大数据Hadoop生态圈
存储: HDFS(namenode,datanode)
计算:MapReduce(map+reduce,基于磁盘)
便于用sql操作:Hive(核心 metastore,存储这些结构化的数据),同类的还有Impala,hbase等
基于yaml的资源调度
hive :通过 HQL访问,适合执行ETL,报表查询,数据分析等数据仓库任务
支持运行在不同的计算框架,包括MapReduce,Spark,Tez等
支持java数据库连接(JDBC),可以建立与ETL,BI工具的通道
避免编写复杂的mapreduce,减少学习成本
可以直接使用存储在hadoop文件系统中的数据
将元数据保存在关系数据库中,大大减少查询过程中执行语义检查的时间
数据仓库:
(英文Data Warehouse 简称数仓,DW)是一个用于存储,分析,报告的数据系统,目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持
定义:
1 数据仓库并不“生产”任何数据,其数据来源不同的外部系统
2 数据仓库不需要“消费”任何的数据,其结果开放给各个外部应用使用
3 这也是为什么叫“仓库”,而不是“工厂”的原因
............................
参考视频:
hdfs:
核心概念:
分布式存储(存储在多个机器上)
元数据(记录存储的位置,权限等,便于查找,由NameNode管理):
两种类型:
1 文件自身属性信息: 文件名称,权限,修改世界,文件大小,复制因子,数据块大小
2 文件块位置映射信息: 记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上
文件分块存储(一个文件特别大/剩余空间不够):默认一个块128M,不足的本身就是一块(hdfs-default.xml:dfs.blocksize)
副本机制(应对硬件故障): dfs.replication默认是3,也就是本身是一份,额外再复制2份。
抽象统一的目录树结构(namespace[命名空间],由nameNode管理,对任何系统文件名称空间或属性的修改都会被记录下来)
NameNode(记录元数据,统领dataNode)/DataNode
主从架构:
1 hdfs集群是标准的master/slave主从架构集群
2 一般一个hdfs是有一个NameNode和一定数目的DataNode组成
3 NameNode 是HDFS主节点,DataNode是HDFS的从节点,两种角色各司其职,共同协调完成分部署的文件存储服务
4 官方架构图是一主五从模式,其中五个从角色位于两个机架(Rack)的不同服务器上
hdfs的shell命令
格式: hadoop fs [generic options]
hadoop发展到现在,除了支持hdfs(hdfs://nn:8020),还支持谷歌(gfs://ip:port/),阿里云,linux,本地文件系统(file:///)等文件系统 —— 具体操作什么取决于命令中文件路径URL中的前缀协议,如果没有指定,则读取core-site.xml:fs.defaultFS属性
hadoop fs -ls hdfs://node1:8020/
hadoop fs -mkdir [-p] <path>
hadoop fs -ls [-h人性化显示] [-R递归查看目录和子目录] [<path>...]
hadoop fs -put [-f覆盖目录文件(已存在)] [-p保留访问和修改时间,所有权和权限] 文件 <path>
hadoop fs -cat :对于大文件读取,慎重
hadoop fs -get [-f] [-p]
完整的: hadoop fs -get hdfs://node1:8020/chino/2.txt file:///root/test/
简化: hadoop fs -get /chino/2.txt /root/test/(./)
hadoop fs -cp [-f覆盖]
hadoop fs -appendToFile :追加数据到文件中
hadoop fs -appendToFile 2.txt 3.txt/1.txt [2.txt,3.txt追加到1.txt末尾,1.txt要在namespace里]
hadoop fs -mv :移动
hdfs的角色和职责:
NameNode:
1 是HDFS的核心,架构中的主角色
2 namenode成为访问hdfs的唯一入口
3 维护和管理文件系统元数据,包括命名空间目录树结构、文件和块的位置信息、访问权限等信息
4 内部通过内存和磁盘文件两种方式管理元数据
磁盘上的元数据文件包括:Fsimage内存元数据镜像文件 和 edits log(Journal)编辑日志
职责:
1 NameNode仅存储HDFS的元数据: 文件系统中所有文件的目录树,并跟踪整个集群中的文件,不存储实际数据
2 NameNode知道HDFS中任何给定文件的块列表及其位置,使用此信息NameNode知道如果从块中构建文件
3 NameNode不持久化存储每个文件中各个块所在的datanode的位置,这些信息会在系统启动时从DataNode重构
4 NameNode是Hadoop集群中的单点故障
5 NameNode所在机器通常会配置有大量内存(RAM)
DataNode:
1 是HDFS的从角色,负责具体的数据库存储
2 DataNode的数量决定了HDFS集群的整体数据存储能力,通过和NameNode配合维护数据块
职责:
1 DataNode负责最终数据块block的存储,是集群中的从角色,也成为Slave
2 DataNode启动时,会将自己注册到NameNode并汇报自己负责持有的快信息
3 当某个DataNode关闭时,不会影响数据的可用性,NameNode将安排由其他DataNode管理的块进行副本复制
4 DataNode所在机器通常配置有大量的硬盘空间,因为实际数据存储在DataNode中
SecondaryNameNode:
1 Secondary NameNode 充当NameNode的辅助节点,但不能替代NameNode
2 主要是帮助主角色进行元数据文件的合并动作,可以通俗理解为主角色的“秘书”
核心概念:
PipeLine :管道,这是HDFS在上传文件写数据过程中采用的一种数据传输方式。
流程:客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点
Q/A
问:为什么datanode之间采用pipeline线性传输,而不是一次给三个datanode拓扑式传输?
答:因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的宽带,避免网络瓶颈和高延迟时的连接,最小化推送所有数据的延时
ACK应答响应(两两之间的校验,三条数据三次响应)
ACK即时确认字符,在数据通信中,接收方给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。
在HDFS pipeline管道传输数据的过程中,传输的反方向会进行ACK校验,确保数据传输安全
默认三副本存储策略
默认副本存储策略是由BlockPlacementPolicyDefault指定
1 第一块副本:优先客户端本地,否则随机
2 第二块副本:不同于第一块副本的不同机架
3 第三块副本:第二块副本相同机架不同机器
写数据流程梳理
1 HDFS客户端创建对象实例DistributedFileSystem,该对象中封装了与HDFS文件系统操作的相关方法
2 调用DistributedFileSystem对象的create()方法,通过RPC请求与NameNode创建文件
NameNode 执行各种检查判断: 目标文件是否存在,客户端是否具有创建该文件的权限等,检查通过,NameNode就会为本次请求记下一条记录,返回FSDataOutputStream输出流对象给客户端用于写数据
3 客户端通过FSDataOutputStream输入流开始写数据(HDFS的输出流,相对客户端是输入流)
4 客户端写数据时,将数据分成一个个数据包(packet 默认64k),内部组件DataStreamer请求NameNode挑选出适合存储数据副本的一组DataNode地址,默认是3副本存储
DataStreamer将数据包流式传输到pipeline的第一个DataNode,该DataNode存储数据包并将它发送到pipeline的第二个DataNode。同样第二个DataNode存储数据包并且发送给第三个DataNode
5 传输的反方向上,会通过ACK机制校验数据包传输是否成功
6 客户端数据写入后,在FSDataOutputSteam输出流上调用colse()方法关闭
7 DistributedFileSystem联系NameNode告知其文件写入完成,等待NameNode确认
因为namenode已经知道文件由那些块组成(DataStream请求分配数据块),因此仅需等待最小复制块即可成功返回。
最小复制是由参数dfs.namenode.replication.min指定,默认是1
MapReduce和Yarn
MapReduce : 分而治之思想,设计构思,官方示例,执行流程(现在退居二线)
Yarn: 介绍,架构组件,程序提交交互流程、调度器(分布式通用的资源管理系统,保证了hadoop屹立不倒)
MapReduce:
分布式计算概念:
1 分布式计算是一种计算方法,和集中式计算是相对的
2 分布式计算将一个应用分解成许多小的部分,分配给多台计算机进行计算。这样可以节约整体计算时间,大大提高计算效率
MR是一个分布式计算框架,是一种面向海量数据处理的一种指导思想,也是一种对于大规模数据进行分布式计算的编程模型
特点:(比Spark等,非常稳定)
1 易于编程
2 良好的扩展性
3 高容错性
4 适合海量数据的离线处理
局限性:
1 实时计算性能差: 主要用于离线作业,无法做到秒级或亚秒级的数据响应
2 不能进行流式计算:
流式计算式数据式源源不断地计算,数据是动态地,而MR作为一个离线计算框架,主要针对静态数据集,数据是不能动态变化
MR地实例进程:
1个完整的MR程序在分布式运行时有三类:
1 MRAppMaster : 负责整个MR程序地过程调度以及状态协调(只有一个)
2 MapTask : 负责map阶段的整个数据处理流程
3 ReduceTask : 负责reduce阶段的整个数据处理流程
阶段组成:
一个MR编程模型中只能包含一个Map阶段和一个Reduce阶段,或者只有Map阶段
eg:map->map->map->redce :不行
eg: map ->reduce->map->reduce->map->reduce:可以
数据类型:
注意: 整个MR程序中,数据都以kv键值对的形式流转的
在实际编程解决各种业务问题中,需要考虑每个阶段的输入输出kv分别是什么
MR内置了很多默认属性,比如排序,分组等,都和数据的k有关,所以kv的类型数据确定及其重要
WordCount编程实现思路:
1 map阶段的核心:把输入的数据经过切割,全部标记1,因此输出就是<单词,1>
2 shuffle阶段核心:经过MR程序内部自带的排序分组等功能,把key相同的单词作为一组构成新的kv对
3 reduce阶段核心:处理shuffle完的一组数据,该组数据就是该单词所有的键值对。对所有的1进行累加求和,就是单词的总次数
hive的安装配置:
- JDK安装:hadoop是用java编写,需要安装jdk
- Hadoop安装: hive 借助hadoop实现计算和大数据存储
- Mysql安装:hive允许将元数据存储于本地远程的外部数据库中,这种设置可以支持hive的多会话生产环境,一般将mysql作为hive的元数据存储仓库(meta store ,存储哪些表,表明,类型,拥有者,列分区字段,表数据所在目录等)
Hive的安装及配置详解(含图文)_hive配置文件-CSDN博客
相关文章:

大数据Hadoop生态圈
存储: HDFS(namenode,datanode) 计算:MapReduce(mapreduce,基于磁盘) 便于用sql操作:Hive(核心 metastore,存储这些结构化的数据),同类的还有Impala,hbase等 基于yaml的资源调度 hive &…...

算法简介:查找与算法运行时间
文章目录 1. 二分查找与简单查找1.1 运行时间 2. 旅行商问题 算法是一组完成任务的指令。任何代码片段都可以视为算法。 1. 二分查找与简单查找 二分查找是一种算法,其输入是一个有序的元素列表,如果要查找的元素包含在列表中,二分查找返回…...

零基础C++开发上位机--基于QT5.15的串口助手(三)
本系列教程本着实践的目的,争取每一节课都带大家做一个小项目,让大家多实践多试验,这样才能知道自己学会与否。 接下来我们这节课,主要学习一下QT的串口编程。做一款自己的串口助手,那么这里默认大家都是具备串口通信…...

Facebook的虚拟社交愿景:元宇宙时代的新起点
在当今数字化时代,社交媒体已经成为人们生活中不可或缺的一部分。而随着科技的不断进步和社会的发展,元宇宙已经成为了人们关注的热点话题之一。作为社交媒体的领军企业之一,Facebook也在积极探索虚拟社交的未来,将其视为元宇宙时…...

【深度学习笔记】4_6 模型的GPU计算
注:本文为《动手学深度学习》开源内容,部分标注了个人理解,仅为个人学习记录,无抄袭搬运意图 4.6 GPU计算 到目前为止,我们一直在使用CPU计算。对复杂的神经网络和大规模的数据来说,使用CPU来计算可能不够…...

留学申请过程中如何合理使用AI?大学招生官怎么看?
我们采访过的学生表示,他们在写essay的过程中会使用 ChatGPT,主要用于以下两个方面:第一,生成想法和头脑风暴;第二,拼写和语法检查。 纽约时报的娜塔莎辛格(Natasha Singer)在一篇文…...

vue2与vue3的diff算法有什么区别
在 Vue 中,虚拟 DOM 是一种重要的概念,它通过将真实的 DOM 操作转化为对虚拟 DOM 的操作,从而提高应用的性能。Vue 框架在虚拟 DOM 的更新过程中采用了 Diff 算法,用于比较新旧虚拟节点树,找出需要更新的部分ÿ…...
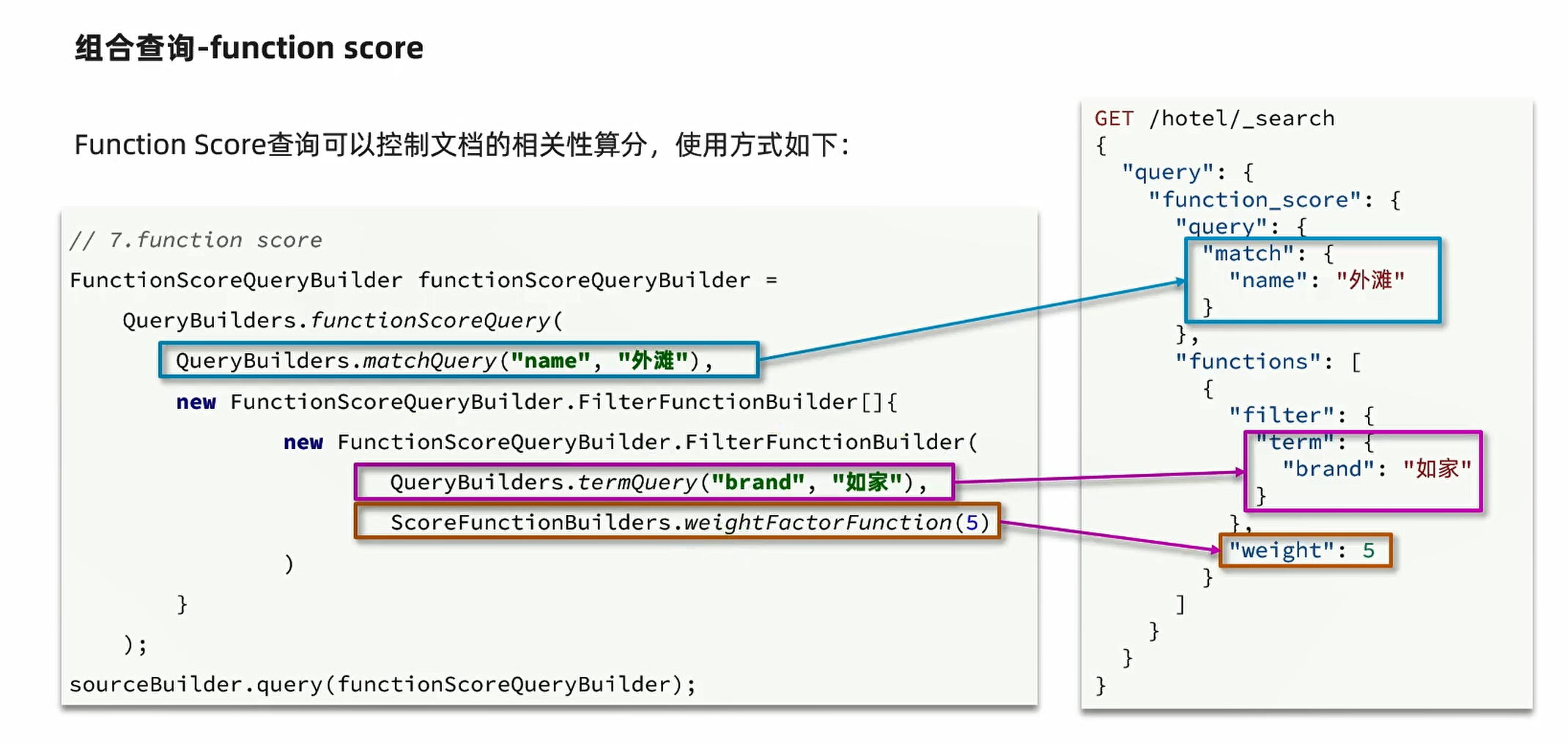
ES小总结
组合查询 FunctionScoreQueryBuilder functionScoreQuery QueryBuilders.functionScoreQuery(boolQuery,new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.termQuery("isAD",true),Score…...

vue2与vue3中父子组件传参的区别
本次主要针对vue中父子组件传参所进行讲解 一、vue2和vue3父传子区别 1.vue2的父传子 1).在父组件子标签中自定义一个属性 <sonPage :子组件接收到的类名"传输的数据">子组件</sonPage> 2).在子组件中peops属性中拿到自定属性 props: {子组件接收的…...

使用vuetify实现全局v-alert消息通知
前排提示,本文为引流文,文章内容不全,更多信息前往:oldmoon.top 查看 简介 使用强大的Vuetify开发前端页面,结果发现官方没有提供简便的全局消息通知组件(像Element中的ElMessage那样)…...

CentOS 7.9上编译wireshark 3.6
工作环境是Centos 7.9,原本是通过flathub安装的wireshark,但是在gnome的application installer上升级到wireshark 4.2.3之后就运行不起来了,flatpak run org.wireshark.Wireshark启动提示缺少qt6,查了一下wireshark新版是依赖qt6的…...

初学学习408之数据结构--数据结构基本概念
初学学习408之数据结构我们先来了解一下数据结构的基本概念。 数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。 本内容来源于参考书籍《大话数据结构》与《王道数据结构》。除去书籍中的内容,作为初学者的我会尽力详细直白地介绍数据结构的…...

Java项目中必须使用本地缓存的几种情况
Java项目中必须使用本地缓存的几种情况 在Java项目的开发过程中,为了提高应用的性能和响应速度,缓存机制经常被使用。其中,本地缓存作为一种常见的缓存方式,将数据存储在应用程序的本地内存或磁盘中,以便快速访问。下…...
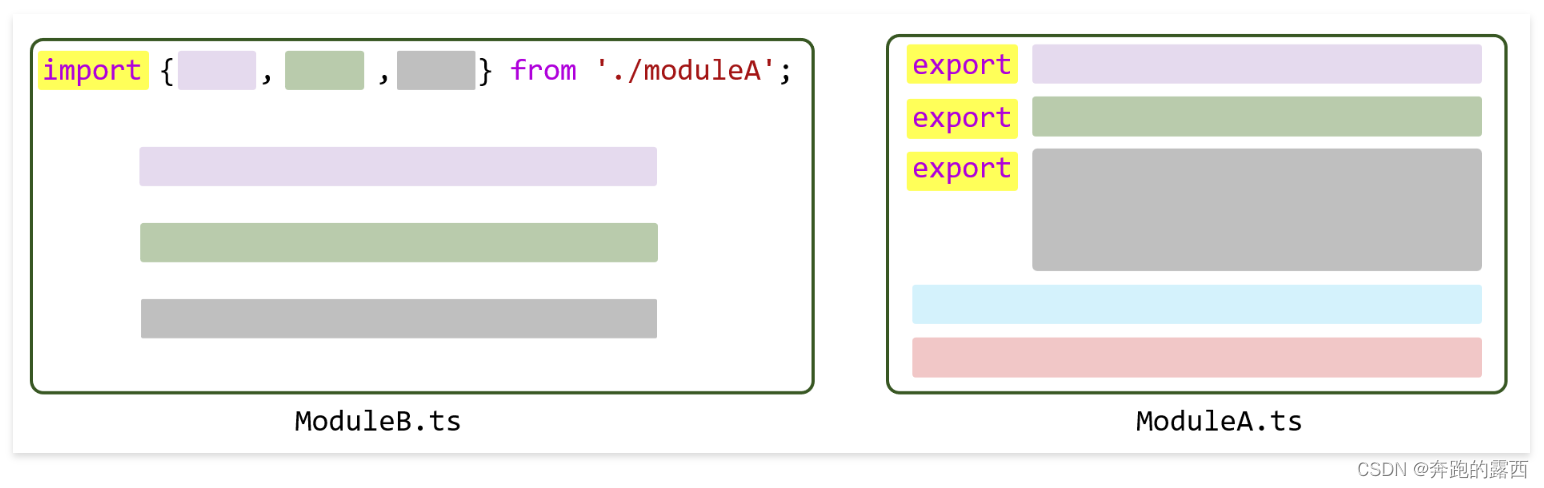
【鸿蒙 HarmonyOS 4.0】TypeScript开发语言
一、背景 HarmonyOS 应用的主要开发语言是 ArkTS,它由 TypeScript(简称TS)扩展而来,在继承TypeScript语法的基础上进行了一系列优化,使开发者能够以更简洁、更自然的方式开发应用。值得注意的是,TypeScrip…...
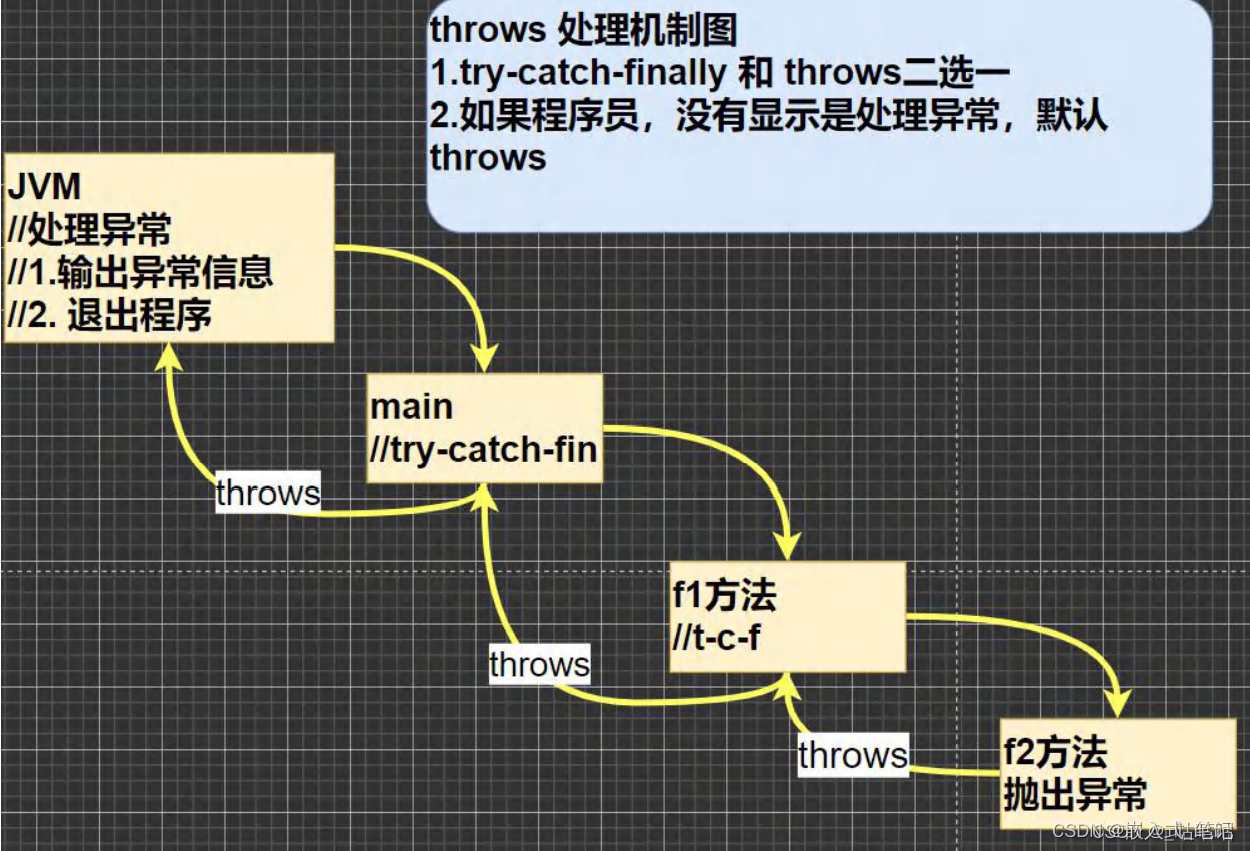
Android java基础_异常
一.异常的概念 在Java中,异常(Exception)是指程序执行过程中可能出现的不正常情况或错误。它是一个事件,它会干扰程序的正常执行流程,并可能导致程序出现错误或崩溃。 异常在Java中是以对象的形式表示的,…...
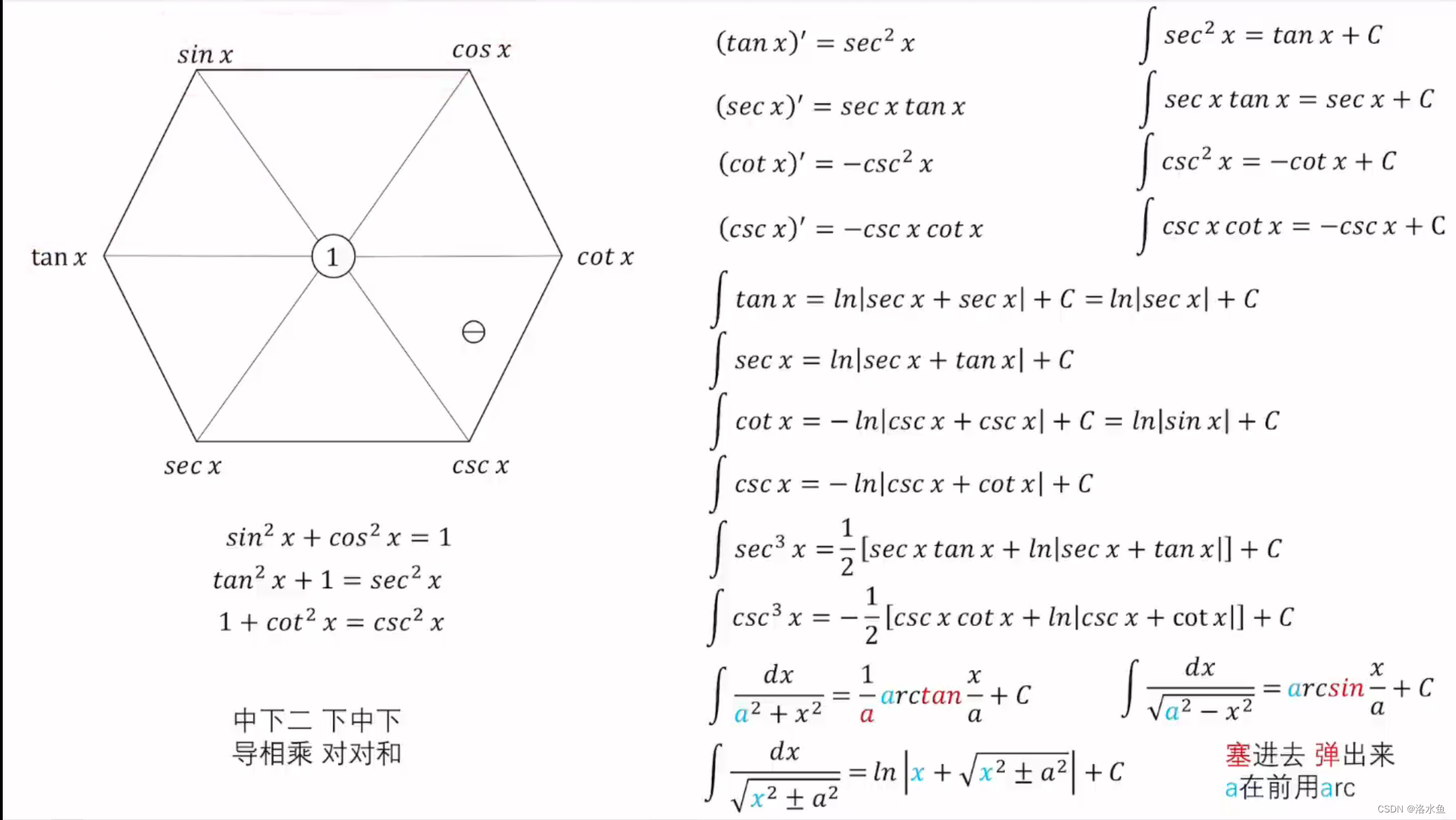
高数考研 -- 公式总结(更新中)
1. 两个重要极限 (1) lim x → 0 sin x x 1 \lim _{x \rightarrow 0} \frac{\sin x}{x}1 limx→0xsinx1, 推广形式 lim f ( x ) → 0 sin f ( x ) f ( x ) 1 \lim _{f(x) \rightarrow 0} \frac{\sin f(x)}{f(x)}1 limf(x)→0f(x)sinf(x)1. (2) lim …...

详解顺序结构滑动窗口处理算法
🎀个人主页: https://zhangxiaoshu.blog.csdn.net 📢欢迎大家:关注🔍点赞👍评论📝收藏⭐️,如有错误敬请指正! 💕未来很长,值得我们全力奔赴更美好的生活&…...

Java 8中使用Stream来操作集合
Java 8中使用Stream来操作集合 在Java 8中,你可以使用Stream API来操作集合,这使得集合的处理变得更加简洁和函数式。Stream API提供了一系列的中间操作(intermediate operations)和终端操作(terminal operations&…...

MATLAB环境下一种改进的瞬时频率(IF)估计方法
相对于频率成分单一、周期性强的平稳信号来说,具有非平稳、非周期、非可积特性的非平稳信号更普遍地存在于自然界中。调频信号作为非平稳信号的一种,由于其频率时变、距离分辨率高、截获率低等特性,被广泛应用于雷达、地震勘测等领域。调频信…...

解决:selenium web browser 的版本适配问题
文章目录 解决方案:使用 webdriver manager 自动适配驱动 使用 selenium 操控浏览器的时候报错: The chromedriver version (114.0.5735.90) detected in PATH at /opt/homebrew/bin/chromedriver might not be compatible with the detected chrome ve…...

【DeepSeek安全防护权威指南】:20年攻防专家亲授Prompt注入3大高危场景与7层防御体系
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Prompt注入防护的演进与现状 随着 DeepSeek 系列大模型在企业级场景中的深度部署,Prompt 注入攻击已从理论威胁演变为高频真实风险。早期防护策略依赖于简单的关键词过滤和长度截断…...

LeagueAkari游戏数据分析工具:从新手到高手的完整进阶攻略
LeagueAkari游戏数据分析工具:从新手到高手的完整进阶攻略 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾在英雄联盟游戏…...

第八部分-企业级实践——40. 容器成本优化
40. 容器成本优化 1. 成本优化概述 容器成本优化涉及资源利用率、云成本、存储成本、运维成本等多个维度。通过合理配置和优化策略,可以显著降低容器化环境的总体拥有成本(TCO)。 ┌────────────────────────────…...
)
用Arduino UNO和L298N驱动板,手把手教你让麦轮小车原地画个‘8’字(附完整代码)
用Arduino UNO和L298N驱动板实现麦轮小车8字轨迹编程实战 想让你的麦克纳姆轮小车跳出机械舞步吗?一个完美的"8"字轨迹不仅能展示麦轮的全向移动特性,更是检验运动控制算法的绝佳试金石。作为已经完成基础搭建的Arduino玩家,这个项…...
C8 edge impulse 快速入门+C9 数据提取+C10 运动数据的特征提取)
(B站TinyML教程学习笔记)C8 edge impulse 快速入门+C9 数据提取+C10 运动数据的特征提取
0:06 - 1:00 为什么使用 Edge Impulse 常见机器学习开发方式 传统机器学习通常会使用: TensorFlowScikit-learn 这些框架功能强大,但: 学习成本高需要写大量代码对嵌入式开发者不太友好 Edge Impulse 的作用 Edge Impulse 核心特点&am…...

从泰鼎高管离职事件看半导体公司治理与技术战略平衡
1. 事件背景与核心脉络梳理2011年初,半导体行业发生了一起在当时颇具话题性的高层人事地震。主角是当时在数字电视和多媒体处理器领域颇有建树的泰鼎微系统(Trident Microsystems, Inc.)。事件的核心是,公司的首席执行官ÿ…...

【PyTorch实战】从零构建CNN模型:MNIST手写数字识别全流程解析
1. 环境准备与数据加载 第一次接触PyTorch时,我对着官方文档折腾了半天环境配置。后来发现用Anaconda管理Python环境真是省心,这里分享我的配置经验。建议先安装Anaconda最新版,然后创建专属环境: conda create -n pytorch_env py…...

032随机链表的复制
随机链表的复制 题目链接:https://leetcode.cn/problems/copy-list-with-random-pointer/description/?envTypestudy-plan-v2&envIdtop-100-liked 我的解答: public Node copyRandomList(Node head) {Node dummy new Node(-1);Node curhead, newCu…...

React Native Expo样板项目:集成导航、状态管理与样式的最佳实践
1. 项目概述:一个为React Native开发者准备的“开箱即用”脚手架 如果你是一名React Native开发者,或者正打算踏入这个领域,那么你一定对项目启动初期那些繁琐的配置工作深有体会。从搭建开发环境、配置路由、集成状态管理,到设置…...

中文知识管理利器:本地化部署与向量检索实践指南
1. 项目概述:一个面向中文用户的知识管理利器 最近在折腾个人知识库,发现了一个挺有意思的开源项目,叫 RomeoSY/zh-knowledge-manager 。乍一看名字,你可能觉得这又是一个“知识管理”工具,市面上不是有 Notion、Ob…...