Stable Diffusion中的Clip模型
基础介绍
Stable Diffusion 是一个文本到图像的生成模型,它能够根据用户输入的文本提示(prompt)生成相应的图像。在这个模型中,CLIP(Contrastive Language-Image Pre-training)模型扮演了一个关键的角色,尤其是在将文本输入转换为机器可以理解的形式方面。
CLIP 模型最初由 OpenAI 开发,它是一个多模态预训练模型,能够理解图像和文本之间的关系。CLIP 通过在大量的图像和文本对上进行训练,学习到了一种能够将文本描述和图像内容对齐的表示方法。这种表示方法使得 CLIP 能够理解文本描述的内容,并将其与图像内容进行匹配。
在 Stable Diffusion 中,CLIP 的文本编码器(Text Encoder)部分被用来将用户的文本输入转换为一系列的特征向量。这些特征向量捕捉了文本的语义信息,并且可以与图像信息相结合,以指导图像的生成过程。
贴一下模型结构:
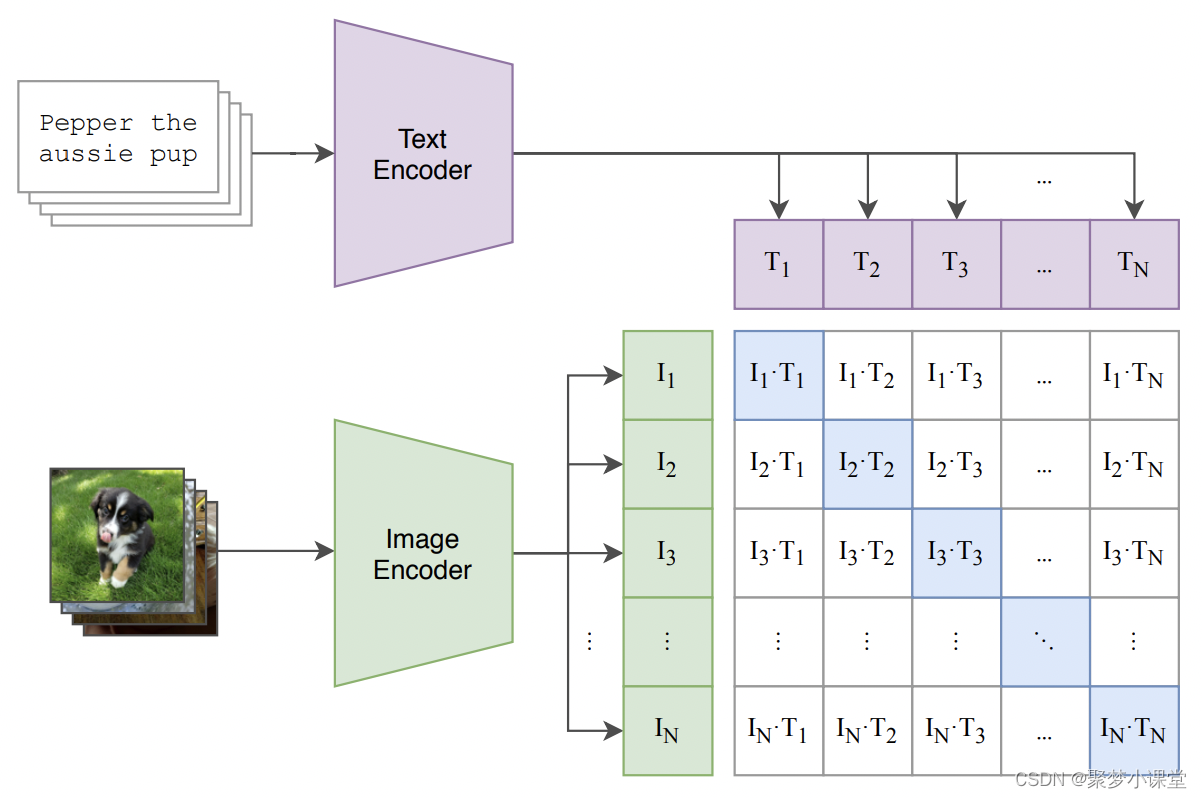
具体来说,当用户输入一个文本提示时,CLIP 的文本编码器会将这个文本转换成一个固定长度的向量序列。这个向量序列包含了文本的语义信息,并且与现实世界中的图像有相关性。在 Stable Diffusion 的图像生成过程中,这些文本特征向量与随机噪声图像一起被送入模型的后续部分,如图像信息创建器(Image Information Creator)和图像解码器(Image Decoder),以生成与文本描述相匹配的图像。
总结来说,CLIP 模型在 Stable Diffusion 中的作用是将文本输入转换为机器可以理解的数值特征,这些特征随后被用来指导图像的生成,确保生成的图像与文本描述相符合。这种结合了文本和图像理解能力的多模态方法,使得 Stable Diffusion 能够创造出丰富多样且与文本描述高度相关的图像。
关于特征向量的长度
在CLIP模型中,文本编码器输出的特征向量的长度是一致的。
CLIP模型的文本编码器通常是一个基于Transformer架构的神经网络,它将输入的文本(例如单词、短语或句子)转换成一系列固定长度的向量。这些向量被称为嵌入(embeddings),它们代表了文本在模型的内部表示空间中的位置。
在CLIP模型的训练过程中,这些嵌入向量的长度是预先设定的,并且在模型的所有训练和推理过程中保持不变。例如,如果CLIP模型被训练为输出768维的文本嵌入,那么无论输入的文本长度如何,每个文本输入都会被转换成一个长度为768的向量。
这种固定长度的向量表示允许模型处理不同长度的文本输入,同时保持模型的一致性和可扩展性。对于较长的文本,CLIP模型可能会采用截断或填充(padding)的方法来确保所有输入的长度一致。这样,无论文本的实际长度如何,模型都能够以统一的方式处理它们。
提示词长度是不是越长越好
在CLIP模型中,如果输入的文本提示(prompt)超过了模型处理的最大长度,可能会出现后半部分的文本不被编码或者不被充分考虑的情况。
CLIP模型在处理文本时,通常会有一个最大长度限制,这意味着它只能有效地处理一定长度内的文本。如果输入的文本超过了这个长度,模型可能会采取以下几种策略之一来处理:
-
截断(Truncation):模型会只考虑文本的前N个标记(tokens),忽略超出部分。这意味着超出长度限制的文本部分不会对最终的特征向量产生影响。
-
摘要(Summarization):模型可能会尝试生成一个文本的摘要,只保留关键信息,但这通常不是CLIP模型的直接功能。
-
滑动窗口(Sliding Window):模型可以采用滑动窗口的方法,对文本的不同部分分别编码,然后将这些局部编码组合起来。这种方法可以保留更多文本信息,但可能会丢失一些上下文信息。
在实际应用中,为了确保文本提示能够有效地影响图像生成的结果,通常会对输入的文本进行适当的编辑,使其长度适应模型的处理能力。
Clip模型是如何与unet模型结合使用的呢
CLIP(Contrastive Language-Image Pre-training)模型与UNet模型结合使用通常是为了在图像生成或图像处理任务中利用CLIP的文本理解能力和UNet的图像处理能力。这种结合可以在多种应用中实现,例如在Stable Diffusion等文本到图像的生成模型中。以下是CLIP与UNet结合使用的一种可能方式:
-
文本编码:首先,CLIP的文本编码器(Text Encoder)部分用于处理用户提供的文本提示(prompt)。它将文本转换为一系列的特征向量(text embeddings),这些向量捕捉了文本的语义信息。
-
图像编码:UNet结构通常用于图像的编码和解码。在图像生成任务中,UNet的编码器(Encoder)部分可以将输入的图像或噪声数据编码为一个隐含向量(latent vector),而解码器(Decoder)部分则可以从这个隐含向量重建图像。
-
结合文本和图像特征:在结合CLIP和UNet时,CLIP提取的文本特征可以与UNet处理的图像特征进行交互。例如,文本特征可以作为注意力机制的一部分,引导UNet在图像生成过程中关注与文本描述相关的图像区域。
-
迭代优化:在生成过程中,UNet可能会进行多次迭代,每次迭代都会根据CLIP提供的文本特征来优化图像。这可以通过交叉注意力(cross-attention)机制实现,其中文本特征作为注意力的键(key)和值(value),而UNet的特征作为查询(query)。
-
生成图像:通过这种结合,模型能够生成与文本提示语义上一致的图像。在迭代过程中,模型不断调整图像,直到生成的图像与文本描述相匹配。
clip skip是什么意思
Stable Diffusion的应用中,Clip Skip是一个参数,它用于控制图像生成过程中的细分程度。这个参数允许用户在生成图像时跳过CLIP模型中的一些层,从而影响生成图像的细节和风格。
具体来说,Clip Skip的作用包括:
-
控制生成速度:
Clip Skip的值越大,Stable Diffusion在生成图像时会跳过更多的层,这可以加快图像生成的速度。但是,这可能会牺牲图像的质量,因为跳过的层可能包含了对生成细节重要的信息。 -
调整图像质量:较低的
Clip Skip值意味着生成过程中会使用更多的层,这通常会导致更详细和精确的图像。相反,较高的Clip Skip值可能会导致图像质量下降,因为模型在生成过程中省略了一些细节。 -
灵活性和多样性:通过调整
Clip Skip的值,用户可以根据他们的需求和偏好来控制生成图像的风格和细节程度。这为用户提供了在速度和质量之间做出权衡的灵活性。
在实际应用中,用户可能需要通过实验来找到最佳的Clip Skip值,以便在保持所需图像质量的同时,实现合理的生成速度。例如,如果用户需要快速生成草图或概念图,可能会选择较高的Clip Skip值;而如果用户追求高质量的艺术作品,可能会选择较低的Clip Skip值。
这里是聚梦小课堂,如果对你有帮助的话,记得点个赞哦~
相关文章:
Stable Diffusion中的Clip模型
基础介绍 Stable Diffusion 是一个文本到图像的生成模型,它能够根据用户输入的文本提示(prompt)生成相应的图像。在这个模型中,CLIP(Contrastive Language-Image Pre-training)模型扮演了一个关键的角色&a…...

Python批量提取文件夹中图片的名称及路径到指定的.txt文件中
目录 一、代码二、提取效果 一、代码 import os# 定义要保存的文件名 file_name "TestImage/Image_Visible_Gray.txt"# 读取文件夹路径 folder_path "TestImage/Image_Visible_Gray"# 遍历文件夹中的所有文件 with open(file_name, "w") as f…...
微软开源 SBOM 生成工具:sbom-tool下载及使用详解
github地址 GitHub - microsoft/sbom-tool: The SBOM tool is a highly scalable and enterprise ready tool to create SPDX 2.2 compatible SBOMs for any variety of artifacts.The SBOM tool is a highly scalable and enterprise ready tool to create SPDX 2.2 compatib…...

【办公类-18-03】(Python)中班米罗可儿证书批量生成打印(班级、姓名)
作品展示——米罗可儿证书打印幼儿姓名 背景需求 2024年3月1日,中4班孩子一起整理美术操作材料《米罗可儿》的操作本——将每一页纸撕下来,分类摆放、确保纸张上下位置正确。每位孩子们都非常厉害,不仅完成了自己的一本,还将没有…...
)
js【详解】数据类型原理(含变量赋值详解-浅拷贝)
JavaScript 中的数据按存储方式的不同,分为值类型和引用类型。 值类型(共 6 种):赋值的时候传值 —— 数字、字符串、布尔值、null 、undefined,Symbol引用类型(仅 1 种):赋值的时候…...

SAM 影像分割——地理空间数据的分段模型的数据调参和自动分割分析
本笔记本展示了如何使用 Segment Anything Model (SAM) 从图像中分割对象,只需几行代码即可完成。 请确保在本笔记本中使用 GPU 运行时。对于 Google Colab,请转到运行时 -> 更改运行时类型,然后选择 GPU 作为硬件加速器。 地理空间数据的分段模型 Segment Anything M…...

Java底层自学大纲_设计模式篇
设计模式专题_自学大纲所属类别学习主题建议课时(h) A 深入理解设计模式001 SOLID设计原则和策略模式2.5 A 深入理解设计模式002 责任链模式2.5 A 深入理解设计模式003 工厂模式和模版方法模式2.5 A 深入理解设计模式004 装饰者模式2.5 A 深入理解设…...

详解字符串函数<string.h>(上)
1. strlen函数的使用和模拟实现 size_t strlen(const char* str); 1.1 函数功能以及用法 字符串长度 strlen函数的功能是计算字符串的长度。在使用时,要求用户传入需要计算长度的字符串的起始位置,并返回字符串的长度。 #include <stdio.h> #…...
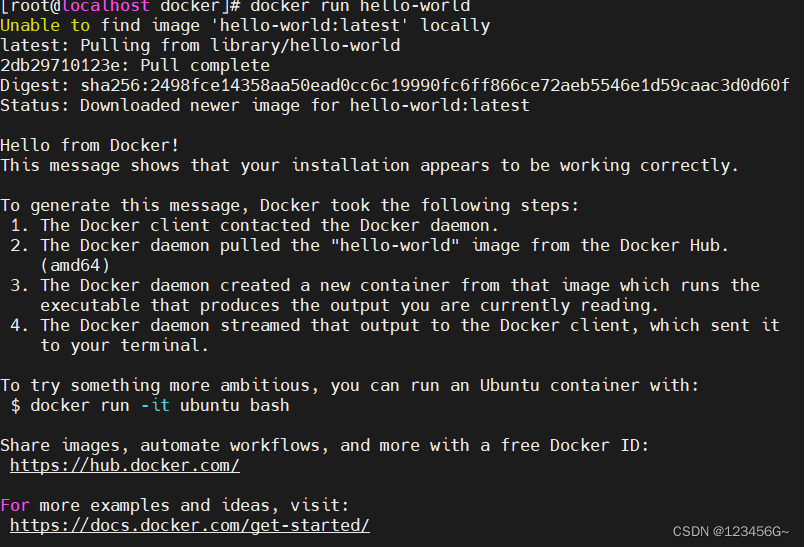
1、docker入门
文章目录 1、tocker简介2、tocker的安装&环境配置2、配置阿里云镜像3、基本命令1、镜像命令2、docker基本命令3、镜像基本命令4、Docker 容器常用命令 1、tocker简介 新一代的虚拟化技术 2、tocker的安装&环境配置 uname -r1、首先查看liunx的内核 yum update -y2、更…...

Qt应用软件【测试篇】cppchecker静态代码检查
文章目录 cppcheker简介下载地址与安装检查项目QT Creator使用CPP Cheker开启检查常见错误总结错误信息说明cppcheker简介 Cppcheck 是一个用于 C/C++ 代码的分析工具。它提供独特的代码分析以检测错误,并专注于检测未定义的行为和危险的编码结构。其目标是仅检测代码中的真实…...

[递推与递归]数的计算
题目描述 给出正整数 n,要求按如下方式构造数列: 只有一个数字 n 的数列是一个合法的数列。在一个合法的数列的末尾加入一个正整数,但是这个正整数不能超过该数列最后一项的一半,可以得到一个新的合法数列。 请你求出ÿ…...
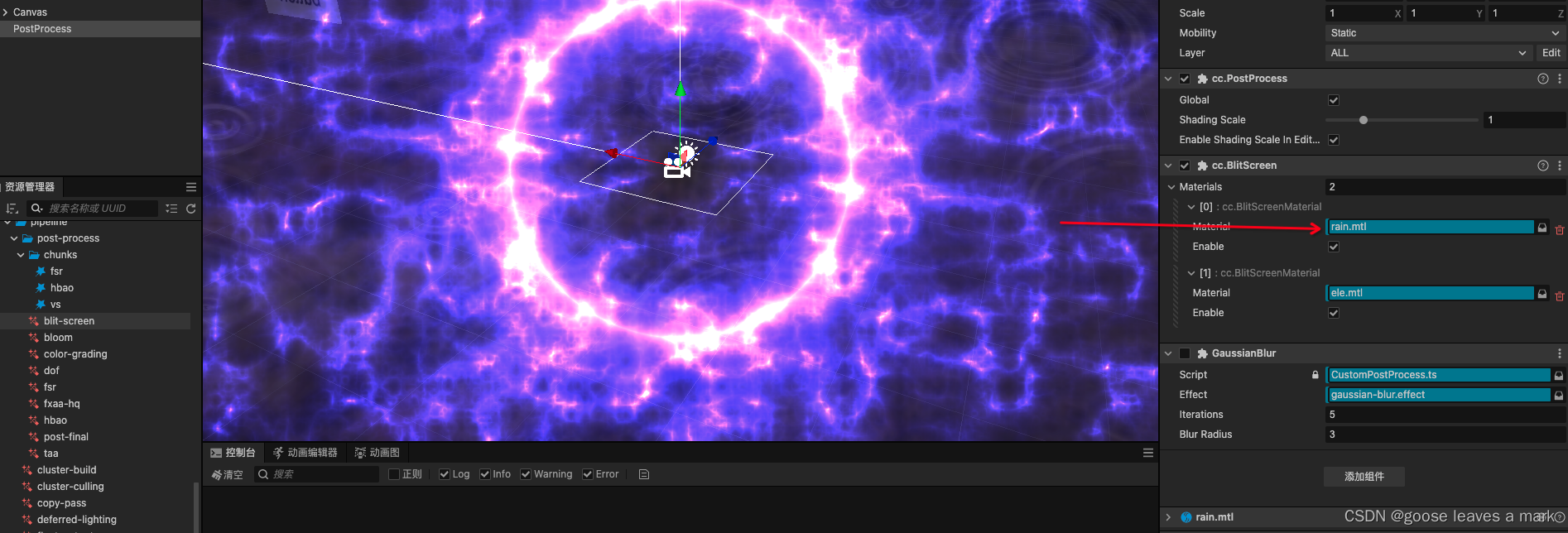
Cocos Creator 3.8.x 后效处理(前向渲染)
关于怎么开启后效效果我这里不再赘述,可以前往Cocos官方文档查看具体细节:后效处理官网 下面讲一下怎么自己定义一个后处理效果,想添加自己的后效处理的话只需要在postProcess节点下添加一个BlitScreen 组件即可,然后自己去添加自…...
【前端素材】推荐优质后台管理系统 Adminity平台模板(附源码)
一、需求分析 1、系统定义 后台管理系统是一种用于管理网站、应用程序或系统的管理界面,通常由管理员和工作人员使用。它提供了访问和控制网站或应用程序后台功能的工具和界面,使其能够管理用户、内容、数据和其他各种功能。 2、功能需求 后台管理系…...

身份证号与姓名实名认证接口-二要素实名认证-C++接口代码
翔云(https://www.netocr.com/idenNoOrd.html)身份证二要素实名认证接口在当今的数字化社会中扮演着至关重要的角色,它不仅守护着网络世界的秩序,也悄然影响着现实生活的点滴。看似普通的身份证号实名认证接口也在悄然守护着人们的…...
笑营宝高校选修课报名考勤系统源码开发方案
一、项目背景与目标 (一)项目背景 随着高等教育的普及和教学模式的不断创新,高校选修课程体系日趋复杂多变。学生对课程选择的自由度提高,使得传统的选课和考勤管理方式变得繁琐且效率低下。目前,许多高校仍然采用纸…...

类型字段定义影响WebApi传值及SqlSugar调用Select创建新对象
ASP.NET Core编写的WebApi,由于输入参数较多,专门定义了输入参数类并设置[FromBody]方式传值,但测试时始终无法通过postman将输入参数值传递给WebApi,condition对象的所有属性值一直都为空。同时在WebApi内部调用SqlSugar查询数据…...

golang 函数式编程库samber/mo使用: IO
golang 函数式编程库samber/mo使用: IO 如果您不了解samber/mo库, 请先阅读第一篇 Option 在函数式编程中,副作用和纯函数是最常见的概念。 IO用来封装IO这类副作用。 什么是副作用 副作用是在计算结果的过程中,改变了系统状态…...

在OceanBase使用中,如何优化因Join估算不准导致执行计划选错的问题
作者:胡呈清,爱可生公司旗下的DBA团队成员,擅长故障分析和性能优化。爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。本文约 1600 字,预计阅读需要 15 分钟。 数据库版本&…...
potplayer安装
官网 解压运行即可...

PostgreSQL 与MySQL 对比使用
一、前言 博主的系统既有 用到MySQL 也有用到PostgreSQL ,之所以用到这两种数据库,主要是现在都是国产替代,虽然说这两款数据库也不是国产的,但是相对开源,oracle是不让用了。所以现在使用比较多的就是这两个关系型数据…...

Flutter安全最佳实践:保护用户数据与应用安全的完整指南
Flutter安全最佳实践:保护用户数据与应用安全的完整指南 【免费下载链接】flta-materials The projects and the materials that accompany the Flutter Apprentice book 项目地址: https://gitcode.com/gh_mirrors/fl/flta-materials 在移动应用开发中&…...

HarmonyOS UI 开发中eventHub用标准化 OHMUrl 拿捏集成态 HSP
做鸿蒙模块化开发的兄弟,多半都领教过维护公共组件的痛苦。特别是当公司里有十几个业务团队,每个人都从你的基础 UI 库里复制粘贴代码时——恭喜你,正式步入了“依赖地狱”。 这时候,你就需要祭出大杀器:集成态 HSP (H…...

ESP-IDF组件依赖管理:如何高效使用Github和Component Registry
ESP-IDF组件依赖管理实战:双源协同与高效工作流设计 在物联网设备开发领域,ESP-IDF已经成为乐鑫芯片生态中最主流的开发框架。随着项目复杂度提升,如何优雅地管理第三方组件依赖成为每个开发者必须掌握的技能。本文将深入剖析Github与ESP Com…...

城通网盘直连解析工具终极指南:3大技术突破实现高速下载
城通网盘直连解析工具终极指南:3大技术突破实现高速下载 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否曾经面对城通网盘的龟速下载而束手无策?每次下载文件都要经历漫长…...
与路由灰度发布)
s2-pro部署实践:多版本s2-pro共存方案(v1.0/v1.2)与路由灰度发布
s2-pro部署实践:多版本s2-pro共存方案(v1.0/v1.2)与路由灰度发布 1. 项目背景与需求 s2-pro作为Fish Audio开源的专业级语音合成模型镜像,在文本转语音领域展现出强大的能力。随着项目迭代,团队同时维护v1.0稳定版和…...

迭代器管理化技术内部迭代器与外部迭代器
迭代器管理化技术:内部与外部迭代器的深度解析 在软件开发中,迭代器是遍历数据集合的重要工具,而迭代器管理化技术进一步优化了其使用方式。内部迭代器和外部迭代器是两种核心实现模式,前者由集合自身控制遍历逻辑,后…...

Oracle高效批量插入数据的四大实战方案解析
1. INSERT INTO SELECT:跨表搬运工的高效玩法 第一次接触Oracle批量插入时,我像发现新大陆一样兴奋——原来不需要写几百条INSERT语句也能搞定海量数据。INSERT INTO SELECT就是我的启蒙老师,它的工作原理就像搬家公司的集装箱卡车ÿ…...

PHP文本操作+文件夹遍历+递归文件夹操作
1、什么是文件操作?磁盘上用户能看到的逻辑数据结构(文件夹和文件)对文件的增删改查2、为什么要有文件操作? 当程序需要为某些特定操作进行文件夹或者文件处理的时候,都会应用到文件操作。 文件上传的时候创建目录&…...

如何免费将网易云音乐NCM格式转换为MP3/FLAC:ncmdumpGUI完整指南
如何免费将网易云音乐NCM格式转换为MP3/FLAC:ncmdumpGUI完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的NCM…...
实现倍频、定时器触发采样)
STM32高精度定时器(HRTIM1)实现倍频、定时器触发采样
STM32高精度定时器(HRTIM1):精准定时与同步触发的强大引擎在嵌入式系统开发中,尤其是在数字电源、电机控制、照明及各类高精度PWM应用领域,定时器的精度和灵活性往往成为系统性能的关键瓶颈。STM32系列微控制器内置的高…...