XGB-9: 分类数据
从1.5版本开始,XGBoost Python包为公共测试提供了对分类数据的实验性支持。对于数值数据,切分条件被定义为 v a l u e < t h r e s h o l d value < threshold value<threshold ,而对于分类数据,切分的定义取决于是否使用分区或独热编码。对于基于分区的切分,切分被指定为 v a l u e ∈ c a t e g o r i e s value \in categories value∈categories,其中categories是一个特征中的类别集。如果使用独热编码,则切分定义为 v a l u e = = c a t e g o r y value == category value==category 。
使用 scikit-learn 进行训练
将分类数据传递给XGBoost的最简单方法是使用数据框和scikit-learn接口,如XGBClassifier。为了准备数据,用户需要将输入预测器的数据类型指定为category。对于pandas/cudf数据框,可以通过以下方式实现:
X["cat_feature"].astype("category")
对于表示分类特征的所有列。之后,用户可以告诉XGBoost启用对分类数据的训练。假设正在使用XGBClassifier进行分类问题,指定参数enable_categorical:
# 支持的树方法有 `approx` 和 `hist`。
clf = xgb.XGBClassifier(tree_method="hist", enable_categorical=True, device="cuda")# X 是前面代码片段中创建的数据框
clf.fit(X, y)# 必须使用 JSON/UBJSON 进行序列化,否则信息将丢失。
clf.save_model("categorical-model.json")
训练完成后,大多数其他特征都可以利用该模型。例如,可以绘制模型并计算全局特征重要性:
# 获取图形
graph = xgb.to_graphviz(clf, num_trees=1)# 获取 matplotlib 轴
ax = xgb.plot_tree(clf, num_trees=1)# 获取特征重要性
clf.feature_importances_
dask中的scikit-learn接口与单节点版本类似。基本思想是创建包含category特征类型的数据框,并通过设置enable_categorical参数告诉XGBoost使用它。有关在scikit-learn接口中使用带有独热编码的分类数据的实际示例,请参见使用cat_in_the_dat数据集进行分类数据的入门。可以在Train XGBoost with cat_in_the_dat dataset中找到使用独热编码数据和XGBoost分类数据支持的比较。
最佳分区Optimal Partitioning
最佳分区是一种用于每个节点拆分的分类预测变量的技术,首次由[1]引入并证明在数值输出方面是最优的。该算法用于决策树[2],后来LightGBM [3]将其引入到梯度提升树的上下文中,现在也作为XGBoost的可选功能用于处理分类拆分。具体而言,Fisher [1]的证明表明,当试图基于这些值的度量之间的距离将一组离散值分区为组时,只需要查看排序的分区而不是枚举所有可能的排列。在决策树的上下文中,离散值是类别,度量是输出叶子值。直观地说,希望将输出类似叶值的类别分组。在查找拆分时,**首先对梯度直方图进行排序,以准备连续的分区,然后根据这些排序的值枚举拆分。**XGBoost的相关参数之一是max_cat_to_onehot,它控制每个特征是使用独热编码还是分区,详见分类特征的参数详情。
使用原生接口Using native interface
scikit-learn接口对用户非常友好,但缺少仅在原生接口中提供的某些功能。例如,用户无法直接计算SHAP值。此外,原生接口支持更多的数据类型。要在具有分类数据的情况下使用原生接口,我们需要将类似的参数传递给DMatrix或QuantileDMatrix和train函数。对于数据框输入:
# X is a dataframe we created in previous snippet
Xy = xgb.DMatrix(X, y, enable_categorical=True)
booster = xgb.train({"tree_method": "hist", "max_cat_to_onehot": 5}, Xy)# Must use JSON for serialization, otherwise the information is lost
booster.save_model("categorical-model.json")
SHAP值计算:
SHAP = booster.predict(Xy, pred_interactions=True)# categorical features are listed as "c"
print(booster.feature_types)
对于其他类型的输入,例如numpy数组,可以通过在DMatrix中使用feature_types参数来告诉XGBoost有关特征类型:
# "q" is numerical feature, while "c" is categorical feature
ft = ["q", "c", "c"]
X: np.ndarray = load_my_data()
assert X.shape[1] == 3
Xy = xgb.DMatrix(X, y, feature_types=ft, enable_categorical=True)
对于数值数据,特征类型可以是"q"或"float",而对于分类特征,则指定为"c"。XGBoost中的Dask模块具有相同的接口,因此dask.Array也可以用于分类数据。最后,sklearn接口XGBRegressor也具有相同的参数。
数据一致性
XGBoost接受参数来指示哪个特征被视为分类特征,可以通过dataframe的dtypes或通过feature_types参数来指定。然而,XGBoost本身不存储关于类别如何编码的信息。例如,给定将音乐流派映射到整数代码的编码模式:
{"acoustic": 0, "indie": 1, "blues": 2, "country": 3}
XGBoost不知道输入的映射,因此无法将其存储在模型中。映射通常在用户的数据工程管道中发生,使用像sklearn.preprocessing.OrdinalEncoder这样的列转换器。为了确保XGBoost的正确结果,用户需要保持在训练和测试数据上一致的数据转换管道。用户应该注意以下错误:
X_train["genre"] = X_train["genre"].astype("category")
reg = xgb.XGBRegressor(enable_categorical=True).fit(X_train, y_train)# invalid encoding
X_test["genre"] = X_test["genre"].astype("category")
reg.predict(X_test)
在上面的代码片段中,训练数据和测试数据被分别编码,导致两个不同的编码模式和无效的预测结果。有关使用序数编码器的示例,请参阅特征工程管道以获取分类数据。
其他注意事项
默认情况下,XGBoost假设输入类别是从0到类别数 [ 0 , n _ c a t e g o r i e s ) [0, n\_categories) [0,n_categories)的整数。然而,由于训练数据集中的错误或缺失值,用户可能提供具有无效值的输入。这可能是负值、无法由32位浮点表示的整数值,或大于实际唯一类别数的值。在训练期间,需要进行验证,但对于预测而言,出于性能原因,它被视为未选择的类别。
参考
-
[1] Walter D. Fisher. “On Grouping for Maximum Homogeneity”. Journal of the American Statistical Association. Vol. 53, No. 284 (Dec., 1958), pp. 789-798.
-
[2] Trevor Hastie, Robert Tibshirani, Jerome Friedman. “The Elements of Statistical Learning”. Springer Series in Statistics Springer New York Inc. (2001).
-
[3] Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu. “LightGBM: A Highly Efficient Gradient Boosting Decision Tree.” Advances in Neural Information Processing Systems 30 (NIPS 2017), pp. 3149-3157.
-
https://xgboost.readthedocs.io/en/latest/tutorials/categorical.html
-
https://www.kaggle.com/code/shahules/an-overview-of-encoding-techniques/notebook
相关文章:

XGB-9: 分类数据
从1.5版本开始,XGBoost Python包为公共测试提供了对分类数据的实验性支持。对于数值数据,切分条件被定义为 v a l u e < t h r e s h o l d value < threshold value<threshold ,而对于分类数据,切分的定义取决于是否使用…...

FreeRTOS学习第8篇--同步和互斥操作引子
目录 FreeRTOS学习第8篇--同步和互斥操作引子同步和互斥概念实现同步和互斥的机制PrintTask_Task任务相关代码片段CalcTask_Task任务相关代码片段实验现象本文中使用的测试工程 FreeRTOS学习第8篇–同步和互斥操作引子 本文目标:学习与使用FreeRTOS中的同步和互斥操…...
,c++STL算法的理解与使用(sort, find, binary_search等))
c++STL容器的使用(vector, list, map, set等),c++STL算法的理解与使用(sort, find, binary_search等)
cSTL容器的使用(vector, list, map, set等) 在C的STL(Standard Template Library)中,容器是重要的一部分,它们提供了各种数据结构来存储和管理数据。以下是一些常见的STL容器及其使用方法的简要说明&#x…...

选择VR全景行业,需要了解哪些内容?
近年来,随着虚拟现实、增强现实等技术的持续发展,VR全景消费市场得以稳步扩张。其次,元宇宙行业的高速发展,也在进一步拉动VR全景技术的持续进步,带动VR产业的高质量发展。作为一种战略性的新兴产业,国家和…...

830. 单调栈
Problem: 830. 单调栈 文章目录 思路解题方法复杂度Code 思路 这是一个单调栈的问题。单调栈是一种特殊的栈结构,它的特点是栈中的元素保持单调性。在这个问题中,我们需要找到每个元素左边第一个比它小的元素,这就需要使用到单调递增栈。 我们…...

H5 个人引导页官网型源码
H5 个人引导页官网型源码 源码介绍:源码无后台、无数据库,H5自检测适应、无加密,直接修改可用。 源码含有多选项,多功能。可展示自己站点、团队站点。手机电脑双端。 下载地址: https://www.changyouzuhao.cn/1434.…...
【Linux】部署前后端分离项目---(Nginx自启,负载均衡)
目录 前言 一 Nginx(自启动) 2.1 Nginx的安装 2.2 设置自启动Nginx 二 Nginx负载均衡tomcat 2.1 准备两个tomcat 2.1.1 复制tomcat 2.1.2 修改server.xml文件 2.1.3 开放端口 2.2 Nginx配置 2.2.1 修改nginx.conf文件 2.2.2 重启Nginx服务 2…...
WPF Style样式设置
1.本window设置样式 <Window x:Class"WPF_Study.MainWindow"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.com/winfx/2006/xaml"xmlns:d"http://schemas.microsoft.com/expressi…...

【STM32】软件SPI读写W25Q64芯片
目录 W25Q64模块 W25Q64芯片简介 硬件电路 W25Q64框图 Flash操作注意事项 状态寄存器 编辑 指令集 INSTRUCTIONS编辑 编辑 SPI读写W25Q64代码 硬件接线图 MySPI.c MySPI.h W25Q64 W25Q64.c W25Q64.h W25Q64_Ins.h main.c 测试 SPI通信(W25…...

普通中小学校管理信息系统V1.1
普通中小学校管理信息系统 Ordinary Primary and Secondary Schools Management Information System 普通中小学校管理信息系统 Ordinary Primary and Secondary Schools Management Information System...

中国水果采摘机器人行业市场研究及发展趋势分析报告
全版价格:壹捌零零 报告版本:下单后会更新至最新版本 交货时间:1-2天 第一章 2016-2026年中国水果采摘机器人行业总概 1.1 中国水果采摘机器人行业发展概述 机器人技术的发展是一个国家高科技水平和工业自动化程度的重要标志和体现。机器…...

Linux多进程与信号
在多进程的服务程序中,如果子进程收到退出信号,子进程自行退出。如果父进程收到退出信号,应该先向全部的子进程发送退出信号,然后自己再退出。 演示demo程序 #include <iostream> // 包含输入输出流库,用于输…...

Self-attention与Word2Vec
Self-attention(自注意力)和 Word2Vec 是两种不同的词嵌入技术,用于将单词映射到低维向量空间。它们之间的区别: Word2Vec: Word2Vec 是一种传统的词嵌入(word embedding)方法,旨在为…...
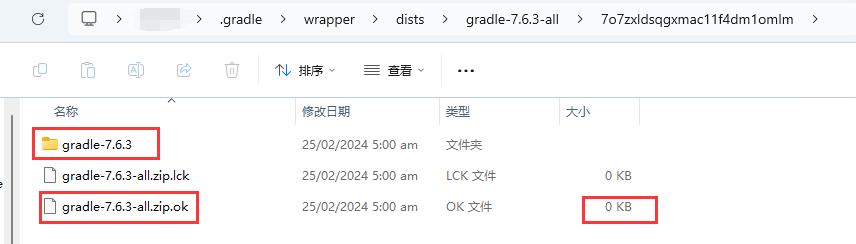
【Flutter/Android】运行到安卓手机上一直卡在 Running Gradle task ‘assembleDebug‘... 的终极解决办法
方法步骤简要 查看你的Flutter项目需要什么版本的 Gradle 插件: 下载这个插件: 方法一:浏览器输入:https://services.gradle.org/distributions/gradle-7.6.3-all.zip 方法二:去Gradle官网找对应的版本:h…...

医疗实施-客户需求分析
在我的日常系统实施过程中,总会遇到不同角色的客户提出不同类别的需求。有的需求,客户目的想提高操作便携,但会对系统稳定性存在风险,应该拒掉。有些需求紧急而且影响重大,应该紧急处理。有些需求可以做,但…...
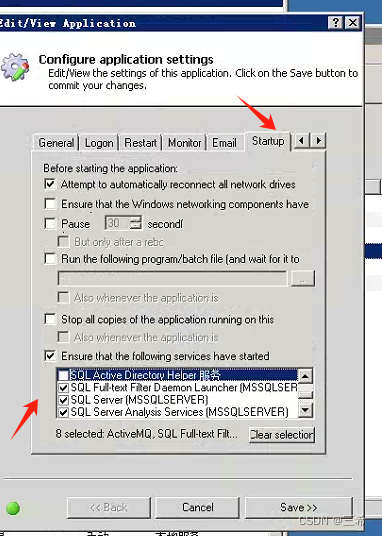
调度服务看门狗配置
查看当前服务器相关的sqlserver服务 在任务栏右键,选择点击启动任务管理器 依次点击,打开服务 找到sqlserver 相关的服务, 确认这些服务是启动状态 将相关服务在看门狗中进行配置 选择调度服务,双击打开 根据上面找的服务进行勾…...

AI时代 编程高手的秘密武器:世界顶级大学推荐的计算机教材
文章目录 01 《深入理解计算机系统》02 《算法导论》03 《计算机程序的构造和解释》04 《数据库系统概念》05 《计算机组成与设计:硬件/软件接口》06 《离散数学及其应用》07 《组合数学》08《斯坦福算法博弈论二十讲》 清华、北大、MIT、CMU、斯坦福的学霸们在新学…...

【数据结构和算法初阶(c语言)】数据结构前言,初识数据结构(给你一个选择学习数据结构和算法的理由)
1.何为数据结构 数据结构(Data Structure)是计算机存储、组织数据的方式,指相互之间存在一种或多种特定关系的 数据元素的集合。本质来讲就是在内存中去管理数据方式比如我们的增删查改。在内存中管理数据的方式有很多种(比如数组结构、链式结构、树型结…...
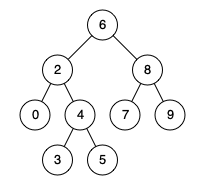
LeetCode 0235.二叉搜索树的最近公共祖先:用搜索树性质(不遍历全部节点)
【LetMeFly】235.二叉搜索树的最近公共祖先:用搜索树性质(不遍历全部节点) 力扣题目链接:https://leetcode.cn/problems/lowest-common-ancestor-of-a-binary-search-tree/ 给定一个二叉搜索树, 找到该树中两个指定节点的最近公…...

【Prometheus】概念和工作原理介绍
目录 一、概述 1.1 prometheus简介 1.2 prometheus特点 1.3 prometheus架构图 1.4 prometheus组件介绍 1、Prometheus Server 2、Client Library 3、pushgateway 4、Exporters 5、Service Discovery 6、Alertmanager 7、grafana 1.5 Prometheus 数据流向 1.6 Pro…...

四个数字,能组成多少个互不重复且无重复数字的三位数
题目:有 1、2、3、4 四个数字,能组成多少个互不相同且无重复数字的三位数?都是多少?思路:用三层嵌套循环让百位、十位、个位各自在 1~4 上枚举(共 444 种组合)。printf 把三个循环变…...

Sealos云操作系统:基于Kubernetes内核的桌面化云原生平台实践
1. 项目概述:从“集群”到“桌面”的云原生新范式如果你和我一样,长期在云原生领域摸爬滚打,那么对“Kubernetes集群”的部署和管理一定不会陌生。从早期的kubeadm手动搭建,到后来各种发行版和托管服务,我们一直在追求…...

艾尔登法环性能优化解决方案:帧率解锁与游戏体验增强
艾尔登法环性能优化解决方案:帧率解锁与游戏体验增强 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/Elde…...

5分钟快速上手COLA架构:构建清晰分层的企业级应用完整指南
5分钟快速上手COLA架构:构建清晰分层的企业级应用完整指南 【免费下载链接】COLA 🥤 COLA: Clean Object-oriented & Layered Architecture 项目地址: https://gitcode.com/gh_mirrors/col/COLA COLA(Clean Object-oriented &…...

2026厦门国际智能交通运输产业博览会开幕:海外需求与国内先进技术的双向奔赴
2026年5月13日,为期三天的2026厦门国际智能交通运输产业博览会(CITSE 2026,以下简称“智交会”)隆重开幕。本届智交会由中国智能交通协会联合厦门会展集团股份有限公司共同举办,以“聚焦产业创新变革,赋能出…...

智能车竞赛实战:从PID控制到图像识别的嵌入式系统开发全解析
1. 项目概述:一场硬核的嵌入式综合实战“飞思卡尔杯”智能车竞赛,这个名字对于很多电子、自动化、计算机相关专业的同学来说,绝对是一个如雷贯耳的存在。它不仅仅是一个比赛,更像是一个集机械、电子、控制、算法于一体的微型“工业…...
终极指南:从入门到实战的完整教程)
多尺度地理加权回归(MGWR)终极指南:从入门到实战的完整教程
多尺度地理加权回归(MGWR)终极指南:从入门到实战的完整教程 【免费下载链接】mgwr Multiscale Geographically Weighted Regression (MGWR) 项目地址: https://gitcode.com/gh_mirrors/mg/mgwr 面对复杂多变的空间数据,传统的地理加权回归(GWR)常…...

告别硬件依赖:用Proteus玩转STM32F1,从CubeMX生成代码到仿真调试的避坑实践
零硬件玩转STM32F103:Proteus仿真全流程与LL库高效开发指南 从真实硬件到虚拟仿真的思维转换 嵌入式开发者的传统认知里,调试灯闪烁必须连接实物开发板——直到他们遇到Proteus。这款电路仿真软件让STM32F103系列芯片在虚拟环境中完美运行,配…...

Python崛起背后的四大引擎:从数据科学到Web开发的全栈语言进化
1. 从数据看趋势:Python为何成为开发者社区的“流量明星”最近在Stack Overflow上看到一组数据,挺有意思的。数据科学家David Robinson指出,Python已经成为该平台上访问量增长最快的主流编程语言。这个结论不是空穴来风,而是基于对…...
)
用Arduino和MAX7219点亮你的第一个8x8 LED点阵屏(附完整代码与接线图)
用Arduino和MAX7219点亮你的第一个8x8 LED点阵屏(附完整代码与接线图) 第一次接触LED点阵屏时,那种通过代码让灯光按自己想法舞动的感觉,就像掌握了某种魔法。MAX7219这颗神奇的驱动芯片,能让我们用最简单的Arduino板…...