探索前景:机器学习中常见优化算法的比较分析
目录
一、介绍
二、技术背景
三、相关代码
四、结论
一、介绍
优化算法在机器学习和深度学习中至关重要,可以最小化损失函数,从而改善模型的预测。每个优化器都有其独特的方法来导航损失函数的复杂环境以找到最小值。本文探讨了一些最常见的优化算法,包括 Adadelta、Adagrad、Adam、AdamW、SparseAdam、Adamax、ASGD、LBFGS、NAdam、RAdam、RMSprop、Rprop 和 SGD,并提供了对其机制、优势和应用的见解。

在寻求学习的过程中,通过优化的每一步不仅会带来更好的模型,而且会带来对旅程本身的更深入理解。
二、技术背景
大多数常用的方法已经得到支持,并且接口足够通用,因此将来也可以轻松集成更复杂的方法。
- 随机梯度下降 (SGD):随机梯度下降 (SGD) 是最基本但最有效的优化算法之一。它以与目标函数相对于参数的梯度相反的方向更新模型的参数。学习率决定了向最小值迈出的步数的大小。虽然 SGD 对于大型数据集来说简单而高效,但收敛速度可能很慢,并且可能在最小值附近振荡。
- 动量和涅斯捷罗夫加速梯度 (NAG):为了克服SGD的振荡和缓慢收敛,引入了动量和涅斯捷罗夫加速梯度(NAG)技术。它们通过将先前更新向量的一小部分添加到当前更新中来合并动量的概念。这种方法有助于在相关方向上加速 SGD 并抑制振荡,使其比标准 SGD 更快、更稳定。
- Adagrad:Adagrad 通过使学习率适应参数,解决了适用于所有参数的全局学习率的限制。它对与频繁出现的要素相关的参数执行较小的更新,对与不频繁出现的要素相关的参数执行较大的更新。这种自适应学习率使 Adagrad 特别适用于稀疏数据。
- Adadelta:Adadelta 是 Adagrad 的扩展,旨在降低其激进的、单调下降的学习率。Adadelta 不是累积所有过去的平方梯度,而是将累积的过去梯度的窗口限制为固定大小,使其对学习制度的变化更可靠。
- RMSprop:RMSprop 修改了 Adagrad 的方法,通过引入衰减因子来累积以前的梯度,从而为最近的梯度赋予更多的权重。这使得它更适合在线和非平稳问题,类似于 Adadelta,但实现方式不同。
- Adam(自适应力矩估计):Adam 结合了 Adagrad 和 RMSprop 的优势,根据梯度的第一和第二矩调整每个参数的学习速率。该优化器因其在实践中的有效性而被广泛采用,尤其是在深度学习应用中。
- AdamW:AdamW 是 Adam 的一个变体,它将权重衰减与优化步骤分离。这种修改提高了性能和训练稳定性,尤其是在深度学习模型中,其中权重衰减被用作正则化的一种形式。
- SparseAdam:SparseAdam 是 Adam 的一个变体,旨在更有效地处理稀疏梯度。它使 Adam 算法仅在必要时更新模型参数,因此对于自然语言处理 (NLP) 和其他具有稀疏数据的应用程序特别有用。
- Adamax:Adamax 是基于无穷范数的 Adam 的变体。它对梯度中的噪声更鲁棒,并且在某些情况下可能比 Adam 更稳定,尽管它不太常用。
- ASGD(平均随机梯度下降):ASGD 会随时间推移对参数值进行平均,这可以在训练结束时实现更平滑的收敛。此方法对于具有嘈杂或波动梯度的任务特别有用。
- LBFGS(有限内存 Broyden-Fletcher-Goldfarb-Shanno):LBFGS 是准牛顿方法系列中的一种优化算法。它近似于 Broyden-Fletcher-Goldfarb-Shanno (BFGS) 算法,使用有限的内存量。由于其内存效率,它非常适合中小型优化问题。
- NAdam(涅斯捷罗夫加速自适应力矩估计):NAdam 将 Nesterov 加速梯度与 Adam 相结合,将 Nesterov 动量的 lookahead 属性纳入 Adam 的框架中。这种组合通常可以提高性能并加快收敛速度。
- 拉丹(纠正亚当): RAdam 在 Adam 优化器中引入了一个整流项来动态调整自适应学习率,解决了一些与收敛速度和泛化性能相关的问题。它提供了更稳定和一致的优化环境。
- Rprop(弹性反向传播):Rprop 仅使用梯度符号调整每个参数的更新,忽略其幅度。这使得它对梯度幅度变化很大但不太适合小批量学习或深度学习应用的问题非常有效。
三、相关代码
创建一个完整的 Python 示例来演示如何在合成数据集上使用这些优化器涉及几个步骤。我们将使用一个简单的回归问题作为示例,其中的任务是从特征预测目标变量。此示例将涵盖创建合成数据集、使用 PyTorch 定义简单神经网络模型、使用每个优化器训练此模型,以及绘制训练指标以比较其性能。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error# Generate synthetic data
np.random.seed(42)
X = np.random.rand(1000, 1) * 5 # Features
y = 2.7 * X + np.random.randn(1000, 1) * 0.9 # Target variable with noise# Convert to torch tensors
X = torch.from_numpy(X).float()
y = torch.from_numpy(y).float()# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)class LinearRegressionModel(nn.Module):def __init__(self):super(LinearRegressionModel, self).__init__()self.linear = nn.Linear(1, 1) # One input feature and one outputdef forward(self, x):return self.linear(x)def train_model(optimizer_name, learning_rate=0.01, epochs=100):model = LinearRegressionModel()criterion = nn.MSELoss()# Select optimizeroptimizers = {"SGD": optim.SGD(model.parameters(), lr=learning_rate),"Adadelta": optim.Adadelta(model.parameters(), lr=learning_rate),"Adagrad": optim.Adagrad(model.parameters(), lr=learning_rate),"Adam": optim.Adam(model.parameters(), lr=learning_rate),"AdamW": optim.AdamW(model.parameters(), lr=learning_rate),"Adamax": optim.Adamax(model.parameters(), lr=learning_rate),"ASGD": optim.ASGD(model.parameters(), lr=learning_rate),"NAdam": optim.NAdam(model.parameters(), lr=learning_rate),"RAdam": optim.RAdam(model.parameters(), lr=learning_rate),"RMSprop": optim.RMSprop(model.parameters(), lr=learning_rate),"Rprop": optim.Rprop(model.parameters(), lr=learning_rate),}if optimizer_name == "LBFGS":optimizer = optim.LBFGS(model.parameters(), lr=learning_rate, max_iter=20, history_size=100)else:optimizer = optimizers[optimizer_name]train_losses = []for epoch in range(epochs):def closure():if torch.is_grad_enabled():optimizer.zero_grad()outputs = model(X_train)loss = criterion(outputs, y_train)if loss.requires_grad:loss.backward()return loss# Special handling for LBFGSif optimizer_name == "LBFGS":optimizer.step(closure)with torch.no_grad():train_losses.append(closure().item())else:# Forward passy_pred = model(X_train)loss = criterion(y_pred, y_train)train_losses.append(loss.item())# Backward pass and optimizeoptimizer.zero_grad()loss.backward()optimizer.step()# Test the modelmodel.eval()with torch.no_grad():y_pred = model(X_test)test_loss = mean_squared_error(y_test.numpy(), y_pred.numpy())return train_losses, test_lossoptimizer_names = ["SGD", "Adadelta", "Adagrad", "Adam", "AdamW", "Adamax", "ASGD", "LBFGS", "NAdam", "RAdam", "RMSprop", "Rprop"]plt.figure(figsize=(14, 10))for optimizer_name in optimizer_names:train_losses, test_loss = train_model(optimizer_name, learning_rate=0.01, epochs=100)plt.plot(train_losses, label=f"{optimizer_name} - Test Loss: {test_loss:.4f}")plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training Loss by Optimizer")
plt.legend()
plt.show()Notes:
- 为简单起见,所有优化器都使用 0.01 的默认学习率。调整学习率和其他超参数可能会导致不同的性能结果。
- 为了完整性,包含优化器,但通常用于具有稀疏梯度的模型,这可能不适用于此简单线性回归示例。
SparseAdam - 由于其行搜索方法,优化器需要的训练循环略有不同。提供的训练功能可能需要修改才能正确使用 。
LBFGSLBFGS
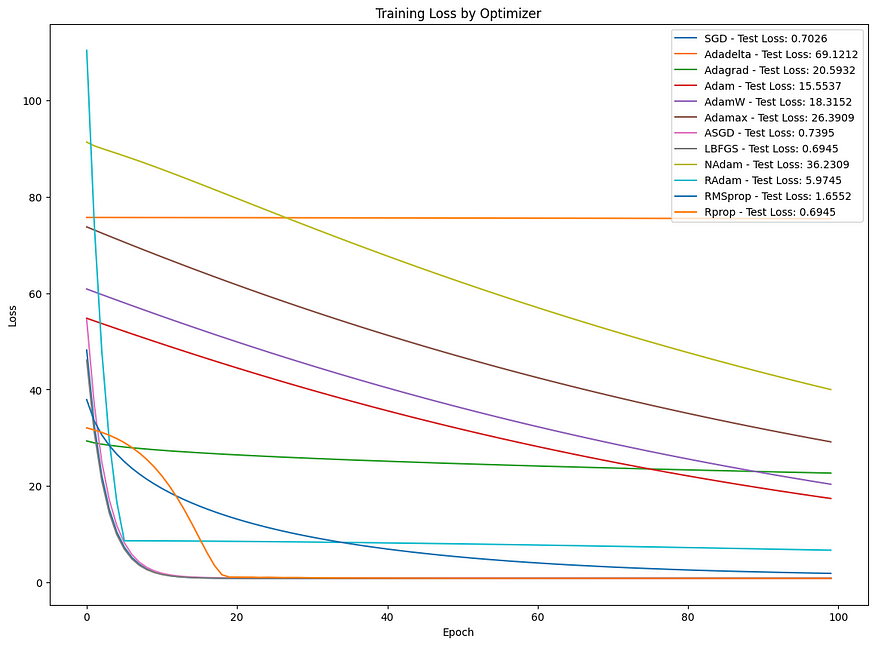
此示例基本比较了不同优化器在简单合成数据集上的表现。对于更复杂的模型和数据集,优化器之间的差异可能更明显,优化器的选择会显著影响模型性能。
四、结论
总之,每个优化器都有其优点和缺点,优化器的选择可以显着影响机器学习模型的性能。选择取决于具体问题、数据的性质和模型体系结构。了解这些优化器的基本机制和特征对于有效地将它们应用于各种机器学习挑战至关重要。
相关文章:
探索前景:机器学习中常见优化算法的比较分析
目录 一、介绍 二、技术背景 三、相关代码 四、结论 一、介绍 优化算法在机器学习和深度学习中至关重要,可以最小化损失函数,从而改善模型的预测。每个优化器都有其独特的方法来导航损失函数的复杂环境以找到最小值。本文探讨了一些最常见的优化算法&…...

基于MRI的阿尔兹海默症病情预测
《阿尔兹海默症病情预测系统:老年痴呆患者的福音》 引言项目背景和意义数据介绍与分析模型介绍模型训练与评估模型应用与展望 引言 阿尔兹海默症(Alzheimer’s Disease)是一种常见的老年疾病,给患者及其家庭带来了巨大的困扰和负…...

高维中介数据: 联合显着性(JS)检验法
摘要 中介分析在流行病学和临床试验中越来越受到关注。在现有的中介分析方法中,流行的联合显着性(JS)检验会产生过于保守的 I 类错误率,因此功效较低。但是,如果在使用 JS 测试高维中介假设时,可以准确控制…...

冒泡排序 和 qsort排序
目录 冒泡排序 冒泡排序部分 输出函数部分 主函数部分 总代码 控制台输出显示 总代码解释 冒泡排序优化 冒泡排序 主函数 总代码 代码优化解释 qsort 排序 qsort 的介绍 使用qsort排序整型数据 使用qsort排序结构数据 冒泡排序 首先,我先介绍我的冒泡…...

asp.net core webapi接收application/x-www-form-urlencoded和form-data参数
框架:asp.net core webapiasp.net core webapi接收参数,请求变量设置 目录 接收multipart/form-data、application/x-www-form-urlencoded类型参数接收URL参数接收上传的文件webapi接收json参数完整控制器,启动类参考Program.cs 接收multipar…...
程序环境和预处理(2)
文章目录 3.2.7 命名约定 3.3 #undef3.4 命令行定义3.5 条件编译3.6 文件包含3.6.1 头文件被包含的方式3.6.2 嵌套文件包含 4. 其他预处理指令 3.2.7 命名约定 一般来讲函数和宏的使用语法很相似,所以语言本身没法帮我们区分二者,那我们平时的一个习惯是…...

Redis安全加固策略:绑定Redis监听的IP地址 修改默认端口 禁用或者重命名高危命令
Redis安全加固策略:绑定Redis监听的IP地址 & 修改默认端口 & 禁用或者重命名高危命令 1.1 绑定Redis监听的IP地址1.2 修改默认端口1.3 禁用或者重命名高危命令1.4 附:redis配置文件详解(来源于网络) 💖The Beg…...
Vuepress的使用
介绍 将markdown静态资源转换成html。 动态资源的转换还有很多,为什么要使用Vuepress? 目录分析 项目配置 详情 具体配置请看文档 插件配置 vuepress-theme-vdoing 主题插件 npm install vuepress-theme-vdoing -D先安装依赖配置主题 使用vuep…...

docker安装php7.4安装
容器 docker pull centos:centos7 docker run -dit -p9100:9100 --name“dade” --privilegedtrue centos:centos7 /usr/sbin/init 一、安装前库文件和工具准备 1、首先安装 EPEL 源 yum -y install epel-release2.安装 REMI 源 yum -y install http://rpms.remirepo.net/en…...

曲线生成 | 图解Dubins曲线生成原理(附ROS C++/Python/Matlab仿真)
目录 0 专栏介绍1 什么是Dubins曲线?2 Dubins曲线原理2.1 坐标变换2.2 单步运动公式2.3 曲线模式 3 Dubins曲线生成算法4 仿真实现4.1 ROS C实现4.2 Python实现4.3 Matlab实现 0 专栏介绍 🔥附C/Python/Matlab全套代码🔥课程设计、毕业设计、…...

「Vue3系列」Vue3 组件
文章目录 一、Vue3 组件二、Vue3 组件实例三、Vue3 官方组件四、Vue3 常用组件五、相关链接 一、Vue3 组件 Vue3 是 Vue.js 的最新版本,它引入了许多新的特性和改进。在 Vue3 中,组件是构建应用程序的核心部分,它们可以重用、组合和嵌套。Vu…...
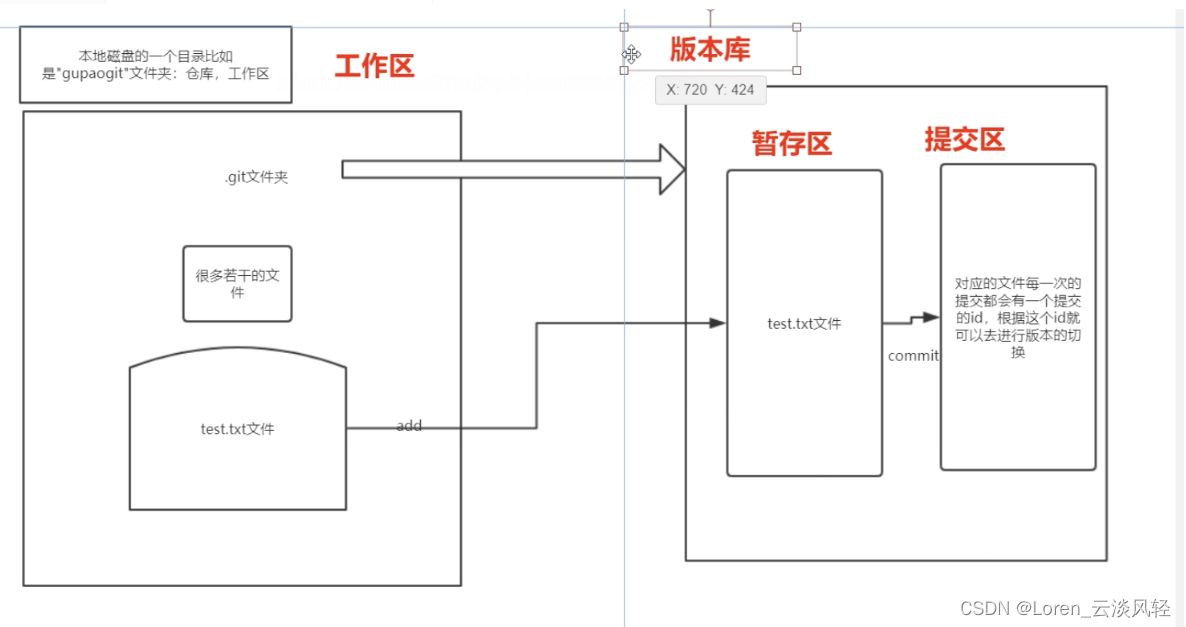
Git实战(2)
git work flow ------------------------------------------------------- ---------------------------------------------------------------- 场景问题及处理 问题1:最近提交了 a,b,c,d记录,想把b记录删掉其他提交记录保留: git reset …...
Java ElasticSearch-Linux面试题
Java ElasticSearch-Linux面试题 前言1、守护线程的作用?2、链路追踪Skywalking用过吗?3、你对G1收集器了解吗?4、你们项目用的什么垃圾收集器?5、内存溢出和内存泄露的区别?6、什么是Spring Cloud Bus?7、…...

微信小程序通过服务器控制ESP8266
声明 本文实现了ESP8266、微信小程序、个人服务器三者互相通信,并且小程序能发消息给微信用户 本文所有代码和步骤均为亲测有效 以下代码均为从网上搜索到后本人加以改动的,并非完全原创,若作者希望删除可联系我 ESP8266与个人服务器通信 ESP8266配置 通过串口通信使用…...

题目 1434: 蓝桥杯历届试题-回文数字
题目描述: 观察数字:12321,123321 都有一个共同的特征,无论从左到右读还是从右向左读,都是相同的。这样的数字叫做:回文数字。 本题要求你找到一些5位或6位的十进制数字。满足如下要求: 该数字的各个数位…...

访问修饰符、Object(方法,使用、equals)、查看equals底层、final--学习JavaEE的day15
day15 一、访问修饰符 含义: 修饰类、方法、属性,定义使用的范围 理解:给类、方法、属性定义访问权限的关键字 注意: 1.修饰类只能使用public和默认的访问权限 2.修饰方法和属性可以使用所有的访问权限 访问修饰符本类本包…...
的性能(来自OpenAI DevDay 会议))
『大模型笔记』最大化大语言模型(LLM)的性能(来自OpenAI DevDay 会议)
最大化大语言模型(LLM)的性能(来自OpenAI DevDay 会议) 文章目录 一. 内容介绍1.1. 优化的两个方向(上下文优化和LLM优化)1.2. 提示工程:从哪里开始1.3. 检索增强生成:拓展知识边界1.4. 微调:专属定制二. 参考文献一. 内容介绍 简述如何以可扩展的方式把大语言模型(LLMs)…...

深度学习:开启你的AI探索之旅
在这个信息爆炸的时代,人工智能(AI)已经渗透到我们生活的方方面面,从智能语音助手到自动驾驶汽车,从智能推荐系统到医疗影像诊断,AI的身影无处不在。而深度学习,作为AI领域的一大核心技术,更是引领着这场科技革命的浪潮。那么,如何入门深度学习,踏上这趟充满挑战与机…...
第十四届蓝桥杯大赛B组 JAVA 蜗牛 (递归剪枝)
题目描述: 这天,一只蜗牛来到了二维坐标系的原点。 在 x 轴上长有 n 根竹竿。它们平行于 y 轴,底部纵坐标为 0,横坐标分别为 x1, x2, …, xn。竹竿的高度均为无限高,宽度可忽略。蜗牛想要从原点走到第 n 个竹竿的底部也…...

基于React低代码平台开发:构建高效、灵活的应用新范式
文章目录 一、React与低代码平台的结合优势二、基于React的低代码平台开发挑战三、基于React的低代码平台开发实践四、未来展望《低代码平台开发实践:基于React》编辑推荐内容简介作者简介目录前言为什么要写这本书 读者对象如何阅读本书 随着数字化转型的深入&…...

低代码Agent平台是怎样实现自动化流程编排的?深度拆解2026企业级智能体底层架构
站在2026年这个时间节点回看,企业数字化转型已从“自动化”全面进化为“智能化”。 过去那种依赖硬编码、高频维护的线性脚本正迅速退场,取而代之的是具备深度推理能力的低代码Agent平台。 很多技术同行在实践中经常问到一个核心问题: 低代码…...

微生物代谢建模与优化:从GEMs构建到工业应用
1. 微生物代谢建模与优化的协同设计方法在工业生物技术领域,微生物代谢建模已成为优化生物转化过程的核心工具。通过构建基因组尺度代谢模型(GEMs),研究人员能够系统分析微生物细胞内数百至数千个酶催化反应的相互作用网络。以丁酸…...

Keil串口调试与程序共享端口的解决方案
1. 串口调试中的端口复用问题解析 在嵌入式开发过程中,使用Keil Vision的Monitor模式进行硬件调试时,开发板上的串口资源往往会被调试器独占。这个问题困扰过不少开发者——当我们需要在调试过程中通过串口输入测试数据时,却发现串口已经被Mo…...

大气层Atmosphere系统深度解析:解锁Switch潜能的终极技术指南
大气层Atmosphere系统深度解析:解锁Switch潜能的终极技术指南 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable Atmosphere大气层系统作为Nintendo Switch最稳定、功能最丰富的定…...

深度揭秘:如何在Mac上无痛备份微信聊天记录
深度揭秘:如何在Mac上无痛备份微信聊天记录 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因微信聊天记录丢失而懊恼?那些珍贵的对话、重…...

嵌入式C语言开发中的三大致命陷阱
很多人刚开始学习C语言时,会觉得: 会指针 会结构体 会寄存器操作 能驱动外设 似乎就已经掌握了嵌入式开发。 但真正进入项目后才会发现: 嵌入式开发最难的,从来不是语法,而是“代码与硬件现实世界之间的耦合”。 同样一句代码: 在PC上可能只是运行错误; 在单片机里却可…...

《男人来自火星,女人来自金星4:生活篇》第1-3章深度解读:大脑化学物质如何决定两性关系
前言 《男人来自火星,女人来自金星》系列自问世以来,全球销量已超过5000万册,被翻译成40多种语言,成为近几十年来最畅销的两性关系书籍之一。作为系列的第四部,《生活篇》(也被称为《健康篇》)从…...

基于RK平台的智慧出行方案:从芯片选型到车规级开发的实战指南
1. 项目概述:当“智慧出行”遇上“RK平台”最近几年,如果你关注汽车电子或者物联网领域,一定对“智慧出行”这个词不陌生。它早已不是科幻电影里的概念,而是真真切切地走进了我们的生活,从智能座舱里流畅的语音交互、多…...

抖音小店搜索排名规则及优化方法
一、抖音商城搜索排名规则1.商品相关性:商品标题、关键词与用户搜索词的匹配程度是重要因素。精准匹配的商品会在搜索结果中更靠前展示。例如,用户搜索"夏季连衣裙”,标题中明确包含该关键词且商品属性也相符的连衣裙,会优先被展示。商品…...

如何在Windows 10/11上完美使用PS3手柄:DsHidMini虚拟HID驱动终极指南
如何在Windows 10/11上完美使用PS3手柄:DsHidMini虚拟HID驱动终极指南 【免费下载链接】DsHidMini Virtual HID Mini-user-mode-driver for Sony DualShock 3 Controllers 项目地址: https://gitcode.com/gh_mirrors/ds/DsHidMini 你是否还在为Windows系统无…...