大数据分析案例-基于SVM支持向量机算法构建手机价格分类预测模型

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
喜欢大数据分析项目的小伙伴,希望可以多多支持该系列的其他文章
| 大数据分析案例-基于随机森林算法预测人类预期寿命 |
| 大数据分析案例-基于随机森林算法的商品评价情感分析 |
| 大数据分析案例-用RFM模型对客户价值分析(聚类) |
| 大数据分析案例-对电信客户流失分析预警预测 |
| 大数据分析案例-基于随机森林模型对北京房价进行预测 |
| 大数据分析案例-基于RFM模型对电商客户价值分析 |
| 大数据分析案例-基于逻辑回归算法构建垃圾邮件分类器模型 |
| 大数据分析案例-基于决策树算法构建员工离职预测模型 |
| 大数据分析案例-基于KNN算法对茅台股票进行预测 |
| 大数据分析案例-基于多元线性回归算法构建广告投放收益模型 |
| 大数据分析案例-基于随机森林算法构建返乡人群预测模型 |
| 大数据分析案例-基于决策树算法构建金融反欺诈分类模型 |
目录
1.项目背景
2.项目简介
2.1项目说明
2.2数据说明
2.3技术工具
3.算法原理
4.项目实施步骤
4.1理解数据
4.2数据预处理
4.3探索性数据分析
4.4特征工程
4.5模型构建
4.6模型预测
5.实验总结
源代码
1.项目背景
随着科技的飞速发展和人们对通讯需求的不断提高,手机已成为现代生活中不可或缺的电子产品。市场上手机品牌众多、型号繁杂,价格也参差不齐,从几百元到上万元不等。对于消费者而言,如何在众多手机中选择适合自己需求和预算的产品成为了一大挑战。
为了帮助消费者更好地进行手机购买决策,并为企业提供市场定价策略参考,本研究旨在构建一个基于SVM支持向量机算法的手机价格分类预测模型。通过该模型,我们希望能够准确地将手机产品根据其价格划分到不同的类别中,从而为消费者提供一个快速筛选符合预算范围的手机的方法,同时也为企业分析市场竞争格局和制定价格策略提供数据支持。
SVM作为一种强大的监督学习算法,在处理高维数据、解决非线性分类问题以及防止过拟合等方面具有显著优势。通过选择合适的核函数和调整相关参数,我们相信SVM算法能够在手机价格分类预测问题上取得良好的效果。
2.项目简介
2.1项目说明
本研究将利用SVM支持向量机算法构建手机价格分类预测模型,旨在为消费者提供便捷的购买决策支持,同时为企业市场分析和定价策略提供有价值的参考信息。
2.2数据说明
本数据集来源于Kaggle,数据集概述:手机特征的集合,包括电池电量、摄像头规格、网络支持、内存、屏幕尺寸和其他属性。“price_range”列将手机按价格范围进行分类,使该数据集适用于手机分类和价格预测任务。
2.3技术工具
Python版本:3.9
代码编辑器:jupyter notebook
3.算法原理
支持向量机(Support Vector Machine,简称SVM)是一种常用的监督学习算法,主要用于分类和回归分析。SVM的基本思想是在特征空间中寻找一个最优超平面,使得该超平面能够最大程度地分隔两个类别的样本,并且保证分类的准确性。
SVM算法的原理可以简要概括为以下几个步骤:
- 初始化:选择核函数和相关参数,如惩罚系数C、核函数参数等。核函数用于将原始特征空间映射到更高维的特征空间,以解决原始特征空间中的线性不可分问题。
- 构建最优超平面:在特征空间中,寻找一个最优超平面,使得两个类别的样本能够最大程度地分隔开。这个最优超平面可以通过最大化间隔(即支持向量到超平面的距离)来实现。
- 求解支持向量:在训练过程中,只有少数样本点会决定最优超平面的位置,这些样本点被称为支持向量。支持向量是离分隔超平面最近的点,它们对于分类结果具有决定性的影响。
- 决策函数:根据最优超平面和支持向量,构建决策函数。对于新的未知样本,可以将其特征向量代入决策函数中,根据函数值的正负来判断其所属的类别。
SVM算法具有许多优点,如分类效果好、鲁棒性强、适用于高维数据等。同时,SVM也存在一些不足之处,如对参数敏感、计算复杂度高、难以处理大规模数据等。在实际应用中,需要根据具体的问题和数据特点来选择合适的算法和参数。
4.项目实施步骤
4.1理解数据
导入第三方库并加载数据
查看数据大小
查看数据基本信息

查看描述性统计
4.2数据预处理
统计缺失值情况
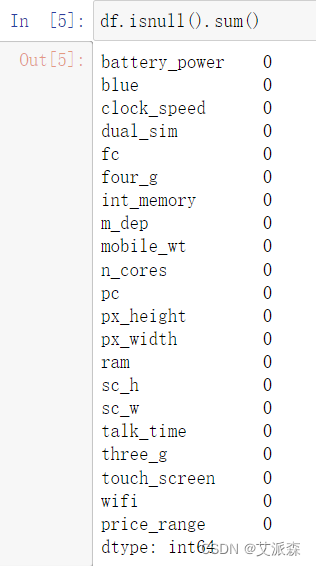
结果发现数据不存在缺失值
检测数据是否存在重复值
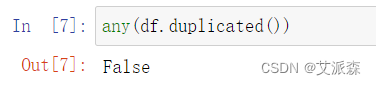
结果为False,说明不存在重复值
4.3探索性数据分析

4.4特征工程
选择特征变量和目标变量,拆分数据集为训练集和测试集,其中测试集比例为0.3

4.5模型构建
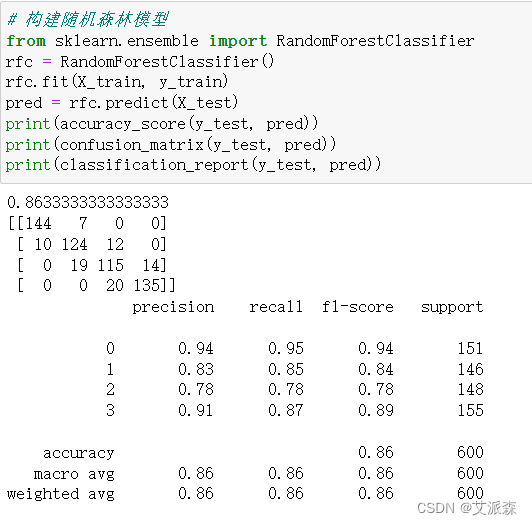
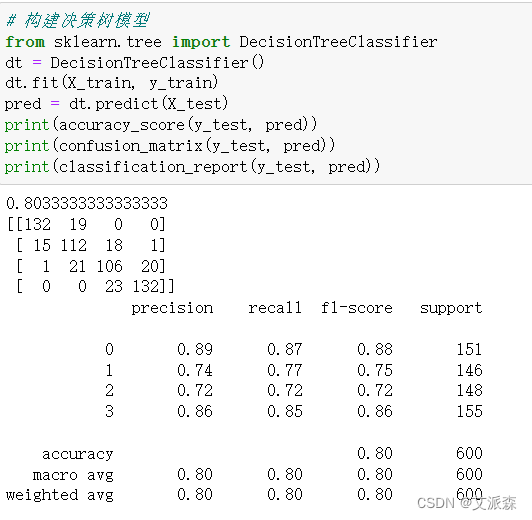
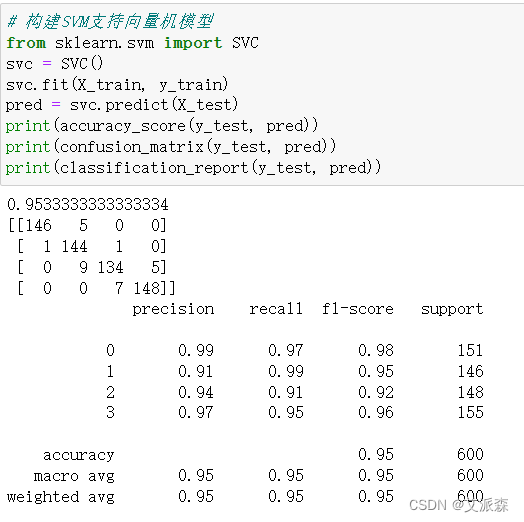
对比三个模型,可以发现SVM支持向量机的模型准确率最高,达到0.95,模型效果最好,故我们选择其作为最终模型。
4.6模型预测
随机抽取10中错了1个,模型效果还不错。
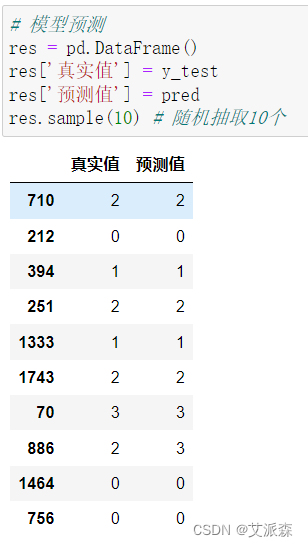
5.实验总结
- 模型有效性:使用SVM算法构建的手机价格分类预测模型是有效的。通过训练集的学习,模型能够较为准确地对手机价格进行分类预测。
- 特征选择的重要性:在模型构建过程中,特征选择对于预测精度至关重要。选取与手机价格相关性强的特征(如品牌、配置、屏幕尺寸、电池容量等)能够显著提高模型的预测性能。
- 参数优化的影响:SVM算法中的参数(如惩罚系数C和核函数参数γ)对模型性能有显著影响。通过实验发现,通过交叉验证等方法对参数进行优化,可以进一步提高模型的预测精度。
- 模型泛化能力:通过对比训练集和测试集的预测结果,发现模型在测试集上的表现略逊于训练集,但整体泛化能力良好。这表明模型对于未知数据的预测能力较强,具有一定的实用价值。
- 与其他模型的比较:将SVM模型与其他常见分类算法(如决策树、随机森林、神经网络等)进行比较,发现SVM模型在本实验中具有较高的预测精度和稳定性。这可能是因为SVM对于高维数据的处理能力较强,且对于非线性关系有较好的处理能力。
- 模型改进方向:虽然SVM模型在本实验中表现良好,但仍有一定的改进空间。未来可以考虑引入更多的特征、优化特征提取方法、尝试不同的核函数等方法来进一步提高模型的预测性能。
综上所述,基于SVM算法构建的手机价格分类预测模型具有较高的预测精度和实用性,为手机价格预测提供了一种有效的方法。同时,实验过程中也发现了模型改进的方向,为未来的研究提供了参考。
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
源代码
数据集概述:手机特征的集合,包括电池电量、摄像头规格、网络支持、内存、屏幕尺寸和其他属性。“price_range”列将手机按价格范围进行分类,使该数据集适用于手机分类和价格预测任务。
# 导入第三方库
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
sns.set(font='SimHei')
warnings.filterwarnings('ignore')
# 读取数据
df = pd.read_csv('train.csv')
df.head() # 查看数据前五行
df.shape
df.info()
df.describe()
df.isnull().sum()
any(df.duplicated())
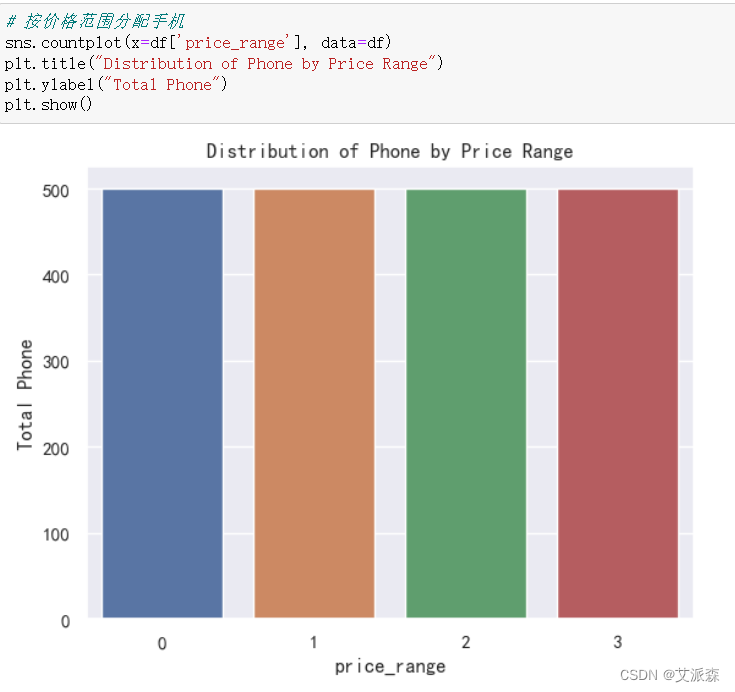
# 按价格范围分配手机
sns.countplot(x=df['price_range'], data=df)
plt.title("Distribution of Phone by Price Range")
plt.ylabel("Total Phone")
plt.show()
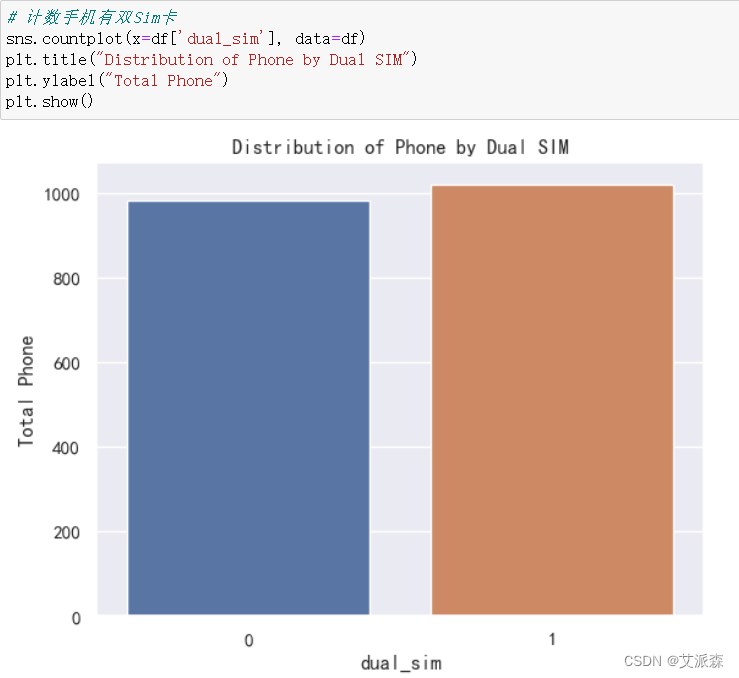
# 计数手机有双Sim卡
sns.countplot(x=df['dual_sim'], data=df)
plt.title("Distribution of Phone by Dual SIM")
plt.ylabel("Total Phone")
plt.show()
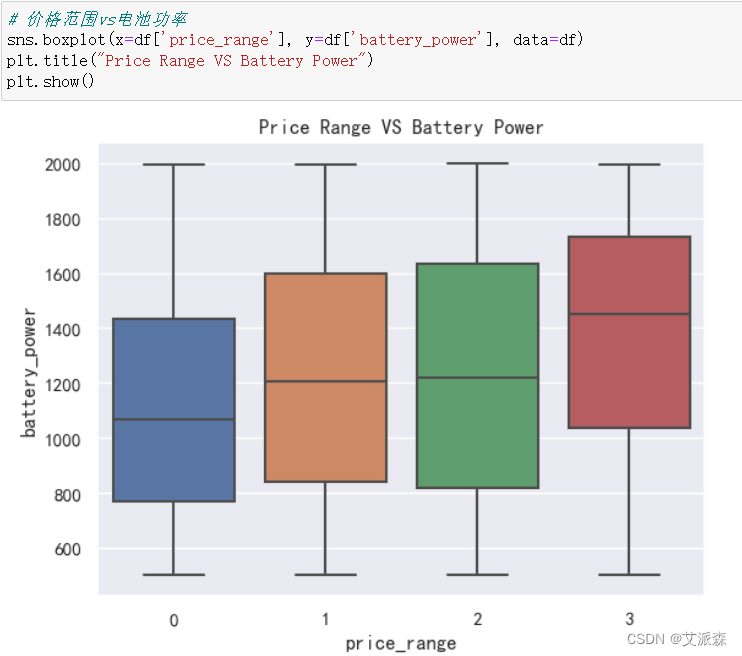
# 价格范围vs电池功率
sns.boxplot(x=df['price_range'], y=df['battery_power'], data=df)
plt.title("Price Range VS Battery Power")
plt.show()
# 价格范围vs内存
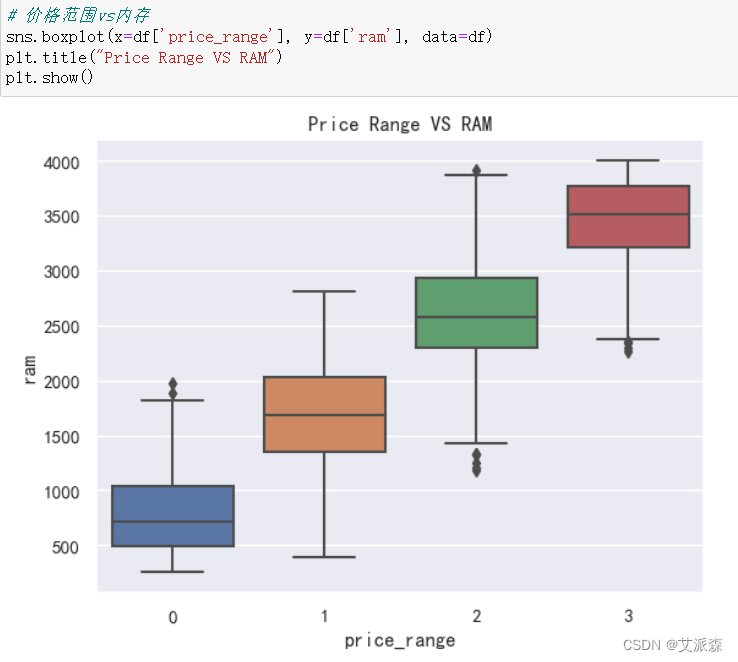
sns.boxplot(x=df['price_range'], y=df['ram'], data=df)
plt.title("Price Range VS RAM")
plt.show()
# 价格范围vs时钟速度
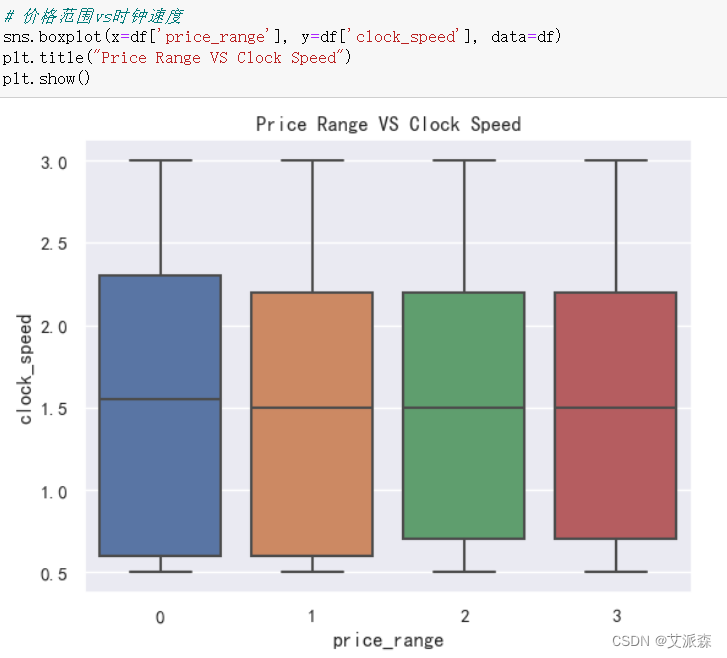
sns.boxplot(x=df['price_range'], y=df['clock_speed'], data=df)
plt.title("Price Range VS Clock Speed")
plt.show()
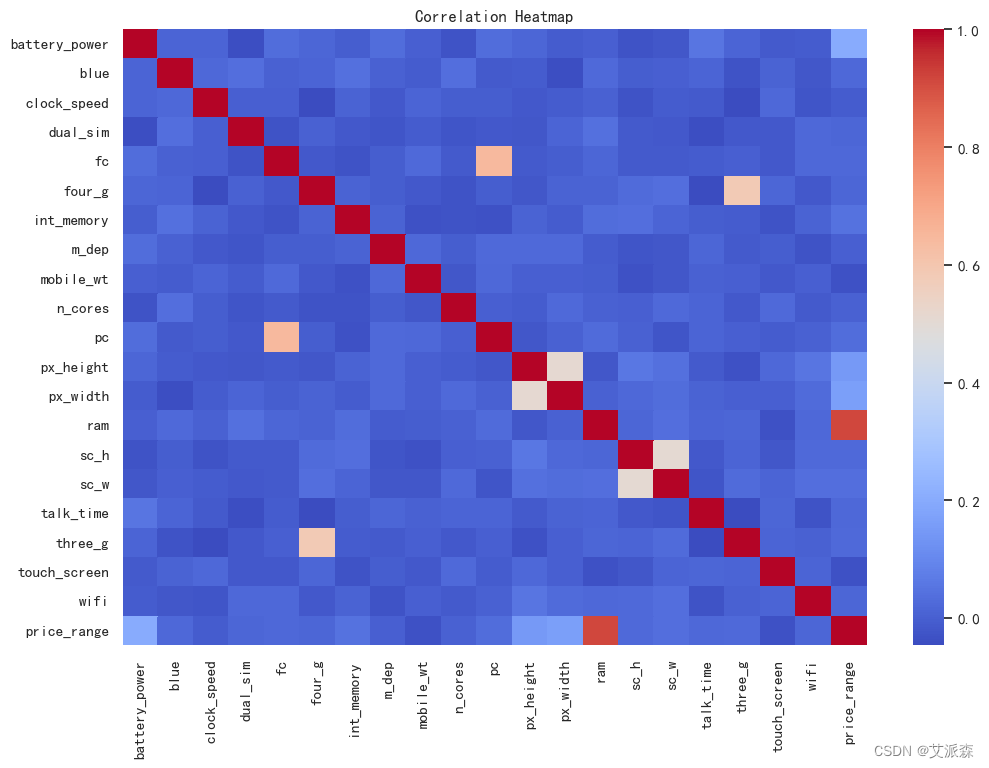
# 相关系数热力图
plt.figure(figsize=(12,8))
sns.heatmap(df.corr(), cmap='coolwarm')
plt.title("Correlation Heatmap")
plt.show()
# 创建一个特征和目标变量
X = df.drop('price_range', axis=1)
y = df['price_range']
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
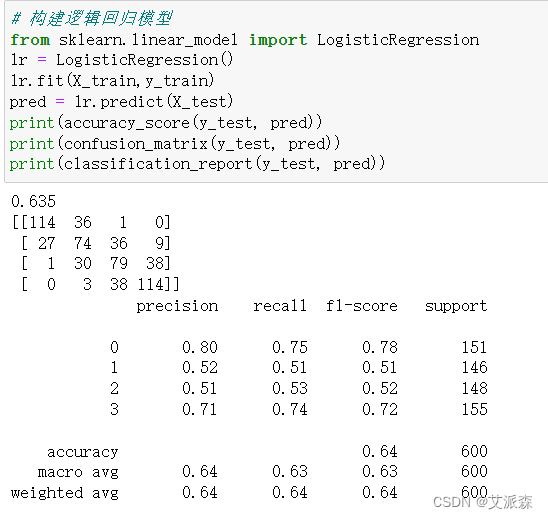
# 构建逻辑回归模型
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train,y_train)
pred = lr.predict(X_test)
print(accuracy_score(y_test, pred))
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred))
# 构建随机森林模型
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
pred = rfc.predict(X_test)
print(accuracy_score(y_test, pred))
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred))
# 构建决策树模型
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier()
dt.fit(X_train, y_train)
pred = dt.predict(X_test)
print(accuracy_score(y_test, pred))
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred))
# 构建SVM支持向量机模型
from sklearn.svm import SVC
svc = SVC()
svc.fit(X_train, y_train)
pred = svc.predict(X_test)
print(accuracy_score(y_test, pred))
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred))
# 模型预测
res = pd.DataFrame()
res['真实值'] = y_test
res['预测值'] = pred
res.sample(10) # 随机抽取10个
相关文章:
大数据分析案例-基于SVM支持向量机算法构建手机价格分类预测模型
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

WPF 滑动条样式
效果图: 浅色: 深色: 滑动条部分代码: <Style x:Key"RepeatButtonTransparent" TargetType"{x:Type RepeatButton}"><Setter Property"OverridesDefaultStyle" Value"true"/&g…...

论文设计任务书学习文档|基于Web的个性化简历职位推荐系统的设计与实现
文章目录 论文(设计)题目:基于Web的个性化简历职位推荐系统的设计与实现1、论文(设计)的主要任务及目标2、论文(设计)的主要内容3、论文(设计)的基本要求4、进度安排论文(设计)题目:基于Web的个性化简历职位推荐系统的设计与实现 1、论文(设计)的主要任务及目标…...

Win11系统安装安卓子系统教程
随着Win11系统的不断普及,以及硬件设备的更新换代,我相信很多同学都已经更新并使用到了最新的Win11系统。那么,Win11系统最受期待的功能“Windows Subsystem for Android”(简称WSA),即《安卓子系统》。他可…...
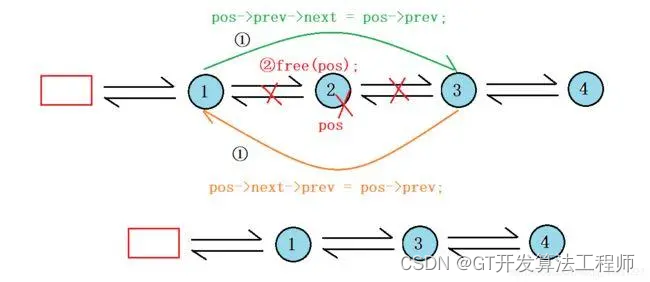
Python实现双向链表:从基础到应用
一、引言 双向链表是一种比单向链表更复杂的数据结构,每个节点除了包含数据和指向下一个节点的指针外,还包含一个指向前一个节点的指针。这种结构使得我们可以从链表的任何节点开始,向前或向后遍历链表。 目录 一、引言 二、节点定义 三、…...

c# 读取DataGridView中的数据
/// <summary> /// 读取DataGridView中的数据 /// </summary> /// <param name"dgv">DataGridView对象</param> /// <returns>DataTable对象</returns> private DataTable GetDgvToTab…...
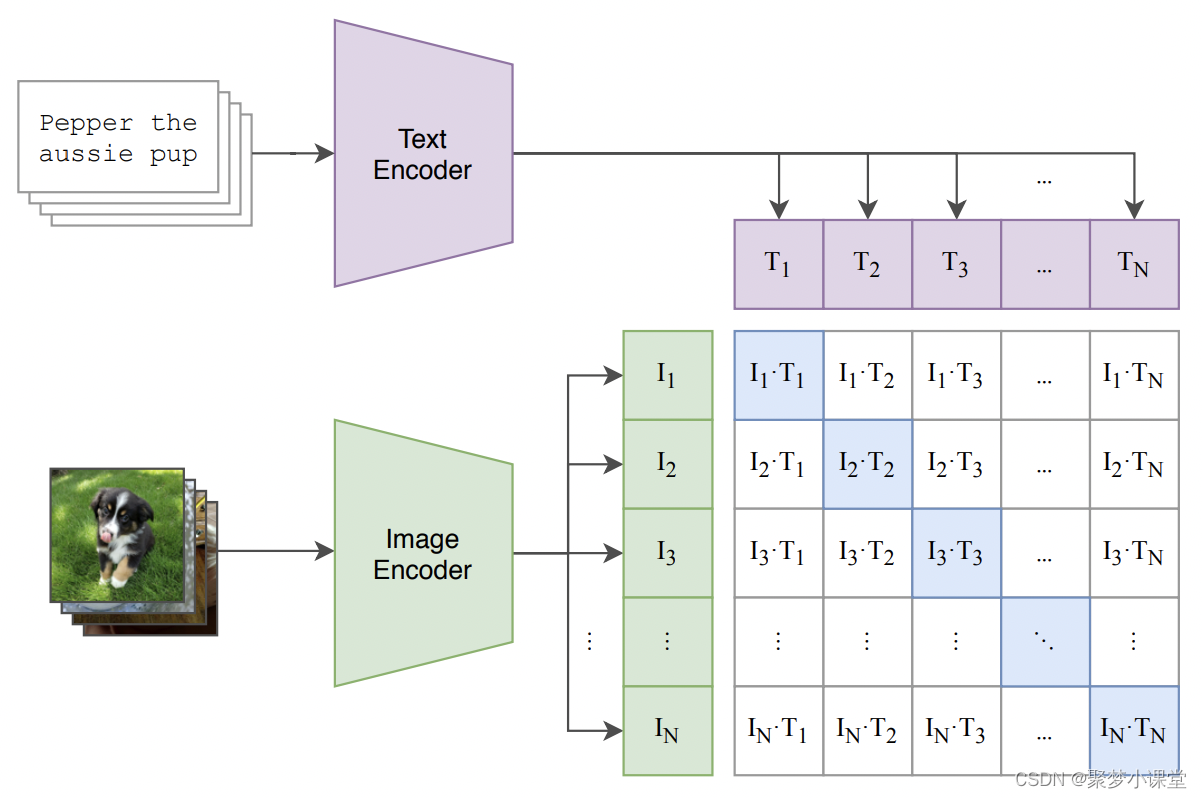
Stable Diffusion中的Clip模型
基础介绍 Stable Diffusion 是一个文本到图像的生成模型,它能够根据用户输入的文本提示(prompt)生成相应的图像。在这个模型中,CLIP(Contrastive Language-Image Pre-training)模型扮演了一个关键的角色&a…...

Python批量提取文件夹中图片的名称及路径到指定的.txt文件中
目录 一、代码二、提取效果 一、代码 import os# 定义要保存的文件名 file_name "TestImage/Image_Visible_Gray.txt"# 读取文件夹路径 folder_path "TestImage/Image_Visible_Gray"# 遍历文件夹中的所有文件 with open(file_name, "w") as f…...
微软开源 SBOM 生成工具:sbom-tool下载及使用详解
github地址 GitHub - microsoft/sbom-tool: The SBOM tool is a highly scalable and enterprise ready tool to create SPDX 2.2 compatible SBOMs for any variety of artifacts.The SBOM tool is a highly scalable and enterprise ready tool to create SPDX 2.2 compatib…...

【办公类-18-03】(Python)中班米罗可儿证书批量生成打印(班级、姓名)
作品展示——米罗可儿证书打印幼儿姓名 背景需求 2024年3月1日,中4班孩子一起整理美术操作材料《米罗可儿》的操作本——将每一页纸撕下来,分类摆放、确保纸张上下位置正确。每位孩子们都非常厉害,不仅完成了自己的一本,还将没有…...
)
js【详解】数据类型原理(含变量赋值详解-浅拷贝)
JavaScript 中的数据按存储方式的不同,分为值类型和引用类型。 值类型(共 6 种):赋值的时候传值 —— 数字、字符串、布尔值、null 、undefined,Symbol引用类型(仅 1 种):赋值的时候…...

SAM 影像分割——地理空间数据的分段模型的数据调参和自动分割分析
本笔记本展示了如何使用 Segment Anything Model (SAM) 从图像中分割对象,只需几行代码即可完成。 请确保在本笔记本中使用 GPU 运行时。对于 Google Colab,请转到运行时 -> 更改运行时类型,然后选择 GPU 作为硬件加速器。 地理空间数据的分段模型 Segment Anything M…...

Java底层自学大纲_设计模式篇
设计模式专题_自学大纲所属类别学习主题建议课时(h) A 深入理解设计模式001 SOLID设计原则和策略模式2.5 A 深入理解设计模式002 责任链模式2.5 A 深入理解设计模式003 工厂模式和模版方法模式2.5 A 深入理解设计模式004 装饰者模式2.5 A 深入理解设…...

详解字符串函数<string.h>(上)
1. strlen函数的使用和模拟实现 size_t strlen(const char* str); 1.1 函数功能以及用法 字符串长度 strlen函数的功能是计算字符串的长度。在使用时,要求用户传入需要计算长度的字符串的起始位置,并返回字符串的长度。 #include <stdio.h> #…...
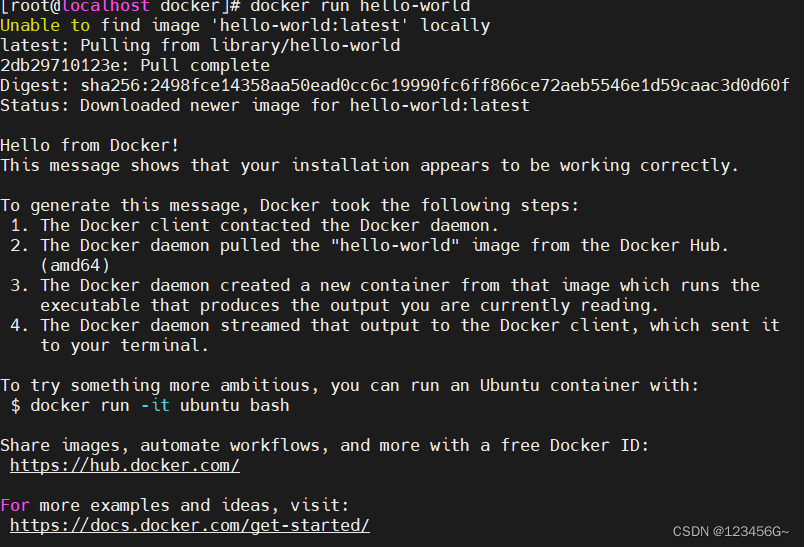
1、docker入门
文章目录 1、tocker简介2、tocker的安装&环境配置2、配置阿里云镜像3、基本命令1、镜像命令2、docker基本命令3、镜像基本命令4、Docker 容器常用命令 1、tocker简介 新一代的虚拟化技术 2、tocker的安装&环境配置 uname -r1、首先查看liunx的内核 yum update -y2、更…...

Qt应用软件【测试篇】cppchecker静态代码检查
文章目录 cppcheker简介下载地址与安装检查项目QT Creator使用CPP Cheker开启检查常见错误总结错误信息说明cppcheker简介 Cppcheck 是一个用于 C/C++ 代码的分析工具。它提供独特的代码分析以检测错误,并专注于检测未定义的行为和危险的编码结构。其目标是仅检测代码中的真实…...

[递推与递归]数的计算
题目描述 给出正整数 n,要求按如下方式构造数列: 只有一个数字 n 的数列是一个合法的数列。在一个合法的数列的末尾加入一个正整数,但是这个正整数不能超过该数列最后一项的一半,可以得到一个新的合法数列。 请你求出ÿ…...
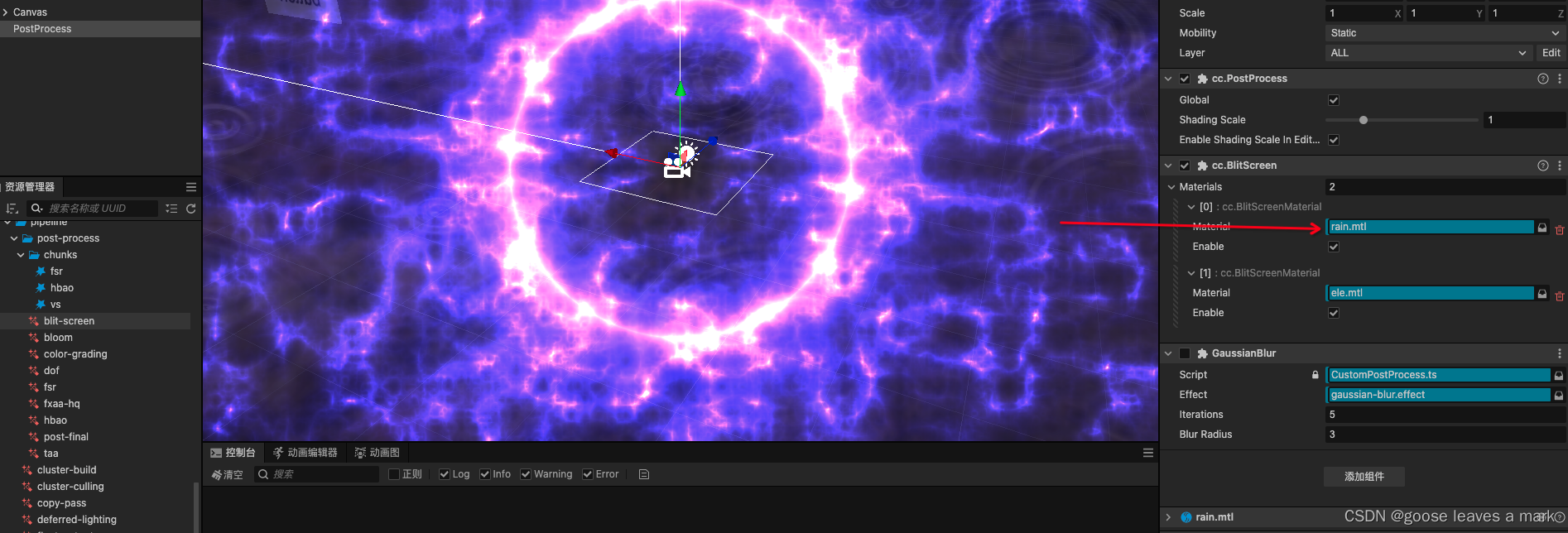
Cocos Creator 3.8.x 后效处理(前向渲染)
关于怎么开启后效效果我这里不再赘述,可以前往Cocos官方文档查看具体细节:后效处理官网 下面讲一下怎么自己定义一个后处理效果,想添加自己的后效处理的话只需要在postProcess节点下添加一个BlitScreen 组件即可,然后自己去添加自…...
【前端素材】推荐优质后台管理系统 Adminity平台模板(附源码)
一、需求分析 1、系统定义 后台管理系统是一种用于管理网站、应用程序或系统的管理界面,通常由管理员和工作人员使用。它提供了访问和控制网站或应用程序后台功能的工具和界面,使其能够管理用户、内容、数据和其他各种功能。 2、功能需求 后台管理系…...

身份证号与姓名实名认证接口-二要素实名认证-C++接口代码
翔云(https://www.netocr.com/idenNoOrd.html)身份证二要素实名认证接口在当今的数字化社会中扮演着至关重要的角色,它不仅守护着网络世界的秩序,也悄然影响着现实生活的点滴。看似普通的身份证号实名认证接口也在悄然守护着人们的…...

BilibiliDown:3分钟学会B站视频下载,打造个人离线视频库
BilibiliDown:3分钟学会B站视频下载,打造个人离线视频库 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com…...

2026 requests零基础入门:从0到1搞定HTTP请求与数据采集
很多刚接触Python数据采集的朋友,第一个遇到的问题就是:怎么用代码访问一个网页?浏览器能正常打开,为什么代码返回403?今天就带大家从零开始学习Python生态最流行的HTTP库——requests。它语法简洁、功能强大ÿ…...

VSCode 与 code-server:浏览器端代码编辑方案选型
VSCode 与 code-server:浏览器端代码编辑方案选型在构建浏览器端的代码编辑能力时,开发者面临一个关键选择:使用 VSCode 官方的 code serve-web 功能,还是采用社区驱动的 code-server 方案?这个选择不仅影响技术架构&a…...

Prodigy-PDF的PDF标注与OCR技术
最近推出了Prodigy插件,通过直接支持第三方集成来扩展Prodigy的功能。其中一款插件是Prodigy-PDF,它提供了PDF标注的功能。 [00:00] 介绍Prodigy-PDF [00:24] 标注PDF分段 [02:22] PDF分段中的OCR [03:55] 折叠启发式算法 本教程相关资源 ● Prodig-ANN:…...

回归力学真实与精度:XTOM高分辨率3D扫描赋能汽车模具全尺寸管控
随着对汽车质量和安全性的关注度不断提高,汽车零部件制造商越来越重视产品质量和用户体验。作为 “工业之母” 的模具,其精度与性能直接决定着下游产品的品质上限。在汽车模具的生产过程中,进行严格的质量控制必不可少。接下来,为…...

126. 如何为 Elemental OS Machine 创建网络绑定
Procedure 程序Configuring NIC Teaming for OS Elemental 为操作系统 Elemental 配置 NIC 分组 Overview 概述 This article provides the procedure for configuring NIC Teaming (bonding) in SUSE Elemental OS. It includes an example configuration that can be adjus…...

HCIA作业
第一步:将拓扑图分成三个架构 (学校内网,运营商,百度网络),再着眼于其中一个架构第二步: 将学校内网分成两个部分:1.二层交换机 2.三层路由器 【先配二层再做三层】2.1:配置交换机࿱…...

从Go到Kotlin:对比学习Channel的5个核心用法与避坑指南
从Go到Kotlin:Channel核心用法与实战避坑指南 1. 理解Channel的本质 对于熟悉Go语言的开发者来说,Kotlin的Channel概念并不陌生。两者都源自相同的并发模型理念,但在实现细节和使用方式上存在显著差异。 Channel本质上是一个线程安全的队列&a…...

Mac Mouse Fix:5分钟让你的普通鼠标在Mac上超越苹果原生体验
Mac Mouse Fix:5分钟让你的普通鼠标在Mac上超越苹果原生体验 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 还在为Mac上第三方鼠标…...

Genshin FPS Unlocker:如何安全突破原神60帧限制,释放硬件全部性能?
Genshin FPS Unlocker:如何安全突破原神60帧限制,释放硬件全部性能? 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock Genshin FPS Unlocker是一款开源工…...