从 Language Model 到 Chat Application:对话接口的设计与实现

作者:网隐
RTP-LLM 是阿里巴巴大模型预测团队开发的大模型推理加速引擎,作为一个高性能的大模型推理解决方案,它已被广泛应用于阿里内部。本文从对话接口的设计出发,介绍了业界常见方案,并分享了 RTP-LLM 团队在此场景下的思考与实践。
一、前言
从 2022 年底 chatGPT 的一炮走红开始,基于大语言模型的对话应用如雨后春笋一般全面开花。刚刚过去的 2023 年是千帆竞发的一年,在这一年里我们见证了百模大战,开源模型社区可谓繁荣昌盛:从 llama 到它的无数变体、qwen 系列的完整中文大模型生态构建、Mixtral 等多模态的成功尝试、再到 llava 等视觉大语言模型的蓄势待发。在语言模型上,我们已经有了十分丰富的选择,这些模型在 RTP-LLM 上都得到了较好的支持,可以高效地完成推理。
在最早设计的 RTP-LLM 推理引擎中,我们认为 llm 本质都是语言模型,因此提供的只有语言模型调用方式,将所有请求简化为输入一个 string,输出一个 string 的模式。然而,从语言模型到 chat 应用之间仍然有一个 gap:输入 prompt 的拼写。text-in-text-out 的设计可以简化引擎开发,但是 prompt 拼写的难题就被丢给了用户。实际上,对于某些模型,比如 chatglm3,如果不加干预,使用 text-in-text-out 的模式是无法正确进行 chat 推理的,详细原因我们后面会展开解释。
从前端的需求侧来看,text-in-text-out 模式也无法满足日益增长的 chat 应用需求。让每个用户都学习甚至实现一遍 chat prompt 的拼写既浪费人力、又会提高错误率,因此,在 LLM 推理引擎层面实现 chat 接口的需求迫在眉睫。
众所周知,openai 作为最早推出 chatGPT 服务的开创式厂家,他们定义好的“openai 接口”也是业界普遍采用的 chat 接口事实标准,不但定义了基础的多轮对话能力,还提供了 funciton call、多模态输入等多种功能。那么要在推理引擎实现 chat 能力,openai 接口就是最合适的格式。本文就来聊一聊,在实现 openai chat 接口中遇到的种种问题。
二、开源实现大赏
在介绍我们的方案之前,我们先来看一看业界的其他框架是怎么实现 chat 能力的。这里讨论的对象不仅限于 openai 接口的实现,凡是实现多轮对话能力的,都在讨论范围之内。提供 chat 能力的核心需求是如何将多轮对话按照模型训练时的格式渲染成模型的 input id。这听起来是个很简单的事情,但是随着模型类型不断扩张,各种五花八门的实现方式要做到正确却并不容易,更不用说如果加上 function call,问题就变得更加复杂。
2.1 huggingface tokenizer
hugging face 将所有的 LLM 抽象成了 text-generation pipeline,由 Model 和 Tokenizer 两部分组成。其中,tokenizer 需要继承PreTrainedTokenizer类进行实现,该类提供了apply_chat_template方法,可以将多轮对话的 dict 转换为 input id 或者 prompt。
具体到实现上,该方法需要 tokenizer 在 config 中配置chat_template,这个 template 大概长这样:
{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}
{% endfor %}
{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}
{% endif %}相信聪明的你看一眼就知道这玩意是啥语法了。有了这个模板,就可以把这样的 messages
[{"role": "user", "content": "Hi there!"},{"role": "assistant", "content": "Nice to meet you!"},{"role": "user", "content": "Can I ask a question?"}
]拼成这样的 prompt:
<|im_start|>user
Hi there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>
<|im_start|>user
Can I ask a question?<|im_end|>如果想进一步详细了解,可以参考官方文档
https://huggingface.co/docs/transformers/main/chat_templating
这个设计看起来简单高效,非常美好。对很多模型来说,它也确实好用。那么我们马上就来看一个失败的例子。
2.2 chatglm
在 chatglm3 官方 repo 的 tokenizer config 中,我们可以看到它定义了 chat_template:

very good, 让我们跑一下试试:

不对啊,这模型根本不说人话。
那么问题出在哪里呢?我们来看看拼好的 prompt:
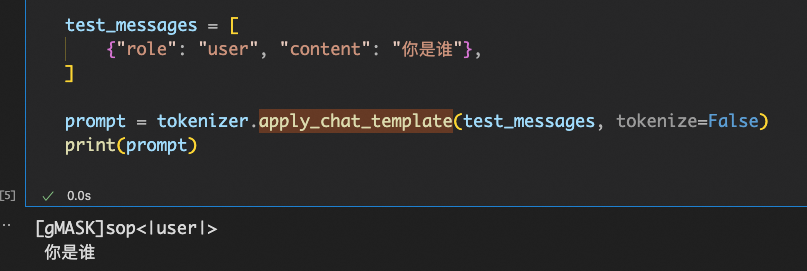
看起来像模像样。但是如果对结果 id 逐个进行 detokenize,马上就漏出了马脚:

原来,由于 chatglm3 tokenizer 实现的问题,诸如[gMASK]、<|user|>等特殊 token,在 tokenize 时会被错误地分割成多个 token 而非一个。而 chatglm3 的 tokenizer 实际上实现了一个非标准的 build_chat_input 接口,能正确处理多轮对话的 id 渲染。
通过这个例子可以看到,chat template 不一定靠谱。
2.3 qwen
qwen 系列模型并没有在 tokenizer config 里提供 chat_template 字段,使用默认模板渲染的结果不难想象当然是错的。实际上,qwen 和 chatglm 类似,自己实现了非标准的 chat 接口和渲染方法make_context,逻辑仅对自己的模型生效。对于单一模型来说当然没问题,但是并不能做成通用逻辑。
这时已经不难发现,开源模型有着五花八门的 prompt 拼写方式。很多支持多模型的开源框架都号称提供了 openai 格式的 chat 接口,那么来看看兼容多模型的开源框架做得如何。
2.4 vllm
vllm 可以说是开源推理框架界的一哥,feature list 里写着支持 openai 接口。先翻翻代码:
@app.post("/v1/chat/completions")
async def create_chat_completion(request: ChatCompletionRequest,raw_request: Request):...try:prompt = tokenizer.apply_chat_template(conversation=request.messages,tokenize=False,add_generation_prompt=request.add_generation_prompt)...result_generator = engine.generate(prompt, sampling_params, request_id,token_ids)直接就无条件信赖 chat template。看起来就不太靠谱,让我们起个 qwen 的服务
python3 -m vllm.entrypoints.openai.api_server --model Qwen/Qwen-7B-Chat --trust-remote-code找个前端接上试试:

第一句话似乎是对的,但是显然,没有正确处理 eos 和 stop words。约等于没法用。
vllm 还提供了手动指定 chat_template 文件的能力,但是这样一来就对用户有一定的使用门槛,做不到开箱即用;二来没有解决 tokenizer 无法 tokenize special token 的问题。
2.5 llama.cpp
作为一个 cpu first 并且支持多种异构加速方式的框架,llama.cpp 在开源社区的呼声也很高。
它的配套项目 llama-cpp-python(https://github.com/abetlen/llama-cpp-python) 也在 readme 的开头就强调了自己支持 openai compatible server。
again,先看看代码实现:在llama_cpp/llama_chat_format.py中定义了一个ChatFormatter类,并针对不同的模型单独写了适配,以 qwen 为例的话:
@register_chat_format("qwen")
def format_qwen(messages: List[llama_types.ChatCompletionRequestMessage],**kwargs: Any,
) -> ChatFormatterResponse:_roles = dict(user="<|im_start|>user", assistant="<|im_start|>assistant")system_message="You are a helpful assistant."system_template="<|im_start|>system\n{system_message}"system_message=system_template.format(system_message=system_message)_messages = _map_roles(messages, _roles)_messages.append((_roles["assistant"], None))_sep = "<|im_end|>"_prompt = _format_chatml(system_message, _messages, _sep)_sep2 = "<|endoftext|>"return ChatFormatterResponse(prompt=_prompt,stop=_sep2)看起来像模像样,那么实际跑一下试试看。llama-cpp 的运行略微麻烦,需要先转换模型为 gguf 模式然后运行。这里只展示一下加载命令:
/opt/conda310/bin/python -m llama_cpp.server --model /mnt/nas1/gguf/qwen-14b-chat-f16.gguf --n_gpu_layers 128 --host 0.0.0.0 --chat_format qwen然后接上前端:

……总之是哪里不对。
看起来,主流开源推理框架提供的 openai 接口很难说得上能用。
2.6 llama-factory 和 fastchat
山穷水尽,峰回路转,在一次跟训练同学的交流中,发现有个做 finetune 的库 llama-factory 写的模板还不错:
https://github.com/hiyouga/LLaMA-Factory/blob/5a207bb7230789ddefba932095de83002d01c005/src/llmtuner/data/template.py
这个 template 的设计十分干净,没有多余依赖;对于 eos、special token 的处理也十分到位,并且提供了 proerty 可供访问,而且已经适配了主流开源模型。
另外,还有个开源框架 fast chat,它也提供了一些 chat prompt 的渲染模板,适配的模型更多,缺点是只拼了 string,无法处理 tokenizer 的问题。
https://github.com/lm-sys/FastChat/blob/main/fastchat/conversation.py
测试了几个模型的 input id 渲染结果发现均符合预期,于是决定直接拿过来用。虽然它们也不能解决所有问题,但可以省去很多模型的适配工作。
三、RTP-LLM 的实现方案
了解了现状之后,我们就希望能开发一个 all in one、适配主流模型、功能丰富且开箱即用的 chat 接口。综合整理多种模型的实现之后,我们设计了如下的缝合方案:
用户指定 template 类型
前文提到,我们从开源项目里抄了一些适配规则。对于这部分规则模板,可以通过环境变量MODEL_TEMPLATE_TYPE指定使用。因为其必须显示指定,并且完成度较高,而且还能解决 tokenizer 的问题,我们给了它最高优先级。
chat_template
如果模型的 tokenizer config 中带了chat_template属性,那么用它作为除了指定模板以外渲染 prompt 的首选依据。这样做有两个考量:
-
一部分开源模型,如 01ai 的 Yi-6B/34B 系列,是用了 llama 的模型结构+自己的 chat_template。依靠 chat_template 属性,无需额外设置即可自动获得正确的渲染结果。
-
如果有用户希望自己定义 chat 接口的 prompt 拼写方式,那么 chat_template 也是最简单的方式,也是业界的标准做法。用户如果自己定义了拼写模板,在导出 checkpoint 时设置了 chat_template,那么应当起效。
qwen 和多模态:特殊处理
对于 qwen 系列模型,为了支持 function,我们单独写了适配逻辑,在下一个 section 会详细讲解。同样,对于多模态模型,因为需要处理图片,处理逻辑更复杂,我们也单独写了渲染逻辑。这些模型
其他模型:根据 model type 再次查找模板
这条规则和 1 类似,只不过是根据 model type 查找模板,而不是额外指定的环境变量。这样可以完成原始版 llama、baichuan 等模型的支持。
保底:default chat template
如果以上的所有规则都不能找到合适的渲染方法,那么执行兜底策略,使用 chatML 的方式拼写 prompt。
实现了以上方案后,用户在启动服务时,无需额外指定任何参数,即可自动得到一个好用的 openai chat 接口;同时又保留了配置能力,可以一键套用常见的开源模板,也可以满足用户自带模板的高级要求。
四、function call 的处理
4.1 基本逻辑
通过 llm 调用外部函数是一个重要的发展趋势,qwen 的全系列也支持用 ReAct 模板返回函数调用并根据函数返回给出最终结果。ReAct 模板的 prompt 大概长这样:
"<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
Answer the following questions as best you can. You have access to the following APIs:get_current_weather: Call this tool to interact with the get_current_weather API. What is the get_current_weather API useful for? Get the current weather in a given location. Parameters: {"type": "object", "properties": {"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"}, "unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}}, "required": ["location"]}Use the following format:Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [get_current_weather]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can be repeated zero or more times)
Thought: I now know the final answer
Final Answer: the final answer to the original input questionBegin!Question: 杭州市余杭区天气如何?<|im_end|>
<|im_start|>assistant具体的拼写逻辑比较复杂,就不展开了。这里比较重要的是,如何处理 response 的问题。
当遇到模型吐出\nAction: 和\nAction Input: 的组合时,我们就知道结果需要返回函数调用了。这个 parse 逻辑不复杂,但是 LLM 往往都是流式返回的结果,而在模型吐字的过程中,框架并不知道它会不会吐出来一个函数调用。
让我们再去先看看开源实现:
qwen 官方的 openai 接口示例
if request.stream:if request.functions:raise HTTPException(status_code=400,detail="Invalid request: Function calling is not yet implemented for stream mode.",)偷懒了,直接不允许流式返回和 function call 同时存在。
再看看 chatglm 的官方示例:
def contains_custom_function(value: str) -> bool: return value and 'get_' in value这位更是高手,直接假设 function call 一定是get_开头的。
至于其他开源框架,当前大部分没有不支持返回 function call。
4.2 实现方法
最终的实现其实也很简单,在模型吐字时留上一小块 buffer 不返回,如果没有\nAction: 那就继续返回;如果遇到这个 string,则说明模型可能要输出 function call,在此收集输出知道遇到 eos 或者作为 stop word 的\nObservation:,然后再把 buffer 一次性 parse 成函数并返回。
实际上,不同模型实现 function call 还有很多其他方式。由于 qwen 的规模最为完整,并且训练时也对 function call 做过 align,所以目前我们的框架只支持了使用 qwen 进行 function call。未来也会继续探索 function 的不同定义方式。
五、实战篇:用 chat 接口构建应用
搞定服务之后,现在我们来实战构建一些基于 chat 接口的应用。
首先,参照 RTP-LLM 的文档启动,以启动任意 size 的 qwen 为例
export MODEL_TYPE=qwen
export CHECKPOINT_PATH=/path/to/model
export START_PORT=50233python3 -m maga_transformer.start_server这里的例子均使用 qwen-14b 模型完成。
5.1 langchain 文本信息结构化输出
这个例子展示 RTP-LLM 提供的 openai 接口返回 function call 的能力。这个例子中 langchain 中对 openai function 设计了一类单独的 chain 抽象,这里我们来看一个结构化抽取实体的例子:
# 配置qwen服务域名为openai endpoint
import os
os.environ["OPENAI_API_KEY"] = "xxxx" # you can use any string for key
os.environ["OPENAI_API_BASE"] = "http://localhost:50233"# langchain打印每一步的完整信息
from langchain.globals import set_debug, set_verbose
set_debug(True)
set_verbose(True)from langchain_core.pydantic_v1 import BaseModel, Field
from langchain.chains.openai_functions import create_structured_output_chain
from langchain_community.chat_models import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate# 定义一个Dog对象
class Dog(BaseModel):"""Identifying information about a dog."""name: str = Field(..., description="The dog's name")color: str = Field(..., description="The dog's color")# 定义prompt模板:用function call提取{input}中的对象。
llm = ChatOpenAI(model="anything-you-like", temperature=0.2)
prompt = ChatPromptTemplate.from_messages([("system", "You are an algorithm for extracting information into structured formats, and respond with function call."),("user", "extract information from the following input: {input}"),]
)# 构建chain并调用,输出解析的结果。output是一个`Dog`对象。
chain = create_structured_output_chain(Dog, llm, prompt)
output = chain.run("John had a dog named Harry, who was a brown beagle that loved chicken")
print(str(output))运行就可以得到解析好的结果
name='Harry' color='brown'复制代码
5.2 用 llamaindex 实现 RAG
下面来看一个基础的 RAG 例子,用 llamaindex 配合几行代码即可实现带搜索增强的对话系统。在这个例子里,我们克隆一个 chatglm3 的官方 github repo 到本地,对目录里的所有文档做索引,并进行增强对话。这里的例子不设计 function call,所以理论上所有模型都能使用。
import os
os.environ["OPENAI_API_KEY"] = "xxxx" # you can use any string for key
os.environ["OPENAI_API_BASE"] = "http://localhost:50233"from llama_index.readers import SimpleDirectoryReader, JSONReader, PDFReader
from llama_index.embeddings import HuggingFaceEmbedding
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.llms import OpenAI# 先从huggingface上拉一个embedding模型,给文本召回用
embed_model = HuggingFaceEmbedding(model_name="sentence-transformers/all-MiniLM-L6-v2")
service_context = ServiceContext.from_defaults(llm=llm, embed_model=embed_model
)
llm = OpenAI()# 从本地目录加载所有文档,并建立向量索引
documents = SimpleDirectoryReader("/home/wangyin.yx/workspace/ChatGLM3").load_data()
index = VectorStoreIndex.from_documents(documents, service_context=service_context)# 进行对话查询
query_engine = index.as_query_engine()
response = query_engine.query("如何在mac上部署chatglm?")
print(response)运行即可得到如下带搜索增强的返回:
针对搭载 Apple Silicon 或 AMD GPU 的 Mac,可以借助 MPS 后端,在 GPU 上运行 ChatGLM3-6B。参照 Apple 的 官方说明以安装 PyTorch-Nightly(正确的版本号应为 2.x.x.dev2023xxxx,而非 2.x.x)。目前 MacOS 只支持从本地加载模型。将代码中的模型加载方式改为从本地加载,并使用 mps 后端,即可在 Mac 上部署 ChatGLM。
```python
model=AutoModel.from_pretrained("your local path", trust_remote_code=True).to('mps')
六、总结
使用 RTP-LLM 的 openai 兼容接口,使得调用开源模型一键构建 chat 应用变得非常容易。同时,框架也提供了足够丰富的配置项,用户可以适配多种方式 train 出来的模型。
相关资料
[01]chatglm3 官方 repo 的 tokenizer config
https://huggingface.co/THUDM/chatglm3-6b/blob/main/tokenizer_config.json
[02] llama-cpp-python
https://github.com/abetlen/llama-cpp-python
相关文章:
从 Language Model 到 Chat Application:对话接口的设计与实现
作者:网隐 RTP-LLM 是阿里巴巴大模型预测团队开发的大模型推理加速引擎,作为一个高性能的大模型推理解决方案,它已被广泛应用于阿里内部。本文从对话接口的设计出发,介绍了业界常见方案,并分享了 RTP-LLM 团队在此场景…...
无人机|LQR控制算法及其无人机控制中的应用仿真
前言 LQR全称Linear Quadratic Regulator(线性二次调节器),顾名思义用于解决形如 x ˙ A x B u y C x D u \begin{aligned}\dot{x}&AxBu\\y&CxDu\end{aligned} x˙yAxBuCxDu 线性时不变系统的一种线性控制方法,…...
ubuntu环境下docker容器详细安装使用
文章目录 一、简介二、ubuntu安装docker1.删除旧版本2.安装方法一3. 安装方法二(推荐使用)4.运行Docker容器5. 配置docker加速器 三、Docker镜像操作1. 拉取镜像2. 查看本地镜像3. 删除镜像4. 镜像打标签5. Dockerfile生成镜像 四、Docker容器操作1. 获取…...

vue2源码分析-vue入口文件global-api分析
文章背景 vue项目开发过程中,首先会有一个初始化的流程,以及我们会使用到很多全局的api,如 this.$set this.$delete this.$nextTick,以及初始化方法extend,initUse, initMixin , initExtend, initAssetRegisters 等等那它们是怎么实现,让我们一起来探究下吧 源码目录 global-…...

Javascript原型 ,原型链如何理解使用 ?有什么特点?
文章目录 图解原型原型链总结有需要的请私信博主,还请麻烦给个关注,博主不定期更新,或许能够有所帮助!!请关注公众号 图解 原型 常被描述为 — 种基于原型的语言–每个对象拥有一个原型对象 当试图访问 一个对象的属性…...
Flutter混合栈管理方案对比
1.Google官方(多引擎方案) Google官方建议的方式是多引擎方案,即每次使用一个新的FlutterEngine来渲染Widget树,存在的主要问题是每个引擎都要有比较大的内存等资源消耗,虽然Flutter 2.0之后的FlutterEngineGroup通过在…...

Asp .Net Core 集成 Newtonsoft.Json
简介 Newtonsoft.Json是一个在.NET环境下开源的JSON格式序列化和反序列化的类库。它可以将.NET对象转换为JSON格式的字符串,也可以将JSON格式的字符串转换为.NET对象。这个类库在.NET开发中被广泛使用,因为它功能强大、易于使用,并且有良好的性能。 使用Newtonsoft.Json,…...

GPT对话知识库——ARM-Cortex架构分为哪几个系列?每个系列有几种工作模式?各种工作模式之间的定义和区别?每种架构不同的特点和应用需求?
目录 1,问: 1,答: 2,问: 2,答: Cortex-A系列 Cortex-R系列 Cortex-M系列 3,问: 3,答: ARM Cortex-A架构 ARM Cortex-R架构…...
)
795. 前缀和(acwing)
文章目录 795.前缀和题目描述前缀和 795.前缀和 题目描述 输入一个长度为n的整数序列。 接下来再输入m个询问,每个询问输入一对l, r。 对于每个询问,输出原序列中从第l个数到第r个数的和。 输入格式 第一行包含两个整数n和m。 第二行包含n个整数&a…...
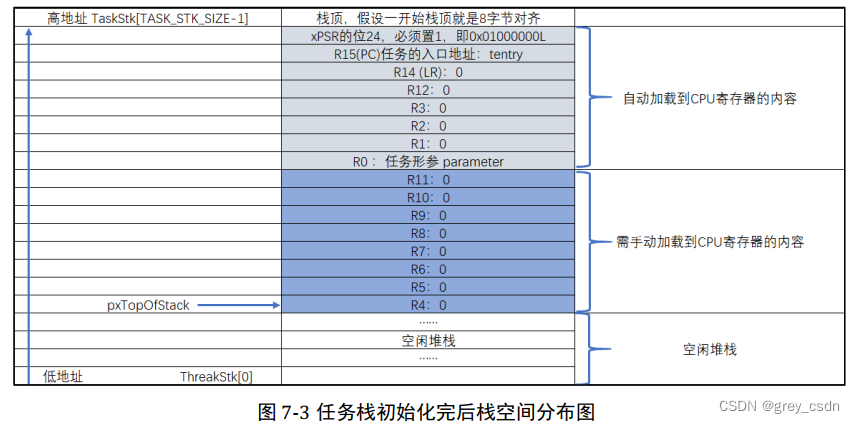
1910_野火FreeRTOS教程阅读笔记_prvStartFirstTask函数
1910_野火FreeRTOS教程阅读笔记_prvStartFirstTask函数 全部学习汇总: g_FreeRTOS: FreeRTOS学习笔记 这是教程中的一个函数,通过汇编来实现的。注释部分以及结合后面的讲解部分,可能还是有一点点细节的地方让初学者疑惑。我结合我自己的理解…...
图论练习5
Going Home Here 解题思路 模板 二分图最优匹配,前提是有完美匹配(即存在一一配对)左右集合分别有顶标,当时,为有效边,即选中初始对于左集合每个点,选择其连边中最优的,然后对于每…...

[C++] Volatile 和常量Const优化
Volatile的作用 volatile 表明某个变量的值可能在外部被改变,因此对这些变量的存取不能缓存到寄存器,每次使用时需要重新存取。 Const 和 Volatile的示例 示例1 int main() {const int a 1;int* pa const_cast<int*>(&a);*pa 4;cout &l…...

嵌入式学习day32 网络
htons();//host to network short 将端口号转换为网络通信中的大端存储 eg:htons(50000); ntohs();//host to network short 将大端存储转换为主机端口号 inet_addr();将IP地址转换为二进制 eg:inet_addr(192.168.1.170); inet_ntoa()…...

算法D33 | 贪心算法3 | 1005.K次取反后最大化的数组和 134. 加油站 135. 分发糖果
1005.K次取反后最大化的数组和 本题简单一些,估计大家不用想着贪心 ,用自己直觉也会有思路。 代码随想录 Python: class Solution:def largestSumAfterKNegations(self, nums: List[int], k: int) -> int:nums.sort(keylambda x: abs(x), reverseT…...

html地铁跑酷
下面是一个简单的HTML代码来展示一个地铁跑酷游戏: <!DOCTYPE html> <html> <head><title>地铁跑酷</title><style>#player {position: absolute;top: 0;left: 0;width: 50px;height: 50px;background-color: red;}</style…...
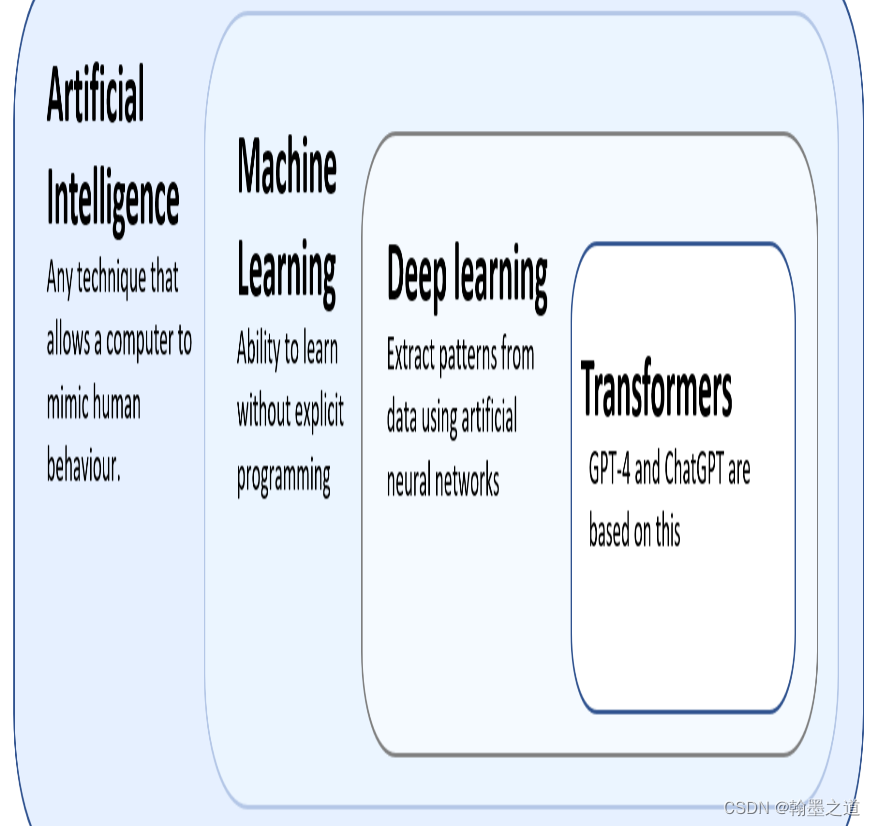
利用GPT开发应用001:GPT基础知识及LLM发展
文章目录 一、惊艳的GPT二、大语言模型LLMs三、自然语言处理NLP四、大语言模型LLM发展 一、惊艳的GPT 想象一下,您可以与计算机的交流速度与与朋友交流一样快。那会是什么样子?您可以创建哪些应用程序?这正是OpenAI正在助力构建的世界&#x…...

Golang Ants 构建协程池
构建的协程池实现两个目标: 1、限制协程池里开启的协程数量 2、当任务数大于协程数时,一个协程可以同时处理多个任务 3、监控是哪个协程ID处理了具体的任务 package mainimport ("fmt""runtime""strconv""string…...
)
【金三银四】面试题汇总(持续编写中)
Java八股文面试题汇总(持续编写中~) Java基础集合JUCJVM 数据库MySQLRedis 框架篇SSMSpringBoot 数据结构与算法数据结构与算法--汇总篇27道基础算法题,学完让你对算法有豁然开朗的感觉(推荐小白) 消息中间件RabbitMQK…...

Hive的数据存储
Hive的数据存储在HDFS的:/user/hive/warehouse中 The /user folder in HDFS is a directory typically used to store user-specific data and configurations. It serves as the home directory for Hadoop users, analogous to the /home directory in Unix-like …...
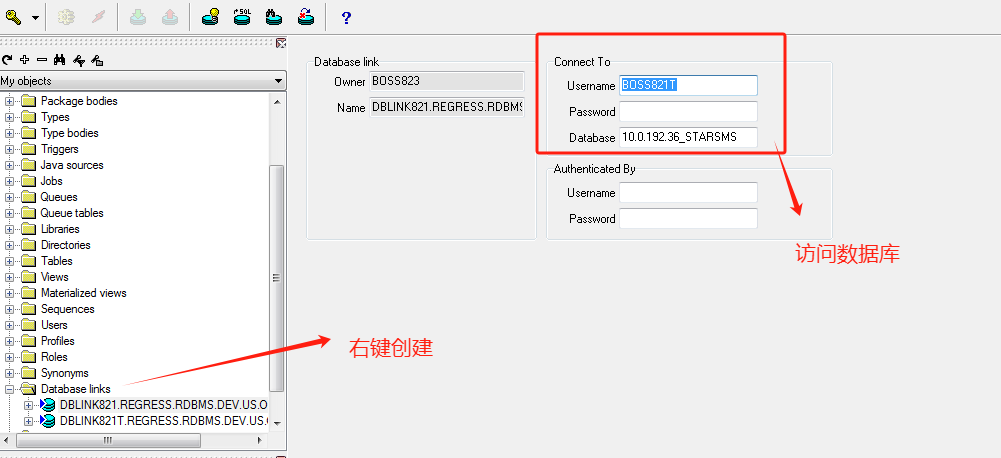
ORACLE 如何使用dblink实现跨库访问
dbLink是简称,全称是databaselink。database link是定义一个数据库到另一个数据库的路径的对象,database link允许你查询远程表及执行远程程序。在任何分布式环境里,database都是必要的。另外要注意的是database link是单向的连接。在创建dat…...

点赞收藏功能修复
从昨天下午开始修复因为逻辑错误导致的系统性错误,开始了大规模的修改。。。。。。。。现在基本修复了:计划广场唯一性,点赞,收藏。理论上已经全都修复了,但是还需要测试剩下测试的功能:举报申述功能...
)
用STM32F103C8T6做个触摸感应示波器?手把手教你ADC采集+OLED波形显示(附完整代码)
用STM32F103C8T6打造触摸感应示波器:从ADC采集到OLED波形显示的趣味实践 在嵌入式开发领域,将枯燥的技术参数转化为可视化的交互体验,往往能激发学习者的深层兴趣。今天我们要实现的,不仅是一个简单的信号采集系统,而是…...

Taotoken平台在持续高并发调用下的稳定性与容灾能力观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台在持续高并发调用下的稳定性与容灾能力观察 在构建依赖大模型能力的应用时,服务的稳定性是开发者关心的核…...

【亲测免费】【免费下载】 探索视觉新边界:RexVision视觉框架深度解析
探索视觉新边界:RexVision视觉框架深度解析 【下载地址】RexVision视觉框架下载仓库 本仓库提供了一个名为“RexVision视觉框架”的资源文件下载。该框架是一个视觉处理相关的工具或库,用户只需将文件放置在D盘的根目录下即可进行编译和使用 项目地址:…...

Prism `IContainerRegistry` 详细调查与讲解
Prism IContainerRegistry 详细调查与讲解 1. 什么是 IContainerRegistry? IContainerRegistry 是 Prism Library 提供的依赖注入容器抽象注册接口。它位于 Prism.Ioc 命名空间。 作用:在 PrismApplication 的 protected override void RegisterTypes(IC…...

产业园区如何构建智能化科技服务体系?
观点作者:科易网-国家科技成果转化(厦门)示范基地 一、现状概述(成效与短板) 近年来,我国产业园区在推动科技成果转化、促进科技创新方面发挥了显著作用。然而,随着数智化浪潮的兴起,…...

初创团队如何利用 Taotoken 模型广场快速进行 AI 技术选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用 Taotoken 模型广场快速进行 AI 技术选型 对于资源有限的初创团队而言,在产品原型阶段快速验证想法是…...
:准确率、溯源性、逻辑连贯性三维评分,这份清单决定你是否该立刻升级)
NotebookLM问答功能终极评估报告(基于217份真实研究笔记测试):准确率、溯源性、逻辑连贯性三维评分,这份清单决定你是否该立刻升级
更多请点击: https://intelliparadigm.com 第一章:NotebookLM问答功能终极评估报告概览 NotebookLM 是 Google 推出的基于用户上传文档构建个性化知识代理的 AI 工具,其核心问答能力依赖于对私有资料的深度语义理解与上下文精准锚定。本章聚…...

从谐波治理到能量回馈:深入聊聊LCL滤波器在光伏逆变器和PWM整流器里的那些关键设计
LCL滤波器设计实战:从谐波抑制到能量回馈的工程权衡 在光伏逆变器和PWM整流器设计中,电流谐波治理一直是工程师面临的核心挑战。当项目要求总谐波失真率(THD)必须低于3%时,传统L滤波器往往力不从心——要么需要超大电感量导致体积膨胀&#x…...

观察使用TaotokenTokenPlan后项目月度AI成本的变化趋势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察使用Taotoken TokenPlan后项目月度AI成本的变化趋势 对于许多采用按量计费模式的中小型项目而言,大模型API的月度支…...