2024-02-23(Spark)
1.RDD的数据是过程数据
RDD之间进行相互迭代计算(Transaction的转换),当执行开启后,代表老RDD的消失
RDD的数据是过程数据,只在处理的过程中存在,一旦处理完成,就不见了。
这个特性可以最大化的利用资源,老旧的RDD没有用了,就从内存中清理,给后续的计算腾出内存空间。内存中只存在一个RDD
2.RDD的缓存
当然,Spark也有缓存技术,Spark提供了缓存API,可以让我们通过调用API,将指定的RDD数据保留在内存或者硬盘上。保留了RDD的血缘关系。
RDD的缓存技术是分散存储的,分区数据各自存储到Executor所在的服务器上。
(有时候一个前置RDD,会被多个后续RDD使用,所以需要持久化一下)
3.RDD的CheckPoint
CheckPoint也是将RDD的数据保存起来,但是它仅支持硬盘存储,但是它不保留血缘关系。
CheckPoint技术是将RDD各个分区的数据集中存储到HDFS上
(有时候一个前置RDD,会被多个后续RDD使用,所以需要持久化一下)
4.Jieba库用于中文分词
5.广播变量
使用场景:有时候一个Executor会处理多个分区数据,这些分区数据是接受相同的数据的,这个时候就不需要数据源一一给这些分区发一份分区数据了,只需要给这个Executor发一份数据就好,其所管辖的分区共享这份相同的数据。可以节约资源,降低IO,节约内存。
使用方式:使用boardcast()接口,将本地需要发送给分区的变量标记为广播变量就可以了
本地集合对象 和 分布式集合对象(RDD)进行关联的时候,需要将本地集合对象 封装为广播变量。可以节省网络IO的次数,Executor的内存占用
6.累加器
可以实现分布式的累加功能(将各个分区的值累加到一起)
Spark为我们提供了专门的累加器变量
7.小总结
广播变量解决了什么问题?
分布式集合RDD和本地集合进行关联使用的时候,降低内存占用以及减少网络IO的传输,提高性能。
累加器解决了什么问题?
分布式代码的执行过程中,进行全局累加。
---------------------------------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------------------Spark内核调度(重点理解)
8.DAG
DAG:有向无环图,有方向没有形成闭环的一个执行流程图(其实就是代码的一个执行流程图(RDD的转换。。。。RDD的执行)罢了,眼睛看着代码就能分析出来)
eg:

上图中,有三个DAG。
此外:上图也可以看出,一个程序Application,可能有多个Job(一条执行路线就是一个Job,可以理解为上图程序做了三件事(也可以说一个Action会产生一个Job(一个应用程序内的子任务)))
一个Application中,可以有多个JOB,每一个JOB内含一个DAG,同时每一个JOB都是由一个Action产生的。
带有分区关系的DAG图:其实就是在有向无环的DAG图中把分区关系画出来而已。
9.DAG的宽窄依赖和阶段划分
窄依赖:父RDD的一个分区,全部将数据发给子RDD的一个分区
宽依赖:父RDD的一个分区,将数据发给子RDD的多个分区。宽依赖的别名:shuffle
10.DAG的阶段划分
对于Spark来说,会根据DAG,按照宽依赖划分不同的DAG阶段
划分依据:从后向前,遇到宽依赖,就划分出一个阶段,称之为stage
在stage的内部,一定都是窄依赖。
例如下图的两个stage:
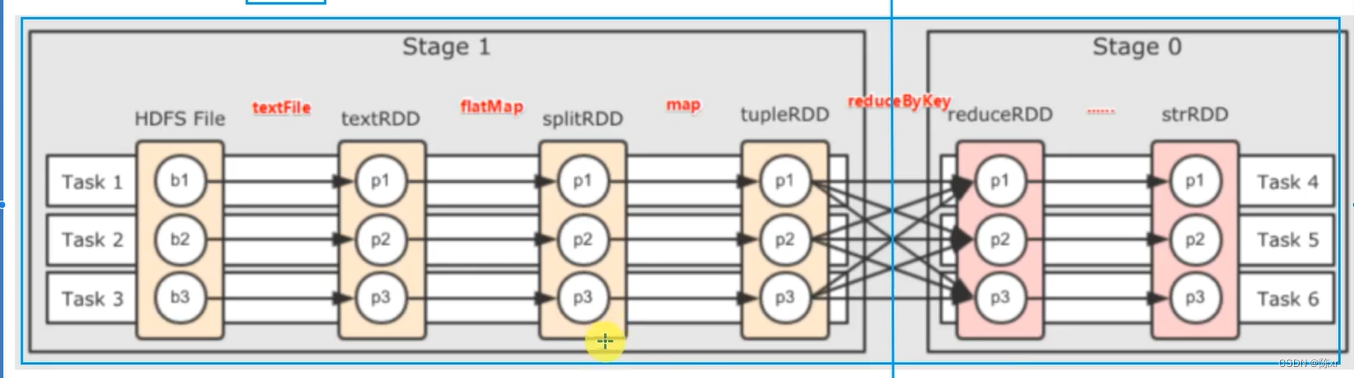
11.Spark是怎么做内存计算的?DAG的作用?Stage阶段划分的作用?
1.Spark会产生DAG图
2.DAG图会基于分区和宽窄依赖关系划分阶段
3.一个阶段内部都是窄依赖,窄依赖内,如果形成前后1:1的分区对应关系,就可以产生许多内存迭代计算的管道
4.这些内存迭代计算的管道,就是一个个具体的执行Task
5.一个Task是一个具体的线程,任务跑在一个线程内,就是走内存计算了。
12.Spark为什么比MapReduce快?
1.Spark的算子十分丰富,MapReduce算子匮乏(Map和Reduce),MapReduce这个编程模型,很难在一套MR任务中处理复杂的任务,很多复杂的任务,是需要写多个MapReduce进行串联,多个MR串联通过磁盘交互数据。
2.Spark可以执行内存迭代,算子之间形成DAG,基于依赖划分阶段之后,在阶段内形成内存迭代管道。但是MapReduce的Map和Reduce之间的交互依旧是通过硬盘来交互的。
综上总结:
a.编程模型上Spark占优(算子丰富)
b.算子交互上,和计算上可以尽量多的内存计算而非磁盘迭代
13.Spark的并行度
在同一时间内,有多少个Task在同时运行
推荐设置全局并行度,不要针对RDD改分区,这可能会影响内存迭代管道的构建,或者会产生额外的Shuffle。
确保是CPUh核心数量的整数倍,最小是2倍,最大一般10倍或者更高均可。
14.Spark的任务调度
Spark的任务,由Driver进行调度,这个工作包含:
a.逻辑DAG的产生
b.分区DAG的产生
c.Task划分
d.将Task分配给Executor并监控其工作
15.Driver内的两个组件
DAG调度器
工作内容:将逻辑的DAG图进行处理,最终得到逻辑上的Task划分
Task调度器
工作内容:基于DAG Schedule的产出,来规划这些逻辑的task,应该在哪些物理的executor上运行,以及监控它们的运行。
16.Spark中的名词概念汇总
Application/应用:用户代码提交到Spark去运行的时候,这就是一个应用。一个Application由一个Driver去控制它的运行。
Application jar:如果是Java语言编写的程序,可以打成一个Application jar的jar包。
Driver program:程序main方法的入口,也是程序的调度者和管理者,也负责构建SparkContext。
Cluster manager/集群管理器:一个外部服务,用于管理整个集群的资源,也就是Master角色的东西
Deploye mode/部署模式:一般用YARN模式(又分为客户端模式 和 集群模式)
Worder node/Worker角色:单台服务器的资源管理者,负责在单个机器内去提供Spark程序运行所需要的资源。
Executor/程序的运行启动器:内部可以分为许多Task,可以理解为真正干活的。
Task/一个工作线程:它是Executor内最小的一个工作单元,这个工作单元对整个Spark任务进行任务的干活。
Job/并行化的计算集合:Job归属于Application,一个Application可以有多个Job。
Stage/阶段:在Job内部基于DAG关系图可以划分出许多Stage(划分依据:宽依赖),每个stage内部都是窄依赖,又因为是窄依赖,便可以构建内存迭代的管道,然后去设定并行的Task。
层级关系梳理:
1.一个Spark环境可以运行多个Application
2.一个代码跑起来,会成为一个Application
3.Application内部可以有多个Job
4.每个Job由一个Action产生,并且每个Job有自己的DAG执行图
5.一个Job的DAG图,会基于宽窄依赖划分成不同的阶段。
6.不同的阶段内,会基于分区数量,形成多个并行的内存迭代管道
7.每一个内存迭代管道形成一个Task(DAG调度器划分将Job内划分具体的task任务,一个Job被划分出来的task在逻辑上称之为这个Job的taskset)
以上就是Spark程序的运行原理,重点理解。
相关文章:
2024-02-23(Spark)
1.RDD的数据是过程数据 RDD之间进行相互迭代计算(Transaction的转换),当执行开启后,代表老RDD的消失 RDD的数据是过程数据,只在处理的过程中存在,一旦处理完成,就不见了。 这个特性可以最大化…...

【JavaSE】实用类——枚举类型、包装类、数学类
目录 Java API枚举优势代码示例 包装类作用包装类和基本数据类型的对应关系包装类的构造方法包装类的常用方法装箱和拆箱 留一个问题大家猜猜看包装类的特点 Math类Random类代码示例 Java API Java API(Java Application Programming Interface) 即Java应用程序编程接口&#…...
: 全局对象)
Qt中常见的JS类和函数(二): 全局对象
相关系列文章 Qt中字符串转换为JS的函数执行 Qt中常见的JS类和函数(一): 全局对象 Qt中常见的JS类和函数(二): 全局对象 目录 2.3.构造函数属性 2.3.1.Object 2.3.2.Function 2.3.3.Array 2.3.4.ArrayBuffer 2.3.5.String 2.3.6.Boolean 2.3.7.Number 2.3.8.DataView …...

mysql 安装 与 使用
1.安装地址(社区免费版本) https://dev.mysql.com/downloads/mysql/ 2.查看端口 ****是否被占用(例子 3306端口) netstat -an | find "3306" 3.配置环境 系统变量名 变量名:MYSQL_HOME 变量值&#…...
)
2月26日做题总结(C/C++真题)
今天是2024年2月16日,新学期开学第一天。在大三这个重要阶段,我决定参加24年秋招。在准备项目的同时,也先做一些入门的笔试题吧,慢慢积累。如果你也是处于这个阶段,欢迎来找我交流讨论! 今天是做题第一天&a…...
创作纪念日:记录我的成长与收获
机缘 一开始是在我深入学习前端知识的Vue.js框架遇到了一个问题,怎么都解决不了,心烦意乱地来csdn上找解决方法。开心的是真被我找到了,真的很感恩,也意识到在这个平台上分享自己的经验是多么有意义的事情,可能随便的…...

全志H713/H618方案:调焦电机(相励磁法步进电机)的驱动原理、适配方法
一、篇头 全志H713平台,作为FHD投影的低成本入门方案,其公板上也配齐了许多投影使用的模组,本文即介绍投影仪调焦所用的步进电机,此模组的驱动原理、配制方法、调试方法。因为条件限制,本文采用的是H618香橙派Z3平台&…...

excel数据导入到数据库的方法
背景:最近在做和HW对接的某项目,需要将第三方接口提供的数据进行展示;在对方提供了详细的excel后,觉得也挺简单的就是将excel数据导入到数据库中。 方案一: 普通的初学者肯定会想,那我读取excel数据&…...
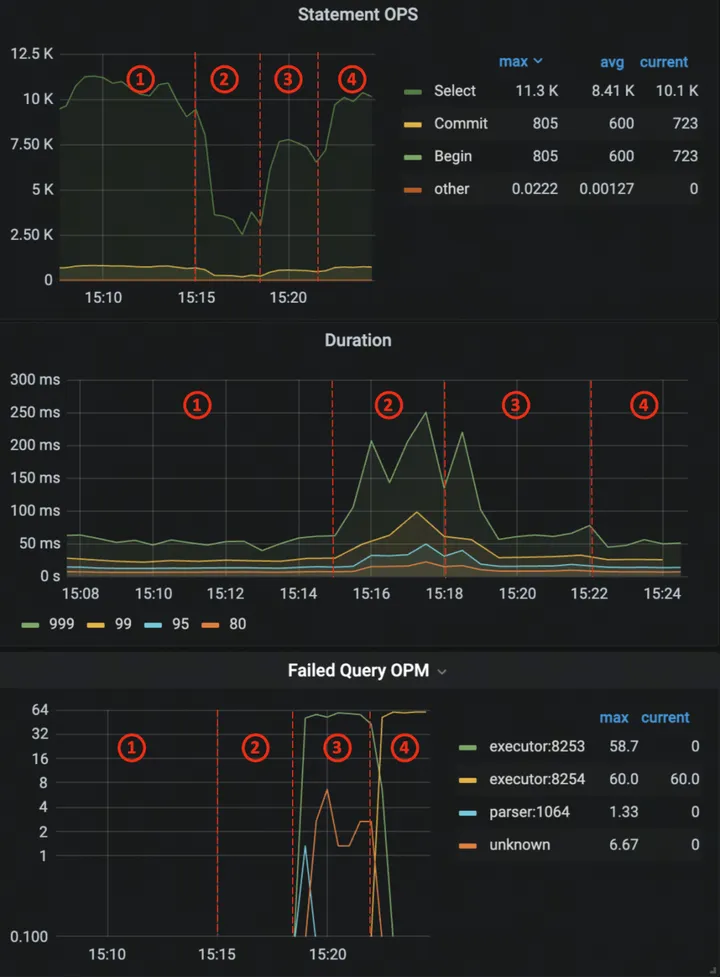
Runaway Queries 管理:提升 TiDB 稳定性的智能引擎
在数字化系统扮演重要角色的今天,数据库稳定性成为企业关注的核心问题。对于重要计算机系统而言,突发的性能下降可能对业务造成不可估量的损失。为了稳定数据库性能,用户可以从管理流程入手规范变更的测试,或者利用产品手段减少预…...

K8S部署Java项目(Gitlab CI/CD自动化部署终极版)
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...
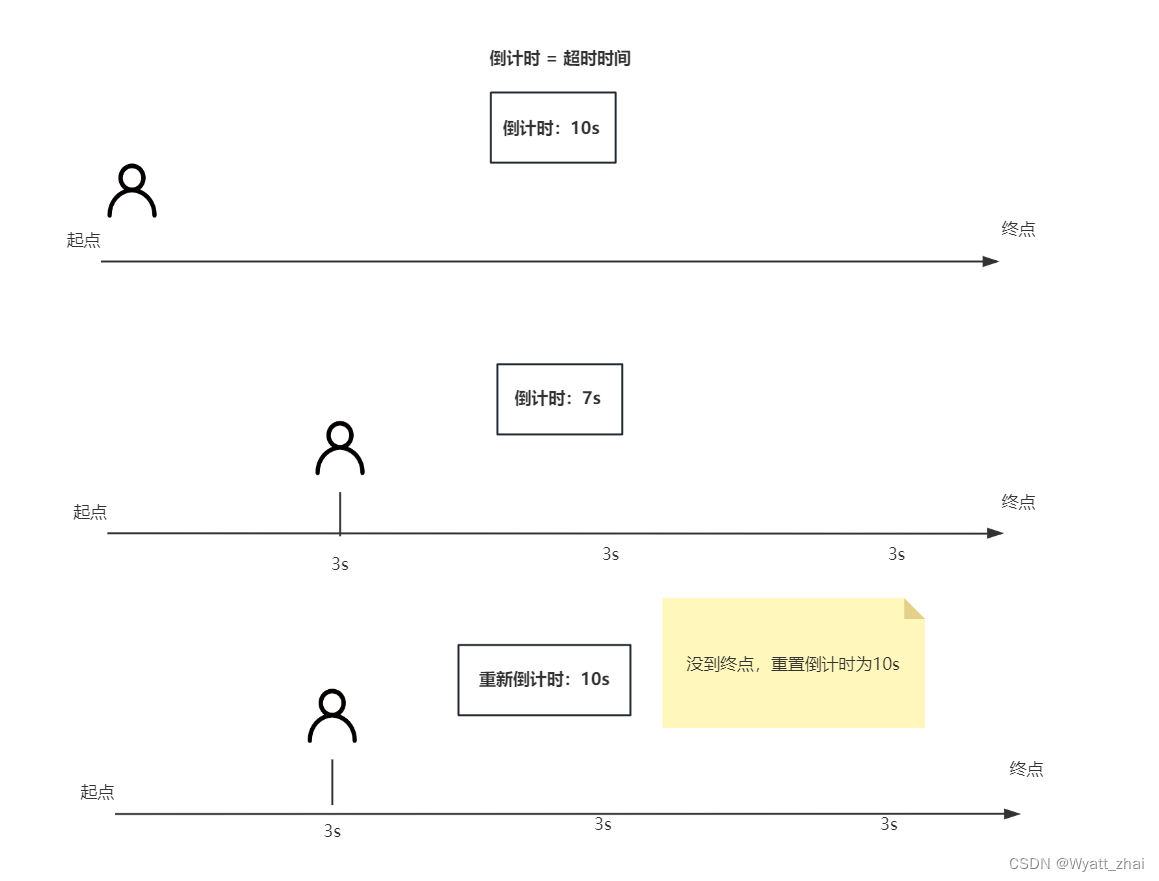
对Redis锁延期的一些讨论与思考
上一篇文章提到使用针对不同的业务场景如何合理使用Redis分布式锁,并引入了一个新的问题 若定义锁的过期时间是10s,此时A线程获取了锁然后执行业务代码,但是业务代码消耗时间花费了15s。这就会导致A线程还没有执行完业务代码,A线程…...

【高德地图】Android高德地图初始化定位并显示小蓝点
📖第3章 初始化定位并显示小蓝点 ✅第1步:配置AndroidManifest.xml✅第2步:设置定位蓝点✅第3步:初始化定位✅完整代码 ✅第1步:配置AndroidManifest.xml 在application标签下声明Service组件 <service android:n…...

继电器测试中需要注意的安全事项有哪些?
继电器广泛应用于电气控制系统中的开关元件,其主要功能是在输入信号的控制下实现输出电路的断开或闭合。在继电器测试过程中,为了确保测试的准确性和安全性,需要遵循一定的安全事项。以下是在进行继电器测试时需要注意的安全事项:…...

Java向ES库中插入数据报错:I/O reactor status: STOPPED
Java向ES库中插入数据报错:java.lang.IllegalStateException: Request cannot be executed; I/O reactor status: STO 一、问题问题原因 二、解决思路 一、问题 在使用Java向ES库中插入数据时,第一次成功插入,第二次出现以下错误:…...

vue3实现页面跳转
有需求是在vue项目中实现点击按钮完成页面跳转。这里不适用a标签,而是用vue自带的vue-router。 首先看一下项目结构 src │ App.vue │ main.js │ ├─router │ index.js │ └─views index.vue content.vue 可以看到&…...

【Linux运维系列】vim操作
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

Centos服务器部署前后端项目
目录 准备工作1. 准备传输软件2. 连接服务器 部署Mysql1.下载Mysql(Linux版本)2. 解压3. 修改配置4. 启动服务另一种方法Docker 部署后端1. 在项目根目录中创建Dockerfile文件写入2. 启动 部署前端1. 在项目根目录中创建Dockerfile文件写入2. 启动 准备工作 1. 准备传输软件 …...

【初始RabbitMQ】延迟队列的实现
延迟队列概念 延迟队列中的元素是希望在指定时间到了之后或之前取出和处理消息,并且队列内部是有序的。简单来说,延时队列就是用来存放需要在指定时间被处理的元素的队列 延迟队列使用场景 延迟队列经常使用的场景有以下几点: 订单在十分…...

spark为什么比mapreduce快?
spark为什么比mapreduce快? 首先澄清几个误区: 1:两者都是基于内存计算的,任何计算框架都肯定是基于内存的,所以网上说的spark是基于内存计算所以快,显然是错误的 2;DAG计算模型减少的是磁盘I/O次数&…...
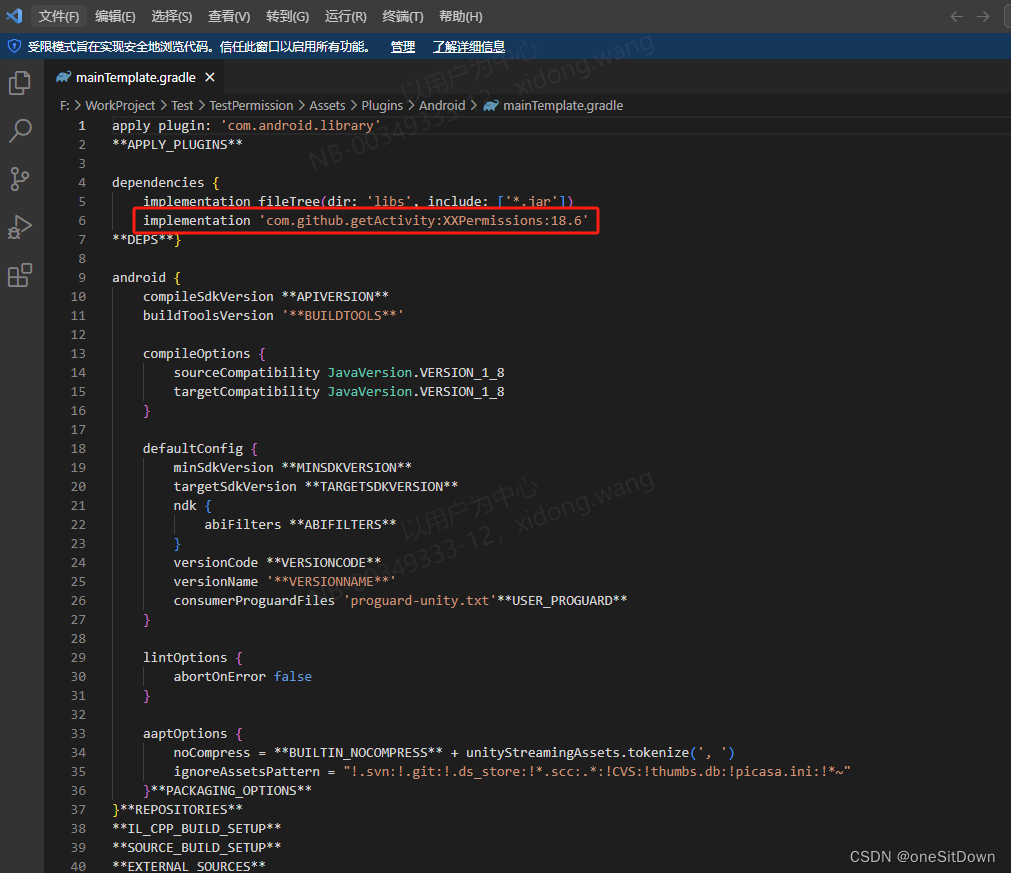
Unity通过XXpermission插件获取MANAGE_EXTERNAL_STORAGE权限
最近公司准备用Unity做一个安卓端的文件管理器功能,文件管理器已经做完了。刚开始的时候想要申请一下所有文件权限,发现在Unity里面申请所有文件权限(android.permission.MANAGE_EXTERNAL_STORAGE)相对来说比较麻烦。所以准备写一下文章记录一下如何申请…...

)
从梯形图到SCL:我的PLC栈功能重构笔记(附完整TIA Portal V17项目文件)
从梯形图到SCL:我的PLC栈功能重构笔记 第一次在TIA Portal V17中看到自己用SCL重写的栈功能模块时,那种感觉就像是从手工作坊走进了现代化工厂。作为在工业自动化领域摸爬滚打八年的工程师,我深知梯形图(LAD)就像老朋友…...

Java NIO 与异步 IO 对比
Java NIO与异步IO对比:高并发场景下的技术选型 在当今高并发的网络应用中,如何高效处理I/O操作成为开发者关注的核心问题。Java NIO(Non-blocking I/O)和异步IO(如AIO)是两种主流的解决方案,它…...

别再死记硬背了!用这5个真实UI案例,彻底搞懂HarmonyOS Flex布局的alignItems
别再死记硬背了!用这5个真实UI案例,彻底搞懂HarmonyOS Flex布局的alignItems 每次看到Flex布局的alignItems属性,你是不是也和我一样,对着文档里的Start、Center、End、Stretch、Baseline这几个选项发愁?明明每个单词都…...

3分钟掌握Unlock-Music:免费音乐解密工具的完整使用指南
3分钟掌握Unlock-Music:免费音乐解密工具的完整使用指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: htt…...
)
从‘Hello World’到‘Hello AI’:用ESP32和TensorFlow Lite做个会呼吸的灯(附完整代码)
从‘Hello World’到‘Hello AI’:用ESP32和TensorFlow Lite打造智能呼吸灯实战指南 1. 为什么嵌入式开发者需要尝试TinyML? 记得第一次点亮LED时的兴奋吗?那种"Hello World"级别的成就感,正是推动我们不断探索技术的原…...

几个知乎上的精彩回答
点击标题下「蓝色微信名」可快速关注技术社群的这篇文章《新来的同事满嘴高并发,但增删改查都还要技术指导,怎么办?》从知乎上节选了几个令人遐想的精彩回答,可能我们会碰到,可能我们有这种经历,重要的是能…...

1.6T 光模块的能效革命
合作核心与产品规格合作双方:光子技术提供商 Sivers Semiconductors 工程制造服务商 Jabil。核心产品:1.6T 线性接收光收发模块。关键技术:集成 Sivers 的高性能分布式反馈激光器。目标应用:下一代超大规模 AI 数据中心的光互连。…...

SteamCleaner终极指南:3步快速释放游戏缓存,轻松回收硬盘空间
SteamCleaner终极指南:3步快速释放游戏缓存,轻松回收硬盘空间 【免费下载链接】SteamCleaner :us: A PC utility for restoring disk space from various game clients like Origin, Steam, Uplay, Battle.net, GoG and Nexon :us: 项目地址: https://…...

实战指南:Parse12306 自动化获取全国高速列车数据的3大核心技术解析
实战指南:Parse12306 自动化获取全国高速列车数据的3大核心技术解析 【免费下载链接】Parse12306 分析12306 获取全国列车数据 项目地址: https://gitcode.com/gh_mirrors/pa/Parse12306 Parse12306作为一款高效的开源工具,为开发者和数据分析师提…...