利用GPT开发应用001:GPT基础知识及LLM发展
文章目录
- 一、惊艳的GPT
- 二、大语言模型LLMs
- 三、自然语言处理NLP
- 四、大语言模型LLM发展
一、惊艳的GPT
想象一下,您可以与计算机的交流速度与与朋友交流一样快。那会是什么样子?您可以创建哪些应用程序?这正是OpenAI正在助力构建的世界,他们的GPT模型为我们的设备带来了类似人类对话能力的功能。
GPT的全称,是Generative Pre-Trained Transformer(生成式预训练Transformer模型)是一种基于互联网的、可用数据来训练的、文本生成的深度学习模型。GPT与专注于下围棋或机器翻译等某一个具体任务的“小模型”不同,AI大模型更像人类的大脑。它兼具“大规模”和“预训练”两种属性,可以在海量通用数据上进行预先训练,能大幅提升AI的泛化性、通用性、实用性。
作为人工智能(AI)领域的最新进展,GPT-4(Generative Pre-trained Transformer - 4)和ChatGPT(Chat Generative Pre-trained Transformer)是基于大量数据训练的大型语言模型(Large Language Models - LLMs),使它们能够以非常高的准确性识别和生成类似人类的文本。
这些人工智能模型的影响远不止于简单的语音助手。得益于OpenAI的模型,开发者现在可以利用自然语言处理(Natural Language Processing - NLP)的力量创建了解我们需求的应用程序,这在过去曾是科幻小说。从学习并适应的创新客户支持系统到理解每个学生独特学习风格的个性化教育工具,GPT-4和ChatGPT打开了一个全新的可能性世界。
但GPT-4和ChatGPT究竟是什么?我们需要深入探讨这些AI模型的基础知识、起源和关键特征。通过理解这些模型的基本原理,您将为基于这些新强大技术构建下一代应用程序迈出重要的一步。
二、大语言模型LLMs
作为大语言模型(Large Language Models - LLMs),GPT-4和ChatGPT是自然语言处理(Natural Language Processing - NLP)领域最新的模型类型,而NLP本身是机器学习(Machine Learning - ML)和人工智能(AI)的一个子领域。因此,在我们深入了解GPT-4和ChatGPT之前,让我们快速了解一下NLP和其他相关领域。
对于人工智能有不同的定义,但其中一个更多或少得到共识的说法是,人工智能指的是开发能够执行通常需要人类智能的任务的计算机系统。根据这个定义,许多算法都属于人工智能范畴。比如,在GPS应用中的交通预测任务或者战略视频游戏中使用的基于规则的系统。从外部看,这些例子中,机器似乎需要智能来完成这些任务。
机器学习(Machine Language - ML)是人工智能(AI)的一个子集。在机器学习中,我们不试图直接实现人工智能系统所使用的决策规则。相反,我们尝试开发算法,让系统能够通过示例自我学习。自从上世纪50年代开始进行机器学习研究以来,许多机器学习算法已经在科学文献中被提出。其中,深度学习(Deep Learning - DL)算法是机器学习模型的著名示例,而GPT-4和ChatGPT是基于一种称为transformers的特定类型深度学习算法。下图展示了这些术语之间的关系。
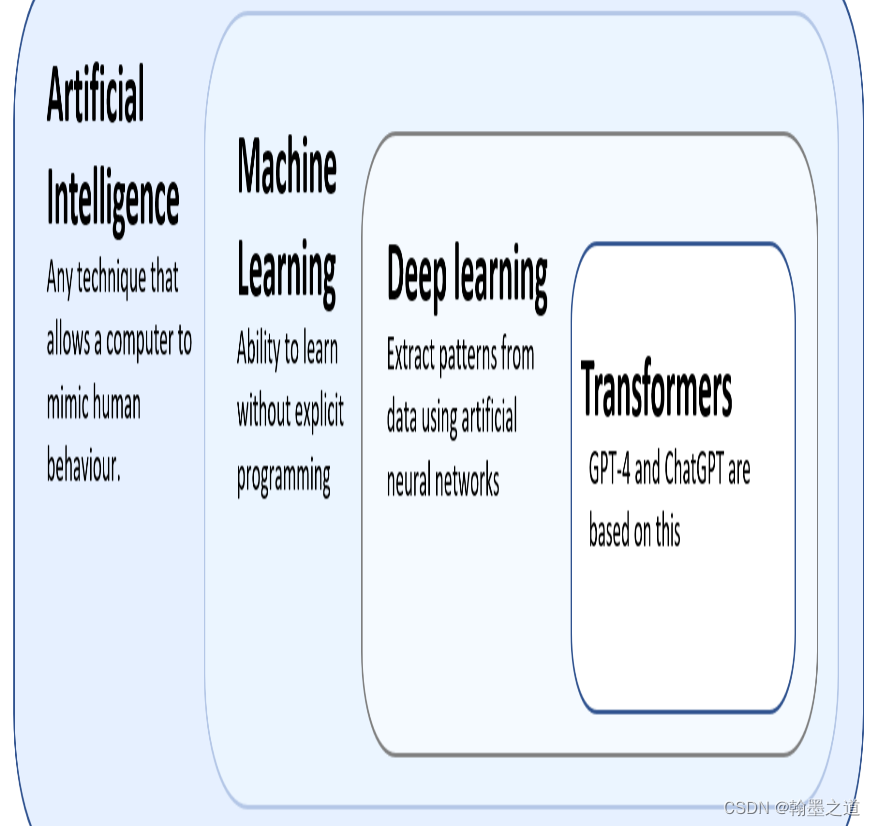
三、自然语言处理NLP
自然语言处理(Natural Language Processing - NLP)是一种人工智能应用,专注于计算机与自然人类语言文本之间的交互。现代NLP解决方案基于机器学习算法。NLP的目标是让计算机理解自然语言文本。这一目标涵盖了广泛的任务:
-
文本分类
将输入的文本划分为预定义的组别。例如,包括情感分析和主题分类等任务。 -
自动翻译
将文本从一种语言自动翻译成另一种语言。 -
问答
根据给定的文本回答问题。 -
文本生成
基于给定的输入文本(称为提示),模型生成连贯和相关的输出文本。
四、大语言模型LLM发展
正如前面提到的,大语言模型(Large Language Models - LLM)是一种试图解决文本生成任务的机器学习模型。LLMs使计算机能够理解、解释和生成人类语言,从而实现更加有效的人机交流。为了做到这一点,LLMs分析或训练大量的文本数据,从而学习句子中单词之间的模式和关系。通过给定输入文本,这种学习过程使LLMs能够对最有可能出现的下一个单词进行预测,并以此方式生成对文本输入有意义的回应。最近几个月发布的现代语言模型非常庞大,并且经过了大量的文本训练,它们现在可以直接执行大多数NLP任务,如文本分类、机器翻译、问答等。GPT-4和ChatGPT模型是两种在文本生成任务上表现优异的现代LLMs。
LLMs的发展可以追溯到数年前。它始于简单的语言模型,比如n-gram模型,它试图基于前面的单词来预测句子中的下一个单词。n-gram模型使用频率来实现这一点。预测的下一个单词是在它训练过的文本中跟随前面单词最频繁出现的单词。虽然这种方法是一个良好的开端,但它需要在理解上下文和语法方面有所改进,以避免生成不一致的文本。
为了提高这些n-gram模型的性能,引入了更先进的学习算法,包括循环神经网络(Recurrent Neural Networks - RNN)和长短期记忆网络(long short term memory networks - LSTM)。这些模型能够学习更长的序列并比n-gram模型更好地分析上下文,但它们仍然需要帮助以高效处理大量数据。这些类型的循环模型长时间以来一直是最高效的模型,因此在自动机器翻译等工具中被广泛使用。
相关文章:
利用GPT开发应用001:GPT基础知识及LLM发展
文章目录 一、惊艳的GPT二、大语言模型LLMs三、自然语言处理NLP四、大语言模型LLM发展 一、惊艳的GPT 想象一下,您可以与计算机的交流速度与与朋友交流一样快。那会是什么样子?您可以创建哪些应用程序?这正是OpenAI正在助力构建的世界&#x…...

Golang Ants 构建协程池
构建的协程池实现两个目标: 1、限制协程池里开启的协程数量 2、当任务数大于协程数时,一个协程可以同时处理多个任务 3、监控是哪个协程ID处理了具体的任务 package mainimport ("fmt""runtime""strconv""string…...
)
【金三银四】面试题汇总(持续编写中)
Java八股文面试题汇总(持续编写中~) Java基础集合JUCJVM 数据库MySQLRedis 框架篇SSMSpringBoot 数据结构与算法数据结构与算法--汇总篇27道基础算法题,学完让你对算法有豁然开朗的感觉(推荐小白) 消息中间件RabbitMQK…...

Hive的数据存储
Hive的数据存储在HDFS的:/user/hive/warehouse中 The /user folder in HDFS is a directory typically used to store user-specific data and configurations. It serves as the home directory for Hadoop users, analogous to the /home directory in Unix-like …...
ORACLE 如何使用dblink实现跨库访问
dbLink是简称,全称是databaselink。database link是定义一个数据库到另一个数据库的路径的对象,database link允许你查询远程表及执行远程程序。在任何分布式环境里,database都是必要的。另外要注意的是database link是单向的连接。在创建dat…...
Sentinel 面试题及答案整理,最新面试题
Sentinel的流量控制规则有哪些,各自的作用是什么? Sentinel的流量控制规则主要包括以下几种: 1、QPS(每秒查询量)限流: 限制资源每秒的请求次数,适用于控制高频访问。 2、线程数限流…...

Qt在windows编译hiredis依赖库
目录 0 前言1 Qt安装遇到的问题2 hiredis源码下载2.0 redis源码下载2.1 hiredis源码下载2.2 编译hiredis源码2.3 遇到的问题列表参考资料0 前言 当前参与的项目需要用Qt对redis进行操作,以前没玩过这块,顺手记下笔记梳理起来~ 1 Qt安装 安装版本下载:https://download.qt…...

【工作向】protobuf编译生成pb.cc和pb.py文件
序言 首先通过protoc --version查看protoc版本,避免pb文件生成方和使用方版本不一致 1. 生成pb.cc 生成命令 protoc -I${proto_file_dir} --cpp_out${pb_file_dir} *.proto参数: -I表示 proto 文件的路径; --cpp_out 表示输出路径ÿ…...
)
android 快速实现 垂直SeekBar(VerticalSeekBar)
1.话不多说上源码: package com.example.widget;import android.content.Context; import android.graphics.Canvas; import android.util.AttributeSet; import android.view.MotionEvent;/*** Class to create a vertical slider*/ public class VerticalSeekBar…...
算法刷题day23:双指针
目录 引言概念一、牛的学术圈I二、最长连续不重复序列三、数组元素的目标和四、判断子序列五、日志统计六、统计子矩阵 引言 关于这个双指针算法,主要是用来处理枚举子区间的事,时间复杂度从 O ( N 2 ) O(N^2) O(N2) 降为 O ( N ) O(N) O(N) …...

学术论文GPT的源码解读与二次开发:从ChatPaper到gpt_academic
前言 本文的前两个部分最早是属于此旧文的《学术论文GPT的源码解读与微调:从ChatPaper到七月论文审稿GPT第1版》,但为了每一篇文章各自的内容更好的呈现,于是我今天做了以下三个改动 原来属于mamba第五部分的「Mamba近似工作之线性Transfor…...
报表生成器FastReport .Net用户指南:表达式(下)
在上一篇文章《报表生成器FastReport .Net用户指南:表达式(上)》中,我们已经介绍了表达式中的表达式编辑器、引用报告对象、使用 .Net 函数、数据元素参考这四部分,接下来让我们继续介绍表达式中的:引用数据…...
JavaScript极速入门(1)
初识JavaScript JavaScript是什么 JavaScript(简称JS),是一个脚本语言,解释型或者即时编译型语言.虽然它是作为开发Web页面的脚本语言而著名,但是也应用到了很多非浏览器的环境中. 看似这门语言叫JavaScript,其实在最初发明之初,这门语言的名字其实是在蹭Java的热度,实际上和…...

鸿蒙Harmony应用开发—ArkTS声明式开发(通用属性:浮层)
设置组件的遮罩文本。 说明: 从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 overlay overlay(value: string | CustomBuilder, options?: { align?: Alignment; offset?: { x?: number; y?: number } })…...

Meta AI移动设备上部署LLM的新框架MobileLLM
Meta AI 研究团队推出的 MobileLLM 标志着大语言模型(LLMs)朝着模拟人类理解和生成自然语言迈出了革命性的一步。LLMs 在处理和分析大量数据集方面的能力已经显著影响了自动化客户服务、语言翻译和内容创作等多个领域。然而,由于传统 LLMs 在计算和存储资源方面的需求庞大,…...

使用Tesseract-OCR对PDF等图片文件进行文字识别
安装 用 Homebrew 来安装 Tesseract brew install tesseract 2. 完成 tessearact 的安装后,还需要安装中文数据包,执行以下两个操作, brew info tesseract 执行这个指令的目的,是找到 Homebrew 把 tesseract 安装在文件夹内&am…...

部署YOLOv8模型的实用常见场景
可以的话,GitHub上点个小心心,翻不了墙的xdm,csdn也可以点个赞,谢谢啦 车流量检测(开源代码github): test3 meiqisheng/YOLOv8-DeepSORT-Object-Tracking (github.com) 车牌检测࿰…...

SpringBoot缓存
目录 缓存支持 缓存集成 redis缓存集成 缓存支持 Spring 框架只提供抽象,不提供具体的缓存存储,底层需要依赖第三方存储组件,如果当前应用没有注册CacheManager 或者 CacheResolver 实例,Spring Boot 会按以下缓存组件的顺序来…...
STC89C52串口通信详解
目录 前言 一.通信基本原理 1.1串行通信与并行通信 1.2同步通信和异步通信 1.2.1异步通信 1.2.2同步通信 1.3单工、半双工与全双工通信 1.4通信速率 二.串口通信简介 2.1接口标准 2.2串口内部结构 2.3串口相关寄存器 三.串口工作方式 四.波特率计算 五.串口初始化步骤 六.实验…...

基础算法|线性结构|前缀和学习
参考文章: https://blog.csdn.net/weixin_72060925/article/details/127835303 二维数组的前缀和练习: 这里要注意的地方就是求子矩阵和的时候,这里要减去的是x1-1,y1-1的部分,因为所求的目标值是包括边界的 //前缀…...

告别黑盒调试:手把手教你用ControlDesk的Bus Navigator虚拟通道抓取CAN信号
告别黑盒调试:手把手教你用ControlDesk的Bus Navigator虚拟通道抓取CAN信号 在汽车电子开发中,硬件在环(HIL)测试往往面临一个典型困境:当物理ECU或CAN卡尚未就绪时,如何提前开展总线信号验证?传…...

性能优化实战:在Unity项目里管理多个Video Player,如何避免内存泄漏和卡顿?
Unity多视频管理实战:规避内存泄漏与卡顿的深度优化策略 在沉浸式游戏体验和交互式AR/VR应用中,视频内容已成为提升用户参与度的关键要素。但当场景中同时存在多个Video Player组件时,开发者往往会遭遇突如其来的性能断崖——内存占用飙升、播…...

Rdkit实战:从2D到3D,解锁分子构象生成与优化的全流程
1. 从2D到3D:分子构象生成的基础概念 第一次接触分子构象生成时,我完全被各种术语搞晕了——距离几何、ETKDG、MMFF这些名词听起来就像天书。直到用RDKit实际操作了几次,才发现这个过程其实就像搭积木:先有个平面设计图ÿ…...

别再只刷固件了!深入Proxmark3硬件层:AT91SAM7S512芯片与Bootrom.bin的救砖原理详解
深入Proxmark3硬件层:AT91SAM7S512芯片与Bootrom.bin的救砖原理详解 当你的Proxmark3设备突然"四灯全亮",USB连接失效,变成一块"砖头"时,大多数教程只会告诉你"短接测试点,用J-Link烧录bootr…...
)
从SPI到QSPI:你的Flash读写速度慢?可能是模式没选对(以W25Q128JV为例)
从SPI到QSPI:解锁W25Q128JV Flash的隐藏性能 在嵌入式系统开发中,存储器的读写速度往往是制约整体性能的关键瓶颈。许多工程师在使用常见的SPI Flash芯片如W25Q128JV时,可能已经习惯了标准的SPI接口操作,却不知道通过简单的模式切…...

深度解析Windows Subsystem for Android:企业级跨平台运行时架构与最佳实践
深度解析Windows Subsystem for Android:企业级跨平台运行时架构与最佳实践 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA Windows Subsystem f…...
详解:Kupffer Cells、HSCs与LSECs如何重建真实肝脏微环境并提升NASH与ADME-Tox研究准确性)
人肝非实质细胞(NPC)详解:Kupffer Cells、HSCs与LSECs如何重建真实肝脏微环境并提升NASH与ADME-Tox研究准确性
摘要:传统单一肝细胞模型在药物肝毒性评价、NASH机制研究以及肝纤维化研究中,长期存在体外快速去分化、病理表型不完整以及与临床结果偏差较大的问题。近年来,人肝非实质细胞(Hepatic Non-Parenchymal Cells,NPC&#…...

在不确定的命题环境中,如何建立稳定的考研数学备考体系
近两年,考研数学始终是考研备考中讨论度较高的科目。每年考试结束后,关于试卷难度、题型变化、计算量以及复习节奏的讨论都会迅速升温。对考生而言,真正需要关注的并不只是某一年试题“偏难”还是“偏易”,而是在变化之中建立一套…...

别再死记硬背了!用Python模拟D触发器与JK触发器波形,5分钟搞定时序逻辑难题
用Python动态模拟时序逻辑:D触发器与JK触发器的可视化实践 时序逻辑电路是数字系统设计的核心基础,但对于许多初学者而言,纯理论推导和手工绘制波形图往往令人望而生畏。本文将带你用Python构建一个直观的触发器模拟系统,通过代码…...

【NS-3实战指南】NetAnim可视化调试与网络拓扑分析
1. NetAnim入门:从安装到第一个动画 第一次接触NS-3仿真的人往往会被命令行输出的数字搞得头晕眼花。记得我刚开始做无线网络仿真时,盯着终端里不断跳动的数据包统计数字,完全想象不出节点之间到底是怎么通信的。直到发现了NetAnim这个神器&a…...