Apache Paimon 使用之Creating Catalogs
Paimon Catalog 目前支持两种类型的metastores:
filesystem metastore (default),在文件系统中存储元数据和表文件。
hive metastore,将metadata存储在Hive metastore中。用户可以直接从Hive访问表。
1.使用 Filesystem Metastore 创建 Catalog
Flink引擎
Flink SQL注册并使用名为my_catalog的Paimon catalog,元数据和表文件存储在hdfs:///path/to/warehouse下。
CREATE CATALOG my_catalog WITH ('type' = 'paimon','warehouse' = 'hdfs:///path/to/warehouse'
);USE CATALOG my_catalog;
在 Catalog 中创建的 tables,可以使用前缀table-default.定义任何默认表选项。
Spark3引擎
通过 shell 命令注册一个名为paimon的paimon catalog,元数据和表文件存储在hdfs:///path/to/warehouse下。
spark-sql ... \--conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog \--conf spark.sql.catalog.paimon.warehouse=hdfs:///path/to/warehouse
对于 catalog 中创建的 tables,可以使用前缀spark.sql.catalog.paimon.table-default.定义默认表选项。
spark-sql启动后,使用以下SQL切换到paimon目录的default数据库。
USE paimon.default;
2.使用 Hive Metastore 创建 Catalog
使用Paimon Hive catalog,对 catalog 的更改将直接影响相应的Hive metastore,在此类 catalog 中创建的表可以直接从 Hive 访问。
要使用Hive catalog,数据库名称、表名和字段名均应小写。
Flink 引擎
Flink 中的Paimon Hive catalog依赖于Flink Hive connector bundled jar,首先要下载Hive connector bundled jar,并将其添加到classpath。
以下Flink SQL注册并使用名为my_hive的Paimon Hive catalog,元数据和表文件存储在hdfs:///path/to/warehouse下,元数据也存储在Hive metastore中。
如果Hive需要security authentication,如Kerberos、LDAP、Ranger,或者希望paimon表由Apache Atlas管理(在hive-site.xml中设置"hive.metastore.event.listeners"),可以在hive-site.xml文件路径中指定hive-conf-dir和hadoop-conf-dir参数。
CREATE CATALOG my_hive WITH ('type' = 'paimon','metastore' = 'hive',-- 'uri' = 'thrift://<hive-metastore-host-name>:<port>', default use 'hive.metastore.uris' in HiveConf-- 'hive-conf-dir' = '...', this is recommended in the kerberos environment-- 'hadoop-conf-dir' = '...', this is recommended in the kerberos environment-- 'warehouse' = 'hdfs:///path/to/warehouse', default use 'hive.metastore.warehouse.dir' in HiveConf
);USE CATALOG my_hive;
对于在 catalog 中创建的表,可以使用前缀table-default.定义默认表选项。
此外,还可以创建Flink Generic Catalog。
Spark3引擎
Spark需要包含Hive dependencies。
以下shell命令注册一个名为paimon的Paimon Hive Catalog,元数据和表文件存储在hdfs:///path/to/warehouse下,此外,元数据也存储在Hive metastore中。
spark-sql ... \--conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog \--conf spark.sql.catalog.paimon.warehouse=hdfs:///path/to/warehouse \--conf spark.sql.catalog.paimon.metastore=hive \--conf spark.sql.catalog.paimon.uri=thrift://<hive-metastore-host-name>:<port>
对于 Catalog 中创建的表,可以使用前缀spark.sql.catalog.paimon.table-default.定义默认表选项。
spark-sql启动后,可以使用以下SQL切换到paimon catalog的default数据库。
USE paimon.default;
此外,还可以创建Spark Generic Catalog。
当使用Hive Catalog通过alter table更改不兼容的列类型时,需要配置hive.metastore.disallow.incompatible.col.type.changes=false。
如果使用的是Hive3,请禁用Hive ACID:
hive.strict.managed.tables=false
hive.create.as.insert.only=false
metastore.create.as.acid=false
3.在Properties中设置Location
如果使用的是对象存储,并且不希望paimon表/数据库的location被hive的文件系统访问,这可能会导致诸如“No filesystem for scheme:s3a”之类的错误,可以通过在属性中配置location来设置表/数据库的location-in-properties。
4.同步Partitions到Hive Metastore
默认,Paimon不会将新创建的分区同步到Hive metastore中,用户将在Hive中看到一个未分区的表,Partition push-down将改为通过filter push-down进行。
如果想在Hive中查看分区表,并将新创建的分区同步到Hive metastore中,请将表属性metastore.partitioned-table设置为true。
5.添加参数到Hive Table
使用table option有助于方便地定义Hive表参数,以hive.前缀的参数将在Hive表的TBLPROPERTIES中自动定义。例如,使用hive.table.owner=Jon将在创建过程中自动将表参数table.owner=Jon添加到表属性中。
6.CatalogOptions
| Key | Default | Type | Description |
|---|---|---|---|
| fs.allow-hadoop-fallback | true | Boolean | Allow to fallback to hadoop File IO when no file io found for the scheme. |
| lineage-meta | (none) | String | The lineage meta to store table and data lineage information. Possible values: “jdbc”: Use standard jdbc to store table and data lineage information.“custom”: You can implement LineageMetaFactory and LineageMeta to store lineage information in customized storage. |
| lock-acquire-timeout | 8 min | Duration | The maximum time to wait for acquiring the lock. |
| lock-check-max-sleep | 8 s | Duration | The maximum sleep time when retrying to check the lock. |
| lock.enabled | false | Boolean | Enable Catalog Lock. |
| metastore | “filesystem” | String | Metastore of paimon catalog, supports filesystem and hive. |
| table.type | managed | Enum | Type of table. Possible values:“managed”: Paimon owned table where the entire lifecycle of the table data is managed.“external”: The table where Paimon has loose coupling with the data stored in external locations. |
| uri | (none) | String | Uri of metastore server. |
| warehouse | (none) | String | The warehouse root path of catalog. |
FilesystemCatalogOptions
| Key | Default | Type | Description |
|---|---|---|---|
| case-sensitive | true | Boolean | Is case sensitive. If case insensitive, you need to set this option to false, and the table name and fields be converted to lowercase. |
HiveCatalogOptions
| Key | Default | Type | Description |
|---|---|---|---|
| hadoop-conf-dir | (none) | String | File directory of the core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml. Currently, only local file system paths are supported. If not configured, try to load from ‘HADOOP_CONF_DIR’ or ‘HADOOP_HOME’ system environment. Configure Priority: 1.from ‘hadoop-conf-dir’ 2.from HADOOP_CONF_DIR 3.from HADOOP_HOME/conf 4.HADOOP_HOME/etc/hadoop. |
| hive-conf-dir | (none) | String | File directory of the hive-site.xml , used to create HiveMetastoreClient and security authentication, such as Kerberos, LDAP, Ranger and so on. If not configured, try to load from ‘HIVE_CONF_DIR’ env. |
| location-in-properties | false | Boolean | Setting the location in properties of hive table/database. If you don’t want to access the location by the filesystem of hive when using a object storage such as s3,oss you can set this option to true. |
FlinkCatalogOptions
| Key | Default | Type | Description |
|---|---|---|---|
| default-database | “default” | String | |
| disable-create-table-in-default-db | false | Boolean | If true, creating table in default database is not allowed. Default is false. |
相关文章:

Apache Paimon 使用之Creating Catalogs
Paimon Catalog 目前支持两种类型的metastores: filesystem metastore (default),在文件系统中存储元数据和表文件。 hive metastore,将metadata存储在Hive metastore中。用户可以直接从Hive访问表。 1.使用 Filesystem Metastore 创建 Cat…...

IntelliJ IDEA分支svn
IntelliJ IDEA分支svn 【为何使用分支】 项目开发中经常会遇到这种情况,项目中功能开发完上线后,新的需求又来了,风风火火的在项目里开发, 突然有一天测试说有个很致命的bug需要紧急修改上线,完蛋了,原来…...

.NET Core日志内容详解,详解不同日志级别的区别和有关日志记录的实用工具和第三方库详解与示例
在本文中,我们将详细介绍.NET Core日志内容,包括不同日志级别的区别,以及一些常用的日志记录实用工具和第三方库。同时,我们还将通过示例来展示如何使用这些工具和库。 一、.NET Core日志级别 .NET Core日志系统提供了五种日志级…...
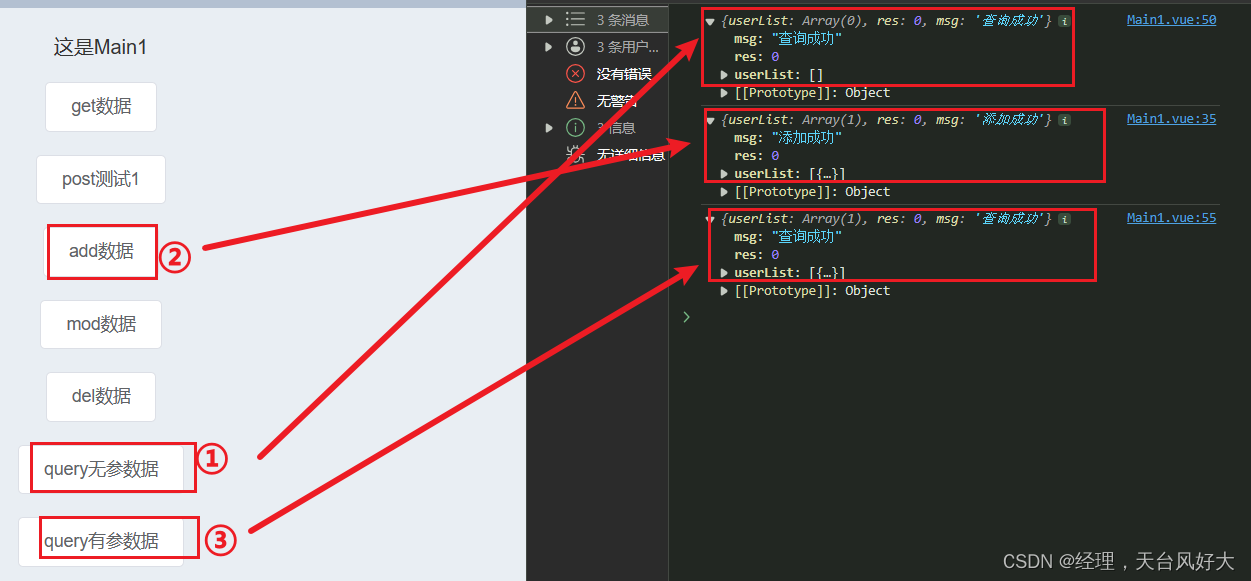
Vue开发实例(七)Axios的安装与使用
说明: 如果只是在前端,axios常常需要结合mockjs使用,如果是前后端分离,就需要调用对应的接口,获取参数,传递参数;由于此文章只涉及前端,所以我们需要结合mockjs使用;由于…...
2024.3.6
作业1:使用C语言完成数据库的增删改 #include <myhead.h>//定义添加员工信息函数 int Add_worker(sqlite3 *ppDb) {//准备sql语句printf("请输入要添加的员工信息:\n");//从终端获取员工信息char rbuf[128]"";fgets(rbuf,sizeof(rbuf),s…...
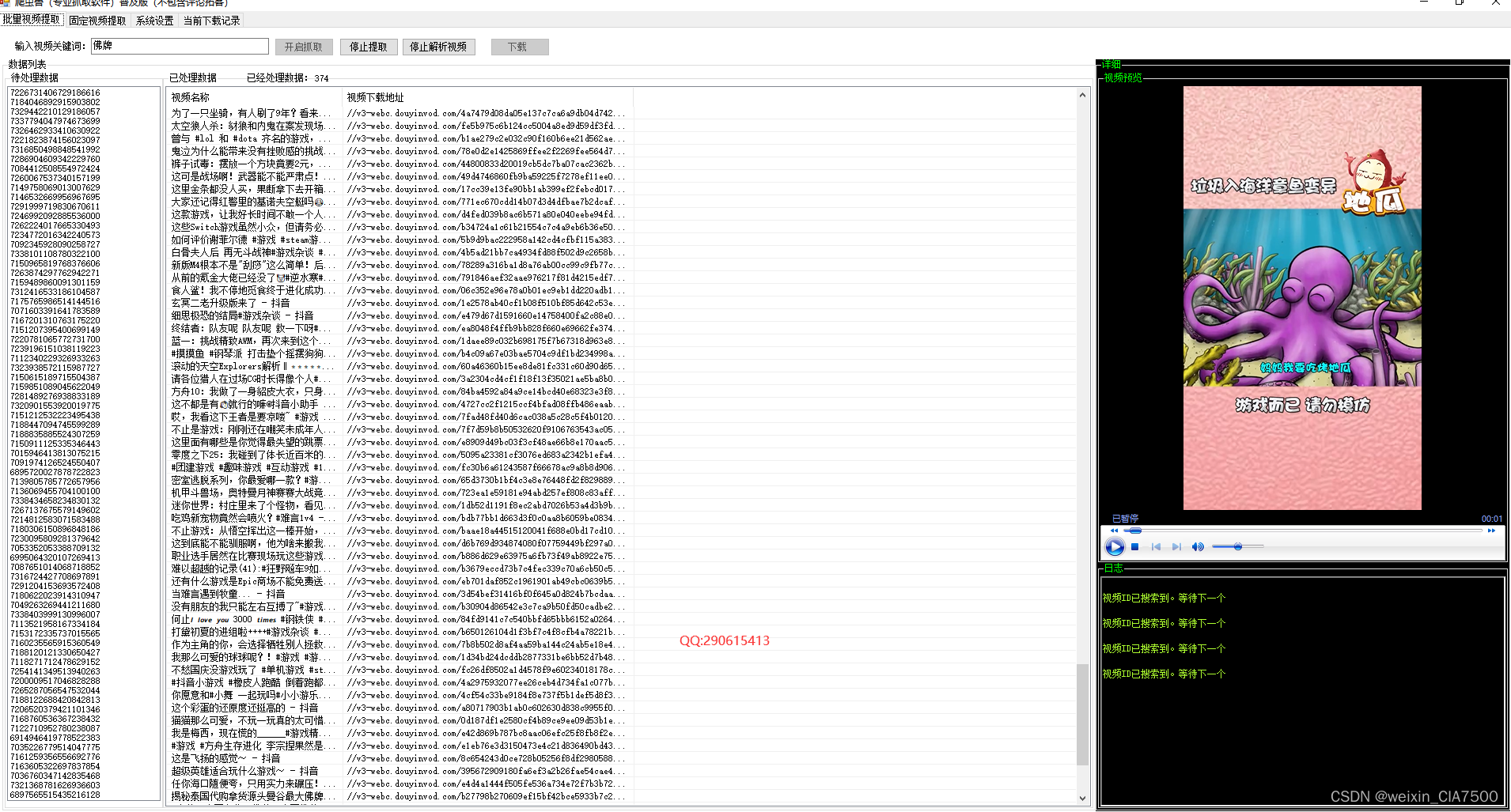
抖音视频批量采集软件|视频评论下载工具
在日常工作中,需要频繁下载抖音视频,但逐个复制分享链接下载效率太低?别担心!我们推出了一款专业的抖音视频批量采集软件,基于C#开发,满足您的需求,让您通过关键词搜索视频并自动批量抓取&#…...

苹果 Vision Pro零售部件成本价格分析
苹果公司发布的全新头戴式显示器 Apple Vision Pro 虽然售价高达3499美元,但其制造成本同样不菲,根据研究机构 Omdia 的估计,该头显仅零部件成本就超过了1500美元。这款头显的总零部件成本估计为1542美元,这还并不包括研发、包装、…...
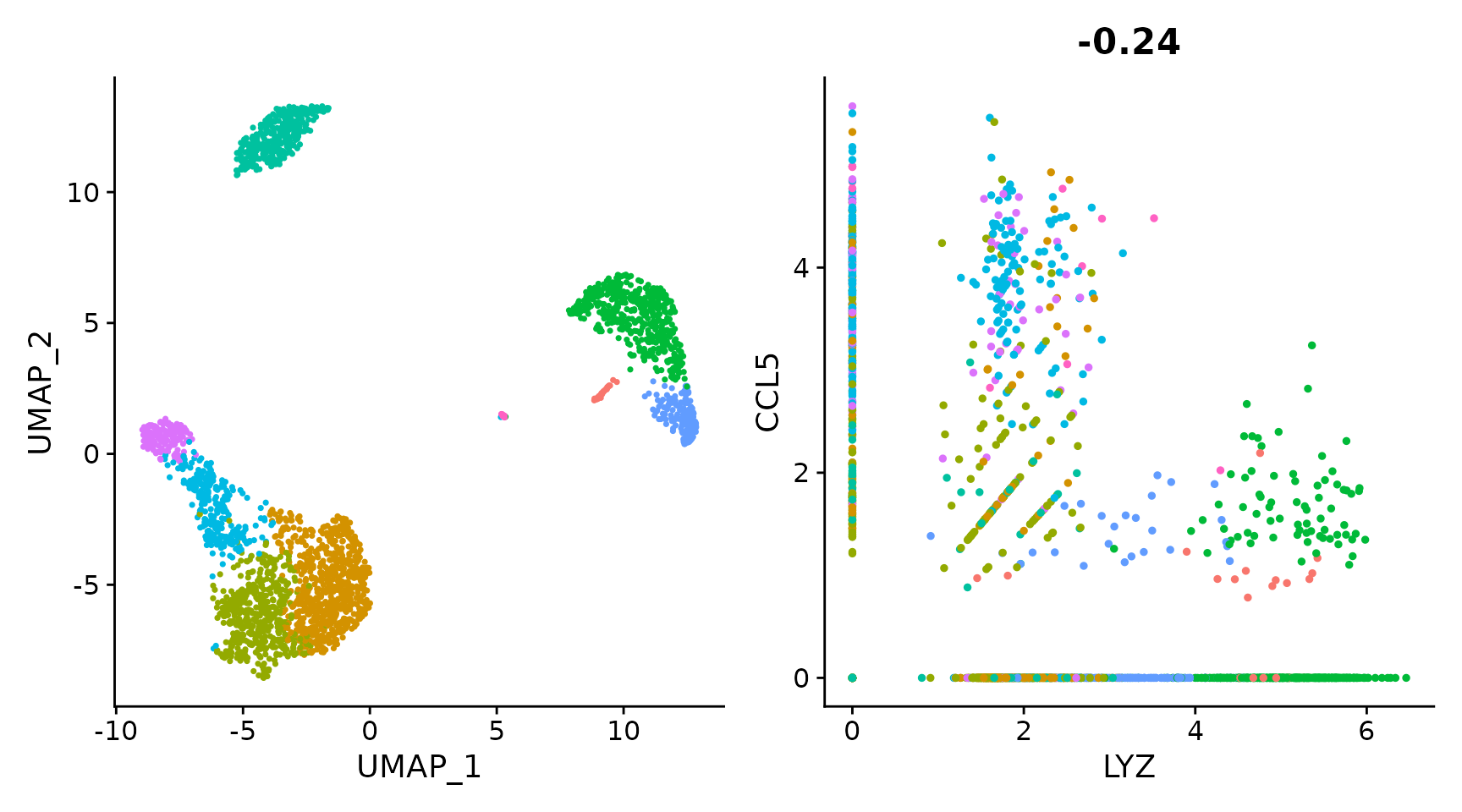
Seurat 中的数据可视化方法
本文[1]将使用从 2,700 PBMC 教程计算的 Seurat 对象来演示 Seurat 中的可视化技术。您可以从 SeuratData[2] 下载此数据集。 SeuratData::InstallData("pbmc3k")library(Seurat)library(SeuratData)library(ggplot2)library(patchwork)pbmc3k.final <- LoadData(…...

ImportError: cannot import name ‘InterpolationMode‘
InterpolationMode 在图像处理库中通常用于指定图像缩放时的插值方法。插值是一种数学方法,在图像大小变化时用于估算新像素位置的像素值。不同的插值方法会影响缩放后图像的质量和外观。 在你提供的 image_transform 函数中,InterpolationMode.BICUBIC…...

HSRP和VRRP
VRRP(Virtual Router Redundancy Protocol,虚拟路由器冗余协议) 是一种网络层的容错协议,主要用于在多台路由器之间提供默认网关冗余。在IP网络中,当一个子网有多个路由器时,VRRP可以确保在主用路由器失效…...
C及C++每日练习(1)
一.选择: 1.以下for循环的执行次数是() for(int x 0, y 0; (y 123) && (x < 4); x); A.是无限循环 B.循环次数不定 C.4次 D.3次 对于循环,其组成部分可以四个部分: for(初始化;循环进行条件;调整) …...

Oracle 12c dataguard查看主备库同步情况的新变化
导读 本文介绍Oracle 12c dataguard在维护方面的新变化 前提:主库备库的同步是正常的。 1、主库上查看archive Log list SYScdb1> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination…...
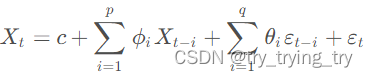
时间序列-AR MA ARIMA
一、AR模型(自回归) AR探索趋势和周期性 预测依赖于过去的观测值和模型中的参数。模型的阶数 p pp 决定了需要考虑多少个过去时间点的观测值。 求AR模型的阶数 p和参数 ϕ i \phi_i ϕi ,常常会使用统计方法如最小二乘法、信息准则(如AIC、BIC…...
:集成Alibaba Druid 连接池)
Spring Boot(六十六):集成Alibaba Druid 连接池
1 Alibaba Druid介绍 在现代的Java应用中,使用一个高效可靠的数据源是至关重要的。Druid连接池作为一款强大的数据库连接池,提供了丰富的监控和管理功能,成为很多Java项目的首选。本文将详细介绍如何在Spring Boot项目中配置数据源,集成Druid连接池,以实现更高效的数据库…...

leetcode 经典题目42.接雨水
链接:https://leetcode.cn/problems/trapping-rain-water 题目描述 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 思路分析 首先,我们需要遍历数组,对于每个元素&am…...

高防服务器的主要作用有哪些?
高防服务器是属于服务器的一种,主要是为了解决流量攻击而设计的,高防服务器能够维护服务器的稳定性和安全性,具备很高的防御能力和更加优质的网络带宽,能够提供更加可靠的服务保障,那么高防服务器主要都有哪些作用呢&a…...

【30 天 JavaScript 挑战】学习笔记
30 天 JavaScript 挑战 专为 JavaScript 初学者设计 掌握必备 JavaScript 技能 前端人,前端魂,刷完 JS 即入门! 题目地址:https://leetcode.cn/studyplan/30-days-of-javascript/ 个人学习笔记:https://github.com/kaimo313/…...

生成 Linux/ubuntu/Debian 上已安装软件包的列表
你可以在终端中使用以下命令生成已安装软件包的列表: 列出所有已安装的软件包: dpkg --get-selections要将列表保存到文件中: dpkg -l > installed_packages_detailed.txt这将在当前目录中创建一个名为“installed_packages_detailed.txt”…...
精品中国货出海wordpress外贸独立站建站模板
旗袍唐装wordpress外贸网站模板 旗袍、唐装、华服wordpress外贸网站模板,适合做衣服生意的外贸公司官网使用。 https://www.jianzhanpress.com/?p3695 劳动防护wordpress外贸独立站模板 劳动防护wordpress外贸独立站模板,劳动保护、劳动防护用品外贸…...
使用Animated.View实现全屏页面可以向下拖动,松开手指页面返回原处的效果
使用Animated.View实现全屏页面可以向下拖动,松开手指页面返回原处的效果 效果示例图代码示例 效果示例图 代码示例 import React, {useRef, useState} from react; import {View,Text,Animated,Easing,PanResponder,StyleSheet, } from react-native;const TestDragCard () …...

减肥成功的人,都有这 4 个共同点
减肥成功的人,都有这 4 个共同点 为什么你总是减肥失败,而有的人却轻松瘦下来不反弹? 今天告诉你真相 👇 01| 吃够基础代谢值 ❌ 极端节食 → 代谢下降 → 越减越肥 ✅ 男生 ≥1400 大卡,女生 ≥1100 大卡 …...

基于金橙子MarkEzd.dll的激光打标二次开发实战:从函数解析到自动化标刻系统构建
1. 金橙子MarkEzd.dll开发入门指南 第一次接触激光打标二次开发的朋友可能会被各种专业术语吓到,但其实只要掌握几个核心概念就能快速上手。MarkEzd.dll是北京金橙子科技为EZCAD2激光打标软件提供的开发接口,相当于给开发者开了一个"后门"&…...

终极游戏MOD加载指南:5分钟学会使用ASI加载器提升游戏体验
终极游戏MOD加载指南:5分钟学会使用ASI加载器提升游戏体验 【免费下载链接】Ultimate-ASI-Loader The Ultimate ASI Loader is a proxy DLL that loads custom .asi libraries into any game process. 项目地址: https://gitcode.com/gh_mirrors/ul/Ultimate-ASI-…...

Solidworks 2018+ 机器人模型避坑指南:用SW2URDF插件导出URDF,再导入Webots R2023a完整流程
SolidWorks 2018机器人模型导入Webots全流程避坑指南 在机器人仿真领域,将SolidWorks设计的机械模型准确导入Webots仿真环境是一个关键但充满挑战的环节。许多工程师和学生在初次尝试这一流程时,往往会在版本兼容性、文件路径、坐标系设置等环节遭遇各种…...

如何高效下载B站视频:BiliDownloader终极使用教程
如何高效下载B站视频:BiliDownloader终极使用教程 【免费下载链接】BiliDownloader BiliDownloader是一款界面精简,操作简单且高速下载的b站下载器 项目地址: https://gitcode.com/gh_mirrors/bi/BiliDownloader 想要轻松保存B站上的精彩视频内容…...

长期使用聚合API平台,对账单清晰度与费用追溯的满意度反馈
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用聚合API平台,对账单清晰度与费用追溯的满意度反馈 作为一名长期负责项目维护的开发者,我所在团队在…...

Altium Designer 21 规则设置保姆级指南:从新手到老鸟,这些默认值千万别乱动
Altium Designer 21 规则设置实战精要:默认值的智慧与关键调整策略 作为一名从学生时代就开始使用Altium Designer的硬件工程师,我至今记得第一次打开规则设置面板时的眩晕感——密密麻麻的选项像是一道道关卡,让人既想全部征服又担心误操作导…...

2026年热门抠图软件怎么选?好用的抠图工具实测对比指南
抠图需求在生活和工作中越来越常见——无论是制作证件照、电商产品展示,还是社交媒体内容编辑,一款趁手的抠图工具能省去大量时间。但市面上的抠图软件五花八门,功能各不相同,如何找到最适合自己的那一款?本文将从多个…...

为开源Agent框架Hermes配置Taotoken作为模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为开源Agent框架Hermes配置Taotoken作为模型供应商 本文将详细介绍如何在Hermes Agent项目中,将其模型供应商配置为Tao…...

LinuxCNC新手到专家:5个步骤打造你的完美数控系统
LinuxCNC新手到专家:5个步骤打造你的完美数控系统 【免费下载链接】linuxcnc LinuxCNC controls CNC machines. It can drive milling machines, lathes, 3d printers, laser cutters, plasma cutters, robot arms, hexapods, and more. 项目地址: https://gitcod…...