大数据计算技术秘史(上篇)
在之前的文章《2024 年,一个大数据从业者决定……》《存储技术背后的那些事儿》中,我们粗略地回顾了大数据领域的存储技术。在解决了「数据怎么存」之后,下一步就是解决「数据怎么用」的问题。
其实在大数据技术兴起之前,对于用户来讲并没有存储和计算的区分,都是用一套数据库或数据仓库的产品来解决问题。而在数据量爆炸性增长后,情况就变得不一样了。单机系统无法存储如此之多的数据,先是过渡到了分库分表这类伪分布式技术,又到了 Hadoop 时代基于分布式文件系统的方案,后来又到了数据库基于一致性协议的分布式架构,最终演进为现在的存算分离的架构。
最近十几年,Data Infra 领域的计算技术以及相关公司层出不穷,最终要解决的根本问题其实只有一个:如何让用户在既灵活又高效,架构既简单又兼具高扩展性,接口既兼容老用户习惯、又能满足新用户场景的前提下使用海量数据。
解读一下,需求如下:
数据量大、数据种类多、数据逻辑复杂
支持 SQL 接口,让习惯了 SQL 接口的 BI 老用户们实现无缝迁移,同时要想办法支持 AI 场景的接口——Python
交互式查询延迟要低,能支持复杂的数据清洗任务,数据接入要实时
架构尽量简单,不要有太多的运维成本,同时还能支持纵向、横向的水平扩展,有足够的弹性
据太可研究所(techinstitute)所知,目前市面上没有哪款产品能同时满足以上所有要求,如果有,那一定是骗人的。所以在计算领域诞生了众多计算引擎、数据库、计算平台、流处理、ETL 等产品,甚至还有一个品类专门做数据集成,把数据在各个产品之间来回同步,对外再提供统一的接口。
不过,如果在计算领域只能选一个产品作为代表,那毫无疑问一定是 Spark。从 09 年诞生起到现在,Spark 已经发布至 3.5.0 版本,社区依旧有很强的生命力,可以说穿越了一个技术迭代周期。它背后的商业公司 Databricks 已经融到了 I 轮,估值 430 亿💲,我们不妨沿着 Spark 的发展历史梳理一下计算引擎技术的变革。
Vol.1
大数据计算的场景主要分两类,一是离线数据处理,二是交互式数据查询。离线数据处理的的特点产生的数据量大、任务时间长(任务时长在分钟级甚至是小时级),主要对应数据清洗任务;交互式查询的特点是任务时间短、并发大、输出结果小,主要对应 BI 分析场景。
时间拨回 2010 年之前,彼时 Spark 还没开源,当时计算引擎几乎只有 Hadoop 配套的 MapReduce 可以用,早年间手写 MapReduce 任务是一件门槛很高的事情。MapReduce 提供的接口非常简单,只有 mapper、reducer、partitioner、combiner 等寥寥几个,任务之间传输数据只有序列化存到 hdfs 这一条路,而真实世界的任务不可能只有 Word Count 这种 demo。所以要写好 MapReduce 肯定要深入理解其中的原理,要处理数据倾斜、复杂的参数配置、任务编排、中间结果落盘等。现在 MapReduce 已经属于半入土的技术了,但它还为业界留下了大量的徒子徒孙,例如各个云厂商的 EMR 产品,就是一种传承。
Spark 开源之后为业界带来了新的方案,RDD 的抽象可以让用户像正常编写代码一样写分布式任务,还支持 Python、Java、Scala 三种接口,大大降低了用户编写任务的门槛。总结下来,Spark 能短时间内获得用户的青睐有以下几点:
更好的设计,包括基于宽窄依赖的 dag 设计,能大大简化 job 编排
性能更高,计算在内存而非全程依赖 hdfs,这是Spark 早期最大的卖点,直到 Spark2.x 的官网上还一直放着一张和 mapreduce 的性能对比,直到这几年没人关心 mapreduce 之后才撤掉
更优雅的接口,RDD 的抽象以及配套的 API 更符合人类的直觉
API 丰富,除了 RDD 和配套的算子,还支持了Python 接口,这直接让受众提升了一个数量级
但早期的 Spark 也有很多问题,例如内存管理不当导致程序 OOM、数据倾斜问题、继承了 Hadoop 那套复杂的配置。Spark 诞生之初非常积极地融入 Hadoop 体系,例如,代码里依赖了大量 Hadoop 的包,文件系统和文件访问接口沿用了 Hadoop 的设计,资源管理一开始只有 Hadoop 的 Yarn。直到现在这些代码依旧大量使用,未来也不可能再做修改,所以说尽管 Hadoop 可能不复存在,但 Hadoop 的代码会一直保留下去,在很多计算引擎里面发挥着不可替代的作用。
Vol.2
无论是非常难用的 MapReduce 接口,还是相对没那么难用的 Spark RDD 接口,受众只是研发人员,接口是代码。
无论是做数据清洗的数据工程师,还是使用 BI 的数据分析师,最熟悉的接口还是 SQL。
因此,市面上便诞生了大量 SQL on Hadoop 的产品,很多产品直到现在也还很有生命力。
最早出现的是 Hive,Hive 的影响力在大数据生态里太大,大到很多人都以为它是 Hadoop 原生自带的产品,不知道它是 Facebook 开源的。Hive 主要的能力只有一个就是把 SQL 翻译成 MapReduce 任务,这件事说来简单,好像也就是本科生大作业的水平,但想把它做好却是件非常有挑战性的工作,早期也只有 Hive 做到了,而且成为了事实上的标准。
要把 SQL 翻译成 MapReduce 任务,需要有几个必备组件,一是 SQL 相关的 Parser、Planner、Optimizer、Executor,基本上是一个 SQL 数据库的标配,二是 metadata,需要存储数据库、表、分区等信息,以及表和 HDFS数据之间的关系。
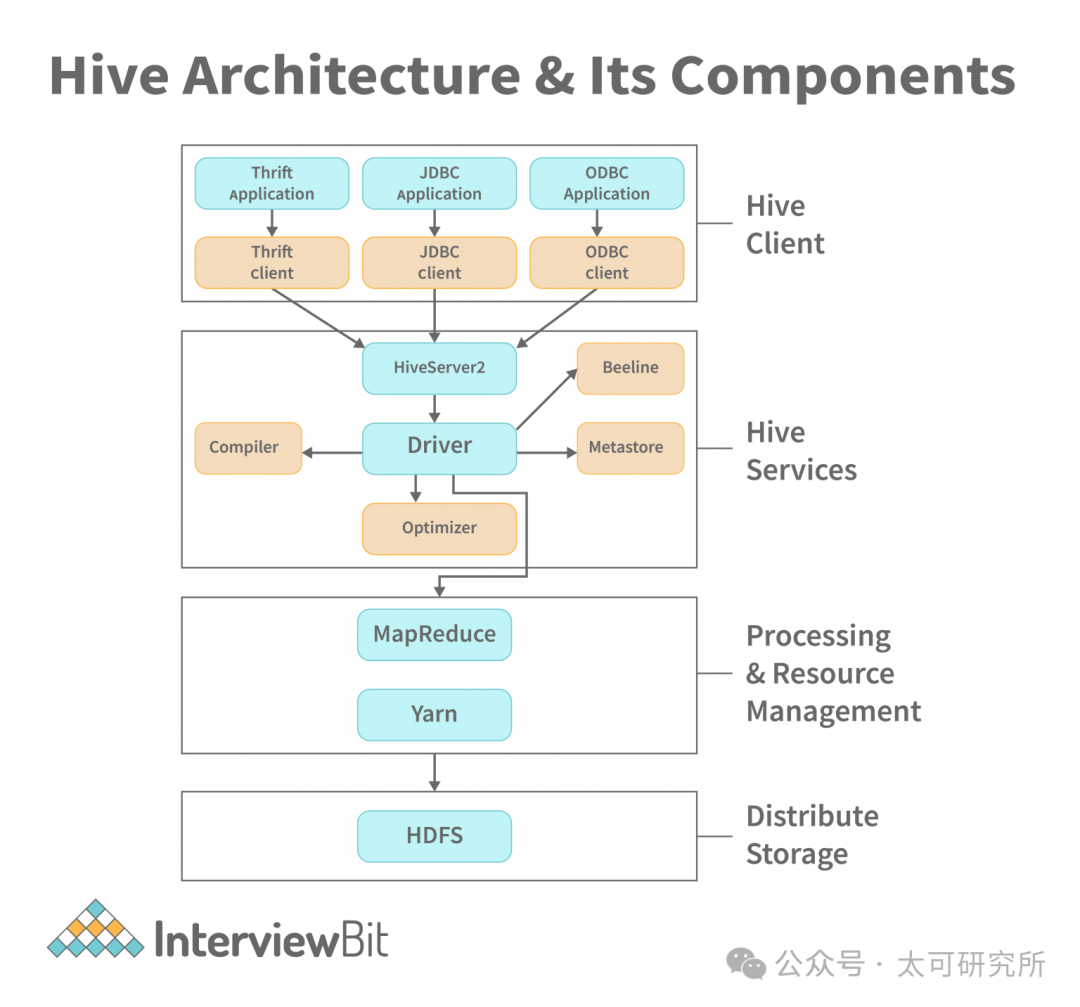 图源|https://www.interviewbit.com/blog/hive-architecture/
图源|https://www.interviewbit.com/blog/hive-architecture/
Hive 的这套思路影响了后来众多的计算引擎,例如 Spark SQL、Presto 等默认都会支持 Hive Metastore。Hive 的架构最大的瓶颈就在 MapReduce 上,无法做到低延迟的查询,也就无法解决用户低延迟、交互式分析的需求。有个很直观的例子,每次用户提交一个 Hive 查询,可以去喝一杯咖啡再回来看结果。此外,哪怕是离线数据清洗的任务使用 Hive 也相对较慢。
Spark 在 2012 年发布的 0.8 版本中开发了 Spark SQL 模块,类似 Hive 的思路,把 SQL 编译成 RDD 任务,同时期的 Presto 也进入了 Apache 孵化器,目标也是解决大数据场景下交互式分析的场景。Spark 和 Presto 支持 SQL 的时间相仿,但后来走上了相当不同的道路,Presto 的定位更接近一个 OLAP 数据库,重心在交互式查询场景,而 Spark 则将注意力放在数据处理任务上,是一个开发分布式任务的框架,自始至终都不是一个完整的数据库,市面上基于 Spark 开发的数据库产品,倒是有不少。
通过 SQL 交互在 10 年代早期,逐渐变成了主流使用大数据产品的主流范式,包括离线任务、交互式查询的接口都逐渐统一到了SQL。随着数据量进一步增长,查询性能一直解决得不好,哪怕是 Spark SQL、Presto,也只能把延迟降低到分钟级别,还是远远无法满足业务的需求。
这种情况直到 2015 年 Kylin 开源才得以解决,基于Cube、预计算技术第一次将大数据领域的交互式查询延迟降低到了秒级,做到了和传统数仓达类似的查询体验。但 kylin 的做法代价也很大,用户需要自定义各种模型、Cube、维度、指标等等概念非常复杂,还要学会设计 rowkey 否则性能也不会很好。Kylin 的出现让业界看到了秒级延迟的可能性,至此内业一些同学甚至觉得大数据场景下 Hadoop + Hive + Spark + Kylin + HBase 可能就是最优解了,顶多还需要加上 Kafka + Flink 去解决实时数据的问题。
但是,2018 年 Clickhouse 横空出世,通过 SIMD、列存、索引优化、数据预热等一系列的暴力优化,竟然也可把查询延迟降低到秒级,而且架构极其简单,只要 Zookeeper + Clickhouse,就能解决上面一堆产品叠加才可解决的问题。这一下子戳中了 Hadoop 体系的痛点——Hadoop 体系产品太多、架构太复杂、运维困难。
自 ClickHouse 后,数据库产品们便开始疯狂吸收其优秀经验,大数据和数据库两个方向逐渐融合,业界重新开始思考「大数据技术真的需要单独的一个体系吗?」「Hadoop 的方向是对的吗?」「数据库能不能解决海量数据的场景?」这个话题有点宏大,可以放在以后讨论。
Vol.3
说回计算引擎,早期的引擎无论是 Hive 也好,Spark 的 RDD 接口也罢,都不适合实时的数据写入。而在大数据技术演进的这些年里,用户的场景也越来越复杂。早期的离线计算引擎只能提供离线数据导入,这就使得用户只能做 T+1 或近似 T+0 的分析。但很多场景需要的是实时分析,到现在,实时分析已经成为了新引擎的标配。
Spark 在 0.9 本版里提供了一套 Spark streaming 接口尝试解决实时的问题,但扒开 Spark streaming 的代码,不难发现它实际上是一段时间触发一个微批任务,对于延迟没那么敏感的用户其实已经够用了。当然也有想要近乎没有延迟的用户,例如金融交易监控、广告营销场景、物联网的场景等。
实时流数据的难度要远高于批处理,首先,如何做到低延迟就是个难点。其次,流数据本身质量远低于批数据,具体体现在流数据会有乱序、数据丢失、数据重复的问题。此外,要做流处理还需要确保任务能长期稳定地运行,这与批处理任务跑完就结束对稳定性的要求很不一样。最后,还有很复杂的数据状态管理,包括 checkpoint 管理、增量更新、状态数据一致性、持久化的问题。
Apache Flink 对这些问题解决的远比 Spark streaming 要好,所以在很长时间内 Flink 就是流计算的代名词。Spark 直到 2.0 发布了 structured streaming 模块之后,才有了和 Flink 同台竞技的资格。Flink 虽然在流计算场景里是无可争议的领导者,但在流计算的场景和市场空间远小于离线计算、交互式分析的市场。可以这样认为,其在数据分析领域锦上添花的功能而非必备能力,Flink 背后的团队和 Databricks 差距也很大,曾创业两次,又先后卖给阿里和 Confluent,这可能也是 Flink 的影响力远小于 Spark 的原因。
好了,本次的大数据计算技术漫谈(上)就先谈到这里,下周同一时间,咱们继续!
本文由 mdnice 多平台发布
相关文章:
大数据计算技术秘史(上篇)
在之前的文章《2024 年,一个大数据从业者决定……》《存储技术背后的那些事儿》中,我们粗略地回顾了大数据领域的存储技术。在解决了「数据怎么存」之后,下一步就是解决「数据怎么用」的问题。 其实在大数据技术兴起之前,对于用户…...
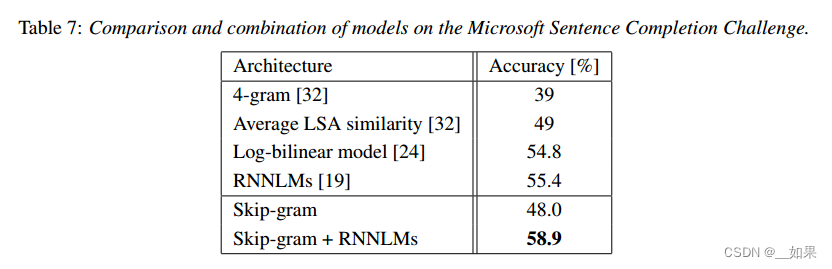
论文精读--word2vec
word2vec从大量文本语料中以无监督方式学习语义知识,是用来生成词向量的工具 把文本分散嵌入到另一个离散空间,称作分布式表示,又称为词嵌入(word embedding)或词向量 Abstract We propose two novel model architec…...

Android13 针对low memory killer内存调优
引入概念 在旧版本的安卓系统中,当触发lmk(low memory killer)的时候一般认为就是内存不足导致,但是随着安卓版本的增加lmk的判断标准已经不仅仅是内存剩余大小,io,cpu同样会做评判,从而保证设备…...
【深入理解设计模式】 工厂设计模式
工厂设计模式 工厂设计模式是一种创建型设计模式,它提供了一种在不指定具体类的情况下创建对象的接口。在工厂设计模式中,我们定义一个创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。 工厂设计模式的目…...
Windows下搭建EFK实例
资源下载 elasticSearch :下载最新版本的就行 kibana filebeat:注意选择压缩包下载 更新elasticsearch.yml,默认端口9200: # Elasticsearch Configuration # # NOTE: Elasticsearch comes with reasonable defaults for most …...
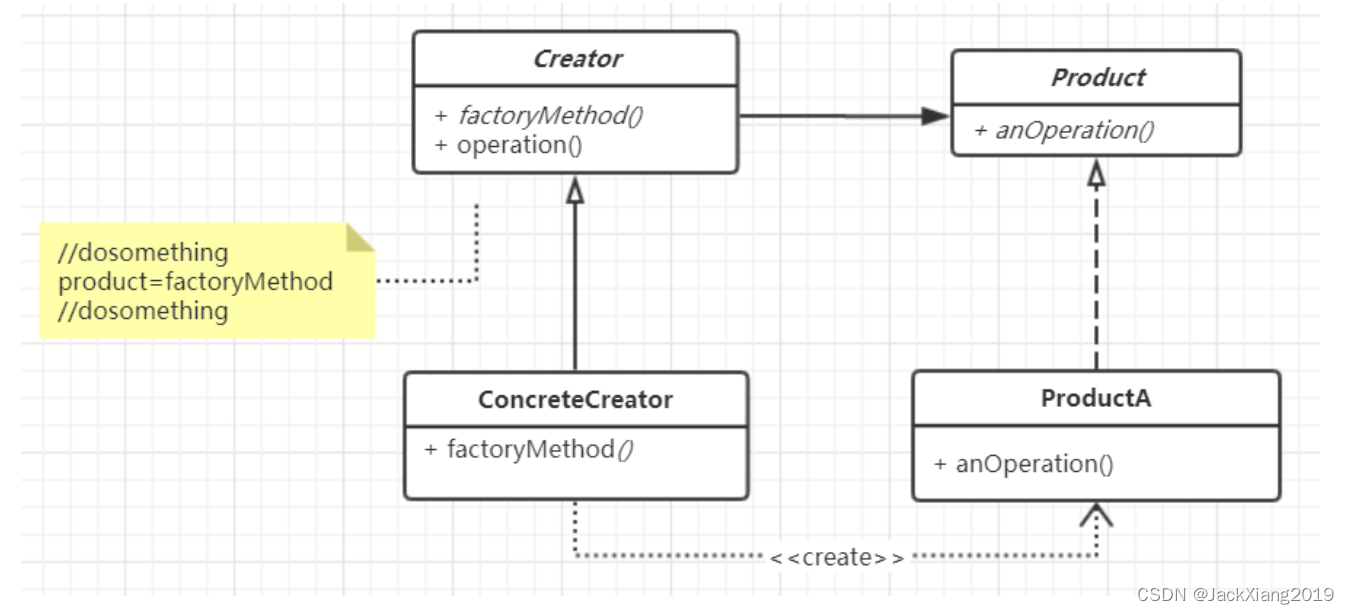
工厂方法模式Factory Method
1.模式定义 定义一个用于创建对象的接口,让子类决定实例化哪一个类。Factory Method 使得一个类的实例化延迟到子类 2.使用场景 1.当你不知道改使用对象的确切类型的时候 2.当你希望为库或框架提供扩展其内部组件的方法时 主要优点: 1.将具体产品和创建…...

Vue的个人笔记
Vue学习小tips ctrl s ----> 运行 alt b <scrip> 链接 <script src"https://cdn.jsdelivr.net/npm/vue2.7.16/dist/vue.js"></script> 插值表达式 指令...

linux platform架构下I2C接口驱动开发
目录 概述 1 认识I2C协议 1.1 初识I2C 1.2 I2C物理层 1.3 I2C协议分析 1.3.1 Start、Stop、ACK 信号 1.3.2 I2C协议的操作流程 1.3.3 操作I2C注意的问题 2 linux platform驱动开发 2.1 更新设备树 2.1.1 添加驱动节点 2.1.2 编译.dts 2.1.3 更新板卡中的.dtb 2.2 …...
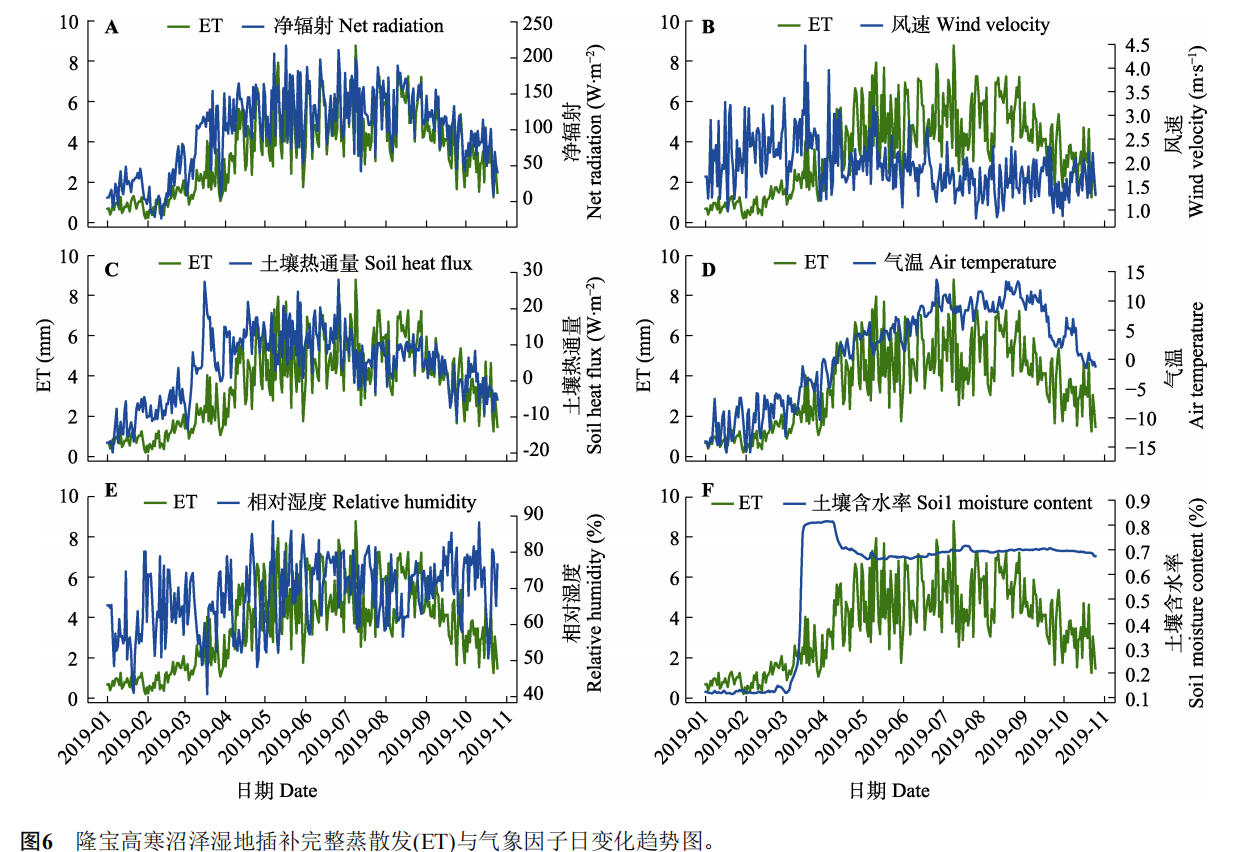
基于机器学习的青藏高原高寒沼泽湿地蒸散发插补研究_王秀英_2022
基于机器学习的青藏高原高寒沼泽湿地蒸散发插补研究_王秀英_2022 摘要关键词 1 材料和方法1.1 研究区概况与数据来源1.2 研究方法 2 结果和分析2.1 蒸散发通量观测数据缺省状况2.2 蒸散发与气象因子的相关性分析2.3 不同气象因子输入组合下各模型算法精度对比2.4 随机森林回归模…...

Failed at the node-sass@4.14.1 postinstall script.
问题描述 安装sass # "node-sass": "^4.9.0" npm i node-sass报错如下 npm ERR! code ELIFECYCLE npm ERR! errno 1 npm ERR! node-sass4.14.1 postinstall: node scripts/build.js npm ERR! Exit status 1 npm ERR! npm ERR! Failed at the node-sass4…...

【鸿蒙系统学习笔记】网络请求
一、介绍 资料来自官网:文档中心 网络管理模块主要提供以下功能: HTTP数据请求:通过HTTP发起一个数据请求。WebSocket连接:使用WebSocket建立服务器与客户端的双向连接。Socket连接:通过Socket进行数据传输。 日常…...

LabVIEW风力机智能叶片控制系统
LabVIEW风力机智能叶片控制系统 介绍了一种风力机智能叶片控制系统的开发。通过利用LabVIEW软件与CDS技术,该系统能够实时监测并调整风力机叶片的角度,优化风能转换效率。此项技术不仅提高了风力发电的稳定性和效率,而且为风力机的智能化管…...

HarmonyOS Stage模型 权限申请
配置声明权限 在module.json5配置文件中声明权限。不论是system_grant还是user_grant类型都需要声明权限,否则应用将无法获得授权。 {"module" : {// ..."requestPermissions":[{"name": "ohos.permission.DISCOVER_BLUETOOTH…...

标题:从预编译到链接:探索C/C++程序的翻译环境全貌
引言 在软件开发的世界里,我们通常会遇到两种不同的环境——翻译环境与运行环境。今天,我们将聚焦于前者,深入剖析C/C程序生命周期中至关重要的“翻译环境”,即从源代码到可执行文件这一过程中涉及的四个关键阶段:预编…...
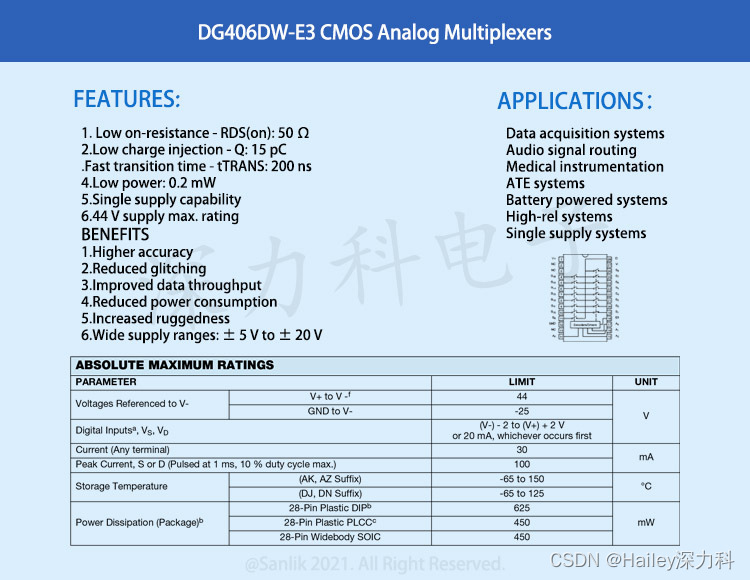
深入理解单端模拟多路复用器DG406DW-E3 应用于高速数据采集、ATE系统和航空电子设备解决方案
DG406DW-E3是一款16通道单端模拟多路复用器设计用于将16个输入中的一个连接到公共端口由4位二进制地址确定的输出。应用包括高速数据采集、音频信号切换和路由、ATE系统和航空电子设备。高性能低功耗损耗使其成为电池供电和电池供电的理想选择远程仪器应用。采用44V硅栅CMOS工艺…...

Redis篇----第六篇
系列文章目录 文章目录 系列文章目录前言一、Redis 的持久化机制是什么?各自的优缺点?二、Redis 常见性能问题和解决方案:三、redis 过期键的删除策略?前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章…...
——代码随想录算法训练营Day38)
【LeetCode】509. 斐波那契数(简单)——代码随想录算法训练营Day38
题目链接:509. 斐波那契数 题目描述 斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是: F(0) 0,F(1) 1 F(n) F(n -…...
 函数对累积缓存设置)
[OpenGL教程05 ] glAccum() 函数对累积缓存设置
Accumulation Buffer:累积缓存 一、说明 openGL编程之所以困难,是因为它是三维图表示;简简单单加入一个Z轴,却使得几何遮挡、光线过度、运动随影等搞得尤其复杂。它的核心处理环节是像素缓存,本篇的积累缓存就是其一个…...

BeautifulSoup的使用与入门
1. 介绍 BeautifulSoup是用来从HTML、XML文档中提取数据的一个python库,安装如下: pip install beautifulsoup4 它支持多种解析器,包括python标准库、lxml HTML解析器、lxml XML解析器、html5lib等。结合稳定性和速度,这里推荐使用lxml HT…...
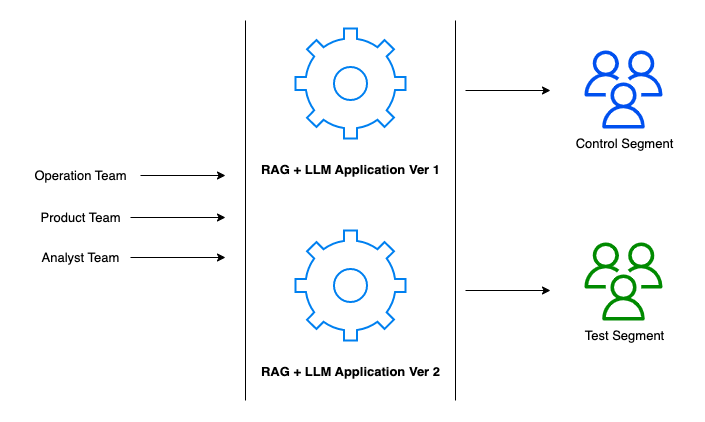
LLM之RAG实战(二十七)| 如何评估RAG系统
有没有想过今天的一些应用程序是如何看起来几乎神奇地智能的?这种魔力很大一部分来自于一种叫做RAG和LLM的东西。把RAG(Retrieval Augmented Generation)想象成人工智能世界里聪明的书呆子,它会挖掘大量信息,准确地找到…...

关联查询,左连接,inner join笔记,BNL,NLJ
文章目录left join的最大值和最小值3个表的inner join关联查询时的is_del处理cross join(full join)NLJ 性能高BNL 性能低blj会导致什么问题?left join的最大值和最小值 假设左表m条,右表n条 最小值是m: 当一条也匹配不到右表时,或者右表中…...

C++ `dynamic_cast
1. 基础 C类型转换概览为什么需要dynamic_cast 2. dynamic_cast 的使用 基本语法与其他类型转换(如 static_cast、reinterpret_cast 和 const_cast)的对比 3. RTTI (运行时类型信息) 什么是RTTI如何在C中启用和禁用RTTI 4. dynamic_cast 与多态 使用dyna…...

FNF-PsychEngine终极指南:3个Lua脚本技巧让游戏体验飙升
FNF-PsychEngine终极指南:3个Lua脚本技巧让游戏体验飙升 【免费下载链接】FNF-PsychEngine Engine originally used on Mind Games mod 项目地址: https://gitcode.com/gh_mirrors/fn/FNF-PsychEngine FNF-PsychEngine是一款功能强大的节奏游戏引擎ÿ…...

YetiForceCRM社区与支持:如何获得帮助并参与开源贡献
YetiForceCRM社区与支持:如何获得帮助并参与开源贡献 【免费下载链接】YetiForceCRM Weve moved! For more information, visit https://github.com/YetiForceCompany/YetiForce 项目地址: https://gitcode.com/gh_mirrors/ye/YetiForceCRM YetiForceCRM是一…...

智慧树自动刷课插件:3分钟安装的终极学习效率提升指南
智慧树自动刷课插件:3分钟安装的终极学习效率提升指南 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的冗长视频课程烦恼吗?智…...

终极指南:3分钟解决微信网页版无法访问的难题
终极指南:3分钟解决微信网页版无法访问的难题 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为微信网页版无法访问而烦恼吗ÿ…...

如何用OpenCATS免费开源招聘系统3天搭建企业级人才库
如何用OpenCATS免费开源招聘系统3天搭建企业级人才库 【免费下载链接】OpenCATS Open-source applicant tracking system (ATS) and recruitment CRM for staffing agencies and hiring teams. 项目地址: https://gitcode.com/gh_mirrors/op/OpenCATS 还在为招聘流程混乱…...

终极指南:3分钟掌握TMSpeech,打造完全本地的实时语音转文字神器
终极指南:3分钟掌握TMSpeech,打造完全本地的实时语音转文字神器 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 你是否厌倦了云端语音识别服务的隐私担忧和网络延迟?想要一个真正…...

线下技术沙龙:AI Coding深度实践LLM应用分享
活动简介 我们正在经历一场软件开发 范式的变革。从Copilot的智能补全,到Cursor的对话式编程,再到Agent自主完成复杂任务——代码的编写方式,正在被重新定义。 但这场变革的核心,不是工具本身,而是使用工具的人。 本…...
深入RT-DETR混合编码器:我是如何把Transformer计算瓶颈‘砍掉’一半的
深入RT-DETR混合编码器:我是如何把Transformer计算瓶颈‘砍掉’一半的 在目标检测领域,实时性能一直是工业界和学术界共同追求的圣杯。当传统YOLO系列通过精心设计的卷积网络不断刷新速度记录时,Transformer架构的DETR家族却因沉重的计算负担…...