ES-ES的基本概念
ES的基本概念
一、文档
1.1 文档相关概念
- ES是面向文档的,文档是所有可搜索数据的最小单位,可以对比理解为关系型数据库中的一条数据
- 日志文件中的一条日志信息
- 一本电影的具体信息/一张唱片的详细信息
- 文档会被序列化成JSON格式保存在ES中
- JSON对象由字段组成
- 每个字段都有对应的字段类型
- 格式比较灵活,不需要预先定义
- 字段的类型可以指定(在索引中的Mapping中指定),也可通过ES自动推算
- 支持数组和嵌套
- 每个文档都有一个Unique ID
- 可以自定义ID
- 也可以通过ES自动生成
1.2 文档的元数据
-
元数据,用于标注文档的相关信息
- _index:文档所属的索引名
- _type:文档所属的类型名,7.0开始每个索引只能创建一个type
- _id:文档的唯一ID
- _source:文档原始的JSON数据
- _all:整合所有的字段内容,7.0以后已经废除
- _version:文档的版本信息,在高并发的情况下会判断文档版本后再进行写入
- _score:相关性打分
{"_index" : "movies","_type" : "doc","_id" : "1","_score" : 14.69302,"_source" : {"year" : 1995,"@version" : "1","genre":["Adventure","Animation","Children","Comedy","Fantasy"],"id":"1","title":"Toy Story"} }
二、索引
2.1 索引的基本概念
- 索引是文档的容器,是一类文档的集合(可以理解为关系型数据库中的表)
- 索引(index)体现了逻辑空间的概念:每个索引都有自己的mapping定义,用于定义包含的文档的字段名和字段类型
- 索引的Mapping定于文档字段的类型
- Setting定义不同的数据分布
- 分片(shard)体现了物理空间的概念:索引中的数据分散在Shard上
- 索引(index)体现了逻辑空间的概念:每个索引都有自己的mapping定义,用于定义包含的文档的字段名和字段类型
2.2 与关系型数据库对比
| 关系型数据库 | ES |
|---|---|
| Table | Index |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | DSL |
三、节点
3.1 节点的基本概念
ES支持分布式部署,其分布式架构支持存储的水平扩容,并且提高了系统的可用性,部分节点停止服务,整个集群的服务不受影响。
ES的分布式架构,不通的集群通过不通的名字来区分,默认集群的名称为elasticsearch,通过配置文件的修改或者直接在启动命令中指定 -E cluster.name=mymain进行设定,一个集群支持一个到多个节点。
-
节点就是一个ES的实例
- 本质上就是一个Java进程
- 一台机器上可以运行多个ES进程
-
每个节点都有一个名字,通过配置文件配置或者启动的时候通过-E node.name=node1指定
-
每个节点在启动以后都会分配一个UUID,保存到data目录下
-
Master节点的概念
- 每个节点启动后,默认就是一个Master-eligible节点,可以通过node.master:false禁止
- Master-eligible节点可以参加选主流程,成为Master节点
- 当第一个节点启动的时候,它会将自己选举成Master节点
- 每个节点上都保存了集群的状态,只有Master节点才能修改集群的状态信息
- 集群状态,维护了一个集群中必要的信息:
- 所有的节点信息
- 所有的索引和其相关的Mapping和Setting信息
- 分片的路由信息
- 如果任意节点都能修改信息会导致数据的不一致性
- 集群状态,维护了一个集群中必要的信息:
-
Data节点
- 可以保存数据的节点叫做Data节点。负责保存分片数据,在数据扩展上起到了至关重要的作用
-
Coordinating节点
-
负责接受Client的请求,将请求分发到合适的节点,最终把结果汇集到一起
-
每个节点都默认起到Coodinating节点的职责
问题:当一个机器上启动多个实例的时候,谁是Master节点,谁是Data节点,谁是Coordinating节点,谁提供的9200端口
-
-
Ingest节点
-
主要用于对数据进行预处理。Ingest节点类似于Logstash中的Filter,可以对数据进行解析、转换和过滤等操作。当数据到达Ingest节点时,它会先对数据进行预处理,然后再将数据发送到Elasticsearch的Data节点进行索引和存储。
-
Hot&Warm节点
- 不通硬件配置的Data Node,用来实现Host & Warm架构,降低集群部署的成本
- Hot节点:这些节点通常用于存储和处理最新的、访问频率最高的数据,也就是所谓的“热”数据。Hot节点通常配置有高性能的硬件(如SSD固态硬盘),以确保快速的数据写入和检索速度。由于这些数据是最常被访问的,因此将它们存储在高性能的节点上可以确保最佳的用户体验。
- Warm节点:与Hot节点相比,Warm节点用于存储那些访问频率较低但仍然需要保留的数据。这些数据可能不再是最新的,但仍然具有一定的价值,需要被检索和分析。Warm节点通常配置有较低性能的硬件(如HDD机械硬盘),以降低存储成本。通过将不常访问的数据迁移到Warm节点,可以释放Hot节点的存储空间,使其能够更高效地处理新的、热门的数据。
-
Machine Learning 节点
- 负责跑机器学习的Job,做数据的异常检测
-
Tribe节点
- 5.3 开始使用Cross Cluster Search
- Tribr Node连接到不通的ES集群并支持将这些集群当成一个单独的集群处理
3.2 配置节点类型
-
开发环境中一个节点可以承担多种角色
-
生产环境中,应该设置单一的角色
节点类型 配置参数 默认值 master eligible node.master true data node.data true hot&warm node.attr.box_type 无 ingest node.ingest true coordinating only 无 每个节点默认都是coordinating节点,设置其他类型全部为false machine learning node.ml true
四、分片
4.1 分片的基本概念
-
在Elasticsearch中,分片(Shard)是数据的基本单位,每个索引在创建时都会被分成多个分片。这些分片是数据的容器,用于存储索引中的数据。每个分片实际上是一个独立的索引实例,包含了数据的一个完全独立的物理副本,这意味着每个分片都包含了数据的一个完整复制集。
-
分片的主要目的是为了在Elasticsearch集群中分发数据,以提供高可用性和负载均衡。通过将数据分散到不同的分片上,Elasticsearch可以在多个节点上并行处理数据,从而提高性能和可扩展性。每个分片都可以独立扩展,而不会影响其他分片的性能。此外,Elasticsearch还支持动态分片分配,这意味着可以自动将新的索引或文档分配到最合适的分片上。
-
在Elasticsearch中,分片可以跨多个节点分布,以提高数据的可用性和可扩展性。当集群扩容或缩小时,Elasticsearch会自动在节点间迁移分片,以使集群保持平衡。分片可以是主分片(primary shard)或者是复制分片(replica shard),主分片用于存储实际数据,而复制分片则是主分片的副本,用于提高数据的可靠性和可用性。
-
我们举例来说明分片的概念与作用:
- 分片是把一个索引分成多个小部分的过程。还是用图书馆作为例子,想象图书馆里的书太多了,一个书架放不下,于是你决定把书分散到多个书架上。每个书架就相当于一个分片。这样,当你想要找书时,你可以同时搜索多个书架,从而加快搜索速度。
4.2 分片的规划
在Elasticsearch中,分片的规划是非常重要的,因为它直接影响到集群的性能、扩展性和数据安全性。以下是一些建议,帮助你规划Elasticsearch中的分片:
- 考虑数据量:首先,你需要估计索引的总数据量。这将帮助你决定需要多少个分片来存储这些数据。每个分片的大小应该控制在一定的范围内,以避免过大或过小的分片导致性能问题。
- 节点和分片的关系:分片数应该与集群中的节点数相匹配。通常,建议将分片数设置为节点数的2-3倍,这样可以在节点故障时提供一定的容错能力。但是,也要避免分片数过多,以免给集群带来过大的压力。
- 主分片和副本:每个索引都应该有一个或多个主分片,以及零个或多个副本分片。主分片用于存储实际数据,而副本分片则是主分片的复制品,用于提高数据的可靠性和查询性能。副本分片的数量可以根据你的需求进行调整,通常建议设置为1-2个副本。
- 动态调整:随着数据量的增长和集群规模的变化,你可能需要动态地调整分片数。Elasticsearch提供了重新索引和分片调整的功能,允许你在不中断服务的情况下调整分片配置。
- 监控和调优:定期监控集群的健康状况、分片分布和性能指标是非常重要的。通过使用Elasticsearch提供的监控工具和API,你可以了解集群的实时状态,并根据需要进行调优。
- 考虑分片键:在创建索引时,你需要选择一个合适的分片键。分片键的选择将决定数据如何被分配到不同的分片中。选择一个合适的分片键可以确保数据的均匀分布和查询性能的优化。
五、倒排索引
在了解倒排索引之前我们先讲解一下什么是正排索引,正排索引就是根据ID查询具体的数据,可以类比于一本书的目录,我们可以快速的根据目录中的页码快速找到对应的内容,而假如现在我们有一个关键词,需要知道关键词所在页码,那么就需要一个关键词和页码的一个索引来帮助我们根据关键词找到对应的页码,这个索引就叫做倒排索引。
| 概念 | 图书 | 搜索引擎 |
|---|---|---|
| 正排索引 | 目录 | 文档ID到文档内容和单词的关联 |
| 倒排索引 | 索引页 | 单词到文档ID的关联 |
我们来举个正排索引和倒排索引的例子:
-
正排索引
文档ID 文档内容 1 Mastering ElasticSearch 2 ElasticSearch Server 3 ElasticSearch Client -
倒排索引
关键词 计数 文档ID:位置 Mastering 1 1:1 ElasticSearch 3 1:2,2:1,3:1 Server 1 2:2 Client 1 3:2
倒排索引的组成:
- 单词词典,记录所有文档的单词,记录单词到倒排列表的关联关系
- 单词词典一般比较大,可以通过B+树或者哈希链算法来实现,以满足高性能的插入和查询
- 倒排列表,记录单词对应的文档组合,由倒排索引项组成
- 倒排索引项
- 文档ID
- 词频TF,该单词在文档中出现的次数,用于相关性打分
- 位置,该单词在文档分词中的位置,用于语句搜索
- 偏移,记录单词的开始结束位置,用于高亮显示
- 倒排索引项
相关文章:

ES-ES的基本概念
ES的基本概念 一、文档 1.1 文档相关概念 ES是面向文档的,文档是所有可搜索数据的最小单位,可以对比理解为关系型数据库中的一条数据 日志文件中的一条日志信息一本电影的具体信息/一张唱片的详细信息 文档会被序列化成JSON格式保存在ES中 JSON对象由…...

排序算法——快速排序的非递归写法
快速排序的非递归 我们写快速排序的时候,通常用的递归的方法实现快速排序,那么有没有非递归的方法实现快速排序呢?肯定是有的。思想还是一样的,不过非递归是看似是非递归其实还是递归。 思路解释 快速排序的非递归使用的是栈这…...
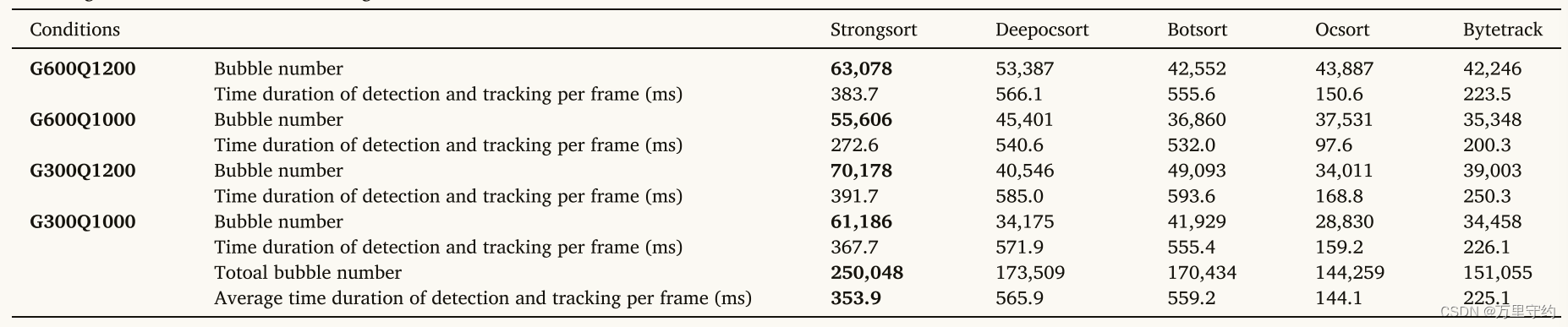
【论文阅读】基于人工智能目标检测与跟踪技术的过冷流沸腾气泡特征提取
Bubble feature extraction in subcooled flow boiling using AI-based object detection and tracking techniques 基于人工智能目标检测与跟踪技术的过冷流沸腾气泡特征提取 期刊信息:International Journal of Heat and Mass Transfer 2024 级别:EI检…...
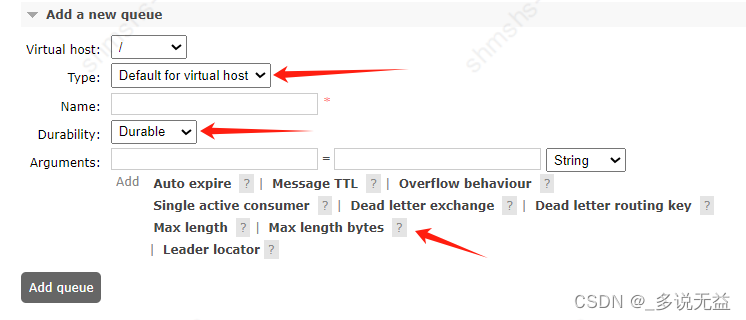
RabbitMQ讲解与整合
RabbitMq安装 类型概念 租户 RabbitMQ 中有一个概念叫做多租户,每一个 RabbitMQ 服务器都能创建出许多虚拟的消息服务器,这些虚拟的消息服务器就是我们所说的虚拟主机(virtual host),一般简称为 vhost。 每一个 vhos…...

python 基础知识点(蓝桥杯python科目个人复习计划56)
今日复习内容:做题 例题1:最小的或运算 问题描述:给定整数a,b,求最小的整数x,满足a|x b|x,其中|表示或运算。 输入格式: 第一行包括两个正整数a,b; 输出格式&#…...

【vue】vue中数据双向绑定原理/响应式原理,mvvm,mvc、mvp分别是什么
关于 vue 的原理主要有两个重要内容,分别是 mvvm 数据双向绑定原理,和 响应式原理 MVC(Model-View-Controller): Model(模型):表示应用程序的数据和业务逻辑。View(视图&…...
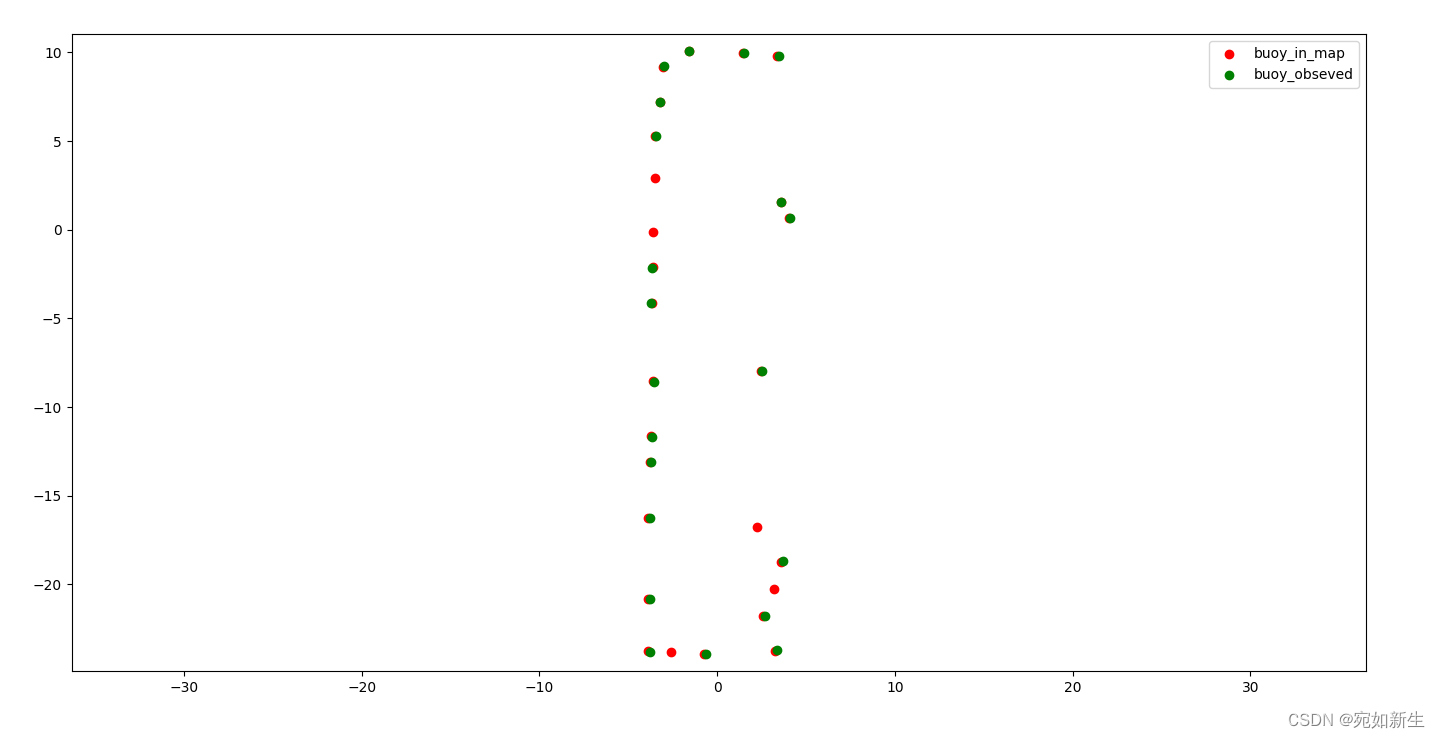
基于反光柱特征的激光定位算法思路
目录 1. 识别反光柱2. 数据关联2.1 基于几何形状寻找匹配2.2 暴力寻找匹配 3. 位姿估计(最小二乘求解)4. 问题4.1 精度问题4.2 快速旋转时定位较差 1. 识别反光柱 反光柱是特殊材料制成,根据激光雷达对反光材料扫描得到的反射值来提取特征。…...

CSM是什么意思?
CSM(Customer Service Management)是企业客户服务管理的信息化(IT)解决方案架构。本着以客户为中心的管理理念,搭建企业客户服务管理平台,实现企业以客户为中心的管理时代的竞争战略。 CSM的核心是以客户为中心,实现对…...

ES6 面试题
1. const、let 和 var 的区别是什么? 答案: var 声明的变量是函数作用域或全局作用域,而 const 和 let 声明的变量是块级作用域。使用 var 声明的变量可以被重复声明,而 const 和 let 不允许重复声明同一变量。const 声明的变量…...
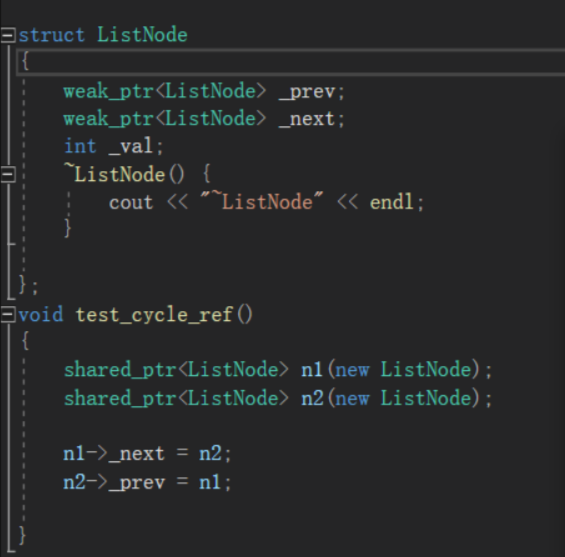
智能指针(C++)
目录 一、智能指针是什么 二、为什么需要智能指针 三、智能指针的使用和原理 3.1、RALL 3.2 智能指针的原理 3.3、智能指针的分类 3.3.1、auto_ptr 3.3.2、unique_ptr 3.3.3、shared_ptr 3.2.4、weak_ptr 一、智能指针是什么 在c中,动态内存的管理式通过一…...

社区店商业模式探讨:如何创新并持续盈利?
在竞争激烈的商业环境中,社区店要想获得成功并持续盈利,需要不断创新和优化商业模式。 作为一名开鲜奶吧5年的创业者,我将分享一些关于社区店商业模式创新的干货和见解,希望能给想开实体店或创业的朋友们提供有价值的参考。 1、…...
一些可以访问gpt的方式
1、Coze扣子是新一代 AI 大模型智能体开发平台。整合了插件、长短期记忆、工作流、卡片等丰富能力,扣子能帮你低门槛、快速搭建个性化或具备商业价值的智能体,并发布到豆包、飞书等各个平台。https://www.coze.cn/ 2、https://poe.com/ 3、插件阿里…...

springer模板参考文献不显示
Spring期刊模板网站,我的问题是23年12月的版本 https://www.springernature.com/gp/authors/campaigns/latex-author-support/see-where-our-services-will-take-you/18782940 参考文献显示问好,在sn-article.tex文件中,这个sn-mathphys-num…...
【【C语言简单小题学习-1】】
实现九九乘法表 // 输出乘法口诀表 int main() {int i 0;int j 0;for (i 1; i < 9; i){for (j 1; j < i;j)printf("%d*%d%d ", i , j, i*j);printf("\n"); }return 0; }猜数字的游戏设计 #define _CRT_SECURE_NO_WARNINGS 1 #include<stdi…...

mongoDB 优化(1)索引
1、创建复合索引(多字段) db.collection_test1.createIndex({deletedVersion: 1,param: 1,qrYearMonth: 1},{name: "deletedVersion_1_param_1_qrYearMonth_1",background: true} ); 2、新增索引前: 执行查询: mb.r…...
stable diffusion webUI之赛博菩萨【秋葉】——工具包新手安裝与使用教程
stable diffusion webUI之赛博菩萨【秋葉】——工具包新手安裝与使用教程 AI浪潮袭来,还是学习学习为妙赛博菩萨【秋葉】简介——(葉ye,四声,同叶)A绘世启动器.exe(sd-webui-aki-v4.6.x)工具包安…...

鸿蒙应用程序包安装和卸载流程
开发者 开发者可以通过调试命令进行应用的安装和卸载,可参考多HAP的调试流程。 图1 应用程序包安装和卸载流程(开发者) 多HAP的开发调试与发布部署流程 多HAP的开发调试与发布部署流程如下图所示。 图1 多HAP的开发调试与发布部署流程 …...

C语言数组全面解析:从初学到精通
数组 1. 前言2. 一维数组的创建和初始化3. 一维数组的使用4. 一维数组在内存中的存储5. 二维数组的创建和初始化6. 二维数组的使用7. 二维数组在内存中的存储8. 数组越界9. 数组作为函数参数10. 综合练习10.1 用函数初始化,逆置,打印整型数组10.2 交换两…...
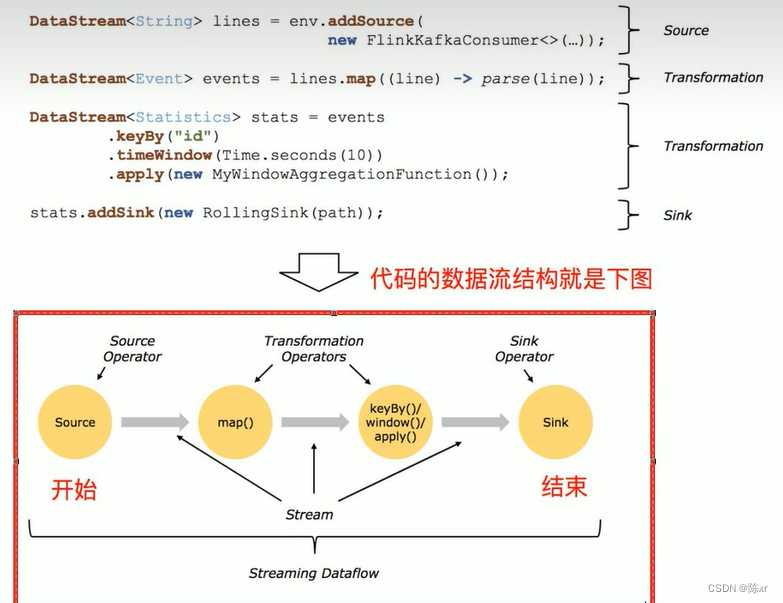
2024-02-28(Kafka,Oozie,Flink)
1.Kafka的数据存储形式 一个主题由多个分区组成 一个分区由多个segment段组成 一个segment段由多个文件组成(log,index(稀疏索引),timeindex(根据时间做的索引)) 2.读数据的流程 …...

Window下编写的sh文件在Linux/Docker中无法使用
Window下编写的sh文件在Linux/Docker中无法使用 一、sh文件目的1.1 初始状态1.2 目的 二、过程与异常2.1 首先获取标准ubuntu20.04 - 正常2.2 启动ubuntu20.04容器 - 正常2.3 执行windows下写的preInstall文件 - 报错 三、检查和处理3.1 评估异常3.2 处理异常3.3 调整后运行测试…...

Windows任务栏定制终极指南:7+ Taskbar Tweaker完全掌控你的桌面体验
Windows任务栏定制终极指南:7 Taskbar Tweaker完全掌控你的桌面体验 【免费下载链接】7-Taskbar-Tweaker A Windows taskbar customization tool for Windows 7, Windows 8, and Windows 10 项目地址: https://gitcode.com/gh_mirrors/7t/7-Taskbar-Tweaker …...

Fish Speech 1.5零样本语音克隆实操:10秒参考音频生成中英日韩多语种语音
Fish Speech 1.5零样本语音克隆实操:10秒参考音频生成中英日韩多语种语音 想不想让AI用你朋友的声音说一段话?或者用某个电影角色的音色,为你朗读一段外语新闻?过去,这需要专业的录音设备和复杂的模型训练。但现在&am…...

Mac系统下Jmeter压力测试工具从零配置到实战:JDK8安装+汉化+电商压测案例
1. 为什么Mac用户需要Jmeter压力测试 做电商的朋友应该都遇到过这样的场景:大促活动刚开始,页面突然卡死无法下单;秒杀商品刚上架,库存瞬间清零却出现超卖。这些问题往往源于系统在高并发场景下的性能瓶颈。而Jmeter正是解决这类问…...

Flink技术实践-实时流中的脏数据治理
一、背景介绍在大数据实时计算领域,脏数据就像一颗定时炸弹,随时可能引爆业务系统 —— 轻则导致计算结果错误,重则引发线上故障,影响业务活动。某电商平台因订单金额字段脏数据(负数、超大值)导致实时销售…...

三步搞定Windows远程桌面多用户配置:告别“不支持“困扰
三步搞定Windows远程桌面多用户配置:告别"不支持"困扰 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 远程桌面多用户配置是许多Windows用户面临的共同挑战,特别是当系统提示&quo…...

如何在5分钟内从视频中提取硬字幕?Video-subtitle-extractor完整教程
如何在5分钟内从视频中提取硬字幕?Video-subtitle-extractor完整教程 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域…...

OpenClaw语音交互扩展:百川2-13B-4bits量化模型+Whisper实时转录
OpenClaw语音交互扩展:百川2-13B-4bits量化模型Whisper实时转录 1. 为什么需要语音交互能力 上周整理项目文档时,我发现自己频繁在键盘操作和语音会议之间切换——右手握着鼠标整理文件,左手拿着手机听语音消息,效率低到令人崩溃…...

OpenClaw技能扩展:Kimi-VL-A3B-Thinking自动化内容审核方案
OpenClaw技能扩展:Kimi-VL-A3B-Thinking自动化内容审核方案 1. 为什么需要自动化内容审核 作为一个长期运营技术博客的自媒体人,我最近遇到了一个头疼的问题:随着内容积累越来越多,人工审核历史文章的合规性变得异常耗时。尤其是…...

开源大模型实战:StructBERT中文句子相似度工具在舆情监测中的关键词语义泛化应用
开源大模型实战:StructBERT中文句子相似度工具在舆情监测中的关键词语义泛化应用 1. 引言 你有没有遇到过这样的问题?在社交媒体上,用户对同一个产品功能,会用完全不同的词语来表达。比如,有人说“手机电池很耐用”&…...

Jimeng LoRA应用案例:快速测试不同Epoch版本,找到最佳训练效果
Jimeng LoRA应用案例:快速测试不同Epoch版本,找到最佳训练效果 1. 项目背景与核心价值 在LoRA模型训练过程中,我们常常面临一个关键问题:**如何确定哪个训练阶段的模型效果最好?**传统方法需要反复加载不同Epoch版本…...