建库建表时,最容易忽略的10个细节
大家使用 DolphinDB 创建数据库和表时,有时对于分区列、分区类型和排序列的选择并不十分清晰。如果不加注意,可能导致查询速度变慢、数据丢失或插入错误等问题。合理地设置分区列、排序列和分区类型,有助于加快查询速度,减少内存使用,并提高 CPU 利用率。
以下内容可以帮助大家更好地了解创建数据库和表时需注意的细节,优化脚本质量。
1. 分区与储存结构简介
1.1 分区类型
分区是进行数据管理和提高分布式文件系统性能的重要手段之一。通过分区实现对大型表的有效管理。一个合理的分区策略能够仅读取查询所需的数据,以减少扫描的数据量,从而降低系统响应延迟。
DolphinDB 支持多种分区类型: 范围分区、哈希分区、值分区、列表分区与复合分区。选择合适的分区类型,有助于用户根据业务特点对数据进行均匀分割。
- 范围分区对每个分区区间创建一个分区。
- 哈希分区利用哈希函数对分区列操作,方便建立指定数量的分区。
- 值分区每个值创建一个分区,例如股票交易日期、股票交易月等。
- 列表分区是根据用户枚举的列表来进行分区,比值分区更加灵活。
- 复合分区适用于数据量特别大而且 SQL where 或 group by 语句经常涉及多列。可使用 2 个或 3 个分区列,每个分区选择都可以采用区间、值、哈希或列表分区。例如按股票交易日期进行值分区, 同时按股票代码进行范围分区。
1.2 分区与数据读写的关系
DolphinDB 以分区为单位管理数据,数据写入和数据读取都是按分区为单位进行的。
对于数据写入,DolphinDB 会将数据按分区写入磁盘,并且对于同一个分区,不允许并发写入数据。对于数据读取,DolphinDB 会根据查询条件进行分区剪枝,排除不符合条件的分区,缩窄查询范围,只对符合查询条件的分区进行读取,分区字段和分区粒度的选择很大程度上影响了查询的效率。
1.3 储存结构
目前 DolphinDB 有 TSDB 和 OLAP 两种储存引擎。OLAP 为列式存储引擎,将数据表中每个分区的每一列存为一个文件。数据在表中的存储顺序与数据写入的顺序一致,数据写入有非常高的效率。TSDB 是基于 LSM 树的存储引擎,其储存结构为行列混存。每一个分区的数据写在一个或多个 Level File 中。每一个 Level File 内部的数据按照指定的列进行排序且创建块索引。
1.3.1 排序列
排序列是 TSDB 引擎特有的结构,它在 TSDB 引擎的存储和读取流程中发挥着重要作用,包括分区内数据索引和去重的双重作用。在创建表时通过参数 sortColumns 来定义排序列,sortColumns 的最后一列必须是时间类型,而除了最后一列之外的其他列被称为 排序键(Sort Key),每个排序键独特值对应的数据按列顺序存储在一起。排序键字段的组合值作为索引键,为数据查询提供了入口,能够迅速定位数据块的位置,从而降低查询时间。在写入过程中,每个事务中的数据会根据 sortColumns 进行排序和去重。
TSDB 引擎的分区内索引包括每个索引键和字段组合的入口信息以及稀疏索引(最大值,最小值,个数和)信息。当索引键个数 X 字段数很大时,索引数据会很大,这对写入性能,查询性能和内存使用都会产生重大影响,可以通过对排序键进行哈希降维来减少索引数量。
2. 建库建表时容易忽略的细节
2.1 使用 TSDB 引擎时单个索引键对应的数据条数过少
使用 TSDB 引擎建表时要指定排序列字段,但是随意设置排序列可能会导致索引键对应的数据过少,会使查询变慢。推荐索引键对应的数据量大于一万行,当每个索引键对应很少的数据量的时候,会产生以下几个问题:
- 由于数据总量不变,导致索引键非常多,索引信息占据大量内存。
- 数据碎片化存储,导致数据读写效率降低。
- 由于数据按照 block 进行压缩,而 block 是每个索引键对应数据按照数据量进行划分的,若每个 block 数据量很少,压缩率也会降低。
2.1.1 错误例子
例子:股票数据(假设股票数量为 5000 支,每天记录 2000 万条,每天数据量为 800 MB),按交易日期字段作为值分区条件。
情况1:只使用 TradeTime 作为排序列会导致索引键数量过多,但是每个索引键对应的数据量又特别少。
单个排序列时,该列就称为排序键,一个分区的索引键数量计算公式:索引键数量 = 每个分区内的排序键独特值数量。
以下例子中,每个分区索引键数量 = TradeTime 去重后的数量。由于 TradeTime 为股票交易时间,即使按秒级别计算一天也有 4 * 3600 = 14400 个独特值,实际上 TradeTime 为毫秒级,故索引键数量远大于 14400 。
db=database("dfs://testDB1",VALUE, 2020.01.01..2021.01.01,engine="TSDB")
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=`pt1, partitionColumns=`TradeDate, sortColumns=`TradeTime, keepDuplicates=ALL)假设交易时间为半秒级,索引键数量为 28800 个,每个索引键对应的行数为 694。
情况2:使用 SecurityID、TradeTime 作为 sortColumns 会导致索引键数量和股票代码数量一样。
多个 sortColumns 时索引键计算公式:索引键数量 = 每个分区内的除去最后一列外其余字段独特值组合值数量。
以下例子中,每个分区索引键的数量为 SecurityID 独特值的数量,即 5000 个。
db=database("dfs://testDB1",VALUE, 2020.01.01..2021.01.01,engine="TSDB")
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=`pt2, partitionColumns=`TradeDate, sortColumns=`SecurityID`TradeTime, keepDuplicates=ALL)假设股票数量为 5000 只,索引键数量为 5000 个,每个索引键对应的行数为 4000。
2.1.2 解决方案
对于上述例子中的情况可以通过以下方案解决。
情况1:只有一个 sortColumns 字段时不选择时间相关的或者去重后数量过多的字段。比如将 TradeTime 替换为 SecurityID 作为 sortColumn。
该方案中,每个分区索引键数量 = SecurityID 去重后的数量 = 5000。每个索引键对应的行数为 4000 和上述例子中的情况2一样。
db=database("dfs://testDB1",VALUE, 2020.01.01..2021.01.01,engine="TSDB")
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=`pt3, partitionColumns=`TradeDate, sortColumns=`SecurityID, keepDuplicates=ALL)还可以对 SecurityID 排序列进行哈希降维。每个分区索引键数量 = 哈希降维后的数量(500)。每个索引键对应的行数为 40000。
db=database("dfs://testDB1",VALUE, 2020.01.01..2021.01.01,engine="TSDB")
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=`pt4, partitionColumns=`TradeDate, sortColumns=`SecurityID keepDuplicates=ALL,sortKeyMappingFunction=[hashBucket{,500}])情况2:有多个 sortColumns 字段时,可以配置 sortKeyMappingFunction 参数进行哈希降维(会影响相关 sortColumns 字段的点查性能,但是会提升范围查询性能)。如果每个分区内除最后一个时间列外,其余字段组合数量超过 1000 ,可以配置 sortKeyMappingFunction 参数进行哈希降维。
使用 SecurityID、TradeTime 作为 sortColumn 并配置 sortKeyMappingFunction 参数进行哈希降维。
多个 sortColumn 时索引键计算公式:索引键数量 = 每个分区内的除去最后一列外其余字段去重(或者哈希降维)后数量相乘。
以下例子中,每个分区索引键数量 = 哈希降维后的数量(500)。每个索引键对应的行数为 40000。
db=database("dfs://testDB1",VALUE, 2020.01.01..2021.01.01,engine="TSDB")
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=`pt5, partitionColumns=`TradeDate, sortColumns=`SecurityID`TradeTime, keepDuplicates=ALL,sortKeyMappingFunction=[hashBucket{,500}])2.1.3 性能测试结果
按照上述五种建表方案进行建表,然后导入 10 天的数据(每天 2000 万条记录)测试其查询性能。
范围查询:
select avg(TradePrice) from pt where TradeDate between 2020.01.04 and 2020.01.05| 排序列 | 每个分区索引键数 | 平均耗时(ms) | 最大耗时(ms) |
|---|---|---|---|
| TradeTime | 28,800 | 167.9 | 215.1 |
| SecurityID、TradeTime | 5000 | 46.3 | 68.6 |
| SecurityID | 5000 | 47.7 | 66.9 |
| SecurityID(哈希降维) | 500 | 6.6 | 8.5 |
| SecurityID(哈希降维)、TradeTime | 500 | 6.7 | 7.9 |
点查询 1(TradeDate + SecurityID):
select avg(TradePrice) from pt where TradeDate = 2020.01.04 and SecurityID=`600| 排序列 | 每个分区索引键数 | 平均耗时(ms) | 最大耗时(ms) |
|---|---|---|---|
| TradeTime | 28,800 | 2002.6 | 2562.8 |
| SecurityID、TradeTime | 5000 | 4.0 | 4.7 |
| SecurityID | 5000 | 3.4 | 4.7 |
| SecurityID(哈希降维) | 500 | 6.5 | 8.5 |
| SecurityID(哈希降维)、TradeTime | 500 | 7.7 | 8.3 |
点查询 2(TradeDate + SecurityID + TradeTime):
select TradePrice from pt where TradeDate = 2020.01.04 and SecurityID=`3740 and TradeTime =09:30:00.000| 排序列 | 每个分区索引键数 | 平均耗时(ms) | 最大耗时(ms) |
|---|---|---|---|
| TradeTime | 28,800 | 1.4 | 2.1 |
| SecurityID、TradeTime | 5000 | 1.5 | 2.6 |
| SecurityID | 5000 | 1.4 | 2.3 |
| SecurityID(哈希降维) | 500 | 5.0 | 7.3 |
| SecurityID(哈希降维)、TradeTime | 500 | 6.2 | 8.0 |
通过上述性能测试实验结果,可以得出结论:排序列设置不合理,查询字段中没有排序列字段,查询性能将大幅下降。对于范围查询索引键对应的数据过少,会影响其性能,可以通过哈希降维大幅提升性能(点查询性能会略微下降)。
2.2 值(VALUE)分区字段为含特殊字符的字符串
值(VALUE)分区字段为字符串类型时,追加的分区列数据不能包含空格、“/n”、 “/r”、“/t”等特殊字符。如果后续插入的数据对应字段有特殊字符,会导致数据插入失败。
2.2.1 错误例子
建表时未考虑后续将设置为值(VALUE)分区字段的列内是否包含特殊字符,导致数据插入该列时因存在特殊字符而失败。
n=1000
ID=take(["1","2","3"], n);
x=rand(1.0, n);
t=table(ID, x);
//将ID列作为值分区
db=database(directory="dfs://valuedb", partitionType=VALUE, partitionScheme=["1"])
pt = db.createPartitionedTable(t, `pt, `ID);
pt.append!(t);
n=1000
ID=take(["1 12","2.12","3 12"], n);
x=rand(1.0, n);
t=table(ID, x);
pt.append!(t);上述代码会报错:A string or symbol value-partitioning column can't contain any invisible character。
2.2.2 解决方案
对于前述例子中的错误,如果这些不可见的特殊字符无意义,可以在插入前删除。如果有意义,可以将该字段设置为哈希(HASH)分区来替代值分区方案。哈希(HASH)分区的数量需要按照具体数据量进行设置,避免分区粒度过大或者过小。或者将对应字段数据进行处理后插入。
2.3 范围(RANGE)分区时范围设置不合理导致插入数据丢失
采用范围(RANGE)分区策略时,如果插入数据的范围(RANGE)分区字段的值在预定义的分区范围外,那么这条记录将不会被插入到表中。tableInsert会返回插入记录的条数以此判断是否有数据在范围(RANGE)分区外而没有存入分区表中。
2.3.1 错误例子
以下例子中,第 2 行 ID 和第 6 行 partitionScheme 的设置存在范围不一致的情况。
n=1000000
ID=rand(20, n)//数据范围是0-20
x=rand(1.0, n)
t=table(ID, x);
//设置分区时RANGE范围是0-5,5-10
db=database(directory="dfs://rangedb", partitionType=RANGE, partitionScheme=0 5 10)pt = db.createPartitionedTable(t, `pt, `ID);
//tableInsert之后只有在0-10部分的数据才被插入,其余的都被丢弃。
tableInsert(pt,t);上述例子通过 tableInsert 插入后返回 499972 条(远小于 1000000)。
2.3.2 解决方案
由于 partitionScheme 设置为 0 5 10,导致只有 0-10 部分数据插入成功,其余部分数据丢失。因此应该设置合适的分区范围,考虑后续数据的范围。或者可以通过 addRangePartitions 函数后续添加分区范围。
2.4 分区粒度过小
分区类型或者分区字段设置不合理会导致分区粒度过小。分区粒度过小可能会导致以下问题:
- 如果查询范围较大,会报错 "The number of partitions relevant to the query is too large."
- 使用 TSDB 引擎时,Level File 索引缓存(LevelFileIndexCache)大量被占用,可能导致所有使用 TSDB 引擎的数据库的查询变慢。
- 查询和计算作业往往会生成大量的子任务,增加数据节点和控制节点之间及控制节点之间的通讯和调度成本。
- 造成很多低效的磁盘访问(小文件读写),导致系统负荷过重。
- 所有分区的元数据都会驻留在控制节点的内存中,过多的分区可能会导致控制节点内存不足。
因此,建议每个分区未压缩前的数据量不要小于 100 MB。
2.4.1 错误例子
例子:股票行情数据(每天 5000 万条记录),先按日期分区然后将股票代码字段按值分区。选择使用 TradeDate、SecurityID 二级分区,而且 SecurityID 是值分区,假设全是国内股票,一天分区数量就达到 5000+。每天数据量为 3 GB(内存中),每个分区大小约为 0.6 MB。
1.默认最大查询分区数为 65536,假设每天 5000 个股票,查询 14 天的数据就会报错The number of partitions relevant to the query is too large。
2.Level File 索引缓存容量默认是最大内存的5%,虽然单个分区的 Level File 索引(LevelFileIndex) 较小,但是如果查询分区数非常多,会导致马上占满 Level File 索引缓存。占满 Level File 索引缓存之后会导致查询效率大幅度下降。
db1 = database(, VALUE, 2020.01.01..2021.01.01)
db2 = database(, VALUE, `a`b)
db = database(directory="dfs://testDB1", partitionType=COMPO, partitionScheme=[db1, db2], engine="TSDB")
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=`pt, partitionColumns=`TradeDate`SecurityID, sortColumns=`SecurityID`TradeTime, keepDuplicates=ALL)2.4.2 解决方案
对于上述例子,先按日期分区,然后将股票代码字段 HASH 分区(需要根据每天的量估计 HASH 多少个分区,一般一个分区占用内存应控制在 100MB-1GB 之间),每天只有 25 个分区,每天数据量为 3 GB(内存中),每个分区大小约为 120 MB。
db1 = database(, VALUE, 2020.01.01..2021.01.01)
db2 = database(, HASH, [SYMBOL, 25])
db = database(directory="dfs://testDB2", partitionType=COMPO, partitionScheme=[db1, db2], engine="TSDB")
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=`pt, partitionColumns=`TradeDate`SecurityID, sortColumns=`SecurityID`TradeTime, keepDuplicates=ALL)2.4.3 性能测试结果
按照上述两种建表方案进行建表,然后导入 10 天的数据(每天 5000 万条记录)测试其范围查询性能。
select avg(TradePrice) from pt where TradeDate=2020.01.04| 建表方案 | 平均耗时(ms) | 最大耗时(ms) |
|---|---|---|
| 日期值分区+股票代码值分区 | 214.4 | 378.1 |
| 日期值分区+股票代码哈希分区 | 13.6 | 20.5 |
通过上述性能测试实验结果,可以得出结论:如果分区粒度过小会导致查询效率过低,建库建表时要选择合适的分区粒度。
2.5 分区粒度过大
分区类型或者分区字段设置不合理会导致分区粒度过大。若分区粒度过大,可能造成:
- 多个工作线程并行时内存不足。
- 系统频繁地在磁盘和工作内存之间切换,影响性能。
- 无法有效利用 DolphinDB 多节点多分区的优势,将本可以并行计算的任务转化成了顺序计算任务。
2.5.1 错误例子
以下例子中的股票行情数据(每天 5000 万条记录),直接按日期分区,一天数据大约有 3 GB(内存中)。
//按交易日期分区
db= database("dfs://testDB1", VALUE, 2020.01.01..2021.01.01)
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
//每天只有1个分区,假设每天数据量为3GB(内存中),每个分区大小约为3GB,分区粒度过大
db.createPartitionedTable(table=tbSchema, tableName=`pt, partitionColumns=`TradeDate)2.5.2 解决方案
对以下例子中的股票行情数据,先按日期分区然后将股票代码字段哈希分区(需要根据每天的量估计需要哈希的分区数量,一般一个分区内存中大小 100 MB - 1 GB 之间)。
//先按交易日期分区,然后按股票代码进行哈希分区
db1 = database(, VALUE, 2020.01.01..2021.01.01)
db2 = database(, HASH, [SYMBOL, 25])
db = database(directory="dfs://testDB2", partitionType=COMPO, partitionScheme=[db1, db2])
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
//每天只有25个分区,假设每天数据量为3GB(内存中),每个分区大小约为120MB
db.createPartitionedTable(table=tbSchema, tableName=`pt, partitionColumns=`TradeDate`SecurityID)2.5.3 性能测试结果
按照上述两种建表方案进行建表,然后导入 10 天的数据(每天 5000 万条记录)测试其点查性能。
select avg(TradePrice) from pt where SecurityID=`600| 建表方案 | 平均耗时(ms) | 最大耗时(ms) |
|---|---|---|
| 日期值分区 | 560.4 | 683.1 |
| 日期值分区+股票代码哈希分区 | 31.2 | 40.8 |
通过上述性能测试实验结果,可以得出结论:如果分区粒度过大会导致查询效率过低,建库建表时要选择合适的分区粒度。
2.6 使用维度表存储大数据量的表
维度表会将整个表加载入内存,并且不会自动释放( 2.00.11 版本之前)。如果创建维度表时未考虑之后的大数据量,会导致查询速度随数据量增加而下降,并占用大量内存。
2.6.1 错误例子
使用维度表存储超过 20 万条记录的数据或难以估算的数据。
例子:以每天产生 2000 万条记录的股票数据为例,如果使用仅有一个分区的维度表,不到几天该表里就会有几亿条数据。假设每天的数据量为 800 MB(内存中),读取维度表数据时会将整个维度表加载入内存,不到几天,内存就会被大量占用。
db= database("dfs://testDB1", VALUE, 2020.01.01..2021.01.01)
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
db.createTable(tbSchema,`dt)所以在预估数据量明确或较少时,可以使用维度表;预估数据量较多时,应该使用分区表。
2.6.2 解决方案
上述例子中每天产生 2000 万条股票数据。为了处理这些数据,可以使用分区表:
- 首先按交易日期进行分区。
- 然后按股票代码进行哈希分区,每天只会有 25 个分区。
以下代码为使用分区表方案建表:
db1 = database(, VALUE, 2020.01.01..2021.01.01)
db2 = database(, HASH, [SYMBOL, 25])
db = database(directory="dfs://testDB2", partitionType=COMPO, partitionScheme=[db1, db2])
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=`pt, partitionColumns=`TradeDate`SecurityID)2.6.3 性能测试结果
按照上述两种建表方案进行建表,然后导入一天的数据( 2000 万条记录)测试其点查性能。
select avg(TradePrice) from tb where SecurityID=`600| 建表方案 | 平均耗时(ms) | 最大耗时(ms) |
|---|---|---|
| 维度表 | 1385.5 | 1545.2 |
| 日期值分区+股票代码哈希分区 | 36.0 | 60.3 |
通过上述性能测试实验结果,可以得出结论:预估数据量明确或较少时,可以使用维度表;预估数据量较多时,应该使用分区表。如果数据量非常多时使用维度表,其查询性能将非常差。
2.7 分区字段选择不合理导致查询速度慢
如果经常查询的字段没有设置为分区字段,而且查询语句中没有涉及分区字段,会导致数据库无法进行分区剪枝,并因扫描所有数据使查询缓慢。
2.7.1 错误例子
例子:对于以下例子中的股票数据,只按股票代码进行分区,如果该数据经常按交易日期和股票代码进行查询,只设置股票代码作为分区列不但会导致按交易日期进行查询时会扫描所有分区,而且会导致分区大小因为每天有数据插入不断变大。
db = database("dfs://testDB1",HASH, [SYMBOL, 25])
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=`pt, partitionColumns=`SecurityID)2.7.2 解决方案
对于上述例子中的股票数据,按交易日期和股票代码进行分区。如果该数据经常按交易日期和股票代码进行查询,可以设置交易日期和股票代码作为分区列。
db1 = database(, VALUE, 2020.01.01..2021.01.01)
db2 = database(, HASH, [SYMBOL, 25])
db = database("dfs://testDB2", partitionType=COMPO, partitionScheme=[db1, db2])
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=`pt, partitionColumns=`TradeDate`SecurityID)2.7.3 性能测试结果
按照上述两种建表方案进行建表,然后导入 10 天的数据(每天 2000 万条记录)测试其点查性能。
select avg(TradePrice) from pt where SecurityID=`600 and TradeDate=2020.01.04| 建表方案 | 平均耗时(ms) | 最大耗时(ms) |
|---|---|---|
| 股票代码哈希分区 | 174.5 | 193.1 |
| 日期值分区+股票代码哈希分区 | 38.1 | 50.4 |
通过上述性能测试实验结果,可以得出结论:选择分区字段时,应该考虑经常查询字段以提升查询效率。
2.8 分区字段选择不合理导致并发写入冲突
为了最大程度优化数据仓库查询、分析、计算的性能,DolphinDB 对事务作了一些限制:
- 首先,一个事务只能包含写或者读,不能同时进行写和读。
- 其次,一个写事务可以跨越多个分区,但是同一个分区不能被并发写入。当一个分区被某一个事务 A 锁定之后,另一个事务 B 试图再次去锁定这个分区时,系统立刻会抛出异常导致事务 B 失败回滚。
建库建表时未考虑后续可能出现的并发写入。出现并发写入时,由于分区冲突,导致并发写入失败。
2.8.1 错误例子
以下例子中,由于建库建表时未考虑后续出现的并发写入,未将各个并发数据不同的字段设置为分区,导致并发写入冲突。
//假设后续并发,是按照日期进行写入,只按股票代码进行分区
db = database("dfs://testDB",HASH, [SYMBOL, 25])
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
//只按股票代码进行分区,而并发写入按照日期进行会导致并发写入冲突,报错“has been owned by transaction”
db.createPartitionedTable(table=tbSchema, tableName=`pt, partitionColumns=`SecurityID)以上建库建表代码按日期并发写入时会报错:xxx has been owned by transaction。
2.8.2 解决方案
对于上述情况有以下解决方法:
- 建库建表时可以按照按日期分区的方式进行建库建表,并行写入程序也按日期划分写入数据。
- 根据分区情况调整并行写入程序,避免写入分区重合。
- 如果使用相关 api 进行写入,可以使用 api 中的并行写入函数,自动对写入数据进行划分,比如 c++ api 和 python api 中的 PartitionedTableAppender。
上述解决方法目的都是,避免同一个分区同时被多个写入事务写入的情况。
2.9 数据量与日俱增的表未使用日期字段分区
一些数据量随日期不断增加的表,没有使用日期字段作为分区字段。数据量随时间增加会导致分区过大,影响查询性能。
2.9.1 错误例子
数据量随日期不断增加的表中,没有把日期字段设为分区列。
例子:对于以下例子中的股票数据,只按股票代码分区,导致按交易日期进行查询时会扫描所有分区,并且分区随每天的数据插入不断变大。
db = database("dfs://testDB1",HASH, [SYMBOL, 25])
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=`pt, partitionColumns=`SecurityID)对于数据量随日期不断增加的表,应将日期字段设为分区列。
2.9.2 解决方案
对于上述例子中的股票数据,按照交易日期和股票代码进行了分区。
这样每个分区不会因为每天的数据插入而不断变大。由于按照交易日期进行了分区,新的分区会随着日期变化而生成。
db1 = database(, VALUE, 2020.01.01..2021.01.01)
db2 = database(, HASH, [SYMBOL, 25])
db = database("dfs://testDB2", partitionType=COMPO, partitionScheme=[db1, db2])
colName = `SecurityID`TradeDate`TradeTime`TradePrice`TradeQty`TradeAmount`BuyNo`SellNo
colType = `SYMBOL`DATE`TIME`DOUBLE`INT`DOUBLE`INT`INT
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=`pt, partitionColumns=`TradeDate`SecurityID)2.9.3 性能测试结果
按照上述两种建表方案进行建表,然后导入 10 天的数据(每天 2000 万条记录)测试其点查性能。
select avg(TradePrice) from pt where SecurityID=`600 and TradeDate=2020.01.04| 建表方案 | 平均耗时(ms) | 最大耗时(ms) |
|---|---|---|
| 股票代码哈希分区 | 174.5 | 193.1 |
| 日期值分区+股票代码哈希分区 | 38.1 | 50.4 |
通过上述性能测试实验结果,可以得出结论:对于数据量与日俱增的表应使用日期字段作为分区字段,提升查询效率。
2.10 使用 OLAP 引擎存储宽表
因为 OLAP 引擎采用列式存储,每个分区的每一列数据都存储为一个文件。列文件过多时,会出现读写时的性能瓶颈,因此 OLAP 引擎不适于存储列数过多的宽表。如果使用 OLAP 引擎存储数据,表的列数应低于 100。
由于 TSDB 引擎采用行列混存的存储策略,在存储宽表数据时,其产生的物理文件数量少于 OLAP 引擎。
2.10.1 错误例子
例子:每个 ID 有 200 个因子,每个因子为一列,该表一共 203 列。使用 OLAP 引擎存储该表。
db= database("dfs://testDB1", VALUE, 2020.01.01..2021.01.01)
//202行的宽表,使用OLAP引擎(默认为OLAP)
colName = `ID`Date`Time
colName.append!(take("factor"+string(0..200),200))
colType = `SYMBOL`DATE
colType.append!(take(["DOUBLE"],200))
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=`pt, partitionColumns=`Date)2.10.2 解决方案
对于上述例子中表列数为 203,采用 TSDB 引擎存储该表能够避免读写时可能出现的性能瓶颈。
db= database("dfs://testDB2", VALUE, 2020.01.01..2021.01.01,engine="TSDB")
//203行的宽表,使用TSDB引擎
colName = `ID`Date`Time
colName.append!(take("factor"+string(0..200),200))
colType = `SYMBOL`DATE`TIME
colType.append!(take(["DOUBLE"],200))
tbSchema = table(1:0, colName, colType)
db.createPartitionedTable(table=tbSchema, tableName=`pt, partitionColumns=`Date,sortColumns=`ID`Time)2.10.3 性能测试结果
按照上述两种建表方案进行建表,然后导入 10 天的数据(每天 200 万条记录)测试其点查性能。
select avg(factor2) from pt where ID=`60 and Date=2020.01.04| 引擎 | 平均耗时(ms) | 最大耗时(ms) |
|---|---|---|
| OLAP 引擎 | 62.6 | 95.9 |
| TSDB 引擎 | 1.2 | 1.3 |
通过上述性能测试实验结果,可以得出结论:对于列数大于 100 列的表可以使用 TSDB 引擎,提升查询效率。
3. 总结
本文介绍了使用 DolphinDB 进行建库建表时,最容易忽略的 10 个细节。这些错误用法的产生,是由于对 DolphinDB 分区机制和数据库引擎原理不了解导致的。如果想进一步了解 DolphinDB 原理层面的细节,可以参考:TSDB 存储引擎详解 (dolphindb.cn)、数据库分区 (dolphindb.cn)、分布式表数据更新原理和性能 (dolphindb.cn)。
最后,我们来归纳一下建库建表的要点:
- 根据业务特点选择合适的引擎(比如宽表选择TSDB引擎)
- 根据业务特点选择分区字段和类型
- 根据分区大小在 100 MB - 1 GB 的原则设计分区粒度
- 根据业务特点完善对应引擎独有的参数(比如TSDB引擎特有的排序列)
相关文章:

建库建表时,最容易忽略的10个细节
大家使用 DolphinDB 创建数据库和表时,有时对于分区列、分区类型和排序列的选择并不十分清晰。如果不加注意,可能导致查询速度变慢、数据丢失或插入错误等问题。合理地设置分区列、排序列和分区类型,有助于加快查询速度,减少内存使…...
)
【基础知识】什么是 PPO(Proximal Policy Optimization,近端策略优化)
什么是 PPO(Proximal Policy Optimization,近端策略优化) PPO(Proximal Policy Optimization,近端策略优化)是一种强化学习算法,由John Schulman等人在2017年提出。PPO属于策略梯度方法&#x…...

程序员如何选择职业赛道?
程序员如何选择职业赛道? 程序员的职业赛道就像是一座迷宫,充满了各种各样的岔路口。每个岔路口都代表着不同的方向,不同的技术领域,不同的职业发展道路。 前端开发 前端开发就像迷宫中的美丽花园,它是用户与网站或应…...
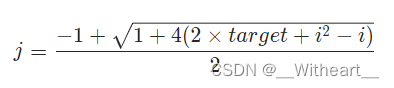
[LeetBook]【学习日记】寻找和为指定数字的连续数字
题目 文件组合 待传输文件被切分成多个部分,按照原排列顺序,每部分文件编号均为一个 正整数(至少含有两个文件)。传输要求为:连续文件编号总和为接收方指定数字 target 的所有文件。请返回所有符合该要求的文件传输组…...

阿里云中小企业扶持权益
为企业提供云资源和技术服务,助力企业开启智能时代创业新范式。阿里云推出中小企业扶持权益 上云必备,助力企业长期低成本用云 一、ECS-经济型e实例、ECS u1实例活动规则 活动时间 2023年10月31日0点0分0秒至2026年3月31日23点59分59秒 活动对象 同时满…...

2核4g服务器能支持多少人访问?并发数性能测评
2核4g服务器能支持多少人访问?支持80人同时访问,阿腾云使用阿里云2核4G5M带宽服务器,可以支撑80个左右并发用户。阿腾云以Web网站应用为例,如果视频图片媒体文件存储到对象存储OSS上,网站接入CDN,还可以支持…...

Anthropic官宣Claude3:建立大模型 推理、数学、编码和视觉等方面 新基准
文章目录 1. product2. Main2.1 核心能力2.2 打榜表现 3. My thoughtsReference Claude 3 在推理、数学、编码、多语言理解和视觉方面,全面超越GPT-4在内的所有大模型,重新树立大模型基准。 1. product https://claude.ai/ 国内暂不能使用,…...
STM32 TIM编码器接口
单片机学习! 目录 文章目录 前言 一、编码器接口简介 1.1 编码器接口作用 1.2 编码器接口工作流程 1.3 编码器接口资源分布 1.4 编码器接口输入引脚 二、正交编码器 2.1 正交编码器功能 2.2 引脚作用 2.3 如何测量方向 2.4 正交信号优势 2.5 执行逻辑 三、编码器定时…...

Jupyter Notebook的安装和使用(windows环境)
一、jupyter notebook 安装 前提条件:安装python环境 安装python环境步骤: 1.下载官方python解释器 2.安装python 3.命令行窗口敲击命令pip install jupyter 4.安装jupyter之后,直接启动命令jupyter notebook,在默认浏览器中打开jupyte…...
Platformview在iOS与Android上的实现方式对比
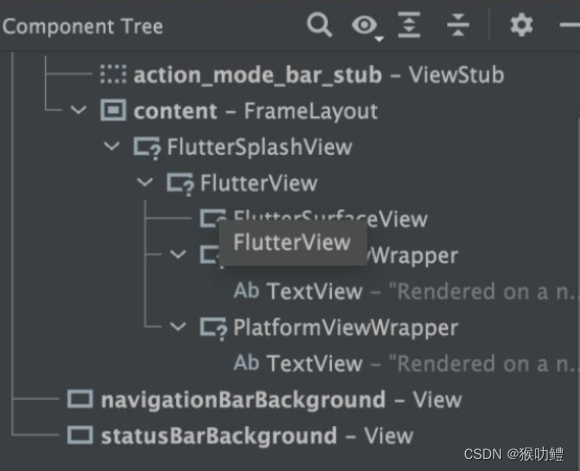
Android中早期版本Platformview的实现基于Virtual Display。VirtualDisplay方案的原理是,先将Native View绘制到虚显,然后Flutter通过从虚显输出中获取纹理并将其与自己内部的widget树进行合成,最后作为Flutter在 Android 上更大的纹理输出的…...
使用lnmp环境部署laravel框架需要注意的点
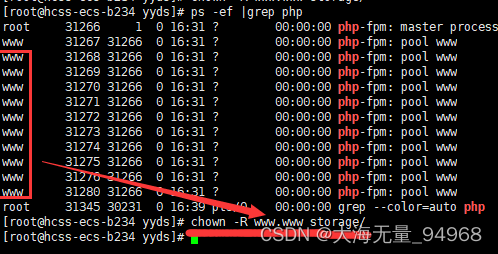
1,上传项目文件后,需要chmod -R 777 storage授予文件权限,不然会报错file_put_contents(/): failed to open stream: Permission denied。 如果后面还是报错没有权限的话,就执行ps -ef |grep php查询php运行用户。然后执行chown …...

AI-RAN联盟在MWC24上正式启动
AI-RAN联盟在MWC24上正式启动。它的logo是这个样的: 2月26日,AI-RAN联盟(AI-RAN Alliance)在2024年世界移动通信大会(MWC 2024)上成立。创始成员包括亚马逊云科技、Arm、DeepSig、爱立信、微软、诺基亚、美…...

Reactor详解
目录 1、快速上手 介绍 2、响应式编程 2.1. 阻塞是对资源的浪费 2.2. 异步可以解决问题吗? 2.3.1. 可编排性与可读性 2.3.2. 就像装配流水线 2.3.3. 操作符(Operators) 2.3.4. subscribe() 之前什么都不会发生 2.3.5. 背压 2.3.6. …...

实践航拍小目标检测,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建无人机航拍场景下的小目标检测识别分析系统
关于无人机相关的场景在我们之前的博文也有一些比较早期的实践,感兴趣的话可以自行移步阅读即可: 《deepLabV3Plus实现无人机航拍目标分割识别系统》 《基于目标检测的无人机航拍场景下小目标检测实践》 《助力环保河道水质监测,基于yolov…...

分布式数据库中全局自增序列的实现
自增序列广泛使用于数据库的开发和设计中,用于生产唯一主键、日志流水号等唯一ID的场景。传统数据库中使用Sequence和自增列的方式实现自增序列的功能,在分布式数据库中兼容Oracle和MySQL等传统数据库语法,也是基于Sequence和自增列的方式实现…...
【论文阅读】TensoRF: Tensorial Radiance Fields 张量辐射场
发表于ECCV2022. 论文地址:https://arxiv.org/abs/2203.09517 源码地址:https://github.com/apchenstu/TensoRF 项目地址:https://apchenstu.github.io/TensoRF/ 摘要 本文提出了TensoRF,一种建模和重建辐射场的新方法。不同于Ne…...

深入了解 Android 中的 FrameLayout 布局
FrameLayout 是 Android 中常用的布局之一,它允许子视图堆叠在一起,可以在不同位置放置子视图。在这篇博客中,我们将详细介绍 FrameLayout 的属性及其作用。 <FrameLayout xmlns:android"http://schemas.android.com/apk/res/androi…...
高级大数据技术 实验一 scala编程
高级大数据技术 实验一 scala编程 写的不是很好,大家多见谅! 1. 计算水仙花数 实验目标; (1) 掌握scala的数组,列表,映射的定义与使用 (2) 掌握scala的基本编程 实验说明 …...

使用Fabric创建的canvas画布背景图片,自适应画布宽高
之前的文章写过vue2使用fabric实现简单画图demo,完成批阅功能;但是功能不完善,对于很大的图片就只能显示一部分出来,不符合我们的需求。这就需要改进,对我们设置的背景图进行自适应。 有问题的canvas画布背景 修改后的…...
枚举与尺取法(蓝桥杯 c++ 模板 题目 代码 注解)
目录 组合型枚举(排列组合模板()): 排列型枚举(全排列)模板: 题目一(公平抽签 排列组合): 编辑 代码: 题目二(座次问题 全排…...

架桥记:耐达讯自动化CC-Link IE转EtherCAT的工业协议融合实战
在工业自动化行业中,生产线的智能化升级常面临一个核心难题:如何让基于不同通信协议的设备“读懂”彼此,协同工作?特别是当代表日系高速网络技术的CC-Link IE,遇上盛行于欧系设备的实时以太网EtherCAT时,协…...

假期出行指南——住酒店如何避开“系统卡顿”与“隐私漏洞”?
清明假期将至,无论是回家扫墓还是踏春出游,酒店入住体验直接决定了假期的幸福感。然而,不少旅客却在酒店客房里遇到了“糟心事”:电视系统卡顿像幻灯片、想投屏却连不上。作为专业的酒店IPTV数字电视系统厂家,辉视深知…...
进行无人机三维路径规划的详细项目实例(含模型描述及部分示例代码) 专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持)
项目介绍 MATLAB实现基于豹群算法(LVO)进行无人机三维路径规划的详细项目实例(含模型描述及部分示例代码) 专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持
MATLAB实现基于豹群算法(LVO)进行无人机三维路径规划的详细项目实例 更多详细内容可直接联系博主本人 或者访问对应标题的完整博客或者文档下载页面(含完整的程序,GUI设计和代码详解) 无人机(UAV&#…...

HsMod:55+创新功能重新定义炉石传说体验
HsMod:55创新功能重新定义炉石传说体验 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod 🌟 项目核心价值概述 HsMod作为基于BepInEx框架的炉石传说模改插件…...

C语言完美演绎6-21
/* 范例:6-21 */#include<stdio.h> #include<conio.h>int main(){int n;printf("这是nn乘法表,请输入一值>");scanf("%d",&n);int i1;for(;i<n;) /* i从1到n次循环*/{int j1;for(;j<n;) /…...

多平台直链获取:突破网盘下载限制的开源解决方案
多平台直链获取:突破网盘下载限制的开源解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 …...

WEEX 宣布赞助职业赛车手 Carl Moon,开启 2026 赛季全球品牌合作
近日,WEEX 宣布正式与职业赛车手兼内容创作者 Carl Moon 达成合作,成为其 2026 赛季年度品牌赞助商。此次合作将覆盖包括 Ferrari Challenge 与 GT World Challenge Europe 在内的多个欧洲顶级赛事,预计贯穿 3 月至 11 月赛季周期,…...

数据仓库实战:查询优化器工作原理深度解析 + 性能提升实战指南
数据仓库实战:查询优化器工作原理深度解析 性能提升实战指南摘要一、基础认知:数据仓库查询优化器是什么?1.1 核心定义1.2 数仓优化器与数据库优化器的区别1.3 优化器核心目标二、工作流程:查询优化器完整执行链路(带…...

应收账款管理:从“被动应对”到“主动管理”的思维转变
“应收账款管理真的太难了!”这是许多企业管理者的心声。中小型企业尤其容易陷入资金回笼慢、坏账风险高的困境,甚至因此影响现金流健康,拖累企业发展。传统管理模式中,信息孤岛、流程繁琐和决策滞后等问题屡见不鲜,让…...

人形机器人手指关节选材:铝合金 vs PEEK,谁才是轻量化的终极方案?
在人形机器人研发中,末端执行器(手部)的性能直接决定了机器人的交互上限。而在手指关节这种“空间极度受限、重量极度敏感、运动频率极高”的部位,选铝合金还是 PEEK(聚醚醚酮),本质上是在“结构…...