【水下图像增强】Enhancing Underwater Imagery using Generative Adversarial Networks
| 原始题目 | Enhancing Underwater Imagery using Generative Adversarial Networks |
|---|---|
| 中文名称 | 使用 GAN 增强水下图像 |
| 发表时间 | 2018年1月11日 |
| 平台 | ICRA 2018 |
| 来源 | University of Minnesota, Minneapolis MN |
| 文章链接 | https://arxiv.org/abs/1801.04011 |
| 开源代码 | 官方:https://github.com/IRVLab/UGAN (tensorflow ) |
摘要
自动水下航行器(Autonomous underwater vehicles (AUVs))依靠各种传感器——声学、惯性和视觉(acoustic, inertial and visual)——进行智能决策。由于其 非侵入性、被动性和高信息量,视觉(non-intrusive, passive nature, and high information content) 是一种有吸引力的传感方式,特别是在较浅的深度。然而,光的 折射和吸收( refraction and absorption)、水中悬浮粒子(suspended particles)、颜色失真(color distortion)等因素会影响视觉数据的质量,导致图像噪声和失真。因此,依赖视觉感知的 AUVs 面临着困难的挑战,因此在视觉驱动的任务中表现不佳。
本文提出了一种使用 GANs 来提高水下视觉场景质量的方法,其目标是 在 自主流程(autonomy pipeline) 中进一步改善视觉驱动行为的输入。此外,我们展示了最近提出的方法如何能够生成用于这种水下图像恢复的数据集。对于任何视觉引导的水下机器人来说,这种改进可以通过强大的视觉感知来提高安全性和可靠性。为此,我们提出了定量和定性的数据,这些数据表明,通过所提出的方法 校正的图像产生了更有视觉吸引力的图像,也为 diver 跟踪算法提供了更高的精度。
5. 结论
提出了一种利用生成对抗网络增强水下彩色图像的方法。展示了使用 CycleGAN 生成配对图像数据集,为所提出的恢复模型提供 训练集。定量和定性的实验结果验证了该方法的有效性,使用 diver 跟踪算法对校正后的潜水员图像序列进行跟踪,结果表明,与未校正的图像序列相比,校正后的 diver 图像序列具有更高的准确性。
未来的工作将专注于从水下物体中创建更大、更多样化的数据集,从而使网络更具泛化性。用粒子和灯光效果等噪声来增强 CycleGAN 生成的数据,可以提高数据集的多样性。还打算研究一些不同的定量性能指标来评估我们的方法。
1. 引言
随着新型平台、传感器和推进机制的出现,水下机器人已经成为自主领域机器人的一个稳步增长的子领域。自主水下航行器通常配备有各种传感器,而视觉感知由于其非侵入、被动和节能的特性,是一个有吸引力的选择。珊瑚礁监测[28]、深海探测[32]和海底测绘[5]是 visually-guided AUVs 和 ROVs (Remotely Operated Vehicles) 广泛使用的一些任务。这些机器人的使用确保了人类不会暴露在水下探索的危险中,因为他们不再需要冒险到深度(这是过去进行此类任务的方式)。尽管水下环境具有使用视觉的优势,但水下环境对视觉感知提出了独特的挑战,因为悬浮粒子的折射、吸收和散射会极大地影响光学。例如,由于红色波长很快被水吸收,图像往往具有绿色或蓝色色调。当越深,这种效果恶化,因为越来越多的红色色调被吸收。这种失真在本质上是极其非线性的,并且受到许多因素的影响,例如光线的数量(阴天与阳光,操作深度),水中粒子的数量,一天中的时间和正在使用的相机。这可能会导致分割、跟踪或分类等任务的困难,因为它们间接或直接使用颜色。
由于颜色和光照开始随着深度的变化而变化,基于视觉的算法需要具有通用性,以便在机器人可能操作的深度范围内工作。由于获取各种水下数据以训练视觉系统的高成本和困难,以及引入的大量噪声,算法可能(并且确实)在这些不同的领域表现不佳。图1 显示了水下环境中可能出现的视觉场景的高变化性。解决这个问题的一个步骤是能够恢复图像,使它们看起来像是在水面上,即 校正颜色并从场景中去除悬浮颗粒。通过进行 多对一(非水下的) 映射 ,即从 水下领域 到 非水下领域(图像在水面上的样子),难以跨多种形式噪声执行的算法 可能只能聚焦一个干净的领域。

深度神经网络已经被证明是强大的非线性函数逼近器,特别是在视觉[17]领域。通常,这些网络需要大量的数据,要么标记为 ground truth.,要么与 ground truth. 配对。对于灰度图像[33]的自动着色问题,由于任何彩色图像都可以转换为黑白图像,因此现成的训练数据是成对的。然而,水下图像受到颜色或其他现象的扭曲,缺乏 ground truth,这是采用类似方法进行校正的主要障碍。本文提出一种基于 Generative Adversarial Networks, GANs 的水下视觉场景质量提升技术,旨在提升自主水下机器人视觉驱动行为的性能。
我们使用最近提出的 CycleGAN[35] 方法,该方法学习在没有图像对的情况下将图像从任意域 X 转换到另一个任意域 Y,作为生成配对数据集的一种方法。 通过让 X 是一组 未失真的(undistorted) 水下图像,Y 是一组 失真的(distorted) 水下图像,我们可以生成一个看起来在水下的图像,同时保留 ground truth 。
2. 相关工作
虽然最近已经有许多成功的自动着色方法[33,11],但大多数都 专注于将灰度图像转换为彩色的任务。
相当多的方法使用基于物理的技术直接模拟光的折射[15]。
针对水下图像的颜色恢复,[29]的工作采用 马尔可夫随机场的能量最小化公式。
与本文提出的工作最相似的是最近提出的 WaterGAN[20],它使用对抗性方法来生成逼真的水下图像。他们的生成器模型可以分为三个阶段:
- 1)衰减,这说明了光的范围相关衰减。
- 2)散射,模拟由光子向图像传感器散射引起的雾霾效果;
- 3)渐晕,在图像角点上产生阴影效果,这种效果可以由特定的相机镜头引起。
与我们的工作不同的是,他们使用 GAN 来生成水下图像,并严格使用 Euclidean loss 来进行颜色校正,
而我们两者都使用 GAN。此外,它们在 WaterGAN 训练期间需要深度信息,这通常很难获得,特别是在水下自主机器人应用中。本文工作在整个过程中只需要两个独立域(例如 水下 和 陆地 )中的物体的图像。
最近在生成模型,特别是 GANs 方面的工作,在 修复[24]、风格迁移[8]和图像到图像转换 等领域显示了巨大的成功[14,35]。这主要是因为它们能够提供比 欧氏距离 更有意义的损失,而 欧氏距离 已被证明会产生模糊的结果。本文将 估计水下图像真实外观的问题 构建 为 成对图像到图像的转换问题,使用生成对抗网络(GANs)作为生成模型(详细信息请参见第 3.2节)。与[14]的工作非常类似,我们使用来自 两个域的图像对 作为输入和 ground
truth。
3. 方法
受颜色或其他环境影响而失真的水下图像缺乏 ground truth,这是以往彩色化方法所必需的。此外,水下图像中的失真是高度非线性的; 简单的方法,如向图像添加色调,不能捕获所有的依赖关系。本文提出使用 CycleGAN 作为失真模型,以生成用于训练的成对图像。给定一个 无失真的水下图像域 和一个 有失真的水下图像域,CycleGAN 能够进行风格迁移。给定一个 未失真的图像,CycleGAN 将其失真,使其看起来像是来自 失真图像的域。然后 在我们的算法中使用这些对进行图像重建。
无失真的水下图像域: 没有水下那种颜色的图像
失真的水下图像域: CycleGAN 生成的图像
3.1 数据生成
深度、光照条件、相机模型和水下环境中的物理位置都是影响 图像失真量 的因素。在某些条件下,水下图像可能有很小的失真,或者完全没有失真。 设 ICI^CIC 为无失真的水下图像,IDI^DID 为 有失真的水下图像。我们的目标是学习函数 f:ID→ICf: I^{D} \rightarrow I^{C}f:ID→IC。 由于收集水下数据的困难,往往不仅 IDI^DID 或 ICI^CIC 不存在,而且 二者都不存在。
为了避免图像对不足的问题,我们使用 CycleGAN 从 ICI^{C}IC 生成 IDI^{D}ID,它给我们一个 成对的图像数据集。给定两个数据集 X 和 Y,其中 $I^C∈X $和 ID∈YI^D∈YID∈Y, CycleGAN 学习一个映射 F:X→YF: X→YF:X→Y。图2 显示了从CycleGAN 生成的配对样本。从这个配对的数据集中,我们训练一个生成器 G 来学习函数 f:ID→ICf: I^D→I^Cf:ID→IC。应该注意的是,在 CycleGAN 的训练过程中,它同时学习映射 G:Y→XG: Y→XG:Y→X,这与 fff 类似。在第 4 节中,我们将 CycleGAN 生成的图像与通过我们的方法生成的图像进行比较。

3.2 对抗网络
在机器学习文献中,生成式对抗网络(GANs)[9] 代表了一类基于博弈论的生成模型,其中 生成器网络与对手竞争。从分类的角度来看,生成器网络 G 产生的实例会主动试图 “欺骗” 鉴别器网络 d。目标是让鉴别器网络能够区分来自 数据集的“真”实例 和生成器网络产生的 “假”实例。在我们的例子中,以图像 IDI^DID 为条件,生成器被训练生成一个图像来试图欺骗鉴别器,鉴别器被训练来区分 失真和非失真的水下图像。在原始 GAN 公式中,我们的目标是解决 minimax 问题:
minGmaxDEIC∼ptrain (IC)[logD(IC)]+EID∼pgen(ID)[log(1−D(G(ID)))](1)\begin{aligned} \min _{G} \max _{D} & \mathbb{E}_{I^{C} \sim p_{\text {train }}\left(I^{C}\right)}\left[\log D\left(I^{C}\right)\right]+ \\ & \mathbb{E}_{I^{D} \sim p_{g e n}\left(I^{D}\right)}\left[\log \left(1-D\left(G\left(I^{D}\right)\right)\right)\right] \end{aligned}\tag{1}GminDmaxEIC∼ptrain (IC)[logD(IC)]+EID∼pgen(ID)[log(1−D(G(ID)))](1)
注意为了表示法的简单性,我们将进一步省略(omit) IC∼Ptrain(IC)\begin{array}{l}{{I^{C}\:\sim\:{\mathcal{P}}_{t r a i n}\left(I^{C}\right)}}\end{array}IC∼Ptrain(IC) 和 ID∼Pgen(ID)I^{D}\;\sim\;\!P_{g e n}\big(I^{D}\big)ID∼Pgen(ID)。在这个公式中,discriminator 被假设为具有 sigmoid 交叉熵损失函数的分类器,这在实践中可能会导致消失梯度和模式崩溃(collapse)等问题。
如[2]所示,随着 判别器 的提升,生成器的梯度消失,使其难以或不可能进行训练。当生成器 “坍缩” 到单个点时,就会发生模式坍缩,仅用一个实例欺骗 判别器。为了说明模式崩溃的影响,假设 GAN 被用于从 MNIST[18]数据集生成数字,但它只生成了相同的数字。实际上,我们期望的结果是生成所有数字的不同集合。为此,最近有许多方法为 判别器 假设了不同的损失函数[21,3,10,34]。本文关注 Wasserstein GAN (WGAN)[3]公式,提出通过使用 Kantorovich-Rubinstein 对偶(duality)[31]构造一个值函数 来使用 Earth-Mover 或 Wasserstein-1 距离 W。在这个公式中,W 被近似给定一组 k-Lipschitz 函数 f 建模为神经网络。为了确保 f 是 k-Lipschitz,判别器 的权重被剪切到某个范围[−c, c]。不像[3]那样裁剪网络权重,本文采用带梯度惩罚的 Wasserstein GAN with gradient penalty (WGAN-GP)[10],通过对 判别器 输出相对于输入的梯度范数实施软约束来确保 Lipschitz 约束。
LWGAN(G,D)=E[D(IC)]−E[D(G(ID))]+λGPEx^∼Px^[(∣∣∇x^D(x^)∣∣2−1)2](2)\begin{aligned}\mathcal{L}_{WGAN}(G,D)=\mathbb{E}[D(I^C)]-\mathbb{E}[D(G(I^D))]+\\ \lambda_{GP}\mathbb{E}_{\hat{x}\sim\mathbb{P}_{\hat{x}}}\left[(||\nabla_{\hat{x}}D(\hat{x})||_2-1)^2\right]\end{aligned}\tag{2}LWGAN(G,D)=E[D(IC)]−E[D(G(ID))]+λGPEx^∼Px^[(∣∣∇x^D(x^)∣∣2−1)2](2)
[2] Martin Arjovsky and L´eon Bottou. Towards principled methods for training generative adversarial networks. arXiv preprint arXiv:1701.04862, 2017.
其中 Px^\mathbb{P}_{\hat{x}}Px^ 被定义为来自 真实数据分布 和 生成器分布 的 点对 之间的直线上的样本,而 λGP 是一个加权因子。为了给 G 一些 ground truth 的感觉,以及捕获图像中的 low level frequencies ,我们还考虑了 L1 损失:
LL1=E[∣∣IC−G(ID)∣∣1](3)\mathcal{L}_{L1}=\mathbb{E}[||I^C-G(I^D)||_1]\tag{3}LL1=E[∣∣IC−G(ID)∣∣1](3)
结合这些,我们得到了我们网络的最终目标函数,我们称之为 Underwater GAN (UGAN):
LUGAN∗=minGmaxDLWGAN(G,D)+λ1LL1(G)(4)\mathcal{L}_{U G A N}^{*}=\operatorname*{min}_{G}\operatorname*{max}_{D}\mathcal{L}_{W G A N}(G,D)+\lambda_{1}\mathcal{L}_{L1}(G)\tag{4}LUGAN∗=GminDmaxLWGAN(G,D)+λ1LL1(G)(4)
3.3 图像梯度差损失 Image Gradient Difference Loss
通常情况下,生成模型会产生模糊的图像。本文探索了一种策略,通过直接惩罚 生成器 中图像梯度预测的differences 来锐化这些预测,如[22]提出的。给定一个 ground truth 图像 ICI^CIC,一个预测图像 IP=G(ID)I^{P}=G(I^{D})IP=G(ID), α 是一个大于等于 1 的整数, Gradient Difference Loss (GDL) 为:
LGDL(IC,IP)=∑i,j∣∣Ii,jC−Ii−1,jC∣−∣Ii,jP−Ii−1,jP∣∣α+∣∣Ii,j−1C−Ii,jC∣−∣Ii,j−1P−Ii,jP∣∣α(5)\begin{array}{c}{\mathcal{L}_{G D L}(I^{C},I^{P})=}\\ {\sum_{i,j}||I_{i,j}^{C}-I_{i-1,j}^{C}|-|I_{i,j}^{P}-I_{i-1,j}^{P}||^{\alpha}+}\\ {||I_{i,j-1}^{C}-I_{i,j}^{C}|-|I_{i,j-1}^{P}-I_{i,j}^{P}||^{\alpha}}\\ \end{array}\tag{5}LGDL(IC,IP)=∑i,j∣∣Ii,jC−Ii−1,jC∣−∣Ii,jP−Ii−1,jP∣∣α+∣∣Ii,j−1C−Ii,jC∣−∣Ii,j−1P−Ii,jP∣∣α(5)
在我们实验中,考虑 GD L时,将网络表示为 UGAN-P,可以表示为:
LUGN-P∗=minGmaxDLWGAN(G,D)+λ1LL1(G)+λ2LGDL(6)\begin{aligned}\mathcal{L}^*_{UGN\text{-}P}=\min\limits_{G}\max\limits_{D}\mathcal{L}_{WGAN}(G,D)+\\ \lambda_{1}\mathcal{L}_{L1}(G)+\lambda_{2}\mathcal{L}_{GDL}\end{aligned}\tag{6}LUGN-P∗=GminDmaxLWGAN(G,D)+λ1LL1(G)+λ2LGDL(6)
3.4 网络架构
所提出的 生成器网络 是一个 全卷积编码器-解码器,类似于[14]的工作,由于输入和输出之间的结构相似性,它被设计为一个" U-Net "[26]。编码器-解码器网络 通过卷积对输入进行下采样(编码)到较低维度的嵌入,然后通过转置卷积对该嵌入进行上采样(解码)以重建图像。使用 “U-Net” 的优势来自于显式地保留 编码器产生的空间依赖关系,而不是依赖嵌入来包含所有信息。 这是通过添加 “skip connections” 来完成的,它将编码器中的卷积层 iii 产生的激活 concatenate 到 解码器中的 转置卷积层 n − i + 1 的输入,其中 n 是网络中的总层数。我们生成器中的每个卷积层都使用 kernel size 为4 × 4,stride 为2。网络编码器部分的卷积之后是 batch normalization[12]和斜率为 0.2 的leaky ReLU activation,而解码器中的转置卷积之后是 ReLU activation 23。解码器的最后一层除外,它使用 TanH 非线性来匹配输入分布[- 1,1]。最近的工作提出了 Instance Normalization[30],以提高 图像到图像翻译任务 的质量,但我们没有观察到额外的好处。
我们的全卷积判别器是模仿[25]的,只是没有使用 batch normalization。 这是因为 WGAN-GP 单独惩罚了每个输入的 判别器 梯度的范数,batch normalization 将会是 无效的。[10]的作者推荐 layer normalization [4],但我们没有发现显著的改进。我们的 判别器 被建模为 PatchGAN[14, 19],它在 图像 patches 的 level 上进行判别。与输出真假对应标量值的常规 判别器 不同,我们的 PatchGAN 判别器输出 32 × 32 × 1 特征矩阵,它为 high level frequencies 提供了度量标准。
4. 实验
4.1 数据集
我们使用 Imagenet[7] 的几个子集 来训练和评估我们的方法。还对从 YouTubeTM 上拍摄的水下潜水员视频进行了频率和空间域 diver tracking 算法的评估。选取 含有水下图像的 Imagenet 子集 用于CycleGAN的训练,并基于 视觉检查(就是人看吧) 手动将其分为两类。设 X 为无失真的水下图像集合,Y 为有失真的水下图像集合。X 包含 6143 张图像,Y 包含 1817 张图像。然后,我们训练 CycleGAN 来学习映射 F: X→Y,这样来自 X 的图像似乎来自 Y。最后,我们用于训练数据的 图像对 是通过用 F 失真 X 中的所有图像来生成的。图2 显示了样本训练对。在与 CycleGAN 进行比较时,使用了从 FlickrTM 获取的 56 幅图像作为测试集。
4. 评估
在 CycleGAN 生成的 图像对 上训练 UGAN 和 UGAN-P,并在来自 测试集 Y 的图像上进行评估。请注意,这些图像不包含任何 ground truth,因为它们是来自 Imagenet 的原始失真图像。用于训练和测试的图像大小为 256 × 256 × 3,归一化在[−1,1]之间。图3 显示了来自测试集的样本。值得注意的是,这些图像包含不同数量的噪声。 UGAN 和 UGAN-P 都能够恢复丢失的颜色信息,以及纠正现有的任何颜色信息。
虽然许多 失真图像 在整个图像空间中都包含 蓝色 或 绿色色调,但情况并不总是如此。在某些环境中,靠近相机的物体可能没有失真,颜色正确,而图像的背景包含失真。在这种情况下,我们希望网络只纠正图像中出现扭曲的部分。图3 中的最后一行显示了这种图像的一个示例。小丑鱼的橙色保持不变,而背景中扭曲的海葵则经过颜色校正。
对于定量评估,我们将其与 CycleGAN 进行比较,因为它在训练 G: Y→X 期间固有地学习了逆映射。我们首先使用 Canny 边缘检测器[6],因为它与真实值相比提供了颜色无关的图像评估。其次,比较局部图像块,提供图像的清晰度指标。展示了现有的水下机器人跟踪算法如何通过生成的图像提高性能。
4.3 与 CycleGAN 对比
略
4.4 Diver Tracking using Frequency Domain Detection
MDPM tracker 在生成的图像上 比 真实图像 上的性能提升。水下图像由于能见度低,往往无法捕捉到前景与背景亮度值的真实对比。生成的图像似乎在一定程度上恢复了这些受侵蚀的强度变化,使 MDPM 跟踪器的阳性检测(正确检测增加了350%)得到了很大的改善。
4.5 训练细节和推理性能
- 所有实验的超参数:λ1=100λ_1 = 100λ1=100, λGP=10λ_{GP} = 10λGP=10,batch size = 32
- 优化器和学习率:Adam, 学习率=1e−4
- 训练策略: 和 WGAN-GP 一样,对于生成器的每次更新,判别器被更新 n 次,其中 n = 5。
- UGAN-P 的超参数: λ2=1.0,α=1λ_2 = 1.0, α = 1λ2=1.0,α=1。
- 实现框架: Tensorflow
- 硬件: GTX 1080
- 训练方式: 从头训练 100 个 epoch
- 推理速度:GPU 上的推理平均耗时 0.0138s,约为每秒 72帧(FPS)。在 CPU (Intel Core i7-5930K)上,推理平均耗时 0.1244s,约为 8 FPS。
- 输入图像大小:256 ×256×3
相关文章:
【水下图像增强】Enhancing Underwater Imagery using Generative Adversarial Networks
原始题目Enhancing Underwater Imagery using Generative Adversarial Networks中文名称使用 GAN 增强水下图像发表时间2018年1月11日平台ICRA 2018来源University of Minnesota, Minneapolis MN文章链接https://arxiv.org/abs/1801.04011开源代码官方:https://gith…...

Maven专题总结—详细版
第一章 为什么使用Maven 获取jar包 使用Maven之前,自行在网络中下载jar包,效率较低。如【谷歌、百度、CSDN…】使用Maven之后,统一在一个地址下载资源jar包【阿里云镜像服务器等…】 添加jar包 使用Maven之前,将jar复制到项目工程…...
)
华为OD机试真题Java实现【字符串加密】真题+解题思路+代码(20222023)
字符串加密 题目 给你一串未加密的字符串str, 通过对字符串的每一个字母进行改变来实现加密, 加密方式是在每一个字母str[i]偏移特定数组元素a[i]的量, 数组a前三位已经赋值:a[0]=1,a[1]=2,a[2]=4。 当i>=3时,数组元素a[i]=a[i-1]+a[i-2]+a[i-3], 例如:原文 abcde …...

「Python 基础」函数与高阶函数
文章目录1. 函数调用函数定义函数函数的参数递归函数2. 高阶函数map/reducefiltersorted3. 函数式编程返回函数匿名函数装饰器偏函数1. 函数 函数是一种重复代码的抽象方式,Python 内建支持的一种封装; 调用函数 调用一个函数,需要知道函数…...

DIV内容滚动,文字符滚动标签marquee兼容稳定不卡
marquee(文字滚动)标签 marquee简介 <marquee>标签,是成对出现的标签,首标签<marquee>和尾标签</marquee>之间的内容就是滚动内容。 <marquee>标签的属性主要有behavior、bgcolor、direction、width、height、hspace、vspace、loop、scrollamount、scr…...
SpringBoot_第五章(Web和原理分析)
目录 1:静态资源 1.1:静态资源访问 1.2:静态资源源码解析-到WebMvcAutoConfiguration 2:Rest请求绑定(设置put和delete) 2.1:代码实例 2.2:源码分析到-WebMvcAutoConfiguratio…...

4-2 Linux进程和内存概念
文章目录前言进程状态进程优先级内存模型进程内存关系前言 进程是一个其中运行着一个或多个线程的地址空间和这些线程所需要的系统资源。一般来说,Linux系统会在进程之间共享程序代码和系统函数库,所以在任何时刻内存中都只有代码的一份拷贝。 进程状态…...

【微信小程序】计算器案例
🏆今日学习目标:第二十一期——计算器案例 ✨个人主页:颜颜yan_的个人主页 ⏰预计时间:30分钟 🎉专栏系列:我的第一个微信小程序 计算器前言实现效果实现步骤wxmlwxssjs数字按钮事件处理函数计算按钮处理事…...
408 计算机基础复试笔记 —— 更新中
计算机组成原理 计算机系统概述 问题一、冯诺依曼机基本思想 存储程序:程序和数据都存储在同一个内存中,计算机可以根据指令集执行存储在内存中的程序。这使得程序具有高度灵活性和可重用性。指令流水线:将指令分成若干阶段,每…...
)
找出最大数-课后程序(Python程序开发案例教程-黑马程序员编著-第二章-课后作业)
实例6:找出最大数 “脑力大乱斗”休闲益智游戏的关卡中,有一个题目是找出最大数。本实例要求编写程序,实现从输入的任意三个数中找出最大数的功能。 实例分析 对于3个数比较大小,我们可以首先先对两个数的大小进行比较ÿ…...
Java——N叉树的层序遍历
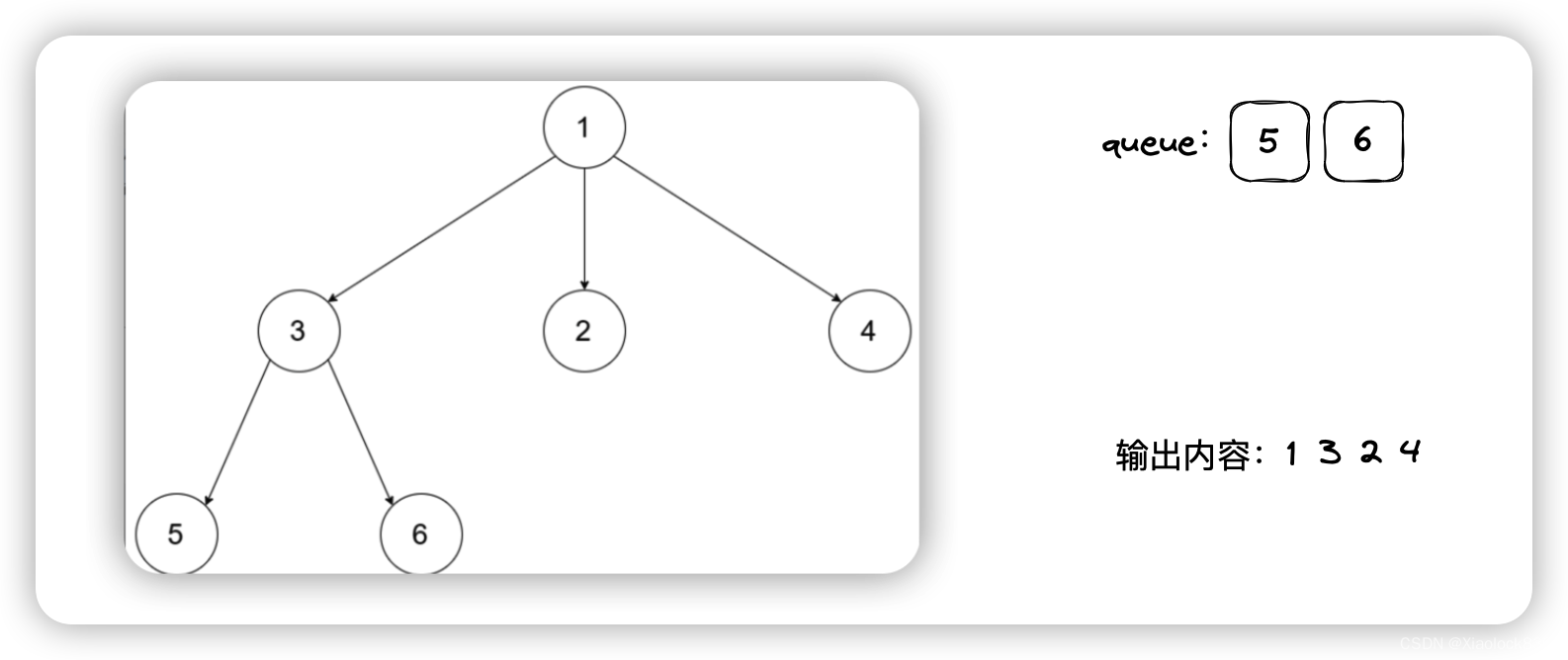
题目链接 leetcode在线oj题——N叉树的层序遍历 题目描述 给定一个 N 叉树,返回其节点值的层序遍历。(即从左到右,逐层遍历)。 树的序列化输入是用层序遍历,每组子节点都由 null 值分隔(参见示例&…...

【Kubernetes】第十八篇 - k8s 服务发现简介
一,前言 上一篇,介绍了阿里云 ECS 服务器重启后的环境修复; 本篇,介绍 k8s 服务发现; 二,服务发现简介 当 A服务依赖了 B服务,而 B服务的IP和端口未知(或相对不固定)&…...
 最好ak的div2)
Codeforces Round 856 (Div. 2) 最好ak的div2
最近几场的div2 E都是一个思路啊,代码大差不差的,感觉随便ak啊。 A. Prefix and Suffix Array 题意 给你前n−1n-1n−1个字符串前缀和后n−1n-1n−1个字符串后缀,判断原字符串是否是回文串 思路 相同长度的判断是否是对称的即可。 代码 B C…...

最新JVM技术: GraalVM,让你一文了解它的方方面面
1. 什么是GraalVM? GraalVM是一种开源的虚拟机平台,由Oracle公司开发。它支持多种编程语言,包括Java、JavaScript、Python、Ruby、R、C++等,旨在提高应用程序的性能和扩展性。 GraalVM通过提供即时编译器(Just-in-Time Compiler,JIT)和Ahead-of-Time(AOT)编译器来提…...

MySQL索引失效的场景
1.like 以%开头,索引无效;当like前缀没有%,后缀有%时,索引有效。 2.数据库表数据量过小 如果表的数据量非常小,则MySQL可能不会使用索引,因为它认为全表扫描的代价更小。 3.or语句前后没有同时使用索引 …...

Java - 对象的比较
一、问题提出 前面讲了优先级队列,优先级队列在插入元素时有个要求:插入的元素不能是null或者元素之间必须要能够进行比较,为了简单起见,我们只是插入了Integer类型, 那优先级队列中能否插入自定义类型对象呢…...

[算法]选择排序
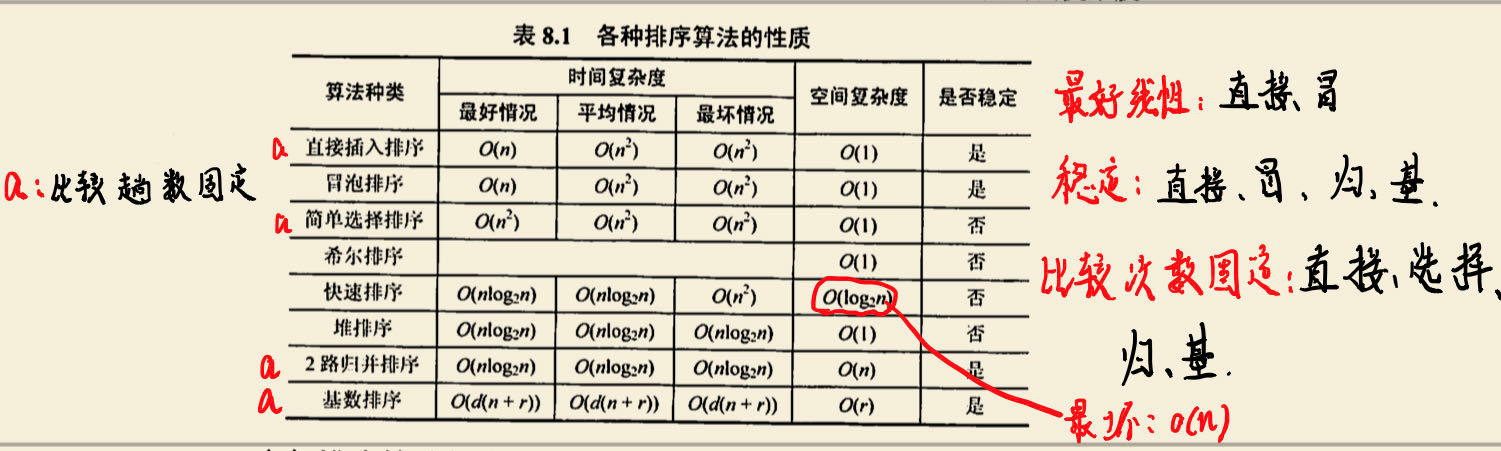
目录 1、选择排序的实现 2、例子 3、代码实现 4、时间复杂度和空间复杂度 5、选择排序的缺点——不稳定性 1、选择排序的实现 选择排序就是每一轮选择最小的元素直接交换到左侧。这种排序的最大优势,就是省去了多余的元素交换。 2、例子 原始数组和选择排序的…...
dp模型——状态机模型C++详解
状态机定义状态机顾名思义跟状态有关系,但到底有什么关系呢。在实际解决的时候,通常把状态想成节点,状态的转换想成有向边的有向图,我们来举个例子。相信大家都玩过类似枪战的游戏(没玩过的也听说过吧)&…...

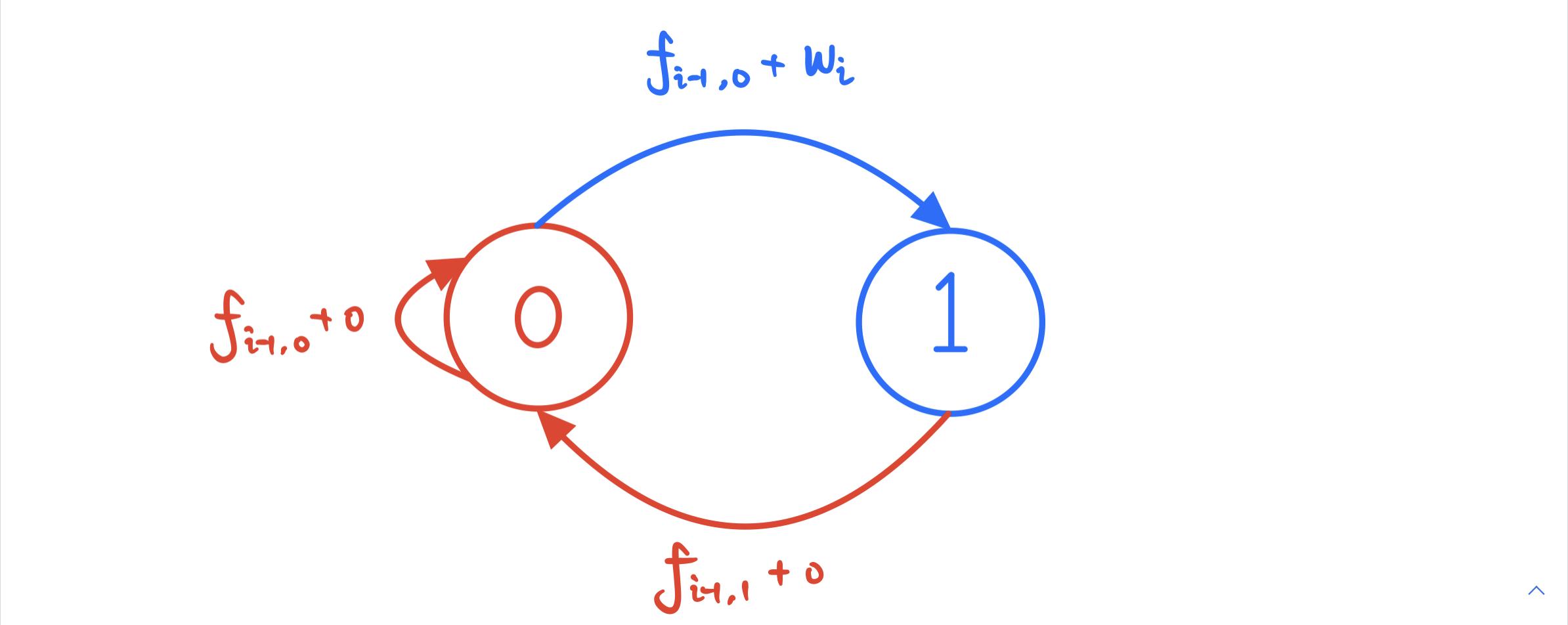
1.4 条件概率与乘法公式
1.4.1 条件概率在实际问题中,除了直接考虑某事件 B 发生的概率P(B)外,有时还会碰到这样的问题,就是“在事件A 已经发生的条件下,事件B 发生的概率”。一般情况下,后概率与前一概率不同,为了区别,我们常把后者称为条件概率,记为P(B…...
VITA/PYTHON/LUPA families
Image Sensor Group Top to Bottom Portfolio in Industrial Imaging Machine Vision • Factory automation and inspection • Robotic vision • Biometrics High-End Surveillance • Aerial Surveillance • Intelligent Traffic Systems (ITS) • Mapping Medical and Sc…...

独立开发者如何借助Taotoken多模型能力打造全能AI助手应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken多模型能力打造全能AI助手应用 对于独立开发者或小型工作室而言,构建一个功能全面的AI助手…...

Performance-Fish:深度解析《环世界》400%性能优化核心技术
Performance-Fish:深度解析《环世界》400%性能优化核心技术 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish Performance-Fish 是专为《环世界》(RimWorld&#…...

Kafka Connect集群部署踩坑实录:从单机到高可用的完整配置与监控方案
Kafka Connect生产级部署实战:高可用架构设计与监控体系构建 当数据管道成为企业核心基础设施时,Kafka Connect的稳定性直接关系到业务连续性。去年某电商大促期间,因单点故障导致数据同步延迟6小时的教训仍历历在目——这正是我们需要深入探…...

暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手
暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神3玩…...

Hitboxer终极指南:专业级游戏键盘重映射与SOCD清理工具完全教程
Hitboxer终极指南:专业级游戏键盘重映射与SOCD清理工具完全教程 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd Hitboxer是一款专为竞技游戏玩家设计的专业级键盘按键重映射和SOCD清理工具ÿ…...

Windows Defender终极移除指南:高效卸载13项核心服务完整教程
Windows Defender终极移除指南:高效卸载13项核心服务完整教程 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mirr…...

C++定时器避坑指南:线程安全、资源泄漏与时间轮参数怎么调?一次讲清楚
C定时器避坑指南:线程安全、资源泄漏与时间轮参数调优实战 在分布式系统和高并发场景中,定时器如同系统的心跳机制,其稳定性直接决定服务可靠性。去年某电商平台大促期间,由于定时任务堆积导致的雪崩效应,造成近千万损…...

如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案
如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想在任何设备上畅玩PC游戏?无论是想…...

基于PyPortal与CircuitPython的物联网游戏数据显示器开发实战
1. 项目概述 如果你和我一样,既是《英雄联盟》的忠实玩家,又对嵌入式硬件开发充满热情,那么把这两者结合起来,做一个能实时展示自己召唤师等级的“实体奖杯”,绝对是一件既酷又有成就感的事情。这个项目就是基于Adafr…...

Helm-Intellisense:VS Code智能补全插件,提升values.yaml编写效率
1. 项目概述:为什么我们需要一个Helm智能补全工具?如果你和我一样,日常工作中大量使用Helm来管理Kubernetes应用,那你一定对编写values.yaml文件时那种“盲人摸象”的感觉深有体会。面对一个动辄几十上百行配置的Helm Chart&#…...