C/C++工程师面试题(STL篇)



STL 中有哪些常见的容器
STL 中容器分为顺序容器、关联式容器、容器适配器三种类型,三种类型容器特性分别如下:
1. 顺序容器 容器并非排序的,元素的插入位置同元素的值无关,包含 vector、deque、list
- vector:动态数组 元素在内存连续存放。随机存取任何元素都能在常数时间完成。在尾端增删元素具有较佳的性能。
- deque:双向队列 元素在内存连续存放。随机存取任何元素都能在常数时间完成(仅次于 vector )。在两端增删元素具有较佳的性能(大部分情况下是常数时间)。
- list:双向链表 元素在内存不连续存放。在任何位置增删元素都能在常数时间完成。不支持随机存取。
2. 关联式容器 元素是排序的;插入任何元素,都按相应的排序规则来确定其位置;在查找时具有非常好的性能;通常以平衡二叉树的方式实现,包含set、map。
- set set中不允许相同元素
- map map 与 set 的不同在于 map 中存放的元素有且仅有两个成员变,一个名为 first,另一个名为 second,map 根据 first 值对元素从小到大排序,并可快速地根据 first 来检索元素。
3. 容器适配器 封装了一些基本的容器,使之具备了新的函数功能,包含 stack、queue。
- stack:栈 栈是项的有限序列,并满足序列中被删除、检索和修改的项只能是最进插入序列的项(栈顶的项),后进先出。
- queue:队列 插入只可以在尾部进行,删除、检索和修改只允许从头部进行,先进先出。
STL 容器用过哪些,查找的时间复杂度是多少,为什么?
以下是其中一些常见容器的查找时间复杂度以及原因:
vector(向量):查找时间复杂度为O(n),因为vector是基于数组实现的,需要线性遍历整个数组来查找元素。
deque(双端队列):在未排序状态下,查找时间复杂度为O(n),类似于vector。但在有序状态下,可以利用二分查找,降低查找时间复杂度为O(log n)。
list(链表):查找时间复杂度为O(n),因为链表是一种线性结构,需要从头开始顺序查找元素。
set(集合)和multiset(多重集合):查找时间复杂度为O(log n),底层通常使用红黑树实现,具有较好的平衡性能。
map(映射)和multimap(多重映射):查找时间复杂度为O(log n),底层通常使用红黑树实现,按键进行自动排序。
stack(栈)和queue(队列):查找时间复杂度为O(n),因为它们是容器适配器,提供了先进先出(FIFO)或后进先出(LIFO)的接口,并不支持快速查找操作。
因此,对于不同的STL容器,其查找时间复杂度取决于底层数据结构的实现方式和算法设计。
vector 和 list 的区别,分别适用于什么场景?
vector 和 list 的区别:
底层数据结构:
- vector: 底层使用动态数组实现。
- list: 底层使用双向链表实现。
插入和删除操作:
- vector: 插入和删除元素效率低。
- list: 插入和删除元素效率高,因为只需要修改相邻节点的指针。
随机访问:
- vector: 支持随机访问,可以通过下标快速访问元素。
- list: 不支持随机访问,只能通过迭代器顺序访问元素。
空间和内存分配:
- vector: vector 一次性分配好内存,不够时才进行扩容。
- list: list 每次插入新节点都会进行内存申请。
适用场景:
vector: 适用于连续存储,支持随机访问,而不在乎插入和删除的效率。
list: 适用于不连续的内存空间,如果需要高效的插入和删除,而不关心随机访问。
简述 vector 的实现原理
vector 是一种动态数组,在内存中具有连续的存储空间,支持快速随机访问,由于具有连续的存储空间,所以在插入和删除操作方面,效率比较慢。
当 vector 的大小和容量相等(size==capacity)时,如果再向其添加元素,那么 vector 就需要扩容。vector 容器扩容的过程需要经历以下 3 步:
- 重新在堆上创建更大的动态数组,大小是原来的2倍;
- 将旧内存空间中的数据,按原有顺序移动到新的内存空间中;
- 最后将旧的内存空间释放。
扩容以后它的内存地址会发生改变
迭代器失效原因,有哪些情况
迭代器失效是指迭代器在遍历容器过程中,由于容器的结构发生改变而导致迭代器指向的元素不再有效。
以下是导致迭代器失效的常见情况:
- 插入和删除操作: 当在容器中插入或删除元素时,可能会导致容器内存重新分配或元素位置的改变,这可能会使迭代器失效。
- 清空容器: 清空容器会使容器内的所有元素被删除,这样迭代器指向的元素就会失效。
- 使用引起重新分配的操作: 例如,在
vector中使用push_back()添加元素时,如果超出了当前容量,可能会触发重新分配操作,从而使所有迭代器失效。- 排序操作: 如果在排序过程中,容器的元素被移动了位置,迭代器可能会失效。
- 使用非常量迭代器遍历过程中修改了容器: 如果在使用非常量迭代器遍历容器的过程中,修改了容器的结构(例如插入或删除元素),会使迭代器失效。
deque 的实现原理
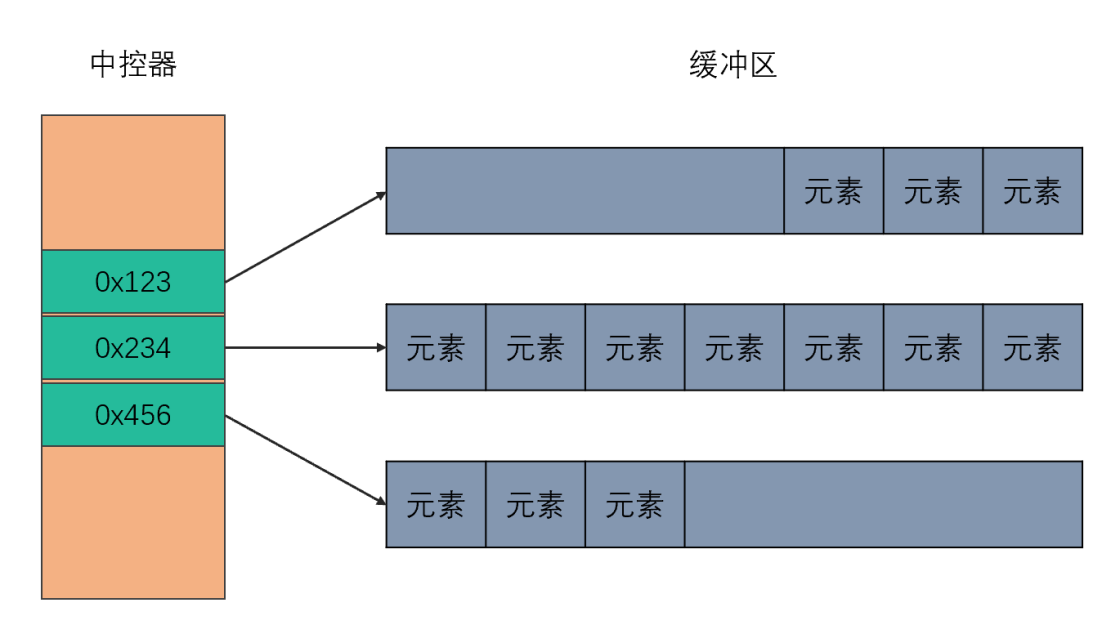
分段连续内存、中控器
deque 是由一段一段的连续空间构成。一旦有必要在 deque 前端或者尾端增加新的空间,便配置一段连续定量的空间,串接在 deque 的头端或者尾端。
deque 采取一块所谓的 map(不是 STL 的 map 容器)作为主控,这里所谓的 map 是一小块连续的内存空间,其中的每个元素(此处成为一个结点)都是一个指针,指向另一段连续性内存空间,称作缓冲区。缓冲区才是 deque的存储空间的主体。
红黑树的特性,为什么要有红黑树
红黑树是一种自平衡的二叉搜索树,它具有以下特性:
- 节点颜色: 每个节点要么是红色,要么是黑色。
- 根节点和叶子节点: 根节点、叶子节点(NIL节点,即空节点)是黑色的
- 颜色相邻节点规则: 不能有两个相邻的红色节点。
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。 这保证了红黑树的关键性质:最长路径不超过最短路径的两倍。
2. 各操作的时间复杂度 插入: O(logN) 查看: O(logN) 删除: O(logN)
map/Set 实现原理,各操作的时间复杂度是多少
1. map 实现原理 map 内部实现了一个红黑树,红黑树有自动排序的功能,因此 map 内部所有元素都是有序的,红黑树的每一个节点都代表着 map 的一个元素。因此,对于 map 进行的查找、删除、添加等一系列的操作都相当于是对红黑树进行的操作。map 中的元素是按照二叉树存储的,特点就是左子树上所有节点的键值都小于根节点的键值,右子树所有节点的键值都大于根节点的键值,使用中序遍历可将键值按照从小到大遍历出来。
2. 各操作的时间复杂度 插入: O(logN) 查看: O(logN) 删除: O(logN)
unordered_map 实现原理
unordered_map 容器和 map 容器一样,以键值对(pair类型)的形式存储数据,存储的各个键值对的键互不相同且不允许被修改。但由于 unordered_map 容器底层采用的是哈希表存储结构,该结构本身不具有对数据的排序功能,所以此容器内部不会自行对存储的键值对进行排序。底层采用哈希表实现无序容器时,会将所有数据存储到一整块连续的内存空间中,并且当数据存储位置发生冲突时,解决方法选用的是“链地址法”(又称“开链法”).
map,unordered_map 的区别
- map是基于红黑树实现的,unordered_map是基于哈希表实现的
- map根据元素的键值会自动排序,而unordered_map是乱序的
- map的增删改查时间复杂度是O(logN),而unordered_map的时间复杂度是最好情况是O(1),最坏情况是O(N)。

相关文章:
C/C++工程师面试题(STL篇)
STL 中有哪些常见的容器 STL 中容器分为顺序容器、关联式容器、容器适配器三种类型,三种类型容器特性分别如下: 1. 顺序容器 容器并非排序的,元素的插入位置同元素的值无关,包含 vector、deque、list vector:动态数组…...

Effective Programming 学习笔记
1 基本语句 1.1 断言 在南溪看来,断言可以用来有效地确定编程中当前代码运行的前置条件,尤其是以下情况: 第三方工具库对输入数据的依赖,例如:minitouch库对Android版本的要求...
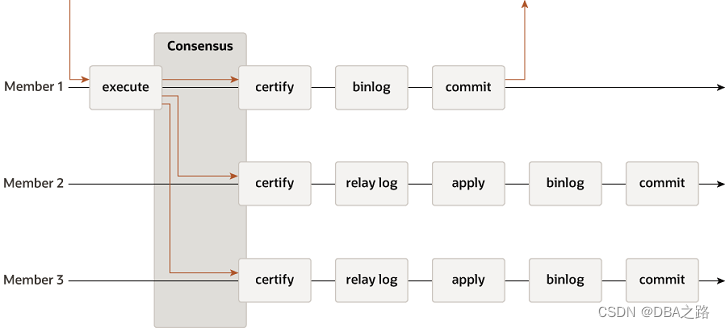
【MGR】MySQL Group Replication 背景
目录 17.1 Group Replication Background 17.1.1 Replication Technologies 17.1.1.1 Primary-Secondary Replication 17.1.1.2 Group Replication 17.1.2 Group Replication Use Cases 17.1.2.1 Examples of Use Case Scenarios 17.1.3 Group Replication Details 17.1…...

300分钟吃透分布式缓存-17讲:如何理解、选择并使用Redis的核心数据类型?
Redis 数据类型 首先,来看一下 Redis 的核心数据类型。Redis 有 8 种核心数据类型,分别是 : & string 字符串类型; & list 列表类型; & set 集合类型; & sorted set 有序集合类型&…...

思科网络设备监控
思科是 IT 行业的先驱之一,提供从交换机到刀片服务器的各种设备,以满足中小企业和企业的各种 IT 管理需求。管理充满思科的 IT 车间涉及许多管理挑战,例如监控可用性和性能、管理配置更改、存档防火墙日志、排除带宽问题等等,这需…...

深入剖析k8s-控制器思想
引言 本文是《深入剖析Kubernetes》学习笔记——《深入剖析Kubernetes》 正文 控制器都遵循K8s的项目中一个通用的编排模式——控制循环 for {实际状态 : 获取集群中对象X的实际状态期望状态 : 获取集群中对象X的期望状态if 实际状态 期望状态 {// do nothing} else {执行…...
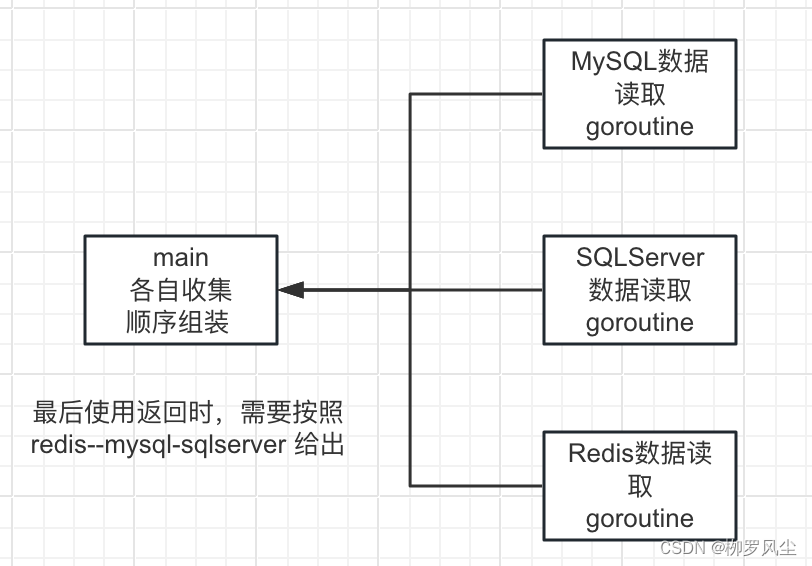
go并发模式之----使用时顺序模式
常见模式之二:使用时顺序模式 定义 顾名思义,起初goroutine不管是怎么个先后顺序,等到要使用的时候,需要按照一定的顺序来,也被称为未来使用模式 使用场景 每个goroutine函数都比较独立,不可通过参数循环…...
[动态规划]---part1
前言 作者:小蜗牛向前冲 专栏:小蜗牛算法之路 专栏介绍:"蜗牛之道,攀登大厂高峰,让我们携手学习算法。在这个专栏中,将涵盖动态规划、贪心算法、回溯等高阶技巧,不定期为你奉上基础数据结构…...
)
java 关于 Object 类中的 wait 和 notify 方法。(生产者和消费者模式!)
4、关于 Object 类中的 wait 和 notify 方法。(生产者和消费者模式!) 第一:wait 和 notify 方法不是线程对象的方法,是 java 中任何一个 java 对象都有的方法,因为这两个方法是 Object 类中自带的。 wait 方…...
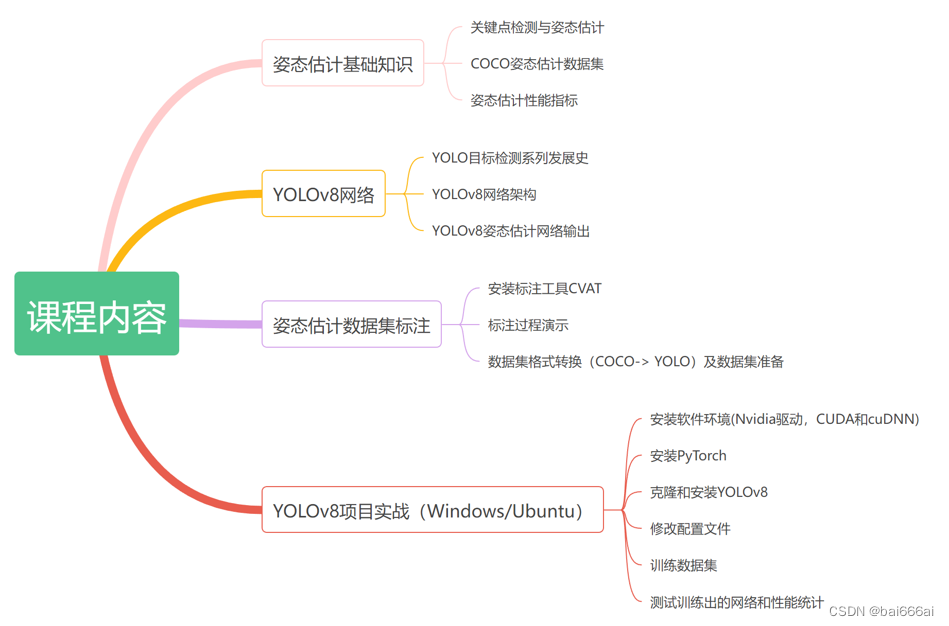
YOLOv8姿态估计实战:训练自己的数据集
课程链接:https://edu.csdn.net/course/detail/39355 YOLOv8 基于先前 YOLO 版本的成功,引入了新功能和改进,进一步提升性能和灵活性。YOLOv8 同时支持目标检测和姿态估计任务。 本课程以熊猫姿态估计为例,将手把手地教大家使用C…...
【海贼王的数据航海:利用数据结构成为数据海洋的霸主】链表—双向链表
目录 往期 1 -> 带头双向循环链表(双链表) 1.1 -> 接口声明 1.2 -> 接口实现 1.2.1 -> 双向链表初始化 1.2.2 -> 动态申请一个结点 1.2.3 -> 双向链表销毁 1.2.4 -> 双向链表打印 1.2.5 -> 双向链表判空 1.2.6 -> 双向链表尾插 1.2.7 -&…...

做测试还是测试开发,选职业要慎重!
【软件测试面试突击班】2024吃透软件测试面试最全八股文攻略教程,一周学完让你面试通过率提高90%!(自动化测试) 突然发现好像挺多人想投测开和测试的,很多人面试的时候也会被问到这几个职位的区别,然后有测…...

Java面试题总结200道(二)
26、简述Spring中Bean的生命周期? 在原生的java环境中,一个新的对象的产生是我们用new()的方式产生出来的。在Spring的IOC容器中,将这一部分的工作帮我们完成了(Bean对象的管理)。既然是对象,就存在生命周期,也就是作用…...
面试数据库篇(mysql)- 03MYSQL支持的存储引擎有哪些, 有什么区别
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式 。存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。 MySQL体系结构 连接层服务层引擎层存储层 存储引擎特点 InnoDB MYSQL支持的存储引擎有哪些, 有什么区别 ? my…...

MySQL深入——25
Join语句如何优化? Join语句的两种算法,分别为Index Nested-Loop Join和Block Nested-Loop Join NLJ在大表Join当中还不错,但BNL在大表join时性能就差很多,很耗CPU资源。 如何优化这两个算法 创建t1,t2算法,在t1中…...

Docker运行时安全之道: 保障容器环境的安全性
引言 Docker作为容器化技术的领军者,为应用部署提供了灵活性和便捷性。然而,在享受这些优势的同时,必须重视Docker运行时的安全性。本文将深入研究一些关键的Docker运行时安全策略,以确保你的容器环境在生产中得到有效的保护。 1. 使用最小特权原则 保持容器以最小权限运…...
前后端分离项目Docker部署指南(上)
目录 前言 一.搭建局域网 1.搭建net-ry局域网,用于部署若依项目 2.注意点 二.安装redis 创建目录 将容器进行挂载 编辑 测试是否安装成功 编辑 三. 安装MySQL 创建文件夹 上传配置文件并且修改 .启动MySQL容器服务 充许远程连接 四.部署后端 使用…...

ARM 架构下国密算法库
目录 前言GmSSL编译环境准备下载 GmSSL 源码编译 GmSSL 源码SM4 对称加密算法SM2 非对称加密算法小结前言 在当前的国际形式下,国替势不可挡。操作系统上,银河麒麟、统信 UOS、鸿蒙 OS 等国产系统开始发力,而 CPU 市场,也是百花齐放,有 龙芯(LoongArch架构)、兆芯(X86…...

源码的角度分析Vue2数据双向绑定原理
什么是双向绑定 我们先从单向绑定切入,其实单向绑定非常简单,就是把Model绑定到View,当我们用JavaScript代码更新Model时,View就会自动更新。那么双向绑定就可以从此联想到,即在单向绑定的基础上,用户更新…...

动态规划(算法竞赛、蓝桥杯)--树形DP树形背包
1、B站视频链接:E18 树形DP 树形背包_哔哩哔哩_bilibili #include <bits/stdc.h> using namespace std; const int N110; int n,V,p,root; int v[N],w[N]; int h[N],to[N],ne[N],tot; //邻接表 int f[N][N];void add(int a,int b){to[tot]b;ne[tot]h[a];h[a…...

深度解析:基于RAG与任务执行的AI Agent全能力矩阵在话务系统的工程实践
在企业通讯架构演进中,话务系统正经历从流程驱动向智能驱动的范式转移。传统话务台高度依赖预设的IVR流程与人工查询,不仅交互生硬,且存在严重的数据孤岛问题。本文将聚焦AI Agent的全能力矩阵,从技术架构与业务逻辑层面ÿ…...

调查研究-141 全球机器人产业深度调研报告【03篇】机器人产业六大利润池:从核心零部件到软件平台的商业逻辑
TL;DR 场景:关注机器人产业商业模式、利润分配和投资机会的投资者、从业者、分析人士结论:机器人产业利润集中在核心零部件(减速器/伺服/电机)、软件AI平台和医疗机器人耗材;本体和集成利润率有限产出:六大…...

消费级EEG眼动追踪技术:原理、应用与挑战
1. 消费级EEG眼动追踪技术概述 在脑机接口(BCI)研究领域,利用脑电信号(EEG)中的眼动伪迹进行视线追踪(ET)正逐渐成为一种创新方法。传统基于摄像头的眼动追踪技术虽然成熟,但在实际应用中存在明显局限——需要充足光照条件、无法在闭眼状态下工作&#…...

Anthropic率先盈利:大模型商业化曙光初现,IPO竞争谁能笑到最后?
1. 前沿模型盈利曙光乍现前沿模型公司的利润表终于出现了正数。据《华尔街日报》报道,Anthropic正迎来关键季度,预计2026年第二季度收入超109亿美元,较第一季度的48亿美元增长超一倍,且首次实现季度营业利润。路透社称其二季度预计…...
)
Linux】2026 年 13 款最强视频播放器(含安装命令 + 优缺点)
Linux视频播放器选择多样,如榛名、MPlayer、VLC等,功能强大、支持多格式,满足各类用户需求 一、榛名视频播放器 榛名视频播放器是一款基于Qt的开源视频播放器,提供了许多基本功能。其特点包括支持Youtube-dl、控制播放速度、丰富…...
)
【性能评估】信标辅助双跳认知无线电无线中继选择方案的性能评估研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

互联网大厂 Java 求职面试实战:音视频场景中的技术挑战
互联网大厂 Java 求职面试实战:音视频场景中的技术挑战在这个互联网飞速发展的时代,越来越多的求职者走进了大厂的面试现场。今天,我们将跟随一位搞笑的程序员燕双非,来看看他在面试中的表现,以及他如何应对各种技术问…...

2026年免费去水印工具哪个好用?免费好用的去水印工具对比推荐
在2026年,无论是自媒体运营者、内容创作者还是普通用户,去水印都是日常高频操作。但面对市场上琳琅满目的去水印工具,要找到一款免费好用的去水印工具着实不易。本文将从多个维度对免费去水印工具对比 2026的各类产品进行详细评测,…...

强化学习实战指南:从原理到工业落地的完整路径
1. 这不是科幻,是正在发生的现实:当机器在围棋、电竞、物流调度甚至蛋白质折叠中全面超越人类你有没有过这种感觉:刷到一条新闻说“AI又赢了人类冠军”,第一反应不是惊讶,而是点开前先猜——这次输的是围棋手、星际争霸…...

【Go Interface】接口诞生的意义
结论:接口(Interface)诞生的唯一意义:解耦接口的诞生,是为了解决软件工程里最致命的痛点:“上层代码”被“底层细节”死死绑架。没有接口时的痛苦假设你的 naga 模块现在要保存心跳数据。 第一周࿰…...