高效加载大文件(pandas+dask)
一、仅用pd加载大文件(iterator、chunksize)
要使用Pandas进行高效加载超大文件,我们通常会利用其内置的分块(chunk)处理功能。不过,请注意,Pandas本身并不支持多线程读取文件;它更倾向于单线程中进行块处理。尽管如此,对于优化加载超大文本文件这一场景,可以通过以下方式实现提速:
- 预先知道或估计每个数据块的行数或大小。
- 利用
pandas.read_csv等方法的chunksize参数来迭代读取数据。- 使用多进程而非多线程来并行处理每一块数据(如果确实需要并发执行),因为Python中GIL(全局解释器锁)限制了同一时刻只能有一个线程执行Python字节码。
下面是一个示例代码。请注意,在此示例中没有直接采用多进程来读取文件分片。相反,我们首先以流式模式逐步载入小数据块,并在必要时可应用某种形式的并行处理框架(如Dask)针对这些已经被逐步载入内存中DataFrame对象进行后续操作。
import pandas as pd
class EfficientTextLoader:"""采用pandas高效加载超大文本文件"""def __init__(self, filepath, chunksize=10000):"""初始化:param filepath: 文件路径:param chunksize: 每次迭代加载的行数,默认设定为10000条记录/行注意:根据你系统和硬件配置调整chunksize大小以获得最佳性能。较小值减少内存消耗但增加I/O频率;较大值则反之。"""self.filepath = filepath# Pandas 从版本0.24 开始支持 TextFileReader 属性 'chunksize'.# 当使用 read_csv 等函数与 'iterator=True' 结合时,# 设置 'chunksize' 可返回 TextFileReader 对象供迭代.self.chunk_size = chunksizedef load(self):"""按照指定chunks逐渐地、有效地装载整个文档"""reader = pd.read_csv(self.filepath,sep='\t', # 假设是制表符分隔的TXT 文档;根据需求而定 iterator=True,header=None,chunksize=self.chunk_size) # 逐行加载chunks = []try:while True:chunks.append(next(reader)) ## 这里可以添加额外代码对当前Chunk进行预处理或转换 ##except StopIteration: print("Iteration is stopped.")data_concatenated=pd.concat(chunks,axis=0) return data_concatenated上述代码做出了几点修改与优化:
1. 使用
pd.read_csv()的iterator=True和chunkSize=参数创建一个可循环遍历所有区段(chunk) 的阅读器 (reader),从而允许手动控制流水线(pipeline) 中各部分内容何时被具体导入到RAM之中。2. 利用 Python 的异常控制结构完成对全部区段(chunk) 数据依次导入直至结束——当无更多内容可供导出(
StopIteration)时跳出循环,并将所有已经在列表(chunks) 中累积起来单元结果合成(concatenate)为最终 DataFrame 对象给予输出。备注: 而关于真正意义上“利用Panda和* 多线性 *” —— 实际情况复杂许多且易受 Python GIL 影响;通常建议替代方案比如 Dask 来达成类似需求。
普通的pandas加载多个文件,pandas加载文件不支持通配符,因此需要glob包来辅助
import pandas as pd import glob # 获取所有匹配路径下CSV格式文档列表 files = glob.glob('path/to/your/files/data_*.csv') # 循环遍历每个文档, 读取后添加至列表中 dfs = [pd.read_csv(file) for file in files] # 将这些 DataFrame 合并成一个 DataFrame (注意: 确保各DataFrame结构相同) df_combined = pd.concat(dfs)pandas 在加载3个2G大小文件时,耗时约为 80s
二、Dask + pd 加载处理大文件
使用Dask优化原有基于Pandas的代码以提高处理超大文件的能力是一个很好的选择。Dask是Python中一个流行且强大的并行计算库,它可以无缝扩展Numpy、Pandas等数据处理操作到分布式计算环境中。
下面展示如何用Dask重新实现之前讨论过加载超大文本文件功能:
import dask.dataframe as ddclass DaskTextLoader:def __init__(self, filepath, blocksize=1024 * 1024 * 128): # 默认块大小为128MB"""使用 Dask 初始化加载器。:param filepath: 要读取的文件路径。:param blocksize: 单个块(block)读入内存时占用字节大小,默认值设定为128MB。根据你系统和硬件配置调整blocksize大小以获得最佳性能,较小值将导致更多、但管理起来较易控制(内存使用上)单元任务;较大则减少任务数量但每个任务更耗时及可能引发更高内存消耗压力。注意:该参数仅针对文本数据有效,如CSV或JSON格式。如果输入其他格式(比如Parquet)DASK将自动管理最佳块划分策略而忽略此设置项。"""self.filepath = filepathself.blocksize = blocksizedef load(self):# 加载txt/csv/json... 文件并返回dask DataFrame对象.df = dd.read_csv(self.filepath, blocksize=self.blocksize)## 这里可以添加任何必要预处理步骤 ##return df这段代码通过
dd.read_csv()函数来读取文本类型数据,并允许通过blocksize参数来控制加载到内存中每个块(chunk) 的大小。这对于处理非常庞大的文件特别有用因为它允许在不完全加载整个文件到RAM情况下进行分片并行操作。一旦得到了Dask DataFrame 对象 (
df) 后即可利用类似 Pandas 的API进行各种复杂操作与运算—例如过滤(filtering), 分组(grouping), 汇总(aggregating), 转换(transformations)—只需记住结果通常也呈现异步形态;故而在需要具体结果前须调用.compute()方法触发真正执行所有累积待办事务序列链条:result_df = df.compute() # 触发实际执行获取Pandas DataFrame结果对象result_df = df.head(5) # 触发实际执行获取Pandas DataFrame结果对象,只获取5条请注意,尽管
.compute()返回标准 Pandas DataFrame 对象包括其所含全部数据项——针对极端庞大规模集合可能会再度碰撞 内存在限制问题; 因此,在设计解决方案结构时应当谨慎试图一次性完全求解而考虑是否逐部递进或者仍然保持部分工作流程在 DASK 执行框架上面智能地选段完成具体细则需求点。
三、自定义单机/多机多线程 dask + pd 加载预处理大文件
要在单机环境中对Dask进行多进程数的控制,你可以使用
dask.distributed模块创建一个本地集群,并控制其工作进程数量。通过这种方式,你能够显式地设定并发执行任务的工作线程或进程数目。以下是如何修改上述代码来加入单机多进程控制的示例:
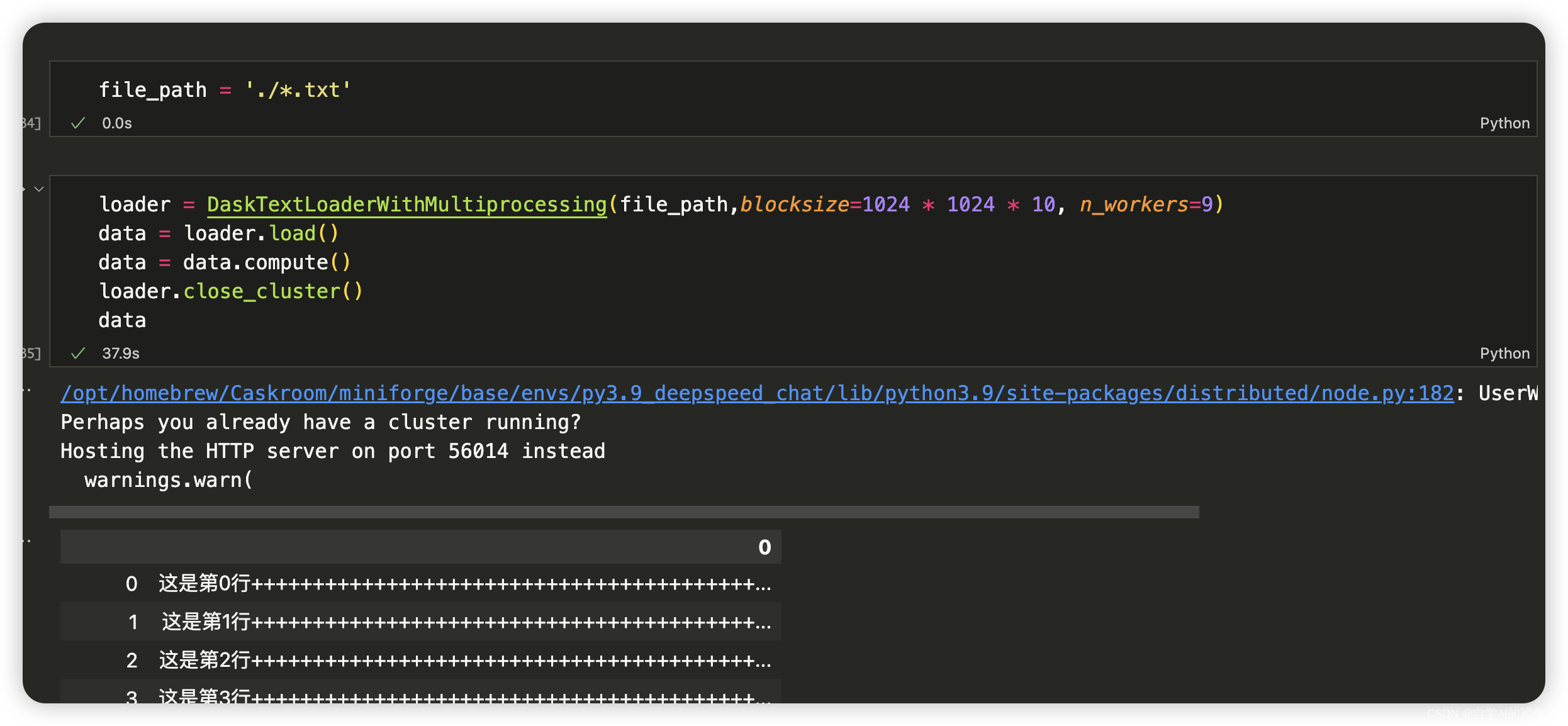
from dask.distributed import Client, LocalCluster
import dask.dataframe as ddclass DaskTextLoaderWithMultiprocessing:def __init__(self, filepath, blocksize=1024 * 1024 * 128, n_workers=4):"""使用 Dask 初始化加载器并设置多处理。:param filepath: 要读取的文件路径。:param blocksize: 单个块(block)读入内存时占用字节大小,默认值设定为128MB。根据系统和硬件配置调整blocksize大小以获得最佳性能,较小值将导致更高I/O频率但容易管理(内存使用上);较大则减少任务数量但每个任务更耗时及可能引发更高内存消耗压力。注意:该参数仅针对文本数据有效,如CSV或JSON格式。如果输入其他格式(比如Parquet)DASK将自动管理最佳块划分策略而忽略此设置项。:param n_workers: 并行工作线程/进程数,默认为4.增加此数字可并行执行更多操作,但也会增加系统资源消耗。"""self.filepath = filepathself.blocksize = blocksize# 创建本地DASK集群 cluster = LocalCluster(n_workers=n_workers)self.client = Client(cluster)def load(self):# 加载txt/csv/json... 文件并返回dask DataFrame对象.df = dd.read_csv(self.filepath, header=None, # 是否使用头sep='\t', # csv 分隔符blocksize=self.blocksize)## 这里可以添加任何必要预处理步骤 ##return df def close_cluster(self):# 关闭client和cluster self.client.close()在这段代码中,我们首先创建了一个
LocalCluster实例,并通过参数n_workers=n_worksers,指明了我们想要在集群中启用的工作者(Worker)数量即实际运行计算操作所使用到核心/线程序列总量。紧接着利用该cluster构造出 aClient, 其扮演着用户与集群之间交互接口角色方便提交相关计算任务请求等功能使命完结后续各类数据操作需求点。请注意,在完成所有需要做的计算之后调用
.close()方法关闭客户端(Clients)与服务端(Cluster),释放相关资源非常重要;特别情况下如果忘记手动关闭可能会导致程序未正常结束情形下挂起保持运行状态占据宝贵资源直至外部干预才得以解决问题。
举个完整的例子来执行该代码
首先,假设已经有了一个CSV文件
example.csv,该文件内容大致如下:
name,age,city
Alice,34,Berlin
Bob,23,London
Charlie,45,New York
现在目标是使用上面定义的Dask处理类来读取这个CSV文件,并计算年龄列(
age)的平均值。
代码示例如下:
# 使用定义好的加载器来读取数据,然后多线程处理数据。
loader = DaskTextLoaderWithMultiprocessing('example.csv', n_workers=2) ## 假设您希望用2个工作进程运行df_dask = loader.load() ## 调用load方法得到dask DataFrame对象 average_age_computed_future=df_dask.age.mean() ## 计算年龄平均值操作 (延迟执行) average_age_result=average_age_computed_future.compute() ### 触发实际执行并获取结果(阻塞直到完成)
print(f"The average age is: {average_age_result}")loader.close_cluster() ### 记住关闭集群释放资源!以上代码段展示了从头至尾创建一个可以控制单机多进程数 的
DASK Text Loader, 然后利用它去异步地读取一个CSV格式文本数据、计算某特定数值列(此处为“age”年龄字段)内所有元素平均值,并最终输出该统计结果。
使用 dask 加载多个文件
使用 Dask 加载多个文件假设你有一系列以相同模式命名(例如data_*.csv)的CSV文件想要加载:import dask.dataframe as dd# 用通配符 '*' 加载匹配到的所有 CSV 文件 df = dd.read_csv('path/to/your/files/data_*.csv')
下面是dask + pd 加载3个2g的文件,耗时约37s,n_workers指定越多,文件大小和文件数量越大,差距拉的就越大
相关文章:
高效加载大文件(pandas+dask)
一、仅用pd加载大文件(iterator、chunksize) 要使用Pandas进行高效加载超大文件,我们通常会利用其内置的分块(chunk)处理功能。不过,请注意,Pandas本身并不支持多线程读取文件;它更倾向于单线程中进行块处理…...
游戏引擎分层简介
游戏引擎分层架构(自上而下) 工具层(Tool Layer) 在一个现代游戏引擎中,我们最先看到的可能不是复杂的代码,而是各种各样的编辑器,利用这些编辑器,我们可以制作设计关卡、角色、动画…...

向爬虫而生---Redis 探究篇6<Redis的Bigkey问题介绍>
前言: 随着数据规模的增长,Redis的BigKey问题也开始显现。 BigKey问题主要指的是存储了大量数据的key,这可能给Redis的性能和可用性带来负面影响。当一个key的数据量过大时,会占用宝贵的内存资源,拖慢Redis的响应速度。此外,存储和恢复这些BigKey也会变得困难和耗时,增…...
【开源物联网平台】FastBee认证方式和MQTT主题设计
🌈 个人主页:帐篷Li 🔥 系列专栏:FastBee物联网开源项目 💪🏻 专注于简单,易用,可拓展,低成本商业化的AIOT物联网解决方案 目录 一、接入步骤 1.1 设备认证 1.2 设备交…...

Ubuntu Qt控制终端运行ros
文章目录 gnome-terminalQt 通过QProcess类Qt 通过system gnome-terminal 在Ubuntu中可以使用man gnome-terminal命令查看gnome-terminal的使用指南,也可在ubuntu manuals查看: NAMEgnome-terminal — 一个终端仿真应用.概要gnome-terminal [-e, --c…...

mysql 性能调优参数配置文件
########################################################################### ## my.cnf for MySQL 8.0.x # ## 本配置参考 https://imysql.com/my-cnf-wizard.html # ## 注意: …...

windows右键新建文件没有txt文本文档怎么办?
我碰到此问题,按照以下方法改了注册表, 重启之后就正常了(没有注销,只是单纯重启)。以下方法来自AI: 如果在注册表的 .txt 路径下没有找到 ShellNew 键,你可以尝试手动创建这个键和所需的值来恢…...

已读不回,我又玻璃心了
最近有点上火,3个询盘给我整我无语了,难道我还没修炼到家?玻璃心又出来作祟了? 客户A急火火的发我一个文件,需求内容ios客户端调整,让我按照需求给找个人处理下,我收到后抓紧时间摇人࿰…...
)
面试经典150题(105-107)
leetcode 150道题 计划花两个月时候刷完之未完成后转,今天(第2天)完成了3道(105-107)150 105.(191. 位1的个数)题目描述: 编写一个函数,输入是一个无符号整数(以二进制串的形式&am…...
javaWebssh药品进销存信息管理系统myeclipse开发mysql数据库MVC模式java编程计算机网页设计
一、源码特点 java ssh药品进销存信息管理系统是一套完善的web设计系统(系统采用ssh框架进行设计开发),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为TOM…...
计算机设计大赛 深度学习实现语义分割算法系统 - 机器视觉
文章目录 1 前言2 概念介绍2.1 什么是图像语义分割 3 条件随机场的深度学习模型3\. 1 多尺度特征融合 4 语义分割开发过程4.1 建立4.2 下载CamVid数据集4.3 加载CamVid图像4.4 加载CamVid像素标签图像 5 PyTorch 实现语义分割5.1 数据集准备5.2 训练基准模型5.3 损失函数5.4 归…...

Linux系统编程(六)高级IO
目录 1. 阻塞和非阻塞 IO 2. IO 多路转接(select、poll、epoll) 3. 存储映射 IO(mmap) 4. 文件锁(fcntl、lockf、flock) 5. 管道实例 - 池类算法 1. 阻塞和非阻塞 IO 阻塞 IO:会等待操作的…...

Python与FPGA——全局二值化
文章目录 前言一、Python全局128二、Python全局均值三、Python全局OTSU四、FPGA全局128总结 前言 为什么要进行图像二值化,rgb图像有三个通道,处理图像的计算量较大,二值化的图像极大的减少了处理图像的计算量。即便从彩色图像转成了二值化图…...

《Docker极简教程》--Docker的高级特性--Docker Compose的使用
Docker Compose是一个用于定义和运行多容器Docker应用程序的工具。它允许开发人员通过简单的YAML文件来定义应用程序的服务、网络和卷等资源,并使用单个命令来启动、停止和管理整个应用程序的容器。以下是关于Docker Compose的一些关键信息和优势: 定义…...

tidyverse去除表格中含有NA的行
在tidyverse中,特别是使用dplyr包,去除含有NA的行可以通过filter()函数结合is.na()和any()或all()函数来实现。dplyr是tidyverse的一部分,提供了一系列用于数据操作的函数,使数据处理变得更加简单和直观。 以下是一个简单的例子&…...
开源爬虫技术在金融行业市场分析中的应用与实战解析
一、项目介绍 在当今信息技术飞速发展的时代,数据已成为企业最宝贵的资产之一。特别是在${industry}领域,海量数据的获取和分析对于企业洞察市场趋势、优化产品和服务至关重要。在这样的背景下,爬虫技术应运而生,它能够高效地从互…...

使用SMTP javamail发送邮件
一、SMTP协议 SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。SMTP协议属于TCP/IP协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。使用javamail编写发送…...

Hello C++ (c++是什么/c++怎么学/c++推荐书籍)
引言 其实C基础语法基本上已经学完,早就想开始写C的博客了,却因为其他各种事情一直没开始。原计划是想讲Linux系统虚拟机安装的,后来考虑了一下还是算了,等Linux学到一定程度再开始相关博客的写作和发表吧。今天写博客想给C开个头…...

最新的前端开发技术(2024年)
关于作者: 还是大剑师兰特:曾是美国某知名大学计算机专业研究生,现为航空航海领域高级前端工程师;CSDN知名博主,GIS领域优质创作者,深耕openlayers、leaflet、mapbox、cesium,canvas࿰…...
GCN 翻译 - 2
2 FAST APROXIMATE CONVOLUTIONS ON GRAPHS 在这一章节,我们为这种特殊的的图基础的神经网络模型f(X, A)提供理论上的支持。我们考虑一个多层的图卷积网络(GCN),它通过以下方式进行层间的传播: 这里,是无…...

从编译失败到成功发布:用VS BuildTools彻底解决MSBuild“能编译不能发布”的坑
从编译到发布:彻底解决MSBuild部署.NET Framework网站的技术困境 许多.NET开发者都曾遇到过这样的场景:在命令行中能够顺利编译项目,却在尝试发布(Publish)ASP.NET网站时遭遇各种莫名错误。这种"能编译不能发布&q…...

构建部署标准化:Code-Agnostic理念在混合技术栈下的实践
1. 项目概述:一个“代码无关”的构建与部署新思路最近在折腾一个老项目的现代化改造,遇到了一个经典难题:项目里混杂着Python、Java、Node.js,甚至还有几段古老的Perl脚本。每次构建部署,都得为每种语言准备一套环境、…...

Rust嵌入式开发实战:开源机械爪控制库openclaw-rs架构解析与应用
1. 项目概述:当Rust遇上开源机械爪最近在逛GitHub的时候,偶然发现了一个挺有意思的项目——neul-labs/openclaw-rs。光看名字,你大概能猜到它是个用Rust语言写的、跟机械爪(Claw)相关的开源项目。没错,这正…...

2026春招AI人才争夺战白热化!小白程序员如何抓住13万高薪机遇?速收藏!
2026年春招显示AI领域岗位量同比增长8.7倍,成为职场新风口。具身智能岗位薪资暴增,AI科学家月薪高达13.2万元。高薪AI岗位紧缺,程序员需拥抱AI工具提升竞争力,否则面临被替代风险。AI能力已成为职场基础设施,不学AI可能…...

回溯算法:暴力枚举最优解
一、上期回顾 吃透二分查找三大模板:基础查找、左边界、右边界,掌握二分答案解题思维,有序数组最优解法全部拿下。今天正式攻克回溯算法,暴力枚举最优写法,解决排列、组合、子集、棋盘类所有搜索题。二、递归与回溯核心…...

硬件身份伪装终极指南:3分钟掌握EASY-HWID-SPOOFER的深度伪装技术
硬件身份伪装终极指南:3分钟掌握EASY-HWID-SPOOFER的深度伪装技术 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 你是否曾经遇到过这样的情况:刚买的软件因…...

Linux内核模块管理:lsmod命令详解与实战应用
1. 项目概述:从“黑盒”到“白盒”,lsmod是你的系统模块探照灯如果你在Linux世界里待过一阵子,尤其是折腾过驱动、内核或者排查过一些稀奇古怪的系统问题,那你大概率听说过或者用过lsmod这个命令。乍一看,它的名字平平…...

霍夫曼编码:让计算机学会“断舍离“的无损压缩原理,为什么Zip文件能完美还原,而JPEG会失真?霍夫曼用一棵二叉树解决了50年的压缩难题
霍夫曼编码:让计算机学会"断舍离"的无损压缩原理 副标题: 为什么Zip文件能完美还原,而JPEG会失真?霍夫曼用一棵二叉树解决了50年的压缩难题痛点:为什么压缩文件能完美还原? 你用WinRAR压缩了一个Word文档&am…...
实现代码))
告别暴力枚举:用‘换根DP’思想5步拆解GDCPC L题‘启航者’(附O(n)实现代码)
从暴力枚举到换根DP:5步拆解树上路径极值问题 在算法竞赛中,树形结构上的动态规划(DP)问题一直是考察重点,而"换根DP"作为一种高效解决树上路径相关问题的技巧,能帮助我们将O(n)的暴力枚举优化到…...

向量数据库在 AI Agent Harness Engineering 记忆模块中的关键作用
向量数据库在 AI Agent Harness Engineering 记忆模块中的关键作用 一、引言 钩子 你有没有遇到过这样的场景:花了3天时间搭了一个专属的AI学习助理Agent,刚上线的时候你告诉它“我对Python异步编程完全不熟悉,以后给我的讲解要尽量基础,不要跳过概念”,它当时答应的好好…...