Dubbo 中 Zookeeper 注册中心原理分析
Dubbo 中 Zookeeper 注册中心原理分析
文章目录
- Dubbo 中 Zookeeper 注册中心原理分析
- 一、ZooKeeper注册中心
- 1.1 ZooKeeper数据结构
- 1.2 ZooKeeper的Watcher机制
- 1.3 ZooKeeper会话机制
- 1.4 使用ZooKeeper作为注册中心
- 二、源码分析
- 2.1 AbstractRegistry
- 2.2 FailbackRegistry
- 2.2.1 核心字段
- 2.3 CacheableFailbackRegistry
- 2.3.1 URL推送模型
- 2.4 ZooKeeperRegistry
- 2.4.1 注册
转载:vivo互联网技术–公众号
本文通过分析Dubbo中ZooKeeper注册中心的实现ZooKeeperResitry的继承体系结构,自顶向下分析了AbstractRegistry(提供了服务数据的本地缓存)、FailbackRegistry(服务注册订阅相关的异常重试)、CacheableFailbackRegistry(Dubbo在URL推送模型做的优化)、ZooKeeperRegistry(ZooKeeper注册中心实现原理)的源码,详细介绍了Dubbo中ZooKeeper注册中心的实现原理。
当服务提供者启动时,服务提供者将自己提供的服务信息注册到注册中心,注册中心将这些信息记录下来。服务消费者启动时,向注册中心发起订阅,将自己感兴趣的服务提供者的信息拉取到本地并缓存起来,用于后续远程调用。另外,注册中心能够感知到服务提供者新增或者下线,并更新自己的服务信息,同时通知服务消费者告知服务提供者新增/下线,从而消费者也可以动态感知到服务提供者的变化。

一、ZooKeeper注册中心
ZooKeeper 是 Apache 的顶级项目。ZooKeeper 为分布式应用提供了高效且可靠的分布式协调服务,提供了诸如统一命名服务、配置管理和分布式锁等分布式的基础服务。在解决分布式数据一致性方面,ZooKeeper 并没有直接采用 Paxos 算法,而是采用了名为 ZAB 的一致性协议。
1.1 ZooKeeper数据结构
ZooKeeper 的数据模型是一个树形结构的文件系统。Dubbo服务在ZooKeeper中的数据结构(旧版模型,Dubbo2.7版本后路由数据、配置数据不再写到该目录下)如下图所示。

ZooKeeper中的节点分为持久节点、持久顺序节点、临时节点、临时顺序节点。Dubbo使用ZooKeeper作为注册中心时,不关心节点的创建顺序,只会创建持久节点和临时节点。
- 持久节点: 服务注册后保证节点不会丢失,注册中心重启也会存在 。
- 临时节点: 服务注册后连接丢失或session超时,注册的节点会自动被移除
1.2 ZooKeeper的Watcher机制
客户端和服务器维持数据交互通常有两种形式:
- 客户端定时向服务器轮询
- 服务器主动向客户端推送数据
ZooKeeper采用的是方式2,主动向客户端推送数据。客户端注册监听它关心的节点(注册Watcher监听指定节点),当节点状态发生变化(数据变化、子节点增减变化)时,则相应的Watcher被触发,ZooKeeper 服务会通知客户端,这就是Watcher机制。
Watcher有以下特点:
- 主动推送:Watcher被触发时,由ZooKeeper主动将更新推送给客户端,而不需要客户端轮询。
- 一次性:在节点上注册Watcher监听后,当节点状态发生变化时该Watcher只会被触发一次,如果客户端想再收到后续发生变化的通知,需要重新再注册一次Watcher。
- 可见性:如果一个客户端在读请求中附带 Watcher,Watcher 被触发的同时再次读取数据,客户端在得到 Watcher 消息之前肯定不可能看到更新后的数据。换句话说,更新通知先于更新结果。
- **顺序性:**如果多个更新触发了多个 Watcher ,那 Watcher 被触发的顺序与更新顺序一致。
1.3 ZooKeeper会话机制
ZooKeeper 客户端通过 TCP 长连接连接到 ZooKeeper 服务集群。会话 (Session) 从第一次连接开始就已经建立,之后通过心跳检测机制来保持有效的会话状态。通过这个连接,客户端可以发送请求并接收响应,同时也可以接收到 Watch 事件的通知。一旦一台客户端与一台服务器建立连接,这台服务器会为这个客户端创建一个新的会话。
每个会话都会有一个超时时间。若由于服务器压力过大、网络故障等各种原因导致客户端连接断开时,只要在会话超时时间之内能够重新连接上ZooKeeper服务器,那么之前创建的会话仍然有效。若服务器在超时时间内没有收到任何请求,则相应会话被视为过期。一旦会话过期,就无法再重新打开,且任何与该会话相关的临时 节点都会被删除。
通常来说,会话应该长期存在,而这需要由客户端来保证。客户端可以通过心跳方式来保持会话不过期。
1.4 使用ZooKeeper作为注册中心
如下图所示,服务提供者(集成了ZK客户端)在服务启动时,会通过ZK客户端与ZK服务端建立连接,将服务提供者信息(提供者的IP地址、端口、服务接口信息等)注册到ZooKeeper服务端,这时会在ZooKeeper服务端生成一个临时节点来存储这些服务信息,这就是服务提供者的注册操作。
服务消费者(集成了ZK客户端)在服务启动时,会通过ZK客户端与ZK服务端建立连接,拉取自己感兴趣的服务提供者信息并缓存到本地,同时也会对自己感兴趣的节点(比如服务提供节点)注册Watcher监听。后续发起远程调用时,会从本地缓存的服务提供者信息通过负载均衡等策略选择一台服务提供者发起服务调用。
如果服务提供者扩容新增了机器,服务提供者会向ZK发起新的注册操作,在对应的目录下创建临时节点(代表这台新增的服务提供者信息),同时会触发之前服务消费者注册的Watcher监听,ZooKeeper服务端会将变更信息推送到服务消费,服务消费者在接收到变更后会更新自己本地的服务提供者信息,这样就完成了服务的自动扩容。同样的,当某台服务提供者下线,它与ZooKeeper服务端的连接会断掉,因为服务注册时创建的是临时节点,因此当连接断掉后,该临时节点会被删除,同时会触发之前服务消费者注册的Watcher监听,相应的服务消费者会收到通知刷新自己本地的服务提供者信息缓存。

二、源码分析

Node,Dubbo中用Node来表示抽象节点,Dubbo中的核心概念Registry、Invoker等都实现了接口Node。
RegistryService定义了注册服务需要提供的基本能力,即增删改查。Registry接口继承了Node和Registry接口,它表示拥有注册中心能力的节点。其中定义了4个默认方法,其中的reExportRegister和reExportUnRegiser方法都是委托给RegisterService的相应方法。
AbstractRegistry实现了Registry接口中的方法,它在内存中实现了注册数据的读写改动,实现了本地缓存的功能。
FailbackRegistry继承了AbstractRegistry,结合时间轮,提供了失败重试的能力。
CacheableFailbackRegistry针对URL推送模型做了优化,减少了URL的创建。
ZooKeeperRegistry提供了基于ZooKeeper的注册中心实现。
下面重点分析AbstractRegistry、FailbackRegistry、CacheableFailbackRegistry和ZooKeeperRegistry。
2.1 AbstractRegistry
AbstractRegistry实现了Registry接口中的方法,它在内存中实现了注册数据的读写改动,从而可以就降低注册中心的压力。从前文继承体系结构可以看出,Dubbo中的注册中心实现都继承了该类。
AbstractRegistry的核心是通过Properties类型的properties与File类型的file字段来记录服务数据。properties基于内存存储了服务相关的数据,file则对应磁盘文件,两者的数据是同步的。在创建AbstractRegistry对象时,会根据传入的URL中的file.cache参数来决定是否开启本地缓存,默认开启。
如果开启,会将磁盘文件file中的数据加载到properties当中。当properties中的数据发生变化时,会同步到磁盘文件file中。如果传入的URL的save.file参数为false(默认是false),会通过线程池来异步同步properties的数据到file,如果是true则是在当前线程同步。
2.2 FailbackRegistry
FailbackRegistry处理的是注册中心相关的逻辑处理异常时如何处理,它会使用时间轮来处理异常重试。像ZooKeeperRegistry、NacosRegistry等注册中心实现,都继承了FailbackRegistry,因此也都有了异常重试的能力。
FailbackRegistry继承了AbstractRegistry,复写了register/unregister、
subscribe/unsubscribe、notify这5个核心方法,在这些方法中首先会调用父类AbstractRegistry对应的方法,然后真正的注册订阅等逻辑还是通过模板方法模式委托给了子类实现,重试逻辑则交由时间轮来处理。
2.2.1 核心字段
FailbackRegistry的核心字段如下:
1)ConcurrentMap < URL,FailedRegisteredTask > failedRegistered,注册失败的URL集合。key是注册失败的URL,value是FailedRegisteredTask,也就是重试注册时要执行的逻辑,该注册重试逻辑会交给时间轮执行。当注册失败时,会调用方法addFailedRegistered添加注册失败的URL。
2)ConcurrentMap < URL,FailedUnregisteredTask > failedUnregistered,取消注册时发生失败的URL集合。key是取消注册失败的URL,value是FailedUnregisteredTask,也就是重试取消注册时要执行的逻辑。
3)ConcurrentMap < Holder,FailedSubscribedTask > failedSubscribed,订阅失败的URL集合。key是Holder(封装了订阅失败的URL以及对应的监听器NotifyListener),value是FailedSubscribedTask,也就是重试订阅时要执行的逻辑。
4)ConcurrentMap < Holder,FailedUnsubscribedTask >failedUnsubscribed,取消订阅发生失败的URL集合。key是Holder(封装了取消订阅失败的URL以及对应的监听器NotifyListener),value是FailedUnsubscribedTask,也就是重试取消订阅时要执行的逻辑。
5)int retryPeriod,重试操作时间间隔。
6)HashedWheelTimer retryTimer,时间轮,用于执行重试操作。
2.2.2 核心方法
以subscribe为例来分析FailbackRegistry中是如何处理重试的(其余方法类似)。如下图所示,首先FailbackRegistry的subscribe方法会调用父类AbstractRegistry的subcribe方法,将订阅数据添加到内存中进行维护,接着会从订阅失败/取消订阅失败的集合中移除该URL相关的订阅数据。
然后调用子类的doSubscribe方法将真正的订阅逻辑交给子类实现,这是典型的模板方法设计模式。如果发生异常,会调用getCacheUrls方法获取缓存的服务提供者数据。如果缓存的服务数据非空,因为这边订阅失败了,所以需要手动触发下notify方法,回调相关的NotifyListener方法,刷新消费者本地的服务提供者列表、路由、配置的数据。如果缓存数据为空,则需要判断下,是否检测订阅失败以及订阅失败的异常是否可以跳过,根据这个来判断是否需要抛出异常还是忽略仅打印日志。
最后会调用addFailedSubscribed方法将订阅失败的信息添加到failedSubscribed集合,以及将任务添加到时间轮中,这样当时间到了,时间轮就可以处理该重试任务了。
这边有一点需要注意,如果任务已经存在failedSubscribed集合中,就不需要重复添加了。failedSubscribed是Map结构,通过key来判断数据是否存在,因此这边的Holder作为key时,需要复写hashCode和equals方法。

@Override
public void subscribe(URL url, NotifyListener listener) {// 调用父类方法, 在内存中记录下订阅相关的数据super.subscribe(url, listener);// 从订阅失败集合、取消订阅失败集合中移除该URL相关的数据, 如果存在需要取消相关任务的执行removeFailedSubscribed(url, listener);try {// 模板方法设计模式, 委托给子类实现真正的订阅逻辑doSubscribe(url, listener);} catch (Exception e) {Throwable t = e;// 订阅发生了异常, 则使用本地缓存的服务提供者数据List<URL> urls = getCacheUrls(url);if (CollectionUtils.isNotEmpty(urls)) {// 调用notify方法回调相关的listener方法, 通知消费者刷新自己本地// 的服务提供者、路由、配置等数据notify(url, listener, urls);} else {// 根据check以及是否是可忽略的异常来判断是否需要抛出异常boolean check = getUrl().getParameter(Constants.CHECK_KEY, true)&& url.getParameter(Constants.CHECK_KEY, true);boolean skipFailback = t instanceof SkipFailbackWrapperException;if (check || skipFailback) {if (skipFailback) {t = t.getCause();}// 抛异常} else {// 仅打印错误日志}}// 添加订阅失败的URL信息addFailedSubscribed(url, listener);}
}
protected void addFailedSubscribed(URL url, NotifyListener listener) {// 封装成HolderHolder h = new Holder(url, listener);// 判断该Holder是否已经存在, 如果已经存在则直接返回, 不需要多次添加FailedSubscribedTask oldOne = failedSubscribed.get(h);if (oldOne != null) {return;}// 创建订阅失败的重试任务FailedSubscribedTask newTask = new FailedSubscribedTask(url, this, listener);// 向订阅失败的集合里面添加该任务, 如果返回null说明之前不存在该任务,// 这次需要往时间轮中注册该任务oldOne = failedSubscribed.putIfAbsent(h, newTask);if (oldOne == null) {// 将该任务添加到时间轮中retryTimer.newTimeout(newTask, retryPeriod, TimeUnit.MILLISECONDS);}
}
2.3 CacheableFailbackRegistry
在2.7.8版本中并没有CacheableFailbackRegistry这个类。在Dubbo3.0中,针对服务数据的推送做了一系列的优化,CacheableFailbackRegistry正是其中一个改动,下面来进行具体的讲解。
2.3.1 URL推送模型
下图所示是Dubbo2.7.8中的URL推送模型,消费者启动后会向ZooKeeper服务端订阅感兴趣的服务,当有新的消费者感兴趣的服务提供者节点(提供者3)加入服务时,该服务(提供者3)会把自己的服务信息注册到ZooKeeper服务端,接着ZooKeeper服务端会把providers节点下的所有服务实例信息(提供者1、2、3)全量推送给消费者,消费者收到后根据推送的数据全量生成URL列表,该URL列表后续会被消费者用来构建自己本地的可选的服务提供者列表数据,后续发起远程调用时,就可以从该服务提供者列表中选择一个节点。
可以看到,当服务提供者实例数量较小时,推送的数据量较小,消费者端构建URL的压力就小一些,但是当某个接口有大量的服务提供者时,当发生服务扩容/缩容,就会有大量的URL被创建。Dubbo3.0中的对该URL推送模型做了一系列的优化,主要是对URL的类结构做了一定调整,引入了多级缓存,下面具体分析。

2.3.2 URL结构变更及多级缓存
如下两图分别是Dubbo2.7.8和Dubbo3.0.7中的URL结构,可以看到在3.0.7中新增了URLAddress和URLParam类,原本URL中的host、port等信息移到了URLAddress中,原本URL的参数信息则移到了URLParam中。为什么要这么做?很大程度上是为了利用缓存,避免重复创建URL对象。比如将URL中的host、port等信息抽取到URLAddress对象中,当发生服务数据变更推送时,根据host、port等信息很大程度上能够从缓存中找到已有的URLAddress对象,这样就避免了一些不必要的URL创建。


2.3.3 核心方法
如下图所示,当消费者接收到ZooKeeper注册中心推送过来的全量服务提供者列表信息(providers)时,会调用到该方法进行ServiceAddressURL列表的创建。首先,会根据消费者URL尝试从缓存stringUrls中获取服务提供者信息对应的Map(key是服务提供者信息的字符串表示,value是对应的ServiceAddressURL)。如果该Map为空,则providers对应的ServiceAddressURL都需要创建。如果Map不为空,则先从该Map中根据provider的字符串key尝试获取缓存,如果存在则不需要调用createURL创建。
createURL也是依次从缓存stringAddress和stringParam获取对应的URLAddress和URLParam,如果缓存中不存在则创建。接着,利用刚刚获取到的URLAddress和URLParam以及consumerURL创建ServiceAddressURL。
创建完成后会判断该ServiceAddressURL是否和当前消费者匹配(version、group这些信息是否匹配,前文已经分析过)。如果不匹配则返回空,后续也不会被更新到stringUrls缓存中。
创建完成后会调用evictURLCache,将待清理的URL信息放入waitForRemove中,cacheRemovalScheduler会定时清理缓存数据。

protected List<URL> toUrlsWithoutEmpty(URL consumer, Collection<String> providers) {// 根据消费者URL信息从stringUrls中获取对应的服务提供者信息Map<String, ServiceAddressURL> oldURLs = stringUrls.get(consumer);// create new urlsMap<String, ServiceAddressURL> newURLs;// 去除consumerURL中的release、dubbo、methods、时间戳、dubbo.tag这些参数URL copyOfConsumer = removeParamsFromConsumer(consumer);// 如果缓存中没有, 肯定都是需要新建的if (oldURLs == null) {newURLs = new HashMap<>((int) (providers.size() / 0.75f + 1));for (String rawProvider : providers) {// 去除掉rawProvider中的时间戳、PID参数rawProvider = stripOffVariableKeys(rawProvider);// 调用createURL创建ServiceAddressURLServiceAddressURL cachedURL =createURL(rawProvider, copyOfConsumer, getExtraParameters());// 如果创建的为空则忽略不放入newURLsif (cachedURL == null) {continue;}newURLs.put(rawProvider, cachedURL);}} else {newURLs = new HashMap<>((int) (providers.size() / 0.75f + 1));// maybe only default , or "env" + defaultfor (String rawProvider : providers) {rawProvider = stripOffVariableKeys(rawProvider);// 从缓存中获取, 如果缓存中存在就不需要再创建了ServiceAddressURL cachedURL = oldURLs.remove(rawProvider);if (cachedURL == null) {cachedURL = createURL(rawProvider, copyOfConsumer, getExtraParameters());if (cachedURL == null) {continue;}}newURLs.put(rawProvider, cachedURL);}}// 清除老的缓存数据evictURLCache(consumer);// 更新stringUrls缓存stringUrls.put(consumer, newURLs);return new ArrayList<>(newURLs.values());
}
protected ServiceAddressURL createURL(String rawProvider, URL consumerURL,Map<String, String> extraParameters) {boolean encoded = true;int paramStartIdx = rawProvider.indexOf(ENCODED_QUESTION_MARK);if (paramStartIdx == -1) {encoded = false;}// 解析rawProvider, 一分为二, 一个用来创建URLAddress、一个用来创建URLParamString[] parts = URLStrParser.parseRawURLToArrays(rawProvider, paramStartIdx);if (parts.length <= 1) {return DubboServiceAddressURL.valueOf(rawProvider, consumerURL);}String rawAddress = parts[0];String rawParams = parts[1];boolean isEncoded = encoded;// 从缓存stringAddress缓存中获取URLAddress, 不存在则创建URLAddress address =stringAddress.computeIfAbsent(rawAddress,k -> URLAddress.parse(k, getDefaultURLProtocol(), isEncoded));address.setTimestamp(System.currentTimeMillis());// 从缓存stringParam缓存中获取URLParam, 不存在则创建URLParam param = stringParam.computeIfAbsent(rawParams,k -> URLParam.parse(k, isEncoded, extraParameters));param.setTimestamp(System.currentTimeMillis());// 用获取到的URLAddress、URLParam直接new创建ServiceAddressURLServiceAddressURL cachedURL = createServiceURL(address, param, consumerURL);// 判断创建出来的ServiceAddressURL是否和当前消费者匹配, 不匹配返回nullif (isMatch(consumerURL, cachedURL)) {return cachedURL;}return null;
}
2.4 ZooKeeperRegistry
2.4.1 注册
根据传入的URL生成该节点要在ZooKeeper服务端上注册的节点路径,值为如下形式:/dubbo/org.apache.dubbo.springboot.demo.DemoService/providers/服务信息,/dubbo是根路径,接下来是服务的接口名,然后/providers是类型信息(如果是消费者则是/consumers节点,路由信息则是/routers),最后是URL的字符串表示。得到节点路径后,会根据URL的dynamic参数(默认是true)决定在ZooKeeper服务端上创建的是临时节点,还是持久节点,默认是临时节点。
注册后数据结构如下图所示。

2.4.2 订阅
订阅的核心是通过ZooKeeperClient在指定的节点的添加ChildListener,当该节点的子节点数据发生变化时,ZooKeeper服务端会通知到该ChildListener的notify方法,然后调用到对应的NotifyListener方法,刷新消费者本地的服务提供者列表等信息。
doSubscribe方法主要分为两个分支:URL的interface参数明确指定了为*(订阅所有,通常实际使用中不会这么使用,Dubbo的控制后台会订阅所有)或者就订阅某个服务接口,接下来分析订阅某个指定服务接口这个分支代码。这块涉及到三个监听器(它们是一对一的):

1)NotifyListener,Dubbo中定义的通用的订阅相关的监听器。它是定义在dubbo-registry-api模块中的,不仅仅在ZooKeeper注册中心模块中使用。
2)ChildListener,Dubbo中定义的针对ZooKeeper注册中心的监听器,用来监听指定节点子节点的数据变化。
3)CuratorWatcher,Curator框架中的监听器,Curator是常用的ZooKeeper客户端,如果Dubbo采用其它ZooKeeper客户端工具,这块就是其它相关的监听器逻辑了。
当订阅的服务数据发生变化时,最先会触发到CuratorWatcher的process方法,process方法中会调用ChildListener的childChanged方法,在childChanged方法会继续触发调用到ZooKeeperRegistry的notify方法。这里有两点需要注意:
1)因为doSubscribe方法中通过ZooKeeperClient添加Watcher监听器时,使用的是usingWatcher,这是一次性的,所以在CuratorWatcher的实现CuratorWatcherImpl的process方法中,当收到ZooKeeper的变更数据推送时,会再次在path上注册Watcher。
2)在ChildListener的实现
RegistryChildListenerImpl的doNotify方法中,会调用ZooKeeperRegistry的toUrlsWithEmpty将传入的字符串形式的服务提供者列表等数据转换成对应的ServiceAddressURL列表数据,以供后面使用。
明确了三个监听器的含义之后,接下来分析doSubscribe的逻辑就简单了。首先会调用toCategoriesPath方法获取三个path路径,分别是
- /dubbo/org.apache.dubbo.demo.DemoService/providers
- /dubbo/org.apache.dubbo.demo.DemoService/configurators
- /dubbo/org.apache.dubbo.demo.DemoService/routers
表示当前消费者(url参数代表)需要订阅这三个节点,当任意一个节点的数据发生变化时,ZooKeeper服务端都会通知到当前注册中心客户端,更新本地的服务数据。依次遍历这三个path路径,分别在这三个path上注册监听器。
ZooKeeperRegistry通过zkListeners这个Map维护了所有消费者(URL)的所有监听器数据,首先根据url参数获取当前消费者对应的监听器listeners,这是一个Map,key是NotifyListener,value是对应的ChildListener,如果不存在则需要创建ChildListener的实现RegistryChildListenerImpl。当创建完成后,会在ZooKeeper服务端创建持久化的path路径,并且在该path路径上注册监听器。首次订阅注册监听器时,会获取到该路径下的所有服务数据的字符串形式,并调用toUrlsWithEmpty转成URL形式,接着调用notify方法刷新消费者本地的服务相关数据。
@Override
public void doSubscribe(final URL url, final NotifyListener listener) {CountDownLatch latch = new CountDownLatch(1);try {List<URL> urls = new ArrayList<>();// 获取三个路径, 分别是/providers、/routers、/configuratorsfor (String path : toCategoriesPath(url)) {// 获取该消费者URL对应的监听器MapConcurrentMap<NotifyListener, ChildListener> listeners =zkListeners.computeIfAbsent(url, k -> new ConcurrentHashMap<>());// 查找NotifyListener对应的ChildListener是否存在, 不存在则创建ChildListener zkListener = listeners.computeIfAbsent(listener,k -> new RegistryChildListenerImpl(url, path, k, latch));if (zkListener instanceof RegistryChildListenerImpl) {((RegistryChildListenerImpl) zkListener).setLatch(latch);}// 在ZooKeeper服务端创建持久节点zkClient.create(path, false);// 添加ChildListener监听器, 并全量拉取下相关服务数据List<String> children = zkClient.addChildListener(path, zkListener);if (children != null) {// 将字符串形式的服务数据转换成URL列表数据urls.addAll(toUrlsWithEmpty(url, path, children));}}// 首次订阅后触发下notify逻辑, 刷新消费者本地的服务提供者列表等数据notify(url, listener, urls);} finally {latch.countDown();}
}
接下来看下AbstractZooKeeperClient的addChildListener方法,逻辑也比较简单,在指定path路径上添加一次性的Watcher。取消订阅的逻辑则是会将传入的UR和NotifyListener对应的ChildListener移除,不再监听。
public List<String> addChildListener(String path, final ChildListener listener) {ConcurrentMap<ChildListener, TargetChildListener> listeners =childListeners.computeIfAbsent(path, k -> new ConcurrentHashMap<>());TargetChildListener targetListener = listeners.computeIfAbsent(listener,k -> createTargetChildListener(path, k));return addTargetChildListener(path, targetListener);
}@Override
public List<String> addTargetChildListener(String path, CuratorWatcherImpl listener) {try {return client.getChildren().usingWatcher(listener).forPath(path);} catch (NoNodeException e) {return null;} catch (Exception e) {throw new IllegalStateException(e.getMessage(), e);}
}
三、总结
本文通过分析Dubbo3.0中AbstractRegistry、FailbackRegistry、ZooKeeperRegistry,详细介绍了Dubbo中ZooKeeper注册中心的实现原理,包括服务数据本地缓存、服务注册订阅异常重试等。另外,网上大部分文章是基于2.x版本的,本文基于Dubbo3.0,重点分析了Dubbo3.0中新引入的CacheableFailbackRegistry,详细介绍了Dubbo在URL推送模型上所做的优化。
参考资料:
- Dubbo3.0 阿里大规模实践解析-URL重构
- 深入浅出ZooKeeper
相关文章:
Dubbo 中 Zookeeper 注册中心原理分析
Dubbo 中 Zookeeper 注册中心原理分析 文章目录Dubbo 中 Zookeeper 注册中心原理分析一、ZooKeeper注册中心1.1 ZooKeeper数据结构1.2 ZooKeeper的Watcher机制1.3 ZooKeeper会话机制1.4 使用ZooKeeper作为注册中心二、源码分析2.1 AbstractRegistry2.2 FailbackRegistry2.2.1 核…...
--哥德巴赫猜想的第一次实际应用)
素数产生新的算法(由筛法减法改为增加法)--哥德巴赫猜想的第一次实际应用
素数产生新的算法(由筛法减法改为增加法)--哥德巴赫猜想的第一次实际应用 摘要:长期以来,人们认为哥德巴赫猜想没有什么实际应用的。 现在,我假设这个不是猜想,而是定理或公理,就产生了新的应用…...

递归-需要满足三个条件
一,概述 递归是一种应用非常广泛的算法(或者编程技巧)。很多数据结构和算法的编码实现都要用到递归,比如 DFS 深度优先搜索、前中后序二叉树遍历等。 去的过程叫“递”,回来的过程叫“归”。基本上所有的递归问题都可…...

【剑指Offer-Java】两个栈实现队列
题目 用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 ) 输入: [“CQueue”,“appendT…...

Allegro如何将Waived掉的DRC显示或隐藏操作指导
Allegro如何将Waived掉的DRC显示或隐藏操作指导 在用Allegro做PCB设计的时候,如果遇到正常的DRC,可以用Waive的命令将DRC不显示,如下图 当DRC被Waive掉的时候,如何将DRC再次显示出来。类似下图效果 具体操作如下 点击Display...
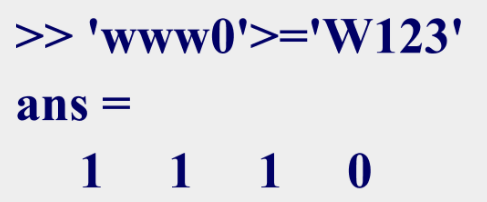
MATLAB——数据及其运算
MATLAB数值数据数值数据类型的分类1.整型整型数据是不带小数的数,有带符号整数和无符号整数之分。表中列出了各种整型数据的取值范围和对应的转换函数。2.浮点型浮点型数据有单精度(single)和双精度((double)之分&…...

【微信小程序】-- 页面导航 -- 声明式导航(二十二)
💌 所属专栏:【微信小程序开发教程】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! &…...

gdb查看汇编代码的例子
gdb查看汇编代码的例子 操作步骤 用 gdb 启动可执行文件:gdb executable_file在 gdb 中设置断点:break function_name 或者 break *memory_address运行程序:run当程序停止在断点处时,使用 disassemble 命令来查看汇编代码&#…...

第四讲:如何将本地代码与服务器代码保持实时同步
一、前言 在我们进行 Ambari 二次开发时,通常会先在服务器上部署一套可以使用的 Ambari 环境。 二次开发,就肯定是要改动代码的,我们不能老是在服务器上用vim编辑文件,那样效率太低,始终不是长久之计。 所以我们需要在本地打开我们的Ambari源码项目,比如用idea工具,可…...
cuda调试(一)vs2019-windows-Nsight system--nvtx使用,添加nvToolsExt.h文件
cuda调试 由于在编程过程中发现不同的网格块的结构,对最后的代码结果有影响,所以想记录一下解决办法。 CUDA的Context、Stream、Warp、SM、SP、Kernel、Block、Grid cuda context (上下文) context类似于CPU进程上下,表示由管理层 Drive …...

向Spring容器中注入bean有哪几种方式?
文章前言: 写这篇文章的时候,我正在手机上看腾讯课堂的公开课,有讲到 Spring IOC 创建bean有哪几种方式,视频中有提到过 set注入、构造器注入、注解方式注入等等;于是,就想到了写一篇《Spring注入bean有几种…...

如何用 Python采集 <豆某yin片>并作词云图分析 ?
嗨害大家好鸭!我是小熊猫~ 总有那么一句银幕台词能打动人心 总有那么一幕名导名作念念不忘 不知道大家有多久没有放松一下了呢? 本次就来给大家采集一下某瓣电影并做词云分析 康康哪一部才是大家心中的经典呢? 最近又有哪一部可能会成为…...

Python装饰器的具体实用示例
示例1:普通装饰器 def name(n):def func(x):res n(xx)return resreturn funcname def run(x): # run name(run)print(x)if __name__ __main__:run(1) # 2def name(n):def func(*x):res n(xx)return resreturn funcname def run(x): # run name(run)pr…...

谈谈我对Retrofit源码的理解
文章目录一、Retrofit简介二、使用介绍2.1 app / build.gradle添加依赖2.2 创建 Retrofit 实例2.3 创建 API 接口定义文件2.4 使用 Retrofit 进行网络请求三、源码分析3.1 创建 Retrofit 实例: 建造者模式创建Retrofit3.2 实例化API接口: 动态代理模式3.3 获取Observable返回值…...
八股文(三)
目录 一、 如何理解原型与原型链 二、 js继承 三、 vuex的使用 1.mutation和action的区别 mutation action 2.Vuex都有哪些API 四、 前端性能优化方法 五、 类型判断 题目 (1)typeof判断哪个类型会出错(即结果不准确)&…...

2023最新实施工程师面试题
1、两电脑都在同一个网络环境中,A 电脑访问不到 B 电脑的共享文件。此现象可能是哪些 方面所导致?怎样处理? 答:首先你要确定是不是在一个工作组内,只有在一个工作组内才可以共享文件,然后看一个看一看有没有防火墙之类的,然后确定文件是不是已经共享 2、 电脑开机时风扇…...
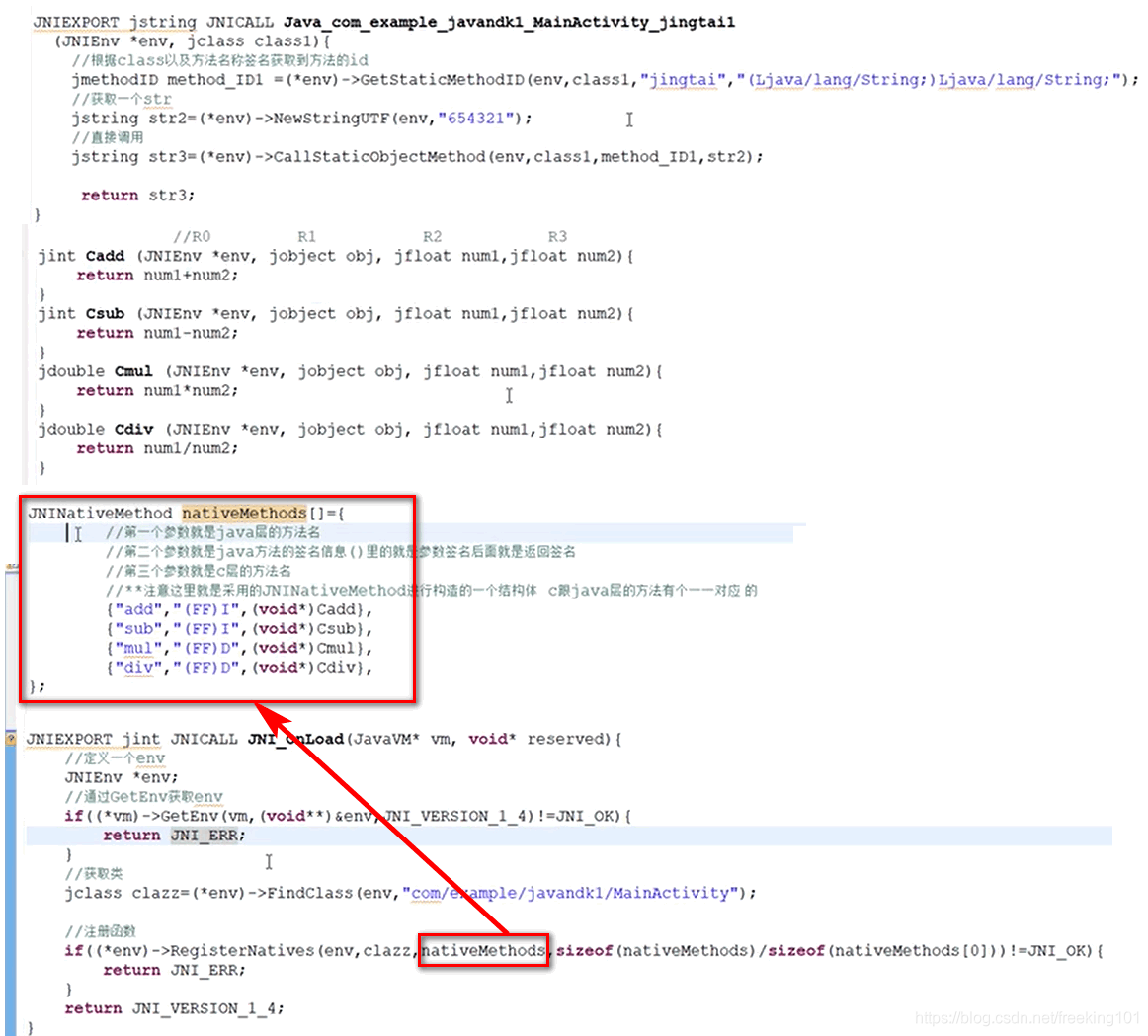
安卓逆向_6 --- JNI 和 NDK
Java 本机接口规范内容:https://docs.oracle.com/en/java/javase/19/docs/specs/jni/index.html JNI官方中文资料:https://blog.csdn.net/yishifu/article/details/52180448 NDK 官方文档:https://developer.android.google.cn/training/ar…...
Pod控制器
K8S之控制器详解#简介#在kubernetes中,按照Pod的创建方式可以将其分为两类:自主式:kubernetes直接创建出来的Pod,这种Pod删除后就没有了,也不会重建。控制器创建pod:通过Pod控制器创建的Pod,这种Pod删除之后还会自动重…...
微服务到云原生
微服务到云原生 微服务 微服务架构(Microservice Architecture)是一种架构概念,旨在通过将功能分解到各个离散的服务中以实现对解决方案的解耦。 微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成。系统中的各…...
Spring Security 实现自定义登录和认证(1):使用自定义的用户进行认证
1 SpringSecurity 1.1 导入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-security</artifactId> </dependency>1.2 编写配置类 在spring最新版中禁用了WebSecurityConfigurerAdapter…...

3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南
3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否厌倦了每次运行AutoHotkey脚本都需要安…...

从纹波和EMI出发:实战分析DC-DC降压电路中PWM与PFM的取舍与优化技巧
从纹波和EMI出发:实战分析DC-DC降压电路中PWM与PFM的取舍与优化技巧 在射频模块或高精度ADC供电设计中,电源的纯净度直接决定系统性能上限。当输出电压纹波超出ADC的LSB范围,或EMI噪声耦合到敏感信号链时,工程师往往需要重新审视D…...

MemPrivacy:面向端云智能体的隐私保护个性化记忆管理框架
之前文章介绍过:89.2%攻击成功率!腾讯、字节研究发现 OpenClaw Agent 存在可利用结构性漏洞 今天介绍一个 MemPrivacy 项目,来自 MemTensor、荣耀和同济大学的联合团队。 他们的研究让云端智能体能正常"记住你",但永远看…...

高效跨平台游戏模组下载:WorkshopDL完全指南
高效跨平台游戏模组下载:WorkshopDL完全指南 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 你是否在Epic Games Store、GOG或其他非Steam平台购买了游戏࿰…...

5分钟免费获取:开源鼠标连点器MouseClick完整使用指南
5分钟免费获取:开源鼠标连点器MouseClick完整使用指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

品牌声音技能化:从模糊概念到可执行AI内容策略
1. 项目概述:品牌声音的“技能化”构建最近在和一些做品牌营销、内容运营的朋友聊天,发现一个挺普遍的现象:大家手里都有一堆品牌手册、VI规范,但一到具体执行,比如写一篇公众号推文、拍一条短视频,或者回复…...

AI 术语通俗词典:计算图
计算图是深度学习、自动微分、神经网络训练和人工智能框架中非常重要的一个术语。它用来描述:把一次数学计算过程表示成由节点和边组成的图结构。换句话说,计算图是在回答:模型中的输入、参数、运算和输出之间,到底是如何一步步连…...

智能GUI自动化:从SAG架构到实战部署的完整指南
1. 项目概述与核心价值最近在开源社区里,我注意到一个挺有意思的项目,叫openclaw-skill-sag。乍一看这个标题,可能会觉得有点抽象,但如果你对自动化、机器人流程自动化(RPA)或者智能体(Agent&am…...

g1810,g3810,ip2700,g5080,g1800,ts3380,TS8380,ts6480报错5B00,P07,E08,5b02,1704,1700,5b04,佳能v6.200,亲测有用。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...

AI智能体操作安卓设备:基于agent-droid-bridge的自动化实践
1. 项目概述:连接AI与安卓设备的桥梁 最近在折腾AI智能体(Agent)和自动化流程时,遇到了一个挺有意思的需求:如何让运行在服务器上的AI程序,直接去操作一台真实的安卓手机或模拟器,完成一些复杂的…...