章目录 一、面向对象与面向过程1、什么是面向过程?2、什么是面向对象? 二、类与对象1. 初识对象2. 类的成员方法2.1 类的定义和使用2.2 成员方法 3. 类和对象4. 魔法方法1. _ _ inint _ _ 构造方法2. _ _ str _ _ 字符串方法3. _ _ lt _ _ 小于符号比较…...

【阿里云服务器的一些使用坑】都是无知的泪水呀
发生了什么? 我想学习一下关于Java的MySQL、Nginx 相关的知识。然后就用首次优惠注册的阿里云,都没有搞清楚实例,镜像,带宽,磁盘。然后。因为一不小心——我想去换一个Ubuntu的镜像而不是CentOS。就把实例给释放啊。之…...

Docker的常用命令||Docker是个流行的容器化平台,它允许你打包、分发和运行应用程序。
Docker是一个流行的容器化平台,它允许你打包、分发和运行应用程序。以下是一些常用的Docker命令及其示例用法: 1. **docker run**: 用于运行一个新的容器实例。 docker run <image_name> 例如,运行一个Nginx容器: docker ru…...

汽车电子论文学习--电动汽车电机驱动系统动力学特性分析
关键重点: 1. 汽车的低速转矩存在最大限制,受附着力限制,因路面不同而变化。 2. 起步加速至规定转速的时间可以计算得到: 3. 电机额定功率的计算方式: 可以采取最高设计车速90%或120km/h匀速行驶的功率作为电机额定功…...

c++的一些陌生用法记录
c的一些陌生用法记录 1. 完美转发std::forward<decltype(PH1)>(PH1)static的用法 1. 完美转发std::forward<decltype(PH1)>(PH1) static的用法 static函数与普通函数的区别: 用static修饰的函数,本限定在本源码文件中,不能被本源…...
)
Postgresql基础实践教程(二)
十三、查询会员的预订开始时间 题目 如何列出名为"David Farrell"的会员的所有预订开始时间? 预期结果 starttime 2012-09-18 09:00:00 2012-09-18 17:30:00 2012-09-18 13:30:00 2012-09-18 20:00:00 2012-09-19 09:30:00 2012-09-19 15:00:00 2012-09-19 12:00:…...

揭秘Midjourney V6拟物化失控真相:为什么87%的设计师调不出真实皮革/金属/织物质感?
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6拟物化失控现象的底层本质 Midjourney V6 引入的拟物化(PhotorealismMaterial Fidelity)增强机制,并非单纯提升纹理细节,而是通过隐式材质…...

Google I/O 2026最魔幻的一幕:发新模型的同时,Google砍了自己的CLI
5月19号凌晨,我刚躺下准备刷会儿手机睡觉,结果被朋友圈刷屏了。 Google I/O 2026,总共两个小时的 keynote,愣是让我看到凌晨两点。不是因为我有多敬业,而是信息量实在太大——大到我觉得不记下来,明天就忘了…...
)
【MATLAB】人脸表情识别与情感分析程序(工程实操版)
【MATLAB】人脸表情识别与情感分析程序(工程实操版) 摘要:人脸表情是人类情感表达的核心载体,人脸表情识别与情感分析技术融合了计算机视觉、图像处理、模式识别等多领域知识,广泛应用于人机交互、心理评估、智能安防、教育教学等场景。传统表情识别依赖人工判断,存在主…...

反向传播:从轮廓到精雕细琢
反向传播:从轮廓到精雕细琢模型知道损失值之后,怎么调整自己的参数?上一篇文章我们讲了损失函数——它像一个指南针,告诉模型"你离正确答案还有多远"。 那知道偏了之后,模型该怎么调整自己的参数?…...

Windows和Office激活终极指南:KMS_VL_ALL_AIO一键解决方案
Windows和Office激活终极指南:KMS_VL_ALL_AIO一键解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office的激活问题烦恼吗?每次重装系统都要重新…...
)
Debian 12.9 最小化安装后,我这样配置成了一台全能家庭服务器(含桌面、DNS、Cockpit)
Debian 12.9 家庭服务器全栈配置指南:从零构建智能家居中枢 在数字化生活日益普及的今天,家庭服务器正逐渐成为现代智能家居的核心枢纽。一台经过精心配置的Debian服务器不仅能满足文件存储、媒体共享等基础需求,更能通过DNS解析、Web化管理等…...

国产车规芯片崛起,如何用东软睿驰NeuSAR或经纬恒润方案快速适配?
国产车规芯片与AUTOSAR方案融合实战:从芯驰MCU到NeuSAR/经纬恒润的适配指南 当一颗国产车规级MCU遇上自主AUTOSAR基础软件,这场"中国芯"与"中国魂"的相遇,正在重构汽车电子开发的成本结构与技术生态。去年某新能源车企的…...

UWB传统厘米级定位 VS 镜像视界AI无感定位|大模型融合视频孪生全面重塑全域空间感知
UWB传统厘米级定位 VS 镜像视界AI无感定位|大模型融合视频孪生全面重塑全域空间感知在全域空间高精度感知产业高速迭代进程中,室内外人员与目标定位技术逐步分化为两大主流发展路径,其一为深耕多年、依托硬件组网实现测距定位的传统UWB厘米级…...

MailHog邮件测试工具:开发者的SMTP调试终极解决方案
MailHog邮件测试工具:开发者的SMTP调试终极解决方案 【免费下载链接】MailHog Web and API based SMTP testing 项目地址: https://gitcode.com/gh_mirrors/ma/MailHog 作为现代软件开发过程中不可或缺的一环,邮件功能测试常常让开发者头疼不已。…...