算法刷题day23:双指针
目录
- 引言
- 概念
- 一、牛的学术圈I
- 二、最长连续不重复序列
- 三、数组元素的目标和
- 四、判断子序列
- 五、日志统计
- 六、统计子矩阵
引言
关于这个双指针算法,主要是用来处理枚举子区间的事,时间复杂度从 O ( N 2 ) O(N^2) O(N2) 降为 O ( N ) O(N) O(N) ,所以还是很方便的,而且枚举这类题出的还是很常见的,所以这个算法还是尤为重要的。加油!
概念
双指针算法:首先要满足单调性,二分是元素的单调性、二段性,这个指的是区间的单调性。
双指针模板:
for(int i = 0, j = 0; i < n; ++i)
{while(j < n && check(i,j)) j++;//该题逻辑
}
一、牛的学术圈I
标签:二分
思路:像这种求最大/最小的问题,基本上都可以用二分。我们不讨论最大值,我们讨论该h指数是否能达到,然后用二分来逼近能成立的最大值,显然该题是具有二段性的,具体长如下这样。然后就是 c h e c k check check 函数了,因为先统计大于等于 m i d mid mid 的个数,再统计满足 a [ i ] + 1 = m i d a[i] + 1 = mid a[i]+1=mid 的个数,与 l l l 取最小值,最后比较是否 r e s ≥ m i d res \geq mid res≥mid 。
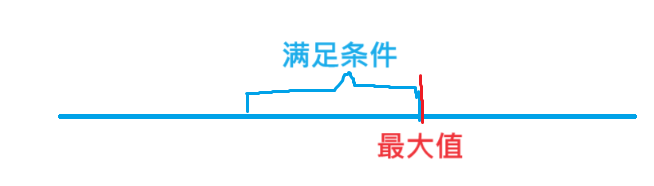
题目描述:
由于对计算机科学的热爱,以及有朝一日成为 「Bessie 博士」的诱惑,奶牛 Bessie 开始攻读计算机科学博士学位。经过一段时间的学术研究,她已经发表了 N 篇论文,并且她的第 i 篇论文得到了来自其他研究文献的 ci 次引用。Bessie 听说学术成就可以用 h 指数来衡量。h 指数等于使得研究员有至少 h 篇引用次数不少于 h 的论文的最大整数 h。例如,如果一名研究员有 4 篇论文,引用次数分别为 (1,100,2,3),则 h 指数为 2,然而若引用次数为 (1,100,3,3)则 h 指数将会是 3。为了提升她的 h 指数,Bessie 计划写一篇综述,并引用一些她曾经写过的论文。由于页数限制,她至多可以在这篇综述中引用 L 篇论文,并且她只能引用每篇她的论文至多一次。请帮助 Bessie 求出在写完这篇综述后她可以达到的最大 h 指数。注意 Bessie 的导师可能会告知她纯粹为了提升 h 指数而写综述存在违反学术道德的嫌疑;我们不建议其他学者模仿 Bessie 的行为。输入格式
输入的第一行包含 N 和 L。
第二行包含 N 个空格分隔的整数 c1,…,cN。输出格式
输出写完综述后 Bessie 可以达到的最大 h 指数。数据范围
1≤N≤105,0≤ci≤105,0≤L≤105
输入样例1:
4 0
1 100 2 3
输出样例1:
2
样例1解释
Bessie 不能引用任何她曾经写过的论文。上文中提到,(1,100,2,3) 的 h 指数为 2。输入样例2:
4 1
1 100 2 3
输出样例2:
3
如果 Bessie 引用她的第三篇论文,引用数会变为 (1,100,3,3)。上文中提到,这一引用数的 h 指数为 3。
示例代码:
#include <bits/stdc++.h>using namespace std;typedef long long LL;const int N = 1e5+10;int n, m;
int a[N];bool check(int mid) // 检查能否到mid
{int res = 0, t = 0;for(int i = 0; i < n; ++i){if(a[i] >= mid) res++;if(a[i] + 1 == mid) t++;}t = min(m, t);res += t;return res >= mid;
}int main()
{ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);cin >> n >> m;for(int i = 0; i < n; ++i) cin >> a[i];int l = 0, r = 1e5;while(l < r){int mid = (LL)l + r + 1 >> 1;if(check(mid)) l = mid;else r = mid - 1;}cout << r << endl;return 0;
}
二、最长连续不重复序列
标签:双指针
思路:模板题。核心就是 [ j , i ] [j,i] [j,i] 维护的是一段有效的序列, i i i 是一值往前走的,用 c n t cnt cnt 来记录每一个值出现的次数,如果重复了,那肯定是 i i i 和 j j j 所对应的元素重复了, j j j 往前走即可,然后找最大值。
题目描述:
给定一个长度为 n 的整数序列,请找出最长的不包含重复的数的连续区间,输出它的长度。输入格式
第一行包含整数 n。
第二行包含 n 个整数(均在 0∼105 范围内),表示整数序列。输出格式
共一行,包含一个整数,表示最长的不包含重复的数的连续区间的长度。数据范围
1≤n≤105
输入样例:
5
1 2 2 3 5
输出样例:
3
示例代码:
#include <bits/stdc++.h>using namespace std;typedef long long LL;const int N = 1e5+10;int n;
int a[N], cnt[N];int main()
{ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);cin >> n;for(int i = 0; i < n; ++i) cin >> a[i];int res = 0;for(int i = 0, j = 0; i < n; ++i){cnt[a[i]]++;while(j < i && cnt[a[i]] > 1) cnt[a[j++]]--;res = max(res, i - j + 1);}cout << res << endl;return 0;
}
三、数组元素的目标和
标签:哈希、双指针
思路1:就是找两个数组中和为 k e y key key 的两个下标,直接先把第一个数组按元素值存入哈希表,然后遍历第二个数组如果存在就输出即可。
思路2:由于都是升序的, i i i 从最小值遍历, j j j 从最大值遍历,如果值总和变小了, i i i 右移,如果变大了, j j j 左移,直到相等。
题目描述:
给定两个升序排序的有序数组 A 和 B,以及一个目标值 x。数组下标从 0 开始。请你求出满足 A[i]+B[j]=x 的数对 (i,j)。数据保证有唯一解。输入格式
第一行包含三个整数 n,m,x,分别表示 A 的长度,B 的长度以及目标值 x。第二行包含 n 个整数,表示数组 A。第三行包含 m 个整数,表示数组 B。输出格式
共一行,包含两个整数 i 和 j。数据范围
数组长度不超过 105。同一数组内元素各不相同。1≤数组元素≤109
输入样例:
4 5 6
1 2 4 7
3 4 6 8 9
输出样例:
1 1
示例代码1: 哈希表
#include <bits/stdc++.h>using namespace std;typedef long long LL;int n, m, k;
unordered_map<int,int> mmap;int main()
{ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);cin >> n >> m >> k;for(int i = 0; i < n; ++i){int t; cin >> t;mmap[t] = i;}for(int i = 0; i < m; ++i){int t; cin >> t;if(mmap.count(k-t)) {cout << mmap[k-t] << " " << i << endl;break;}}return 0;
}
示例代码2: 双指针
#include <bits/stdc++.h>using namespace std;typedef long long LL;const int N = 1e5+10;int n, m;
LL k;
int a[N], b[N];int main()
{ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);cin >> n >> m >> k;for(int i = 0; i < n; ++i) cin >> a[i];for(int i = 0; i < m; ++i) cin >> b[i];int i = 0, j = m - 1;for(; i < n && j > -1; ++i){while(j > -1 && a[i] + b[j] > k) j--;if(j > -1 && (LL)a[i] + b[j] == k) break;}cout << i << " " << j << endl;return 0;
}
四、判断子序列
标签:双指针、模板题
思路:双指针模板,没啥说的。
题目描述:
给定一个长度为 n 的整数序列 a1,a2,…,an 以及一个长度为 m 的整数序列 b1,b2,…,bm。请你判断 a 序列是否为 b 序列的子序列。子序列指序列的一部分项按原有次序排列而得的序列,例如序列 {a1,a3,a5} 是序列 {a1,a2,a3,a4,a5} 的一个子序列。输入格式
第一行包含两个整数 n,m。
第二行包含 n 个整数,表示 a1,a2,…,an。
第三行包含 m 个整数,表示 b1,b2,…,bm。输出格式
如果 a 序列是 b 序列的子序列,输出一行 Yes。
否则,输出 No。数据范围
1≤n≤m≤105,109≤ai,bi≤109
输入样例:
3 5
1 3 5
1 2 3 4 5
输出样例:
Yes
示例代码:
#include <bits/stdc++.h>using namespace std;typedef long long LL;const int N = 1e5+10;int n, m;
int a[N], b[N];int main()
{ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);cin >> n >> m;for(int i = 0; i < n; ++i) cin >> a[i];for(int j = 0; j < m; ++j) cin >> b[j];int i = 0, j = 0;while(i < n && j < m){if(a[i] == b[j]) i++;j++;}if(i == n) puts("Yes");else puts("No");return 0;
}
五、日志统计
标签:枚举、双指针
思路:一般这种题都是遍历订单,而我看这道题要按 i d id id 号由小到大输出,那我就遍历 i d id id 号了,然后找出满足条件的输出就行了,我用 v e c t o r + 数组 vector+数组 vector+数组 来存,第 i i i 号 v e c t o r vector vector 代表 i d id id 号为 i i i 的订单时间, v e c t o r vector vector 里存的是该 i d id id 的点赞时间,首先如果数量够 k k k 个,然后由小到大排序,遍历每 k k k 个时间,判断是否间隔时间在 d d d 以内,如果是输出即可。
题目描述:
小明维护着一个程序员论坛。现在他收集了一份”点赞”日志,日志共有 N 行。其中每一行的格式是:ts id 表示在 ts 时刻编号 id 的帖子收到一个”赞”。现在小明想统计有哪些帖子曾经是”热帖”。如果一个帖子曾在任意一个长度为 D 的时间段内收到不少于 K 个赞,小明就认为这个帖子曾是”热帖”。具体来说,如果存在某个时刻 T 满足该帖在 [T,T+D) 这段时间内(注意是左闭右开区间)收到不少于 K 个赞,该帖就曾是”热帖”。给定日志,请你帮助小明统计出所有曾是”热帖”的帖子编号。输入格式
第一行包含三个整数 N,D,K。以下 N 行每行一条日志,包含两个整数 ts 和 id。输出格式
按从小到大的顺序输出热帖 id。每个 id 占一行。数据范围
1≤K≤N≤105,0≤ts,id≤105,1≤D≤10000
输入样例:
7 10 2
0 1
0 10
10 10
10 1
9 1
100 3
100 3
输出样例:
1
3
示例代码:
#include <bits/stdc++.h>using namespace std;typedef long long LL;const int N = 1e5+10;int n, d, k;
vector<int> logs[N]; // 统计第i号订单的日期int main()
{ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);cin >> n >> d >> k;for(int i = 0; i < n; ++i){int ts, id;cin >> ts >> id;logs[id].push_back(ts);}for(int i = 0; i < N; ++i) // 遍历每一个id{if(logs[i].size() >= k){sort(logs[i].begin(), logs[i].end()); // 给其时间排序for(int j = 0; j + k - 1 < logs[i].size(); ++j){if(logs[i][j+k-1] - logs[i][j] + 1 <= d) {cout << i << endl;break;}}}}return 0;
}
六、统计子矩阵
标签:前缀和、二分
思路:本来用前缀和直接做的话,时间复杂度在 O ( N 4 ) O(N^4) O(N4) ,明显超时了。由题意得元素没有负数,所以满足单调性,可以用上下界限拿前缀和处理,左右拿双指针处理,这样时间复杂度就降为了 O ( N 3 ) O(N^3) O(N3) 刚好能过。
题目描述:
给定一个 N×M 的矩阵 A,请你统计有多少个子矩阵 (最小 1×1,最大 N×M) 满足子矩阵中所有数的和不超过给定的整数 K?输入格式
第一行包含三个整数 N,M 和 K。之后 N 行每行包含 M 个整数,代表矩阵 A。输出格式
一个整数代表答案。数据范围对于 30% 的数据,N,M≤20,
对于 70% 的数据,N,M≤100,
对于 100% 的数据,1≤N,M≤500;0≤Aij≤1000;1≤K≤2.5×108。输入样例:
3 4 10
1 2 3 4
5 6 7 8
9 10 11 12
输出样例:
19
样例解释
满足条件的子矩阵一共有 19,包含:大小为 1×1 的有 10 个。大小为 1×2 的有 3 个。大小为 1×3 的有 2 个。大小为 1×4 的有 1 个。大小为 2×1 的有 3 个。
示例代码:
#include <bits/stdc++.h>using namespace std;typedef long long LL;const int N = 510;int n, m, k;
int s[N][N];int main()
{ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);cin >> n >> m >> k;for(int i = 1; i <= n; ++i){for(int j = 1; j <= m; ++j){cin >> s[i][j];s[i][j] += s[i-1][j];}}LL res = 0;for(int i = 1; i <= n; ++i){for(int j = i; j <= n; ++j){for(int l = 1, r = 1, sum = 0; r <= m; ++r){sum += s[j][r] - s[i-1][r];while(l <= m && sum > k) sum -= s[j][l] - s[i-1][l], l++;res += r - l + 1;}}}cout << res << endl;return 0;
}
相关文章:
算法刷题day23:双指针
目录 引言概念一、牛的学术圈I二、最长连续不重复序列三、数组元素的目标和四、判断子序列五、日志统计六、统计子矩阵 引言 关于这个双指针算法,主要是用来处理枚举子区间的事,时间复杂度从 O ( N 2 ) O(N^2) O(N2) 降为 O ( N ) O(N) O(N) …...

学术论文GPT的源码解读与二次开发:从ChatPaper到gpt_academic
前言 本文的前两个部分最早是属于此旧文的《学术论文GPT的源码解读与微调:从ChatPaper到七月论文审稿GPT第1版》,但为了每一篇文章各自的内容更好的呈现,于是我今天做了以下三个改动 原来属于mamba第五部分的「Mamba近似工作之线性Transfor…...
报表生成器FastReport .Net用户指南:表达式(下)
在上一篇文章《报表生成器FastReport .Net用户指南:表达式(上)》中,我们已经介绍了表达式中的表达式编辑器、引用报告对象、使用 .Net 函数、数据元素参考这四部分,接下来让我们继续介绍表达式中的:引用数据…...
JavaScript极速入门(1)
初识JavaScript JavaScript是什么 JavaScript(简称JS),是一个脚本语言,解释型或者即时编译型语言.虽然它是作为开发Web页面的脚本语言而著名,但是也应用到了很多非浏览器的环境中. 看似这门语言叫JavaScript,其实在最初发明之初,这门语言的名字其实是在蹭Java的热度,实际上和…...

鸿蒙Harmony应用开发—ArkTS声明式开发(通用属性:浮层)
设置组件的遮罩文本。 说明: 从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 overlay overlay(value: string | CustomBuilder, options?: { align?: Alignment; offset?: { x?: number; y?: number } })…...

Meta AI移动设备上部署LLM的新框架MobileLLM
Meta AI 研究团队推出的 MobileLLM 标志着大语言模型(LLMs)朝着模拟人类理解和生成自然语言迈出了革命性的一步。LLMs 在处理和分析大量数据集方面的能力已经显著影响了自动化客户服务、语言翻译和内容创作等多个领域。然而,由于传统 LLMs 在计算和存储资源方面的需求庞大,…...

使用Tesseract-OCR对PDF等图片文件进行文字识别
安装 用 Homebrew 来安装 Tesseract brew install tesseract 2. 完成 tessearact 的安装后,还需要安装中文数据包,执行以下两个操作, brew info tesseract 执行这个指令的目的,是找到 Homebrew 把 tesseract 安装在文件夹内&am…...

部署YOLOv8模型的实用常见场景
可以的话,GitHub上点个小心心,翻不了墙的xdm,csdn也可以点个赞,谢谢啦 车流量检测(开源代码github): test3 meiqisheng/YOLOv8-DeepSORT-Object-Tracking (github.com) 车牌检测࿰…...

SpringBoot缓存
目录 缓存支持 缓存集成 redis缓存集成 缓存支持 Spring 框架只提供抽象,不提供具体的缓存存储,底层需要依赖第三方存储组件,如果当前应用没有注册CacheManager 或者 CacheResolver 实例,Spring Boot 会按以下缓存组件的顺序来…...
STC89C52串口通信详解
目录 前言 一.通信基本原理 1.1串行通信与并行通信 1.2同步通信和异步通信 1.2.1异步通信 1.2.2同步通信 1.3单工、半双工与全双工通信 1.4通信速率 二.串口通信简介 2.1接口标准 2.2串口内部结构 2.3串口相关寄存器 三.串口工作方式 四.波特率计算 五.串口初始化步骤 六.实验…...

基础算法|线性结构|前缀和学习
参考文章: https://blog.csdn.net/weixin_72060925/article/details/127835303 二维数组的前缀和练习: 这里要注意的地方就是求子矩阵和的时候,这里要减去的是x1-1,y1-1的部分,因为所求的目标值是包括边界的 //前缀…...
设计模式之模版方法实践
模版方法实践案例 实践之前还是先了解一下模版方法的定义 定义 模板方法模式是一种行为设计模式,它定义了一个骨架,并允许子类在不改变结构的情况下重写的特定步骤。模板方法模式通过在父类中定义一个模板方法,其中包含了主要步骤…...

sql中COALESCE函数详解
在SQL中,COALESCE函数是一个非常有用的函数,用于从其参数列表中返回第一个非NULL值。如果所有给定的参数都是NULL,那么COALESCE函数将返回NULL。这个函数可以接受多个参数,使其在处理可能出现的NULL值时非常灵活和强大。 语法 C…...

rust-analyzer报错“Failed to spawn one or more proc-macro servers,....“怎么解决?
最近,在使用vscode测试rust代码时,遇到了一些问题。在经过反复折腾后,最终解决了问题,在此写下作为记录,以便于以后参考。 我遇到的报错内容是: Failed to spawn one or more proc-macro servers. cannot find proc-macro-srv, the workspace E:\100rust\temp is missin…...

Communications--9--一文读懂双机热备冗余原理
1、热备冗余管理 2、主备系状态判断 3、如何从冷备做到热备? 参见: 用软件实现热备冗余信号系统的安全切换...

可调恒定电流稳压器NSI50150ADT4G车规级LED驱动器 提供专业的汽车级照明解决方案
NSI50150ADT4G产品概述: NSI50150ADT4G可调恒定电流稳压器 (CCR) ,是一款简单、经济和耐用的器件,适用于为 LED 中的调节电流提供成本高效的方案(与恒定电流二极管 CCD 类似)。该 (CCR) 基于自偏置晶体管 (SBT) 技术&…...

Unity中使用代码动态修改URP管线下的标准材质是否透明
//修改为透明 material.SetFloat("_Surface",1.0f); material.SetInt("_SrcBlend", (int)UnityEngine.Rendering.BlendMode.One); material.SetInt("_DstBlend", (int)UnityEngine.Rendering.BlendMode.OneMinusSrcAlpha); material.Set…...

关于制作Python游戏全过程(汇总1)
目录 前言: 1.plane_sprites模块: 1.1导入模块: 1.1.1pygame:一个用于创建游戏的Python库。 1.1.2random:Python标准库中的一个模块,用于生成随机数。 1.2定义事件代号: 1.2.1ENEMY_EVENT:自定义的敌机出场事件代号…...

独立站营销新纪元:AI与大数据塑造个性化体验的未来
随着全球互联网的深入发展和数字化转型的不断推进,作为品牌建设和市场营销的重要载体,独立站将迎来新的发展机遇。新技术的涌现,特别是人工智能和大数据等技术的广泛应用,为独立站带来了前所未有的机遇与挑战。本文Nox聚星将和大家…...

C语言项目实战——贪吃蛇
C语言实现贪吃蛇 前言一、 游戏背景二、游戏效果演示三、课程目标四、项目定位五、技术要点六、Win32 API介绍6.1 Win32 API6.2 控制台程序6.3 控制台屏幕上的坐标COORD6.4 GetStdHandle6.5 GetConsoleCursorInfo6.5.1 CONSOLE_CURSOR_INFO 6.6 SetConsoleCursorInfo6.7 SetCon…...

透明计费如何帮助精准预测与控制AI功能月度开支
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 透明计费如何帮助精准预测与控制AI功能月度开支 1. 项目背景:深度集成AI的网站 我们负责一个内容创作辅助网站&#x…...

创新设计与智能系统设计融合
在智能制造与工业大模型时代,创新设计(以生成式AI、变型衍生、大规模定制为核心)与智能系统设计(以端-边-云协同、工业智能体、自主控制为核心)的融合,是制造企业实现研发与生产双向闭环的终极路径 。两者的…...

【免费下载】 探索SFP模块的奥秘:SFP-I2C工具推荐
探索SFP模块的奥秘:SFP-I2C工具推荐 项目介绍 在现代网络通信中,SFP(Small Form-factor Pluggable)模块扮演着至关重要的角色。这些模块通过I2C接口提供了丰富的信息,包括制造商、功能支持以及诊断数据等。然而&#x…...

Linux应用回滚流程排查方法
Linux应用回滚流程排查方法本文面向具备一定 Linux 基础的技术人员,围绕应用回滚流程展开,重点讨论版本切换、配置恢复和数据兼容。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在一起…...

CircuitPython内存优化与PyCharm集成:嵌入式开发实战指南
1. 项目概述与核心挑战在嵌入式开发的世界里,CircuitPython以其极低的入门门槛和强大的硬件抽象能力,成为了连接创意与现实的桥梁。无论是驱动一串炫彩的NeoPixel灯带,还是读取传感器数据,CircuitPython都让这一切变得像在桌面Pyt…...

DIY红外遥控电视关机器:从ATTINY85到晶体管驱动的硬件实践
1. 项目概述:从“关不掉”的烦恼到“一键清静”的实践不知道你有没有过这样的经历:在餐厅吃饭,墙上挂着的电视正播放着吵闹的广告;在候车室,多台电视同时播放着不同的节目,让人心烦意乱。你只想安安静静地待…...

OmenSuperHub:让你的惠普OMEN游戏本性能全开,告别官方臃肿软件
OmenSuperHub:让你的惠普OMEN游戏本性能全开,告别官方臃肿软件 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为惠普OMEN游戏…...

ContextMenuManager:5分钟掌握Windows右键菜单管理的终极免费方案
ContextMenuManager:5分钟掌握Windows右键菜单管理的终极免费方案 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否厌倦了每次右键点击文件时&a…...

FreeRTOS互斥信号量实战:用STM32CubeIDE解决多任务访问共享串口的优先级翻转问题
FreeRTOS互斥信号量实战:用STM32CubeIDE解决多任务访问共享串口的优先级翻转问题 在嵌入式系统开发中,多任务并发访问共享资源是一个常见且棘手的问题。想象一下这样的场景:你的STM32设备上有两个任务需要向同一个串口发送数据——一个高优先…...

【声纳技术手册】3 三维水声传播的快速计算:从海底山脉到水平折射
三维水声传播的快速计算:从海底山脉到水平折射 副标题:当我们在深海中"听见"一座山——3D射线追踪、Normal Mode Coupling与剪切波效应的直觉之旅 写在前面:为什么我们需要三维? 别急,我们先从一个你熟悉的场景开始想象。 想象你站在一个巨大的游泳池边,水面…...