利用 lxml 库的XPath()方法在网页中快速查找元素
XPath() 函数是 lxml 库中 Element 对象的方法。在使用 lxml 库解析 HTML 或 XML 文档时,您可以通过创建 Element 对象来表示文档的元素,然后使用 Element 对象的 XPath() 方法来执行 XPath 表达式并选择相应的元素。
具体而言,XPath() 方法是 Element 对象的一个实例方法,用于在该特定元素上执行 XPath 查询。通过调用这个方法并传入合适的 XPath 表达式,您可以定位到符合条件的元素,并对其进行操作或提取信息。
# 使用 XPath 表达式选择具有特定属性值的元素
tree = html.fromstring(html_page)
# 这段代码使用了 Python 的 lxml 库将 HTML 页面解析成元素树,并将树的根节点打印出来。
# print(tree) #输出: <Element html at 0x1e1ebe699a0>
element = tree.xpath("//div[@class='content']")
# Element 对象是 lxml 库中表示 XML/HTML 元素的数据类型。
# 它包含了元素的标签名、属性、文本内容以及子元素等信息,并提供了一系列方法和属性来操作和访问这些信息。在 Python 的 lxml 库中,Element 对象通常用于表示 HTML 或 XML 文档中的各个元素,可以通过它来获取元素的标签名、属性值、文本内容,以及对元素进行遍历、搜索、修改等操作。
# 在程序中,element 变量是一个 Element 对象的列表,表示选中的所有元素。
# 您可以遍历这个列表,对每个元素进行进一步处理或者提取特定的信息。
# print(element) #输出: [<Element div at 0x1e1ec44cc30>]
# 输出结果
print(element[0].text)
XPath() 函数通常用于在网页中查找元素,并且它接受不同类型的参数来定位和选择元素。以下是 XPath() 函数可能接受的参数类型:
字符串类型(String):最常见的参数类型,用于指定要查找的元素或属性的名称、值或文本内容。例如:
//tagname[@attribute='value'] 中的 'value'
//tagname[contains(text(), 'search_text')] 中的 'search_text'
//tagname[starts-with(@attribute, 'prefix')] 中的 'prefix'
# 使用 XPath 表达式选择具有特定属性值的元素
tree = html.fromstring(html_page)
element = tree.xpath("//div[@class='content']")
# 输出结果
print(element[0].text)
节点类型(Node):用于表示要查找的节点或元素。可以通过元素的标签名、属性等来指定节点。例如:
//tagname 中的 tagname
//tagname[@attribute='value'] 中的 @attribute
//tagname[text()='text_value'] 中的 text()='text_value'
# 使用 XPath 表达式选择具有指定文本内容的元素
tree = html.fromstring(html_page)
element = tree.xpath("//a[text()='Click here']")
# 输出结果
print(element[0].get('href'))
数值类型(Number):在一些情况下,XPath 表达式可能需要使用数值类型的参数,如位置索引等。例如:
(//tagname)[1] 中的 1
(//tagname)[position] 中的 position
# 使用 XPath 表达式选择具有指定位置的元素
tree = html.fromstring(html_page)
element = tree.xpath("(//div)[2]")
# 输出结果
print(element[0].text)
布尔类型(Boolean):用于表示真(true)或假(false)的值,通常用于逻辑运算符的判断条件。例如:
//tagname[@attribute='value' and @attribute2='value2'] 中的 and
# 使用 XPath 表达式选择同时满足多个条件的元素
tree = html.fromstring(html_page)
element = tree.xpath("//div[@class='content' and @id='main']")
# 输出结果
print(element[0].text)
当使用 Python 中的 lxml 库时,xpath() 方法用于执行 XPath 表达式以选择 XML 或 HTML 文档中的元素。
XPath 是一种用于定位和选择文档中特定部分的语言,它提供了丰富的功能和灵活性。
下面是一些常见的 XPath 表达式及其对应的功能和示例:
选择所有元素:XPath 表达式: //*
示例:elements = root.xpath('//*')
根据标签名选择元素:XPath 表达式: //tagname
示例:books = root.xpath('//book')
使用谓词选择特定条件下的元素:XPath 表达式: //tagname[@attribute='value']
示例:book = root.xpath("//book[@id='1']")
选择子元素:XPath 表达式: ./childtagname
示例:title = book[0].xpath('./title')[0]
使用位置索引选择元素:XPath 表达式: (//tagname)[position]
示例:first_book = root.xpath('(//book)[1]')
选择特定路径下的元素:XPath 表达式: //pathto/element
示例:chapter_titles = root.xpath('//book/chapters/chapter/title')
XPath 还支持许多其他功能,使您能够更灵活地定位和选择文档中的元素。
下面是一些常见的功能:
使用逻辑运算符:
and:同时满足两个条件 示例: //tagname[@attribute='value' and @attribute2='value2']
or:满足两个条件之一 示例: //tagname[@attribute='value' or @attribute2='value2']
not:不满足条件 示例: //tagname[not(@attribute='value')]
使用函数调用:
text():选择元素的文本内容 示例: //tagname/text()
contains():选择包含指定文本的元素 示例: //tagname[contains(text(), 'search_text')]
starts-with():选择以指定文本开头的元素 示例: //tagname[starts-with(@attribute, 'prefix')]
使用通配符:
*:选择当前节点的所有子元素 示例: //tagname/*
@*:选择当前节点的所有属性 示例: //tagname/@*
使用轴(坐标轴):
ancestor:选择当前节点的所有祖先节点 示例: //tagname/ancestor::ancestor_name
parent:选择当前节点的父节点 示例: //tagname/parent::parent_name
following-sibling:选择当前节点之后的所有同级节点 示例: //tagname/following-sibling::sibling_name
contains():选择包含指定文本的元素
语法://tagname[contains(text(), 'search_text')]
示例://div[contains(text(), 'Hello World')]
说明:这个表达式会选择所有 <tagname> 元素中包含文本 'search_text' 的元素。注意,这里的 text() 是用来选取元素的文本内容。
starts-with():选择以指定文本开头的元素
语法://tagname[starts-with(@attribute, 'prefix')]
示例://a[starts-with(@href, 'https://')]
说明:这个表达式会选择所有 <tagname> 元素中属性 'attribute' 的值以 'prefix' 开头的元素。在示例中,我们选择所有链接元素中 href 属性值以 'https://' 开头的链接。
# 导入必要的库和模块
from lxml import html# 定义要解析的 HTML 页面
html_page = '''<html><head><title>Example Page</title></head><body><div class="content">This is the main content.</div><div class="sidebar">This is the sidebar.</div></body></html>
'''# 使用 XPath 表达式选择具有特定属性值的元素
tree = html.fromstring(html_page)
# 这段代码使用了 Python 的 lxml 库将 HTML 页面解析成元素树,并将树的根节点打印出来。
# print(tree) #输出: <Element html at 0x1e1ebe699a0>
element = tree.xpath("//div[@class='content']")
# Element 对象是 lxml 库中表示 XML/HTML 元素的数据类型。
# 它包含了元素的标签名、属性、文本内容以及子元素等信息,并提供了一系列方法和属性来操作和访问这些信息。
# 在程序中,element 变量是一个 Element 对象的列表,表示选中的所有元素。
# 您可以遍历这个列表,对每个元素进行进一步处理或者提取特定的信息。
# print(element) #输出: [<Element div at 0x1e1ec44cc30>]
# 输出结果
print(element[0].text)print("*"*30)# 导入必要的库和模块
from lxml import html# 定义要解析的 HTML 页面
html_page = '''<html><head><title>Example Page</title></head><body><a href="http://www.example.com">Click here</a></body></html>
'''# 使用 XPath 表达式选择具有指定文本内容的元素
tree = html.fromstring(html_page)
element = tree.xpath("//a[text()='Click here']")# 输出结果
print(element[0].get('href'))print("*"*30)# 导入必要的库和模块
from lxml import html# 定义要解析的 HTML 页面
html_page = '''<html><head><title>Example Page</title></head><body><div class="content">This is the main content.</div><div class="sidebar">This is the sidebar.</div></body></html>
'''# 使用 XPath 表达式选择具有指定位置的元素
tree = html.fromstring(html_page)
element = tree.xpath("(//div)[2]")# 输出结果
print(element[0].text)print("*"*30)# 导入必要的库和模块
from lxml import html# 定义要解析的 HTML 页面
html_page = '''<html><head><title>Example Page</title></head><body><div class="content" id="main">This is the main content.</div><div class="sidebar">This is the sidebar.</div></body></html>
'''# 使用 XPath 表达式选择同时满足多个条件的元素
tree = html.fromstring(html_page)
element = tree.xpath("//div[@class='content' and @id='main']")# 输出结果
print(element[0].text)oooooo='''
lxml 库是一个功能强大且高效的 Python 库,用于处理 XML 和 HTML 数据。它基于 libxml2 和 libxslt 库,提供了简单易用的 API 接口,使开发者能够方便地解析、生成和操作 XML/HTML 文档。
lxml 库主要包含两个模块:lxml.etree 和 lxml.html。其中,lxml.etree 模块用于处理 XML 数据,提供了 ElementTree API 的增强版,支持 XPath、XSLT、解析、序列化等功能;lxml.html 模块则专门用于处理 HTML 数据,提供了类似于 lxml.etree 的功能,同时还包含了一些针对 HTML 的特定方法和功能。
使用 lxml 库,您可以轻松地完成以下任务:
解析 XML/HTML 文档并构建相应的 Element 对象树。
使用 XPath 表达式查询文档中的元素。
修改、删除或添加文档中的元素。
序列化 Element 对象树为字符串或文件。
执行 XSLT 转换等操作。
总的来说,lxml 库是处理 XML 和 HTML 数据的重要工具,提供了丰富的功能和灵活的接口,适合各种数据处理和 web 抓取任务。
----------------------
XPath() 函数是 lxml 库中 Element 对象的方法。在使用 lxml 库解析 HTML 或 XML 文档时,您可以通过创建 Element 对象来表示文档的元素,然后使用 Element 对象的 XPath() 方法来执行 XPath 表达式并选择相应的元素。
具体而言,XPath() 方法是 Element 对象的一个实例方法,用于在该特定元素上执行 XPath 查询。通过调用这个方法并传入合适的 XPath 表达式,您可以定位到符合条件的元素,并对其进行操作或提取信息。
XPath() 函数通常用于在网页中查找元素,并且它接受不同类型的参数来定位和选择元素。
以下是 XPath() 函数可能接受的参数类型:
字符串类型(String):最常见的参数类型,用于指定要查找的元素或属性的名称、值或文本内容。例如:
//tagname[@attribute='value'] 中的 'value'
//tagname[contains(text(), 'search_text')] 中的 'search_text'
//tagname[starts-with(@attribute, 'prefix')] 中的 'prefix'
# 使用 XPath 表达式选择具有特定属性值的元素
tree = html.fromstring(html_page)
element = tree.xpath("//div[@class='content']")
# 输出结果
print(element[0].text)节点类型(Node):用于表示要查找的节点或元素。可以通过元素的标签名、属性等来指定节点。例如:
//tagname 中的 tagname
//tagname[@attribute='value'] 中的 @attribute
//tagname[text()='text_value'] 中的 text()='text_value'
# 使用 XPath 表达式选择具有指定文本内容的元素
tree = html.fromstring(html_page)
element = tree.xpath("//a[text()='Click here']")# 输出结果
print(element[0].get('href'))数值类型(Number):在一些情况下,XPath 表达式可能需要使用数值类型的参数,如位置索引等。例如:
(//tagname)[1] 中的 1
(//tagname)[position] 中的 position
# 使用 XPath 表达式选择具有指定位置的元素
tree = html.fromstring(html_page)
element = tree.xpath("(//div)[2]")
# 输出结果
print(element[0].text)布尔类型(Boolean):用于表示真(true)或假(false)的值,通常用于逻辑运算符的判断条件。例如:
//tagname[@attribute='value' and @attribute2='value2'] 中的 and
# 使用 XPath 表达式选择同时满足多个条件的元素
tree = html.fromstring(html_page)
element = tree.xpath("//div[@class='content' and @id='main']")
# 输出结果
print(element[0].text)
-----------------------
当使用 Python 中的 lxml 库时,xpath() 方法用于执行 XPath 表达式以选择 XML 或 HTML 文档中的元素。
XPath 是一种用于定位和选择文档中特定部分的语言,它提供了丰富的功能和灵活性。
下面是一些常见的 XPath 表达式及其对应的功能和示例:
选择所有元素:XPath 表达式: //*
示例:elements = root.xpath('//*')
根据标签名选择元素:XPath 表达式: //tagname
示例:books = root.xpath('//book')
使用谓词选择特定条件下的元素:XPath 表达式: //tagname[@attribute='value']
示例:book = root.xpath("//book[@id='1']")
选择子元素:XPath 表达式: ./childtagname
示例:title = book[0].xpath('./title')[0]
使用位置索引选择元素:XPath 表达式: (//tagname)[position]
示例:first_book = root.xpath('(//book)[1]')
选择特定路径下的元素:XPath 表达式: //pathto/element
示例:chapter_titles = root.xpath('//book/chapters/chapter/title')
----------------------------
XPath 还支持许多其他功能,使您能够更灵活地定位和选择文档中的元素。下面是一些常见的功能:
使用逻辑运算符:
and:同时满足两个条件 示例: //tagname[@attribute='value' and @attribute2='value2']
or:满足两个条件之一 示例: //tagname[@attribute='value' or @attribute2='value2']
not:不满足条件 示例: //tagname[not(@attribute='value')]
使用函数调用:
text():选择元素的文本内容 示例: //tagname/text()
contains():选择包含指定文本的元素 示例: //tagname[contains(text(), 'search_text')]
starts-with():选择以指定文本开头的元素 示例: //tagname[starts-with(@attribute, 'prefix')]
使用通配符:
*:选择当前节点的所有子元素 示例: //tagname/*
@*:选择当前节点的所有属性 示例: //tagname/@*
使用轴(坐标轴):
ancestor:选择当前节点的所有祖先节点 示例: //tagname/ancestor::ancestor_name
parent:选择当前节点的父节点 示例: //tagname/parent::parent_name
following-sibling:选择当前节点之后的所有同级节点 示例: //tagname/following-sibling::sibling_name
------------------------
contains():选择包含指定文本的元素
语法://tagname[contains(text(), 'search_text')]
示例://div[contains(text(), 'Hello World')]
说明:这个表达式会选择所有 <tagname> 元素中包含文本 'search_text' 的元素。注意,这里的 text() 是用来选取元素的文本内容。
starts-with():选择以指定文本开头的元素
语法://tagname[starts-with(@attribute, 'prefix')]
示例://a[starts-with(@href, 'https://')]
说明:这个表达式会选择所有 <tagname> 元素中属性 'attribute' 的值以 'prefix' 开头的元素。在示例中,我们选择所有链接元素中 href 属性值以 'https://' 开头的链接。
---------------
lxml.etree 模块是 lxml 库中用于处理 XML 数据的核心模块,提供了 ElementTree API 的增强版,并支持 XPath、XSLT、解析、序列化等功能。以下是 lxml.etree 中一些重要的方法:
etree.parse():解析 XML 文件并返回 Element 对象树。
from lxml import etree
# 解析 XML 文件并返回 Element 对象树
tree = etree.parse('example.xml')etree.fromstring():将 XML 字符串转换为 Element 对象。
from lxml import etree
# 将 XML 字符串转换为 Element 对象
xml_str = "<root><a>1</a><b>2</b></root>"
root = etree.fromstring(xml_str)element.xpath():使用 XPath 表达式选择元素。
from lxml import etree
# 使用 XPath 表达式选择元素
tree = etree.parse('example.xml')
elements = tree.xpath('//book[author="John Doe"]')element.get():获取元素的指定属性。
from lxml import etree
# 获取元素的指定属性
tree = etree.parse('example.xml')
element = tree.xpath('//book')[0]
title = element.get('title')element.text:获取或设置元素的文本内容。
from lxml import etree
# 获取或设置元素的文本内容
tree = etree.parse('example.xml')
element = tree.xpath('//book/author')[0]
author = element.text
--------------------------
lxml.html 模块则是 lxml 库中用于解析和处理 HTML 数据的模块,它提供了类似于 lxml.etree 的功能,同时还包含了一些针对 HTML 的特定方法和功能。以下是 lxml.html 中一些重要的方法:
html.fromstring():将 HTML 字符串转换为 Element 对象。
from lxml import html
# 将 HTML 字符串转换为 Element 对象
html_str = '<html><body><h1>Hello, World!</h1></body></html>'
root = html.fromstring(html_str)element.xpath():使用 XPath 表达式选择元素。
from lxml import html
# 使用 XPath 表达式选择元素
html_str = '<html><body><h1>Hello, World!</h1></body></html>'
root = html.fromstring(html_str)
elements = root.xpath('//h1')element.cssselect():使用 CSS 选择器选择元素。
from lxml import html
# 使用 CSS 选择器选择元素
html_str = '<html><body><h1>Hello, World!</h1></body></html>'
root = html.fromstring(html_str)
elements = root.cssselect('h1')element.text_content():获取元素及其子元素的文本内容。
from lxml import html
# 获取元素及其子元素的文本内容
html_str = '<html><body><p>Hello, <strong>World!</strong></p></body></html>'
root = html.fromstring(html_str)
content = root.xpath('//p')[0].text_content()element.make_links_absolute():将相对链接转换为绝对链接。
from lxml import html
# 将相对链接转换为绝对链接
html_str = '<html><body><a href="/about">About</a></body></html>'
root = html.fromstring(html_str)
root.make_links_absolute('https://example.com')
link = root.xpath('//a')[0].get('href')
总的来说,lxml.etree 和 lxml.html 模块提供了丰富的功能和灵活的接口,适合各种 XML/HTML 数据处理任务。
'''lxml 库是一个功能强大且高效的 Python 库,用于处理 XML 和 HTML 数据,开发者能够方便地解析、生成和操作 XML/HTML 文档。
lxml 库主要包含两个模块:lxml.etree 和 lxml.html。其中,lxml.etree 模块用于处理 XML 数据,提供了 ElementTree API 的增强版,支持 XPath、XSLT、解析、序列化等功能;lxml.html 模块则专门用于处理 HTML 数据,提供了类似于 lxml.etree 的功能,同时还包含了一些针对 HTML 的特定方法和功能。
使用 lxml 库,您可以轻松地完成以下任务:
- 解析 XML/HTML 文档并构建相应的 Element 对象树。
- 使用 XPath 表达式查询文档中的元素。
- 修改、删除或添加文档中的元素。
- 序列化 Element 对象树为字符串或文件。
- 执行 XSLT 转换等操作。
总的来说,lxml 库是处理 XML 和 HTML 数据的重要工具,提供了丰富的功能和灵活的接口,适合各种数据处理和 web 抓取任务。
--
lxml.etree 模块是 lxml 库中用于处理 XML 数据的核心模块,提供了 ElementTree API 的增强版,并支持 XPath、XSLT、解析、序列化等功能。以下是 lxml.etree 中一些重要的方法:
etree.parse():解析 XML 文件并返回 Element 对象树。
from lxml import etree
# 解析 XML 文件并返回 Element 对象树
tree = etree.parse('example.xml')
etree.fromstring():将 XML 字符串转换为 Element 对象。
from lxml import etree
# 将 XML 字符串转换为 Element 对象
xml_str = "<root><a>1</a><b>2</b></root>"
root = etree.fromstring(xml_str)
element.xpath():使用 XPath 表达式选择元素。
from lxml import etree
# 使用 XPath 表达式选择元素
tree = etree.parse('example.xml')
elements = tree.xpath('//book[author="John Doe"]')
element.get():获取元素的指定属性。
from lxml import etree
# 获取元素的指定属性
tree = etree.parse('example.xml')
element = tree.xpath('//book')[0]
title = element.get('title')
element.text:获取或设置元素的文本内容。
from lxml import etree
# 获取或设置元素的文本内容
tree = etree.parse('example.xml')
element = tree.xpath('//book/author')[0]
author = element.text
lxml.html 模块则是 lxml 库中用于解析和处理 HTML 数据的模块,它提供了类似于 lxml.etree 的功能,同时还包含了一些针对 HTML 的特定方法和功能。以下是 lxml.html 中一些重要的方法:
html.fromstring():将 HTML 字符串转换为 Element 对象。
element.xpath():使用 XPath 表达式选择元素。
element.cssselect():使用 CSS 选择器选择元素。
element.text_content():获取元素及其子元素的文本内容。
相关文章:
方法在网页中快速查找元素)
利用 lxml 库的XPath()方法在网页中快速查找元素
XPath() 函数是 lxml 库中 Element 对象的方法。在使用 lxml 库解析 HTML 或 XML 文档时,您可以通过创建 Element 对象来表示文档的元素,然后使用 Element 对象的 XPath() 方法来执行 XPath 表达式并选择相应的元素。 具体而言,XPath() 方法是…...
nginx---------------重写功能 防盗链 反向代理 (五)
一、重写功能 rewrite Nginx服务器利用 ngx_http_rewrite_module 模块解析和处理rewrite请求,此功能依靠 PCRE(perl compatible regular expression),因此编译之前要安装PCRE库,rewrite是nginx服务器的重要功能之一,重写功能(…...

unity shaderGraph实例-物体线框显示
文章目录 本项目基于URP实现一,读取UV网格,由自定义shader实现效果优缺点效果展示模型准备整体结构各区域内容区域1区域2区域3区域4shader属性颜色属性材质属性后处理 实现二,直接使用纹理,使用默认shader实现优缺点贴图准备材质准…...
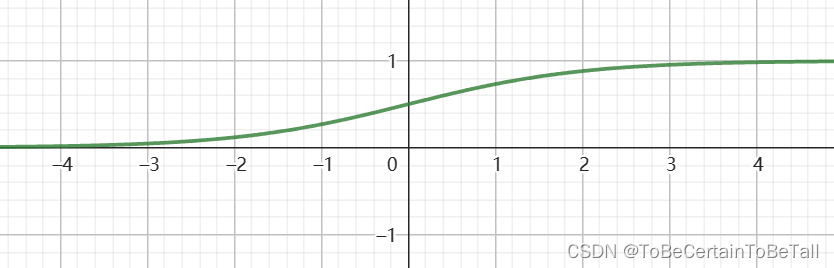
分类问题经典算法 | 二分类问题 | Logistic回归:公式推导
目录 一. Logistic回归的思想1. 分类任务思想2. Logistic回归思想 二. Logistic回归算法:线性可分推导 一. Logistic回归的思想 1. 分类任务思想 分类问题通常可以分为二分类,多分类任务;而对于不同的分类任务,训练的主要目标是…...
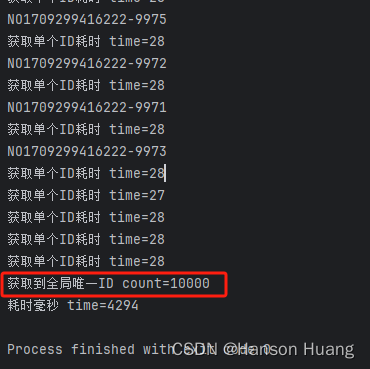
redis实现分布式全局唯一id
目录 一、前言二、如何通过Redis设计一个分布式全局唯一ID生成工具2.1 使用 Redis 计数器实现2.2 使用 Redis Hash结构实现 三、通过代码实现分布式全局唯一ID工具3.1 导入依赖配置3.2 配置yml文件3.3 序列化配置3.4 编写获取工具3.5 测试获取工具 四、运行结果 一、前言 在很…...

Sora引发安全新挑战
文章目录 前言一、如何看待Sora二、Sora加剧“深度伪造”忧虑三、Sora无法区分对错四、滥用导致的安全危机五、Sora面临的安全挑战总结前言 今年2月,美国人工智能巨头企业OpenAI再推行业爆款Sora,将之前ChatGPT以图文为主的生成式内容全面扩大到视频领域,引发了全球热议,这…...

Android 14.0 Launcher3定制化之桌面分页横线改成圆点显示功能实现
1.前言 在14.0的系统rom产品定制化开发中,在进行launcher3的定制化中,在双层改为单层的开发中,在原生的分页 是横线,而为了美观就采用了系统原来的另外一种分页方式,就是圆点比较美观,接下来就来分析下相关…...
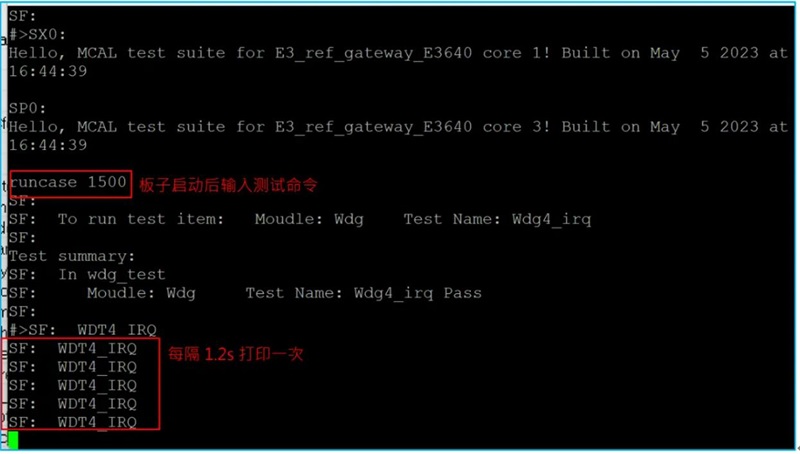
SemiDrive E3 MCAL 开发系列(3)– Wdg 模块的使用
一、 概述 本文将会介绍 SemiDrive E3 MCAL Wdg 模块的基本配置,并且会结合实际操作的介绍,帮助新手快速了解并掌握这个模块的使用,文中的 MCAL 是基于 PTG3.0 的版本,开发板是官方的 E3640 网关板。 二、 Wdg 模块的主要配置 …...

AI推荐算法的演进之路
推荐算法 基于大数据和AI技术,提供全流程一站式推荐平台,协助企业构建个性化推荐应用,提升企业应用的点击率留存率和永久体验。目前,主要的推荐方法包括:基于内容推荐、协同过滤推荐、基于关联规则推荐、基于效用推荐…...
Tomcat安装,配置文件、组件
一、Tomcat的基本功能 1.1.Tomcat是什么? Tomcat服务器是一个免费的开放源代码的Web应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP程序的首选。一般来说,T…...

精读《React Hooks 最佳实践》
简介 React 16.8 于 2019.2 正式发布,这是一个能提升代码质量和开发效率的特性,笔者就抛砖引玉先列出一些实践点,希望得到大家进一步讨论。 然而需要理解的是,没有一个完美的最佳实践规范,对一个高效团队来说&#x…...

varFormatter 数据格式化库 以性能优先的 快速的 内存对象格式转换
varFormatter 数据格式化 技术 开源技术栏 对象/变量格式化工具库,其支持将一个对象进行按照 JSON XML HTML 等格式进行转换,并获取到结果字符串! 目录 文章目录 varFormatter 数据格式化 技术目录介绍获取方式 使用实例格式化组件的基本使…...
基于PHP的在线英语学习平台
有需要请加文章底部Q哦 可远程调试 基于PHP的在线英语学习平台 一 介绍 此在线英语学习平台基于原生PHP开发,数据库mysql。系统角色分为学生,教师和管理员。(附带参考设计文档) 技术栈:phpmysqlphpstudyvscode 二 功能 学生 1 注册/登录/…...
答辩常规问题和如何回答(答辩指导))
基于微信小程序电影院订票选座系统 (后台JSP+JDBC+Mysql)答辩常规问题和如何回答(答辩指导)
博主介绍:黄菊华老师《Vue.js入门与商城开发实战》《微信小程序商城开发》图书作者,CSDN博客专家,在线教育专家,CSDN钻石讲师;专注大学生毕业设计教育和辅导。 所有项目都配有从入门到精通的基础知识视频课程ÿ…...
:模拟算法真题 ★★★☆☆《安全警报》)
C++知识点总结(22):模拟算法真题 ★★★☆☆《安全警报》
安全警报 1. 审题 题目描述 Z市最大的金融公司:太平洋金融遭到了入侵,一名黑客潜入到了公司中,公司紧急启动安保程序,将大楼封锁,并安排作为安全主管的你对楼层进行搜查。所以你准备写一个程序,输入搜查楼…...

蓝桥杯练习系统(算法训练)ALGO-993 RP大冒险
资源限制 内存限制:64.0MB C/C时间限制:200ms Java时间限制:600ms Python时间限制:1.0s 问题描述 请尽情使用各种各样的函数来测试你的RP吧~~~ 输入格式 一个数N表示测点编号。 输出格式 一个0~9的数。 样例输入 0 样…...
Unity的相机跟随和第三人称视角
Unity相机跟随和第三人称视角 介绍镜头视角跟随人物方向进行旋转的镜头视角固定球和人的镜头视角 思路跟随人物方向进行旋转的镜头视角固定球和人的镜头视角 镜头旋转代码人物移动的参考代码注意 介绍 最近足球项目的镜头在做改动,观察了一下实况足球的视角&#x…...

哪个超声波清洗机品牌值得入手?销量榜品牌值得选购!
在科技日益发展的今天,超声波清洗技术以其高效、便捷和深度清洁的特点,已经深入到生活的诸多领域,从精密仪器到珠宝首饰,从眼镜框到假牙,甚至是厨房用品的日常护理,都能见到超声波清洗机的身影。面对市场上…...

Stwo:基于Circle STARK和M31的下一代STARK证明系统
1. 引言 StarkWare团队和Polygon Labs团队,历时数月,构造了基于Mersenne素数域M31的Circle STARK协议,通过使用M31 over a circle,可基于任意有限域构造高效STARKs,具体见2024年2月19日论文《Circle STARKs》。 基于…...
)
笔记本以太网集线器Hub充电可能导致网络异常(貌似是我把服务器网关写错了)
文章目录 笔记本以太网集线器(Hub)充电导致网络异常概述原理分析电源与信号干扰设备热度设备兼容性问题 解决方案升级固件提高设备散热效率选择兼容性好的设备 总结 今天用笔记本以太网直连服务器,一开始能连通,结果以太网hub插上…...

零基础玩转Z-Image-Turbo-辉夜巫女:8步生成高质量图片,小白也能当AI画师
零基础玩转Z-Image-Turbo-辉夜巫女:8步生成高质量图片,小白也能当AI画师 1. 引言:人人都能成为AI画师 你是否曾经羡慕那些能随手画出精美插画的大触?现在,借助Z-Image-Turbo-辉夜巫女这个AI工具,零基础的…...

Heygem数字人系统在教育培训场景的应用:快速生成多讲师教学视频
Heygem数字人系统在教育培训场景的应用:快速生成多讲师教学视频 1. 教育培训行业的视频制作痛点 教育培训机构在制作教学视频时常常面临以下挑战: 讲师资源有限:优秀讲师时间宝贵,难以满足大量课程录制需求制作成本高昂&#x…...

别再纠结选哪个了!基于模态混叠、端点效应、重构误差和速度,给你的信号分解方法选型指南
信号分解方法选型实战指南:从模态混叠到运行效率的全面权衡 在工程实践中,我们常常需要处理各种非平稳信号——从机械振动监测到心电图分析,从金融时间序列预测到语音信号处理。面对这些复杂信号,传统的傅里叶变换等线性方法往往力…...

性能揭秘:HY-MT1.5-1.8B为何能以小博大,媲美千亿模型?
性能揭秘:HY-MT1.5-1.8B为何能以小博大,媲美千亿模型? 1. 引言:轻量级翻译模型的突破 在机器翻译领域,模型规模与性能的关系似乎已成定式——更大的参数量通常意味着更好的翻译质量。然而,腾讯混元团队最…...

OpenClaw Windows 一键部署教程|Win10/11 通用小白版
适配系统:Windows10/11 64 位当前版本:v2.3.10/v2.3.12(虾壳云版)核心优势:全程可视化操作,无需命令行、无需手动配置 Python/Node.js,内置全部运行依赖,5 分钟即可完成部署…...

4090D显卡专属优化!Guohua Diffusion国风绘画工具部署教程
4090D显卡专属优化!Guohua Diffusion国风绘画工具部署教程 1. 工具简介与核心优势 Guohua Diffusion是一款专为国风绘画设计的本地生成工具,基于原生Guohua-Diffusion模型开发。相比通用绘画工具,它具有以下独特优势: 4090D显卡…...

Paparazzi企业级部署指南:CI/CD集成与大规模团队协作
Paparazzi企业级部署指南:CI/CD集成与大规模团队协作 【免费下载链接】paparazzi Render your Android screens without a physical device or emulator 项目地址: https://gitcode.com/gh_mirrors/pa/paparazzi Paparazzi是一款强大的Android屏幕渲染工具&a…...
骨)
AI开发-python-langchain框架(--langchain与milvus的结合 )骨
一、 什么是 AI Skills:从工具级到框架级的演化 AI Skills(AI 技能) 的概念最早在 Claude Code 等前沿 Agent 实践中被强化。最初,Skills 被视为“工具级”的增强,如简单的文件读写或终端操作,方便用户快速…...

BERT在小说大模型中的核心定位:理解者、解码者、守护者
在AI重塑文学创作与阅读体验的时代浪潮中,Transformer架构的大语言模型无疑是聚光灯下的绝对主角。GPT系列以惊人的生成能力续写故事,DeepSeek-R1在阅文集团的集成让网文创作迎来了智能化时刻。然而,一个微妙却关键的问题正在浮出水面&#x…...

RelayModule:嵌入式继电器面向对象驱动库
1. RelayModule 库深度解析:面向嵌入式系统的数字继电器模块面向对象驱动设计继电器是嵌入式系统中实现强电控制与弱电隔离的核心执行器件,广泛应用于工业自动化、智能家居、电源管理及测试设备等场景。传统继电器驱动多采用裸机 GPIO 直接控制ÿ…...