强化学习嵌入Transformer(代码实践)
这里写目录标题
- ChatGPT的答案
- GPT4.0
ChatGPT的答案
# 定义Transformer模块
class Transformer(nn.Module):def __init__(self, input_dim, hidden_dim, num_heads, num_layers):super(Transformer, self).__init__()self.encoder_layer = nn.TransformerEncoderLayer(d_model=input_dim, nhead=num_heads)self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers)self.linear = nn.Linear(input_dim, hidden_dim)def forward(self, x):x = self.transformer_encoder(x)x = self.linear(x)return x# 定义策略网络
class PolicyNetwork(nn.Module):def __init__(self, input_dim, output_dim, hidden_dim, num_heads, num_layers):super(PolicyNetwork, self).__init__()self.transformer = Transformer(input_dim, hidden_dim, num_heads, num_layers)self.fc = nn.Linear(hidden_dim, output_dim)def forward(self, x):x = self.transformer(x)x = F.softmax(self.fc(x), dim=-1)return x
问:为什么只有Encoder 没有decoder?
在强化学习任务中,特别是在策略梯度方法中,通常不需要一个完整的Transformer模型,包括Encoder和Decoder。这是因为在这些任务中,我们通常只需要一个从状态到动作的映射,而不需要生成序列。
因此,我们可以只使用Transformer的Encoder部分,将状态作为输入,经过编码后得到一个表示状态的向量,然后将这个向量传递给策略网络(或者Critic网络)来进行动作选择或值函数估计。
使用Transformer的Encoder部分可以有效地处理状态的变长输入,并且具有对序列建模的能力,这在处理许多强化学习任务中是非常有用的。
因此,在PPO算法中,我们只需使用Transformer的Encoder部分,而不需要Decoder部分。在强化学习中,尤其是在处理具有复杂状态和动作空间的任务时,能够捕获状态序列间的依赖关系对于预测未来奖励和决策至关重要。Transformer通过其自注意力机制,能够有效地处理这种序列依赖,从而提升策略性能。
GPT4.0
# time: 2024/3/1 21:31
# author: YanJP
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from torch.distributions import Categorical
from torch.nn import TransformerEncoder, TransformerEncoderLayer
from torch.utils.data.sampler import BatchSampler, SubsetRandomSampler# Transformer特征提取器
class TransformerFeatureExtractor(nn.Module):def __init__(self, input_dim, model_dim, num_heads, num_layers, dropout=0.1):super(TransformerFeatureExtractor, self).__init__()self.model_dim = model_dimencoder_layers = TransformerEncoderLayer(d_model=model_dim, nhead=num_heads, dropout=dropout)self.transformer_encoder = TransformerEncoder(encoder_layer=encoder_layers, num_layers=num_layers)self.input_projection = nn.Linear(input_dim, model_dim)def forward(self, x):x = self.input_projection(x)# 添加一个序列长度的维度,假设x的原始形状为(batch, model_dim)x = x.unsqueeze(0) # 现在x的形状变为(1, batch, model_dim)output = self.transformer_encoder(x)return output.squeeze(0) # 移除序列长度的维度,恢复到(batch, model_dim)# PPO网络定义
class PPONetwork(nn.Module):def __init__(self, state_dim, action_dim, model_dim=64, num_heads=4, num_layers=4):super(PPONetwork, self).__init__()self.feature_extractor = TransformerFeatureExtractor(input_dim=state_dim, model_dim=model_dim,num_heads=num_heads, num_layers=num_layers)self.policy_head = nn.Linear(model_dim, action_dim)self.value_head = nn.Linear(model_dim, 1)def forward(self, state):features = self.feature_extractor(state)# features = features[:, -1, :] # 使用最后一个时间步的特征action_probs = torch.softmax(self.policy_head(features), dim=-1)state_values = self.value_head(features)return action_probs, state_values# PPO Agent
class PPOAgent:def __init__(self, env):self.env = envself.state_dim = env.observation_space.shape[0]self.action_dim = env.action_space.nself.network = PPONetwork(self.state_dim, self.action_dim)self.optimizer = optim.Adam(self.network.parameters(), lr=2.5e-4)self.gamma = 0.99self.lamda = 0.95self.eps_clip = 0.2self.K_epoch = 4self.buffer_capacity = 1000self.batch_size = 64self.buffer = {'states': [], 'actions': [], 'log_probs': [], 'rewards': [], 'is_terminals': []}def select_action(self, state):state = torch.FloatTensor(state).unsqueeze(0)with torch.no_grad():action_probs, _ = self.network(state)dist = Categorical(action_probs)action = dist.sample()return action.item(), dist.log_prob(action)def put_data(self, transition):self.buffer['states'].append(transition[0])self.buffer['actions'].append(transition[1])self.buffer['log_probs'].append(transition[2])self.buffer['rewards'].append(transition[3])self.buffer['is_terminals'].append(transition[4])def train_net(self):R = 0discounted_rewards = []for reward, is_terminal in zip(reversed(self.buffer['rewards']), reversed(self.buffer['is_terminals'])):if is_terminal:R = 0R = reward + (self.gamma * R)discounted_rewards.insert(0, R)discounted_rewards = torch.tensor(discounted_rewards, dtype=torch.float32)old_states = torch.tensor(np.array(self.buffer['states']), dtype=torch.float32)old_actions = torch.tensor(self.buffer['actions']).view(-1, 1)old_log_probs = torch.tensor(self.buffer['log_probs']).view(-1, 1)# Normalize the rewardsdiscounted_rewards = (discounted_rewards - discounted_rewards.mean()) / (discounted_rewards.std() + 1e-5)for _ in range(self.K_epoch):for index in BatchSampler(SubsetRandomSampler(range(len(self.buffer['states']))), self.batch_size, False):# Extract batchesstate_sample = old_states[index]action_sample = old_actions[index]old_log_probs_sample = old_log_probs[index]returns_sample = discounted_rewards[index].view(-1, 1)# Get current policiesaction_probs, state_values = self.network(state_sample)dist = Categorical(action_probs)entropy = dist.entropy().mean()new_log_probs = dist.log_prob(action_sample.squeeze(-1))# Calculating the ratio (pi_theta / pi_theta__old):ratios = torch.exp(new_log_probs - old_log_probs_sample.detach())# Calculating Surrogate Loss:advantages = returns_sample - state_values.detach()surr1 = ratios * advantagessurr2 = torch.clamp(ratios, 1 - self.eps_clip, 1 + self.eps_clip) * advantagesloss = -torch.min(surr1, surr2) + 0.5 * (state_values - returns_sample).pow(2) - 0.01 * entropy# take gradient stepself.optimizer.zero_grad()loss.mean().backward()self.optimizer.step()self.buffer = {'states': [], 'actions': [], 'log_probs': [], 'rewards': [], 'is_terminals': []}def train(self, max_episodes):for episode in range(max_episodes):state = self.env.reset()done = Falserewards=0while not done:action, log_prob = self.select_action(state)next_state, reward, done, _ = self.env.step(action)rewards+=rewardself.put_data((state, action, log_prob, reward, done))state = next_stateif done:self.train_net()if episode % 5 == 0:print("eposide:", episode, '\t reward:', rewards)# 主函数
def main():env = gym.make('CartPole-v1')agent = PPOAgent(env)max_episodes = 300agent.train(max_episodes)if __name__ == "__main__":main()
注意:代码能跑,但是不能正常学习到策略!!!!!!!!!!!!!!!!!!!!!!!!!!!!
相关文章:
强化学习嵌入Transformer(代码实践)
这里写目录标题 ChatGPT的答案GPT4.0 ChatGPT的答案 # 定义Transformer模块 class Transformer(nn.Module):def __init__(self, input_dim, hidden_dim, num_heads, num_layers):super(Transformer, self).__init__()self.encoder_layer nn.TransformerEncoderLayer(d_modeli…...

决定西弗吉尼亚州地区版图的关键历史事件
决定西弗吉尼亚州地区版图的关键历史事件: 1. 内部分裂与美国内战: - 在1861年美国内战爆发时,弗吉尼亚州作为南方邦联的一员宣布退出美利坚合众国。然而,弗吉尼亚州西部的一些县由于经济结构(主要是农业非依赖奴隶制…...

LeetCode_22_中等_括号生成
文章目录 1. 题目2. 思路及代码实现(Python)2.1 暴力法2.2 回溯法 1. 题目 数字 n n n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。 示例 1: 输入: n 3 n 3 …...
Verilog(未完待续)
Verilog教程 这个教程写的很好,可以多看看。本篇还没整理完。 一、Verilog简介 什么是FPGA?一种可通过编程来修改其逻辑功能的数字集成电路(芯片) 与单片机的区别?对单片机编程并不改变其地电路的内部结构࿰…...

【Linux实践室】Linux初体验
🌈个人主页:聆风吟 🔥系列专栏:Linux实践室、网络奇遇记 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 一. ⛳️任务描述二. ⛳️相关知识2.1 🔔Linux 目录结构介绍2.2 🔔Linux …...

Flutter中高级JSON处理:使用json_serializable进行深入定制
Flutter中高级JSON处理 使用json_serializable库进行深入定制 - 文章信息 - Author: 李俊才 (jcLee95) Visit me at: https://jclee95.blog.csdn.netEmail: 291148484163.com. Shenzhen ChinaAddress of this article:https://blog.csdn.net/qq_28550263/article/details/1363…...

华为OD技术面试案例4-2024年
个人情况:985本,目标院校非计算机专业,情况比较特殊,23年11月研究生退学,电子信息类专业。 初识od:10月底打算退学的时候在智联、BOSS上疯狂投硬件方面的岗位。投了大概一两天后有德科和HW的HR打电话给我介…...
 重试机制与监听器的使用)
【TestNG】(4) 重试机制与监听器的使用
在UI自动化测试用例执行过程中,经常会有很多不确定的因素导致用例执行失败,比如网络原因、环境问题等,所以我们有必要引入重试机制(失败重跑),来提高测试用例成功率。 在不写代码的情况没有提供可配置方式…...

“智农”-高标准农田
高标准农田是指通过土地整治、土壤改良、水利设施、农电配套、机械化作业等措施,提升农田质量和生产能力,达到田块平整、集中连片、设施完善、节水高效、宜机作业、土壤肥沃、生态友好、抗灾能力强、与现代农业生产和经营方式相适应的旱涝保收、稳产高产…...
方法在网页中快速查找元素)
利用 lxml 库的XPath()方法在网页中快速查找元素
XPath() 函数是 lxml 库中 Element 对象的方法。在使用 lxml 库解析 HTML 或 XML 文档时,您可以通过创建 Element 对象来表示文档的元素,然后使用 Element 对象的 XPath() 方法来执行 XPath 表达式并选择相应的元素。 具体而言,XPath() 方法是…...
nginx---------------重写功能 防盗链 反向代理 (五)
一、重写功能 rewrite Nginx服务器利用 ngx_http_rewrite_module 模块解析和处理rewrite请求,此功能依靠 PCRE(perl compatible regular expression),因此编译之前要安装PCRE库,rewrite是nginx服务器的重要功能之一,重写功能(…...

unity shaderGraph实例-物体线框显示
文章目录 本项目基于URP实现一,读取UV网格,由自定义shader实现效果优缺点效果展示模型准备整体结构各区域内容区域1区域2区域3区域4shader属性颜色属性材质属性后处理 实现二,直接使用纹理,使用默认shader实现优缺点贴图准备材质准…...
分类问题经典算法 | 二分类问题 | Logistic回归:公式推导
目录 一. Logistic回归的思想1. 分类任务思想2. Logistic回归思想 二. Logistic回归算法:线性可分推导 一. Logistic回归的思想 1. 分类任务思想 分类问题通常可以分为二分类,多分类任务;而对于不同的分类任务,训练的主要目标是…...
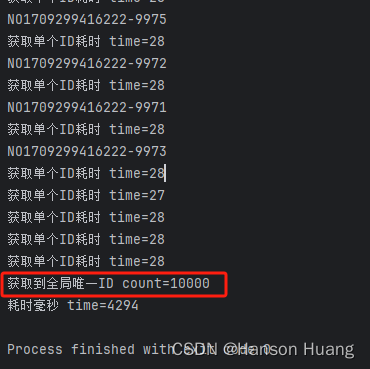
redis实现分布式全局唯一id
目录 一、前言二、如何通过Redis设计一个分布式全局唯一ID生成工具2.1 使用 Redis 计数器实现2.2 使用 Redis Hash结构实现 三、通过代码实现分布式全局唯一ID工具3.1 导入依赖配置3.2 配置yml文件3.3 序列化配置3.4 编写获取工具3.5 测试获取工具 四、运行结果 一、前言 在很…...

Sora引发安全新挑战
文章目录 前言一、如何看待Sora二、Sora加剧“深度伪造”忧虑三、Sora无法区分对错四、滥用导致的安全危机五、Sora面临的安全挑战总结前言 今年2月,美国人工智能巨头企业OpenAI再推行业爆款Sora,将之前ChatGPT以图文为主的生成式内容全面扩大到视频领域,引发了全球热议,这…...

Android 14.0 Launcher3定制化之桌面分页横线改成圆点显示功能实现
1.前言 在14.0的系统rom产品定制化开发中,在进行launcher3的定制化中,在双层改为单层的开发中,在原生的分页 是横线,而为了美观就采用了系统原来的另外一种分页方式,就是圆点比较美观,接下来就来分析下相关…...
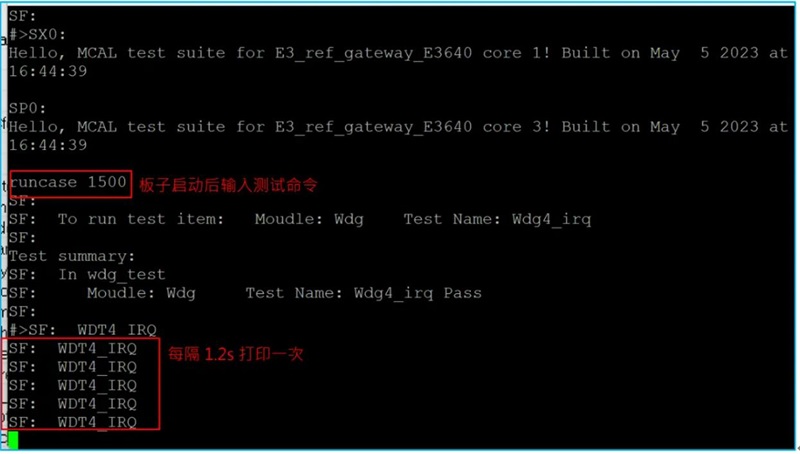
SemiDrive E3 MCAL 开发系列(3)– Wdg 模块的使用
一、 概述 本文将会介绍 SemiDrive E3 MCAL Wdg 模块的基本配置,并且会结合实际操作的介绍,帮助新手快速了解并掌握这个模块的使用,文中的 MCAL 是基于 PTG3.0 的版本,开发板是官方的 E3640 网关板。 二、 Wdg 模块的主要配置 …...

AI推荐算法的演进之路
推荐算法 基于大数据和AI技术,提供全流程一站式推荐平台,协助企业构建个性化推荐应用,提升企业应用的点击率留存率和永久体验。目前,主要的推荐方法包括:基于内容推荐、协同过滤推荐、基于关联规则推荐、基于效用推荐…...
Tomcat安装,配置文件、组件
一、Tomcat的基本功能 1.1.Tomcat是什么? Tomcat服务器是一个免费的开放源代码的Web应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试JSP程序的首选。一般来说,T…...

精读《React Hooks 最佳实践》
简介 React 16.8 于 2019.2 正式发布,这是一个能提升代码质量和开发效率的特性,笔者就抛砖引玉先列出一些实践点,希望得到大家进一步讨论。 然而需要理解的是,没有一个完美的最佳实践规范,对一个高效团队来说&#x…...

asp.net core + ef core 实现动态可扩展的分页方案
在开始之前,先问你一个问题:你做的系统,是不是每次增加一个查询条件或者排序字段,都要去请求参数对象里加一个属性,然后再跑去改 EF Core 的查询逻辑?如果是,那这篇文章应该对你有用。我会带你做…...

rosdep-ROS2
ROS2 Humble rosdep 从入门到排错:定义、作用+404/超时终极解决方案(亲测有效) 前言:很多ROS2新手在搭建环境、编译功能包时,都会遇到 rosdep update 404、超时等问题,甚至不清楚rosdep到底是什么、为什么要用。本文从基础概念入手,一步步讲清rosdep的核心作用,再针对…...

Typora Markdown写作伴侣:集成Phi-4-mini-reasoning实现智能校对与内容拓展
Typora Markdown写作伴侣:集成Phi-4-mini-reasoning实现智能校对与内容拓展 1. 智能写作新体验 想象一下这样的场景:你在Typora中奋笔疾书,突然对某个专业术语的解释拿捏不准;或者写了一大段文字,却不确定语气是否得…...
2012本科毕业设计)
液压折弯机(全套)2012本科毕业设计
液压折弯机作为金属板材加工领域的核心设备,其全套系统设计直接决定了加工精度与效率。该设备通过液压系统驱动滑块实现垂直运动,配合模具对板材施加压力,使其按预设角度弯曲成型。其核心作用体现在三方面:一是精准控制弯曲角度&a…...

dplyr和tidyr用法亚
1. 引入 在现代 AI 工程中,Hugging Face 的 tokenizers 库已成为分词器的事实标准。不过 Hugging Face 的 tokenizers 是用 Rust 来实现的,官方只提供了 python 和 node 的绑定实现。要实现与 Hugging Face tokenizers 相同的行为,最好的办法…...
)
选股小龙虾智能选股系统-2026.4.12.13 版本完整技术报告(修订版)
选股小龙虾智能选股系统2026.4.12.13 版本完整技术报告(修订版)生成时间:2026年04月12日 17:41:36【根据用户反馈修订:调整任务顺序、补充具体内容、完善技能列表】目录第一章:系统概述与版本演进第二章:完…...

Qwen2.5-7B-Instruct网络安全应用:智能威胁检测与分析
Qwen2.5-7B-Instruct网络安全应用:智能威胁检测与分析 1. 引言 网络安全运维团队每天都要面对海量的日志数据,传统的分析方法往往力不从心。安全工程师需要花费大量时间手动筛选日志、分析异常模式、编写威胁报告,这种重复性工作不仅效率低…...

麒麟V10系统下微信PC版安装与系统升级全攻略
1. 麒麟V10系统与微信PC版适配现状 最近两年国产操作系统发展迅猛,银河麒麟V10作为其中的佼佼者,已经能够流畅运行微信PC版。但很多用户在安装过程中还是会遇到各种"拦路虎"——找不到安装包、依赖缺失、版本冲突等问题层出不穷。 我实测发现&…...

深入剖析Ultralytics中RT-DETR的RepC3模块维度匹配问题
1. RT-DETR与RepC3模块的核心作用 RT-DETR作为Ultralytics推出的实时目标检测模型,其核心优势在于将DETR系列模型的Transformer架构与实时推理需求相结合。我在实际部署中发现,RepC3模块作为模型颈部的关键组件,承担着多尺度特征融合与通道维…...

ESP32 PlatformIO I/O扩展驱动:统一抽象与线程安全控制
1. 项目概述htcw_esp_io_expander是一个面向 ESP32 系列微控制器(特别是 ESP32-S2/S3/C3/C6)的 I/O 扩展驱动组件,其本质是将 Espressif 官方 ESP-IDF 组件仓库中io_expander模块封装为 PlatformIO 兼容的独立软件包。该组件并非全新实现&…...