【pytorch】使用mixup技术扩充数据集进行训练
目录
- 1.mixup技术简介
- 2.pytorch实现代码,以图片分类为例
1.mixup技术简介

mixup是一种数据增强技术,它可以通过将多组不同数据集的样本进行线性组合,生成新的样本,从而扩充数据集。mixup的核心原理是将两个不同的图片按照一定的比例进行线性组合,生成新的样本,新样本的标签也是进行线性组合得到。比如,对于两个样本x1和x2,它们的标签分别为y1和y2,那么mixup生成的新样本x’和标签y’如下:
x’ = λx1 + (1-λ)x2
y’ = λy1 + (1-λ)y2
其中,λ为0到1之间的一个随机数,它表示x1和x2在新样本中的权重。
本文中,使用mixup扩充数据集后的损失函数,为:
loss = λ * criterion(outputs, targets_a) + (1 - λ) * criterion(outputs, targets_b)
即由两张图片融合后新图片的损失为,分别计算原先两图片与各自标签的损失值之和。
mixup也可以增加数据集的多样性,从而降低模型的方差,提高模型的鲁棒性。
总之,mixup是一种非常实用的数据增强技术,它可以用于各种机器学习任务中,可以有效地防止过拟合,并且可以提高模型的泛化能力。在实际应用中,mixup可以帮助我们更好地利用有限的数据集,并且提高模型的性能。
2.pytorch实现代码,以图片分类为例
import matplotlib.pyplot as plt
import torchvision
import torch
import torch.nn as nn
import torchvision.models as models
import torchvision.transforms as transforms
import numpy as np
import torch.nn.functional as F
from PIL import Image
import os
import cv2
# 加载resnet18模型
resnet18 = models.resnet18(pretrained=False)# 获取resnet18最后一层输出,输出为512维,最后一层本来是用作 分类的,原始网络分为1000类
# 用 softmax函数或者 fully connected 函数,但是用 nn.identtiy() 函数把最后一层替换掉,相当于得到分类之前的特征!
#Identity模块,它将输入直接传递给输出,而不会对输入进行任何变换。
resnet18.fc = nn.Identity()
# 构建新的网络,将resnet18的输出作为输入
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.resnet18 = resnet18self.fc1 = nn.Linear(512, 256)self.fc2 = nn.Linear(256, 64)self.fc3 = nn.Linear(64, 10)self.fc4 = nn.Linear(10, 2)self.softmax = nn.Softmax(dim=1)def forward(self, x):x = self.resnet18(x)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = F.relu(self.fc3(x))x = F.relu(self.fc4(x))x = self.softmax(x)x=x.view(-1,2)return x
#使用mixup时的数据集融合器,输入数据集的输入(一批图片),以及对应标签,返回线性相加后的图片
def mixup_data(x, y, alpha=1.0):#随机生成一个 beta 分布的参数 lam,用于生成随机的线性组合,以实现 mixup 数据扩充。lam = np.random.beta(alpha, alpha)#生成一个随机的序列,用于将输入数据进行 shuffle。batch_size = x.size()[0]index = torch.randperm(batch_size)#得到混合后的新图片mixed_x = lam * x + (1 - lam) * x[index, :]#得到混图对应的两类标签y_a, y_b = y, y[index]return mixed_x, y_a, y_b, lam# 实例化网络
net = Net()
# 将模型放入GPU
net = net.cuda()# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器,添加l2正则化
optimizer = torch.optim.Adam(net.parameters(), lr=0.0005,weight_decay=0)# 加载数据集
# 创建一个transform对象
def rgb2bgr(image):image = np.array(image)[:, :, ::-1]image=Image.fromarray(np.uint8(image))return imagetransform = transforms.Compose([transforms.ColorJitter(brightness=1, contrast=1, saturation=1, hue=0.5),# rgb转bgrtorchvision.transforms.Lambda(rgb2bgr),torchvision.transforms.Resize(112),# 入的图片为PIL image 或者 numpy.nadrry格式的图片,其shape为(HxWxC)数值范围在[0,255],转换之后shape为(CxHxw),数值范围在[0,1]transforms.ToTensor(),# 进行归一化和标准化,Imagenet数据集的均值和方差为:mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225),# 因为这是在百万张图像上计算而得的,所以我们通常见到在训练过程中使用它们做标准化。transforms.Normalize(mean=[0.406, 0.456, 0.485], std=[0.225, 0.224, 0.229]),# #这行代码表示使用transforms.RandomErasing函数,以概率p=1,在图像上随机选择一个尺寸为scale=(0.02, 0.33),长宽比为ratio=(1, 1)的区域,# #进行随机像素值的遮盖,只能对tensor操作:transforms.RandomErasing(p=0.1, scale=(0.02, 0.2), ratio=(1, 1), value='random')
])train_dataset = torchvision.datasets.ImageFolder(r'D:\eyeDataSet\train', transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=128, shuffle=True)
test_dataset = torchvision.datasets.ImageFolder(r'D:\eyeDataSet\test', transform=transform)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=128, shuffle=True)## 绘制训练及测试集迭代曲线
# 记录训练集准确率
train_acc = []
# 记录测试集准确率
test_acc = []
for epoch in range(50):running_loss = 0.0#[(0, data1), (1, data2), (2, data3), ...]for i, data in enumerate(train_loader, 0):# 获取输入inputs, labels = datainputs, labels = inputs.cuda(), labels.cuda()# mixup扩充数据集inputs, targets_a, targets_b, lam = mixup_data(inputs, labels, alpha=1.0)# 梯度清零optimizer.zero_grad()# forward + backwardoutputs = net(inputs)#这里对应调整了使用mixup后的数据集的lossloss = lam * criterion(outputs, targets_a) + (1 - lam) * criterion(outputs, targets_b)loss.backward()# 更新参数optimizer.step()# 打印log信息# loss 是一个scalar,需要使用loss.item()来获取数值,不能使用loss[0]running_loss += loss.item()if i % 10 == 9: # 每200个batch打印一下训练状态print('[%d, %5d] loss: %.3f' \% (epoch+1, i+1, running_loss / 2000))running_loss = 0.0# 在每次训练完成后,使用测试集进行测试correct = 0total = 0with torch.no_grad():for i2,data2 in enumerate(test_loader):#控制测试集的数量if i2>5:breakimages, labels = data2images, labels = images.cuda(), labels.cuda()outputs = net(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()test_acc.append(100 * correct / total)print('Accuracy of the network on the test images: %.3f,now max acc is %.3f' % (100 * correct / total,max(test_acc)))# 保存测试集上准确率最高的模型if 100 * correct / total == max(test_acc):if not os.path.exists(r'./result'):os.makedirs(r'./result')if max(test_acc)>93:savename="./result/bestmodel"+"%.3f"%max(test_acc)+".pth"torch.save(net.state_dict(), savename)print("最大准确度:",max(test_acc))
相关文章:
【pytorch】使用mixup技术扩充数据集进行训练
目录1.mixup技术简介2.pytorch实现代码,以图片分类为例1.mixup技术简介 mixup是一种数据增强技术,它可以通过将多组不同数据集的样本进行线性组合,生成新的样本,从而扩充数据集。mixup的核心原理是将两个不同的图片按照一定的比例…...

面向对象设计模式:创建型模式之单例模式
1. 单例模式,Singleton Pattern 1.1 Definition 定义 单例模式是确保类有且仅有一个实例的创建型模式,其提供了获取类唯一实例(全局指针)的方法。 单例模式类提供了一种访问其唯一的对象的方式,可以直接访问…...
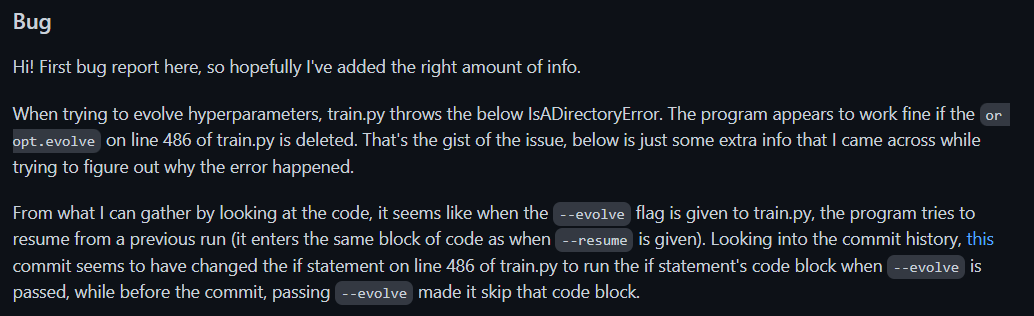
IsADirectoryError: [Errno 21] Is a directory: ‘.‘
项目场景: 基于YOLOv5的室内场景识别 工具:colab 问题描述 Traceback (most recent call last): File “train.py”, line 630, in main(opt) File “train.py”, line 494, in main d torch.load(last, map_location‘cpu’)[‘opt’] File “/usr/…...

判断三角面片与空间中球体是否相交
文章目录一、问题描述二、解题思路 在做项目时遇到了一个数学问题,即,如何判断给定一个三角面片与空间中某个球体有相交部分?这个问题看似简单,实际处理起来需要一些方法和手段。一、问题描述 已知空间中球体的球心位置center&a…...

继承下的缺省参数值和访问说明符
前言 本文将介绍 C 继承体系下,函数缺省参数的绑定和函数访问说明符的绑定。这些奇怪的问题实际上不应在我们的代码中出现,但它们能帮助我们理解 C 的动态绑定和静态绑定,也能帮助我们更好的通过面试。 缺省参数值 先来看一段代码…...
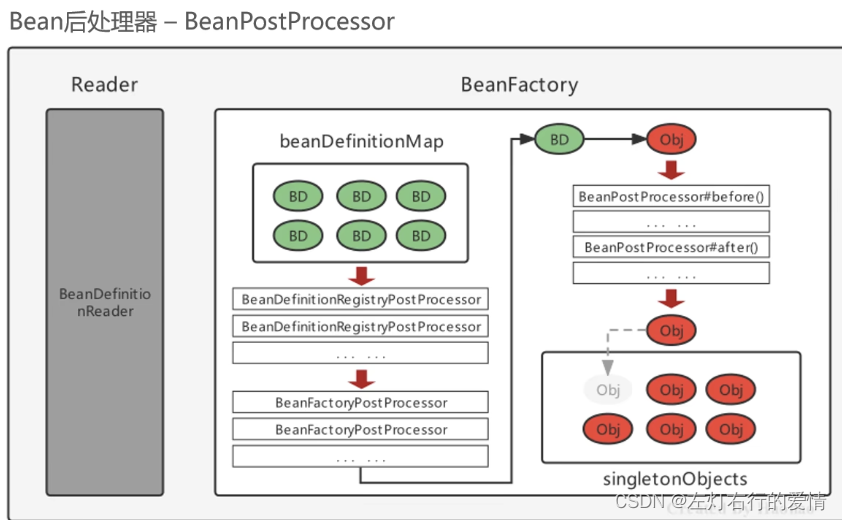
Spring核心模块—— BeanFactoryPostProcessorBeanPostProcessor(后处理器)
后置处理器前言Spring的后处理器BeanFactoryPostProcessor(工厂后处理器)执行节点作用基本信息经典场景子接口——BeanDefinitiRegistryPostProcessor基本介绍用途具体原理例子——注册BeanDefinition使用Spring的BeanFactoryPostProcessor扩展点完成自定…...
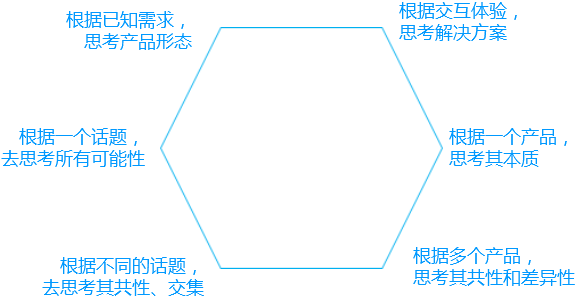
产品新人如何培养产品思维?
什么是产品思维?其实很难定义,不同人有不同的定义。有的人定义为以用户为中心打磨一个完美体验的产品;有的定义为从需求调研到需求上线各个步骤需要思考的点,等等。本文想讨论的产品思维是:怎么去发现问题,…...

「兔了个兔」CSS如此之美,看我如何实现可爱兔兔LOADING页面(万字详解附源码)
💂作者简介: THUNDER王,一名热爱财税和SAP ABAP编程以及热爱分享的博主。目前于江西师范大学会计学专业大二本科在读,同时任汉硕云(广东)科技有限公司ABAP开发顾问。在学习工作中,我通常使用偏后…...
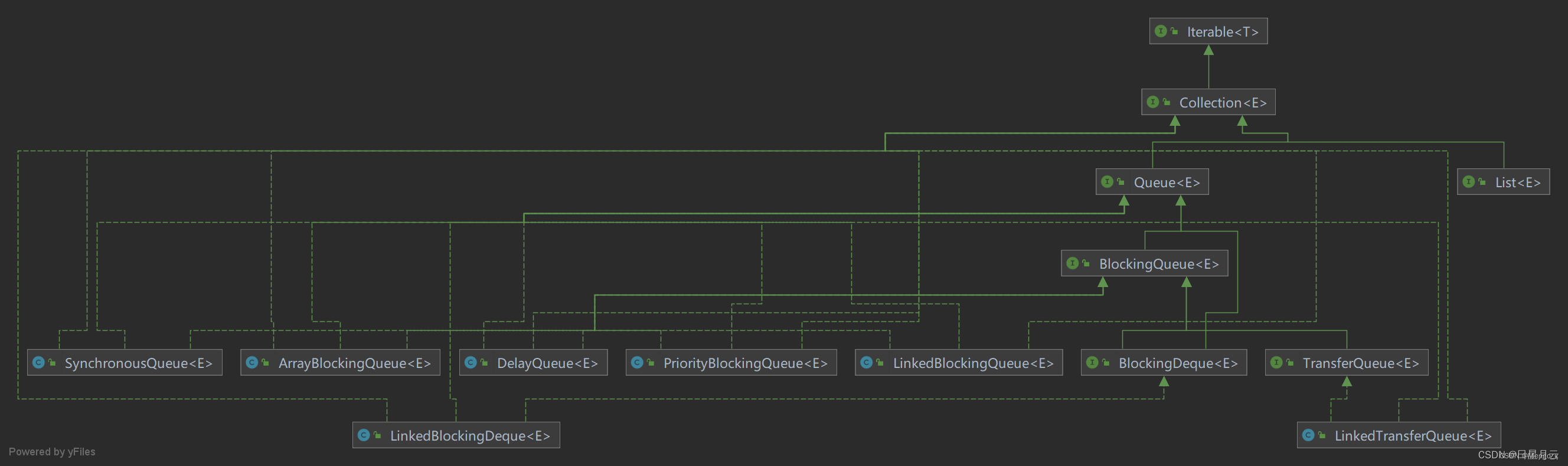
【Java】阻塞队列 BlcokingQueue 原理、与等待唤醒机制condition/await/singal的关系、多线程安全总结
在实习过程中使用阻塞队列对while sleep 轮询机制进行了改造,提升了发送接收的效率,这里做一点点总结。 自从Java 1.5之后,在java.util.concurrent包下提供了若干个阻塞队列,BlcokingQueue继承了Queue接口,是线程安全…...

【水下图像增强】Enhancing Underwater Imagery using Generative Adversarial Networks
原始题目Enhancing Underwater Imagery using Generative Adversarial Networks中文名称使用 GAN 增强水下图像发表时间2018年1月11日平台ICRA 2018来源University of Minnesota, Minneapolis MN文章链接https://arxiv.org/abs/1801.04011开源代码官方:https://gith…...

Maven专题总结—详细版
第一章 为什么使用Maven 获取jar包 使用Maven之前,自行在网络中下载jar包,效率较低。如【谷歌、百度、CSDN…】使用Maven之后,统一在一个地址下载资源jar包【阿里云镜像服务器等…】 添加jar包 使用Maven之前,将jar复制到项目工程…...
)
华为OD机试真题Java实现【字符串加密】真题+解题思路+代码(20222023)
字符串加密 题目 给你一串未加密的字符串str, 通过对字符串的每一个字母进行改变来实现加密, 加密方式是在每一个字母str[i]偏移特定数组元素a[i]的量, 数组a前三位已经赋值:a[0]=1,a[1]=2,a[2]=4。 当i>=3时,数组元素a[i]=a[i-1]+a[i-2]+a[i-3], 例如:原文 abcde …...

「Python 基础」函数与高阶函数
文章目录1. 函数调用函数定义函数函数的参数递归函数2. 高阶函数map/reducefiltersorted3. 函数式编程返回函数匿名函数装饰器偏函数1. 函数 函数是一种重复代码的抽象方式,Python 内建支持的一种封装; 调用函数 调用一个函数,需要知道函数…...

DIV内容滚动,文字符滚动标签marquee兼容稳定不卡
marquee(文字滚动)标签 marquee简介 <marquee>标签,是成对出现的标签,首标签<marquee>和尾标签</marquee>之间的内容就是滚动内容。 <marquee>标签的属性主要有behavior、bgcolor、direction、width、height、hspace、vspace、loop、scrollamount、scr…...
SpringBoot_第五章(Web和原理分析)
目录 1:静态资源 1.1:静态资源访问 1.2:静态资源源码解析-到WebMvcAutoConfiguration 2:Rest请求绑定(设置put和delete) 2.1:代码实例 2.2:源码分析到-WebMvcAutoConfiguratio…...

4-2 Linux进程和内存概念
文章目录前言进程状态进程优先级内存模型进程内存关系前言 进程是一个其中运行着一个或多个线程的地址空间和这些线程所需要的系统资源。一般来说,Linux系统会在进程之间共享程序代码和系统函数库,所以在任何时刻内存中都只有代码的一份拷贝。 进程状态…...

【微信小程序】计算器案例
🏆今日学习目标:第二十一期——计算器案例 ✨个人主页:颜颜yan_的个人主页 ⏰预计时间:30分钟 🎉专栏系列:我的第一个微信小程序 计算器前言实现效果实现步骤wxmlwxssjs数字按钮事件处理函数计算按钮处理事…...
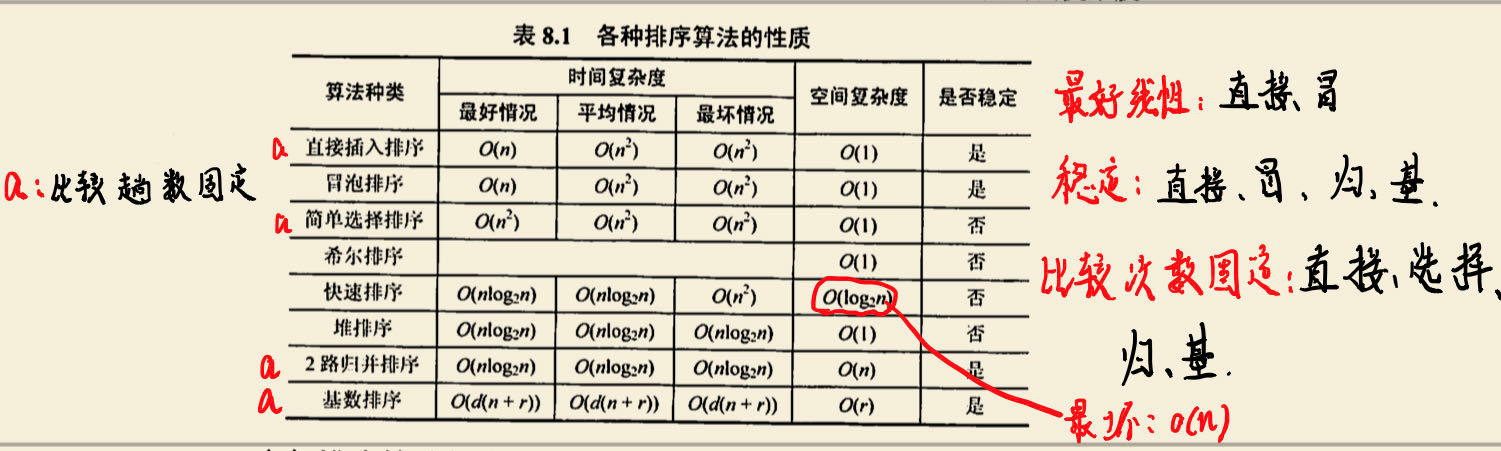
408 计算机基础复试笔记 —— 更新中
计算机组成原理 计算机系统概述 问题一、冯诺依曼机基本思想 存储程序:程序和数据都存储在同一个内存中,计算机可以根据指令集执行存储在内存中的程序。这使得程序具有高度灵活性和可重用性。指令流水线:将指令分成若干阶段,每…...
)
找出最大数-课后程序(Python程序开发案例教程-黑马程序员编著-第二章-课后作业)
实例6:找出最大数 “脑力大乱斗”休闲益智游戏的关卡中,有一个题目是找出最大数。本实例要求编写程序,实现从输入的任意三个数中找出最大数的功能。 实例分析 对于3个数比较大小,我们可以首先先对两个数的大小进行比较ÿ…...
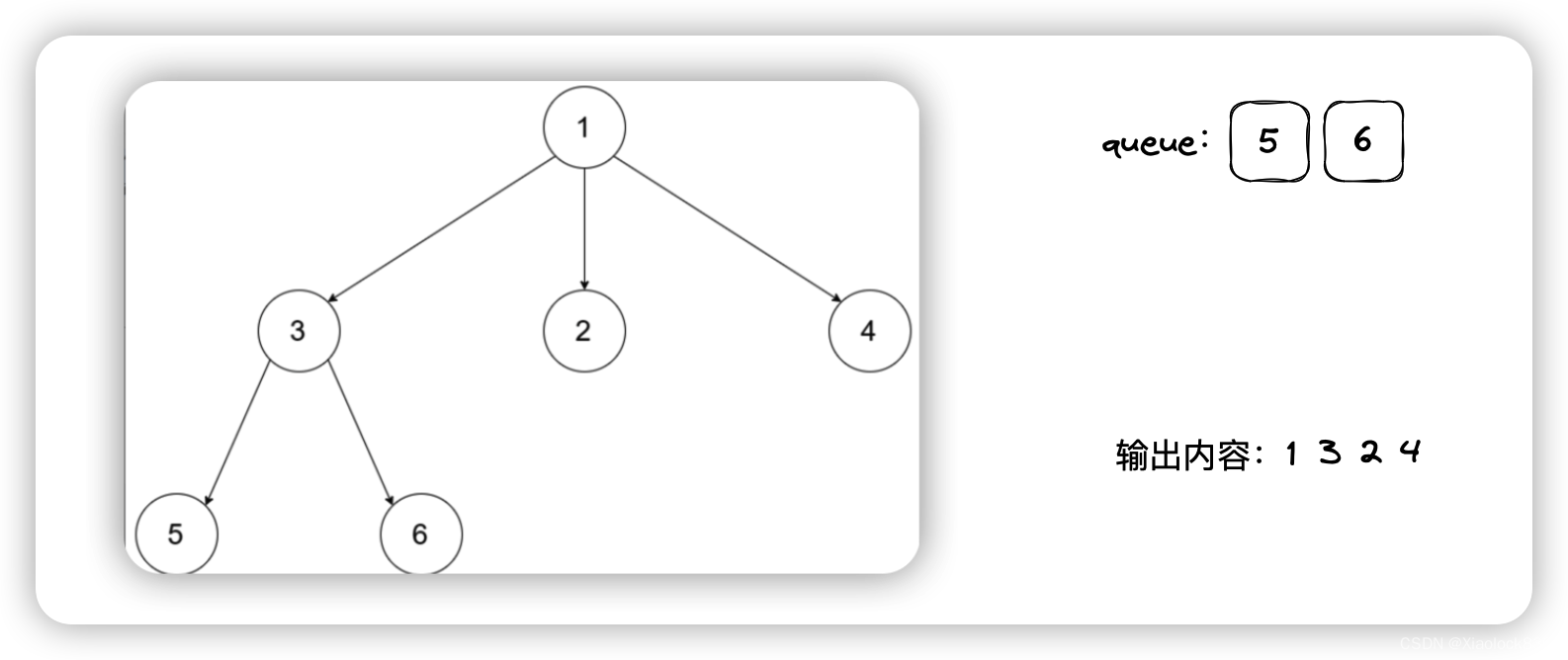
Java——N叉树的层序遍历
题目链接 leetcode在线oj题——N叉树的层序遍历 题目描述 给定一个 N 叉树,返回其节点值的层序遍历。(即从左到右,逐层遍历)。 树的序列化输入是用层序遍历,每组子节点都由 null 值分隔(参见示例&…...
)
用Python和OpenCV手把手教你搞定自动驾驶图像坐标系转换(附NuScenes数据集实战代码)
用Python和OpenCV手把手教你搞定自动驾驶图像坐标系转换(附NuScenes数据集实战代码) 自动驾驶技术的核心在于让车辆"看懂"周围环境,而坐标系转换正是连接物理世界与数字世界的桥梁。想象一下,当一辆自动驾驶汽车行驶在…...

Netgear路由器终极救援指南:如何用免费开源工具nmrpflash快速修复“变砖“设备
Netgear路由器终极救援指南:如何用免费开源工具nmrpflash快速修复"变砖"设备 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你的Netgear路由器因固件升级失败、意外断电或系统崩…...

Go语言开源漏洞扫描器Abyss-Scanner:架构解析与CI/CD集成实践
1. 项目概述:一个为安全而生的开源漏洞扫描器最近在整理自己的开源项目工具箱,发现一个挺有意思的工具,叫 Abyss-Scanner。这名字起得挺有深意,“深渊扫描器”,听起来就有点探索未知、发现潜在风险的味道。简单来说&am…...

Zotero插件市场:三步快速上手的插件管理神器
Zotero插件市场:三步快速上手的插件管理神器 【免费下载链接】zotero-addons Zotero Add-on Market | Zotero插件市场 | Browsing, installing, and reviewing plugins within Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-addons 想象一下&a…...

如何快速免费管理游戏DLSS版本?DLSS Swapper终极指南
如何快速免费管理游戏DLSS版本?DLSS Swapper终极指南 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款革命性的开源工具,专为PC游戏玩家设计,能够智能管理、下载和…...

Claude API企业准入最后窗口期:2024Q3起强制启用OAuth 2.1+硬件级密钥绑定,现在不升级将无法续签
更多请点击: https://intelliparadigm.com 第一章:Claude API企业准入政策的演进与合规紧迫性 随着Anthropic对Claude模型商用边界的持续收束,企业级API接入正从“技术可用性”转向“治理可验证性”。2024年Q2起,所有新注册企业账…...

开源办公套件自动化部署与集成实战:基于OpenOffice的服务化解决方案
1. 项目概述:为什么我们需要一个“开源”的办公套件?如果你在GitHub上搜索过办公软件相关的仓库,大概率会看到过longyangxi/OpenOffice这个项目。乍一看,你可能会以为这是一个Apache OpenOffice的镜像或者某个分支。但点进去仔细研…...

Path of Building:3个步骤从Build小白到规划大师的完整指南
Path of Building:3个步骤从Build小白到规划大师的完整指南 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding Path of Building作为流放之路玩家最信赖的Build规…...

基于GitHub Pages与Jekyll的静态博客搭建与深度定制指南
1. 项目概述:一个静态博客的诞生与演进如果你对搭建个人博客感兴趣,或者正在寻找一个轻量、高效、完全可控的线上空间,那么“RyansGhost/RyansGhost.github.io”这个项目仓库,很可能就是你一直在寻找的答案。这不仅仅是一个托管在…...

OpenAgentsControl:构建多智能体协同系统的开源框架解析
1. 项目概述:一个面向智能体控制的开放框架最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的开源仓库:darrenhinde/OpenAgentsControl。这个项目名字直译过来就是“开放智能体控制”,听起来就很有搞…...