【Langchain多Agent实践】一个有推销功能的旅游聊天机器人
【Langchain+Streamlit】旅游聊天机器人_langchain streamlit-CSDN博客
视频讲解地址:【Langchain Agent】带推销功能的旅游聊天机器人_哔哩哔哩_bilibili
体验地址: http://101.33.225.241:8503/
github地址:GitHub - jerry1900/langchain_chatbot: langchain+streamlit打造的一个有memory的旅游聊天机器人,可以和你聊旅游相关的事儿
之前,我们介绍如何打算一款简单的旅游聊天机器人,而且之前我们介绍了SalesGPT,我们看能不能把这两个东西结合起来,让我们的旅游聊天机器人具有推销产品的功能。我们先来看看效果:
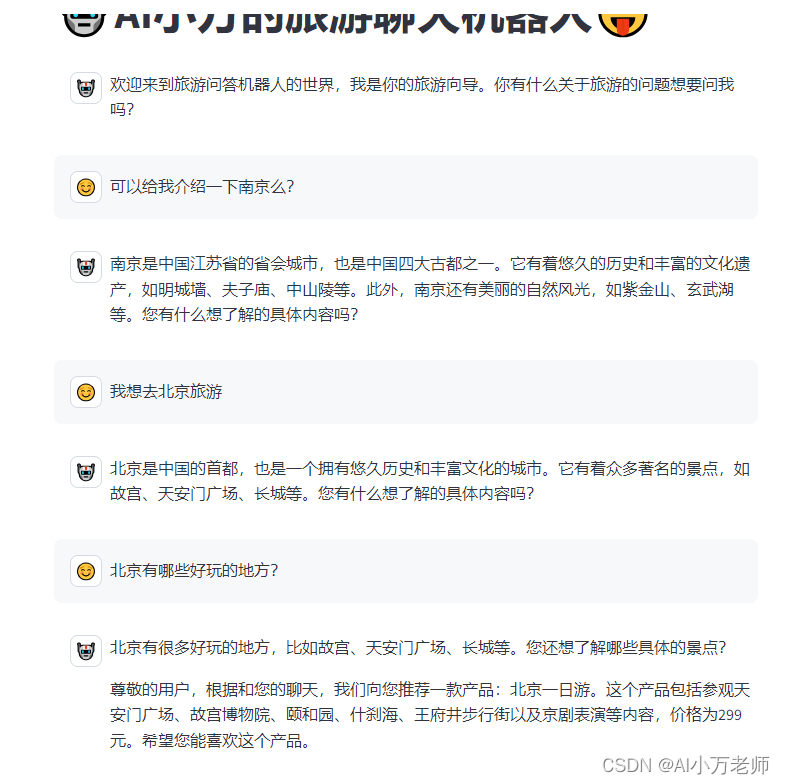
首先,你可以和机器人闲聊关于旅游的事儿(如果你问的问题和旅游无关的话,会提示你只回答旅游问题) ;其次,当你连续询问有关同一个地点时(比如北京),机器人会检查自己的本地知识库,看看产品库里有没有相关的旅游产品,如果有的话就推荐给客户,如果没有就输出一个空的字符串,用户是没有感知的,我们来看一下是如何实现的。
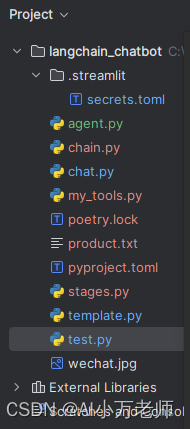
1. 项目结构
我们是在原来项目基础上逐步叠加的,主要增加了一个agent.py、my_tools.py、stages.py等文件。我们这次的项目是使用poetry来管理和运行的:
项目结构如图:
我们新加了一个产品文件用于存储旅游产品,下面是三个产品中的一个:
产品名称:北京一日游
产品价格:299元
产品内容:{
北京作为中国的首都和历史文化名城,有许多令人着迷的景点和活动。以下是一个充满活力和文化的北京一日游的建议:
早上:天安门广场: 开始您的一日游,您可以前往天安门广场,这是世界上最大的城市广场之一,也是中国的政治中心。您可以欣赏到天安门城楼,参观升国旗仪式(早上升旗时间)。
故宫博物院: 天安门广场北侧就是故宫,这是中国最大、最完整的古代皇家宫殿建筑群。在这里,您可以领略中国古代皇家建筑的壮丽和深厚的历史文化。
中午:午餐: 您可以选择在附近的餐馆品尝地道的北京菜,比如炸酱面、北京烤鸭等。
下午:颐和园: 中午过后,您可以前往颐和园,这是中国最大的皇家园林之一,也是清代的皇家园林。园内有美丽的湖泊、精致的建筑和独特的风景。
什刹海: 在下午的最后时段,您可以前往什刹海地区,这里是一个古老而又时尚的区域,有着许多酒吧、咖啡馆和特色小店。您可以漫步在湖边,欣赏夕阳下的美景,体验北京的悠闲氛围。
晚上:王府井步行街: 晚上,您可以前往王府井步行街,这是北京最繁华的购物街之一,有着各种商店、餐馆和娱乐场所。您可以尝试美食、购物或者观赏街头表演。
京剧表演: 如果时间允许,您还可以观看一场京剧表演,京剧是中国传统戏曲的代表之一,有着悠久的历史和独特的艺术魅力。
}
2. chat.py的改动,新增了欢迎词,添加了Agent构造的方法
这里构造一个专门负责提示词的Agent(其实就是一个LLMChain),并构造一个负责会话和判断功能的ConversationAgent,让这个agent初始化并构造一个负责判断阶段的内部agent,我们把他们都要放到session里:
#需要国内openai开发账号的请联系微信 15652965525if "welcome_word" not in st.session_state:st.session_state.welcome_word = welcome_agent()st.session_state.messages.append({'role': 'assistant', 'content': st.session_state.welcome_word['text']})st.session_state.agent = ConversationAgent()st.session_state.agent.seed_agent()st.session_state.agent.generate_stage_analyzer(verbose=True)在用户输入后的每一步,先进行一下阶段判断,然后调用agent的human_step方法,再调用agent的step()方法,完成一轮对话:
st.session_state.agent.determine_conversation_stage(prompt)st.session_state.agent.human_step(prompt)response = st.session_state.agent.step()
3. welcome_agent
这个比较简单,就是一个咱们学习过无数遍的一个简单的chain:
def welcome_agent():llm = OpenAI(temperature=0.6,# openai_api_key=os.getenv("OPENAI_API_KEY"),openai_api_key=st.secrets['api']['key'],# base_url=os.getenv("OPENAI_BASE_URL")base_url=st.secrets['api']['base_url'])prompt = PromptTemplate.from_template(WELCOME_TEMPLATE)chain = LLMChain(llm=llm,prompt=prompt,verbose=True,)response = chain.invoke("简短的欢迎词")return response这里我们希望每次调用它的时候,可以得到一些不一样的、有创意的欢迎词,所以我们的temperature调的比较高,这样它可能生成一些有创意的欢迎词。
4. ConversationAgent类
这个类是我们的核心类,里面有很多属性和方法,我们用python的dir()方法来看一下它里面的结构:
from agent import ConversationAgentagent = ConversationAgent()
print(dir(ConversationAgent))里面以_开头的是Object基本类自带的属性和方法,其他的是我们构造的属性和方法:
['__annotations__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_respond_without_tools', 'conversation_agent_with_tool', 'conversation_agent_without_tool', 'conversation_history', 'conversation_stage_id', 'current_conversation_stage', 'determine_conversation_stage', 'fake_step', 'generate_stage_analyzer', 'get_tools', 'human_step', 'llm', 'recommend_product', 'retrieve_conversation_stage', 'seed_agent', 'show_chat_history', 'stage_analyzer_chain', 'step']
我们先来看类的属性和一些简单的方法,注意我们这里构造了一个llm,之后下面有很多方法会用到这个llm:
class ConversationAgent():stage_analyzer_chain: StageAnalyzerChain = Field(...)conversation_agent_without_tool = Field()conversation_agent_with_tool = Field()conversation_history = []conversation_stage_id: str = "1"current_conversation_stage: str = CONVERSATION_STAGES.get("1")llm = OpenAI(temperature=0,openai_api_key=st.secrets['api']['key'],base_url=st.secrets['api']['base_url'])def seed_agent(self):self.conversation_history.clear()print("——Seed Successful——")def show_chat_history(self):return self.conversation_historydef retrieve_conversation_stage(self, key):return CONVERSATION_STAGES.get(key)我们继续来看:
def fake_step(self):input_text = self.conversation_history[-1]ai_message = self._respond_with_tools(str(input_text), verbose=True)print(ai_message,type(ai_message['output']))def step(self):input_text = self.conversation_history[-1]print(str(input_text)+'input_text****')if int(self.conversation_stage_id) == 1:ai_message = self._respond_without_tools(str(input_text),verbose=True)else:chat_message = self._respond_without_tools(str(input_text), verbose=True)recommend_message = self.recommend_product()print(recommend_message,len(recommend_message))if len(recommend_message)<=5:ai_message = chat_messageelse:ai_message = chat_message + '\n\n' + recommend_message# output_dic = self._respond_with_tools(str(input_text),verbose=True)# ai_message = str(output_dic['output'])print(ai_message,type(ai_message))ai_message = "AI:"+str(ai_message)self.conversation_history.append(ai_message)# print(f"——系统返回消息'{ai_message}',并添加到history里——")return ai_message.lstrip('AI:')
fake_step是一个模拟输出的方法,不用管,测试的时候用;step方法是接收用户的输入,从聊天记录里取出来(input_text = self.conversation_history[-1]) ,然后再根据不同的对话阶段进行不同的逻辑,如果是第二个阶段推销阶段,那么就调用recommend_product方法去生成一个推销产品的信息,并把两条信息拼接起来。
def human_step(self,input_text):human_message = input_texthuman_message = "用户: " + human_messageself.conversation_history.append(human_message)# print(f"——用户输入消息'{human_message}',并添加到history里——")return human_message
human_step方法比较简单,就是把用户的输入挂到conversation_history聊天记录里。然后是构造阶段判断的agent和阶段判断的方法,这些都是模仿SalesGPT里的,做了一些调整:
def generate_stage_analyzer(self,verbose: bool = False):self.stage_analyzer_chain = StageAnalyzerChain.from_llm(llm=self.llm,verbose=verbose)print("成功构造一个StageAnalyzerChain")def determine_conversation_stage(self,question):self.question = questionprint('-----进入阶段判断方法-----')self.conversation_stage_id = self.stage_analyzer_chain.run(conversation_history=self.conversation_history,question=self.question)print(f"Conversation Stage ID: {self.conversation_stage_id}")print(type(self.conversation_stage_id))self.current_conversation_stage = self.retrieve_conversation_stage(self.conversation_stage_id)print(f"Conversation Stage: {self.current_conversation_stage}")
然后是_respond_without_tools这么一个内部的方法,它在step里被调用:
def _respond_without_tools(self,input_text,verbose: bool = False):self.conversation_agent_without_tool = ConversationChain_Without_Tool.from_llm(llm=self.llm,verbose=verbose)response = self.conversation_agent_without_tool.run(question = input_text,conversation_history=self.conversation_history,)return response最后是get_tools方法和recommend_product方法,这里也都是模仿了SalesGPT里的写法:
def get_tools(self):file_path = r'C:\Users\Administrator\langchain_chatbot\product.txt'knowledge_base = build_knowledge_base(file_path)tools = get_tools(knowledge_base)return toolsdef recommend_product(self,verbose =True):tools = self.get_tools()prompt = CustomPromptTemplateForTools(template=RECOMMEND_TEMPLATE,tools_getter=lambda x: tools,# This omits the `agent_scratchpad`, `tools`, and `tool_names` variables because those are generated dynamically# This includes the `intermediate_steps` variable because that is neededinput_variables=["intermediate_steps", # 这是在调用tools时,会产生的中间变量,是一个list里面的一个tuple,一个是action,一个是observation"conversation_history",],)llm_chain = LLMChain(llm=self.llm, prompt=prompt, verbose=verbose)tool_names = [tool.name for tool in tools]# WARNING: this output parser is NOT reliable yet## It makes assumptions about output from LLM which can break and throw an erroroutput_parser = SalesConvoOutputParser()recommend_agent = LLMSingleActionAgent(llm_chain=llm_chain,output_parser=output_parser,stop=["\nObservation:"],allowed_tools=tool_names,)sales_agent_executor = AgentExecutor.from_agent_and_tools(agent=recommend_agent, tools=tools, verbose=verbose, max_iterations=5)inputs = {"conversation_history": "\n".join(self.conversation_history),}response = sales_agent_executor.invoke(inputs)return str(response['output'])
5. chain.py
chain这里有三个类,差异在于使用模板的不同还有部分传参的不同,这里写的有点冗余了,大家可以自己优化一下:
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from template import STAGE_ANALYZER_INCEPTION_PROMPT,BASIC_TEMPLATE,RECOMMEND_TEMPLATEclass StageAnalyzerChain(LLMChain):"""通过查看聊天记录判断是否要转向推荐和销售阶段."""@classmethoddef from_llm(cls, llm, verbose: bool = True) -> LLMChain:"""Get the response parser."""stage_analyzer_inception_prompt_template = STAGE_ANALYZER_INCEPTION_PROMPTprompt = PromptTemplate(template=stage_analyzer_inception_prompt_template,input_variables=["conversation_history","question"],)return cls(prompt=prompt, llm=llm, verbose=verbose)class ConversationChain_Without_Tool(LLMChain):#当用户没有明确的感兴趣话题时,用这个chain和用户闲聊@classmethoddef from_llm(cls, llm, verbose: bool = True) -> LLMChain:"""Get the response parser."""conversation_without_tools_template = BASIC_TEMPLATEprompt = PromptTemplate(template=conversation_without_tools_template,input_variables=["conversation_history",],)return cls(prompt=prompt, llm=llm, verbose=verbose)class Recommend_Product(LLMChain):#当用户有明确的感兴趣话题时,用这个chain查询产品库,看是否命中,如果命中则生成一个产品推荐信息@classmethoddef from_llm(cls, llm, verbose: bool = True) -> LLMChain:"""Get the response parser."""conversation_without_tools_template = RECOMMEND_TEMPLATEprompt = PromptTemplate(template=conversation_without_tools_template,input_variables=["conversation_history",],)return cls(prompt=prompt, llm=llm, verbose=verbose)6. my_tools.py
这个文件里有有很多,是我把SalesGPT里的一些文件改写拿过来用的,有一些根据实际项目需要进行的微调:
import re
from typing import Unionfrom langchain.agents import Tool
from langchain.chains import RetrievalQA
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from typing import Callable
from langchain.prompts.base import StringPromptTemplate
from langchain.agents.agent import AgentOutputParser
from langchain.agents.conversational.prompt import FORMAT_INSTRUCTIONS
from langchain.schema import AgentAction, AgentFinish # OutputParserExceptiondef build_knowledge_base(filepath):with open(filepath, "r", encoding='utf-8') as f:product_catalog = f.read()text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=10)texts = text_splitter.split_text(product_catalog)llm = ChatOpenAI(temperature=0)embeddings = OpenAIEmbeddings()docsearch = Chroma.from_texts(texts, embeddings, collection_name="product-knowledge-base")knowledge_base = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever())return knowledge_basedef get_tools(knowledge_base):# we only use one tool for now, but this is highly extensible!tools = [Tool(name="ProductSearch",func=knowledge_base.invoke,description="查询产品库,输入应该是'请介绍一下**的旅游产品'",)]print('tools构造正常')return toolsclass CustomPromptTemplateForTools(StringPromptTemplate):# The template to usetemplate: strtools_getter: Callabledef format(self, **kwargs) -> str:# Get the intermediate steps (AgentAction, Observation tuples)# Format them in a particular wayintermediate_steps = kwargs.pop("intermediate_steps")thoughts = ""for action, observation in intermediate_steps:thoughts += action.logthoughts += f"\nObservation: {observation}\nThought: "# Set the agent_scratchpad variable to that valueprint('——thoughts——:'+thoughts+'\n End of ——thoughts——')kwargs["agent_scratchpad"] = thoughtstools = self.tools_getter([])# Create a tools variable from the list of tools providedkwargs["tools"] = "\n".join([f"{tool.name}: {tool.description}" for tool in tools])# Create a list of tool names for the tools providedkwargs["tool_names"] = ", ".join([tool.name for tool in tools])print('prompt构造正常')return self.template.format(**kwargs)class SalesConvoOutputParser(AgentOutputParser):ai_prefix: str = "AI" # change for salesperson_nameverbose: bool = Truedef get_format_instructions(self) -> str:return FORMAT_INSTRUCTIONSdef parse(self, text: str) -> Union[AgentAction, AgentFinish]:if self.verbose:print("TEXT")print(text)print("-------")if f"{self.ai_prefix}:" in text:if "Do I get the answer?YES." in text:print('判断Agent是否查到结果,yes')return AgentFinish({"output": text.split(f"{self.ai_prefix}:")[-1].strip()}, text)else:print('判断Agent是否查到结果,no')return AgentFinish({"output": {}}, text)regex = r"Action: (.*?)[\n]*Action Input: (.*)"match = re.search(regex, text)if not match:## TODO - this is not entirely reliable, sometimes results in an error.return AgentFinish({"output": "I apologize, I was unable to find the answer to your question. Is there anything else I can help with?"},text,)# raise OutputParserException(f"Could not parse LLM output: `{text}`")action = match.group(1)action_input = match.group(2)print('output_paserser构造正常')return AgentAction(action.strip(), action_input.strip(" ").strip('"'), text)@propertydef _type(self) -> str:return "sales-agent"7. 结束语
整个项目就是把之前的两个项目进行了一个组合拼装,在这个过程中可以更好地理解Sales
GPT这个项目,以及多Agent是怎么运行的。
相关文章:
【Langchain多Agent实践】一个有推销功能的旅游聊天机器人
【LangchainStreamlit】旅游聊天机器人_langchain streamlit-CSDN博客 视频讲解地址:【Langchain Agent】带推销功能的旅游聊天机器人_哔哩哔哩_bilibili 体验地址: http://101.33.225.241:8503/ github地址:GitHub - jerry1900/langcha…...
算法学习(十二)并查集
并查集 1. 概念 并查集主要用于解决一些 元素分组 问题,通过以下操作管理一系列不相交的集合: 合并(Union):把两个不相交的集合合并成一个集合 查询(Find):查询两个元素是否在同一…...
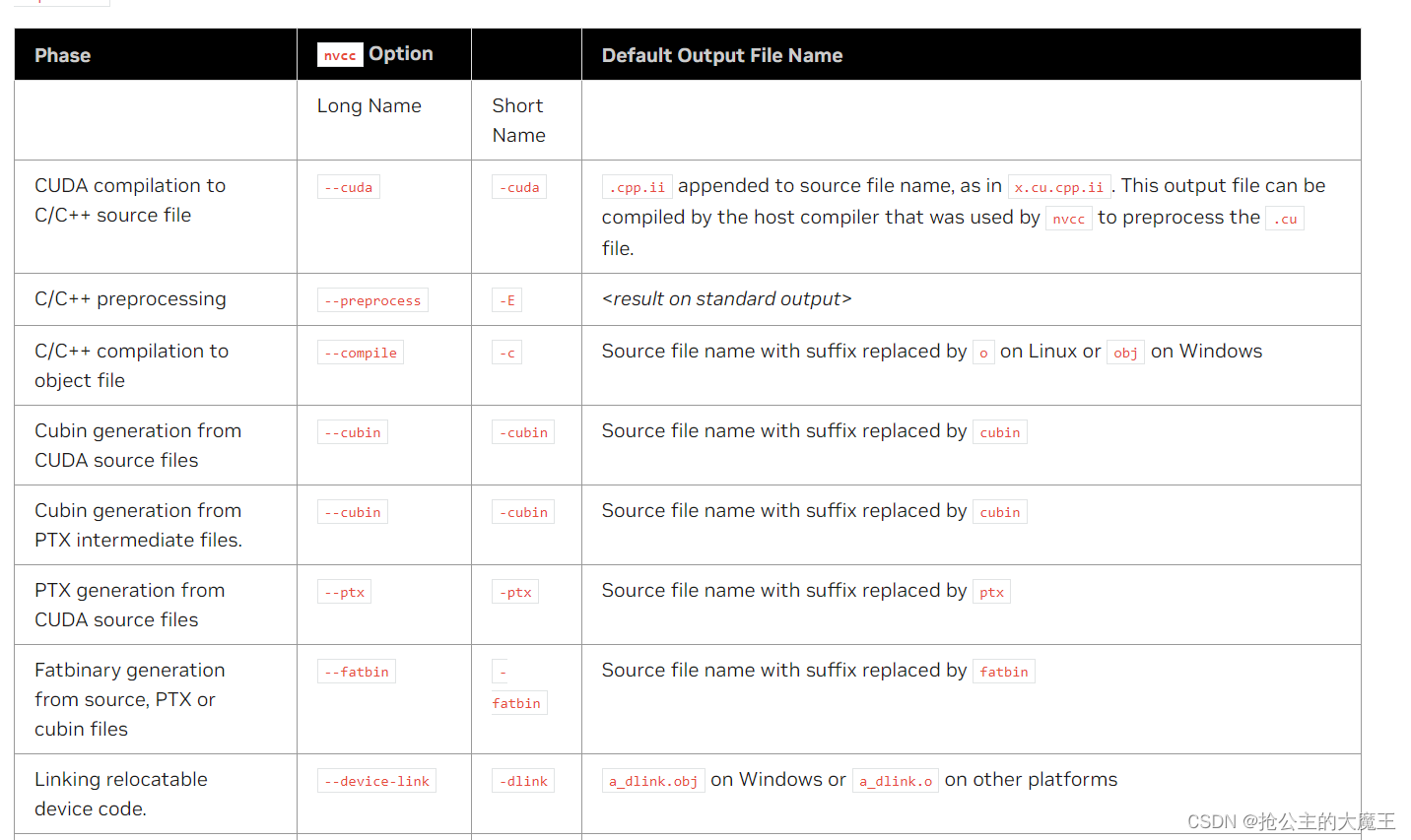
TensorRT及CUDA自学笔记003 NVCC及其命令行参数
TensorRT及CUDA自学笔记003 NVCC及其命令行参数 各位大佬,这是我的自学笔记,如有错误请指正,也欢迎在评论区学习交流,谢谢! NVCC是一种编译器,基于一些命令行参数可以将使用PTX或C语言编写的代码编译成可…...

数据库管理-第154期 Oracle Vector DB AI-06(20240223)
数据库管理154期 2024-02-23 数据库管理-第154期 Oracle Vector DB & AI-06(20240223)1 环境准备创建表空间及用户TNSNAME配置 2 Oracle Vector的DML操作创建示例表插入基础数据DML操作UPDATE操作DELETE操作 3 多Vector列表4 固定维度的向量操作5 不…...

解决uni-app vue3 nvue中使用pinia页面空白问题
main.js中,最关键的就是Pinia要return出去的问题,至于原因嘛! 很忙啊,先用着吧 import App from ./App import * as Pinia from pinia import { createSSRApp } from vue export function createApp() {const app createSSRApp(App);app.us…...

不用加减乘除做加法
1.题目: 写一个函数,求两个整数之和,要求在函数体内不得使用、-、*、/四则运算符号。 数据范围:两个数都满足 −10≤�≤1000−10≤n≤1000 进阶:空间复杂度 �(1)O(1),时间复杂度 &am…...

旅游组团自驾游拼团系统 微信小程序python+java+node.js+php
随着社会的发展,旅游业已成为全球经济中发展势头最强劲和规模最大的产业之一。为方便驴友出行,寻找旅游伙伴,更好的规划旅游计划,开发一款自驾游拼团小程序,通过微信小程序发起自驾游拼团,吸收有车或无车驴…...

LeetCode 第41天 | 背包问题 二维数组 一维数组 416.分割等和子集 动态规划
46. 携带研究材料(第六期模拟笔试) 题目描述 小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。他需要带一些研究材料,但是他的行李箱空间有限。这些研究材料包括实验设备、文献资料和实…...
Ubuntu20.04和Windows11下配置StarCraft II环境
1.Ubuntu20.04 根据下面这篇博客就可以顺利安装: 强化学习实战(九) Linux下配置星际争霸Ⅱ环境https://blog.csdn.net/weixin_39059031/article/details/117247635?spm1001.2014.3001.5506 Ubuntu下显示游戏界面目前还没有解决掉。 大家可以根据以下链接看看能…...
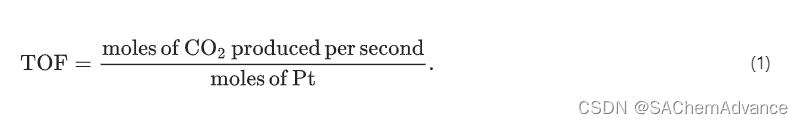
【NCom】:通过高温气相合成调节Pt-CeO2相互作用以提高晶格氧的还原性
摘要:在这项工作中,我们比较了通过两种方法制备的 Pt 单原子催化剂(SAC)的 CO 氧化性能:(1)传统的湿化学合成(强静电吸附strong electrostatic adsorption–SEA)…...

git 将一个分支的提交移动到另一个分支
假设想把分支A上的最后一部分commit移动到分支B之上: 首先切到分支B git checkout B然后执行如下指令,commit id 为A分支上,需要移动的那些提交 git cherry-pick <commit id> ( <commit id> 可多个)中途可能遇到一些…...

vue3 实现 el-pagination页面分页组件的封装以及调用
示例图 一、组件代码 <template><el-config-provider :locale"zhCn"><el-pagination background class"lj-paging" layout"prev, pager, next, jumper" :pager-count"5" :total"total":current-page"p…...
#FPGA(IRDA)
1.IDE:Quartus II 2.设备:Cyclone II EP2C8Q208C8N 3.实验:IRDA(仿真接收一个来自0x57地址的数据0x22 (十进制34)) 4.时序图: 5.步骤 6.代码: irda_receive.v module irda_receive ( input wire…...

Sora—openai最新大模型文字生成视频
这里没办法发视频,发几个图片感受感受吧 OpenAI发布了Sora,一种文字生成视频的技术,从演示看,效果还是相当不错的。 Sora的强大之处在于其能够根据文本描述,生成长达 60秒的视频,其中包含精细复杂的场景…...
介绍(网络电话、ip电话))
VoIP(Voice over Internet Protocol 基于IP的语音传输)介绍(网络电话、ip电话)
文章目录 VoIP(基于IP的语音传输)1. 引言2. VoIP基础2.1 VoIP工作原理2.2 VoIP协议 3. VoIP的优势和挑战3.1 优势3.2 挑战 4. VoIP的应用5. 总结 VoIP(基于IP的语音传输) 1. 引言 VoIP,全称Voice over Internet Prot…...

编程笔记 Golang基础 027 结构体
编程笔记 Golang基础 027 结构体 一、结构体的定义二、结构体的实例化1. 直接初始化2. 使用键值对初始化(即使字段顺序不一致也能正确赋值)3. 部分初始化(未指定的字段会得到它们类型的零值)4. 使用var声明和初始化5. 结构体字面量…...

opencascade15解析导出为step格式
#include "DisplayScene.h" // 包含显示场景的头文件 #include "Viewer.h" // 包含查看器的头文件// OpenCascade 包含 #include <BRepPrimAPI_MakeCylinder.hxx> // 创建圆柱体 #include <BinXCAFDrivers.hxx> // 二进制XCAF驱动程序 #includ…...

【软件设计模式之模板方法模式】
文章目录 前言一、什么是模板方法模式?二、模板方法模式的结构1. 抽象类定义2. 具体实现 三、模板方法模式的应用场景1. 算法重用2. 操作中的固定步骤3. 扩展框架的功能4. 提供回调方法5. 遵循开闭原则 四、模板方法模式的优缺点1. 优点代码复用扩展性好符合开闭原则…...
Spring Boot项目怎么对System.setProperty(key, value)设置的属性进行读取加解密
一、前言 之前我写过一篇文章使用SM4国密加密算法对Spring Boot项目数据库连接信息以及yaml文件配置属性进行加密配置(读取时自动解密),对Spring Boot项目的属性读取时进行加解密,但是没有说明对System.setProperty(key, value)设…...
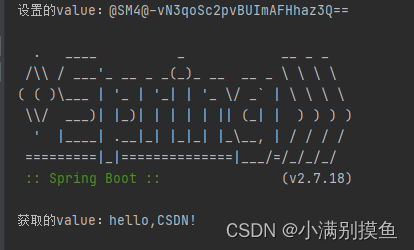
Linux理解
VMware安装Linux安装 目录 VMware安装Linux安装 1.1 什么是Linux 1.2 为什么要学Linux 1.3 学完Linux能干什么 2.1 主流操作系统 2.2 Linux系统版本 VMware安装Linux安装 1.1 什么是Linux Linux是一套免费使用和自由传播的操作系统。 1.2 为什么要学Linux 1). 企业用人…...
)
PyTorch实战:手把手教你实现DCNv2可变形卷积(附完整代码与避坑指南)
PyTorch实战:手把手教你实现DCNv2可变形卷积(附完整代码与避坑指南) 当你在处理计算机视觉任务时,是否遇到过这样的困扰:传统卷积神经网络对物体几何变换的适应性有限,导致模型在复杂场景下的表现不尽如人意…...

大疆M4系列+YOLOV8识别算法 如何训练无人机罂粟识别检测数据集 让非法种植无处可藏:无人机+AI罂粟识别数据集发布,覆盖花期_果期多阶段检测 无人机俯拍+AI识别罂粟
无人机俯拍AI识别罂粟,准确率超95%!,助力禁毒攻坚》 《科技禁毒再升级!YOLO实测mAP 83.9%》 《让非法种植无处可藏:无人机AI罂粟识别数据集发布,覆盖花期/果期多阶段检测 智慧巡检 {专业级AI巡查无人机…...

PoE Overlay终极指南:3个核心技巧解决流放之路玩家最头疼的问题
PoE Overlay终极指南:3个核心技巧解决流放之路玩家最头疼的问题 【免费下载链接】PoE-Overlay An Overlay for Path of Exile. Built with Overwolf and Angular. 项目地址: https://gitcode.com/gh_mirrors/po/PoE-Overlay 你是否曾经在《流放之路》中面对满…...

2025最权威的五大降重复率方案推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 处于学术探索的终点之处,一篇出色的毕业论文乃是知识跟汗水所凝结而成的&#x…...
)
别再只会`cmatrix`了!解锁Linux终端屏保的10种炫酷玩法(含快捷键大全)
终端美学革命:10种cmatrix高阶玩法与快捷键全解析 当绿色代码雨第一次在终端流淌而下时,那种黑客帝国般的视觉冲击令人难忘。但你是否知道,这个看似简单的cmatrix命令背后隐藏着一个可编程的视觉艺术工具箱?本文将带你突破基础用法…...
)
用1.44寸ST7735 TFT屏DIY一个桌面天气站(附STM32/Arduino完整项目代码)
用1.44寸ST7735 TFT屏打造智能桌面天气站(STM32/Arduino全流程实战) 在创客圈里,能够实时显示天气信息的桌面小设备一直备受青睐。本文将带你从零开始,利用常见的1.44寸ST7735 TFT屏幕,构建一个功能完善的智能天气站。…...

ElevenLabs泰米尔语音部署踩坑实录:DNS解析超时、UTF-8 BOM导致静音、方言ID混淆——97%开发者忽略的3个关键参数
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs泰米尔语音部署踩坑实录:DNS解析超时、UTF-8 BOM导致静音、方言ID混淆——97%开发者忽略的3个关键参数 DNS解析超时:被忽略的区域路由策略 ElevenLabs 的 API 在印度…...
)
Mac小白必看:手把手教你用终端命令重建丢失的Recovery HD分区(附详细路径解释)
Mac用户自救指南:彻底掌握Recovery HD分区修复全流程 当你发现CommandR组合键失效时,那种无助感我深有体会。去年帮朋友修复一台二手MacBook时,我们花了整整一个下午才搞明白为什么恢复模式无法启动——原来前主人为了腾出空间删除了Recovery…...

避开这些坑!ISCE2数据下载实战:Earthdata账号、.netrc配置与DEM自动拼接
ISCE2数据下载实战:Earthdata账号配置与DEM自动拼接避坑指南 当你第一次尝试用ISCE2处理哨兵数据时,可能会被各种数据下载问题搞得焦头烂额。Earthdata认证失败、DEM下载报错、脚本运行异常——这些看似简单的问题往往会让整个项目停滞数天。本文将分享…...

书匠策AI官网www.shujiangce.com|别再熬夜抠格式了!这个AI工具让期刊论文写起来像“开外挂“
各位还在论文苦海里挣扎的宝子们,我是你们的论文老司机。 今天不聊选题,不聊开题,咱们来聊一个被90%的研究生忽略的神器——书匠策AIhttp://ww 官网直达:www.shujiangce.com里的期刊论文功能。 你是不是也经历过这种崩溃时刻&a…...