基于OpenCV的图形分析辨认02
目录
一、前言
二、实验目的
三、实验内容
四、实验过程
一、前言
编程语言:Python,编程软件:vscode或pycharm,必备的第三方库:OpenCV,numpy,matplotlib,os等等。
关于OpenCV,numpy,matplotlib,os等第三方库的下载方式如下:
第一步,按住【Windows】和【R】调出运行界面,输入【cmd】,回车打开命令行。
第二步,输入以下安装命令(可以先升级一下pip指令)。
pip升级指令:
python -m pip install --upgrade pip
opencv库的清华源下载:
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
numpy库的清华源下载:
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
matplotlib库的清华源下载:
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
os库的清华源下载:
pip install os -i https://pypi.tuna.tsinghua.edu.cn/simple
二、实验目的
1.了解不同图像缩放算法;
2.基于公用图像处理函式库完成图片、视频缩小及放大;
3.根据图像缩放算法,自行撰写代码完成图像及视频数据的缩小及放大;
4.比较及分析公用函式库及自行撰写函式的效能。
三、实验内容
1.任选彩色图片、视频,进行缩小及放大
(1)使用OpenCV函数
(2)不使用OpenCV函数
- Nearest-Neighbor interpolation
- Bi-linear interpolation
2.在彩色图、视频上任意选取区域執行不同的放大方式,结果如下图
(1)使用OpenCV函数
(2)不使用OpenCV函数
- Nearest-Neighbor interpolation
- Bi-linear interpolation
四、实验过程
(1)基于OpenCV的图像和视频缩放:
图像代码如下:
import cv2
import matplotlib.pyplot as plt# 读取原始图像
img_origin = cv2.imread(r"D:\Image\img1.jpg")
# 获取图像的高度和宽度
height, width = img_origin.shape[:2]
# 放大图像
img_amplify = cv2.resize(img_origin, None, fx = 1.25, fy = 1.0, interpolation = cv2.INTER_AREA)
# 缩小图像
img_reduce = cv2.resize(img_origin, None, fx = 0.75, fy = 1.0, interpolation = cv2.INTER_AREA)# 创建一个大小为(10, 10)的图形
plt.figure(figsize=(10, 10))
# 在第1行第1列的位置创建子图,设置坐标轴可见,设置标题为"origin"
plt.subplot(1, 3, 1), plt.axis('on'), plt.title("origin")
# 显示原始图像
plt.imshow(cv2.cvtColor(img_origin, cv2.COLOR_BGR2RGB))# 在第1行第2列的位置创建子图,设置坐标轴可见,设置标题为"amplify: fx = 1.25, fy = 1.0"
plt.subplot(1, 3, 2), plt.axis('on'), plt.title("amplify: fx = 1.25, fy = 1.0")
# 显示放大后的图像
plt.imshow(cv2.cvtColor(img_amplify, cv2.COLOR_BGR2RGB))# 在第1行第3列的位置创建子图,设置坐标轴可见,设置标题为"reduce: fx = 0.75, fy = 1.0"
plt.subplot(1, 3, 3), plt.axis('on'), plt.title("reduce: fx = 0.75, fy = 1.0")
# 显示缩小后的图像
plt.imshow(cv2.cvtColor(img_reduce, cv2.COLOR_BGR2RGB))# 调整子图布局
plt.tight_layout()
# 显示图形
plt.show()
# 保存图像
retval = cv2.imwrite(r"D:\Image\image_lab2\img_amplify.jpg", img_amplify)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_reduce.jpg", img_reduce)代码运行结果:

视频代码如下:
import cv2
import oscap = cv2.VideoCapture(r"D:\Image\video1.mp4")
currentframe = 0# 循环读取视频帧并保存为图片
while (True):ret, frame = cap.read()if ret:name = str(currentframe)cv2.imwrite(r"D:\Image\image_lab2\video_img\%s.jpg"%name, frame)currentframe += 1else:break# 释放视频对象
cap.release()video_path = r"D:\Image\image_lab2\video_img"
# 获取视频文件夹中的所有文件
img_files = os.listdir(video_path)
# 统计图片文件数量
img_count = len(img_files)
# 设定视频编解码器
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# 设定图片大小放大后的目标尺寸
img_size_amplify = (1280, 1280)
# 设定图片大小缩小后的目标尺寸
img_size_reduce = (720, 720)
# 视频保存路径(放大版本)
video_save_amplify = r"D:\Image\image_lab2\video_amplify.mp4"
# 视频保存路径(缩小版本)
video_save_reduce = r"D:\Image\image_lab2\video_reduce.mp4"
# 创建放大版本的视频写入对象
video_writer_amplify = cv2.VideoWriter(video_save_amplify, fourcc, 60, img_size_amplify)
# 创建缩小版本的视频写入对象
video_writer_reduce = cv2.VideoWriter(video_save_reduce, fourcc, 60, img_size_reduce)
print("视频放大及缩小开始")for i in range(0, img_count):# 设定图片文件路径img_path = video_path + "/" + str(i) + ".jpg"# 读取图片img = cv2.imread(img_path, cv2.IMREAD_COLOR)# 若读取失败则跳过本次循环if img is None:continue# 图片放大img_amplify = cv2.resize(img, img_size_amplify)# 图片缩小img_reduce = cv2.resize(img, img_size_reduce)# 将放大后的图片写入放大版本的视频video_writer_amplify.write(img_amplify)# 将缩小后的图片写入缩小版本的视频video_writer_reduce.write(img_reduce)print(f"第{i}张图片合成完成")print("视频放大及缩小完成")基于最近邻插值和双线性插值的图像和视频缩放:
将最近邻插值和双线性插值编写成函数文件,命名为【Nearest_Bilinear】,代码如下:
import numpy as npdef Nearest(img, height, width, channels):# 创建一个与给定高度、宽度和通道数相同的零数组img_nearest = np.zeros(shape=(height, width, channels), dtype=np.uint8)# 遍历每个像素点for i in range(height):for j in range(width):# 计算在给定高度和宽度下对应的img的行和列row = (i / height) * img.shape[0]col = (j / width) * img.shape[1]# 取最近的整数行和列row_near = round(row)col_near = round(col)# 如果行或列到达img的边界,则向前取整if row_near == img.shape[0] or col_near == img.shape[1]:row_near -= 1col_near -= 1# 将最近的像素赋值给img_nearestimg_nearest[i][j] = img[row_near][col_near]# 返回最近映射后的图像return img_nearestdef Bilinear(img, height, width, channels):# 生成一个用于存储bilinear插值结果的零矩阵img_bilinear = np.zeros(shape=(height, width, channels), dtype=np.uint8)# 对矩阵的每一个元素进行插值计算for i in range(0, height):for j in range(0, width):# 计算当前元素所在的行和列的相对位置row = (i / height) * img.shape[0]col = (j / width) * img.shape[1]row_int = int(row)col_int = int(col)# 计算当前元素所在点的权重u = row - row_intv = col - col_int# 判断当前元素是否越界,若是则调整相对位置if row_int == img.shape[0] - 1 or col_int == img.shape[1] - 1:row_int -= 1col_int -= 1# 根据权重进行插值计算img_bilinear[i][j] = (1 - u) * (1 - v) * img[row_int][col_int] + (1 - u) * v * img[row_int][col_int + 1] + u * (1 - v) * img[row_int + 1][col_int] + u * v * img[row_int + 1][col_int + 1]# 返回bilinear插值结果return img_bilinear后续在实现图像放缩时导入该函数即可,图像放缩代码如下:
import cv2
import matplotlib.pyplot as plt
from Nearest_Bilinear import *# 读取图像
img = cv2.imread(r"D:\Image\img1.jpg", cv2.IMREAD_COLOR)
# 获取图像的高度、宽度和通道数
height, width, channels = img.shape
print(height, width, channels)# 对图像进行放大操作,增加200个像素的高度
img_nearest_amplify = Nearest(img, height + 200, width, channels)
# 对图像进行缩小操作,减少200个像素的高度
img_nearest_reduce = Nearest(img, height - 200, width, channels)# 创建一个大小为10x10的图像窗口
plt.figure(figsize=(10, 10))
# 在第一个子图中显示原始图像
plt.subplot(1, 3, 1), plt.axis('on'), plt.title("origin")
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# 在第二个子图中显示放大后的图像
plt.subplot(1, 3, 2), plt.axis('on'), plt.title("Nearest_amplify")
plt.imshow(cv2.cvtColor(img_nearest_amplify, cv2.COLOR_BGR2RGB))
# 在第三个子图中显示缩小后的图像
plt.subplot(1, 3, 3), plt.axis('on'), plt.title("Nearest_reduce")
plt.imshow(cv2.cvtColor(img_nearest_reduce, cv2.COLOR_BGR2RGB))
plt.tight_layout()
plt.show()# 对图像进行放大操作,增加200个像素的高度
img_bilinear_amplify = Bilinear(img, height + 200, width, channels)
# 对图像进行缩小操作,减少200个像素的高度
img_bilinear_reduce = Bilinear(img, height - 200, width, channels)# 创建一个大小为10x10的图像窗口
plt.figure(figsize=(10, 10))
# 在第一个子图中显示原始图像
plt.subplot(1, 3, 1), plt.axis('on'), plt.title("origin")
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# 在第二个子图中显示放大后的图像
plt.subplot(1, 3, 2), plt.axis('on'), plt.title("Bilinear_amplify")
plt.imshow(cv2.cvtColor(img_bilinear_amplify, cv2.COLOR_BGR2RGB))
# 在第三个子图中显示缩小后的图像
plt.subplot(1, 3, 3), plt.axis('on'), plt.title("Bilinear_reduce")
plt.imshow(cv2.cvtColor(img_bilinear_reduce, cv2.COLOR_BGR2RGB))
plt.tight_layout()
plt.show()# 保存图像
retval = cv2.imwrite(r"D:\Image\image_lab2\img_nearest_amplify.jpg", img_nearest_amplify)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_nearest_reduce.jpg", img_nearest_reduce)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_bilinear_amplify.jpg", img_bilinear_amplify)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_bilinear_reduce.jpg", img_bilinear_reduce)代码运行结果如下:
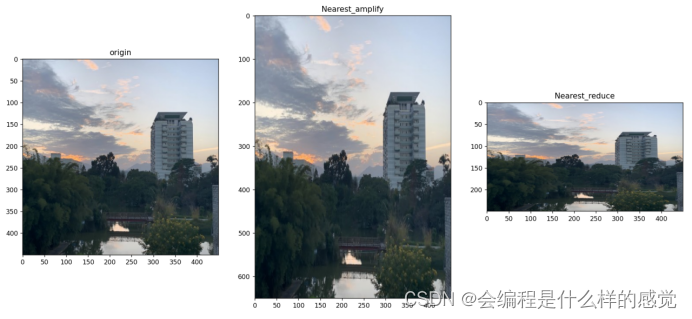

基于最近邻插值的视频缩放代码:
import cv2
import os
from Nearest_Bilinear import *video_path = r"D:\Image\image_lab2\video_img"
# 获取视频文件夹中的所有文件
img_files = os.listdir(video_path)
# 统计图片文件数量
img_count = len(img_files)
# 设定视频编解码器
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# 设定图片大小放大后的目标尺寸
img_size_amplify = (1280, 1280)
# 设定图片大小缩小后的目标尺寸
img_size_reduce = (720, 720)
# 视频保存路径(放大版本)
video_save_amplify = r"D:\Image\image_lab2\video_amplify_Nearest.mp4"
# 视频保存路径(缩小版本)
video_save_reduce = r"D:\Image\image_lab2\video_reduce_Nearest.mp4"
# 创建放大版本的视频写入对象
video_writer_amplify = cv2.VideoWriter(video_save_amplify, fourcc, 60, img_size_amplify)
# 创建缩小版本的视频写入对象
video_writer_reduce = cv2.VideoWriter(video_save_reduce, fourcc, 60, img_size_reduce)
print("视频放大及缩小开始")for i in range(0, img_count):# 设定图片文件路径img_path = video_path + "/" + str(i) + ".jpg"# 读取图片img = cv2.imread(img_path, cv2.IMREAD_COLOR)# 若读取失败则跳过本次循环if img is None:continue# 图片放大img_amplify = Nearest(img, img_size_amplify[0], img_size_amplify[1], 3)# 图片缩小img_reduce = Nearest(img, img_size_reduce[0], img_size_reduce[1], 3)# 将放大后的图片写入放大版本的视频video_writer_amplify.write(img_amplify)# 将缩小后的图片写入缩小版本的视频video_writer_reduce.write(img_reduce)print(f"第{i}张图片合成完成")print("视频放大及缩小完成")基于双线性插值的视频放缩代码:
import cv2
import os
from Nearest_Bilinear import *video_path = r"D:\Image\image_lab2\video_img"
# 获取视频文件夹中的所有文件
img_files = os.listdir(video_path)
# 统计图片文件数量
img_count = len(img_files)
# 设定视频编解码器
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# 设定图片大小放大后的目标尺寸
img_size_amplify = (1280, 1280)
# 设定图片大小缩小后的目标尺寸
img_size_reduce = (720, 720)
# 视频保存路径(放大版本)
video_save_amplify = r"D:\Image\image_lab2\video_amplify_Bilinear.mp4"
# 视频保存路径(缩小版本)
video_save_reduce = r"D:\Image\image_lab2\video_reduce_Bilinear.mp4"
# 创建放大版本的视频写入对象
video_writer_amplify = cv2.VideoWriter(video_save_amplify, fourcc, 60, img_size_amplify)
# 创建缩小版本的视频写入对象
video_writer_reduce = cv2.VideoWriter(video_save_reduce, fourcc, 60, img_size_reduce)
print("视频放大及缩小开始")for i in range(0, img_count):# 设定图片文件路径img_path = video_path + "/" + str(i) + ".jpg"# 读取图片img = cv2.imread(img_path, cv2.IMREAD_COLOR)# 若读取失败则跳过本次循环if img is None:continue# 图片放大img_amplify = Bilinear(img, img_size_amplify[0], img_size_amplify[1], 3)# 图片缩小img_reduce = Bilinear(img, img_size_reduce[0], img_size_reduce[1], 3)# 将放大后的图片写入放大版本的视频video_writer_amplify.write(img_amplify)# 将缩小后的图片写入缩小版本的视频video_writer_reduce.write(img_reduce)print(f"第{i}张图片合成完成")print("视频放大及缩小完成")(2)基于OpenCV的局部图像和视频缩放
局部图像的缩放代码如下:
import cv2
import matplotlib.pyplot as plt# 读取原始图像
img_origin = cv2.imread(r"D:\Image\img1.jpg", cv2.IMREAD_COLOR)
# 获取图像的高度和宽度
height, width = img_origin.shape[:2]
# 定义图像的一部分的坐标范围
y1, y2 = 100, 300
x1, x2 = 100, 300
# 获取图像的一部分
img_part = img_origin[y1:y2, x1:x2]
# 放大图像
img_amplify = cv2.resize(img_part, None, fx=1.25, fy=1.0, interpolation=cv2.INTER_NEAREST)
# 缩小图像
img_reduce = cv2.resize(img_part, None, fx=0.75, fy=1.0, interpolation=cv2.INTER_LINEAR)
# 创建绘图窗口
plt.figure(figsize=(10, 10))
# 绘制图像
plt.subplot(2, 2, 1), plt.axis('on'), plt.title("origin")
plt.imshow(cv2.cvtColor(img_origin, cv2.COLOR_BGR2RGB))
plt.subplot(2, 2, 2), plt.axis('on'), plt.title("part")
plt.imshow(cv2.cvtColor(img_part, cv2.COLOR_BGR2RGB))
plt.subplot(2, 2, 3), plt.axis('on'), plt.title("amplify: fx = 1.25, fy = 1.0")
plt.imshow(cv2.cvtColor(img_amplify, cv2.COLOR_BGR2RGB))
plt.subplot(2, 2, 4), plt.axis('on'), plt.title("reduce: fx = 0.75, fy = 1.0")
plt.imshow(cv2.cvtColor(img_reduce, cv2.COLOR_BGR2RGB))# 调整子图布局
plt.tight_layout()
# 显示图形
plt.show()# 保存图像
retval = cv2.imwrite(r"D:\Image\image_lab2\img_part.jpg", img_part)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_amplify_part.jpg", img_amplify)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_reduce_part.jpg", img_reduce)
局部视频的缩放代码如下:
import cv2
import osvideo_path = r"D:\Image\image_lab2\video_img"
# 获取视频文件夹中的所有文件
img_files = os.listdir(video_path)
# 统计图片文件数量
img_count = len(img_files)
# 设定视频编解码器
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# 设定图片大小放大后的目标尺寸
img_size_amplify = (720, 720)
# 设定图片大小缩小后的目标尺寸
img_size_reduce = (250, 250)
# 视频保存路径(放大版本)
video_save_amplify = r"D:\Image\image_lab2\video_amplify_part.mp4"
# 视频保存路径(缩小版本)
video_save_reduce = r"D:\Image\image_lab2\video_reduce_part.mp4"
# 创建放大版本的视频写入对象
video_writer_amplify = cv2.VideoWriter(video_save_amplify, fourcc, 60, img_size_amplify)
# 创建缩小版本的视频写入对象
video_writer_reduce = cv2.VideoWriter(video_save_reduce, fourcc, 60, img_size_reduce)
print("视频放大及缩小开始")for i in range(0, img_count):# 设定图片文件路径img_path = video_path + "/" + str(i) + ".jpg"# 读取图片img = cv2.imread(img_path, cv2.IMREAD_COLOR)img = img[100:500, 100:500]# 若读取失败则跳过本次循环if img is None:continue# 图片放大img_amplify = cv2.resize(img, img_size_amplify)# 图片缩小img_reduce = cv2.resize(img, img_size_reduce)# 将放大后的图片写入放大版本的视频video_writer_amplify.write(img_amplify)# 将缩小后的图片写入缩小版本的视频video_writer_reduce.write(img_reduce)print(f"第{i}张图片合成完成")print("视频放大及缩小完成")基于最近邻插值和双线性插值的局部图像和视频缩放:
局部图像的缩放代码如下:
import cv2
import matplotlib.pyplot as plt
from Nearest_Bilinear import *# 读取图像
img = cv2.imread(r"D:\Image\img1.jpg", cv2.IMREAD_COLOR)
# 获取图像的高度、宽度和通道数
height, width, channels = img.shape
# 定义图像的一部分的坐标范围
y1, y2 = 100, 300
x1, x2 = 100, 300
# 获取图像的一部分
img_part = img[y1:y2, x1:x2]# 对图像进行放大操作,增加100个像素的高度
img_nearest_amplify_part = Nearest(img_part, height + 100, width, channels)
# 对图像进行缩小操作,减少100个像素的高度
img_nearest_reduce_part = Nearest(img_part, height - 100, width, channels)
# 创建一个大小为10x10的图像窗口
plt.figure(figsize=(10, 10))
# 在第一个子图中显示原始图像
plt.subplot(1, 3, 1), plt.axis('on'), plt.title("origin")
plt.imshow(cv2.cvtColor(img_part, cv2.COLOR_BGR2RGB))
# 在第二个子图中显示放大后的图像
plt.subplot(1, 3, 2), plt.axis('on'), plt.title("Nearest_amplify")
plt.imshow(cv2.cvtColor(img_nearest_amplify_part, cv2.COLOR_BGR2RGB))
# 在第三个子图中显示缩小后的图像
plt.subplot(1, 3, 3), plt.axis('on'), plt.title("Nearest_reduce")
plt.imshow(cv2.cvtColor(img_nearest_reduce_part, cv2.COLOR_BGR2RGB))
plt.tight_layout()
plt.show()# 对图像进行放大操作,增加100个像素的高度
img_bilinear_amplify_part = Bilinear(img_part, height + 100, width, channels)
# 对图像进行缩小操作,减少100个像素的高度
img_bilinear_reduce_part = Bilinear(img_part, height - 100, width, channels)
# 创建一个大小为10x10的图像窗口
plt.figure(figsize=(10, 10))
# 在第一个子图中显示原始图像
plt.subplot(1, 3, 1), plt.axis('on'), plt.title("origin")
plt.imshow(cv2.cvtColor(img_part, cv2.COLOR_BGR2RGB))
# 在第二个子图中显示放大后的图像
plt.subplot(1, 3, 2), plt.axis('on'), plt.title("Bilinear_amplify")
plt.imshow(cv2.cvtColor(img_bilinear_amplify_part, cv2.COLOR_BGR2RGB))
# 在第三个子图中显示缩小后的图像
plt.subplot(1, 3, 3), plt.axis('on'), plt.title("Bilinear_reduce")
plt.imshow(cv2.cvtColor(img_bilinear_reduce_part, cv2.COLOR_BGR2RGB))
plt.tight_layout()
plt.show()# 保存图像
retval = cv2.imwrite(r"D:\Image\image_lab2\img_nearest_amplify_part.jpg", img_nearest_amplify_part)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_nearest_reduce_part.jpg", img_nearest_reduce_part)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_bilinear_amplify_part.jpg", img_bilinear_amplify_part)
retval = cv2.imwrite(r"D:\Image\image_lab2\img_bilinear_reduce_part.jpg", img_bilinear_reduce_part)
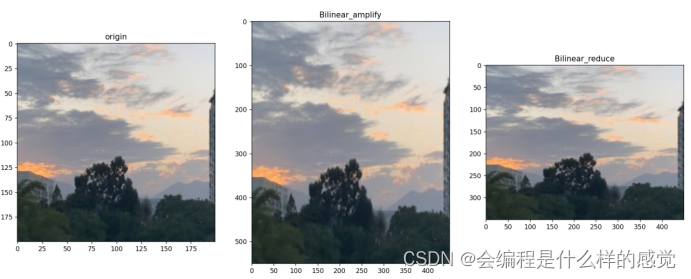
基于最近邻插值的局部视频缩放代码:
import cv2
import os
from Nearest_Bilinear import *video_path = r"D:\Image\image_lab2\video_img"
# 获取视频文件夹中的所有文件
img_files = os.listdir(video_path)
# 统计图片文件数量
img_count = len(img_files)
# 设定视频编解码器
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# 设定图片大小放大后的目标尺寸
img_size_amplify = (720, 720)
# 设定图片大小缩小后的目标尺寸
img_size_reduce = (250, 250)
# 视频保存路径(放大版本)
video_save_amplify = r"D:\Image\image_lab2\video_amplify_Nearest_part.mp4"
# 视频保存路径(缩小版本)
video_save_reduce = r"D:\Image\image_lab2\video_reduce_Nearest_part.mp4"
# 创建放大版本的视频写入对象
video_writer_amplify = cv2.VideoWriter(video_save_amplify, fourcc, 60, img_size_amplify)
# 创建缩小版本的视频写入对象
video_writer_reduce = cv2.VideoWriter(video_save_reduce, fourcc, 60, img_size_reduce)
print("视频放大及缩小开始")for i in range(0, img_count):# 设定图片文件路径img_path = video_path + "/" + str(i) + ".jpg"# 读取图片img = cv2.imread(img_path, cv2.IMREAD_COLOR)img = img[100:500, 100:500]# 若读取失败则跳过本次循环if img is None:continue# 图片放大img_amplify = Nearest(img, img_size_amplify[0], img_size_amplify[1], 3)# 图片缩小img_reduce = Nearest(img, img_size_reduce[0], img_size_reduce[1], 3)# 将放大后的图片写入放大版本的视频video_writer_amplify.write(img_amplify)# 将缩小后的图片写入缩小版本的视频video_writer_reduce.write(img_reduce)print(f"第{i}张图片合成完成")print("视频放大及缩小完成")基于双线性插值的局部视频缩放代码如下:
import cv2
import os
from Nearest_Bilinear import *video_path = r"D:\Image\image_lab2\video_img"
# 获取视频文件夹中的所有文件
img_files = os.listdir(video_path)
# 统计图片文件数量
img_count = len(img_files)
# 设定视频编解码器
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# 设定图片大小放大后的目标尺寸
img_size_amplify = (720, 720)
# 设定图片大小缩小后的目标尺寸
img_size_reduce = (250, 250)
# 视频保存路径(放大版本)
video_save_amplify = r"D:\Image\image_lab2\video_amplify_Bilinear_part.mp4"
# 视频保存路径(缩小版本)
video_save_reduce = r"D:\Image\image_lab2\video_reduce_Bilinear_part.mp4"
# 创建放大版本的视频写入对象
video_writer_amplify = cv2.VideoWriter(video_save_amplify, fourcc, 60, img_size_amplify)
# 创建缩小版本的视频写入对象
video_writer_reduce = cv2.VideoWriter(video_save_reduce, fourcc, 60, img_size_reduce)
print("视频放大及缩小开始")for i in range(0, img_count):# 设定图片文件路径img_path = video_path + "/" + str(i) + ".jpg"# 读取图片img = cv2.imread(img_path, cv2.IMREAD_COLOR)img = img[100:500, 100:500]# 若读取失败则跳过本次循环if img is None:continue# 图片放大img_amplify = Bilinear(img, img_size_amplify[0], img_size_amplify[1], 3)# 图片缩小img_reduce = Bilinear(img, img_size_reduce[0], img_size_reduce[1], 3)# 将放大后的图片写入放大版本的视频video_writer_amplify.write(img_amplify)# 将缩小后的图片写入缩小版本的视频video_writer_reduce.write(img_reduce)print(f"第{i}张图片合成完成")print("视频放大及缩小完成")都看到最后了,不点个赞吗?
相关文章:
基于OpenCV的图形分析辨认02
目录 一、前言 二、实验目的 三、实验内容 四、实验过程 一、前言 编程语言:Python,编程软件:vscode或pycharm,必备的第三方库:OpenCV,numpy,matplotlib,os等等。 关于OpenCV&…...

python基础——基础语法
文章目录 一、基础知识1、字面量2、常用值类型3、注释4、输入输出5、数据类型转换6、其他 二、字符串拓展1、字符串定义2、字符串拼接3、字符串格式化4、格式化精度控制 三、条件/循环语句1、if2、while3、for循环 四、函数1、函数定义2、函数说明文档3、global关键字 五、数据…...
vue3 vue-i18n 多语言
1. 安装 npm install vue-i18n -s 2. 引入main.js import { createI18n } from vue-i18n import messages from ./i18n/index const i18n createI18n({legacy: false,locale: Cookies.get(language) || en_us, // set localefallbackLocale: en_us, // set fallback local…...
二级水平导航菜单栏的实现
1. 这个是本人设计的一带一路的二级水平导航栏HTML代码; 这里最后实现的效果是鼠标悬停在导航栏上面,就会显示下面的4个部分页面,这里只是以评论热 点作为例子,其他的类似; 2.首先要设计DIV,然后利用无…...
和mr.diffs()的区别)
在GitLab Python库中,mr.changes()和mr.diffs()的区别
在GitLab Python库中,mr.changes()和mr.diffs()都用于获取合并请求(Merge Request)中的文件更改信息,但它们之间有一些区别: mr.changes(): mr.changes() 方法返回合并请求中所有文件的更改信息。返回的结果…...

JavaScript | 【讨论】微软早在2022年已经停用ie的今天,js开发还需要考虑ie9以下的情况嘛?
CSDN的C知道机器回复: 在进行JavaScript开发时,通常需要考虑IE9以下的况。尽管IE9以下的浏览器在市场份额上逐渐减少,但仍然有一部分用户在使用这些旧版本的浏览器。为了确保网站或应用在这些浏览器上能够正常运行,以下是一些需要…...
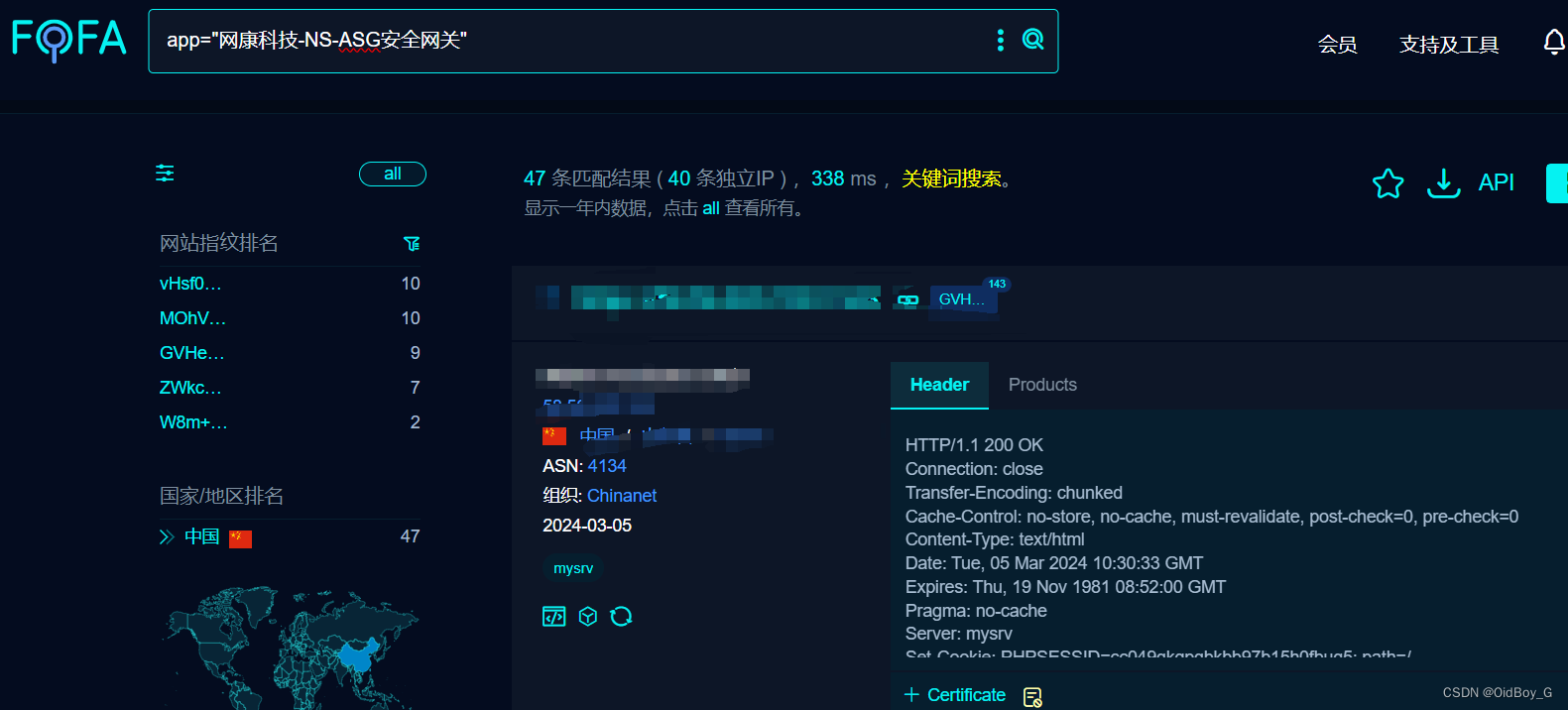
网康科技 NS-ASG 应用安全网关 SQL注入漏洞复现(CVE-2024-2022)
0x01 产品简介 网康科技的NS-ASG应用安全网关是一款软硬件一体化的产品,集成了SSL和IPSec,旨在保障业务访问的安全性,适配所有移动终端,提供多种链路均衡和选择技术,支持多种认证方式灵活组合,以及内置短信认证、LDAP令牌、USB KEY等多达13种认证方式。 0x02 漏洞概述 …...

英福康INFICON软件真空Tware32中文操作手册
英福康INFICON软件真空Tware32中文操作手册...

UnityAPI的学习——Quaternion类
Quaternion又称为四元数,由x、y、z和w这4个分量组成,属于struct类型。 在Unity中,用Quaternion来存储和表示对象的旋转角度。 Quaternion类实例属性 在Quaternion类中,涉及的实例属性主要有eulerAngles eulerAngles属性&#x…...

chromedriverUnable to obtain driver for chrome using ,selenium找不到chromedriver
1、下载chromedriver chromedriver下载网址:CNPM Binaries Mirror 老版本在:chromedriver/ 较新版本在:chrome-for-testing/ 2、设置了环境变量还是找不到chromedriverUnable to obtain driver for chrome using NoSuchDriverException:…...

剑指offer面试算法题目,自己总结的
JZ31 栈的压入、弹出序列-C++-CSDN博客 剑指 Offer(C++版本)系列:从尾到头打印单链表(C++)-CSDN博客 剑指offer》15--二进制中1的个数[C++]-CSDN博客 《剑指offer》14--剪绳子(整数拆分)[C++]-CSDN博客 剑指 Offer 12. 矩阵中的路径-CSDN博客 C++--机器人的运动范围…...
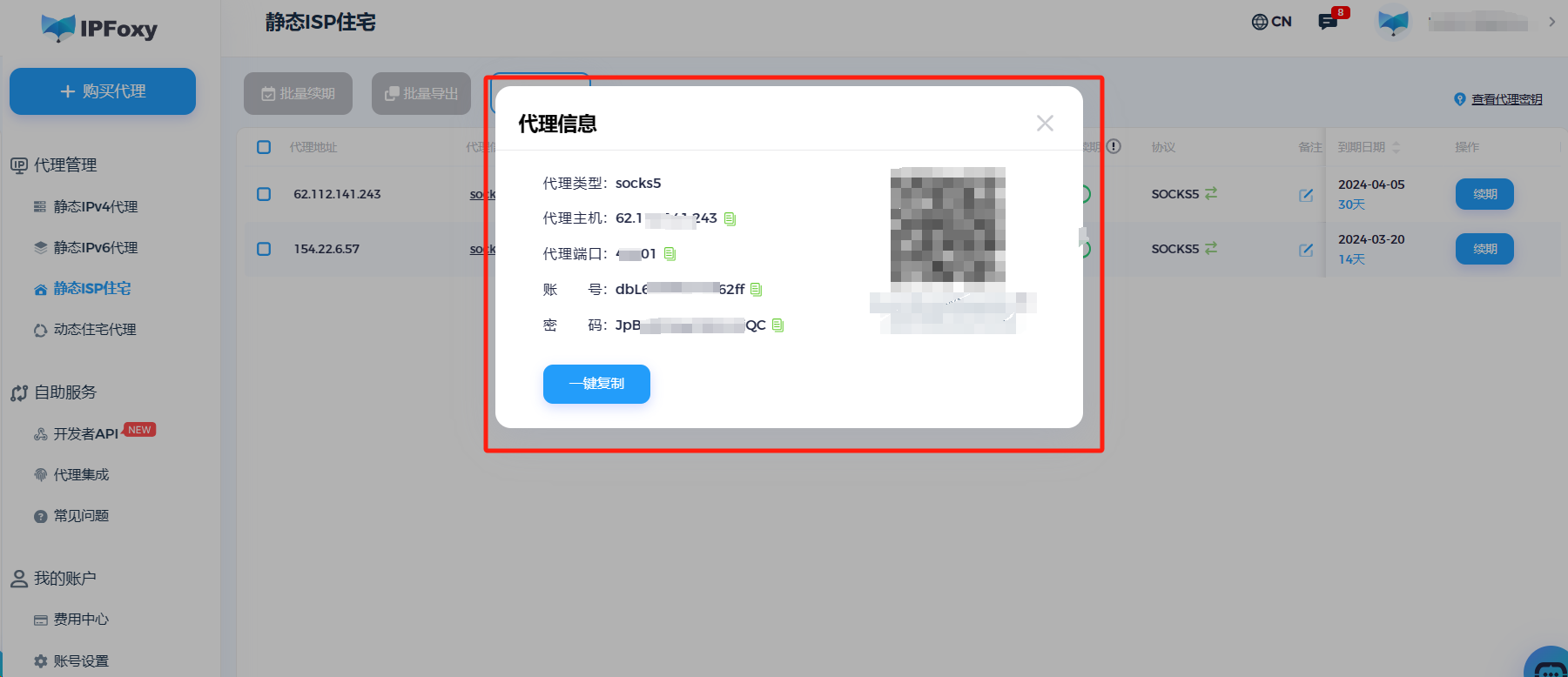
原生IP是什么?如何测试代理是不是原生IP?
一、什么是原生IP 原生IP地址是互联网服务提供商(ISP)直接分配给用户的真实IP地址,无需代理或转发。这类IP的注册国家与IP所在服务器的注册地相符。这种IP地址直接与用户的设备或网络关联,不会被任何中间服务器或代理转发或隐藏。…...
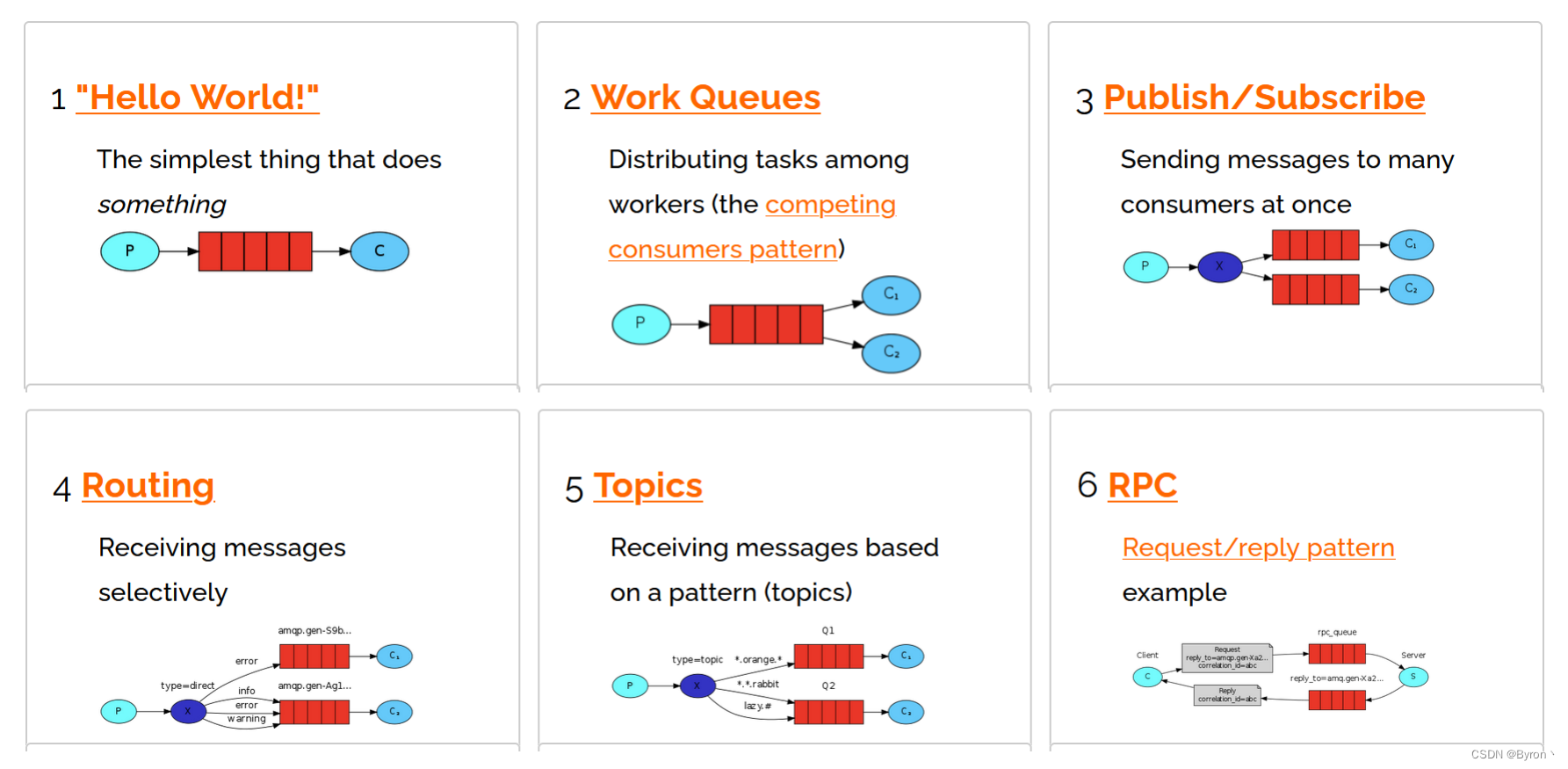
1、MQ_介绍、优缺点、类型等
MQ介绍 1. MQ概述 MQ(Message Queue):消息队列,是基础数据结构中FIFO(first in first out)的一种数据结构。一般用来解决流量削峰、应用解耦、异步处理等问题,实现高性能,高可用&a…...

Go-gin-example 第三部分 编写一个简单的文件日志系统
文章目录 本文目标新建logging包file.go编写log文件当前目录结构 接入自定义的log功能验证功能 本文目标 在上一节中,我们解决了 API’s 可以任意访问的问题,那么我们现在还有一个问题,就是我们的日志,都是输出到控制台上的&…...

SQL中如何添加数据
SQL中如何添加数据 一、SQL中如何添加数据(方法汇总)二、SQL中如何添加数据(方法详细解说)1. 使用SQL脚本(推荐)1.1 在表中插入1.1.1 **第一种形式**1.1.2 **第二种形式**SQL INSERT INTO 语法示例SQL INSE…...

如何更好的理解设计模式之桥接模式
桥接模式 点奶茶的时候, 我们一般选择原味奶茶/牛奶奶茶/咸味奶茶 现在假设我们也有这些已经实现好的奶茶类, 且这个奶茶类仅仅就是一个类, 什么也没有, 不可改动 类似 class 奶茶{ }class 原味奶茶 extends 奶茶{ }但是奶茶也分大杯奶茶, 中杯奶茶, 小杯奶茶, 如果我们要实现…...

归并排序
参考链接 排序算法:归并排序【图解代码】_哔哩哔哩_bilibili #include <stdio.h> #include <stdlib.h>// 合并 void merge(int arr[], int tempArr[], int left, int mid, int right) {// 标记左半区第一个未排序的元素int l_pos left;// 标记右半区…...
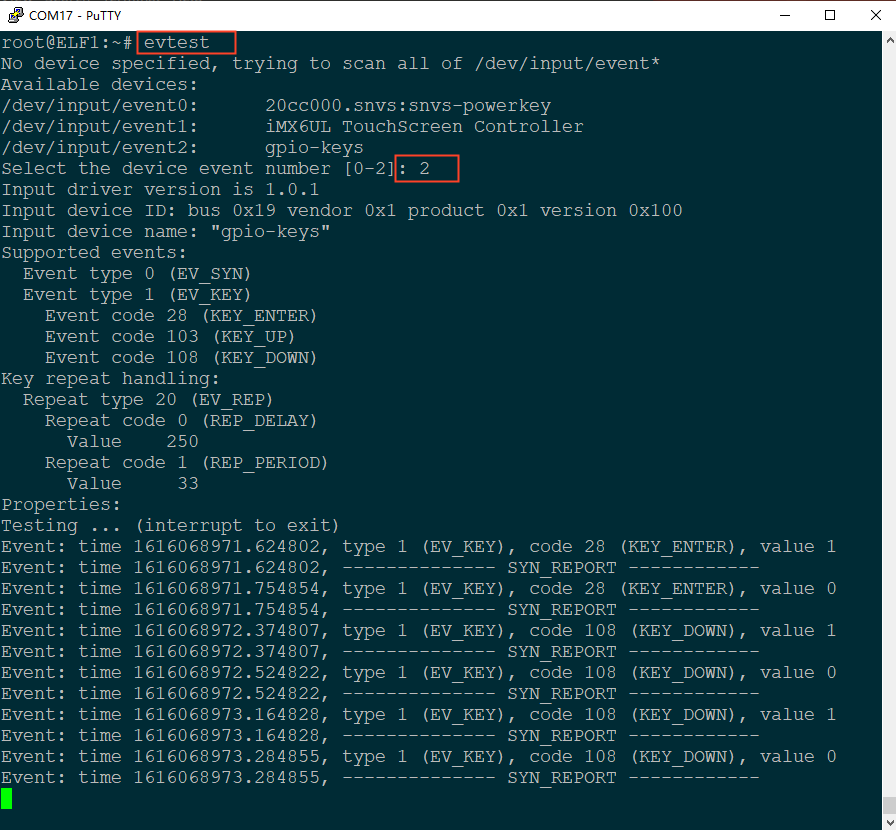
ELF 1技术贴|在NXP源码基础上适配开发板的按键功能
本次源代码适配是在NXP i.MX6ULL EVK评估板的Linux内核源代码(特定版本号为Linux-imx_4.1.15)的基础中展开的。 首要任务集中在对功能接口引脚配置的精细调整,确保其能无缝匹配至ELF 1开发板。接下来,我们将详细阐述适配过程中关…...
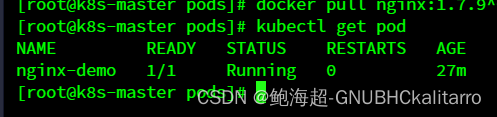
Linux:kubernetes(k8s)pod的基础操作(6)
Linux:kubernetes(k8s)允许在任意节点使用kubectl命令(5)-CSDN博客https://blog.csdn.net/w14768855/article/details/136460090?spm1001.2014.3001.5501 我在前两张进行了基础环境的一系列搭建,现在就正…...

【Docker】掌握 Docker 镜像操作:从基础到进阶
🍎个人博客:个人主页 🏆个人专栏:Linux ⛳️ 功不唐捐,玉汝于成 目录 前言 正文 结语 我的其他博客 前言 在现代软件开发和部署中,容器化技术已经成为不可或缺的一部分。而 Docker 作为最流行的容器化…...

3种高级策略突破AI编辑器限制:Cursor Pro逆向工程技术解析
3种高级策略突破AI编辑器限制:Cursor Pro逆向工程技术解析 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...

G-Helper:华硕笔记本用户的终极轻量级硬件控制方案
G-Helper:华硕笔记本用户的终极轻量级硬件控制方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Exper…...

告别刺耳噪音!ESP32 PWM驱动无源蜂鸣器,从调频到调占空比的音效实战
ESP32音效魔法:PWM驱动无源蜂鸣器的进阶实战指南 从刺耳噪音到悦耳旋律的蜕变之旅 当无源蜂鸣器发出刺耳的"滴滴"声时,很多创客的第一反应是降低音量或缩短发声时间。但真正的解决方案藏在ESP32的PWM(脉冲宽度调制)模块…...

【人工智能】某公司AI落地实践总结
某公司AI落地实践总结 一、AI落地的整体路径框架 某公司的AI落地遵循"认知 → 工具使用 → 流程自动化 → 高阶能力构建 → 场景化落地 → 持续迭代 → 激励驱动"的闭环路径,具体分为四个阶段: 初阶入门(认知筑基):AI基础概念与常用工具,零基础扫盲,掌握提示…...
)
从3D打印机到机械臂:聊聊步进电机选型时,那些容易被忽略的‘动态指标’(附避坑清单)
从3D打印机到机械臂:步进电机选型中那些被低估的动态性能指标 在自动化设备和精密运动控制领域,步进电机因其开环控制特性、高性价比和易于集成的特点,成为3D打印机、CNC机床、机械臂等设备的首选驱动元件。然而,许多工程师在选型…...

5分钟搞定飞书文档转换:这款免费文档转换工具让你效率翻倍!
5分钟搞定飞书文档转换:这款免费文档转换工具让你效率翻倍! 【免费下载链接】cloud-document-converter Convert Lark Doc to Markdown 项目地址: https://gitcode.com/gh_mirrors/cl/cloud-document-converter 还在为飞书文档格式转换而烦恼吗&a…...

scanf/fscanf/sscanf和printf/fprintf/sprintf的对比
目录 摘要: 一:函数的对比 二:函数的使用 1:printf 2:scanf 3:fprintf 4:fscanf 5:sprintf 6:sscanf 摘要: 本博客从函数参数到具体使用过程去对比这…...

Windows Audio服务启动报错‘193 0xc1’?可能是系统文件损坏了,试试这个修复流程
Windows音频服务报错‘193 0xc1’深度修复指南:从原理到实战 当你在Windows系统中遭遇音频服务无法启动,并看到神秘的"193 0xc1"错误代码时,这通常意味着系统核心组件出现了问题。不同于普通的驱动故障,这类错误往往需要…...
)
告别手写代码!用Roboflow的Auto-Orient和Mosaic增强你的YOLO数据集(附完整流程)
零代码实现YOLO数据集增强:Roboflow自动化工具全解析 在目标检测领域,数据质量往往直接决定模型性能上限。传统数据增强方法需要开发者手动编写Python脚本调整图像方向、处理标注格式,不仅耗时耗力,还容易因格式兼容性问题导致训练…...
)
告别死记硬背!用Python+NumPy图解机器学习中的矩阵求导(附常见公式速查表)
告别死记硬背!用PythonNumPy图解机器学习中的矩阵求导(附常见公式速查表) 在机器学习和深度学习的实践中,矩阵求导是理解反向传播、优化算法等核心概念的关键数学工具。然而,传统的数学教材往往以抽象符号和理论推导为…...