sqoop-import 详解
文章目录
- 前言
- 一、介绍
- 1. sqoop简介
- 2. sqoop import的作用
- 3. 语法
- 3.1 sqoop import 语法
- 3.2 导入配置属性
- 二、导入参数
- 1. 常见参数
- 2. 验证参数
- 3. 导入控制参数
- 4. 用于覆盖映射的参数
- 5. 增量导入参数
- 6. 输出行格式参数
- 7. 输入解析参数
- 8. Hive 参数
- 9. HBase 参数
- 10. Accumulo 参数
- 11. 代码生成参数
- 三、Sqoop-HCatalog
- 1. 介绍
- 2. HCatalog 参数
- 3. HCatalog 支持的 Hive 参数
- 4. HCatalog 不支持的参数
- 四、应用示例
- 1. 从SQL server导入数据到Hive
- 2. 从Oracle导入数据到Hive
- 总结
前言
本文介绍了Sqoop工具的基本概念、使用方法和常见参数,以及Sqoop与HCatalog的集成。Sqoop是一个用于在Hadoop和关系型数据库之间传输数据的工具,可以方便地将关系型数据库中的数据导入到Hadoop生态系统中的HDFS或Hive中。通过Sqoop的导入功能,用户可以选择全表导入或增量导入模式,并可以使用各种参数来控制导入的行为。此外,本文还介绍了Sqoop与HCatalog的集成,HCatalog是Hadoop生态系统中的一个表和存储管理服务,可以为Sqoop提供更多的数据处理和管理功能。
一、介绍
1. sqoop简介
Sqoop是一个用于在Apache Hadoop和关系型数据库之间传输数据的工具。它允许用户将结构化数据从关系型数据库(如MySQL、Oracle、PostgreSQL等)导入到Hadoop生态系统中的Hadoop分布式文件系统(HDFS)或Hive中,并且可以将数据从HDFS或Hive导出到关系型数据库中。
2. sqoop import的作用
sqoop import用于从关系型数据库中导入数据到Hadoop生态系统中。它支持全表导入和增量导入两种模式。全表导入将整个表的数据导入到HDFS或Hive中,而增量导入只导入源数据库中新增或更新的数据。
3. 语法
3.1 sqoop import 语法
sqoop import (泛型参数) (导入参数)
3.2 导入配置属性
可以在命令行的泛型参数中指定导入配置属性。
sqoop import -D property.name=property.value ...
| 参数 | 描述 |
|---|---|
| sqoop.bigdecimal.format.string | 控制 BigDecimal 列在存储为 String 时的格式设置方式。值 (default) 将使用 toPlainString 来存储它们,而无需指数分量 (0.0000001);而值 true或false 将使用 toString,其中可能包含指数 (1E-7) |
| sqoop.hbase.add.row.key | 设置为(default)时,Sqoop 不会将用作行键的列添加到 HBase 中的行数据中。设置为 false或true 时,用作行键的列将添加到 HBase 中的行数据中。 |
二、导入参数
1. 常见参数
| 参数 | 描述 |
|---|---|
| –connect <jdbc-uri> | 指定 JDBC 连接字符串 |
| –connection-manager <class-name> | 指定要使用的连接管理器类 |
| –driver <class-name> | 手动指定要使用的 JDBC 驱动程序类 |
| –hadoop-mapred-home <dir> | 覆盖 $HADOOP_MAPRED_HOME |
| –help | 打印使用说明 |
| –password-file | 设置包含身份验证密码的文件的路径 |
| -P | 从控制台读取密码 |
| –password <password> | 设置身份验证密码 |
| –username <username> | 设置身份验证用户名 |
| –verbose | 工作时打印更多信息 |
| –connection-param-file <filename> | 提供连接参数的可选属性文件 |
| –relaxed-isolation | 将连接事务隔离设置为映射器的未提交读取 |
2. 验证参数
| 参数 | 描述 |
|---|---|
| –validate | 启用对复制数据的验证,仅支持单个表副本。 |
| –validator <class-name> | 指定要使用的验证程序类。 |
| –validation-threshold <class-name> | 指定要使用的验证阈值类。 |
| –validation-failurehandler <class-name> | 指定要使用的验证失败处理程序类。 |
3. 导入控制参数
| 参数 | 描述 |
|---|---|
| –append | 将数据追加到 HDFS 中的现有数据集中 |
| –as-avrodatafile | 将数据导入 Avro 数据文件中 |
| –as-sequencefile | 将数据导入 Sequence 文件中 |
| –as-textfile | 以纯文本格式导入数据(默认) |
| –as-parquetfile | 将数据导入 Parquet 文件中 |
| –boundary-query <statement> | 用于创建拆分的边界查询 |
| –columns <col,col,col…> | 要从表中导入的列 |
| –delete-target-dir | 删除导入目标目录(如果存在) |
| –direct | 如果数据库存在,请使用直接连接器 |
| –fetch-size <n> | 一次要从数据库读取的条目数 |
| –inline-lob-limit <n> | 设置内联 LOB 的最大大小 |
| -m,–num-mappers <n> | 使用 n 个map任务并行导入 |
| -e,–query <statement> | 导入sql查询语句的结果 |
| –split-by <column-name> | 用于拆分工作单元的表列。不能与选项 --autoreset-to-one-mapper 一起使用。 |
| –split-limit <n> | 每个拆分大小的上限。这仅适用于 Integer 和 Date 列。对于日期或时间戳字段,它以秒为单位计算。 |
| –autoreset-to-one-mapper | 如果表没有主键且未提供拆分列,则导入应使用一个映射器。不能与选项 --split-by <col> 一起使用。 |
| –table <table-name> | 要读取的表 |
| –target-dir <dir> | HDFS 目标目录 |
| –temporary-rootdir <dir> | 导入期间创建的临时文件的 HDFS 目录(覆盖默认的“_sqoop”) |
| –warehouse-dir <dir> | 表目标的 HDFS 父级 |
| –where <where clause> | 导入期间使用的 WHERE 子句 |
| -z,–compress | 启用压缩 |
| –compression-codec <c> | 使用 Hadoop 编解码器(默认 gzip) |
| –null-string <null-string> | 要为字符串列的 null 值写入的字符串 |
| –null-non-string <null-string> | 要为非字符串列的 null 值写入的字符串 |
4. 用于覆盖映射的参数
| 参数 | 描述 |
|---|---|
| –map-column-java <mapping> | 覆盖已配置列从 SQL 到 Java 类型的映射 |
| –map-column-hive <mapping> | 覆盖从 SQL 到 Hive 类型的映射,以配置列 |
5. 增量导入参数
| 参数 | 描述 |
|---|---|
| –check-column (col) | 指定在确定要导入的行时要检查的列。(该列不应为 CHAR/NCHAR/VARCHAR/VARNCHAR/LONGVARCHAR/LONGVARCHAR 类型) |
| –incremental (mode) | 指定 Sqoop 如何确定哪些行是新行。include 和 modeappendlastmodified 的合法值。 |
| –last-value (value) | 指定上一次导入的检查列的最大值。 |
6. 输出行格式参数
| 参数 | 描述 |
|---|---|
| –enclosed-by <char> | 设置封闭字符 |
| –escaped-by <char> | 设置转义字符 |
| –fields-terminated-by <char> | 设置字段分隔符 |
| –lines-terminated-by <char> | 设置行尾字符 |
| –mysql-delimiters | 使用 MySQL 的默认分隔符集: fields: lines: escaped-by: optionally-enclosed-by:,\n’ |
| –optionally-enclosed-by <char> | 设置可选封闭字符 |
7. 输入解析参数
| 参数 | 描述 |
|---|---|
| –input-enclosed-by <char> | 设置输入封闭字符 |
| –input-escaped-by <char> | 设置输入转义字符 |
| –input-fields-terminated-by <char> | 设置输入字段分隔符 |
| –input-lines-terminated-by <char> | 设置输入行尾字符 |
| –input-optionally-enclosed-by <char> | 设置输入可选封闭字符 |
8. Hive 参数
| 参数 | 描述 |
|---|---|
| –hive-home <dir> | 覆盖$HIVE_HOME |
| –hive-import | 将表导入 Hive,如果未设置任何分隔符,则使用 Hive 的默认分隔符。 |
| –hive-overwrite | 覆盖 Hive 表中的现有数据。 |
| –create-hive-table | 设置后,如果目标 hive 表存在,任务将失败。默认情况下,此属性为 false。 |
| –hive-table <table-name> | 设置导入 Hive 时要使用的表名。 |
| –hive-drop-import-delims | 导入到 Hive 时,从字符串字段中删除 \n、\r 和 \01。 |
| –hive-delims-replacement | 导入到 Hive 时,将字符串字段中的 \n、\r 和 \01 替换为用户定义的字符串。 |
| –hive-partition-key | 要分区的 hive 字段的名称 |
| –hive-partition-value <v> | hive 分区值 |
| –map-column-hive <map> | 覆盖已配置列从 SQL 类型到 Hive 类型的默认映射。如果在此参数中指定逗号,请使用 URL 编码的键和值,例如,使用 DECIMAL(1%2C%201) 而不是 DECIMAL(1, 1)。 |
9. HBase 参数
| 参数 | 描述 |
|---|---|
| –column-family <family> | 设置导入的目标列族 |
| –hbase-create-table | 如果指定,请创建缺少的 HBase 表 |
| –hbase-row-key <col> | 指定要用作行键的输入列,如果输入表包含复合键,则 |
| –hbase-table <table-name> | 指定要用作目标的 HBase 表,而不是 HDFS |
| –hbase-bulkload | 支持批量加载 |
10. Accumulo 参数
| 参数 | 描述 |
|---|---|
| –accumulo-table <table-nam> | 指定要用作目标的 Accumulo 表,而不是 HDFS |
| –accumulo-column-family <family> | 设置导入的目标列族 |
| –accumulo-create-table | 如果指定,将创建缺少的 Accumulo 表 |
| –accumulo-row-key <col> | 指定要用作行键的输入列 |
| –accumulo-visibility <vis> | (可选)指定要应用于插入到 Accumulo 中的所有行的可见性标记。默认值为空字符串。 |
| –accumulo-batch-size <size> | (可选)设置 Accumulo 的写入缓冲区的大小(以字节为单位)。默认值为 4MB。 |
| –accumulo-max-latency <ms> | (可选)设置 Accumulo 批处理编写器的最大延迟(以毫秒为单位)。默认值为 0。 |
| –accumulo-zookeepers <host:port> | Accumulo 实例使用的 Zookeeper 服务器的逗号分隔列表 |
| –accumulo-instance <table-name> | 目标Accumulo实例的名称 |
| –accumulo-user <username> | 要导入为 的 Accumulo 用户的名称 |
| –accumulo-password <password> | Accumulo 用户的密码 |
11. 代码生成参数
| 参数 | 描述 |
|---|---|
| –bindir <dir> | 已编译对象的输出目录 |
| –class-name <name> | 设置生成的类名。这将覆盖 --package-name 与 --jar-file 结合使用时,设置的输入类。 |
| –jar-file <file> | 禁用代码生成,使用指定的 jar |
| –outdir <dir> | 生成代码的输出目录 |
| –package-name <name> | 将自动生成的类放在此包中 |
| –map-column-java <m> | 覆盖已配置列从 SQL 类型到 Java 类型的默认映射。 |
三、Sqoop-HCatalog
1. 介绍
HCatalog是Hadoop生态系统中的一个表和存储管理服务,它为用户提供了在Hadoop集群上读取和写入数据的便利性。HCatalog的设计目标是为使用不同数据处理工具(如Pig、MapReduce和Hive)的用户提供一个统一的接口,使他们能够更轻松地处理分布式数据。
HCatalog通过提供表的抽象概念,向用户展示了Hadoop分布式数据的关系视图。它将底层的文件系统(如HDFS)中的数据组织成表的形式,并隐藏了数据的存储细节,使用户无需关心数据存储在何处以及数据的存储格式(如RCFile、文本文件或序列文件)。
HCatalog支持读取和写入Hive所支持的任何文件格式,这得益于它使用了序列化器-反序列化器(SerDe)。默认情况下,HCatalog支持RCFile、CSV、JSON和SequenceFile格式的文件。如果需要使用自定义的文件格式,用户需要提供相应的InputFormat和OutputFormat以及SerDe。
HCatalog的能力可以抽象各种存储格式,这也使得它能够为其他工具提供支持。例如,HCatalog可以为Sqoop提供RCFile(以及未来的文件类型)的支持,使得Sqoop能够更方便地与HCatalog集成,实现数据的导入和导出操作。
总而言之,HCatalog是一个在Hadoop生态系统中提供表和存储管理服务的组件,它简化了用户对分布式数据的处理,提供了统一的接口和抽象,使得用户可以更轻松地读取和写入数据,而无需关心底层数据的存储细节和格式。
在HCatalog作业中,以下选项将被忽略:
- 所有输入分隔符选项都会被忽略。
- 输出分隔符通常会被忽略,除非使用了
--hive-delims-replacement或--hive-drop-import-delims选项。当指定了--hive-delims-replacement选项时,所有类型的数据库表列将被后处理,以删除或替换分隔符。这仅在HCatalog表使用文本格式时才需要。
2. HCatalog 参数
| 参数 | 描述 |
|---|---|
| –hcatalog-database | 指定hive数据库 |
| –hcatalog-table | 指定hive表 |
| –hcatalog-home | HCatalog 安装的主目录 |
| –create-hcatalog-table | 创建hive表,默认已创建 |
| –drop-and-create-hcatalog-table | 如果hive表已存在,则删除后再创建 |
| –hcatalog-storage-stanza | 指定要追加到表的存储节 |
| –hcatalog-partition-keys | 指定多个静态分区 键/值 对,用逗号分隔 |
| –hcatalog-partition-values | 指定多个静态分区 键/值 对,用逗号分隔 |
3. HCatalog 支持的 Hive 参数
| 参数 | 描述 |
|---|---|
| –hive-home <dir> | 覆盖$HIVE_HOME |
| –hive-partition-key | 要分区的 hive 字段的名称 |
| –hive-partition-value <v> | hive 分区值 |
| –map-column-hive <map> | 覆盖已配置列从 SQL 类型到 Hive 类型的默认映射。如果在此参数中指定逗号,请使用 URL 编码的键和值,例如,使用 DECIMAL(1%2C%201) 而不是 DECIMAL(1, 1)。 |
4. HCatalog 不支持的参数
| 参数 |
|---|
| –hive-import |
| –hive-overwrite |
| –export-dir |
| –target-dir |
| –warehouse-dir |
| –append |
| –as-sequencefile |
| –as-avrodatafile |
| –as-parquetfile |
四、应用示例
1. 从SQL server导入数据到Hive
sqoop import \--connect "jdbc:sqlserver://ip:port;database=db_name" \--username sqlserver_username \--password sqlserver_password \--query "select * from sqlserver_table where \$CONDITIONS" \--hcatalog-database hive_database_name \--hcatalog-table hive_table_name \--fields-terminated-by '\0001' \--lines-terminated-by '\n' \--hive-drop-import-delims \--null-string '\\N' \--null-non-string '\\N' \-m 1
注意:如果并行度大于1,必须使用 --split-by 指定拆分列
2. 从Oracle导入数据到Hive
sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \--connect "jdbc:oracle:thin:@ip:port:oracle_database_name" \--username oracle_username \--password oracle_password \--query "select * from oracle_table_name where \$CONDITIONS" \--hcatalog-database hive_database_name \--hcatalog-table hive_table_name \--hcatalog-partition-keys 'year,month' \--hcatalog-partition-values '2019,03' \--fields-terminated-by '\0001' \--lines-terminated-by '\n' \--hive-drop-import-delims \--null-string '\\N' \--null-non-string '\\N' \-m 1
总结
本文详细介绍了Sqoop工具的导入功能和常见参数,以及Sqoop与HCatalog的集成。通过Sqoop的导入功能,用户可以方便地将关系型数据库中的数据导入到Hadoop生态系统中,并可以使用各种参数来控制导入的行为。同时,通过与HCatalog的集成,用户可以更方便地管理和处理导入的数据。
希望本教程对您有所帮助!如有任何疑问或问题,请随时在评论区留言。感谢阅读!
参考链接:
- https://sqoop.apache.org/docs/1.4.7/SqoopUserGuide.html
相关文章:

sqoop-import 详解
文章目录 前言一、介绍1. sqoop简介2. sqoop import的作用3. 语法3.1 sqoop import 语法3.2 导入配置属性 二、导入参数1. 常见参数2. 验证参数3. 导入控制参数4. 用于覆盖映射的参数5. 增量导入参数6. 输出行格式参数7. 输入解析参数8. Hive 参数9. HBase 参数10. Accumulo 参…...
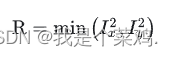
第二周opencv
一、边缘检测算子 边缘检测算子是用于检测图像中物体边界的工具。边缘通常表示图像中灰度值或颜色发生显著变化的地方。边缘检测有助于识别图像中的物体形状、轮廓和结构。这些算子通过分析图像的灰度或颜色梯度来确定图像中的边缘。 梯度算子 要得到一幅图像的梯度,…...
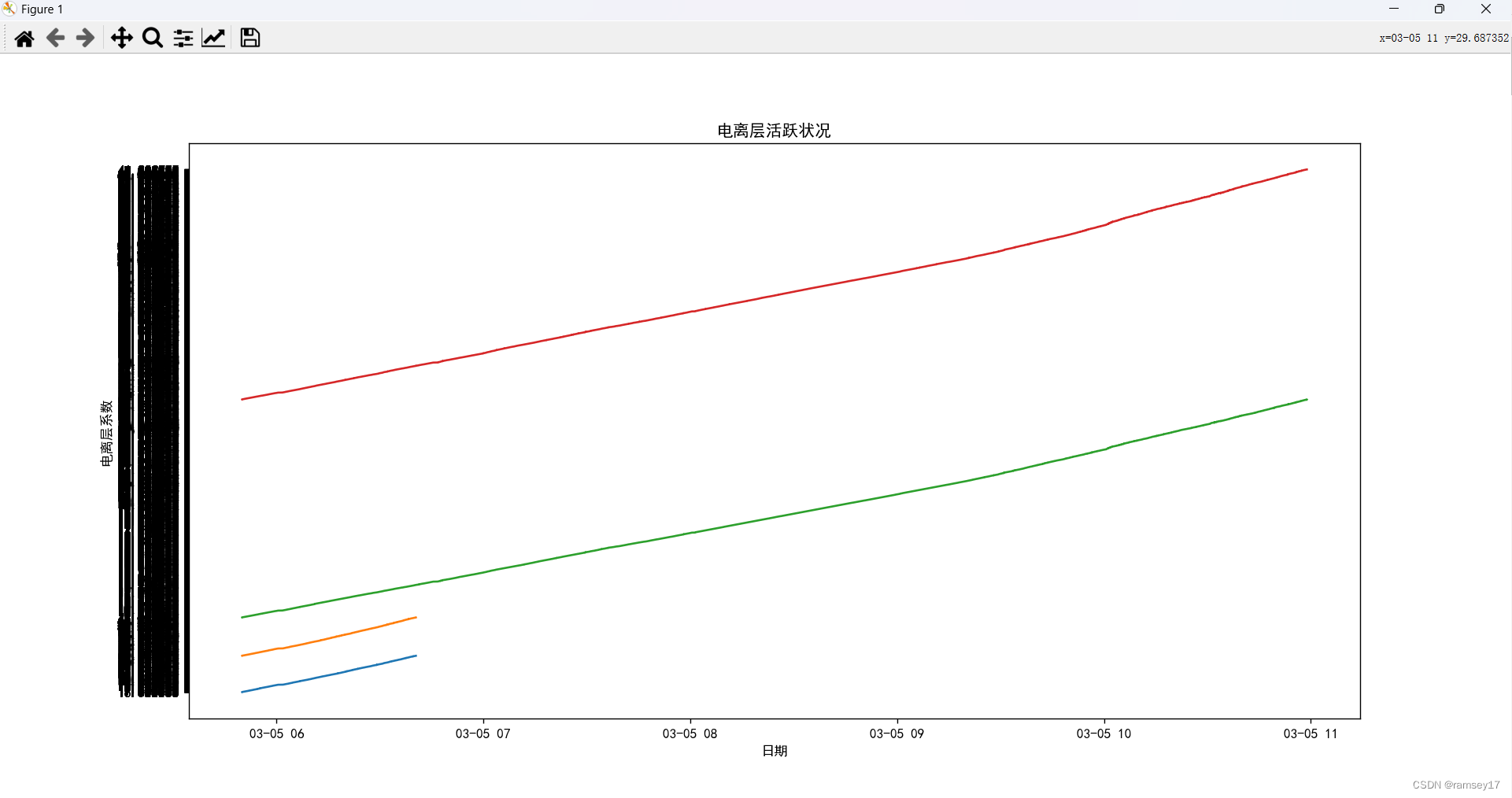
python_读取txt文件绘制多条曲线II
从给定的列表中来匹配txt文件对应列的数据; import matplotlib.pyplot as plt import re from datetime import datetime from pylab import mplmpl.rcParams["font.sans-serif"] ["SimHei"] # 设置显示中文字体 mpl.rcParams["axes.un…...
)
java排序简单总结和推荐使用套路(数据排序,结构体排序)
了解int和Integer的区别 int是Java的基本数据类型,用于表示整数值。Integer是int的包装类,它是一个对象,可以包含一个int值并提供一些额外的功能。 Java集合框架中的集合类(如List、Set、Map)只能存储对象,…...

掘根宝典之C语言联合和枚举
联合 C语言中的联合(Union)是一种特殊的数据类型,它允许在同一块内存空间中存储不同类型的数据。 联合与结构体类似,但不同的是,在给联合变量赋值时,它只能存储最后一次赋值的值。 创建联合 在C语言中&…...
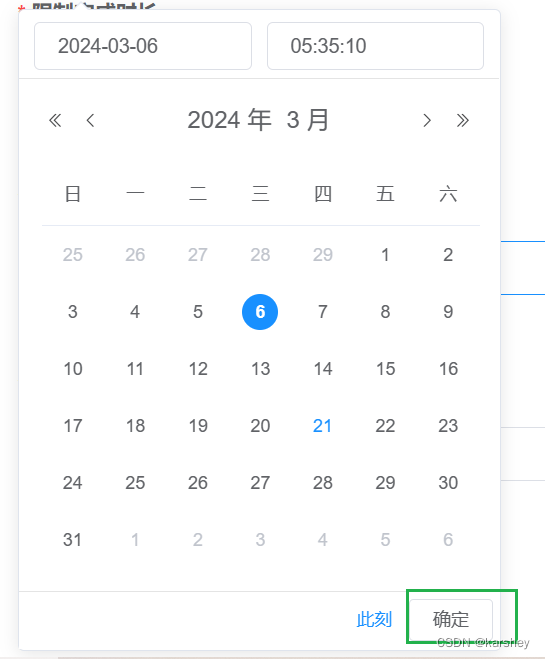
【debug】element-ui时间控件回显后不可编辑且显示为空
问题:使用element-ui的时间控件回显数据,编辑数据没有反应:点时间和“确认”按钮都没反应。 输入框中会显示数据,但提交时的校验显示为空。 <el-form-item label"开始时间" prop"limitStartTime"><…...
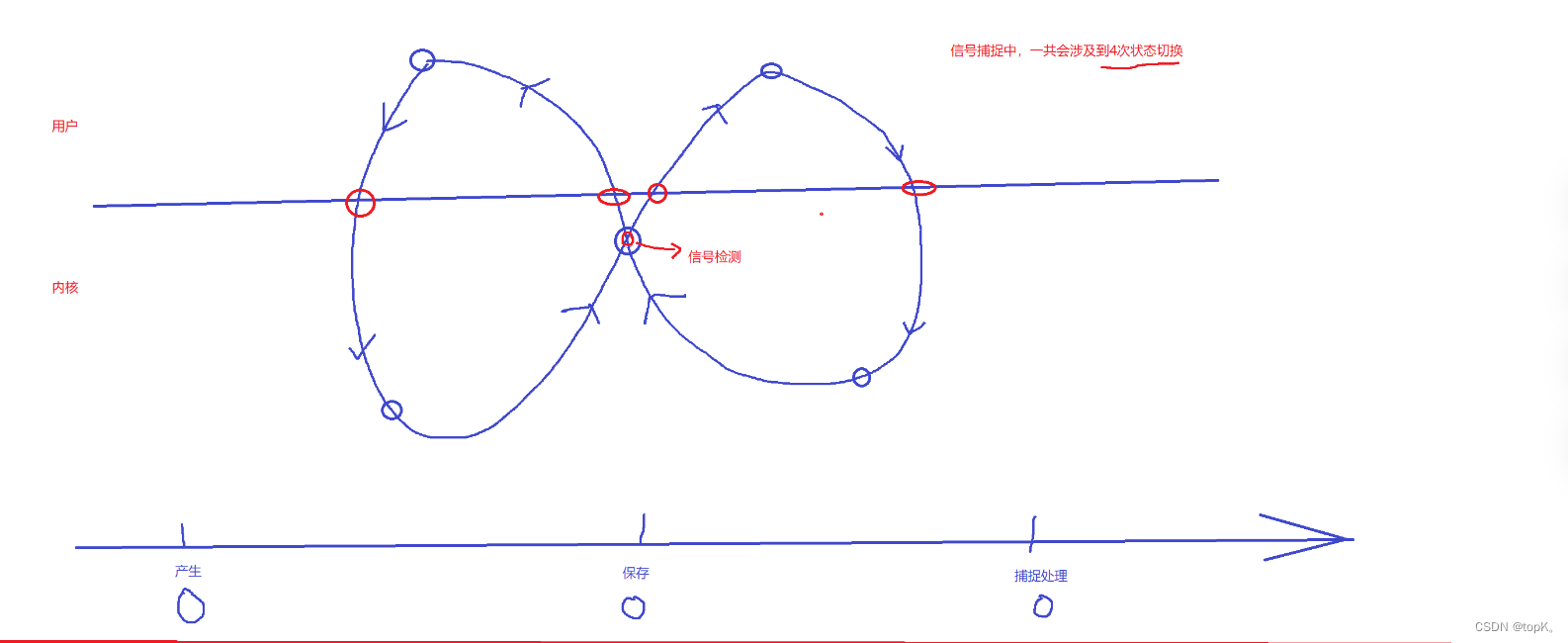
【Linux从青铜到王者】进程信号
——————————————————————————————————————————— 信号入门 在了解信号之前有许多要理解的相关概念 我们可以先通过一个生活例子来初步认识一下信号 1.生活角度的信号 你在网上买了很多件商品,再等待不同商品快递的到来…...
MyBatis-Plus 快速入门
介绍 jMyBatis-Plus (opens new window)(简称 MP)是一个 MyBatis (opens new window)的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。 官网:MyBatis-Plus (baomidou.com) 1.…...
iOS调起高德/百度/腾讯/谷歌/苹果地图并使用GCJ02坐标进行导航
使用演示: 2.地图API相关网站 : 高德:...
HarmonyOS Full SDK的安装
OpenHarmony的应用开发工具HUAWEI DevEco Studio现在随着OpenHarmony版本发布而发布,只能在版本发布说明中下载,例如最新版本的OpenHarmony 4.0 Release。对应的需要下载DevEco Studio 4.0 Release,如下图。 图片 下载Full SDK主要有两种方式,一种是通过DevEco Studio下载…...

小程序嵌套H5-真机突然无法使用
今天测试反馈了一个问题,测试环境的小程序突然就登录不了了。我自己拿手机扫码登录是正常的,用其他同事的手机扫描登录也是正常。 下面是排查的路线: 1、其他环境使用测试手机扫码登录是否正常?(正常) 2、H5地址改为本地IP&#…...
 浅析)
自然语言处理 | 语言模型(LM) 浅析
自然语言处理(NLP)中的语言模型(Language Model, LM)是一种统计模型,它的目标是计算一个给定文本序列的概率分布,即对于任意给定的一段文本序列(单词序列),语言模型能够估…...

全量知识系统问题及SmartChat给出的答复 之13 解析器+DDD+文法型
Q32. DDD的领域概念和知识系统中设计的解析器之间的关系。 那下面,我们回到前面的问题上来。 前面说到了三种语法解析器,分别是 形式语言的(机器或计算机语言)、人工语言的和自然语言的。再前面,我们聊到了DDD设计思…...
华中某科技大学校园网疑似dns劫持的解决方法
问题 在校园网ping xxx.ddns.net,域名解析失败 使用热点ping xxx.ddns.net,可以ping通 尝试设置windows dns首选dns为114.114.114.114,重新ping,仍然域名解析失败 猜测【校园网可能劫持dns请求】 解决方法 使用加密的dns请求…...

模型部署 - onnx 的导出和分析 -(1) - PyTorch 导出 ONNX - 学习记录
onnx 的导出和分析 一、PyTorch 导出 ONNX 的方法1.1、一个简单的例子 -- 将线性模型转成 onnx1.2、导出多个输出头的模型1.3、导出含有动态维度的模型 二、pytorch 导出 onnx 不成功的时候如何解决2.1、修改 opset 的版本2.2、替换 pytorch 中的算子组合2.3、在 pytorch 登记&…...
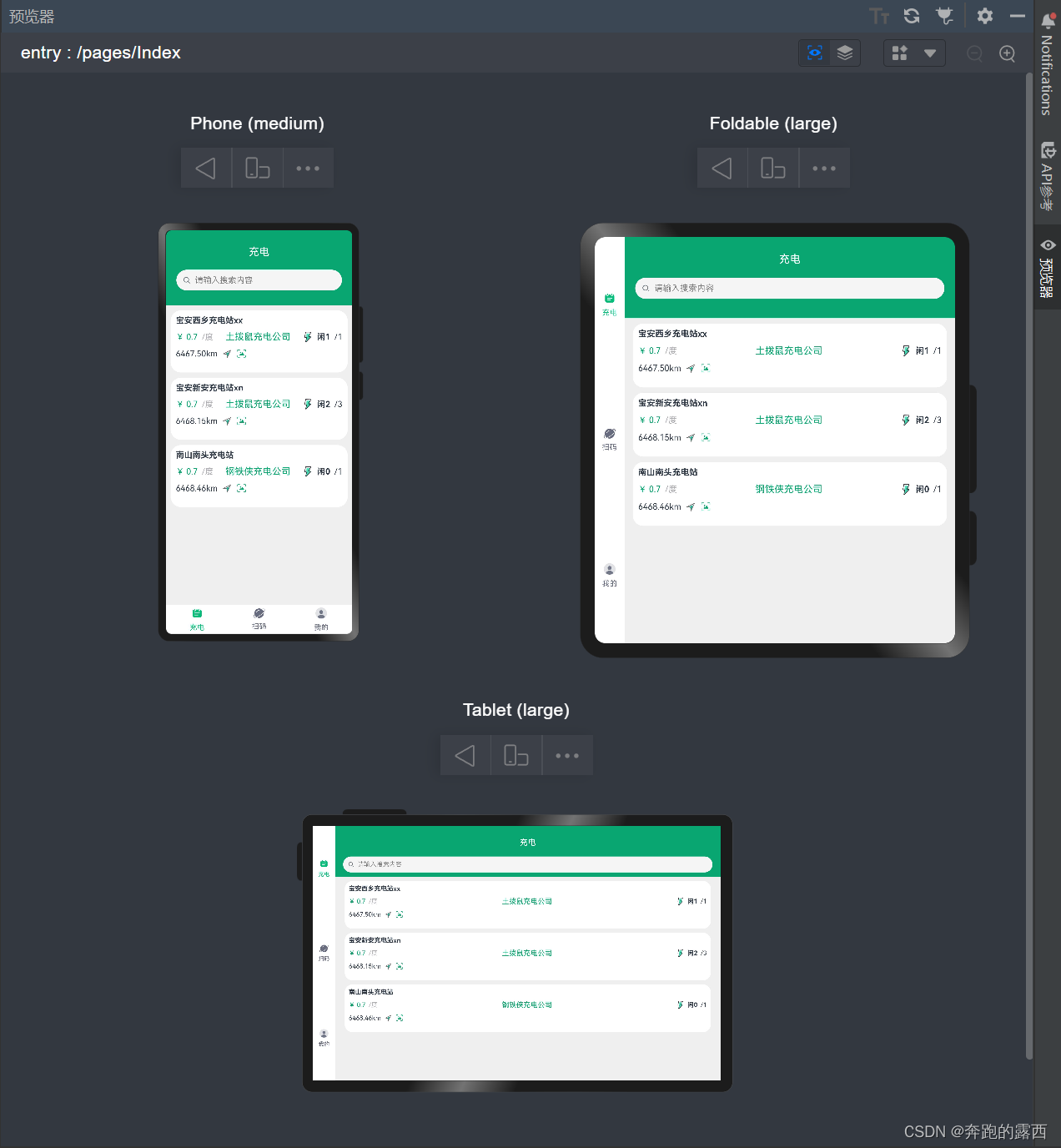
【鸿蒙 HarmonyOS 4.0】多设备响应式布局
一、背景 在渲染页面时,需要根据不同屏幕大小渲染出不同的效果,动态的判断设备屏幕大小,便需要采用多设备响应式布局。这种设计方法能够动态适配各种屏幕大小,确保网站在不同设备上都能呈现出最佳的效果。 二、媒体查询…...

Android ANR 日志分析定位
ANR 是 Android 应用程序中的 "Application Not Responding" 的缩写,中文意思是 "应用程序无响应"。这是当应用程序在 Android 系统上运行时,由于某种原因不能及时响应用户输入事件或执行一个操作,导致界面无法更新&…...

Optional 详解
Optional 详解 1、Optional 介绍2、创建 Optional 对象3、Optional 常用方法1. 判断值是否存在 — isPresent()2. 非空表达式 — ifPresent()3. 设置(获取)默认值 — orElse()、orElseGet()4. 获取值 — get()5. 过滤值 — filter()6. 转换值 — map() 作为一名 Java 程序员&am…...
数据库基础知识)
(科目三)数据库基础知识
1、基本概念 1.1 数据库 1、数据、信息和数据处理 数据是指表达信息的某种物理符号; 信息是对客观事物的反映,是为某一特定目的二提供的决策数据; 数据处理是指将数据转换成信息的过程,是对各类型的数据进行收集、整理、存储、…...
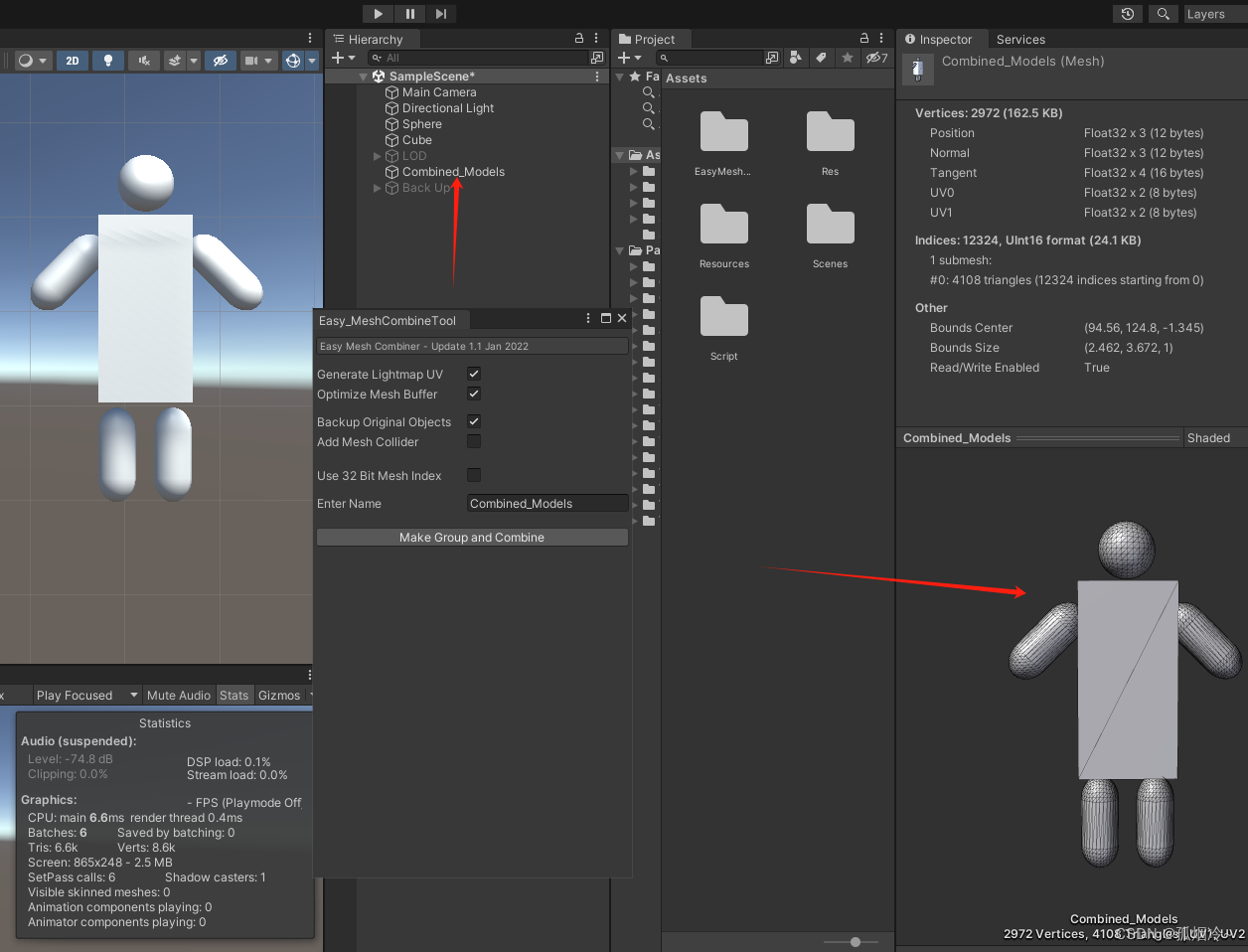
Unity性能优化篇(十) 模型优化之网格合并 Easy Mesh Combine Tool插件使用以及代码实现网格合并
把多个模型的网格合并为一个网格。可以使用自己写代码,使用Unity自带的CombineMeshes方法,也可以使用资源商店的插件,在资源商店搜Mesh Combine可以搜索到相关的插件,例如Easy Mesh Combine Tool等插件。 可大幅度减少Batches数量…...

okbiye 实测:本科生如何用 AI 搞定毕业论文全流程,从选题到格式一步到位
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 引言:当本科论文撞上 “时间焦虑”,你需要的不是 “文字裁缝” 凌晨三点的宿舍,电脑屏幕的蓝光映着你通…...
)
Midjourney团队协作功能深度解析(仅限Beta内测成员验证的7层工作流架构)
更多请点击: https://kaifayun.com 第一章:Midjourney团队协作功能的演进逻辑与Beta内测准入机制 Midjourney自V5.2起将协作能力从“单用户提示工程”转向“多角色协同创作范式”,其核心演进逻辑围绕权限粒度、上下文继承性与资产归属治理三…...

上机器人真能省人吗,先看这几个车间实情
就以我自己的视角,给同样想推动自动化改造的工厂管理者们,聊聊这里面的门道和实在账。很多人问我,你们做自动化集成的是不是就爱忽悠老板砸钱上机器人?听着光鲜,最后落灰的“铁疙瘩”我见得多了。我是自动化老厂的二代…...

量子变分算法优化:ADAPT-VQE与ASC协同技术解析
1. 量子变分算法优化背景与挑战 量子变分特征求解器(VQE)作为当前量子计算化学模拟的核心算法,其核心思想是通过参数化量子电路(PQC)制备试探波函数,并利用经典优化器调整参数以逼近目标哈密顿量的基态能量…...

彻底告别iPhone过热降频!thermalmonitordDisabler让你的设备性能满血释放
彻底告别iPhone过热降频!thermalmonitordDisabler让你的设备性能满血释放 【免费下载链接】thermalmonitordDisabler A tool used to disable iOS daemons. 项目地址: https://gitcode.com/gh_mirrors/th/thermalmonitordDisabler 你是否曾经在游戏激战中突然…...

fpga开发过程中遇到的一些小问题
vivado开发过程中的一些error1、[Chipscope 16-213] The debug port u_ila_0/probe13 has 28 unconnected channels (bits). This will cause errors during implementation.2、ERROR: [Labtools 27-3312] Data read from hw_ila [hw_ila_1] is corrupted. Unable to upload wa…...

RISC-V RTOS移植:RT-Thread首个任务启动与上下文切换详解
1. 项目概述与核心思路今天咱们接着聊RISC-V内核单片机上移植RTOS那点事儿。之前两篇把基础环境、任务栈和上下文切换的坑都踩了一遍,这篇算是整个移植过程的“临门一脚”——怎么让CPU从初始化代码里跳出来,稳稳当当地跑起第一个用户任务。这事儿听起来…...

3步打造专业网络视频系统:DistroAV NDI插件完全指南
3步打造专业网络视频系统:DistroAV NDI插件完全指南 【免费下载链接】obs-ndi DistroAV (formerly OBS-NDI): NDI integration for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-ndi 你是否还在为复杂的视频线缆而烦恼?或者为多设…...

三极管Ube到底变不变?从静态分析到动态放大,一张图帮你彻底搞懂
三极管Ube到底变不变?从静态分析到动态放大,一张图帮你彻底搞懂 刚接触三极管放大电路时,很多初学者都会被一个看似矛盾的现象困扰:教科书告诉我们三极管的Ube电压恒定为0.7V,但在分析动态放大过程时,又说U…...

用VSCode+ESP-IDF给机器人装“关节”:PCA9685驱动16路舵机保姆级配置流程
用VSCodeESP-IDF给机器人装“关节”:PCA9685驱动16路舵机保姆级配置流程 在机器人开发中,精确控制多个舵机是实现复杂动作的基础。想象一下,一个六足机器人需要协调18个关节的运动,或者一个机械臂要完成精准抓取动作——这些场景都…...