Python算法题集_实现 Trie [前缀树]
Python算法题集_实现 Trie [前缀树]
- 题208:实现 Trie (前缀树)
- 1. 示例说明
- 2. 题目解析
- - 题意分解
- - 优化思路
- - 测量工具
- 3. 代码展开
- 1) 标准求解【定义数据类+默认字典】
- 2) 改进版一【初始化字典+无额外类】
- 3) 改进版二【字典保存结尾信息+无额外类】
- 4. 最优算法
- 5. 相关资源
本文为Python算法题集之一的代码示例
题208:实现 Trie (前缀树)
1. 示例说明
-
Trie(发音类似 “try”)或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补完和拼写检查。
请你实现 Trie 类:
Trie()初始化前缀树对象。void insert(String word)向前缀树中插入字符串word。boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。
示例:
输入 ["Trie", "insert", "search", "search", "startsWith", "insert", "search"] [[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]] 输出 [null, null, true, false, true, null, true]解释 Trie trie = new Trie(); trie.insert("apple"); trie.search("apple"); // 返回 True trie.search("app"); // 返回 False trie.startsWith("app"); // 返回 True trie.insert("app"); trie.search("app"); // 返回 True提示:
1 <= word.length, prefix.length <= 2000word和prefix仅由小写英文字母组成insert、search和startsWith调用次数 总计 不超过3 * 104次
2. 题目解析
- 题意分解
- 本题是为自动补完、拼写检查等创造一个高效率的检索类
- 基本的设计思路迭代单词,每层用字典保存,同时还需要保存单词结尾信息【search检测结尾、startWith不检测】
- 优化思路
-
通常优化:减少循环层次
-
通常优化:增加分支,减少计算集
-
通常优化:采用内置算法来提升计算速度
-
分析题目特点,分析最优解
-
可以尝试使用默认字典
defaultdict -
本题都是小写字母,因此26个元素的字典就可以保存一个层级
-
所有单词字符都是ASCII码,Ord值都在0-127,因此128个元素的字典可以正常使用【超时测试用例,需要128一层】
-
可以考虑将单词结尾信息保存在字典中,用一个单词中不会出现的字符即可,比如’#’
-
- 测量工具
- 本地化测试说明:LeetCode网站测试运行时数据波动很大【可把页面视为功能测试】,因此需要本地化测试解决数据波动问题
CheckFuncPerf(本地化函数用时和内存占用测试模块)已上传到CSDN,地址:Python算法题集_检测函数用时和内存占用的模块- 本题本地化超时测试用例自己生成,详见章节【最优算法】,需要安装和部署**
NLTK**
3. 代码展开
1) 标准求解【定义数据类+默认字典】
使用默认字典,定位专门的数据类,使用类属性保存单词结尾信息
页面功能测试,马马虎虎,超过33%
import CheckFuncPerf as cfpclass prenode:def __init__(self):self.chars = defaultdict(int)class Trie_base:def __init__(self):self.node = prenode()self.bEnd = Falsedef searchPrefix(self, prefix):tmpNode = selffor achar in prefix:ichar = ord(achar) - ord("a")if tmpNode.node.chars[ichar] == 0:return NonetmpNode = tmpNode.node.chars[ichar]return tmpNodedef insert(self, word):tmpNode = selffor achar in word:ichar = ord(achar) - ord("a")if tmpNode.node.chars[ichar] == 0:tmpNode.node.chars[ichar] = Trie_base()tmpNode = tmpNode.node.chars[ichar]tmpNode.bEnd = Truedef search(self, word):node = self.searchPrefix(word)return node is not None and node.bEnddef startsWith(self, prefix):return self.searchPrefix(prefix) is not NonetmpTrie = Trie_base()
result = cfp.getTimeMemoryStr(testTrie, tmpTrie, actions)
print(result['msg'], '执行结果 = {}'.format(result['result']))# 运行结果
函数 testTrie 的运行时间为 7127.62 ms;内存使用量为 373008.00 KB 执行结果 = 99
2) 改进版一【初始化字典+无额外类】
将字典数据和单词结尾信息都保存在节点类中,创建类同时初始化字典的128个元素【按题意只需26,本类已经按超时测试改写】
页面功能测试,马马虎虎,超过65%
import CheckFuncPerf as cfpclass Trie_ext1:def __init__(self):self.data = [None] * 128self.bEnd = Falsedef searchPrefix(self, prefix):tmpnode = selffor achar in prefix:ichar = ord(achar)if not tmpnode.data[ichar]:return Nonetmpnode = tmpnode.data[ichar]return tmpnodedef insert(self, word):tmpnode = selffor achar in word:ichar = ord(achar)if not tmpnode.data[ichar]:tmpnode.data[ichar] = Trie_ext1()tmpnode = tmpnode.data[ichar]tmpnode.bEnd = Truedef search(self, word):tmpnode = self.searchPrefix(word)return tmpnode is not None and tmpnode.bEnddef startsWith(self, prefix):return self.searchPrefix(prefix) is not NonetmpTrie = Trie_ext1()
result = cfp.getTimeMemoryStr(testTrie, tmpTrie, actions)
print(result['msg'], '执行结果 = {}'.format(result['result']))# 运行结果
函数 testTrie 的运行时间为 5857.32 ms;内存使用量为 793700.00 KB 执行结果 = 99
3) 改进版二【字典保存结尾信息+无额外类】
在字典中保存单词结尾信息,将字典数据保存在节点类中,创建类时不初始化字典
页面功能测试,性能卓越,超越96%
import CheckFuncPerf as cfpclass Trie_ext2:def __init__(self):self.tree = {}def insert(self, word):tree = self.treefor achar in word:if achar not in tree:tree[achar] = {}tree = tree[achar]tree["#"] = "#"def search(self, word):tree = self.treefor achar in word:if achar not in tree:return Falsetree = tree[achar]return "#" in treedef startsWith(self, prefix):tree = self.treefor achar in prefix:if achar not in tree:return Falsetree = tree[achar]return TruetmpTrie = Trie_ext2()
result = cfp.getTimeMemoryStr(testTrie, tmpTrie, actions)
print(result['msg'], '执行结果 = {}'.format(result['result']))# 运行结果
函数 testTrie 的运行时间为 1670.38 ms;内存使用量为 146692.00 KB 执行结果 = 99
4. 最优算法
根据本地日志分析,最优算法为第3种方式【字典保存结尾信息+无额外类】Trie_ext2
本题大概有以下结论:
- 独立的变量,如果能保存在字典结构里,减少独立的变量数,可以提升性能
- 数据集的默认初始化可能会扩大内存使用,同时数据量过大、内存过大也拖累性能
import random
from nltk.corpus import words
word_list = list(words.words())
def testTrie(aTrie, actions):for act in actions:if act[0]==1: # insertaTrie.insert(act[1])elif act[0]==2: # searchaTrie.search(act[1])elif act[0]==3: # startsWithaTrie.startsWith(act[1])return 99
import random
actions = []
iLen = 1000000
for iIdx in range(iLen):actions.append([random.randint(1, 3), random.choice(word_list)])
tmpTrie = Trie_base()
result = cfp.getTimeMemoryStr(testTrie, tmpTrie, actions)
print(result['msg'], '执行结果 = {}'.format(result['result']))
tmpTrie = Trie_ext1()
result = cfp.getTimeMemoryStr(testTrie, tmpTrie, actions)
print(result['msg'], '执行结果 = {}'.format(result['result']))
tmpTrie = Trie_ext2()
result = cfp.getTimeMemoryStr(testTrie, tmpTrie, actions)
print(result['msg'], '执行结果 = {}'.format(result['result']))# 算法本地速度实测比较
函数 testTrie 的运行时间为 7127.62 ms;内存使用量为 373008.00 KB 执行结果 = 99
函数 testTrie 的运行时间为 5857.32 ms;内存使用量为 793700.00 KB 执行结果 = 99
函数 testTrie 的运行时间为 1670.38 ms;内存使用量为 146692.00 KB 执行结果 = 99
5. 相关资源
本文代码已上传到CSDN,地址:**Python算法题源代码_LeetCode(力扣)_**实现Trie(前缀树)
一日练,一日功,一日不练十日空
may the odds be ever in your favor ~
相关文章:
Python算法题集_实现 Trie [前缀树]
Python算法题集_实现 Trie [前缀树] 题208:实现 Trie (前缀树)1. 示例说明2. 题目解析- 题意分解- 优化思路- 测量工具 3. 代码展开1) 标准求解【定义数据类默认字典】2) 改进版一【初始化字典无额外类】3) 改进版二【字典保存结尾信息无额外类】 4. 最优算法5. 相关…...

pytorch简单新型模型测试参数
import torch from torch.nn import Conv2d,MaxPool2d,Sequential,Flatten,Linear import torchvision import torch.optim.optimizer from torch.utils.data import DataLoader,dataset from torch import nn import torch.optim.optimizer# 建模 model nn.Linear(2,1)#损失 …...
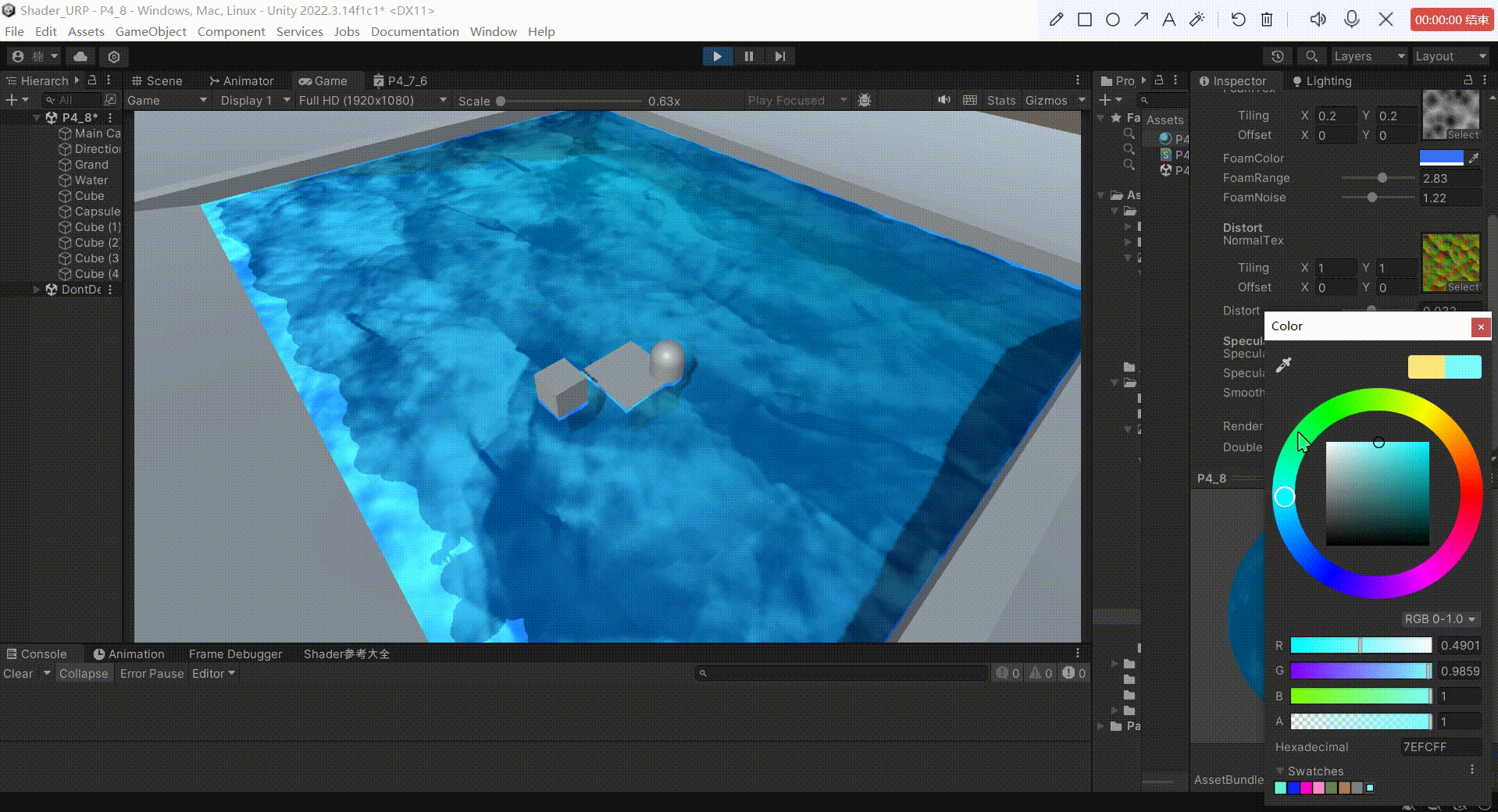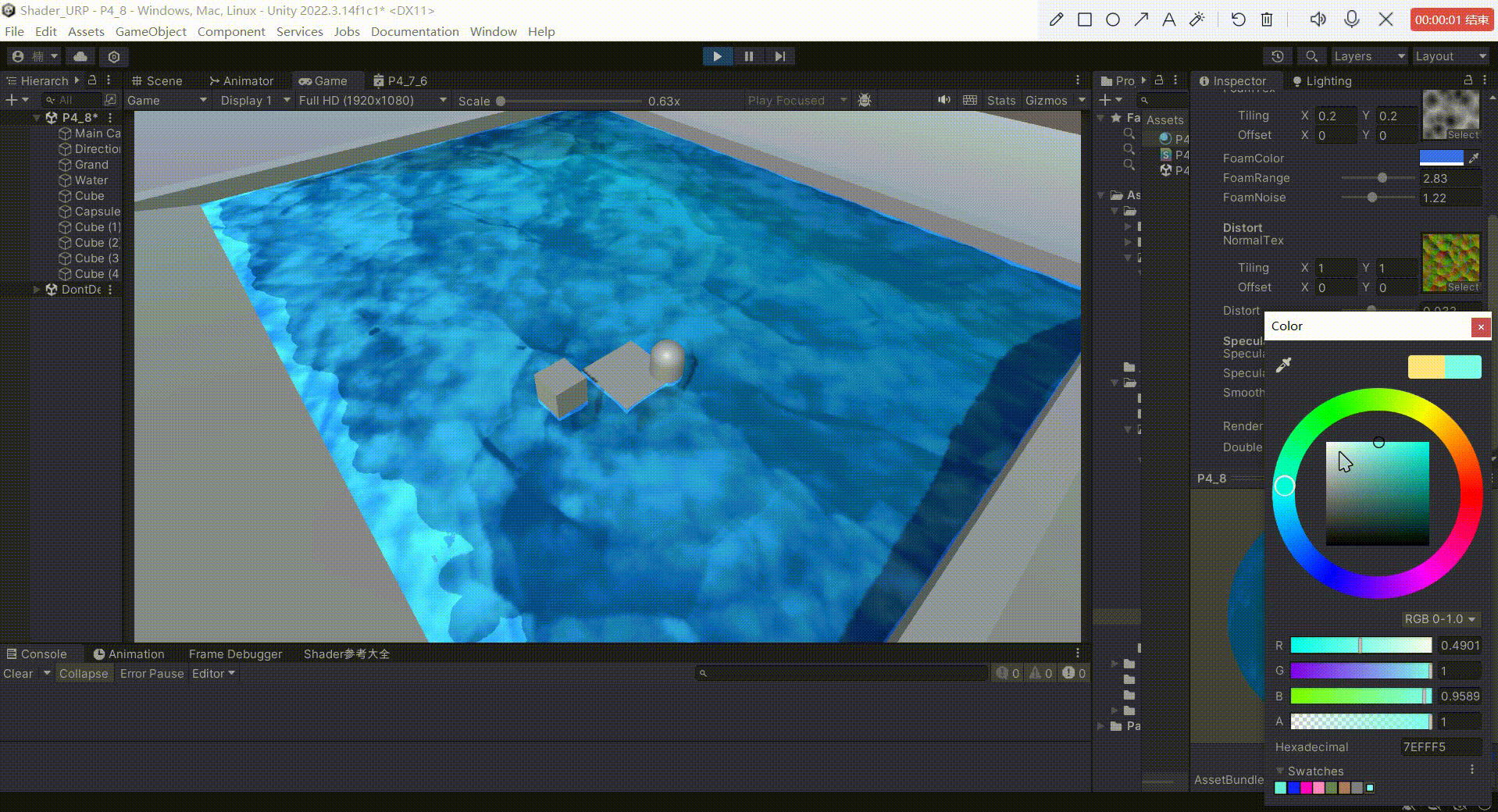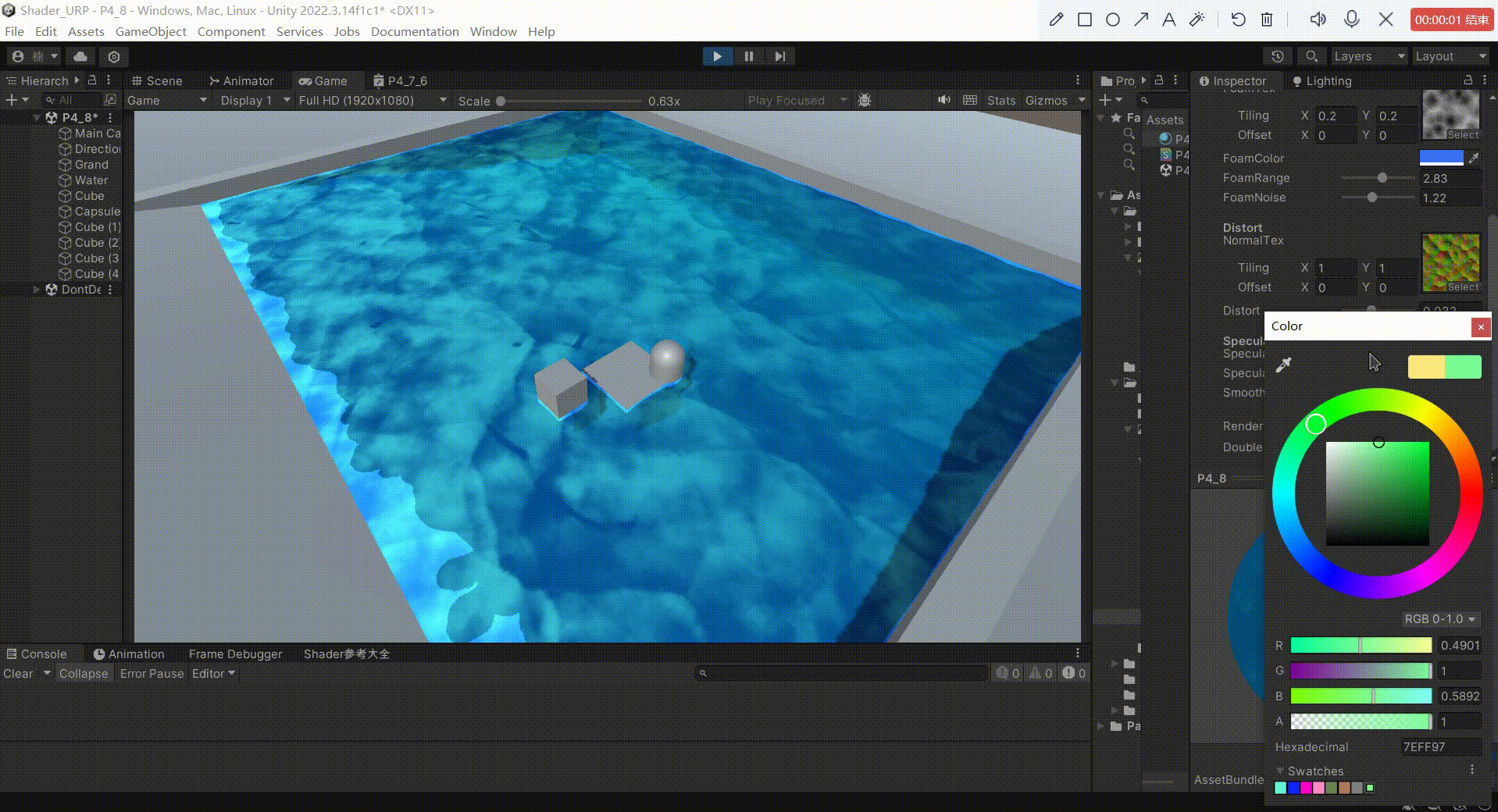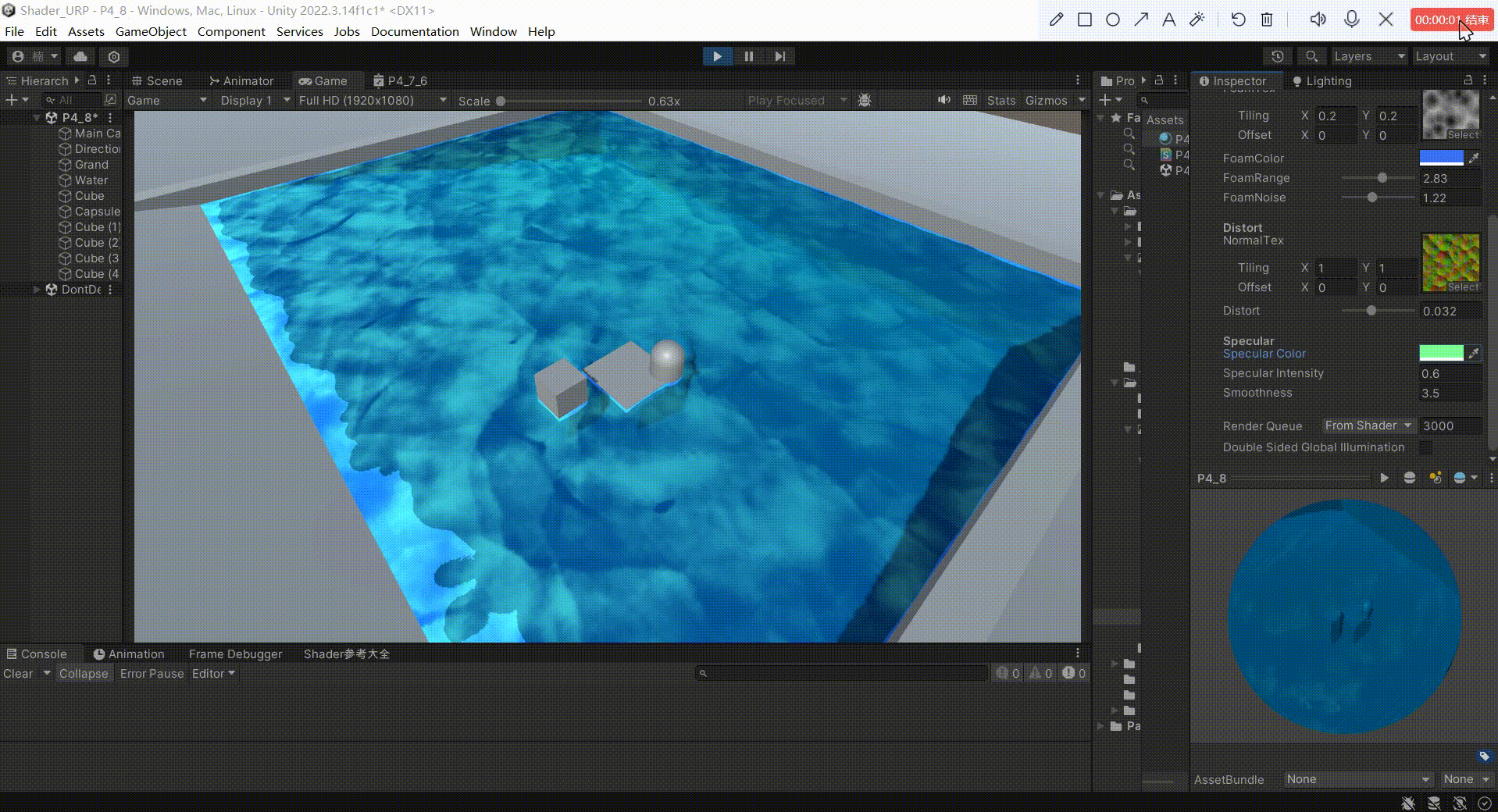
Unity中URP下实现水体(水面高光)
文章目录 前言一、实现高光反射原理1、原理:2、公式: 二、实现1、定义 _SpecularColor 作为高光反射的颜色2、定义 _SpecularIntensity 作为反射系数,控制高光反射的强度3、定义 _Smoothness 作为高光指数,用于模型高光范围4、模拟…...

26.HarmonyOS App(JAVA)列表对话框
列表对话框的单选模式: //单选模式 // listDialog.setSingleSelectItems(new String[]{"第1个选项","第2个选项"},1);//单选 // listDialog.setOnSingleSelectListener(new IDialog.ClickedListener() { // Override …...

五种主流数据库:常用字符函数
SQL 字符函数用于字符数据的处理,例如字符串的拼接、大小写转换、子串的查找和替换等。 本文比较五种主流数据库常用数值函数的实现和差异,包括 MySQL、Oracle、SQL Server、PostgreSQL 以及 SQLite。 字符函数函数功能MySQLOracleSQL ServerPostgreSQ…...

软考笔记--企业资源规划和实施
企业资源是指企业业务活动和战略运营的事物,包括人、财和物,也包括信息资源,同时也包括企业的内部和外部资源。企业资源可以归纳为物流,资金流和信息流。企业资源规划(ERP)是只建立在信息技术基础上&#x…...
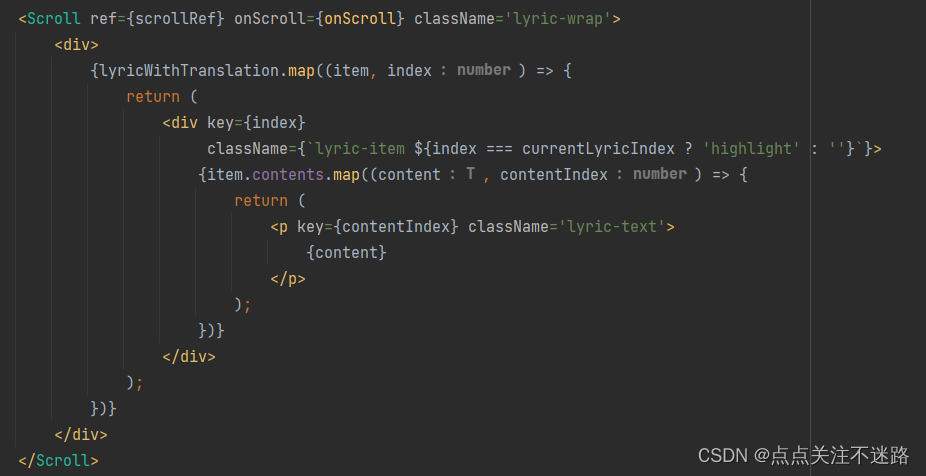
React歌词滚动效果(跟随音乐播放时间滚动)
首先给audio绑定更新时间事件 const updateTime e > {console.log(e.target.currentTime)setCurrentTime(e.target.currentTime);};<audiosrc{currentSong.url}ref{audio}onCanPlay{ready}onEnded{end}onTimeUpdate{updateTime}></audio>当歌曲播放时间改变的时…...
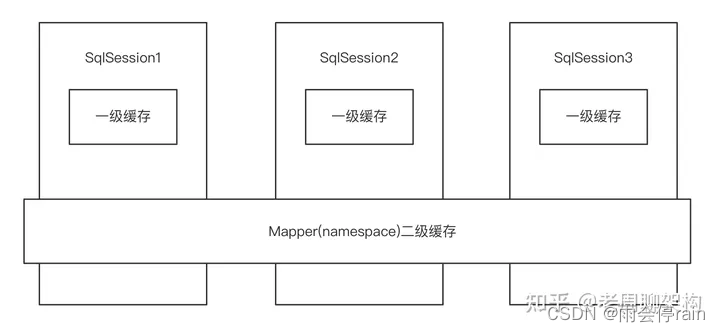
java面试题之mybatis篇
什么是ORM? ORM(Object/Relational Mapping)即对象关系映射,是一种数据持久化技术。它在对象模型和关系型数据库直接建立起对应关系,并且提供一种机制,通过JavaBean对象去操作数据库表的数据。 MyBatis通过…...

Java的编程之旅19——使用idea对面相对象编程项目的创建
在介绍面向对象编程之前先说一下我们在idea中如何创建项目文件 使用快捷键CtrlshiftaltS新建一个模块,点击“”,再点New Module 点击Next 我这里给Module起名叫OOP,就是面向对象编程的英文缩写,再点击下面的Finish 点Apply或OK均可 右键src…...

docker build基本命令
背景 我们经常会构建属于我们应用自己的镜像,这种情况下编写dockerfile文件不可避免,本文就来看一下常用的dockerfile的指令 常用的dockerfile的指令 首先我们看一下docker build的执行过程 ENV指令: env指令用于设置shell的环境变量&am…...
nginx高级配置详解
目录 一、网页的状态页 1、状态页的基本配置 2、搭配验证模块使用 3、结合白名单使用 二、nginx 第三方模块 1、echo模块 1.1 编译安装echo模块 1.2 配置echo模块 三、nginx变量 1、内置变量 2、自定义变量 四、自定义图标 五、自定义访问日志 1、自定义日志格式…...

小程序--分包加载
分包加载是优化小程序加载速度的一种手段。 一、为什么进行分包 小程序限制单个包体积不超过2M; 分包可以优化小程序页面的加载速度。 二、启用/使用分包语法subPackages subPackages:下载app.json文件中 root:分包所在的目录 pages&#x…...
)
R语言【base】——writeLines()
Package base version 4.2.0 Description 向连接写入文本行。 Usage writeLines(text, con stdout(), sep "\n", useBytes FALSE) Arguments 参数【text】:一个字符向量。 参数【con】:一个 connection 对象 或 一个字符串。 参数【se…...

微信小程序-人脸检测
微信小程序的人脸检测功能,配合蓝牙,配合ESP32 可以实现一些有趣的玩具 本文先只说微信小程序的人脸检测功能 1、人脸检测使用了摄像头,就必须在用户隐私权限里面声明。 修改用户隐私声明后,还需要等待审核,大概一天 …...

微信小程序自制动态导航栏
写在前面 关于微信小程序导航栏的问题以及解决办法我已经在先前的文章中有提到,点击下面的链接即可跳转~ 🤏微信小程序自定义的导航栏🤏 在这篇文章中我们需要做一个这样的导航栏!先上效果图 👇👇…...
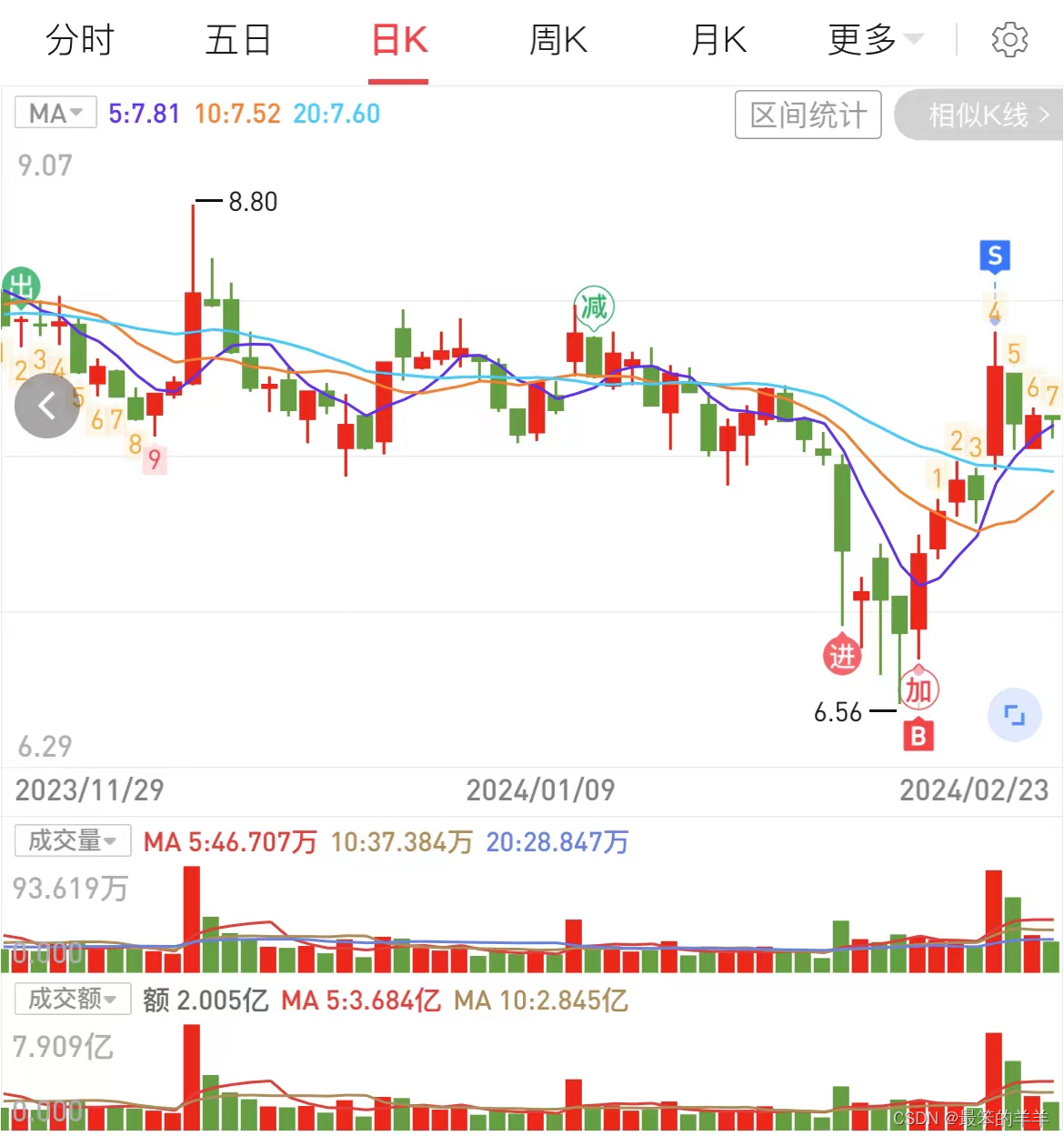
金融知识分享系列之:五日线
金融知识分享系列之:五日线 一、股票均线二、五日线三、五日线加量能三、五日线案例四、五日线案例五、五日线案例六、五日线案例七、五日线案例八、五日线案例 一、股票均线 股票均线是一种用于平滑股票价格的指标。它是根据一段时间内的股票价格计算得出的平均值…...
回归测试详解
🍅 视频学习:文末有免费的配套视频可观看 🍅 关注公众号:互联网杂货铺,回复1 ,免费获取软件测试全套资料,资料在手,涨薪更快 什么是回归测试 回归测试(Regression testi…...

渲染效果图有哪几种分类?效果图为什么用云渲染更快
云渲染利用了集群化的云端服务器资源,通过并行计算充分发挥了高性能硬件的优势,显著提升了渲染的速度。这一技术特别适用于处理规模庞大或细节丰富的渲染任务,在缩短项目完成时间方面表现卓越。无论是用于为建筑提供精确的可视化效果图&#…...
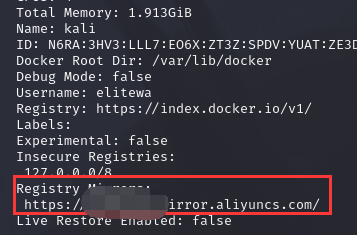
Docker镜像加速
前言 众所周知,我们常用的一些工具或系统的下载源都是国外的,这就会导致我们在下载一些东西时,会导致下载巨慢或者下载失败的情况,下面便是docker换下载源的教程 镜像加速 下面是几个常用的国内的镜像 科大镜像:ht…...

吴恩达deeplearning.ai:sigmoid函数的替代方案以及激活函数的选择
以下内容有任何不理解可以翻看我之前的博客哦:吴恩达deeplearning.ai专栏 文章目录 引入——改进下需求预测模型ReLU函数(整流线性单元 rectified linear unit)线性激活函数(linear activation function)激活函数的选择实现方式为什么需要激活函数 到现在…...

Cursor Free VIP破解工具:终极免费方案解决AI编程助手试用限制
Cursor Free VIP破解工具:终极免费方案解决AI编程助手试用限制 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached …...

Python 异步HTTP客户端实战:aiohttp深度解析
Python 异步HTTP客户端实战:aiohttp深度解析 引言 在现代Python后端开发中,异步HTTP客户端是构建高性能服务的关键组件。作为一名从Rust转向Python的后端开发者,我深刻体会到异步编程在处理大量并发请求时的优势。aiohttp作为Python生态中最流…...

终极视频字幕提取指南:用Video-subtitle-extractor轻松获取87种语言字幕
终极视频字幕提取指南:用Video-subtitle-extractor轻松获取87种语言字幕 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕…...

创业早期如何利用导师与代理模型构建核心支持体系
1. 创业早期支持体系的核心价值在技术驱动的创业领域,尤其是半导体、电子设计自动化这类高门槛行业,一个普遍存在的认知是:只要技术足够领先,产品足够创新,成功便是水到渠成。然而,现实往往比这复杂得多。我…...
与时间参数STmin)
从CANoe实战出发:深度解析UDS网络层诊断中的流控帧(FC)与时间参数STmin
从CANoe实战解析UDS流控帧:FC与STmin参数调优指南 在汽车电子测试领域,UDS诊断协议的网络层流控机制直接影响着ECU通信的可靠性与效率。当测试工程师在CANoe环境中模拟诊断会话时,经常会遇到因流控帧参数配置不当导致的报文丢失、响应超时等问…...

AI意识与认知操控:技术伦理、风险与治理框架
1. 项目概述:当“意识”成为可编程对象最近几年,我身边不少从事AI研发的朋友,聊天时的话题已经从“模型精度又提升了几个点”逐渐转向了一些更“虚”但更根本的问题。比如,我们训练的大语言模型,在和我们进行几轮深度对…...

IJPay实战:一站式解决微信APP支付签名与回调难题
1. 为什么选择IJPay解决微信APP支付难题 第一次接触微信APP支付时,我被官方文档里密密麻麻的参数列表吓到了。特别是签名验证环节,光是参数顺序错误就让我调试了整整两天。后来发现团队里老张的项目接支付接口特别快,追问之下才知道用了IJPay…...

泰拉瑞亚地图编辑器TEdit:5步打造专业级游戏世界的终极指南
泰拉瑞亚地图编辑器TEdit:5步打造专业级游戏世界的终极指南 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets y…...

大模型上下文长度对Agent的影响:从4K到1M的质变
目录大模型上下文长度对Agent的影响:从4K到1M的质变引言:工作台革命一、上下文窗口演进史:从4K到1M的百倍跃迁1.1 时间线上的技术里程碑1.2 为什么2025年成为“百万Token元年”?二、长上下文的质变:Agent能力的三重跃迁…...

MegaParse:一站式文档解析库的设计原理与工程实践
1. 项目概述:从“MegaParse”看文档解析的“大”与“全”在信息爆炸的时代,我们每天都要处理海量的文档——PDF报告、Word合同、Excel表格、PPT演示稿,甚至网页截图和扫描件。对于开发者、数据分析师和知识管理从业者来说,如何将这…...