深入了解Kafka的文件存储原理
Kafka简介
Kafka最初由Linkedin公司开发的分布式、分区的、多副本的、多订阅者的消息系统。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存是根据Topic进行归类,发送消息者称为Producer;消息接受者称为Consumer;此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息(kafka的0.8版本之后,producer不在依赖zookeeper保存meta信息,而是producer自己保存meta信息)。本文不打算对Apache Kafka的原理和实现进行介绍,而在编程的角度上介绍如何使用Apache Kafka。我们分别介绍如何编写Producer、Consumer以及Partitioner等。
Producer发送的消息是如何定位到具体的broker
- 生产者初始化:Producer在初始化时会加载配置参数,并开启网络线程准备发送消息。
- 拦截器逻辑:Producer可以设置拦截器来预处理消息,例如,修改或者丰富消息内容。
- 序列化:Producer将处理后的消息key/value进行序列化,以便在网络上传输。
- 分区策略:Producer会根据分区策略选择一个合适的分区,这个分区策略可以是轮询、随机或者根据key的哈希值等。
- 选择Broker:Producer并不直接将消息发送到指定的Broker,而是将消息发送到所选分区的leader副本所在的Broker。如果一个主题有多个分区,这些分区会均匀分布在集群中的Broker上。每个分区都有一个leader副本,Producer总是将消息发送到leader副本,然后由leader副本负责同步到follower副本。
- 发送模式:Producer发送消息的模式主要有三种:发后即忘(不关心结果),同步发送(等待结果),以及异步发送(通过Future对象跟踪状态)。
- 缓冲和批量发送:为了提高效率,Producer会先将消息收集到一个批次中,然后再一次性发送到Broker。
- 可靠性配置:Producer可以通过设置
request.required.acks参数来控制消息的可靠性级别,例如,设置为"all"时,需要所有in-sync replicas都确认接收后才认为消息发送成功。 - 失败重试:如果请求失败,Producer会根据配置的
retries参数来决定是否重试发送消息。
Kafka的Producer通过一系列步骤来确定消息的发送目标,其中分区策略和leader副本的选择是关键步骤,确保了消息能够正确地发送到相应的Broker。同时,通过合理的配置和重试机制,Producer能够保证消息的可靠性和系统的健壮性。
Kafka存储文件长什么样
在kafka集群中,每个broker(一个kafka实例称为一个broker)中有多个topic,topic数量可以自己设定。在每个topic中又有多个partition,每个partition为一个分区。kafka的分区有自己的命名的规则,它的命名规则为topic的名称+有序序号,这个序号从0开始依次增加。
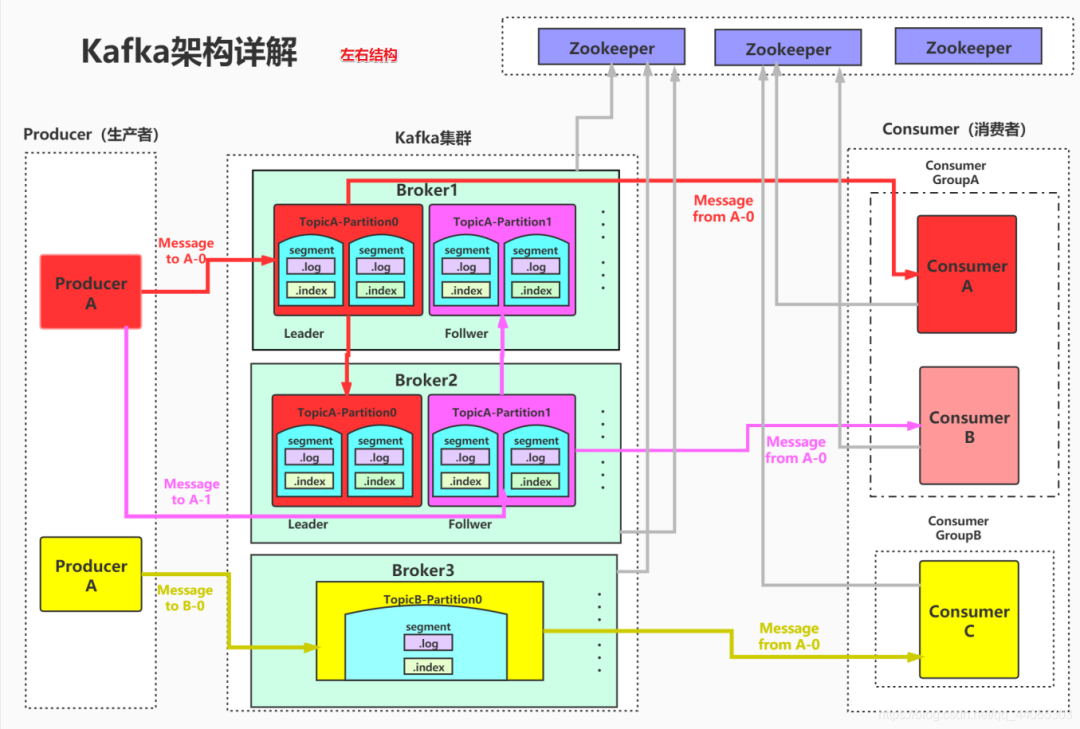
在每个partition中有可以分为多个segment file。当生产者往partition中存储数据时,内存中存不下了,就会往segment file里面存储。kafka默认每个segment file的大小是500M,在存储数据时,会先生成一个segment file,当这个segment file到500M之后,再生成第二个segment file 以此类推。每个segment file对应两个文件,分别是以.log结尾的数据文件和以.index结尾的索引文件。
具体来说,Kafka中的每个分区(Partition)由一个或多个Segment组成。每个Segment实际上是磁盘上的一个目录,这个目录下面会包含几个特定的文件:
- .log文件:这是真正存储消息数据的地方。每个Segment有一个对应的.log文件,它存储了属于这个Segment的所有消息。
- .index文件:索引文件,用于快速定位到.log文件中的具体消息。通过.index文件可以高效地查找消息所在的.log文件位置。
- .timeindex文件(可选):如果启用了时间戳索引,还会有这个文件。它用于按时间戳高效检索消息。
此外,Segment作为Kafka中数据组织的基本单位,设计成固定大小,这样做可以方便地进行数据的清理和压缩,同时保证性能。当一个Segment文件写满后,Kafka会自动创建一个新的Segment来继续存储数据。旧的Segment文件在满足一定条件(如被消费且达到一定的保留期)后会被删除,释放磁盘空间。
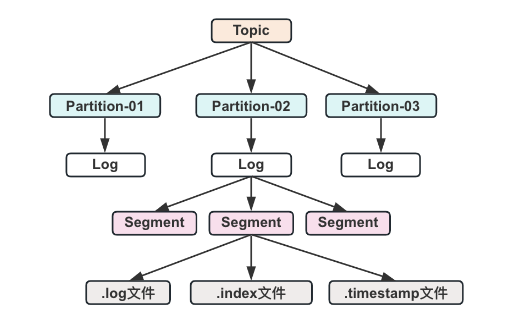
每个segment file也有自己的命名规则,每个名字有20个字符,不够用0填充。每个名字从0开始命名,下一个segment file文件的名字就是上一个segment file中最后一条消息的索引值。在.index文件中,存储的是key-value格式的,key代表在.log中按顺序开始第条消息,value代表该消息的位置偏移。但是在.index中不是对每条消息都做记录,它是每隔一些消息记录一次,避免占用太多内存。即使消息不在index记录中在已有的记录中查找,范围也大大缩小了。
Consumer如何消费数据
Kafka中的Consumer通过以下步骤来消费数据:
- 创建消费者实例:需要创建一个消费者实例,并指定一些关键配置,如消费者所属的群组、Topic名称以及与服务器通信的相关设置。
- 订阅主题:创建好的消费者实例需要订阅一个或多个主题,以便开始接收消息。
- 拉取数据:与一些消息系统采用的推送模式不同,Kafka的消费者采用的是“拉取”模式。这意味着消费者需要主动从Broker拉取数据,而不是等待Broker将数据推送过来。这种模式使得消费者可以根据自身处理能力来控制数据的获取速度。
- 长轮询机制:在没有新消息可消费时,消费者会使用长轮询机制等待新消息到达。消费者调用
poll()方法时可以设置超时时间(timeout),这样如果没有新消息,消费者会在等待一段时间后返回,并在下次调用poll()时继续尝试获取新消息。 - 提交偏移量:消费者在消费过程中会跟踪每个分区的消费进度,即偏移量(offset)。当消费者处理完消息后,它会提交当前的偏移量到Broker,以便在服务重启或故障恢复的情况下可以从准确的位置继续消费数据。
- 故障恢复:如果消费者发生宕机等故障,由于Kafka会持久化消费者的偏移量信息,消费者可以在恢复后继续从之前提交的偏移量处消费数据,确保不丢失任何消息。
- 消费者群组:Kafka支持多个消费者组成一个群组共同消费一个主题。在一个群组内,每个消费者会被分配不同的分区来消费,从而实现负载均衡和横向伸缩。同一个分区不能被一个群组内的多个消费者同时消费。
- 数据处理:消费者在拉取到数据后,可以根据自己的业务逻辑对数据进行处理,比如进行实时流处理或者存储到数据库中进行离线分析。
综上所述,Kafka的Consumer通过上述流程高效地从Broker拉取并处理数据,这些特性使得Kafka能够在高吞吐量和可扩展性方面表现出色,适合处理大规模数据流的场景。
Kafka中的过期数据处理机制
kafka作为一个消息中间件,是需要定期处理数据的,否则磁盘就爆了。
处理的机制
- 根据数据的时间长短进行清理,例如数据在磁盘中超过多久会被清理(默认是168个小时)
- 根据文件大小的方式给进行清理,例如数据大小超过多大时,删除数据(大小是按照每个partition的大小来界定的)。
删除过期的日志的方式
Kafka通过日志清理机制来删除过期的日志,主要依赖于两个配置参数来实现这一功能:
- 日志保留时间:通过设置
log.retention.hours参数,可以指定日志文件的保留时间。当日志文件的保存时间超过这个设定值时,这些文件将被删除。 - 日志清理策略:Kafka支持两种日志清理策略,分别是
delete和compact。delete策略会根据数据的保存时间或日志的最大大小来进行删除。而compact策略则是根据消息中的key来进行删除操作,通常用于特定类型的主题,如__consumer_offsets。
此外,在Kafka 0.9.0及更高版本中,日志清理功能默认是开启的(log.cleaner.enable默认为true)。这意味着Kafka会自动运行清理线程来执行定时清理任务。
综上所述,Kafka通过结合保留时间和清理策略的配置,实现了对过期日志的有效管理。这些机制确保了系统资源的合理利用,同时避免了因日志无限增长而导致的潜在问题
相关文章:
深入了解Kafka的文件存储原理
Kafka简介 Kafka最初由Linkedin公司开发的分布式、分区的、多副本的、多订阅者的消息系统。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存是根据Topic进行归类,发送消息者称为Producer&…...
RabbitMQ 高级
在昨天的练习作业中,我们改造了余额支付功能,在支付成功后利用RabbitMQ通知交易服务,更新业务订单状态为已支付。 但是大家思考一下,如果这里MQ通知失败,支付服务中支付流水显示支付成功,而交易服务中的订单…...

音视频开发之旅——音频基础概念、交叉编译原理和实践(LAME的交叉编译)(Android)
本文主要讲解的是音频基础概念、交叉编译原理和实践(LAME的交叉编译),是基于Android平台,示例代码如下所示: AndroidAudioDemo 音频基础概念 在进行音频开发的之前,了解声学的基础还是很有必要的。 声音…...

直播美颜SDK开发指南:构建个性化的主播美颜工具
本篇文章,小编将带您深入了解如何构建个性化的主播美颜工具,从而为用户提供更优质的直播体验。 一、美颜技术概述 在开始SDK的开发之前,我们首先需要了解美颜技术的基本原理。美颜技术通常包括肤色检测、人脸检测、特征点定位、滤镜处理等步…...

羊大师揭秘,羊奶有哪些好处和不足呢?
羊大师揭秘,羊奶有哪些好处和不足呢? 羊奶的好处主要包括: 营养丰富:羊奶中含有多种人体所需的营养成分,如蛋白质、脂肪、碳水化合物、矿物质和维生素等。尤其是蛋白质含量高,且易于人体吸收利用。 增强免…...

鸿蒙问题之CustomDialog后持久化@state数据崩溃
开发需求:有一个字符串数组,可以通过弹框编辑其中的某个字符串,编辑完成后更新数组并持久化这个数组。 这个需求算是很简单,很常见的需求了。但是,开发过程中却遇到了一个不小的难题。 我的数组内容需要在组件中显示…...

微服务高性能通信技术-gRPC实战落地
在微服务架构中,服务之间的通信是至关重要的。为了实现高性能、低延迟和跨语言的服务间通信,gRPC是一个流行的选择。gRPC是一个开源的、高性能的、通用的RPC(远程过程调用)框架,基于HTTP/2协议和Protocol Buffers序列化…...

洛阳旅游攻略
洛阳旅游攻略 第一天(抵达当天): 1.先将行李放到酒店—2.老城十字街(打车可能会堵车)—3.洛邑古城—4.丽景门(步行) 第二天: 1.早起吃早餐—(打车三十分钟,…...
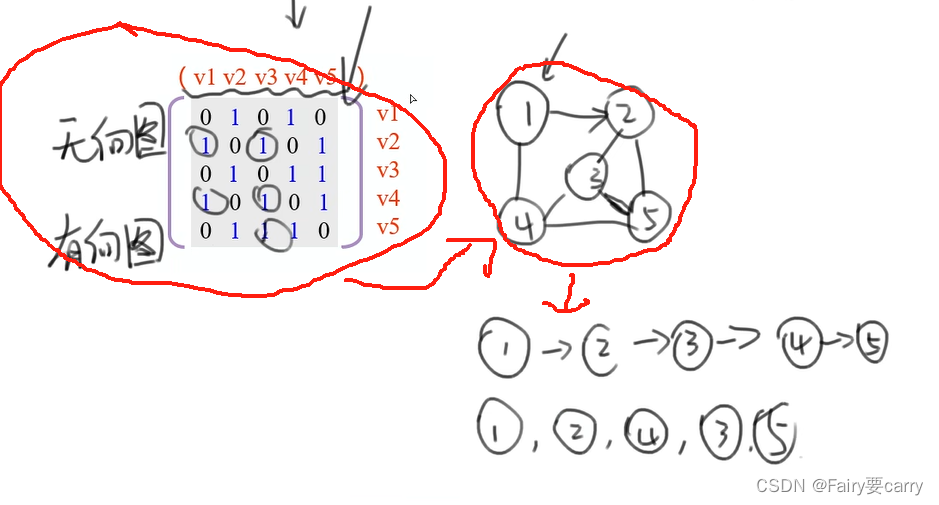
图论例题解析
1.图论基础概念 概念 (注意连通非连通情况,1节点) 无向图: 度是边的两倍(没有入度和出度的概念) 1.完全图: 假设一个图有n个节点,那么任意两个节点都有边则为完全图 2.连通图&…...

图解 TCP 拥塞控制
文章目录 什么是拥塞控制拥塞控制算法慢启动拥塞避免快速恢复 TCP拥塞控制状态机 什么是拥塞控制 拥塞控制是一种 确保网络中的数据包以可持续的速率传输 的机制,避免因为数据包太多而超过网络当前的承载能力,导致网络性能下降,甚至产生大量…...
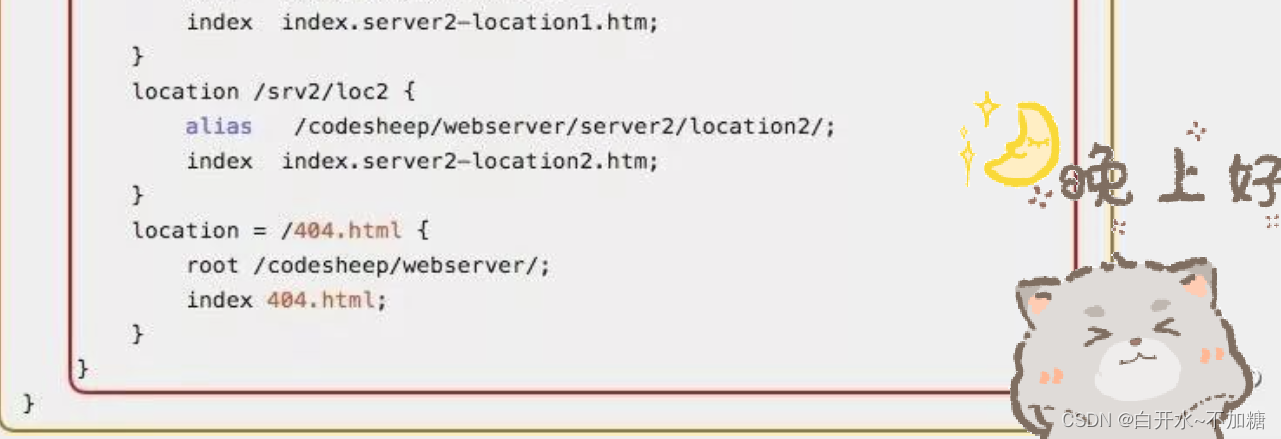
Nginx配置文件的整体结构
一、Nginx配置文件的整体结构 从图中可以看出主要包含以下几大部分内容: 1. 全局块 该部分配置主要影响Nginx全局,通常包括下面几个部分: 配置运行Nginx服务器用户(组) worker process数 Nginx进程PID存放路径 错误…...
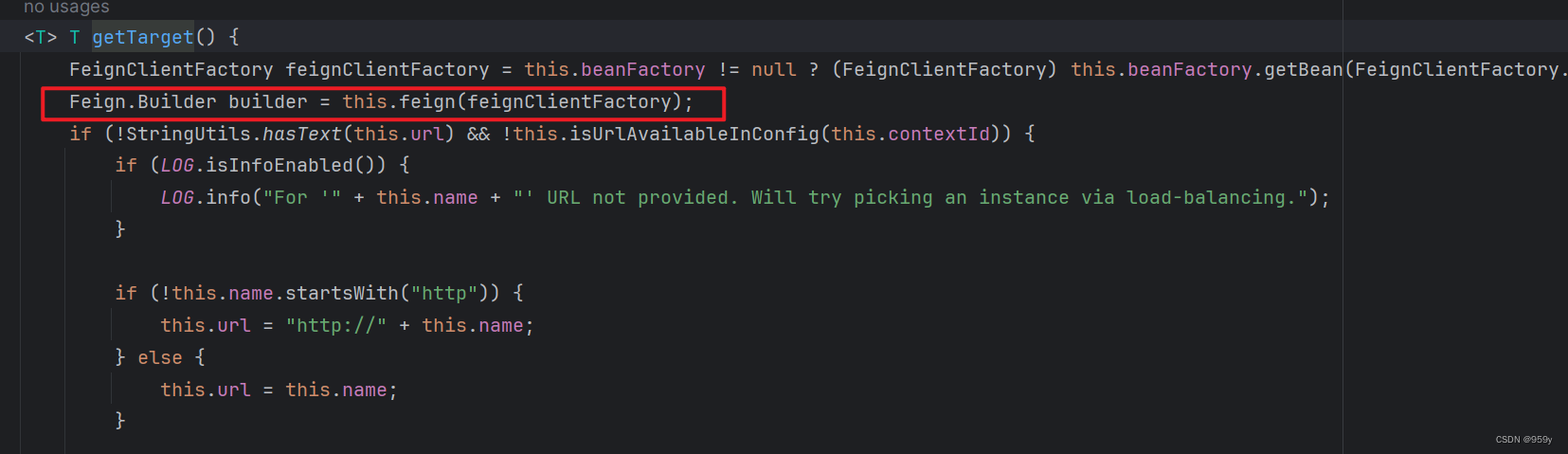
[SpringCloud] OpenFeign核心架构原理 (三)
文章目录 1.SpringCloud是如何整合Feign的1.1 将FeignClient接口注册到Spring中1.2 FeignClientFactoryBean相关 1.SpringCloud是如何整合Feign的 核心组件重新实现, 支持更多的SpringCloud生态的功能。将接口动态代理对象注入到Spring容器中。 1.1 将FeignClient接口注册到S…...

elementUI Table组件点击取当前行索引
在使用element UI Table组件时,需要点击取当前行索引,并删除当前行,看了element UI 文档好象没有这个的,仔细看下发现当前行索引是在scope里的$.index里。 element UI文档:https://www.uihtm.com/element/#/zh-CN/comp…...

组基轨迹建模 GBTM的介绍与实现(Stata 或 R)
基本介绍 组基轨迹建模(Group-Based Trajectory Modeling,GBTM)(旧名称:Semiparametric mixture model) 历史:由DANIELS.NAGIN提出,发表文献《Analyzing Developmental Trajectori…...

解决前端性能问题:如何优化大量数据渲染和复杂交互?
✨✨祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心!✨✨ 🎈🎈作者主页: 喔的嘛呀🎈🎈 目录 引言 一、分页加载数据 二、虚拟滚动 三、懒加载 四、数据缓存 五、减少重绘和回流 …...

【Vue3】深入理解Vue中的ref属性
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢…...

CentOS上安装与配置Nginx
CentOS上安装与配置Nginx Nginx是一款轻量级的Web服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,并在一个BSD-like协议下发行。以下是在CentOS系统上安装和配置Nginx的步骤。 🌟 前言 欢迎来到我的小天地,这…...
DataGrip 连接 Centos MySql失败
首先检查Mysql是否运行: systemctl status mysqld , 如果显示没有启动则需要启动mysql 检查防火墙是否打开,是否打开3306的端口 sudo firewall-cmd --list-all 如果下面3306没有打开则打开3306端口 publictarget: defaulticmp-block-inver…...
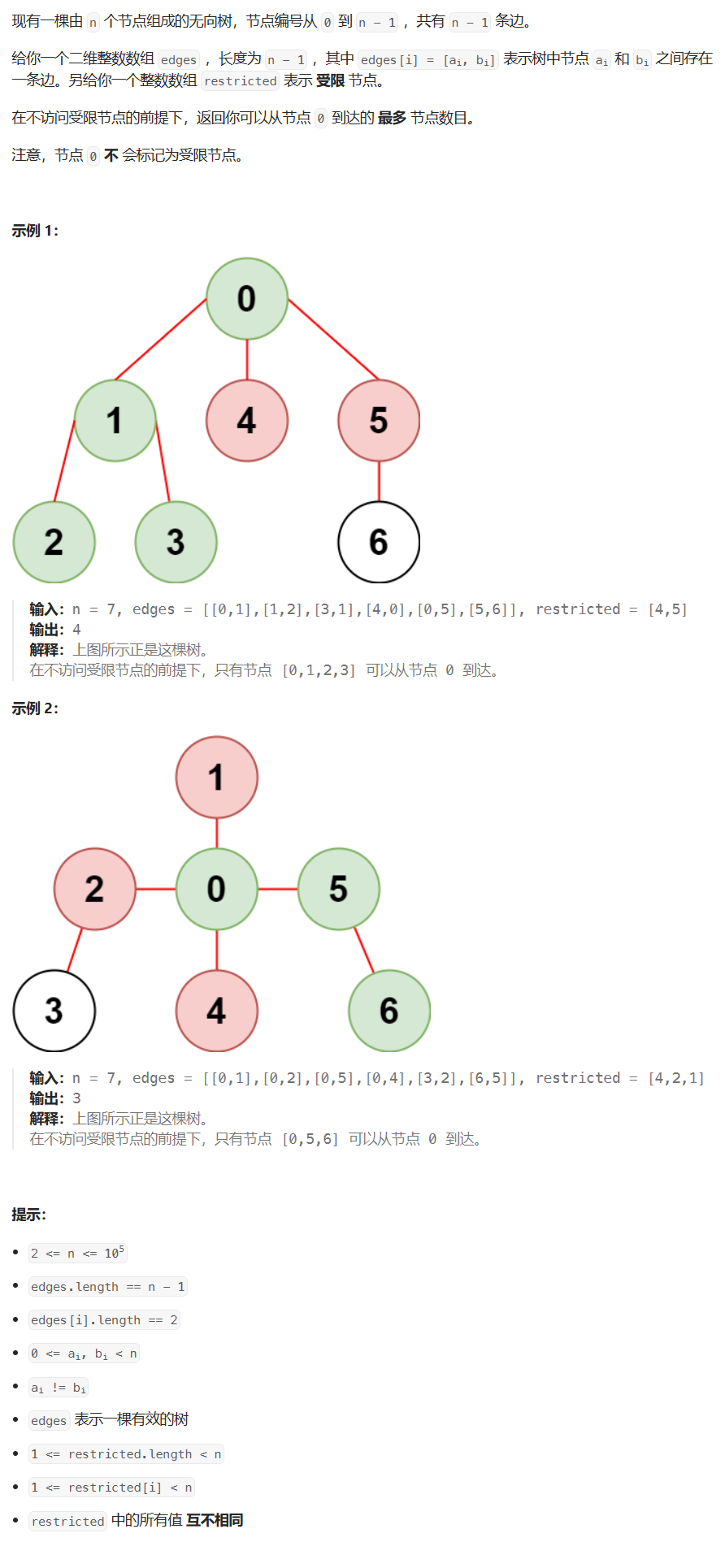
【图论】图的遍历 - 构建领接表(无向图)
文章目录 例题:受限条件下可到达节点的数目题目描述代码与注释模板抽象 例题:受限条件下可到达节点的数目 题目链接:2368. 受限条件下可到达节点的数目 题目描述 代码与注释 func reachableNodes(n int, edges [][]int, restricted []int)…...

Claude 3家族惊艳亮相:AI领域掀起新浪潮,GPT-4面临强劲挑战
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法|MySQL| 💫个人格言:“没有罗马,那就自己创造罗马~” #mermaid-svg-agd7RSCGMblYxo85 {font-family:"trebuchet ms",verdana,arial,sans-serif;f…...
)
手把手教你用STM32的编码器模式,精准读取JGB37-520电机转速(附TB6612驱动配置)
基于STM32编码器模式实现JGB37-520电机闭环控制实战指南 在智能硬件开发领域,精确控制电机转速和位置是实现高质量运动控制的基础。JGB37-520作为一款带有霍尔编码器的减速电机,配合TB6612驱动模块,可以构建完整的闭环控制系统。本文将深入解…...
)
从‘黑窗口’到彩色世界:用GLUT快速实现你的第一个OpenGL图形程序(含完整代码解析)
从命令行到绚丽图形:GLUT快速入门OpenGL视觉编程 在计算机图形学的浩瀚海洋中,OpenGL无疑是最闪耀的灯塔之一。对于初学者而言,如何快速跨过复杂的配置和抽象的理论,直接看到图形输出的成果,是激发学习兴趣的关键。本文…...

Angular-dragdrop与Bootstrap集成:构建响应式拖放界面的完美方案
Angular-dragdrop与Bootstrap集成:构建响应式拖放界面的完美方案 【免费下载链接】angular-dragdrop Implementing jQueryUI Drag and Drop functionality in AngularJS (with Animation) is easier than ever 项目地址: https://gitcode.com/gh_mirrors/an/angul…...

API 监控告警系统
LogMonitor - API监控告警系统 基于Python的智能API监控系统,集成Splunk日志分析和钉钉告警,支持多种API类型的实时监控和趋势分析。 代码地址 https://github.com/junbingliu007/log_monitor 功能特性 多API类型监控:支持多种API类型智…...

半波整流电路:从原理到实践,掌握AC-DC转换基础
1. 项目概述:从交流到直流的第一步在电子电路的世界里,我们常常需要将交流电(AC)转换为直流电(DC),这个过程我们称之为“整流”。而半波整流电路,可以说是所有整流电路中最基础、最经…...
)
图吧工具箱下载安装和使用保姆级教程(2026实测)
图吧工具箱全名图拉丁吧硬件检测工具箱,简称 “图吧工具箱”,是国内硬件爱好者社区 “图拉丁吧” 开发维护的免费开源工具合集,2014 年首发,至今持续更新,是 DIY 玩家、装机员、普通用户公认的 “电脑硬件全能管家”。…...

7分钟掌握中国行政区划数据:从零到实战的完整指南
7分钟掌握中国行政区划数据:从零到实战的完整指南 【免费下载链接】Administrative-divisions-of-China 中华人民共和国行政区划:省级(省份)、 地级(城市)、 县级(区县)、 乡级&…...

全息三维空间孪生,全域无感精准智位系列:UWB:多路径干扰精度失稳|镜像:多源时空误差融合
在全域空间数字化、实景虚实融合与空间智能快速演进的产业周期中,镜像视界(浙江)科技有限公司持续深耕视频原生三维重构、时空AI像素解算、全域无感精准定位、跨镜轨迹智能推演底层核心领域,依托八大自主可控核心引擎构筑全栈技术…...

Taotoken在应对大模型API服务波动时的路由与容灾机制体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken在应对大模型API服务波动时的路由与容灾机制体验 1. 背景与观测场景 在开发实践中,我们时常会遇到依赖的某个…...
)
学术论文翻译翻车重灾区!Perplexity翻译查询功能如何通过引用锚点保留+LaTeX公式智能隔离实现零失真输出(仅限Pro+订阅用户可见的隐藏模式)
更多请点击: https://intelliparadigm.com 第一章:学术论文翻译翻车重灾区的底层归因分析 学术论文翻译失准并非偶然现象,其背后存在系统性语言学、认知科学与工程实践三重张力。当非母语研究者依赖通用大模型或词典式工具进行技术文本转译时…...