《Spring源码深度分析》第4章 自定义标签的解析
目录标题
- 前言
- 一、自定义标签使用
- 二、自定义标签解析
- 1、代码入口
- 2、parseCustomElement【BeanDefinitionParserDelegate】
- 2.1 resolve【DefaultNamespaceHandlerResolver】
- 3、parse【NamespaceHandlerSupport】
- 4、parse【AbstractBeanDefinitionParser】
- 4.1 parseInternal【AbstractSingleBeanDefinitionParser】
- 总结
前言
汇总:《Spring源码深度分析》持续更新中…
在之前的章节中,我们提到了在 Spring 中存在默认标签与自定义标签两种,而在上一章节中我们分析了 Spring 中对默认标签的解析过程,相信大家一定已经有所感悟。那么,现在将开始新的里程,分析 Spring 中自定义标签的加载过程。
一、自定义标签使用
在分析Spring的自定义标签源码之前,我们可以自己手写一个自定义标签:
【Spring学习】Spring自定义标签详细步骤
二、自定义标签解析
1、代码入口
DefaultBeanDefinitionDocumentReader的parseBeanDefinitions方法:
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {if (delegate.isDefaultNamespace(root)) {NodeList nl = root.getChildNodes();for (int i = 0; i < nl.getLength(); i++) {Node node = nl.item(i);if (node instanceof Element) {Element ele = (Element) node;if (delegate.isDefaultNamespace(ele)) {// 解析默认的标签元素parseDefaultElement(ele, delegate);}else {// 解析自定义的标签元素delegate.parseCustomElement(ele);}}}}// 解析自定义的标签元素else {delegate.parseCustomElement(root);}}
2、parseCustomElement【BeanDefinitionParserDelegate】
@Nullablepublic BeanDefinition parseCustomElement(Element ele, @Nullable BeanDefinition containingBd) {// 获取自定义标签的命名空间String namespaceUri = getNamespaceURI(ele);if (namespaceUri == null) {return null;}// 根据命名空间,获取对应的'自定义标签处理器'(spring.handlers)NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);if (handler == null) {error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);return null;}// 进行解析(NamespaceHandlerSupport的parse方法)return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));}2.1 resolve【DefaultNamespaceHandlerResolver】
此处会调用子类的init方法,用于【注册解析器】。
public NamespaceHandler resolve(String namespaceUri) {// 格式:Map<NameSpace,HandlerClassPathName>Map<String, Object> handlerMappings = getHandlerMappings();Object handlerOrClassName = handlerMappings.get(namespaceUri);if (handlerOrClassName == null) {return null;}else if (handlerOrClassName instanceof NamespaceHandler) {return (NamespaceHandler) handlerOrClassName;}else {String className = (String) handlerOrClassName;try {Class<?> handlerClass = ClassUtils.forName(className, this.classLoader);if (!NamespaceHandler.class.isAssignableFrom(handlerClass)) {throw new FatalBeanException("Class [" + className + "] for namespace [" + namespaceUri +"] does not implement the [" + NamespaceHandler.class.getName() + "] interface");}NamespaceHandler namespaceHandler = (NamespaceHandler) BeanUtils.instantiateClass(handlerClass);// 调用MyNamespaceHandler的init方法。注册解析器:registerBeanDefinitionParser("user", new UserBeanDefinitionParser());namespaceHandler.init();handlerMappings.put(namespaceUri, namespaceHandler);return namespaceHandler;}catch (ClassNotFoundException ex) {throw new FatalBeanException("Could not find NamespaceHandler class [" + className +"] for namespace [" + namespaceUri + "]", ex);}catch (LinkageError err) {throw new FatalBeanException("Unresolvable class definition for NamespaceHandler class [" +className + "] for namespace [" + namespaceUri + "]", err);}}}
3、parse【NamespaceHandlerSupport】
@Override@Nullablepublic BeanDefinition parse(Element element, ParserContext parserContext) {// 该自定义标签的解析器BeanDefinitionParser parser = findParserForElement(element, parserContext);// 调用AbstractBeanDefinitionParser中的parse方法return (parser != null ? parser.parse(element, parserContext) : null);}
4、parse【AbstractBeanDefinitionParser】
public final BeanDefinition parse(Element element, ParserContext parserContext) {// (重点)parseInternal是真正做解析的方法。 AbstractSingleBeanDefinitionParser//在 parseInternal 中并不是直接调用自定义的 doParse 函数,而是进行了一系列的数据准备,包括对 beanClass、 scope、lazyInit 等属性的准备。AbstractBeanDefinition definition = parseInternal(element, parserContext);if (definition != null && !parserContext.isNested()) {try {String id = resolveId(element, definition, parserContext);if (!StringUtils.hasText(id)) {parserContext.getReaderContext().error("Id is required for element '" + parserContext.getDelegate().getLocalName(element)+ "' when used as a top-level tag", element);}String[] aliases = null;if (shouldParseNameAsAliases()) {String name = element.getAttribute(NAME_ATTRIBUTE);if (StringUtils.hasLength(name)) {aliases = StringUtils.trimArrayElements(StringUtils.commaDelimitedListToStringArray(name));}}BeanDefinitionHolder holder = new BeanDefinitionHolder(definition, id, aliases);// 注册definition 和 aliasregisterBeanDefinition(holder, parserContext.getRegistry());if (shouldFireEvents()) {BeanComponentDefinition componentDefinition = new BeanComponentDefinition(holder);postProcessComponentDefinition(componentDefinition);//parserContext.registerComponent(componentDefinition);}}catch (BeanDefinitionStoreException ex) {String msg = ex.getMessage();parserContext.getReaderContext().error((msg != null ? msg : ex.toString()), element);return null;}}return definition;}
4.1 parseInternal【AbstractSingleBeanDefinitionParser】
此处会调用doParse方法,用于【解析自定义标签】。
protected final AbstractBeanDefinition parseInternal(Element element, ParserContext parserContext) {BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition();String parentName = getParentName(element);if (parentName != null) {builder.getRawBeanDefinition().setParentName(parentName);}Class<?> beanClass = getBeanClass(element);if (beanClass != null) {builder.getRawBeanDefinition().setBeanClass(beanClass);}else {String beanClassName = getBeanClassName(element);if (beanClassName != null) {builder.getRawBeanDefinition().setBeanClassName(beanClassName);}}builder.getRawBeanDefinition().setSource(parserContext.extractSource(element));BeanDefinition containingBd = parserContext.getContainingBeanDefinition();if (containingBd != null) {// Inner bean definition must receive same scope as containing bean.builder.setScope(containingBd.getScope());}if (parserContext.isDefaultLazyInit()) {// Default-lazy-init applies to custom bean definitions as well.builder.setLazyInit(true);}// (关键)调用子类的doParse方法。 自定义解析器的doParse方法doParse(element, parserContext, builder);return builder.getBeanDefinition();}
总结
回顾一下全部的自定义标签处理过程,虽然在实例中我们定义 UserBeanDefinitionParser,但是在其中我们只是做了与自己业务逻辑相关的部分。不过我们没做但是并不代表没有,在这个处理过程中同样也是按照 Spring 中默认标签的处理方式进行,包括创建 BeanDefinition 以及进行相应默认属性的设置,对于这些工作 Spring 都默默地帮我们实现了,只是**暴露出一些接口来供用户实现个性化的业务**。
通过对本章的了解,相信读者对 Spring 中自定义标签的使用以及在解析自定义标签过程中 Spring 为我们做了哪些工作会有一个全面的了解。到此为止我们已经完成了 Spring 中全部的解析工作,也就是说到现在为止我们已经理解了 Spring 将 bean 从配置文件到加载到内存中的全过程,而接下来的任务便是如何使用这些 bean,下一章将介绍 bean的加载。
相关文章:

《Spring源码深度分析》第4章 自定义标签的解析
目录标题前言一、自定义标签使用二、自定义标签解析1、代码入口2、parseCustomElement【BeanDefinitionParserDelegate】2.1 resolve【DefaultNamespaceHandlerResolver】3、parse【NamespaceHandlerSupport】4、parse【AbstractBeanDefinitionParser】4.1 parseInternal【Abst…...

MATLAB绘制椭圆形相关系矩阵图
数据/代码准备 数据及代码下载: 下载专区-《MATLAB统计分析与应用:40个案例分析》程序与数据 绘图函数: matrixplot(data, PARAM1,val1, PARAM2,val2, ...) 案例 数据如下: MATLAB代码如下: clc close all clear …...

「SQL面试题库」 No_1 员工薪水中位数
🍅 1、专栏介绍 「SQL面试题库」是由 不是西红柿 发起,全员免费参与的SQL学习活动。我每天发布1道SQL面试真题,从简单到困难,涵盖所有SQL知识点,我敢保证只要做完这100道题,不仅能轻松搞定面试ÿ…...
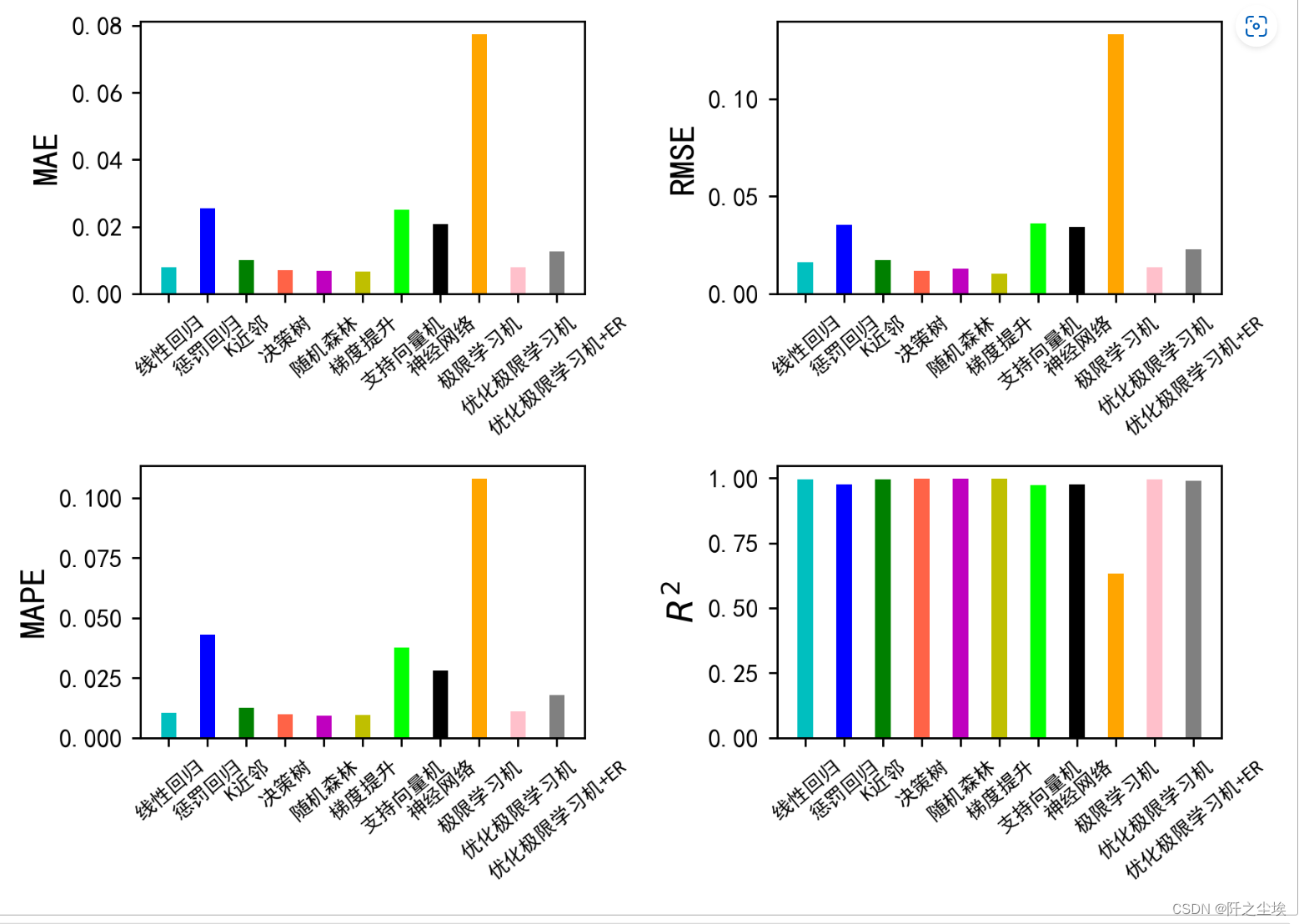
Python机器学习17——极限学习机(ELM)
本系列基本不讲数学原理,只从代码角度去让读者们利用最简洁的Python代码实现机器学习方法。 背景: 极限学习机(ELM)也是学术界常用的一种机器学习算法,严格来说它应该属于神经网络,应该属于深度学习栏目,但是我这里把它…...
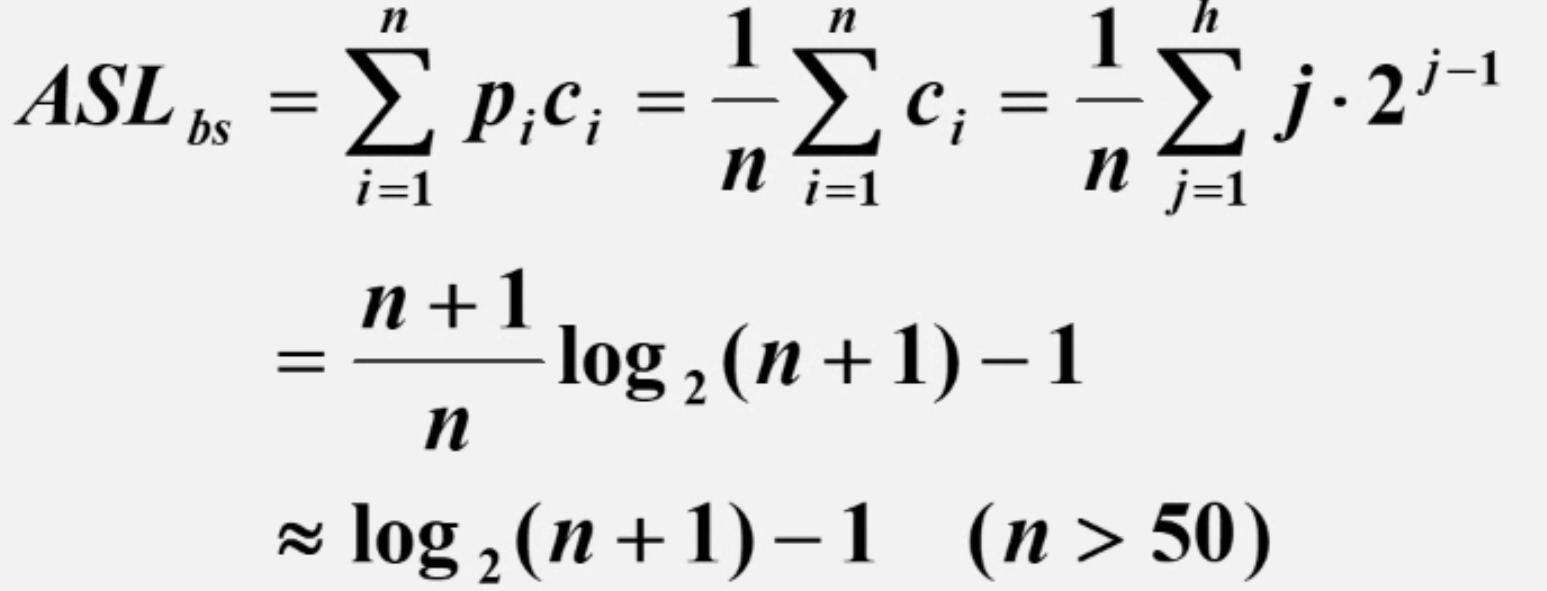
二分查找与判定树
二分查找的算法思想二分查找也称“折半查找”,要求查找表为采用顺序存储结构的有序表。本例一律采用升序排列。二分查找每一次都会比较给定值与序列[low,high]的中间元素,该元素的下标为mid (lowhigh)/2,若两者相等,则返回元素的下标为mid;如…...
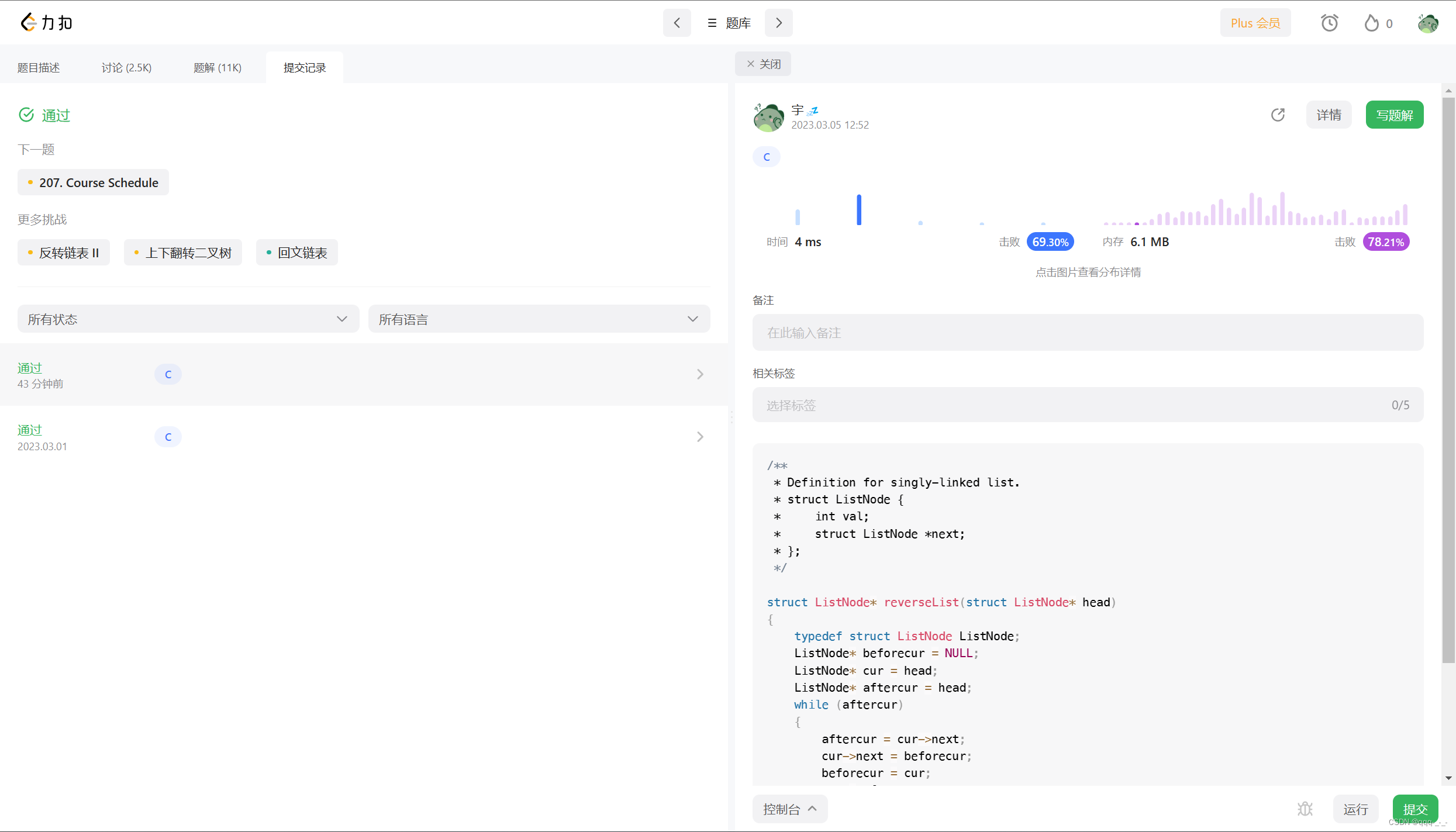
反转链表(精美图示详解哦)
全文目录引言反转链表题目描述与思路实现总结引言 在学习了单链表的相关知识后,尝试实现一些题目可以帮助我们更好的理解单链表的结构以及对其的使用。 从这篇文章开始,将会介绍一些编程题来帮助我们更好的掌握单链表: 分别是反转链表、链表…...

深入理解多线程
一、线程基本概念 1、概述 线程是允许应用程序并发的一种机制。线程共享进程内的所有资源。 线程是调度的基本单位。 每个线程都有自己的 errno。 所有 pthread 函数均以返回 0 表示成功,返回一个正值表示失败。 编译 pthread 程序需要添加链接库(…...
)
华为OD机试题 - 英文输入法(JavaScript)
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解: 英文输入法题目输入输出示例一输入输出说明示例一输入输出Code…...

64 云原生容器化
文章目录 一、什么是rancher二、为什么使用rancher三、 Rancher与[k8s](https://so.csdn.net/so/search?q=k8s&spm=1001.2101.3001.7020)的关系及区别1、Rancher具有的优势三、rancher安装1、细部介绍四、图形化操作1、执行2、图形化操作1、进行客户机登录rancher2、Ranch…...

IronXL for .NET 2023.2.5 Crack
关于适用于 .NET 的 IronXL 在 C# 中阅读和编辑 Excel 电子表格,无需 MS Office 或 Excel Interop。 IronXL for .NET 允许开发人员在 .NET 应用程序和网站中读取、生成和编辑 Excel(和其他电子表格文件)。您可以读取和编辑 XLS/XLSX/CSV/TS…...
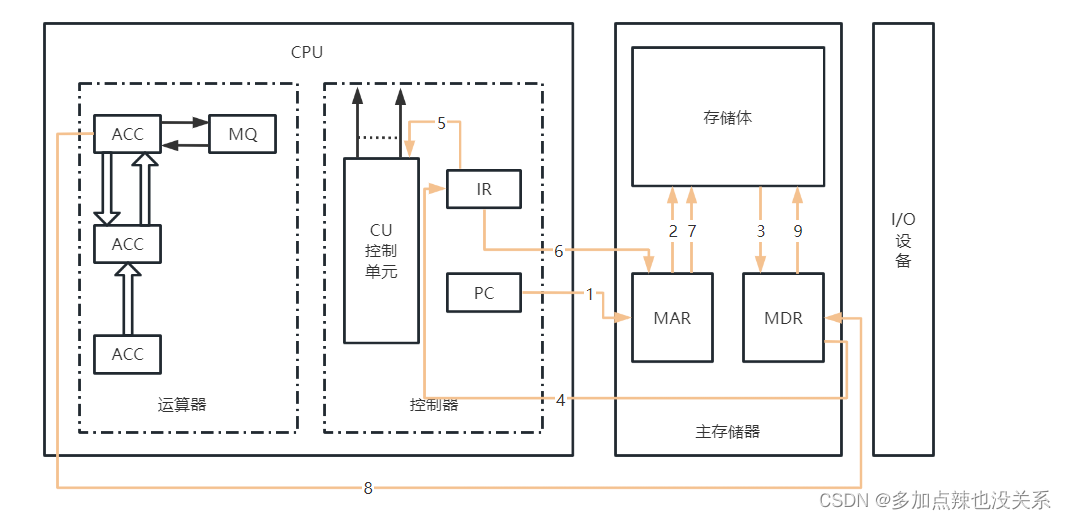
计算机组成原理|第一章(笔记)
目录第一章 计算机系统概论1.1 计算机系统简介1.1.1 计算机的软硬件概念1.1.2 计算机系统的层次结构1.1.3 计算机组成和计算机体系结构1.2 计算机的基本组成1.2.1 冯 诺伊曼计算机的特点1.2.2 计算机的硬件框图1.2.3 计算机的工作过程1.3 计算机硬件的主要技术指标1.3.1 机器字…...
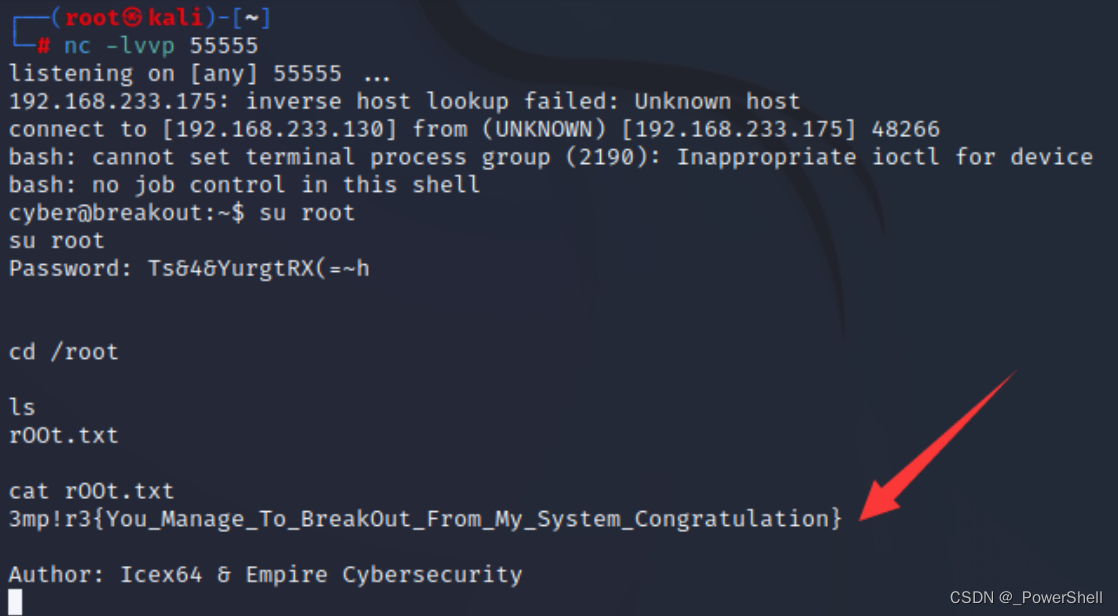
[ vulnhub靶机通关篇 ] Empire Breakout 通关详解
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...
IP定位离线库有什么作用?
IP离线是什么意思?我们以丢失手机为例来寻找它,现在手机都有IP定位功能,只要手机开通了IP定位,就能找到手机。iPhone定位显示离线一般是iPhone手机关机了或者iPhone手机中“查找我的iPhone”功能关闭了。如果手机在手中的话可以打…...

[C++]vector模拟实现
目录 前言: 1. vector结构 2. 默认成员函数 2.1 构造函数 无参构造: 有参构造: 有参构造重载: 2.2 赋值运算符重载、拷贝构造(难点) 2.3 析构函数: 3. 扩容 3.1 reserve 3.2 resize…...

DevOps实战50讲-(2)Jenkins配置
1. Docker镜像方式安装拉取Jenkins镜像docker pull jenkins/jenkins编写docker-compose.ymlversion: "3.1" services:jenkins:image: jenkins/jenkinscontainer_name: jenkinsports:- 8080:8080- 50000:50000volumes:- ./data/:/var/jenkins_home/首次启动会因为数据…...
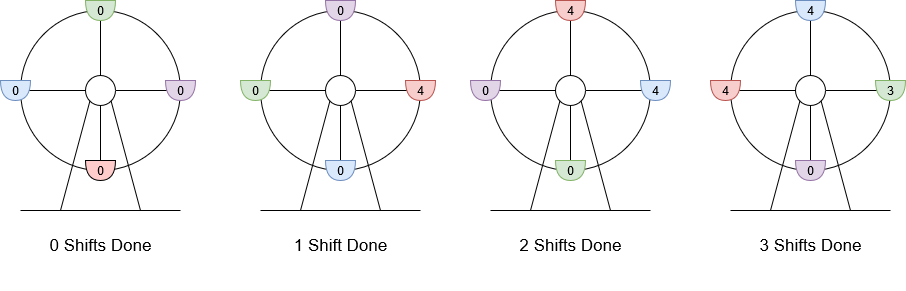
LC-1599. 经营摩天轮的最大利润(贪心)
1599. 经营摩天轮的最大利润 难度中等39 你正在经营一座摩天轮,该摩天轮共有 4 个座舱 ,每个座舱 最多可以容纳 4 位游客 。你可以 逆时针 轮转座舱,但每次轮转都需要支付一定的运行成本 runningCost 。摩天轮每次轮转都恰好转动 1 / 4 周。…...
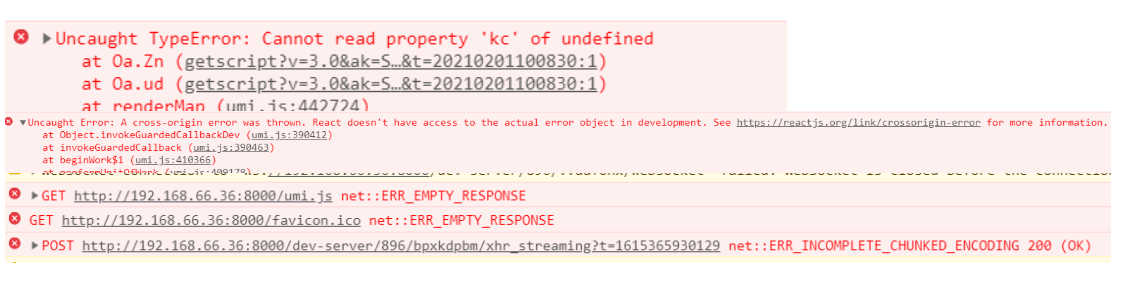
Umi使用百度地图服务
需求描述 需要在前端页面中使用地图定位功能,所以在前端umi项目中使用百度地图服务,由于umi项目默认没有入口的html文件,所以无法通过常规的在head中加入外链js的方式使用 百度ak zyqeLCzvQPCCNImRu9yRGOqWlEUicxxGreact使用百度api 链接:…...

js中getBoundingClientRect()方法
getBoundingClientRect()返回值是一个 DOMRect 对象,是包含整个元素的最小矩形(包括 padding 和 border-width)。该对象使用 left、top、right、bottom、x、y、width 和 height 这几个以像素为单位的只读属性描述整个矩形的位置和大小。除了 …...

Unity记录2.2-动作-动画、相机、Debug与总结
文章首发及后续更新:https://mwhls.top/4453.html,无图/无目录/格式错误/更多相关请至首发页查看。 新的更新内容请到mwhls.top查看。 欢迎提出任何疑问及批评,非常感谢! 汇总:Unity 记录 摘要:重写了动画触…...

分享十个前端Web3D可视化框架附地址
Three.js:Three.js是一个流行的3D库,提供了大量的3D功能,包括基本几何形状、材质、灯光、动画、特效等。它是一个功能强大、易于使用的框架,广泛用于Web3D可视化应用程序的开发。Three.js:https://threejs.org/Babylon…...

突破网页媒体限制:3分钟掌握资源嗅探技术,轻松下载在线音视频
突破网页媒体限制:3分钟掌握资源嗅探技术,轻松下载在线音视频 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字内容爆…...

基于Vue3的前端界面开发:FLUX.1-dev图像生成平台搭建
基于Vue3的前端界面开发:FLUX.1-dev图像生成平台搭建 1. 引言 想象一下,你刚拿到一个强大的AI图像生成模型FLUX.1-dev,它能根据文字描述生成高质量图片,还能进行智能编辑。但如何让这个"大脑"拥有一个友好的"面孔…...

通义千问1.5-1.8B-Chat-GPTQ-Int4数据库课程设计助手:ER图生成与SQL优化
通义千问1.5-1.8B-Chat-GPTQ-Int4数据库课程设计助手:ER图生成与SQL优化 对于计算机相关专业的学生来说,数据库课程设计是个绕不过去的坎。从需求分析到ER图绘制,再到建表写SQL,最后还要面对性能优化,每一步都让不少同…...

vLLM-v0.17.1开源贡献指南:从代码阅读到提交PR
vLLM-v0.17.1开源贡献指南:从代码阅读到提交PR 1. 为什么你应该参与vLLM开源项目 vLLM作为当前最热门的大模型推理框架之一,正在重塑AI服务的性能标准。参与这个项目的开发不仅能让你深入理解大模型服务的技术细节,还能直接与全球顶尖开发者…...

RTX 4090D镜像免配置优势:PyTorch 2.8环境无需conda/pip手动安装依赖
RTX 4090D镜像免配置优势:PyTorch 2.8环境无需conda/pip手动安装依赖 1. 为什么选择预装环境镜像 深度学习项目从零搭建环境往往是最耗时的环节之一。传统方式需要手动安装CUDA、PyTorch和各种依赖库,不仅步骤繁琐,还经常遇到版本冲突问题。…...

FFmpeg 新手必学:5个实用命令搞定视频转码、剪辑与音频提取
FFmpeg 新手必学:5个实用命令搞定视频转码、剪辑与音频提取 第一次接触FFmpeg时,我被这个开源工具的强大功能震撼到了——它几乎能处理所有常见的多媒体格式转换和编辑需求,而且完全免费。作为一款跨平台的命令行工具,FFmpeg在专业…...
开发环境搭建避坑指南(2024版))
ESP32(VSCode+PlatformIO)开发环境搭建避坑指南(2024版)
1. 环境准备:避开Python安装的那些坑 第一次用ESP32开发板时,我兴冲冲地按照教程安装Python,结果在验证环节直接翻车。命令行输入python后居然提示"不是内部命令",这种基础问题浪费了我两小时。后来才发现是系统环境变量…...
完整复刻了一个古建筑)
从无人机照片到3D模型:我用Metashape(原PhotoScan)完整复刻了一个古建筑
从无人机照片到3D模型:我用Metashape完整复刻古建筑的实战记录 去年春天,我在山西考察一座明代戏台时,被其精巧的斗拱结构深深吸引。这座木构建筑历经六百年风雨,细节之复杂让传统测绘束手无策。当时我随身带着大疆Mavic 3无人机&…...

OpenClaw成本优化:Qwen3.5-9B-AWQ-4bit量化模型长期运行实测
OpenClaw成本优化:Qwen3.5-9B-AWQ-4bit量化模型长期运行实测 1. 为什么关注量化模型与OpenClaw的适配性 第一次用OpenClaw执行图片处理任务时,我的MacBook Pro风扇狂转的噪音让我意识到问题的严重性——原版Qwen3.5-9B模型在连续处理20张产品截图后&am…...
的通用连接池)
Go项目实战:手把手教你用GORM封装一个支持6种数据库(含4种国产库)的通用连接池
Go项目实战:构建支持6种数据库的GORM通用连接池 当企业级应用需要同时对接多种数据库时,开发团队往往面临巨大挑战。特别是当项目涉及国产数据库时,官方驱动支持不足、文档匮乏等问题会让开发周期大幅延长。本文将分享如何基于GORM构建一个支…...