【Python学习笔记】22.Python3 数据结构
前言
本章节我们主要结合前面所学的知识点来介绍Python数据结构。
列表
Python中列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和元组不能。
以下是 Python 中列表的方法:
| 方法 | 描述 |
|---|---|
| list.append(x) | 把一个元素添加到列表的结尾,相当于 a[len(a):] = [x]。 |
| list.extend(L) | 通过添加指定列表的所有元素来扩充列表,相当于 a[len(a):] = L。 |
| list.insert(i, x) | 在指定位置插入一个元素。第一个参数是准备插入到其前面的那个元素的索引,例如 a.insert(0, x) 会插入到整个列表之前,而 a.insert(len(a), x) 相当于 a.append(x) 。 |
| list.remove(x) | 删除列表中值为 x 的第一个元素。如果没有这样的元素,就会返回一个错误。 |
| list.pop([i]) | 从列表的指定位置移除元素,并将其返回。如果没有指定索引,a.pop()返回最后一个元素。元素随即从列表中被移除。(方法中 i 两边的方括号表示这个参数是可选的,而不是要求你输入一对方括号,你会经常在 Python 库参考手册中遇到这样的标记。) |
| list.clear() | 移除列表中的所有项,等于del a[:]。 |
| list.index(x) | 返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误。 |
| list.count(x) | 返回 x 在列表中出现的次数。 |
| list.sort() | 对列表中的元素进行排序。 |
| list.reverse() | 倒排列表中的元素。 |
| list.copy() | 返回列表的浅复制,等于a[:]。 |
下面示例演示了列表的大部分方法:
实例
>>> a = [66.25, 333, 333, 1, 1234.5]
>>> print(a.count(333), a.count(66.25), a.count('x'))
2 1 0
>>> a.insert(2, -1)
>>> a.append(333)
>>> a
[66.25, 333, -1, 333, 1, 1234.5, 333]
>>> a.index(333)
1
>>> a.remove(333)
>>> a
[66.25, -1, 333, 1, 1234.5, 333]
>>> a.reverse()
>>> a
[333, 1234.5, 1, 333, -1, 66.25]
>>> a.sort()
>>> a
[-1, 1, 66.25, 333, 333, 1234.5]
注意:类似 insert, remove 或 sort 等修改列表的方法没有返回值。
将列表当做堆栈使用
列表方法使得列表可以很方便的作为一个堆栈来使用,堆栈作为特定的数据结构,最先进入的元素最后一个被释放(后进先出)。用 append() 方法可以把一个元素添加到堆栈顶。用不指定索引的 pop() 方法可以把一个元素从堆栈顶释放出来。例如:
实例
>>> stack = [3, 4, 5]
>>> stack.append(6)
>>> stack.append(7)
>>> stack
[3, 4, 5, 6, 7]
>>> stack.pop()
7
>>> stack
[3, 4, 5, 6]
>>> stack.pop()
6
>>> stack.pop()
5
>>> stack
[3, 4]
将列表当作队列使用
也可以把列表当做队列用,只是在队列里第一加入的元素,第一个取出来;但是拿列表用作这样的目的效率不高。在列表的最后添加或者弹出元素速度快,然而在列表里插入或者从头部弹出速度却不快(因为所有其他的元素都得一个一个地移动)。
实例
>>> from collections import deque
>>> queue = deque(["Eric", "John", "Michael"])
>>> queue.append("Terry") # Terry arrives
>>> queue.append("Graham") # Graham arrives
>>> queue.popleft() # The first to arrive now leaves
'Eric'
>>> queue.popleft() # The second to arrive now leaves
'John'
>>> queue # Remaining queue in order of arrival
deque(['Michael', 'Terry', 'Graham'])
列表推导式
列表推导式提供了从序列创建列表的简单途径。通常应用程序将一些操作应用于某个序列的每个元素,用其获得的结果作为生成新列表的元素,或者根据确定的判定条件创建子序列。
每个列表推导式都在 for 之后跟一个表达式,然后有零到多个 for 或 if 子句。返回结果是一个根据表达从其后的 for 和 if 上下文环境中生成出来的列表。如果希望表达式推导出一个元组,就必须使用括号。
这里我们将列表中每个数值乘三,获得一个新的列表:
>>> vec = [2, 4, 6]
>>> [3*x for x in vec]
[6, 12, 18]
现在我们玩一点小花样:
>>> [[x, x**2] for x in vec]
[[2, 4], [4, 16], [6, 36]]
这里我们对序列里每一个元素逐个调用某方法:
实例
>>> freshfruit = [' banana', ' loganberry ', 'passion fruit ']
>>> [weapon.strip() for weapon in freshfruit]
['banana', 'loganberry', 'passion fruit']
我们可以用 if 子句作为过滤器:
>>> [3*x for x in vec if x > 3]
[12, 18]
>>> [3*x for x in vec if x < 2]
[]
以下是一些关于循环和其它技巧的演示:
>>> vec1 = [2, 4, 6]
>>> vec2 = [4, 3, -9]
>>> [x*y for x in vec1 for y in vec2]
[8, 6, -18, 16, 12, -36, 24, 18, -54]
>>> [x+y for x in vec1 for y in vec2]
[6, 5, -7, 8, 7, -5, 10, 9, -3]
>>> [vec1[i]*vec2[i] for i in range(len(vec1))]
[8, 12, -54]
列表推导式可以使用复杂表达式或嵌套函数:
>>> [str(round(355/113, i)) for i in range(1, 6)]
['3.1', '3.14', '3.142', '3.1416', '3.14159']
嵌套列表解析
Python的列表还可以嵌套。
以下实例展示了3X4的矩阵列表:
>>> matrix = [
... [1, 2, 3, 4],
... [5, 6, 7, 8],
... [9, 10, 11, 12],
... ]
以下实例将3X4的矩阵列表转换为4X3列表:
>>> [[row[i] for row in matrix] for i in range(4)]
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
以下实例也可以使用以下方法来实现:
>>> transposed = []
>>> for i in range(4):
... transposed.append([row[i] for row in matrix])
...
>>> transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
另外一种实现方法:
>>> transposed = []
>>> for i in range(4):
... # the following 3 lines implement the nested listcomp
... transposed_row = []
... for row in matrix:
... transposed_row.append(row[i])
... transposed.append(transposed_row)
...
>>> transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
del 语句
使用 del 语句可以从一个列表中根据索引来删除一个元素,而不是值来删除元素。这与使用 pop() 返回一个值不同。可以用 del 语句从列表中删除一个切割,或清空整个列表(我们以前介绍的方法是给该切割赋一个空列表)。例如:
>>> a = [-1, 1, 66.25, 333, 333, 1234.5]
>>> del a[0]
>>> a
[1, 66.25, 333, 333, 1234.5]
>>> del a[2:4]
>>> a
[1, 66.25, 1234.5]
>>> del a[:]
>>> a
[]
也可以用 del 删除实体变量:
>>> del a
元组和序列
元组由若干逗号分隔的值组成,例如:
>>> t = 12345, 54321, 'hello!'
>>> t[0]
12345
>>> t
(12345, 54321, 'hello!')
>>> # Tuples may be nested:
... u = t, (1, 2, 3, 4, 5)
>>> u
((12345, 54321, 'hello!'), (1, 2, 3, 4, 5))
如你所见,元组在输出时总是有括号的,以便于正确表达嵌套结构。在输入时可能有或没有括号, 不过括号通常是必须的(如果元组是更大的表达式的一部分)。
集合
集合是一个无序不重复元素的集。基本功能包括关系测试和消除重复元素。
可以用大括号({})创建集合。注意:如果要创建一个空集合,你必须用 set() 而不是 {} ;后者创建一个空的字典,下一节我们会介绍这个数据结构。
以下是一个简单的演示:
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # 删除重复的
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # 检测成员
True
>>> 'crabgrass' in basket
False>>> # 以下演示了两个集合的操作
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a # a 中唯一的字母
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # 在 a 中的字母,但不在 b 中
{'r', 'd', 'b'}
>>> a | b # 在 a 或 b 中的字母
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 在 a 和 b 中都有的字母
{'a', 'c'}
>>> a ^ b # 在 a 或 b 中的字母,但不同时在 a 和 b 中
{'r', 'd', 'b', 'm', 'z', 'l'}
集合也支持推导式:
>>> a = {x for x in 'abracadabra' if x not in 'abc'}
>>> a
{'r', 'd'}
字典
另一个非常有用的 Python 内建数据类型是字典。
序列是以连续的整数为索引,与此不同的是,字典以关键字为索引,关键字可以是任意不可变类型,通常用字符串或数值。
理解字典的最佳方式是把它看做无序的键=>值对集合。在同一个字典之内,关键字必须是互不相同。
一对大括号创建一个空的字典:{}。
这是一个字典运用的简单例子:
>>> tel = {'jack': 4098, 'sape': 4139}
>>> tel['guido'] = 4127
>>> tel
{'sape': 4139, 'guido': 4127, 'jack': 4098}
>>> tel['jack']
4098
>>> del tel['sape']
>>> tel['irv'] = 4127
>>> tel
{'guido': 4127, 'irv': 4127, 'jack': 4098}
>>> list(tel.keys())
['irv', 'guido', 'jack']
>>> sorted(tel.keys())
['guido', 'irv', 'jack']
>>> 'guido' in tel
True
>>> 'jack' not in tel
False
构造函数 dict() 直接从键值对元组列表中构建字典。如果有固定的模式,列表推导式指定特定的键值对:
>>> dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
{'sape': 4139, 'jack': 4098, 'guido': 4127}
此外,字典推导可以用来创建任意键和值的表达式词典:
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
如果关键字只是简单的字符串,使用关键字参数指定键值对有时候更方便:
>>> dict(sape=4139, guido=4127, jack=4098)
{'sape': 4139, 'jack': 4098, 'guido': 4127}
遍历技巧
在字典中遍历时,关键字和对应的值可以使用 items() 方法同时解读出来:
>>> knights = {'gallahad': 'the pure', 'robin': 'the brave'}
>>> for k, v in knights.items():
... print(k, v)
...
gallahad the pure
robin the brave
在序列中遍历时,索引位置和对应值可以使用 enumerate() 函数同时得到:
>>> for i, v in enumerate(['tic', 'tac', 'toe']):
... print(i, v)
...
0 tic
1 tac
2 toe
同时遍历两个或更多的序列,可以使用 zip() 组合:
>>> questions = ['name', 'quest', 'favorite color']
>>> answers = ['lancelot', 'the holy grail', 'blue']
>>> for q, a in zip(questions, answers):
... print('What is your {0}? It is {1}.'.format(q, a))
...
What is your name? It is lancelot.
What is your quest? It is the holy grail.
What is your favorite color? It is blue.
要反向遍历一个序列,首先指定这个序列,然后调用 reversed() 函数:
>>> for i in reversed(range(1, 10, 2)):
... print(i)
...
9
7
5
3
1
要按顺序遍历一个序列,使用 sorted() 函数返回一个已排序的序列,并不修改原值:
>>> basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
>>> for f in sorted(set(basket)):
... print(f)
...
apple
banana
orange
pear
相关文章:

【Python学习笔记】22.Python3 数据结构
前言 本章节我们主要结合前面所学的知识点来介绍Python数据结构。 列表 Python中列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和元组不能。 以下是 Python 中列表的方法…...
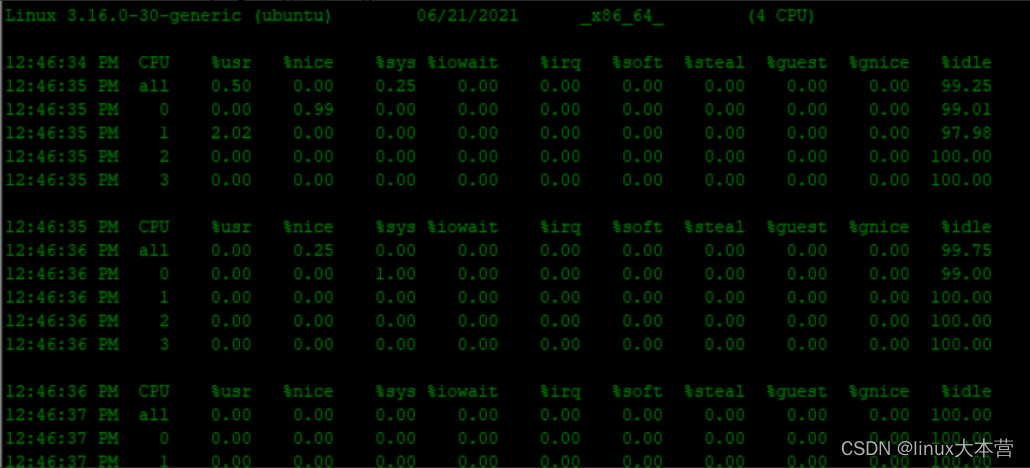
一文搞懂 什么是CPU上下文?为什么要切换?如何减少切换?
最近经常有小伙伴问到的一些问题,比较集中的是关于CPU切换. 实际用C/C,go开发,你会特别注意内存和CPU的使用情况,那些对于CPU使用情况特别关注,或者性能特别关注的朋友可以看看这篇文章,相信看完结尾的示例…...
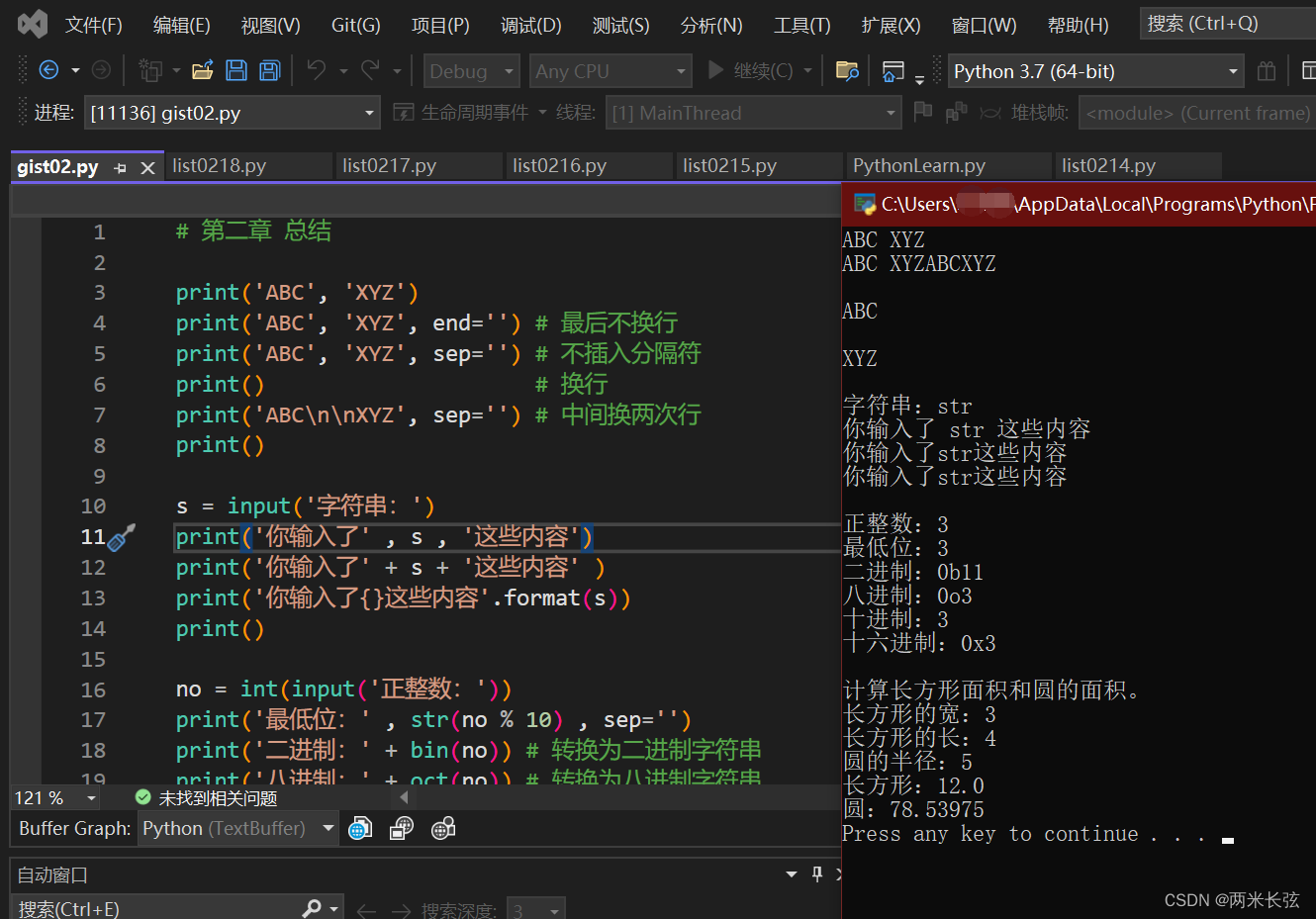
【Python】Python学习笔记(二)基本输入输出
Python娘来源:https://next.rikunabi.com/tech/docs/ct_s03600.jsp?p002412 目录print()函数不进行自动换行的print()函数打印输出多个字符串只进行换行input()函数使用format方法格式化字符串字符串与数值转换字符串转换为数值数值转换为字符串总结参考资料print(…...

LeetCode刷题系列 -- 724. 寻找数组的中心下标
给你一个整数数组 nums ,请计算数组的 中心下标 。数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。如果中心下标位于数组最左端,那么左侧数之和视为 0 ,因为在下标的左侧不存在元素。这一点对于…...

Linux编辑器vim
本文已收录至《Linux知识与编程》专栏! 作者:ARMCSKGT 演示环境:CentOS 7 目录 前言 正文 vim常用方式 进入vim 退出vim vim基本模式及模式功能 命令模式 插入模式 底行模式 替换模式 视图模式 配置vim 自己配置vim 自动化配置…...

基于“python+”潮汐、风驱动循环、风暴潮等海洋水动力模拟
查看原文>>>基于“python”潮汐、风驱动循环、风暴潮等海洋水动力模拟ADCIRC是新一代海洋水动力计算模型,它采用了非结构三角形网格广义波动连续方程的设计,在提高计算精确度的同时还减小了计算时间。被广泛应用于:模拟潮汐和风驱动…...
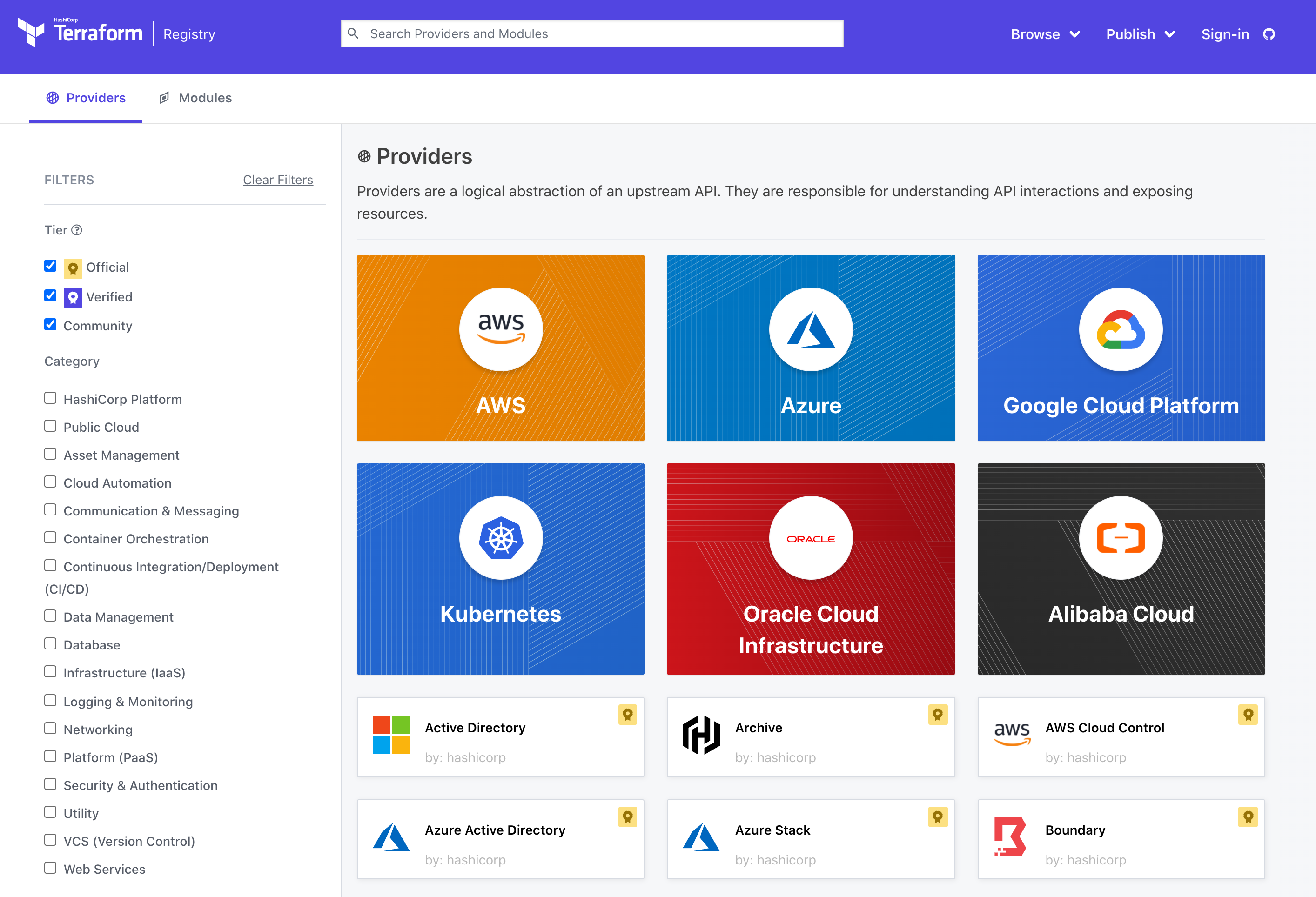
《Terraform 101 从入门到实践》 第二章 Providers插件管理
《Terraform 101 从入门到实践》这本小册在南瓜慢说官方网站和GitHub两个地方同步更新,书中的示例代码也是放在GitHub上,方便大家参考查看。 不怕出身低,行行出状元。 插件 Terraform可以对多种平台的多种资源进行管理,这个是通过…...
)
03- pandas 数据库可视化 (机器学习)
pandas库的亮点: 一个快速、高效的DataFrame对象,用于数据操作和综合索引;用于在内存数据结构和不同格式之间读写数据的工具:CSV和文本文件、Microsoft Excel、SQL数据库和快速HDF 5格式;智能数据对齐和丢失数据的综合处理&#…...
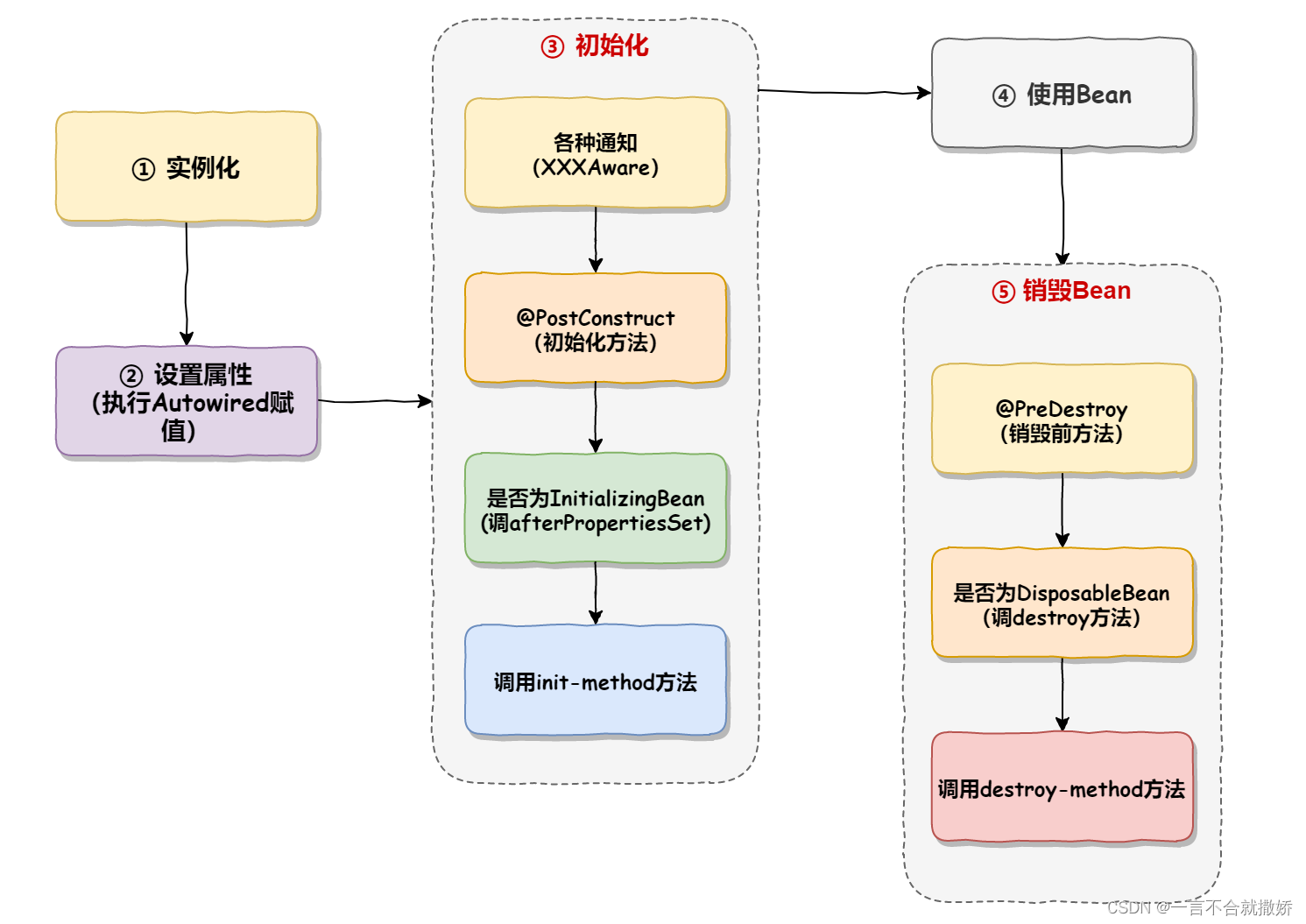
Spring为什么这么火 之 Bean的6种作用域和Bean的生命周期
1、Bean的作用域 1.1、什么是作用域? 限定程序中变量的可用范围叫做作用域,或者说在源代码中定义变量的某个区域就叫做作用域 1.2、Bean的6种作用域 singleton:单例作用域prototype:原型作用域【多例作用域】request࿱…...

【CSS面试题】2023前端最新版css模块,高频15问
🥳博 主:初映CY的前说(前端领域) 🌞个人信条:想要变成得到,中间还有做到! 🤘本文核心:博主收集的CSS面试题 目录 一、CSS必备面试题 1.CSS3新特性 2.CSS实现元素两个盒子垂…...

SpringCloud-Netflix学习笔记10——Hystrix实现服务熔断
一、概述 1、分布式系统面临的问题 复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免的失败! 2、服务雪崩 多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B 和微服务C又…...
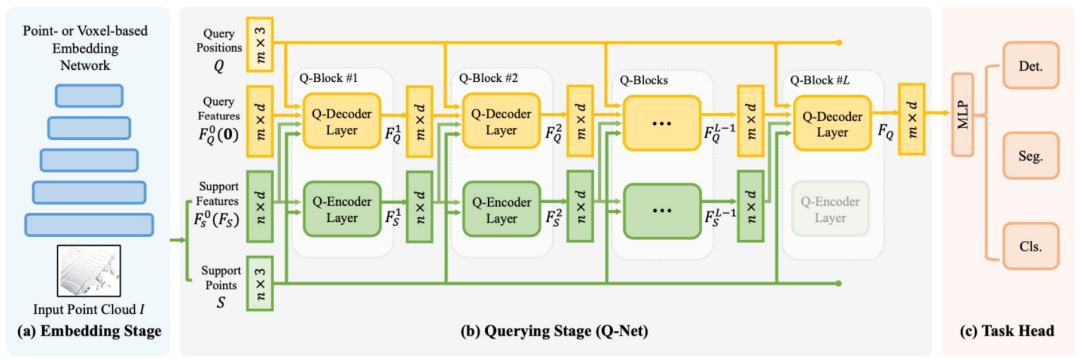
精华文稿|迈向统一的点云三维物体检测框架
分享嘉宾 | 杨泽同 文稿整理 | William 嘉宾介绍 Introduction 3D检测是在三维世界中去定位和分类不同的物体,与传统2D检测的区别在于它有一个深度信息。目前,大部分的工作是倾向于用点云去做三维检测,点云实际上是通过传感器去扫描出来的一…...
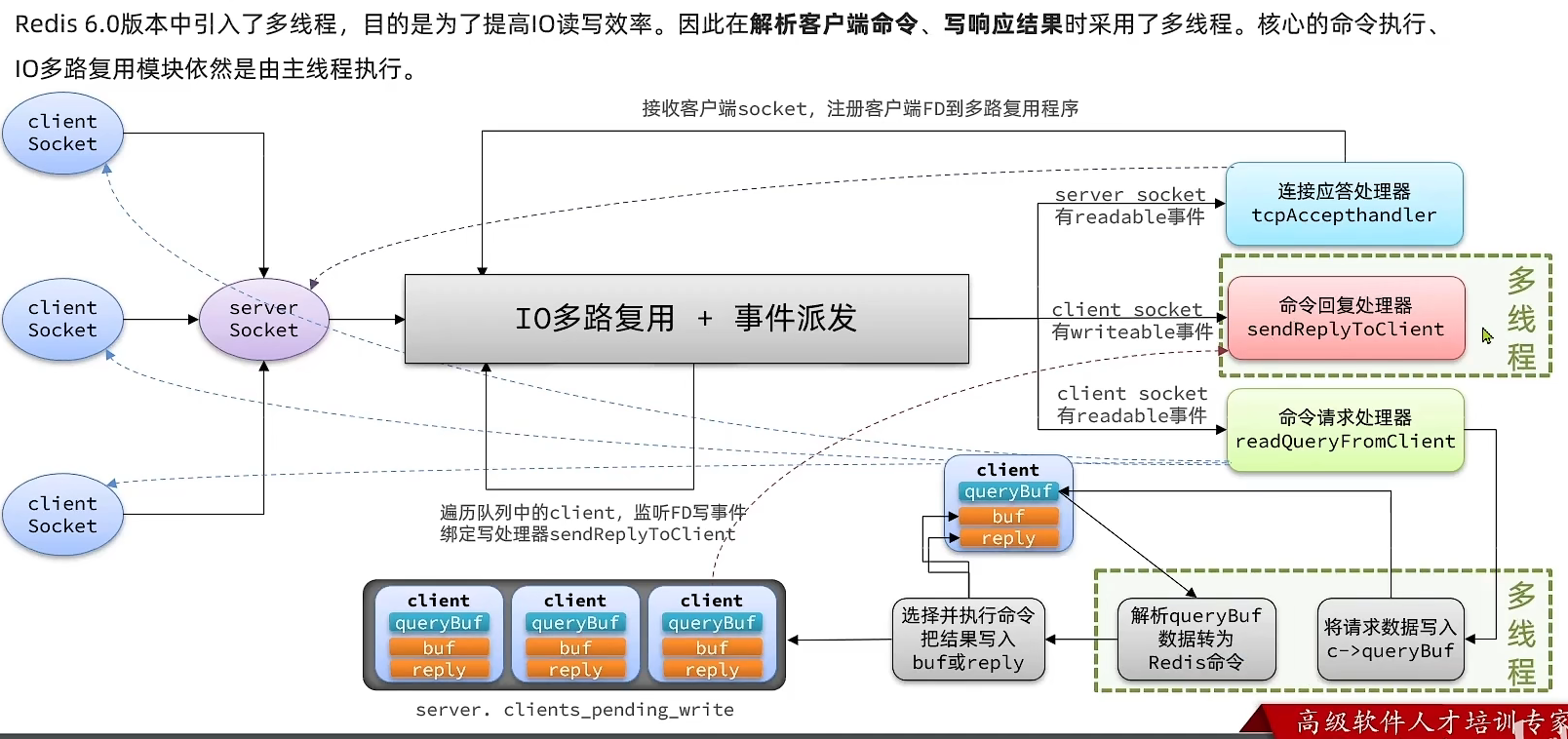
面试题:Redis网络模型
1 用户空间和内核空间以Centos 7 linux操作系统为例。计算机系统被内核操控, 内核被应用操控。为了避免用户应用导致冲突甚至内核崩溃,用户应用与内核是分离的进程的寻址空间会划分为两部分:内核空间、用户空间。用户空间只能执行受限的命令(Rin3&#x…...
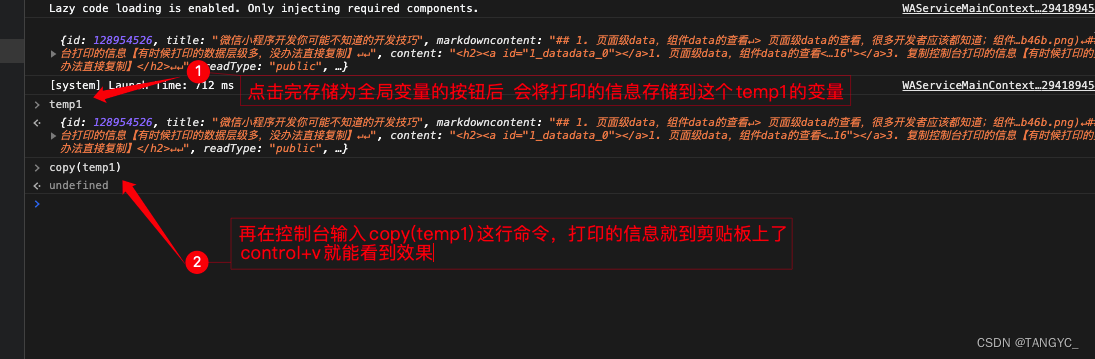
微信小程序开发你可能不知道的开发技巧
1. 页面级data,组件data的查看 页面级data的查看,很多开发者应该都知道;组件级的数据查看我是开发了大半年才发现的; 页面级的data查看: 组件的data查看: 2. 放大模拟器【调整一些UI细节】 效果&#x…...
STM32开发(8)----CubeMX配置串口通讯(中断方式和DMA方式)
CubeMX配置串口通讯(中断方式和DMA方式)前言一、中断方式1.CubeMX配置2.代码实现3.实验结果二、DMA方式1.CubeMX配置2.代码实现3.实验结果总结前言 本章继续介绍使用STM32CubeMX对串口进行配置的方法,串口通讯有三种方式:轮询&am…...

7.1 微服务-SpringCloud(二)
目录 前言 7.1.5 Hystrix 7.1.5.1 什么是Hystrix 7.1.5.2 雪崩问题 7.1.5.3 线程隔离,服务降级 7.1.5.4 搭建 7.1.5.4.1 引入依赖 7.1.5.4.2 开启熔断 7.1.5.4.3 编写降级逻辑 1.局部降级逻辑 2.全局降级逻辑 7.1.5.4.4 设置超时 7.1.5.5 服务熔断 7.…...

Spring的AOP开发-基于xml配置的AOP
Spring的AOP开发-基于xml配置的AOP xml方式AOP快速入门 通过配置文件的方式解决以下问题 配置哪些包、哪些类、哪些方法需要被增强配置目标方法要被哪些通知方法所增强,在目标方法执行之前还是之后执行增强 配置方式的设计、配置文件(注解),Spring已…...

JAVA的垃圾收集器与内存分配策略【一篇文章直接看懂】
内存动态分配和垃圾收集技术是JAVA和C之间最大的区别之一 垃圾收集(Garbage Collection,GC)只办三件事: 哪些内存需要回收什么时候回收如何回收 对于对象回收的方法 引用计数法: 每处引用时1,引用失效…...

NLP学习——信息抽取
信息抽取 自动从半结构或无结构的文本中抽取出结构化信息的任务。常见的信息抽取任务有三类:实体抽取、关系抽取、事件抽取。 1、实体抽取 从一段文本中抽取出文本内容并识别为预定义的类别。 实体抽取任务中的复杂问题: 重复嵌套,原文中…...
【深度学习基础7】预训练、激活函数、权重初始化、块归一化
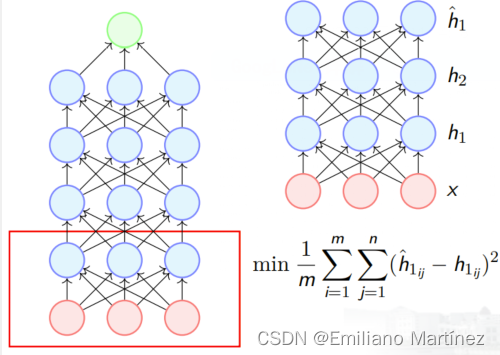
一、Unsupervised Pre-training 得益于 Hinton and Salakhutdinov 在 2006 年的开创性工作— 无监督预训(unsupervised pre-training);在《Reducing the dimensionality of data with neural networks.》这篇论文中,他们在 RBMs 中引入无监督预训练,下面我们将在Autoenco…...

Switch大气层系统完整教程:从零开始打造稳定自制系统环境
Switch大气层系统完整教程:从零开始打造稳定自制系统环境 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 大气层系统(Atmosphere)是任天堂Switch平台上最…...
)
Gemini深度研究模式权限与数据隔离机制全披露(含GDPR/等保2.0合规对照表)
更多请点击: https://intelliparadigm.com 第一章:Gemini深度研究模式权限与数据隔离机制全景概览 Gemini 深度研究模式(Deep Research Mode)是 Google 提供的高级推理能力,专为复杂多步信息检索与跨源分析设计。该模…...

Flutter 轻量存储方案介绍、区别、对比和使用场景
在 Flutter 项目中,本地存储通常可以分为几类: 第一类是轻量 Key-Value 存储,例如 shared_preferences、get_storage、mmkv,适合保存开关、配置、登录状态等简单数据。 第二类是安全存储,例如 flutter_secure_storage&…...

规格驱动营销:用AI代理与工程化思维打造Twitter增长自动化
1. 项目概述:一个为AI SaaS产品设计的Twitter营销自动化工具包如果你正在开发一款AI SaaS产品,并且已经为产品上线后的Twitter营销感到焦虑——不知道如何规划内容、如何与用户互动、如何将推文流量转化为实际用户——那么你很可能需要一套系统化的方法&…...
)
Midjourney油彩模式正在悄悄升级!内部测试通道流出的--oil-mode beta参数文档(含笔触方向控制与亚麻布基底模拟指令)
更多请点击: https://intelliparadigm.com 第一章:Midjourney油彩模式的演进脉络与beta通道解密 Midjourney 的油彩模式(Oil Painting Mode)并非官方命名的功能,而是社区对一组特定风格化参数组合的统称,…...

轻量级容器化部署工具Ship:简化中小团队应用部署流程
1. 项目概述:一个面向开发者的轻量级容器化部署工具最近在和朋友聊起中小团队或个人开发者的部署痛点时,大家普遍觉得,虽然Kubernetes(K8s)生态强大,但对于一个快速迭代的独立项目或小团队来说,…...

ACE Awards:电子行业年度创新风向标与工程师成长指南
1. 项目概述:一场属于电子工程师的年度庆典如果你在半导体或电子设计行业待过几年,肯定对“EE Times”和“EDN”这两个名字不陌生。它们就像是电子工程师的“行业圣经”,每天刷一刷,看看又有哪些新芯片发布、哪些技术路线在争论&a…...

曲轴基于灵敏度的拓扑优化-CAE操作过程
前言 本示例展示了曲轴基于灵敏度的拓扑优化的基本工作流程。 该模型为简化曲轴模型,设计区域采用壳单元建模,轴体部分采用梁单元建模,壳单元与梁单元之间通过 RBE2 多点约束单元 进行耦合连接。 本次优化的目标是通过体积最小化实现曲轴的轻…...

StreamCap:让直播录制变得如此简单的跨平台自动录制工具
StreamCap:让直播录制变得如此简单的跨平台自动录制工具 【免费下载链接】StreamCap Multi-Platform Live Stream Automatic Recording Tool | 多平台直播流自动录制客户端 基于FFmpeg 支持监控/定时/转码 项目地址: https://gitcode.com/gh_mirrors/st/StreamC…...

芯片测试中的扫描压缩技术解析与应用
1. 扫描压缩技术概述在当今纳米级芯片设计中,扫描压缩技术已成为降低测试成本、保证测试质量的必备手段。随着芯片复杂度呈指数级增长,传统扫描测试方法面临两大核心挑战:测试数据量(Test Data Volume)爆炸式增长导致测…...