【论文阅读|基于 YOLO 的红外小目标检测的逆向范例】

基于 YOLO 的红外小目标检测的逆向范例
- 摘要
- 1 引言
- 2 相关工作
- 2.1 逆向推理
- 2.2 物体检测方法
- 3 方法
- 3.1 总体架构
- 3.2 逆向标准的可微分积分
- 4 实验
- 4.1 数据集和指标
- 4.2 实验环境
- 4.4 OL-NFA 为少样本环境带来稳健性
- 5 结论
论文题目: A Contrario Paradigm for YOLO-based Infrared Small Target Detection(基于 YOLO 的红外小目标检测的逆向范例)
论文下载链接: https://arxiv.org/pdf/2402.02288.pdf
摘要
检测红外图像中的微小目标是计算机视觉领域的一项具有挑战性的任务,尤其是在将这些目标从嘈杂或纹理背景中区分出来时。与分割神经网络相比,传统的物体检测方法(如 YOLO)在检测微小物体时非常吃力,因此在检测小目标时性能较弱。为了在保持高检测率的同时减少误报,在 YOLO 检测器的训练中引入了反向决策标准。后者利用小目标的不可预测性,将它们与复杂背景区分开来。在 YOLOv7-tiny 中加入这一统计标准,缩小了红外小目标检测和物体检测网络中最先进的分割方法之间的性能差距。它还大大提高了 YOLO 对少样本环境的鲁棒性。
关键词: 小目标检测、逆向推理、YOLO、少样本检测
1 引言
在包括医疗或安全领域在内的各种应用中,准确检测红外(infrared, IR)图像中的小目标至关重要。红外小目标检测(Infrared small target detection, IRSTD)是计算机视觉领域的一项巨大挑战,其困难主要在于:(1) 目标的大小(面积低于 20 像素);(2) 复杂且纹理丰富的背景,从而导致许多误报;(3) 学习条件,即从小型、多样化程度低且高度类不平衡的数据集中学习,因为与背景类像素相比,目标类像素的数量非常少。过去几十年来,深度学习方法的兴起在物体检测领域取得了令人瞩目的进步,这主要归功于它们能够从大量标注数据中学习,提取出非常适合最终任务的非线性特征。在 IRSTD 中,语义分割神经网络的应用最为广泛[1]。其中包括 ACM[2]、LSPM[3]和最近最先进的(SOTA)方法之一,即 DNANet[4],它由多个嵌套的 UNets 和一个多尺度融合模块组成,能够分割不同大小的小物体。然而,依靠分割神经网络进行物体检测的一个主要问题是,在调整用于二值化分割图的阈值时,可能会出现物体破碎的情况。这会导致许多不希望出现的误报,并扭曲计数指标。Faster-RCNN [5] 或 YOLO [6] 等物体检测算法通过边界框回归明确定位物体,从而降低了这种风险。然而,这些算法往往难以检测到微小物体。很少有研究关注将此类检测器用于 IRSTD [7],也没有与 SOTA IRSTD 方法进行严格比较。
在本文中,提出了一种新颖的 YOLO 检测头,称为 OL-NFA(for Object-Level Number of False Alarms, OL-NFA对象级误报数量),专门用于小物体检测。该模块集成了一个逆向决策标准,用于引导特征提取,从而使不可预测的物体在背景中脱颖而出并被检测到。它用于重新估算由 YOLO 骨干计算出的对象性分数,并经过精心实施,以便在训练过程中进行反向传播。使用逆向范式的一个好处是,因为有大量的背景样本,它侧重于对背景建模,而不是对物体本身建模。这样,通过拒绝背景分布的假设来进行检测,就可以绕过类不平衡和训练数据少的问题。主要贡献如下:
1.设计了一种新颖的 YOLO 检测头,它整合了一种用于估算对象性分数的逆向标准。通过重点对背景而非物体本身进行建模,放宽了对大量训练样本的限制。
2.在著名的 IRSTD 基准上比较了 SOTA 分割神经网络和物体检测方法,结果表明在 YOLOv7-tiny 骨干中添加 OL-NFA 可以缩小 IRSTD 中物体检测器和 SOTA 分割神经网络 之间的性能差距。
3.此外,还在少样本环境中大幅提高了 YOLOv7-tiny 的性能(15-shot 的 AP 为 39.2%),证明了逆向范式在弱训练条件下的鲁棒性。
2 相关工作
2.1 逆向推理
逆向决策方法可以自动推导出与假设检验相关的决策标准。这些方法从感知理论,尤其是Gestalt理论中汲取灵感[8]。这些方法包括通过使用可解释的检测阈值来拒绝表征非结构化背景的原始模型。后者允许控制误报数量(NFA),通常定义为被测物体总数与所选原始的模型所遵循的规律的尾部分布之间的乘积。由于计算出的尾值取决于对象的特征,因此 NFA 值可以与任何给定对象相关联。文献中提出了几种逆向的公式。它们取决于考虑的是灰度图像还是二值图像。在第一种情况下,最常用的原始模型是像素灰度值的高斯分布 [9、10、11]。后者已被 [12] 整合到深度学习框架中,并在小目标分割中表现出了很好的性能。在第二种情况下,最广泛使用的原始模型是图像网格中 "真实 "像素的均匀空间分布。这就导致了参数 p p p 的二项分布,即 "真实 "像素 κ κ κ在任何给定参数形状的区域 ν ν ν内的数量[13, 14]:
NFA ( κ , ν , p ) = η ∑ i = κ ν ( ν i ) p i ( 1 − p ) ν − i , \text{NFA}\left(\kappa,\nu,p\right)=\eta\sum_{i=\kappa}^{\nu}\begin{pmatrix}\nu\\i\end{pmatrix}p^{i}\left(1-p\right)^{\nu-i}, NFA(κ,ν,p)=ηi=κ∑ν(νi)pi(1−p)ν−i,
其中, η η η 是测试对象的数量。根据公式 (1),可能代表物体的像素子集更加重要,因为与图像整体密度相比,它包含许多空间上接近的点。工作重点是将这一原始的模型整合到物体检测器的训练循环中,以引导特征提取,而这在之前的研究中并没有考虑到。与 [12] 不同的是,[12] 的原始模型适用于像素级分类(即分割),而作者考虑的是另一种直接适用于对象级的模型,因此更适用于有边界框建议的神经网络。
2.2 物体检测方法
物体检测是在图像中检测感兴趣的物体,并通过边界框确定其位置的任务。针对此类任务,已经提出了几种深度学习方法 [15, 6]。YOLO 框架是应用最广泛的一种,因为它在各种应用中都有很好的性能,而且执行时间短。它是一种单阶段算法,使用单个卷积神经网络来预测边界框坐标、对象性和分类分数。具体来说,它将图像划分为一个个网格,并预测任何给定网格单元包含物体的概率(表示为物体度分数),如果存在物体,则预测物体的边界框坐标。YOLO 早期版本的一个问题是,它们在检测小物体时很吃力。事实上,如果要检测的物体太小,它可能只占据网格单元的一小部分,这使得 YOLO 难以准确地检测到它。为了解决这个问题,YOLOv3 [16] 引入了一个特征金字塔网络(feature pyramid network,FPN),将在多个尺度上检测到的特征结合起来。YOLO 的一些最新版本,如 YOLOR [17] 或 YOLOv7 [18],在一些著名的计算机视觉基准测试中取得了具有竞争力的检测性能,同时还提高了执行速度。还有人提出了卷积层数更少的 YOLO 微型版本。
3 方法
3.1 总体架构

作者提出了一种新颖的 YOLO 检测头,称为 OL-NFA(对象级 NFA 检测头),它集成了一种逆向标准,用于检测具有意外偏离背景分布特征的物体。OL-NFA 将根据 NFA 标准(式 (1))计算对象性得分,并应用于网络生成的特征图。
图 1 展示了方法的整体架构。红外输入图像首先经过 YOLO 主干网络,提取不同尺度的特征图。然后,通过颈部将三个较低层次的特征组合在一起,从而得到最终的特征图 F i F_i Fi,用于执行三个层次的检测: i ∈ 1 , 2 , 3 i∈{1, 2, 3} i∈1,2,3。为了实现检测,首先要通过密集层预测边界框坐标。然后,引入 OL-NFA 模块,利用 NFA 准则重新估算每个边界框的对象度得分。为此,使用 Faster R-CNN [15] 中的 ROI Align 提取出 η 个感兴趣区域(ROI),用 f r o i f_{roi} froi表示,并通过第 3.2 节所述的重要性层计算出每个 ROI 的重要性得分。最后,通过第 3.2 节中定义的函数 f a c t f_{act} fact,这些分数的范围为 [0,1],这样就可以应用 YOLO 中使用的二元交叉熵损失。
3.2 逆向标准的可微分积分
图 1 中的重要性层整合了公式 (1) 中给出的逆向标准。然而,由于该公式 (i) 是为二值图像而非灰度特征图而设计的,而且 (ii) 不可微,因此需要进行一些近似处理,以便将其整合到 YOLO 训练循环中。公式 (1) 带来的第一个困难是计算 f r o i ∈ R 2 f_{roi}∈\mathbb{R}^2 froi∈R2 中 "True "像素 κ 的数量。如果要对 f r o i f_{roi} froi进行二值化处理,就会破坏反向传播循环。因此,建议考虑实数成员系数(以模糊聚类或分类的精神为指导),即对每个像素处理一个系数,表示它属于包含二进制情况下的值为 1像素的集合的程度。为此,在像素值上使用了 sigmoid 函数 σ,这样就可以通过这些模糊归属系数的总和,近似地计算出 f r o i f_{roi} froi 中包含的像素数量,从而估算出局部密度。在计算 F i F_i Fi中的总点数时,也采用了同样的近似方法,以估算公式 (1) 中二项式定律的参数 p p p(代表 F i F_i Fi 的全局密度)。第二个问题是,NFA 函数是不连续的、不可微的,而且由于处理的是面积很小的物体 ν ν ν,它只取极少数不同的值。这些因素使得很难将公式 (1) "原封不动 "地集成到训练环路中,并进行有效的反向传播。因此,定义了 S ( κ , ν , p ) = − l n ( N F A ( κ , ν , p ) ) S (κ, ν, p) = - ln(NFA(κ, ν, p)) S(κ,ν,p)=−ln(NFA(κ,ν,p)) 的意义,并在 k v > p \frac{k}{v} > p vk>p 时使用霍夫丁近似,从而得出
S ( κ , ν , p ) ≈ ν [ κ ν ln ( κ ν p ) + ( 1 − κ ν ) ln ( 1 − κ ν 1 − p ) ] − ln η . S\left(\kappa,\nu,p\right)\approx\nu\left[\frac{\kappa}{\nu}\ln\left(\frac{\frac{\kappa}{\nu}}{p}\right)+\left(1-\frac{\kappa}{\nu}\right)\ln\left(\frac{1-\frac{\kappa}{\nu}}{1-p}\right)\right]-\ln\eta. S(κ,ν,p)≈ν[νκln(pνκ)+(1−νκ)ln(1−p1−νκ)]−lnη.
这样,就可以将函数 S ( κ , ν , p ) S (κ, ν, p) S(κ,ν,p) 的域扩展到 R 3 \mathbb{R}^3 R3,并输出更多的中间值。在 κ ν ≤ p \frac{\kappa}{\nu}≤ p νκ≤p 的情况下,只需指定 ( κ , ν , p ) = − l n η (κ, ν, p) = - ln~η (κ,ν,p)=−ln η,因为它对应于明显的背景值。最后,由于显著性值的范围为 [ − l n ( N t e s t ) , + ∞ ] [- ln(N_{test}), +∞] [−ln(Ntest),+∞],其中大值对应于可能的目标,为了获得范围为[0, 1]的对象性得分,应用了非对称激活函数 f a c t ( x , η ) = 2 σ ( x + l n η ) − 1 f_{act}(x, η) = 2σ(x + ln η) - 1 fact(x,η)=2σ(x+lnη)−1,其中 x ∈ R x∈ \mathbb{R} x∈R, η ∈ N ∗ η∈ \mathbb{N}^∗ η∈N∗。
4 实验
4.1 数据集和指标
在 NUAA-SIRST 数据集[2]上对提出的方法进行了评估,该数据集是为数不多的可公开获取并在文献中广泛使用的红外小目标数据集之一。该数据集由 427 幅红外图像组成,波长范围为 950 到 1200 nm。来自 NUAA-SIRST 的目标的空间范围从 2 - 3 像素到最大目标的 100 像素以上不等,这使得该数据集适合在各种目标尺寸上评估提出的方法。如图 2 第一行所示,目标被淹没在纹理云等具有挑战性的场景中。按照 60 : 20 : 20 的比例将数据集分为训练集、验证集和测试集。还通过仅在 15 幅和 25 幅图像上训练 神经网络 来评估提出的方法在少样本环境中的优势。在定量评估方面,侧重于传统的检测指标:F1 分数(F1)和平均精度(AP,精度-召回曲线下的面积)。还依赖精度(Prec.)和召回率(Rec.)来了解 F1 分数的实现值。表格中的结果是三次不同训练的平均值,上标为 F1 和 AP 的标准偏差。

4.2 实验环境
在 YOLOv7tiny 的基础上添加了 OL-NFA 检测头,因为与其他 YOLO 主干线相比,该基线在 NUAA-SIRST 数据集上表现出色。将其与几种基线进行比较:1) 专门为 IRSTD 设计的分割网络,即 ACM [2]、LSPM [3] 和 DNANet [4];2) YOLO 基线,如 YOLOv3 [16]、YOLOR [17]、YOLOv7 和 YOLOv7-tiny [18]。对于 IRSTD 分割神经网络,使用原始论文中推荐的训练设置。所有物体检测神经网络都在 Nvidia RTX6000 GPU 上进行了 600 epochs从头开始的训练,使用 Adam 优化器 [19],批量大小等于 16,学习率等于 0.001。少量训练也采用了相同的设置。
表 1 显示了每种比较方法在 NUAA-SIRST 上取得的性能。可以看到,用OLNFA 代替传统的 YOLO 检测头不仅提高了微小物体检测的 YOLO 性能,还缩小了 SOTA IRSTD 分割神经网络与传统物体检测神经网络之间的性能差距。具体来说,提出的方法比最佳 YOLO 基线的 F1 分数高出 0.7%。AP 标准也提高了 0.4%。此外,提出的方法在 F1 和 AP 方面的表现略好于 DNANet,后者是 IRSTD 的 SOTA 方法。提出的方法的推理时间也比 DNANet 的推理时间短得多,因此可以进行实时目标检测。提出的 OL-NFA 模块之所以性能卓越,主要是因为精度更高,但召回率损失有限,这可以用 NFA 控制误报数量的特性来解释。事实上,增加一个逆向的判定标准有助于增强小物体的特征,从而将它们与复杂背景区分开来。这一点可以从图 2 中看出,最佳 YOLO 基线会导致输入 3 和输入 4 出现多个误报,而提出的方法则能提供正确的检测,没有任何误报。

4.4 OL-NFA 为少样本环境带来稳健性
将逆向推理纳入神经网络的一个重要动机是网络能够通过学习背景元素的表示而不是目标本身学习判别小目标。因此,它应该能使神经网络对薄弱的训练条件具有鲁棒性。为了证实猜想,在 NUAASIRST 数据集上定量评估了所提出的方法在少样本环境中的优势。为此,分别在 15 幅和 25 幅图像上对网络进行了训练。对于每种少样本设置,都在三个明显的褶皱上训练检测器,它们之间没有重叠。在第 4.1 节定义的测试集上获得的结果是这三个褶皱的平均值,计算出的平均值见表 2。可以看出,提出的方法在节俭设置中的表现明显优于基线方法。事实上,在这些情况下,F1 分数和平均精度都至少提高了 20%。因此,得出结论,在基线方法中添加对象级 NFA 能显著提高其在节俭环境下的鲁棒性:当训练样本数量除以 10 以上时,F1 分数仅降低 15%,而平均精度则保持在 90% 以上。

5 结论
在本文中,提出了一种名为 OL-NFA 的新型 YOLO 检测头,它在 YOLO 网络的训练循环中集成了一个逆向的决策标准。它迫使网络对背景分布而不是要检测的物体进行建模。广泛的实验表明,提出的方法不仅显著提高了 YOLO 网络在节俭型和少样本环境下的小目标检测性能,而且在小目标检测方面与 SOTA 分割网络的性能相当。这一令人鼓舞的性能促使考虑进一步研究如何使用逆向范式来检测微小目标。
相关文章:
【论文阅读|基于 YOLO 的红外小目标检测的逆向范例】
基于 YOLO 的红外小目标检测的逆向范例 摘要1 引言2 相关工作2.1 逆向推理2.2 物体检测方法 3 方法3.1 总体架构3.2 逆向标准的可微分积分 4 实验4.1 数据集和指标4.2 实验环境4.4 OL-NFA 为少样本环境带来稳健性 5 结论 论文题目: A Contrario Paradigm for YOLO-b…...

【presto权威指南】常用操作
shell ./bin/launcher start ./bin/launcher status ./bin/launcher stop /home/work/presto/bin/presto --server hadoop2:8443 --catalog hive --schema defult --debug --user ‘sdfyypt_2_0_eywa_admin’ //指定用户 presto -f 可以指定执行sql文件 presto -execute 可以…...

Python程序员面试准备:八股文题目与解答思路
目录 描述一下Python中的列表推导式(List Comprehension)及其用法。 代码示例: 解答思路: 解释一下Python中的装饰器(Decorator)及其作用。 代码示例: 输出: 解答思路: 谈谈Python中的GIL(Global Interprete…...

如何系统地自学Python?
如何系统地自学Python? 如何系统地自学Python?1.了解编程基础2.学习Python基础语法3.学习Python库和框架4.练习编写代码5.参与开源项目6.加入Python社区7.利用资源学习8.制定学习计划9.持之以恒总结 如何系统地自学Python? 作为一个Python语…...

mysql 2-21
约束的分类 添加约束 查看表约束 非空约束 唯一性约束 复合的唯一性约束 只要有一个字段不重复,就可以添加成功 主键约束 自增列 mysql 8.0具有持久化,重启服务器会继续自增 外键约束 创建外键 关联必须有唯一性约束,或者是主键 约束等级 …...
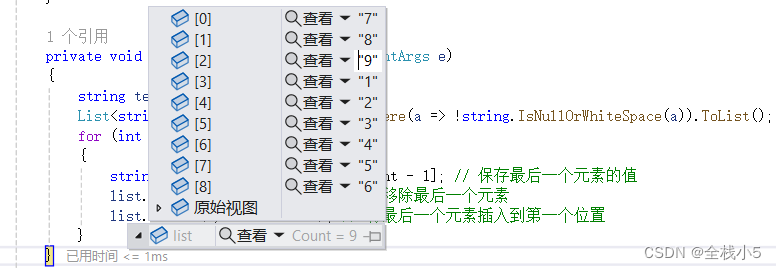
【C#】List泛型数据集如何循环移动,最后一位移动到第一位,以此类推
欢迎来到《小5讲堂》 大家好,我是全栈小5。 这是《C#》系列文章,每篇文章将以博主理解的角度展开讲解, 特别是针对知识点的概念进行叙说,大部分文章将会对这些概念进行实际例子验证,以此达到加深对知识点的理解和掌握。…...

LeetCode23.合并K个升序链表
题目 给你一个链表数组,每个链表都已经按升序排列。 请你将所有链表合并到一个升序链表中,返回合并后的链表。 示例 : 输入:lists [[1,4,5],[1,3,4],[2,6]] 输出:[1,1,2,3,4,4,5,6] 解释:链表数组如下&…...
(01)Hive的相关概念——架构、数据存储、读写文件机制
目录 一、架构及组件介绍 1.1 Hive整体架构 1.2 Hive组件 1.3 Hive数据模型(Data Model) 1.3.1 Databases 1.3.2 Tables 1.3.3 Partitions 1.3.4 Buckets 二、Hive读写文件机制 2.1 SerDe 作用 2.2 Hive读写文件流程 2.2.1 读取文件的过程 …...
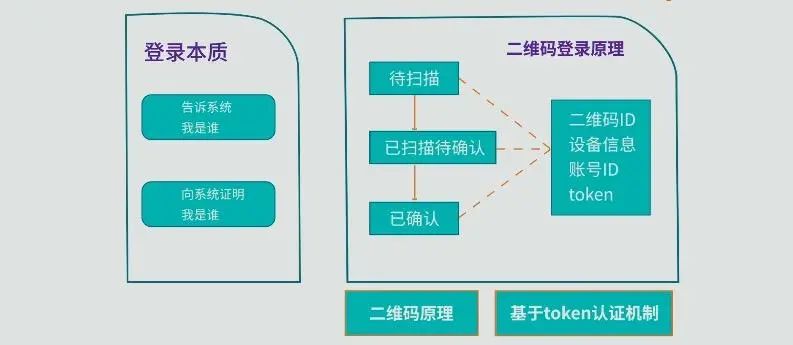
二维码扫码登录原理,其实比你想的要简单的多
二维码,大家再熟悉不过了 购物扫个码,吃饭扫个码,坐公交也扫个码 在扫码的过程中,大家可能会有疑问:这二维码安全吗? 会不会泄漏我的个人信息? 更深度的用户还会考虑:我的系统是不…...
)
Java 实现 Awaitable(多线程并行等待,类似 AutoEventReset 的作用)
AutoEventReset、ManualEventReset,是我们在多线程并行编程之中常常需要涉及的,但是 ManualEventReset 可能用的并没有那么多,这个多用于实现读写锁的,当然 Java 自己库提供了官方实现,就没必要自己去整了。 C/C 里面…...

AI之Sora:Sora(文本指令生成视频的里程碑模型)的简介(能力/安全性/技术细节)、使用方法、案例应用之详细攻略
AI之Sora:Sora(文本指令生成视频的里程碑模型)的简介(能力/安全性/技术细节)、使用方法、案例应用之详细攻略 导读:Sora 是OpenAI研发的一个可以根据文字描述生成视频的AI模型。它的主要特性、功能以及OpenAI在安全和应用方面的策略的核心要点如下所示&a…...

IListManger feeds流
目的:将feeds的分页加载和下拉刷新,与网络请求关联起来 ListLibRecyclerViewProxy 在this.getRecyclerView().addOnScrollListener中记录事件 recyclerView.computeVerticalScrollOffset() // 已经向下滚动的距离,为0时表示已处于顶部。 recyclerView.computeVerticalScro…...
视频推拉流EasyDSS视频直播点播平台授权出现激活码无效并报错400是什么原因?
视频推拉流EasyDSS视频直播点播平台集视频直播、点播、转码、管理、录像、检索、时移回看等功能于一体,可提供音视频采集、视频推拉流、播放H.265编码视频、存储、分发等视频能力服务,在应用场景上,平台可以运用在互联网教育、在线课堂、游戏…...

设计模式三:工厂模式
工厂模式包括简单工厂模式、工厂方法模式和抽象工厂模式,其中后两者属于23中设计模式 各种模式中共同用到的实体对象类: //汽车类:宝马X3/X5/X7;发动机类:B48TU、B48//宝马汽车接口 public interface BMWCar {void s…...
2024.2.15 模拟实现 RabbitMQ —— 消息持久化
目录 引言 约定存储方式 消息序列化 重点理解 针对 MessageFileManager 单元测试 小结 统一硬盘操作 引言 问题: 关于 Message(消息)为啥在硬盘上存储? 回答: 消息操作并不涉及到复杂的增删查改消…...

【技巧】金融企业在搭建服务器时,选择私有云方案还是全栈专属云?
金融企业在搭建服务器时,选择私有云方案还是全栈专属云,需要根据企业的具体需求和情况进行综合考虑。Cloud Ace云一作为谷歌云全球战略合作伙伴,专注于企业级出海云服务 ,为大家带来两种方案的优劣势比较: 私有云 优势…...
模型评测)
【大厂AI课学习笔记】【2.2机器学习开发任务实例】(10)模型评测
目录 一、模型评测的定义 二、模型评测的方法 三、模型评测的原理 四、涉及的关键技术 五、实例阐述 今天是2.2机器学习开发任务实例的最后一个部分——模型评测。 不同的模型计算出的MSE值会有差异,通过模型的选择,参数的变换,可以比较…...
【C++游戏开发-03】贪吃蛇
文章目录 前言一、工具准备1.1游戏开发框架1.2visual studio2022下载1.3easyX下载1.4图片素材 二、逻辑分析2.1数据结构2.2蛇的移动2.3吃食物2.4游戏失败 三、DEMO代码实现四、完整源代码总结 🐱🚀个人博客https://blog.csdn.net/qq_51000584?typeblo…...
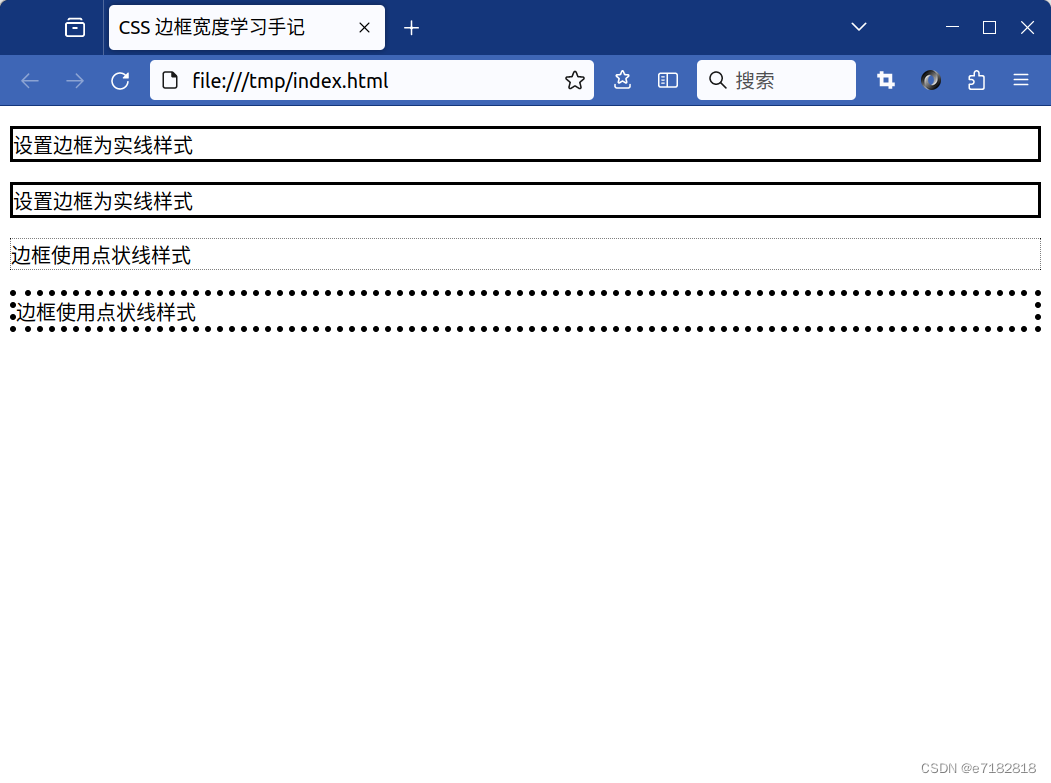
如何理解CSS的边框宽度?
CSS 边框宽度学习手记 CSS 边框宽度小概念 在CSS的世界里,border-width这个属性真的很实用,它能帮我指定HTML元素四周边框的宽度。这个宽度嘛,可以用像素px、点pt、厘米cm、相对单位em这些来表示,很方便吧!还有呢&am…...

java 写入写出 zip
package com.su.test.aaaTest.ioTest; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.util.zip.ZipEntry; import java.util.zip.ZipOutputStream; /** 将文件压缩到 zip 中 */ public c…...
)
DeepSeek V2多模态支持真相(官方未公开的API隐藏能力全披露)
更多请点击: https://codechina.net 第一章:DeepSeek V2多模态支持真相(官方未公开的API隐藏能力全披露) DeepSeek V2 官方文档明确声明为纯文本大模型,但逆向分析其生产环境 API 流量与响应头后发现:其底…...

【案例共创】CodeArts+SKILL 双引擎:AI 驱动 WEB 服务器极速部署
本案例由开发者:JeffDing提供,华为开发者空间案例中心优化并收录。 最新案例动态,请查阅【案例共创】CodeArtsSKILL 双引擎:AI 驱动 WEB 服务器极速部署小伙伴们快来进行实操吧! 一、概述 1.1 案例介绍 华为云码道…...
)
用随机森林实现手写英文字母识别(Python实战)
1. 项目概述:用随机森林搞定手写信件识别,这事儿比你想象中更接地气 “How To Perform Letter Recognition in Python Using Random Forest Classifier”——这个标题乍看像教科书里的章节名,但实际拆开来看,它直指一个非常具体、…...

AI——LangChain 三大核心概念
LangChain 三大核心概念一、LangChain 三大核心概念1. 提示词模板 PromptTemplate2. 模型调用 ChatOpenAI / ChatZhipuAI3. 链 Chain二、完整可运行代码(带角色设定)功能三、如果你想用 **智谱 GLM**四、总结一、LangChain 三大核心概念 1. 提示词模板 …...
)
C++ 左右值引用 完全详解(从入门到精通)
左右值引用是 C11 引入的最核心、影响最深远的特性,它直接催生了移动语义、完美转发、智能指针优化等现代 C 的基石。本文从最基础的定义开始,逐层深入到所有高级特性和常见陷阱,看完就能解决 99% 的面试和开发问题。一、先彻底搞懂ÿ…...

通达信缠论量化插件:自动化技术分析新体验
通达信缠论量化插件:自动化技术分析新体验 【免费下载链接】Indicator 通达信缠论可视化分析插件 项目地址: https://gitcode.com/gh_mirrors/ind/Indicator 通达信缠论量化插件是一款基于缠论理论的智能分析工具,通过算法自动化识别K线走势中的关…...

Unity 2D开发核心原理:坐标系统、物理引擎与资源契约
1. 为什么“Unity 2D 游戏开发教程(二)”不是续集,而是分水岭 很多人点开这个标题,下意识以为是“上一讲的延续”,就像看剧追更一样等着主角升级打怪。但实际在Unity 2D开发的真实工作流里,“第二讲”从来不…...

Chrome二维码插件终极指南:3分钟解决跨设备链接传输难题
Chrome二维码插件终极指南:3分钟解决跨设备链接传输难题 【免费下载链接】chrome-qrcode :zap: A Chrome plugin to Genrate QRCode of URL / Text, or Decode the QRcode in website. 一个Chrome浏览器插件,用于生成当前URL或者选中内容的二维码&#x…...

WPF-VisionMasterOpenCV
WPF-VisionMasterOpenCV 一、项目概述 WPF-VisionMasterOpenCV 是一个基于 WPF EmguCV(OpenCV的.NET封装)开发的机器视觉软件框架。它采用节点流程图的方式,让用户可以通过拖拽节点来构建视觉检测流程。 项目架构 WPF-VisionMaster/ ├─…...

从靶场搭建到防御加固:一次Hydra爆破Win7 SMB的完整复盘与安全启示
从攻击到防御:SMB协议安全实战分析与加固指南 当一台运行Windows 7系统的计算机暴露在网络中时,它可能正在无声地发出安全警报。SMB协议作为Windows生态中广泛使用的文件共享服务,常常成为攻击者突破内网的第一道门户。本文将从一个真实的渗透…...