大模型(LLM)的token学习记录-I
文章目录
- 基本概念
- 什么是token?
- 如何理解token的长度?
- 使用openai tokenizer 观察token的相关信息
- open ai的模型
- token的特点
- token如何映射到数值?
- token级操作:精确地操作文本
- token 设计的局限性
- tokenization
- token 数量对LLM 的影响
- 训练模型参数量与训练数据量统计
- 影响模型效果的因素有哪些?
- 参考
基本概念
什么是token?
- 在 LLM 中,token代表模型可以理解和生成的最小意义单位,是 LLM 进行处理的最小单元。
- 根据所使用的特定标记化【Tokenization】方案,token可以表示单词、单词的一部分,甚至只表示字符。采用的方案由模型的类型和大小决定
- token被赋予数值或标识符,并按序列或向量排列,并被输入或从模型中输出,是模型的语言构件。
- 模型理解这些token之间的统计关系,并擅长做token的接龙
- token化是将输入和输出文本分割成可以由LLM AI模型处理的较小单元的过程
- token作为原始文本数据和 LLM 可以使用的数字表示之间的桥梁。LLM使用token来确保文本的连贯性和一致性,有效地处理各种任务,如写作、翻译和回答查询。
如何理解token的长度?
下面是一些有用的经验法则,可以帮助理解token的长度:
- 1 token ~= 4 chars in English
- 1 token ~= ¾ words
- 100 tokens ~= 75 words
- 1-2 句子 ~= 30 tokens
- 1 段落 ~= 100 tokens
- 1,500 单词 ~= 2048 tokens
- 一个unicode字符可以拆分为多个token
使用openai tokenizer 观察token的相关信息
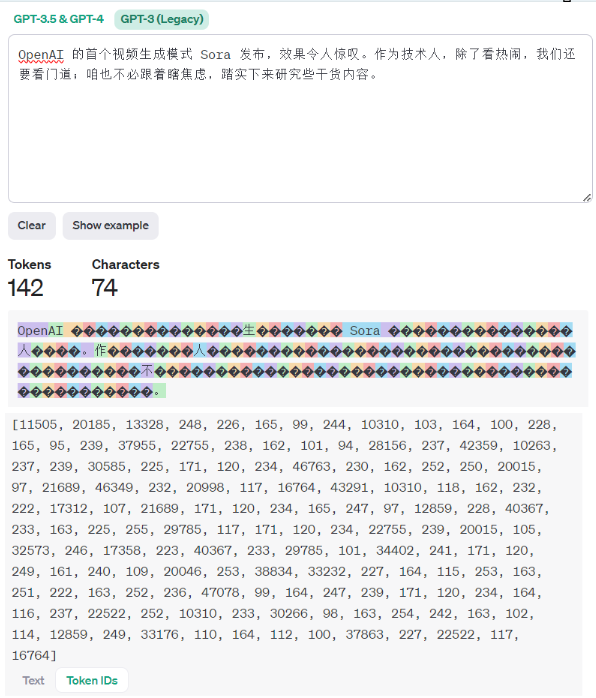
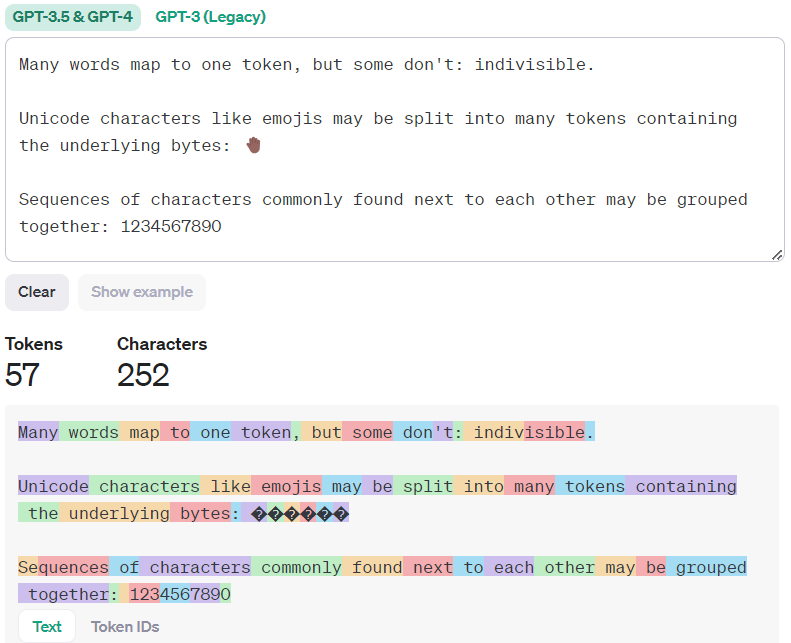
可以通过https://platform.openai.com/tokenizer 来观察token 的相关信息。
可以看到,GPT-3.5&GPT-4 与 GPT-3(Legacy) 模型tokenizer方案是不同的,前者产生的token数据量变少,针对中文的处理更加合理。

open ai的模型
OpenAI API由一组不同的模型提供支持,这些模型具有不同的功能和价位
GPT-4是一个大型多模态模型(接受文本或图像输入和输出文本),由于其更广泛的一般知识和先进的推理能力,它可以比我们以前的任何模型都更准确地解决难题。
| MODEL | DESCRIPTION |
|---|---|
| GPT-4 and GPT-4 Turbo | A set of models that improve on GPT-3.5 and can understand as well as generate natural language or code |
| GPT-3.5 Turbo | A set of models that improve on GPT-3.5 and can understand as well as generate natural language or code |
| DALL·E | A model that can generate and edit images given a natural language prompt |
| TTS | A set of models that can convert text into natural sounding spoken audio |
| Whisper | A model that can convert audio into text |
| Embeddings | A set of models that can convert text into a numerical form |
| Moderation | A fine-tuned model that can detect whether text may be sensitive or unsafe |
| GPT base | A set of models without instruction following that can understand as well as generate natural language or code |
| Deprecated | A full list of models that have been deprecated along with the suggested replacement |
token的特点
token如何映射到数值?
词汇表将token映射到唯一的数值表示。LLM 使用数字输入,因此词汇表中的每个标记都被赋予一个唯一标识符或索引。这种映射允许 LLM 将文本数据作为数字序列进行处理和操作,从而实现高效的计算和建模。
为了捕获token之间的意义和语义关系,LLM 采用token编码技术。这些技术将token转换成称为嵌入的密集数字表示。嵌入式编码语义和上下文信息,使 LLM 能够理解和生成连贯的和上下文相关的文本。像transformer这样的体系结构使用self-attention机制来学习token之间的依赖关系并生成高质量的嵌入。
token级操作:精确地操作文本
token级别的操作是对文本数据启用细粒度操作。LLM 可以生成token、替换token或掩码token,以有意义的方式修改文本。这些token级操作在各种自然语言处理任务中都有应用,例如机器翻译、情感分析和文本摘要等。
token 设计的局限性
在将文本发送到 LLM 进行生成之前,会对其进行tokenization。token是模型查看输入的方式ーー单个字符、单词、单词的一部分或文本或代码的其他部分。每个模型都以不同的方式执行这一步骤,例如,GPT 模型使用字节对编码(BPE)
token会在tokenizer发生器的词汇表中分配一个 id,这是一个将数字与相应的字符串绑定在一起的数字标识符。例如,“ Matt”在 GPT 中被编码为token编号[13448],而 “Rickard”被编码为两个标记,“ Rick”,“ ard”带有 id[8759,446],GPT-3拥有1400万字符串组成的词汇表。
token 的设计大概存在着以下的局限性:
- 大小写区分:不同大小写的单词被视为不同的标记。“ hello”是token[31373] ,“ Hello”是[15496] ,而“ HELLO”有三个token[13909,3069,46]。
- 数字分块不一致。数值“380”在 GPT 中标记为单个“380”token。但是“381”表示为两个token[“38”,“1”]。“382”同样是两个token,但“383”是单个token[“383”]。一些四位数字的token有: [“3000”] ,[“3”,“100”] ,[“35”,“00”] ,[“4”,“500”]。这或许就是为什么基于 GPT 的模型并不总是擅长数学计算的原因。
- 尾随的空格。有些token有空格,这将导致提示词和单词补全的有趣行为。例如,带有尾部空格的“once upon a ”被编码为[“once”、“upon”、“a”、“ ”]。然而,“once on a time”被编码为[“once”,“ upon”,“ a”,“ time”]。因为“ time”是带有空格的单个token,所以将空格添加到提示词将影响“ time”成为下一个token的概率。
tokenization
- 将文本划分为不同token的正式过程称为 tokenization.
tokenization是特定于模型的。根据模型的词汇表和tokenization方案,标记可能具有不同的大小和含义。
BPE 是一种将最频繁出现的字符对或字节合并到单个标记中的方法,直到达到一定数量的标记或词汇表大小为止。BPE 可以帮助模型处理罕见或不可见的单词,并创建更紧凑和一致的文本表示。BPE 还允许模型通过组合现有单词或标记来生成新单词或标记。词汇表越大,模型生成的文本就越多样化并富有表现力。但是,词汇表越大,模型所需的内存和计算资源就越多。因此,词汇表的选择取决于模型的质量和效率之间的权衡。
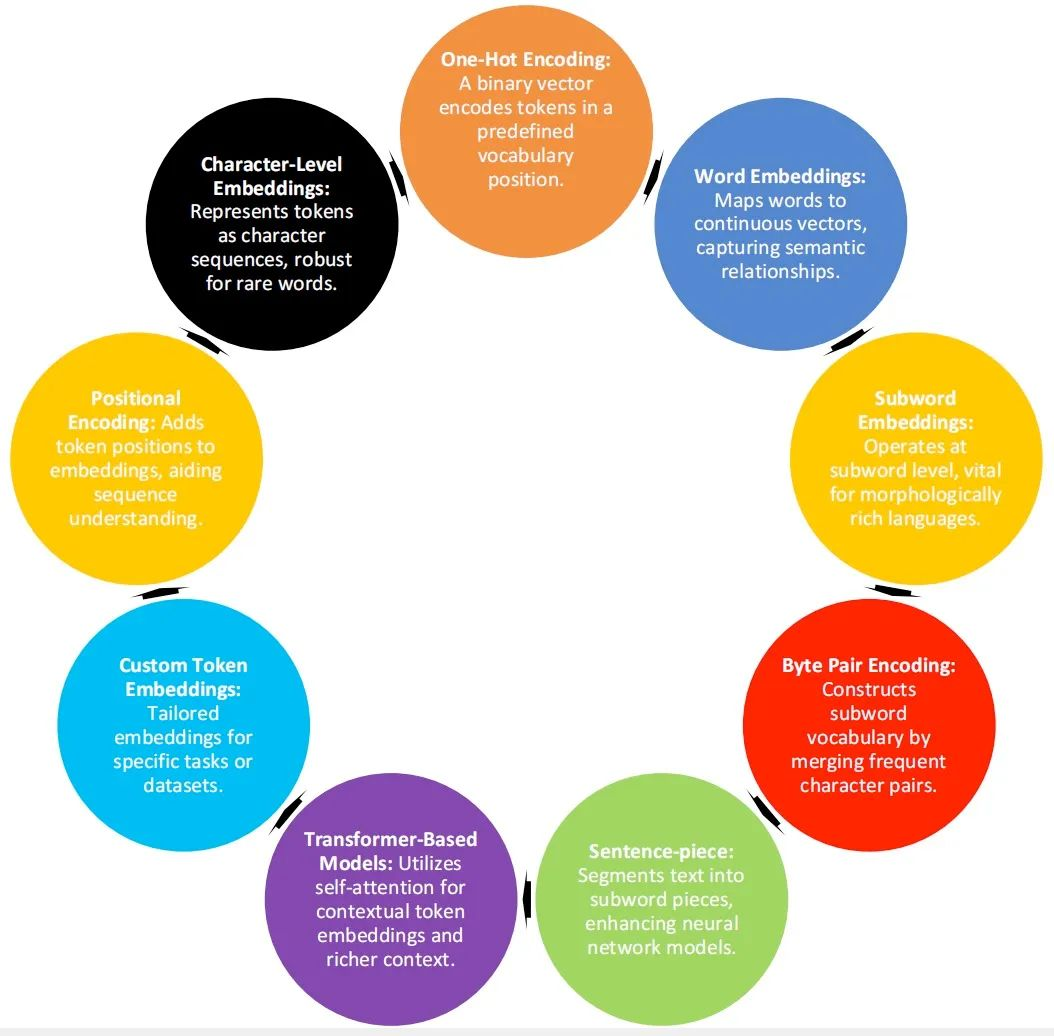
tokenization涉及到将文本分割成有意义的单元,以捕捉其语义和句法结构,可以采用各种tokenization技术,如字级、子字级(例如,使用字节对编码或 WordPiece)或字符级。根据特定语言和特定任务的需求,每种技术都有自己的优势和权衡。
- 字节对编码(BPE):为AI模型构建子词词汇,用于合并出现频繁的字符/子字对。
- 子词级tokenization:为复杂语言和词汇划分单词。将单词拆分成更小的单元,这对于复杂的语言很重要。
- 单词级tokenization:用于语言处理的基本文本tokenization。每个单词都被用作一个不同的token,它很简单,但受到限制。
- 句子片段:用习得的子词片段分割文本,基于所学子单词片段的分段。
- 分词tokenization:采用不同合并方法的子词单元。
- 字节级tokenization:使用字节级token处理文本多样性,将每个字节视为令牌,这对于多语言任务非常重要。
- 混合tokenization:平衡精细细节和可解释性,结合词级和子词级tokenization。
相关的技术参见 下图:
token 数量对LLM 的影响
训练模型参数量与训练数据量统计
2022 年 9 月,DeepMind(Chinchilla 论文)中提出Hoffman scaling laws:表明每个参数需要大约 20 个文本token进行训练。比如一个7B的模型需要140B token,若每个token使用int32(四字节)进行编码的话,就是560GB的数据。
训练模型参数量与训练数据量的统计
| 参数量 | 数据量(tokens) 1T tokens约为 2000-4000 GB 数据(与token的编码字节数相关) |
|---|---|
| llama-7B | 1.0 T |
| -13B | 1.0 T |
| -33B | 1.4 T |
| -65B | 1.4 T |
| Llama2-7B | 2.0 T |
| -13B | 2.0 T |
| -34B | 2.0 T |
| -70B | 2.0 T |
| Bloom-176B | 1.6 T |
| LaMDA-137B | 1.56 T |
| GPT-3-175B | 0.3 T |
| Jurassic-178B | 0.3 T |
| Gopher-280B | 0.3 T |
| MT-NLG 530B | 0.27 T |
| Chinchilla-70B | 1.4 T |
影响模型效果的因素有哪些?
虽然模型可以处理或已经接受过训练的token数量确实影响其性能,但其响应的一般性或详细程度更多地是其训练数据、微调和所使用的解码策略的产物。
解码策略也起着重要的作用。修改模型输出层中使用的SoftMax函数的“temperature”可以使模型的输出更加多样化(更高的温度)或者更加确定(更低的温度)。在OpenAI 的API中设置temperature的值可以调整确定性和不同输出之间的平衡。
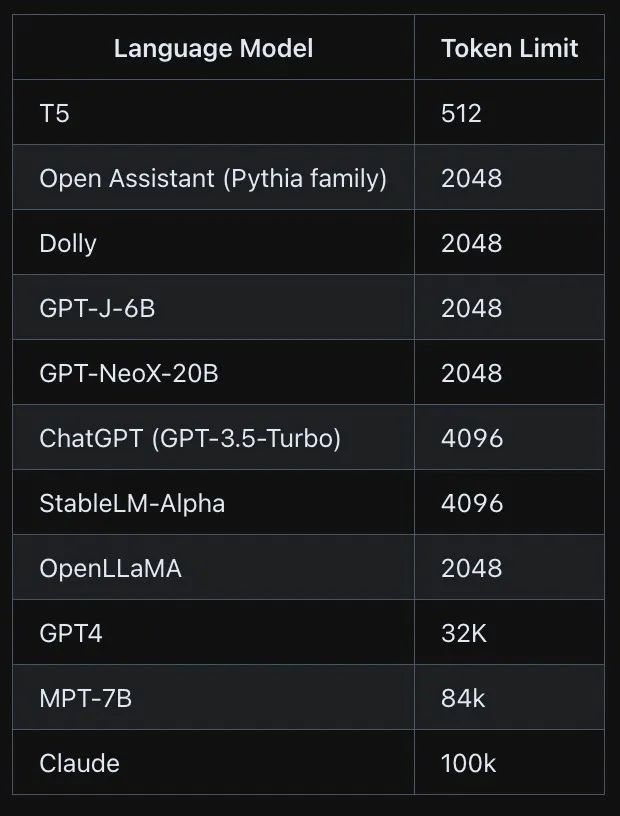
上下文窗口: 这是模型一次可以处理的token的最大数量。如果要求模型比上下文窗口生成更多的token,它将在块中这样做,这可能会失去块之间的一致性。
不同的模型支持不同的上下文token窗口,见下表
| MODEL | DESCRIPTION | CONTEXT WINDOW | TRAINING DATA |
|---|---|---|---|
| gpt-4-0125-preview | New GPT-4 Turbo The latest GPT-4 model intended to reduce cases of “laziness” where the model doesn’t complete a task. Returns a maximum of 4,096 output tokens. Learn more. | 128,000 tokens | Up to Dec 2023 |
| gpt-4 | Currently points to gpt-4-0613. See continuous model upgrades. | 8,192 tokens | Up to Sep 2021 |
| gpt-4-32k | Currently points to gpt-4-32k-0613. See continuous model upgrades. This model was never rolled out widely in favor of GPT-4 Turbo. | 32,768 tokens | Up to Sep 2021 |
| gpt-3.5-turbo-1106 | GPT-3.5 Turbo model with improved instruction following, JSON mode, reproducible outputs, parallel function calling, and more. Returns a maximum of 4,096 output tokens. Learn more. | 16,385 tokens | Up to Sep 2021 |
| gpt-3.5-turbo-instruct | Similar capabilities as GPT-3 era models. Compatible with legacy Completions endpoint and not Chat Completions. | 4,096 tokens | Up to Sep 2021 |
| gpt-3.5-turbo-16k | Legacy Currently points to gpt-3.5-turbo-16k-0613. | 16,385 tokens | Up to Sep 2021 |
等这样的大模型有一个最大token 数量限制,超过这个限制,它们就不能接受输入或生成输出
一般地, 可以尝试以下方法来解决token长度限制的问题:
- 截断
- 抽样
- 重组
- 编解码
- 微调
参考
LLM 中 Token 的通俗解释
解读大模型(LLM)的token
大模型参数量与训练数据量关系
相关文章:
大模型(LLM)的token学习记录-I
文章目录 基本概念什么是token?如何理解token的长度?使用openai tokenizer 观察token的相关信息open ai的模型 token的特点token如何映射到数值?token级操作:精确地操作文本token 设计的局限性 tokenizationtoken 数量对LLM 的影响训练模型参…...
探索前景:机器学习中常见优化算法的比较分析
目录 一、介绍 二、技术背景 三、相关代码 四、结论 一、介绍 优化算法在机器学习和深度学习中至关重要,可以最小化损失函数,从而改善模型的预测。每个优化器都有其独特的方法来导航损失函数的复杂环境以找到最小值。本文探讨了一些最常见的优化算法&…...

基于MRI的阿尔兹海默症病情预测
《阿尔兹海默症病情预测系统:老年痴呆患者的福音》 引言项目背景和意义数据介绍与分析模型介绍模型训练与评估模型应用与展望 引言 阿尔兹海默症(Alzheimer’s Disease)是一种常见的老年疾病,给患者及其家庭带来了巨大的困扰和负…...

高维中介数据: 联合显着性(JS)检验法
摘要 中介分析在流行病学和临床试验中越来越受到关注。在现有的中介分析方法中,流行的联合显着性(JS)检验会产生过于保守的 I 类错误率,因此功效较低。但是,如果在使用 JS 测试高维中介假设时,可以准确控制…...

冒泡排序 和 qsort排序
目录 冒泡排序 冒泡排序部分 输出函数部分 主函数部分 总代码 控制台输出显示 总代码解释 冒泡排序优化 冒泡排序 主函数 总代码 代码优化解释 qsort 排序 qsort 的介绍 使用qsort排序整型数据 使用qsort排序结构数据 冒泡排序 首先,我先介绍我的冒泡…...

asp.net core webapi接收application/x-www-form-urlencoded和form-data参数
框架:asp.net core webapiasp.net core webapi接收参数,请求变量设置 目录 接收multipart/form-data、application/x-www-form-urlencoded类型参数接收URL参数接收上传的文件webapi接收json参数完整控制器,启动类参考Program.cs 接收multipar…...
程序环境和预处理(2)
文章目录 3.2.7 命名约定 3.3 #undef3.4 命令行定义3.5 条件编译3.6 文件包含3.6.1 头文件被包含的方式3.6.2 嵌套文件包含 4. 其他预处理指令 3.2.7 命名约定 一般来讲函数和宏的使用语法很相似,所以语言本身没法帮我们区分二者,那我们平时的一个习惯是…...

Redis安全加固策略:绑定Redis监听的IP地址 修改默认端口 禁用或者重命名高危命令
Redis安全加固策略:绑定Redis监听的IP地址 & 修改默认端口 & 禁用或者重命名高危命令 1.1 绑定Redis监听的IP地址1.2 修改默认端口1.3 禁用或者重命名高危命令1.4 附:redis配置文件详解(来源于网络) 💖The Beg…...
Vuepress的使用
介绍 将markdown静态资源转换成html。 动态资源的转换还有很多,为什么要使用Vuepress? 目录分析 项目配置 详情 具体配置请看文档 插件配置 vuepress-theme-vdoing 主题插件 npm install vuepress-theme-vdoing -D先安装依赖配置主题 使用vuep…...

docker安装php7.4安装
容器 docker pull centos:centos7 docker run -dit -p9100:9100 --name“dade” --privilegedtrue centos:centos7 /usr/sbin/init 一、安装前库文件和工具准备 1、首先安装 EPEL 源 yum -y install epel-release2.安装 REMI 源 yum -y install http://rpms.remirepo.net/en…...

曲线生成 | 图解Dubins曲线生成原理(附ROS C++/Python/Matlab仿真)
目录 0 专栏介绍1 什么是Dubins曲线?2 Dubins曲线原理2.1 坐标变换2.2 单步运动公式2.3 曲线模式 3 Dubins曲线生成算法4 仿真实现4.1 ROS C实现4.2 Python实现4.3 Matlab实现 0 专栏介绍 🔥附C/Python/Matlab全套代码🔥课程设计、毕业设计、…...

「Vue3系列」Vue3 组件
文章目录 一、Vue3 组件二、Vue3 组件实例三、Vue3 官方组件四、Vue3 常用组件五、相关链接 一、Vue3 组件 Vue3 是 Vue.js 的最新版本,它引入了许多新的特性和改进。在 Vue3 中,组件是构建应用程序的核心部分,它们可以重用、组合和嵌套。Vu…...
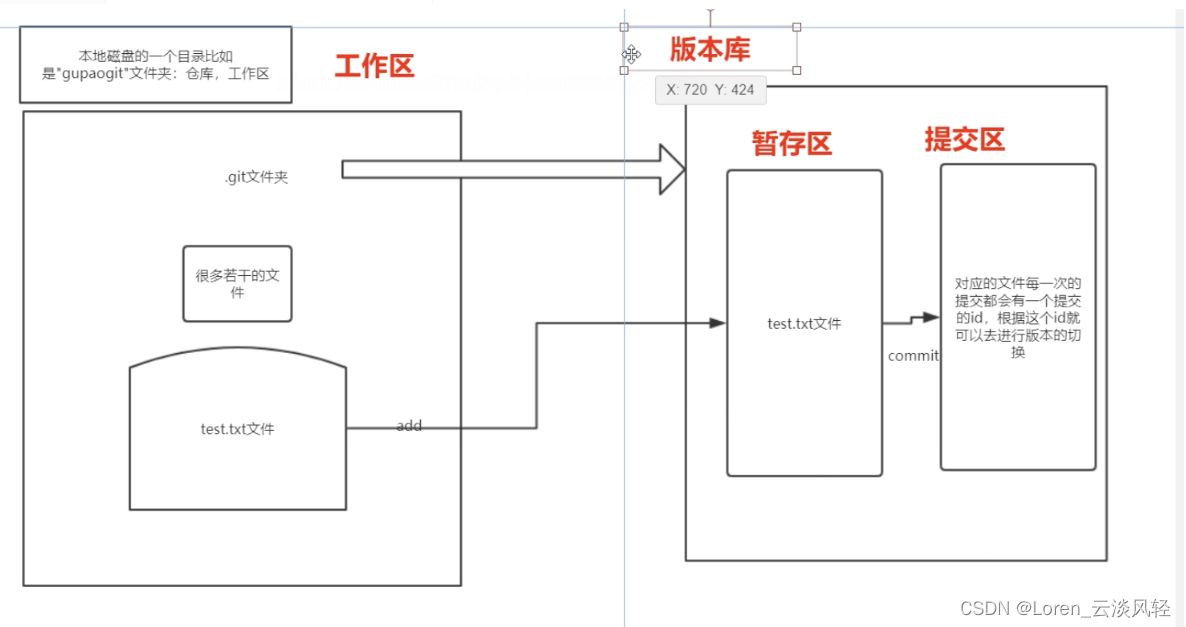
Git实战(2)
git work flow ------------------------------------------------------- ---------------------------------------------------------------- 场景问题及处理 问题1:最近提交了 a,b,c,d记录,想把b记录删掉其他提交记录保留: git reset …...
Java ElasticSearch-Linux面试题
Java ElasticSearch-Linux面试题 前言1、守护线程的作用?2、链路追踪Skywalking用过吗?3、你对G1收集器了解吗?4、你们项目用的什么垃圾收集器?5、内存溢出和内存泄露的区别?6、什么是Spring Cloud Bus?7、…...

微信小程序通过服务器控制ESP8266
声明 本文实现了ESP8266、微信小程序、个人服务器三者互相通信,并且小程序能发消息给微信用户 本文所有代码和步骤均为亲测有效 以下代码均为从网上搜索到后本人加以改动的,并非完全原创,若作者希望删除可联系我 ESP8266与个人服务器通信 ESP8266配置 通过串口通信使用…...

题目 1434: 蓝桥杯历届试题-回文数字
题目描述: 观察数字:12321,123321 都有一个共同的特征,无论从左到右读还是从右向左读,都是相同的。这样的数字叫做:回文数字。 本题要求你找到一些5位或6位的十进制数字。满足如下要求: 该数字的各个数位…...

访问修饰符、Object(方法,使用、equals)、查看equals底层、final--学习JavaEE的day15
day15 一、访问修饰符 含义: 修饰类、方法、属性,定义使用的范围 理解:给类、方法、属性定义访问权限的关键字 注意: 1.修饰类只能使用public和默认的访问权限 2.修饰方法和属性可以使用所有的访问权限 访问修饰符本类本包…...
的性能(来自OpenAI DevDay 会议))
『大模型笔记』最大化大语言模型(LLM)的性能(来自OpenAI DevDay 会议)
最大化大语言模型(LLM)的性能(来自OpenAI DevDay 会议) 文章目录 一. 内容介绍1.1. 优化的两个方向(上下文优化和LLM优化)1.2. 提示工程:从哪里开始1.3. 检索增强生成:拓展知识边界1.4. 微调:专属定制二. 参考文献一. 内容介绍 简述如何以可扩展的方式把大语言模型(LLMs)…...

深度学习:开启你的AI探索之旅
在这个信息爆炸的时代,人工智能(AI)已经渗透到我们生活的方方面面,从智能语音助手到自动驾驶汽车,从智能推荐系统到医疗影像诊断,AI的身影无处不在。而深度学习,作为AI领域的一大核心技术,更是引领着这场科技革命的浪潮。那么,如何入门深度学习,踏上这趟充满挑战与机…...
第十四届蓝桥杯大赛B组 JAVA 蜗牛 (递归剪枝)
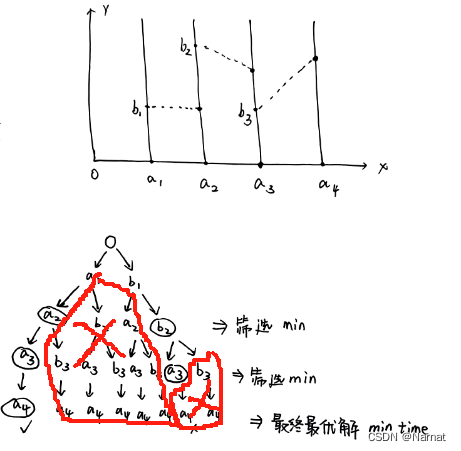
题目描述: 这天,一只蜗牛来到了二维坐标系的原点。 在 x 轴上长有 n 根竹竿。它们平行于 y 轴,底部纵坐标为 0,横坐标分别为 x1, x2, …, xn。竹竿的高度均为无限高,宽度可忽略。蜗牛想要从原点走到第 n 个竹竿的底部也…...

Linux内核启动时,你的isolcpus参数到底经历了什么?从GRUB到CPU掩码的完整旅程
Linux内核启动时,isolcpus参数的奇幻漂流:从GRUB配置到CPU隔离的完整解密当你在GRUB配置文件中写下isolcpus2-3这行看似简单的指令时,可能不会想到这个字符串将经历一场跨越多个软件层的奇妙旅程。本文将带你以侦探视角,追踪这个参…...

The Front 末日生存战争游戏专属服务器搭建教程
The Front 末日生存战争游戏专属服务器搭建教程 《The Front》(前线)是一款以末日废土为背景的多人生存建造游戏,玩家在充满战争气息的废土世界中采集资源、建造据点、研发科技、与其他玩家或 NPC 势力展开激烈对抗。自建专属服务器可以让你…...

FPGA加速机器学习在粒子物理触发系统中的应用与实战
1. 项目概述:当FPGA遇上机器学习,为粒子物理装上“火眼金睛” 在大型强子对撞机(LHC)的心脏地带,每秒发生着数亿次质子对撞。每一次对撞都可能产生希格斯玻色子、顶夸克,或是我们尚未知晓的新物理现象。然而…...

Win11已加密?统信UOS 1060双系统安装后数据盘共享踩坑实录与解决方案
Win11与统信UOS 1060双系统数据共享难题:从加密隔离到无缝互通当Windows 11的BitLocker加密遇上统信UOS的文件系统支持,双系统用户常常陷入一个尴尬境地——明明两块硬盘物理相连,数据却像隔着一道无形的墙。这不是简单的权限问题,…...

1000个文件重命名,1秒完成!批量文件重命名软件
前言: 大家好,这里是惠众资料库, 在日常办公、资料归档、素材整理、摄影剪辑等各类场景中,用户会积累大量图片、文档、视频、音频、文件夹等各类文件。为了实现文件分类规整、统一命名规范、方便快速检索调用,文件重命…...

《论三生原理》对《周易》《道德经》的一次根本性重写?
AI辅助创作:一、关于《周易》来历根源的推断属于文化创新实验,是对《周易》来历、性质、底层逻辑的一次根本性重写?《论三生原理》关于《周易》来历根源的推断,确实属于一次大胆的文化创新实验,并且是对《周易》的来历…...

Keil µVision库模块选择问题解决方案
1. 问题现象解析在Keil Vision IDE 4.53.06版本中,当用户为C51/C251/C166工具链项目添加库文件时,可以通过Options for File对话框选择需要链接的特定模块。这个功能本应记住用户的选择,使得下次打开对话框时保持相同的模块选中状态。但实际使…...

MDK Middleware网络组件的嵌入式安全防护解析
1. MDK Middleware网络组件的安全特性解析在嵌入式系统开发中,网络安全往往是最容易被忽视却又至关重要的环节。作为Keil MDK开发环境的核心组件,Middleware Network为Cortex-M系列微控制器提供了轻量级TCP/IP协议栈实现。不同于桌面级操作系统自带的网络…...

PyTorch神经网络初始化实战:解决梯度消失、对称性陷阱与LSTM失谐
神经网络初始化看似只是模型训练前的一个“小动作”,但我在带团队做工业级视觉检测项目时,亲眼见过三次因初始化不当导致的全线返工:一次是产线缺陷识别模型在验证集上准确率突然掉到42%,查了三天才发现权重全初始化为0.1…...

6款靠谱降AIGC软件 创作效率拉满
写论文时总是担心AI生成痕迹太重影响成绩?别慌,这里整理了6款超实用的免费论文降AIGC工具,堪称解决AI痕迹问题的"高效帮手"。它们能有效识别并去除AI生成特征,降痕效果显著,让你的论文更自然流畅,…...