數據集成平台:datax將hive數據步到mysql(全部列和指定列)
數據集成平台:datax將hive數據步到mysql(全部列和指定列)
1.py腳本
傳入參數:
target_database:數據庫
target_table:表
target_columns:列
target_positions:hive列的下標(從0開始)
# coding=utf-8
import json
import getopt
import os
import sys
import MySQLdb# MySQL相关配置,需根据实际情况作出修改
mysql_host = "hadoop102"
mysql_port = "3306"
mysql_user = "root"
mysql_passwd = "xx"# HDFS NameNode相关配置,需根据实际情况作出修改
hdfs_nn_host = "mycluster"
hdfs_nn_port = "8020"def get_connection():return MySQLdb.connect(host=mysql_host, port=int(mysql_port), user=mysql_user, passwd=mysql_passwd)def get_mysql_meta(database, table, columns):connection = get_connection()cursor = connection.cursor()if columns == 'all':# 如果传入 '*' 表示要所有列sql = "SELECT COLUMN_NAME, DATA_TYPE FROM information_schema.COLUMNS WHERE TABLE_SCHEMA='%s' AND TABLE_NAME='%s' ORDER BY ORDINAL_POSITION" % (database, table)else:# 传入指定列# 将每个列名加上单引号columns = ', '.join("'%s'" % col.strip() for col in columns.split(','))sql = "SELECT COLUMN_NAME, DATA_TYPE FROM information_schema.COLUMNS WHERE TABLE_SCHEMA='%s' AND TABLE_NAME='%s' AND COLUMN_NAME IN (%s) ORDER BY ORDINAL_POSITION" % (database, table, columns)cursor.execute(sql)fetchall = cursor.fetchall()# print(fetchall)cursor.close()connection.close()return fetchalldef get_mysql_columns(database, table, target_columns):return map(lambda x: x[0], get_mysql_meta(database, table, target_columns))def get_hive_columns(database, table, target_columns, target_positions):def type_mapping(mysql_type):mappings = {"bigint": "bigint","int": "bigint","smallint": "bigint","tinyint": "bigint","mediumint": "bigint","decimal": "string","double": "double","float": "float","binary": "string","char": "string","varchar": "string","datetime": "string","time": "string","timestamp": "string","date": "string","text": "string","bit": "string",}return mappings[mysql_type]meta = get_mysql_meta(database, table, target_columns)if target_columns == 'all':return map(lambda x: {"name": x[0], "type": type_mapping(x[1].lower())}, meta)else:positions = list(map(int, target_positions.split(',')))return map(lambda x, i: {"index": positions[i], "type": type_mapping(x[1].lower())}, meta, range(len(meta)))def generate_json(target_database, target_table, target_columns, target_positions):print(get_hive_columns(target_database, target_table, target_columns, target_positions))if target_columns == 'all':target_columns_hive = "[*]"else:target_columns_hive = get_hive_columns(target_database, target_table, target_columns, target_positions)job = {"job": {"setting": {"speed": {"channel": 15},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{"reader": {"name": "hdfsreader","batchSize": "8192","batchByteSize": "33554432","parameter": {"path": "${exportdir}","defaultFS": "hdfs://" + hdfs_nn_host + ":" + hdfs_nn_port,"column": target_columns_hive,"fileType": "orc","encoding": "UTF-8","fieldDelimiter": u"\u0001","nullFormat": "\\N"}},"writer": {"name": "mysqlwriter","batchSize": "8192","batchByteSize": "33554432","parameter": {"writeMode": "replace","username": mysql_user,"password": mysql_passwd,"column": get_mysql_columns(target_database, target_table, target_columns),"connection": [{"jdbcUrl":"jdbc:mysql://" + mysql_host + ":" + mysql_port + "/" + target_database + "?useUnicode=true&characterEncoding=utf-8&useSSL=false","table": [target_table]}]}}}]}
}output_path = "/opt/module/datax/job/export/" + target_databaseif not os.path.exists(output_path):os.makedirs(output_path)with open(os.path.join(output_path, ".".join([target_database, target_table, "json"])), "w") as f:json.dump(job, f)def main(args):target_database = ""target_table = ""target_columns = "" # 默认为 None,表示没有指定列信息target_positions = ""options, arguments = getopt.getopt(args, 'p:d:t:c:', ['positions=', 'targetdb=', 'targettbl=', 'columns='])for opt_name, opt_value in options:if opt_name in ('-d', '--targetdb'):target_database = opt_valueif opt_name in ('-t', '--targettbl'):target_table = opt_valueif opt_name in ('-c', '--columns'):target_columns = opt_valueif opt_name in ('-p', '--positions'):target_positions = opt_valueprint(target_database, target_table, target_columns, target_positions)generate_json(target_database, target_table, target_columns, target_positions)if __name__ == '__main__':main(sys.argv[1:])2.sh腳本
#!/bin/bash
python ~/bin/test.py -d db-t table -c all
#kunnr,name1,sort2,addrnumber,country,state -p 0,1,2,3,4,5
#all相关文章:
)
數據集成平台:datax將hive數據步到mysql(全部列和指定列)
數據集成平台:datax將hive數據步到mysql(全部列和指定列) 1.py腳本 傳入參數: target_database:數據庫 target_table:表 target_columns:列 target_positions:hive列的下標&#x…...
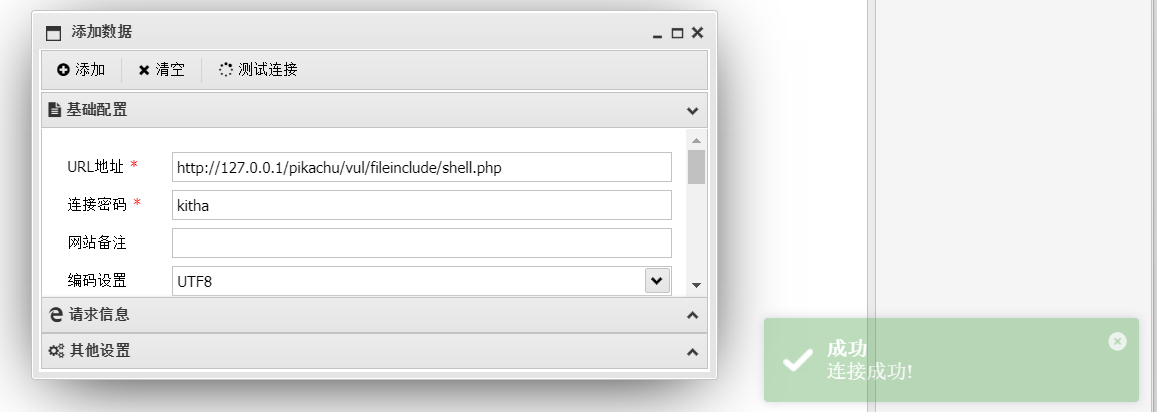
pikachu靶场-File Inclusion
介绍: File Inclusion(文件包含漏洞)概述 文件包含,是一个功能。在各种开发语言中都提供了内置的文件包含函数,其可以使开发人员在一个代码文件中直接包含(引入)另外一个代码文件。 比如 在PHP中,提供了&…...

[今天跟AI聊聊职场] ~你能接受你的直接领导能力不如你,年纪还比你小很多吗?
知乎问题: 弟弟今年35岁,刚换了一份工作,直接领导小A比他小5岁,各方面经验没有他成熟。难的工作都是弟弟在做,功劳都被直接领导小A抢走了,有时候还要被直接领导小A打压。弟弟感觉升职加薪无望。现在找工作不…...
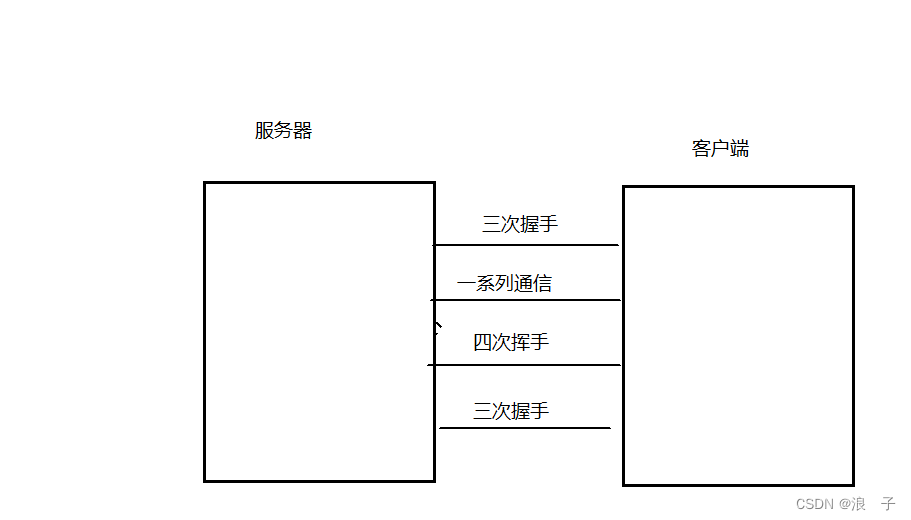
网络原理TCP之“三次握手“
TCP内核中的建立连接 众所周知,TCP是有连接的. 当我们在客户端敲出socket new Socket(serverIp,severPort)时,就在系统内核就在建立连接 真正建立连接是在系统内核中建立的,我们程序员只是调用相关的api. 在此处,我们把TCP的建立连接称为三次握手. 系统在内核建立连接时如上…...

990-03产品经理与程序员:什么是 IT 与业务协调以及为什么它很重要?
What is IT-business alignment and why is it important? 什么是IT-业务一致性?为什么它很重要? It’s more important than ever that IT and the business operate from the same playbook(剧本). So why do so many organizations struggle to ach…...
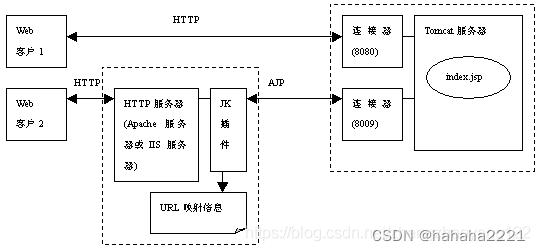
Java Web(七)__Tomcat(二)
Tomcat工作模式 Tomcat作为Servlet容器,有以下三种工作模式。 1)独立的Servlet容器,由Java虚拟机进程来运行 Tomcat作为独立的Web服务器来单独运行,Servlet容器组件作为Web服务器中的一部分而存在。这是Tomcat的默认工作模式。…...

【项目实战】帮美女老师做一个点名小程序(Python tkinter)
前言 博主有一个非常漂亮的老师朋友😍。最近,她急需一个能够实现随机点名的小程序,而博主正好擅长这方面的技术🤏。所以,今天博主决定为她制作一个专门用于点名的小程序💪。 博主在美女老师面前吹完牛皮之…...

Elasticsearch 去重后求和
标题的要求可以用如下 SQL 表示 select sum(column2) from (select distinct(column1),column2 from table)t 要如何用 DSL 实现呢,先准备下索引和数据 PUT test_index {"mappings": {"properties": {"column1": {"type"…...
)
考研数学——高数:函数与极限(3)
函数的连续性与间断点 函数的连续性 左连续 右连续 区间上的连续性 在xo处连续 函数的间断点 第一类间断点(左右极限都存在) 可去间断点: f(xo-0)= f(xo+0) 跳跃间断点: f(xo-0)≠ f(xo+0) 第二类间断点(震荡间断点、无穷间断点)...

LeetCode49 字母异位词分组
LeetCode49 字母异位词分组 在这篇博客中,我们将探讨 LeetCode 上的一道经典算法问题:字母异位词分组。这个问题要求将给定的字符串数组中的字母异位词组合在一起,并以任意顺序返回结果列表。 问题描述 给定一个字符串数组 strs࿰…...
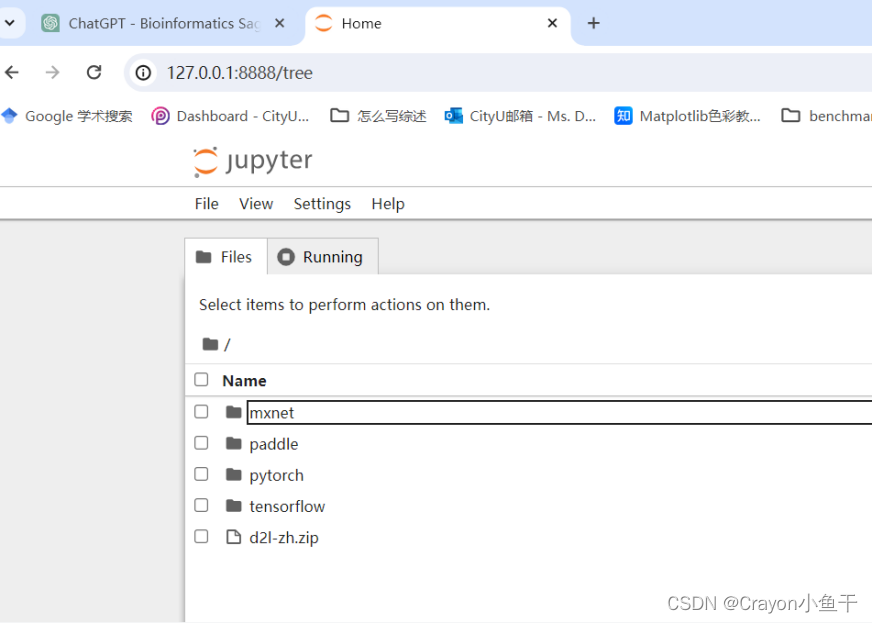
【Python】Windows本地映射远程Linux服务器上的端口(解决jupyter notebook无法启动问题)
创作日志: 学习深度学习不想在本地破电脑上再安装各种软件,我就用实验室的服务器配置环境,启动jupyter notebook时脑子又瓦特了,在自己Windows电脑上打开服务器提供的网址,那肯定打不开啊,以前在其它电脑上…...

C++面试:用户态和内核态的基本概念、区别
目录 一、基本概念 概念: 区别: 二、Windows示例 基础介绍 用户态到内核态的切换过程: 程序实例 三、Linux示例 特权级别: 用户态到内核态的切换过程: 调度和中断处理: 程序实例 总结 在操作系…...
)
Vue计算属性computed()
1. 计算属性定义 获取计算属性值 <div>{{ 计算属性名称}}</div>创建计算属性 let 定义的属性ref/reactive....let 计算属性名称 computed(() > {//这里写函数式,函数式里面包含定义属性//只有这个包含的定义属性被修改时才出发此函数式//通过计算属性名称co…...
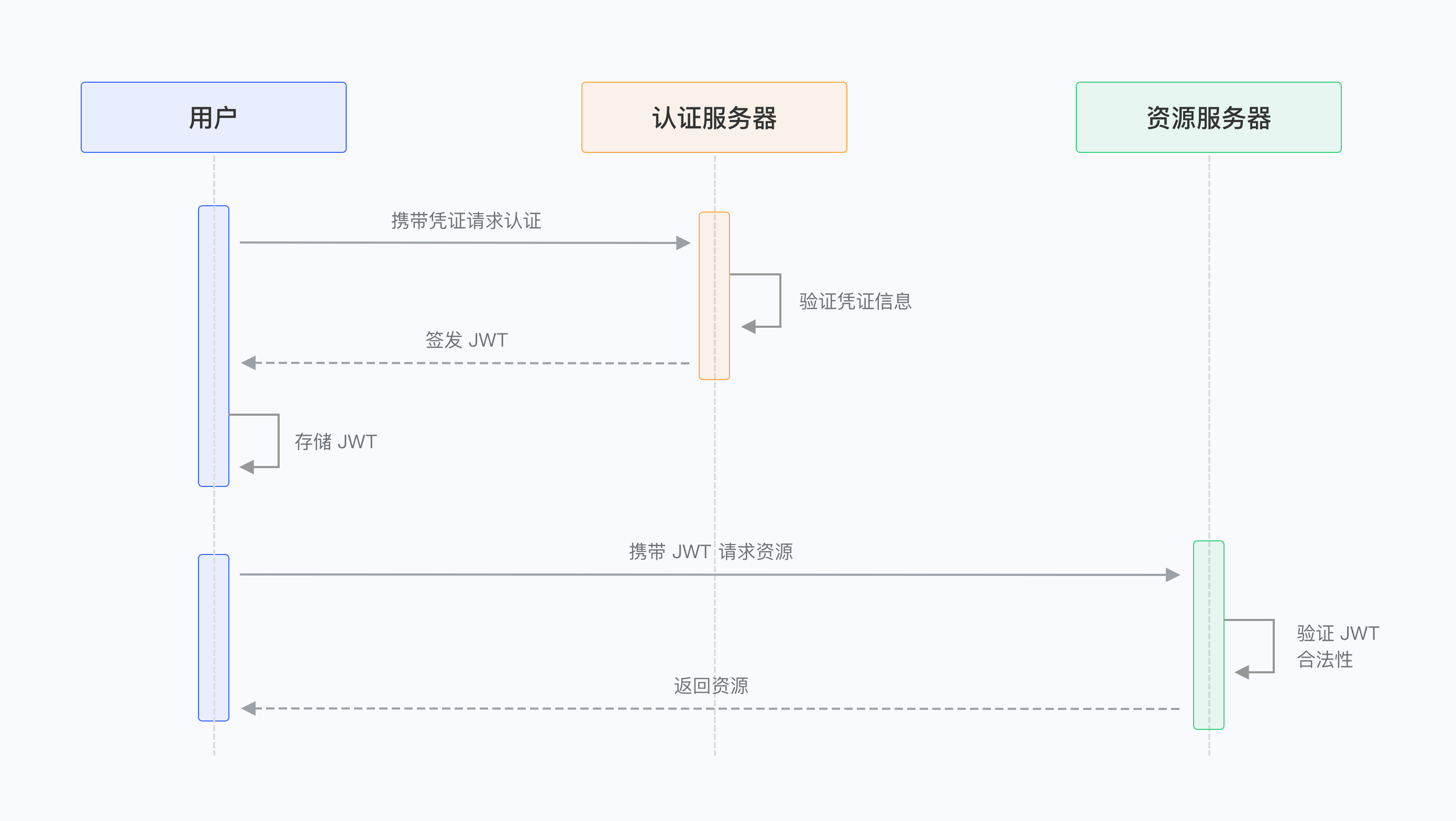
JWT学习笔记
了解 JWT Token 释义及使用 | Authing 文档 JSON Web Token Introduction - jwt.io JSON Web Token (JWT,RFC 7519 (opens new window)),是为了在网络应用环境间传递声明而执行的一种基于 JSON 的开放标准((RFC 7519)。该 token 被设计为紧凑…...
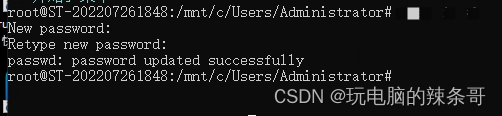
WSL里的Ubuntu 登录密码忘了怎么更改
环境: Win10 专业版 WSL2 如何 Ubuntu22.04 问题描述: WSL里的Ubuntu 登录密码忘了怎么更改 解决方案: 在WSL中的Ubuntu系统中,忘记了密码,可以通过以下步骤重置密码: 1.打开命令提示符或PowerShel…...
【软件测试面试】要你介绍项目-如何说?完美面试攻略...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、测试面试时&am…...

【Crypto | CTF】RSA打法 集合
天命:我发现题题不一样,已知跟求知的需求都不一样 题目一:已知 p q E ,计算T,最后求D 已知两个质数p q 和 公钥E ,通过p和q计算出欧拉函数T,最后求私钥D 【密码学 | CTF】BUUCTF RSA-CSDN…...

在springboot中调用openai Api并实现流式响应
之前在《在springboot项目中调用openai API及我遇到的问题》这篇博客中,我实现了在springboot中调用openai接口,但是在这里的返回的信息是一次性全部返回的,如果返回的文字比较多,我们可能需要等很久。 所以需要考虑将请求接口响应…...

C++构造函数重难点解析
一、C构造函数是什么 C的构造函数是一种特殊的成员函数,用于初始化类的对象。它具有与类相同的名称,并且没有返回类型。构造函数在创建对象时自动调用,并且可以执行必要的初始化操作。 二、C构造函数特点 类的构造函数不能被继承,…...
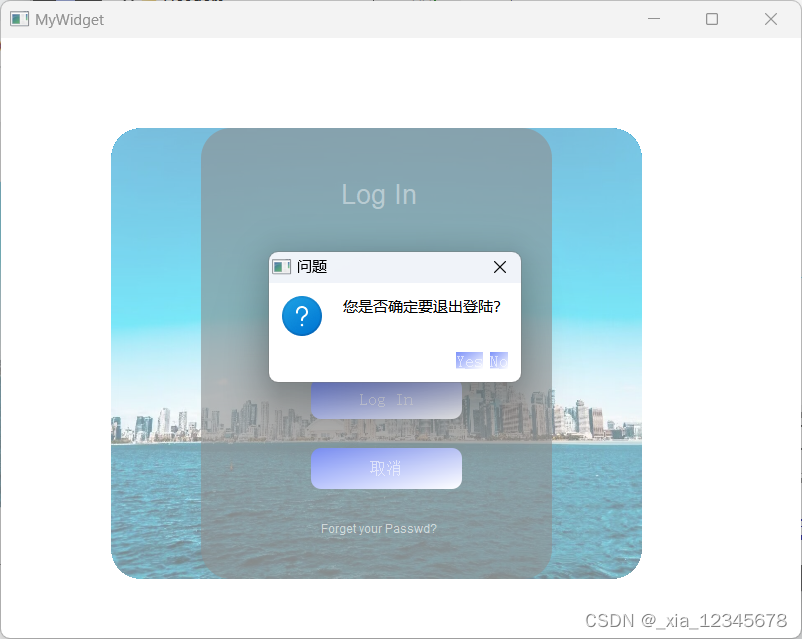
QT day3 作业2.22
思维导图: 作业: 完善对话框,点击登录对话框,如果账号和密码匹配,则弹出信息对话框,给出提示”登录成功“,提供一个Ok按钮,用户点击Ok后,关闭登录界面,跳转到…...

基于RAG与智能分块构建LLM本地知识库:llm-books开源工具实战
1. 项目概述:一个为LLM“喂书”的开源工具最近在折腾大语言模型本地应用的朋友,可能都遇到过同一个头疼的问题:怎么让模型“读懂”我手头那几百页的PDF报告、电子书或者研究论文?直接复制粘贴?上下文长度不够。手动分段…...

FPGA串行FIR滤波器设计:Verilog实现与资源优化实战
1. 项目概述在数字信号处理(DSP)的硬件实现领域,FIR(有限脉冲响应)滤波器因其绝对稳定性和线性相位特性,成为工程师们手中的一把利器。无论是通信系统的信道均衡,还是音频处理中的噪声抑制&…...
)
科研绘图避坑指南:手把手教你用Cytoscape处理String PPI数据(TSV文件导入、节点筛选与双环图制作)
科研绘图避坑指南:Cytoscape实战PPI网络分析与双环图设计 在生物医学研究中,蛋白互作网络(PPI)可视化是揭示分子机制的重要工具。许多研究者在使用String数据库和Cytoscape软件时会遇到数据导入失败、节点筛选困难、图形美化耗时等问题。本文将针对这些痛…...

终极指南:5分钟掌握Illustrator批量替换神器ReplaceItems.jsx,效率提升20倍
终极指南:5分钟掌握Illustrator批量替换神器ReplaceItems.jsx,效率提升20倍 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 如果你正在寻找能够大幅提升Adob…...

低延时RS译码器优化设计【附代码】
✨ 长期致力于RS码、低延时、功耗优化、译码器研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)改进型RiBM迭代展开算法加速关键方程求解: …...

【NotebookLM政治学研究加速器】:20年政治理论研究员亲授5大高阶用法,告别文献综述低效时代
更多请点击: https://intelliparadigm.com 第一章:NotebookLM政治学研究辅助的范式革命 传统政治学研究长期依赖人工文献综述、手工编码与静态模型推演,面临信息过载、理论验证滞后与跨文本语义关联薄弱等结构性瓶颈。NotebookLM 作为基于引…...

DIY蓝牙游戏手柄:基于Arduino与Cherry MX轴体的全流程制作指南
1. 项目概述与核心思路几年前,我在折腾机械键盘时,看着手边多出来的几颗Cherry MX轴体,突然冒出一个想法:这些清脆、精准的触发单元,除了在键盘上噼里啪啦,能不能变成更直接的操控工具?比如&…...
)
调试效率翻倍:在VSCode里实时查看PY32的RTT日志(JLink OB就行)
嵌入式开发效率革命:VSCode集成JLink RTT日志全攻略 1. 嵌入式开发者的效率痛点与解决方案 在嵌入式开发领域,调试信息的输出一直是影响开发效率的关键环节。传统方式通常需要依赖串口输出,开发者不得不在多个工具间频繁切换——编写代码时使…...
)
跟着 MDN 学 HTML day_51:(深入理解 XPathEvaluator 接口)
在前端开发中,我们经常需要对 DOM 树进行复杂的节点查询。虽然 querySelector 和 querySelectorAll 已经能够满足大部分 CSS 选择器需求,但在某些场景下,我们需要更强大的查询能力,比如根据节点的文本内容查找、根据属性是否存在进…...

PCIe 6.0 Flit Mode 实战解析:从TLP到Flit,你的数据包到底经历了什么?
PCIe 6.0 Flit Mode 深度解析:数据包的奇幻漂流之旅 当一颗来自CPU的事务请求被封装成TLP(Transaction Layer Packet)时,它即将开始一段穿越PCIe 6.0协议栈的奇妙旅程。这段旅程不再是传统PCIe版本中的"自由行"…...