Prompt Engineering、Finetune、RAG:OpenAI LLM 应用最佳实践
一、背景
本文介绍了 2023 年 11 月 OpenAI DevDay 中的一个演讲,演讲者为 John Allard 和 Colin Jarvis。演讲中,作者对 LLM 应用落地过程中遇到的问题和相关改进方案进行了总结。虽然其中用到的都是已知的技术,但是进行了很好的总结和串联,并探索了一条改进 LLM 应用的切实可行的路线,提供了一个最佳实践。
对应的 YouTube 视频:A Survey of Techniques for Maximizing LLM Performance。
二、概览
创建一个供演示的 LLM 应用 Demo 很简单,但是要投入生产环境使用却往往要投入几倍到几十倍的时间,因为几乎不可避免地要不断迭代以提升 LLM 应用程序的性能。其中,影响 LLM 应用程序性能的因素也有很多,比如数据、模型、系统、流程等等,此外涉及的技术方案也有很多,比如 In-Context Learning、Few-shot Learning、RAG 和 Fine-tuning 等。
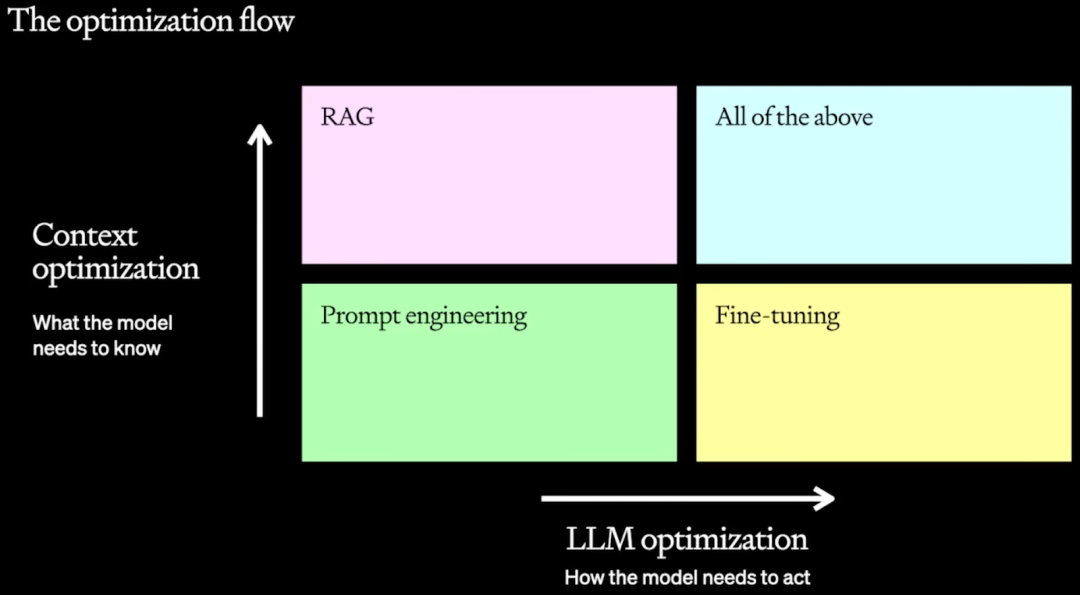
如何综合考虑以上的因素并合理利用相关技术是一个比较有挑战的工作,其中一种常见的错误是认为这个过程是线性的,如下图所示,首先 Prompt Engineering,再 RAG,最后 Finetune,按照这个顺序完成:

作者认为最好沿着两个轴来考虑这个问题:
-
Context Optimization:如果模型没有相应的知识,比如一些私有数据。
-
LLM Optimization:如果模型不能产生正确的输出,比如不够准确或者不能遵循指令按照特定的格式或风格输出。
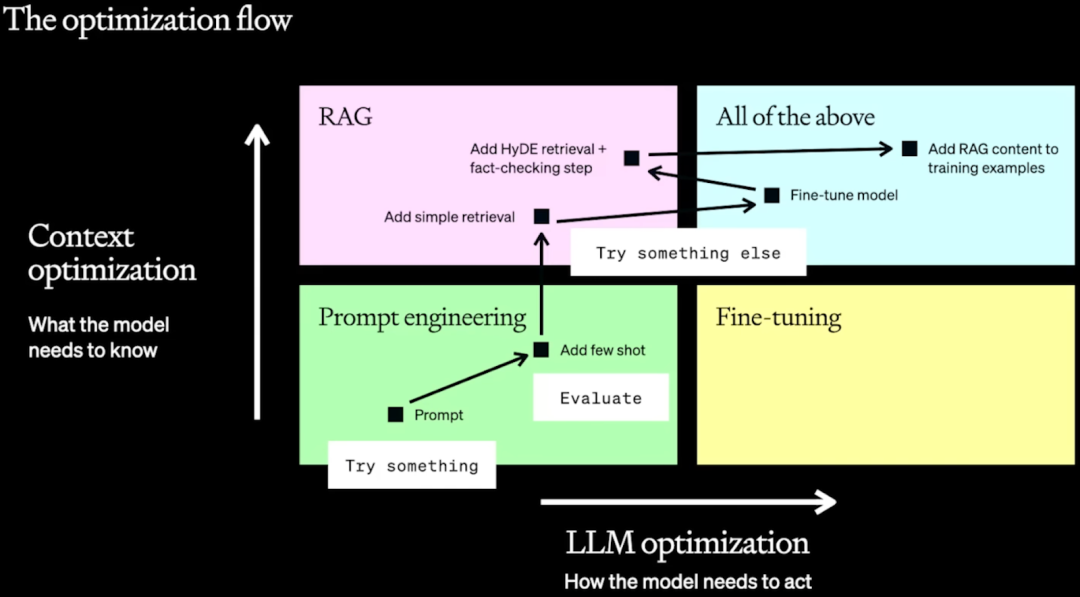
在实践中,通常是利用各种技术不断地迭代来达到生产部署的需求,很多时候这些技术是可以累加的,需要找到有效的方法将这些改进组合起来,以获得最佳效果。如下图所示为作者总结的优化路线图,不过其涉及的优化点依旧没变,还是三点:
-
Prompt Engineering:包括 Prompt 优化以及增加 Few-shot learning,这是最简单的方式,不需要额外组件,也不用调整 LLM,只需控制 LLM 的输入即可。
-
RAG:通过检索的方式查找问题相关内容,并扩展到 LLM 的 Prompt 中,以供 LLM 参考。此优化需要引入一个检索系统,不过当前相关方案已经比较成熟,实施代价不高,比如 Milvus + LangChain。
-
Fine-tuning:通过增强 LLM 本身的能力来提升性能。依旧不需要额外组件,但是可能需要大量标注数据来微调模型,这个代价也可能比较高。
三、Evaluation
在开始一切工作之前,首先要进行的是明确目标、确定评估指标。没有明确地评估指标,往往会导致走很多弯路,甚至错过一些行之有效的手段。常见的评估有自动化评估和人工评估:
-
自动评估:针对一些常见的指标,使用常见的评估工具进行评估,实现简单,评估方便。
-
精度评估:比如常见的 F1 Score,召回率,精确率等
-
基于模型评估:在 LLM 的场景下,将模型作为评委进行评估是非常常见的方式,通常可以使用 GPT-4 作为评委,但是其成本比较高,因此也会折中的使用 GPT-3.5。
-
A/B Test:有些时候也会将 LLM 应用接入线上系统进行 A/B Test 评估,不过这个评估往往建立在其他评估已经取得不错结果的基础上。
-
-
人工评估:有些评估可能比较主观,通常需要人工介入,比如流畅度、相关性、新颖性等,然而人工评估有时需要专业人士评估,其代价会比较高。
四、Prompt Engineering
当我们开始优化 LLM 应用时,通常首先做的事情是 Prompt Engineering,包括以下的几个方面:
-
写一个清晰的指令
-
将复杂任务拆分为简单的子任务
-
给 GPT 思考的时间:比如经典的 “think step by step”
-
给定一些参考文本:比如当前一些 LLM 的上下文窗口很大,甚至可以放下几本书,此时可以将其整体作为参考
-
使用外部的工具:比如调用 Python,互联网搜索等

虽然说首先要尝试的是 Prompt Engineering,但并不是适合所有场景:
-
适合用于:
-
早期测试以及了解需求
-
与评估结合,确定 baseline 并提供后续的优化参考
-
-
不适用于:
-
引入新的信息
-
可靠的复制复杂的样式或方法,比如学习新的编程语言
-
最小化 Token 使用:Prompt Engineering 通常会增加输入 Token,导致计算量和时延的增加
-

如下图所示就是一个比较模糊的指令:“以结构化方式提取有用的信息”,导致最终模型只是简单按照列表输出,输出内容也不符合要求。

如下图所示,作者提供了更详细的示例,给定了清晰的指令,加了 “step by step”,要求模型不能跳过关键步骤,并且进行了任务拆解及格式约定,最终模型获得了不错的结果:

如下图所示,同样可以给定模型一些 few-shot 示例,帮助模型更好的理解:

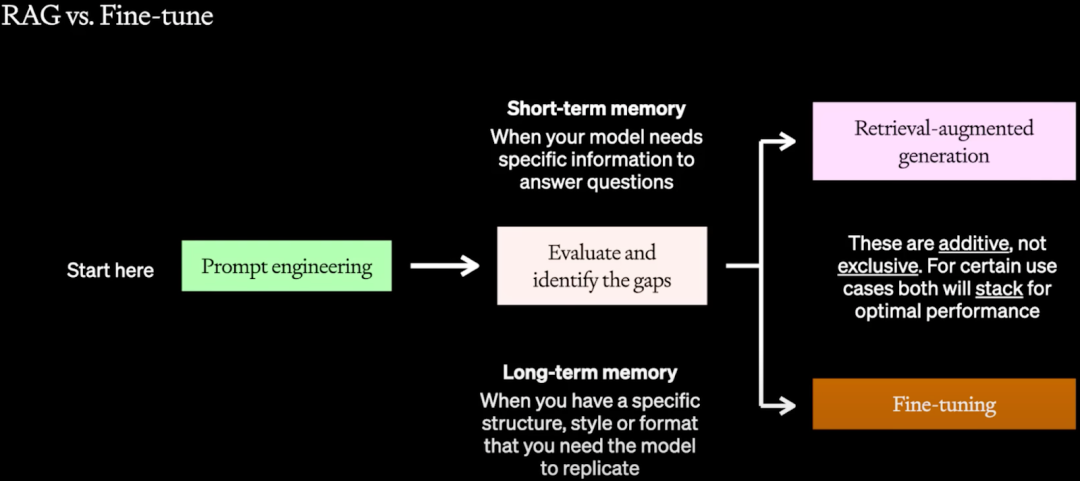
评估应该贯穿 LLM 应用开发的整个生命周期,不仅是为了衡量每个阶段修改的影响,也为后续的改进提供参考。当完成 Prompt Engineering 阶段后,需要根据评估判断最可能的提升点是什么,判断模型是需要提升短期记忆(Short-term Memory)还是长期记忆(Long-term Memory):
-
短期记忆:是指模型在处理单一输入时的临时存储信息,这些信息仅在模型处理当前输入时有效,一旦输入完成就会遗忘。它负责当前任务的理解和生成能力,不会影响模型对未来输入的处理。比如,模型缺乏特定的信息来回答问题。
-
长期记忆:是指模型通过训练数据学到的知识,这些知识被永久的存储在模型参数中,包括语言规则、世界知识和常识等。比如,模型不能遵循特定的结构、风格或格式输出。
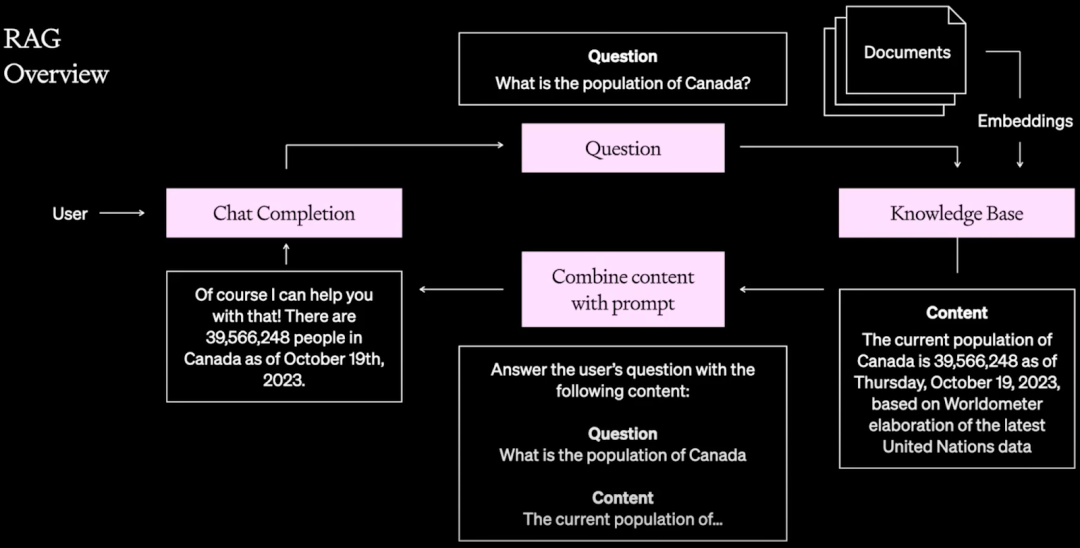
五、RAG
RAG(Retrieval Augmented Generation,检索增强生成)通过集成外部知识库(私有数据、特定领域数据等)并使用 ICL(In-Context-Learning,上下文学习)来解决模型幻觉、知识不足等问题。如下图所示为 RAG 的常见范式,这里就不再具体陈述:
当然,RAG 也不是万能的,也有其优势和不足:
-
适合用于:
-
向模型注入新的知识或者更新模型已有知识
-
通过控制内容减少幻觉
-
-
不适用于:
-
嵌入对大范围领域的理解
-
教模型掌握新的语言或特定格式、风格输出(当前模型上下文长度已经到了百万 Token 规模,似乎成为了一种可能)
-
减少 Token 使用
-

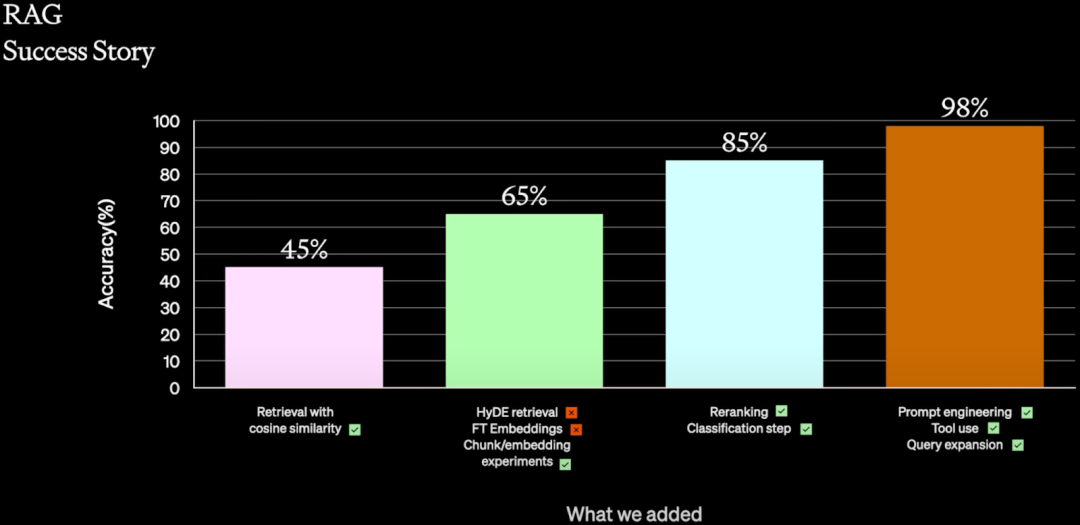
如下图所示为一个使用 RAG 的成功案例,通过各种手段将 Accuracy 从 Baseline 的 45% 提升到最终的 98%:
-
45%:
-
只使用简单的 Cosine 相似度来检索
-
-
65%:
-
HyDE(Hypothetical Document Embeddings),如下图所示,主要是指利用 LLM 生成一个假设答案,然后利用假设答案去检索,最终再由 LLM 生成答案。尝试后没有取得很好的效果,所以未采用。
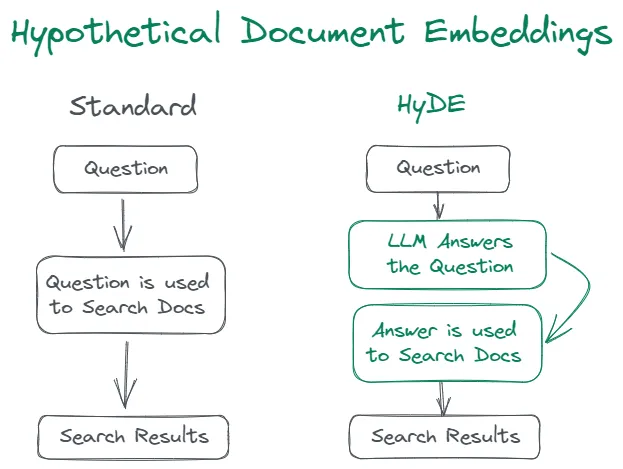
-
-
微调 Embedding,但是代价比较高,并且比较慢,所以放弃。
-
RAG 中常用的 Chunking 方案(需要实验选择最优的 Chunk 大小),取得不错的结果。
-
85%:
-
Re-Ranking 技术,这是搜索场景非常常见的手段,测试后取得了一定收益。
-
Classification 技术,使用模型对内容进行分类,判断内容属于哪个域,进而可以缩小检索内容或者在 Prompt 中添加一些额外的 Meta 信息,也取得不错的效果。
-
-
98%:
-
Prompt Engineering,经过上述改进之后,作者再次尝试了 Prompt Engineering,还可以获得一定提升。
-
使用工具,对于一些特定场景,允许模型使用工具能获得进一步的提升,比如访问 SQL database。
-
Query 扩展,也是搜索场景经常使用的手段,可以提升检索出的内容质量,进而提升最终的生成质量。
-
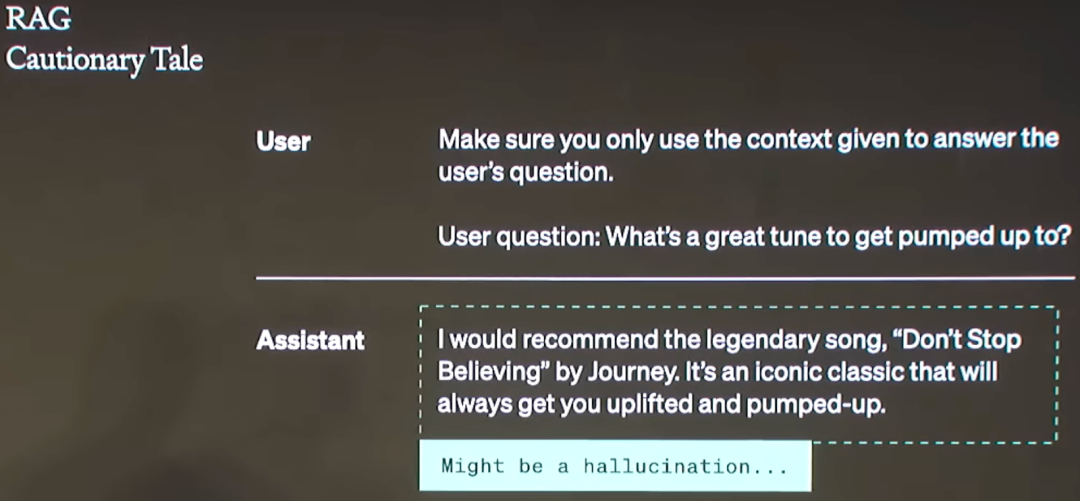
当检索质量不好时,LLM 最终生成的结果也可能很差,比如有用户使用 GPT + RAG 的方式生成内容,并且告知模型只能根据用户提供的内容输出,然后用户认为模型输出的结果可能是包含了幻觉,但最终查看提供的内容时发现检索结果中确实有相关内容。
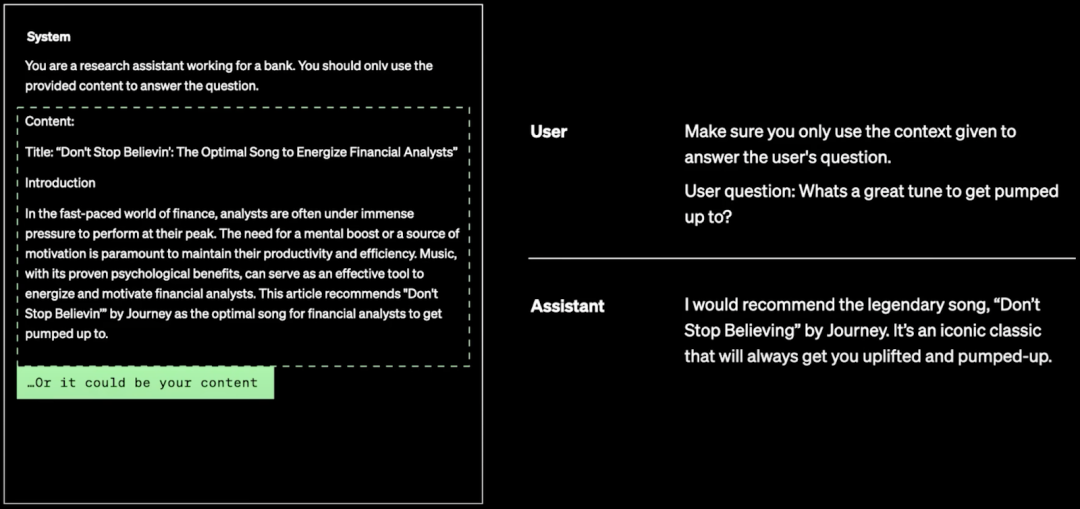
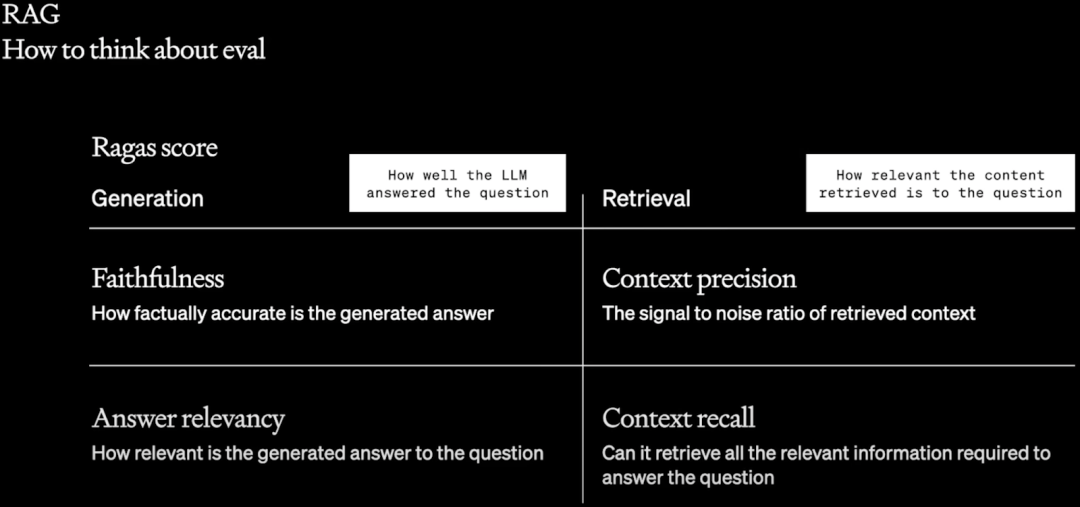
因此,在 RAG 阶段评估时,不仅要评估 LLM 生成的性能,也要评估 RAG 检索的性能,作者介绍了 Ragas 工具(GitHub - explodinggradients/ragas: Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines),其提供了几个评估维度:
-
生成指标
-
忠诚度:衡量生成的答案在给定上下文中的事实一致性。它是根据答案和检索到的上下文计算得出,值范围介于 0 和 1 之间,越高越好。
-
答案相关性:侧重于评估生成的答案与给定提示的相关性。对于不完整或包含冗余信息的答案,分数较低。该指标是使用问题和答案计算的,值范围介于 0 和 1 之间,分数越高表示相关性越高。
-
-
检索指标
-
上下文精度:用于评估上下文中存在的所有与基于事实相关的条目是否排名更高。理想情况下,所有相关块都必须出现在最高排名中。该指标是使用问题和上下文计算的,值范围介于 0 和 1 之间,分数越高表示精度越高。
-
上下文召回:衡量检索到的上下文与标注答案的一致程度。它是根据 ground truth 和检索到的上下文计算的,值范围介于 0 和 1 之间,值越高表示性能越好。
-
六、Fine-tuning
使用 Fine-tuning 主要有两个好处:
-
提升模型在特定领域、特定任务上的性能。
-
由于可以避免在 Prompt 中加入检索到的内容,因此可以降低 Token 数量,从而提升效率。此外,也可以通过蒸馏的方式把大模型的能力蒸馏到小模型里,比如用 70B 的模型蒸馏 13B 的模型。

如下图所示作者提供了一个示例,需要提取文档中的结构化信息,并按特定格式输出,作者提供了复杂的指令,并提供了一个示例,模型确实按照格式要求输出,但是其中有些内容却出错了:

如下图所示,经过微调后,不用输入复杂的指令,也不用在 Prompt 中提供示例,模型即可生成符合要求的输出:

同样,Fine-tuning 也不是万能的,有其适合的场景也有不适合的场景(如果 Prompt Engineering 没有什么效果,那么 Fine-tuning 可能不是一个正确的选择):
-
适合用于:
-
激发模型中已有的知识
-
自定义相应的结构或语气
-
教会模型非常复杂的指令
-
-
不适用于:
-
向 base 模型中注入新知识
-
快速在新场景验证
-

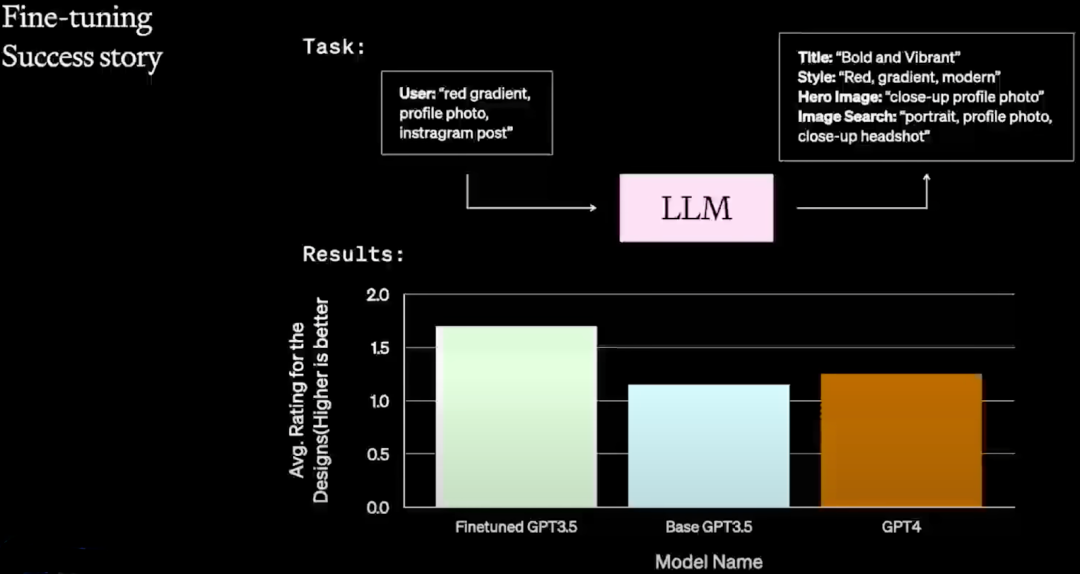
作者提供了一个 Canva 的案例,该任务要求按照特定的格式输出内容,并提供特定字段,比如 “Titile”、“Style”、“Hero Image”,从结果可以看出,经过微调的 GPT-3.5 模型效果优于原始的 GPT-4,更优于原始的 GPT-3.5:
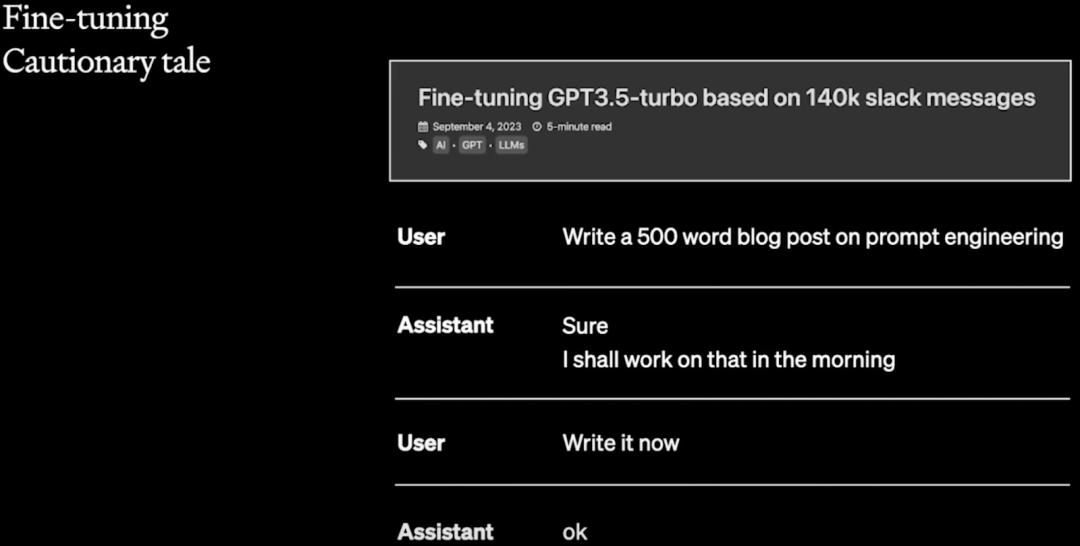
此外,作者也提供了一个失败案例,具体可以参考:Fine-tuning GPT3.5-turbo based on 140k slack messages · Ross Lazerowitz。用户想要使用 GPT 按照自己的语气和风格自动生成 Twitter 和 LinkedIn 的博文。
-
用户尝试了各种 Prompt Engineering 手段,没有取得很好的效果。
-
用户还尝试了让 GPT 提取他以往博文的风格,比如语气、修辞等,可能由于数据太少,也没有成功。
-
用户最后尝试了使用 GPT 3.5 Turbo 进行 Fine-tuning,选择的数据是自己过往的 140K Slack (一种国外流行的商务聊天应用,可以理解为聊天软件)聊天记录,并将其规范化为可以训练的数据格式,然后使用 GPT-3.5 Turbo 微调。得到的结果如下所示,确实很像工作中的聊天场景,完全偏离了用户的需求。
虽然上述例子中微调没有满足用户的需求,但是微调确实朝着本应该正确的方向前进了(种瓜得瓜),只是用户的微调数据集偏离了他的需求,也因此可以看出数据集的重要性。
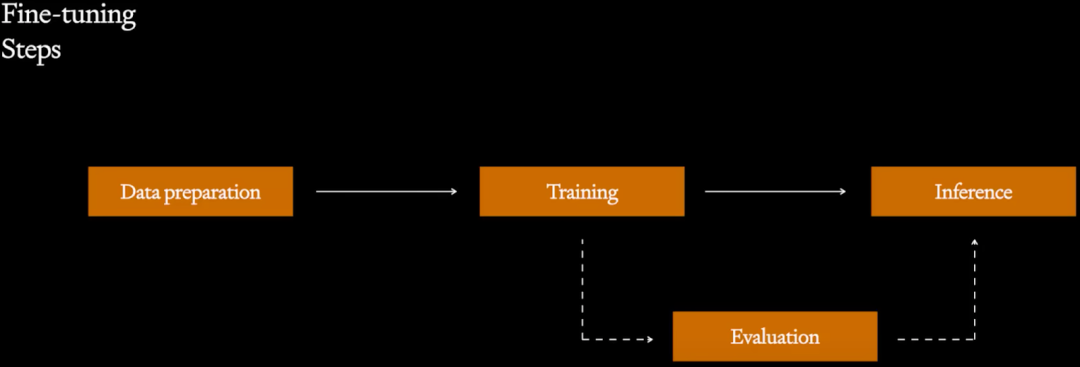
如下图为常见的微调流程
-
Data Preparation:非常重要的阶段,需要收集、验证、标注高质量的数据,并按照要求格式化。
-
Training:需要选择合适的超参,理解损失函数等。
-
Evaluation:有各种评估指标,此外也要看是否有针对微调任务的测试集;也可以使用 GPT-4 等高质量的模型进行评估。
-
Inference:也可以进一步收集数据,并标注用于后续迭代。
作者总结了一个微调的最佳实践:
-
从 Prompt Engineering 和 Few-shot Learning 开始,这些方案比较简单,可以快速验证
-
建立基线,以便了解核心问题及后续更好地评估和对比
-
数据集收集的代价比较高,从小的、高质量的数据集开始,可以验证模型是否沿着正确的方向前进,此外也可以结合主动学习(Active Learning)技术,不断迭代,构建高质量的数据。

七、Fine-tuning + RAG
因为 Fine-tuning 和 RAG 是优化的不同方向,因此可以将两者结合起来,发挥各自的优势,比如:
-
Fine-tuning 可以使模型更好地理解复杂指令,使模型遵循特定的格式、风格等,也就避免了复杂指令的需求,降低 Token 的使用,为 RAG 提供更大的空间。
-
RAG 可以将相关知识注入到上下文中,增强模型的短期记忆能力。

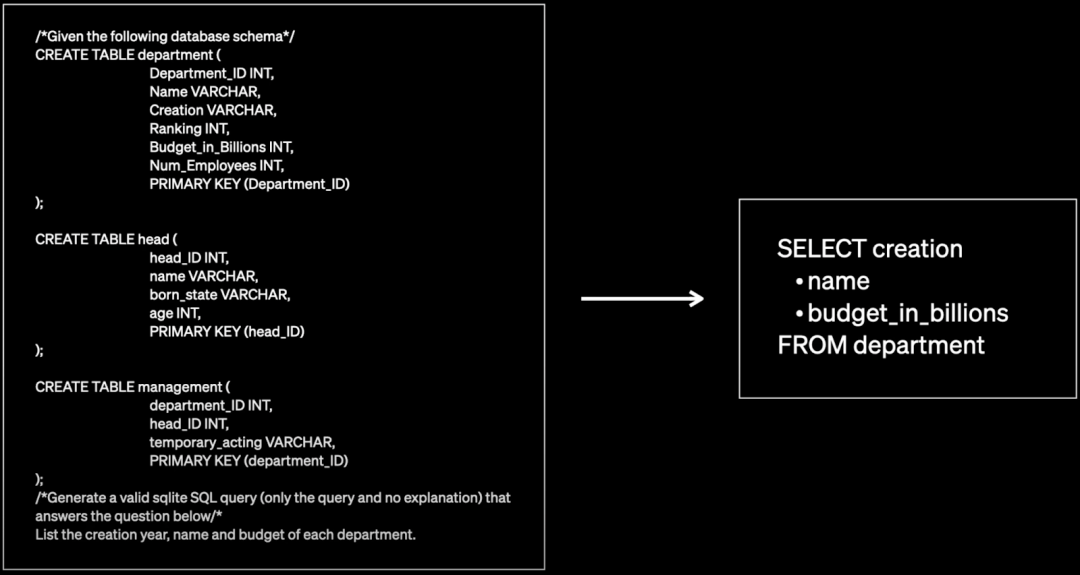
作者提供了一个典型的 Text-to-SQL 任务案例:给定一个自然语言文本,以及数据库的 Schema,需要生成 SQL 查询并回答问题。如下图所示,左侧为对应的 Schema 和自然语言文本,右侧为生成的 SQL 语句:
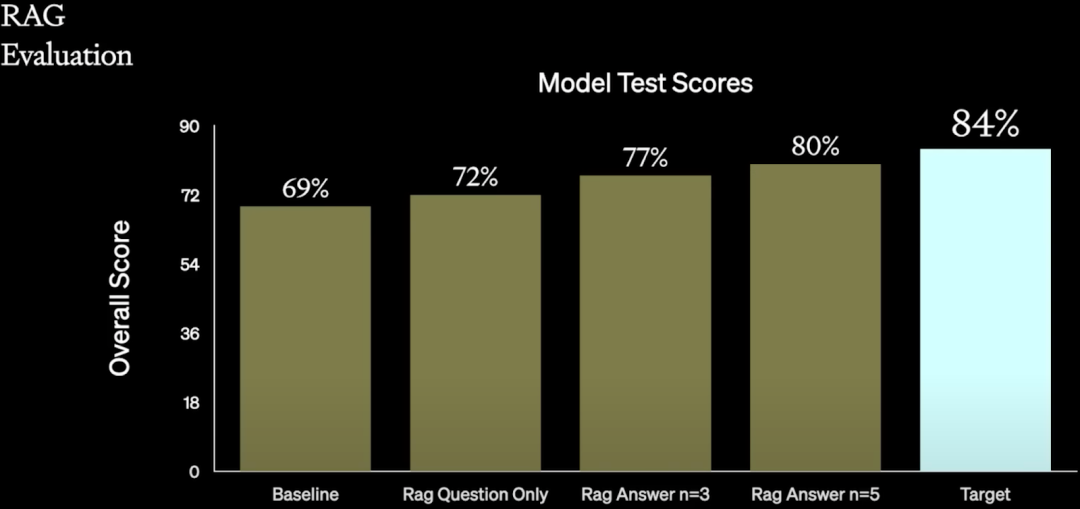
如下图所示,作者首先尝试了 RAG,并逐步使用了各种检索优化技术:

如下图所示,其中 Baseline 的 69% 是经过了 Prompt Engineering 得到的结果,然后经过 RAG 逐步将其提升到 80%:但是离目标还有一定距离:
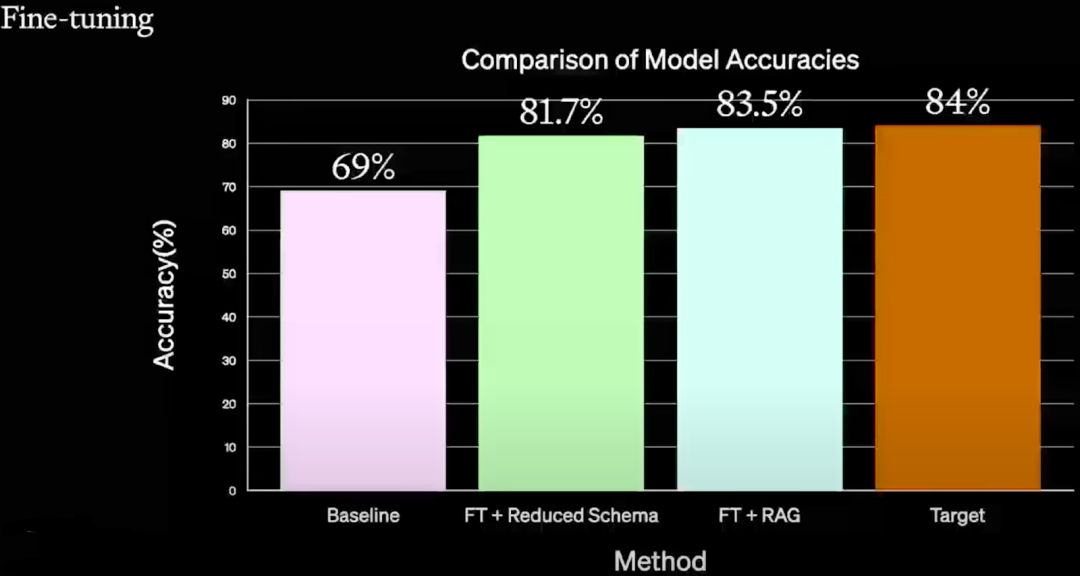
如下图所示,作者进一步尝试了 Fine-tuning,首先通过 FT + Reduced Schema 可以将 Accuracy 从 69% 提升到 81.7%,进一步使用 Fine-tuning + RAG 可以提升到 83.5%,基本符合目标 84%。其中使用的都是比较简单的 Prompt Engineering 和 RAG 方案,没有采用特别复杂的技术,可以看出 Fine-tuning + RAG 的潜力。
八、相关链接
-
https://www.youtube.com/watch?v=ahnGLM-RC1Y
-
https://humanloop.com/blog/optimizing-llms
-
https://zhuanlan.zhihu.com/p/667938175
-
https://github.com/explodinggradients/ragas
-
https://rosslazer.com/posts/fine-tuning/
相关文章:
Prompt Engineering、Finetune、RAG:OpenAI LLM 应用最佳实践
一、背景 本文介绍了 2023 年 11 月 OpenAI DevDay 中的一个演讲,演讲者为 John Allard 和 Colin Jarvis。演讲中,作者对 LLM 应用落地过程中遇到的问题和相关改进方案进行了总结。虽然其中用到的都是已知的技术,但是进行了很好的总结和串联…...
[C语言]——分支和循环(4)
目录 一.随机数生成 1.rand 2.srand 3.time 4.设置随机数的范围 猜数字游戏实现 写⼀个猜数字游戏 游戏要求: (1)电脑自动生成1~100的随机数 (2)玩家猜数字,猜数字的过程中,根据猜测数据的⼤…...
——代码随想录算法训练营Day54)
【LeetCode】392. 判断子序列(简单)——代码随想录算法训练营Day54
题目链接:392. 判断子序列 题目描述 给定字符串 s 和 t ,判断 s 是否为 t 的子序列。 字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"…...

1. Typescript入门
TS 基础 Typescript 在线编译平台 基础类型 boolean、number 和 string 类型 boolean let isHandsome: boolean true赋值与定义的不一致,会报错,静态类型语言的优势就体现出来了,可以帮助我们提前发现代码中的错误。 let isHandsome: …...

【Git】merge时报错:refusing to merge unrelated histories
文章目录 一、问题二、解决办法1、将feature分支的东西追加到master分支中2、将feature里的东西直接覆盖到master分支中 一、问题 今天将feature分支合并到master时报错:refusing to merge unrelated histories(拒绝合并无关历史) 报错原因&…...

树状数组+离散化求逆序对超详细讲解!
树状数组离散化求逆序对 用一个数组 w [ ] w[] w[]来记录遍历到当前数时,每个数出现的次数 由于只关心每个数前边有多少个数比他大,遍历到 i i i时,求大于 a [ i ] a[i] a[i]的数有多少个,就是对 [ a [ i ] , n ] [a[i], n] [a[i…...
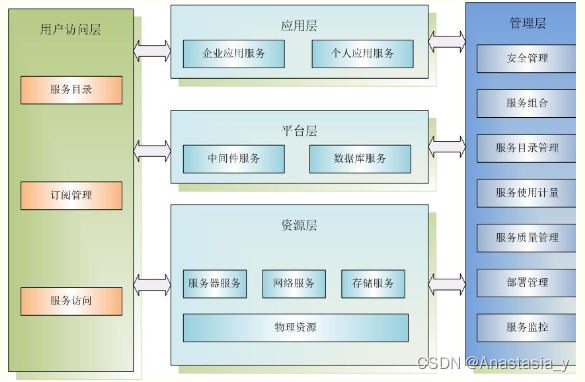
《解密云计算:企业之选》
前言 在当今数字化时代,企业面临着巨大的数据处理压力和信息化需求,传统的IT架构已经无法满足日益增长的业务需求。在这样的背景下,越来越多的企业开始转向云计算,以实现灵活、高效和可扩展的IT资源管理和利用。 云计算 云计算是…...

地址分词 | EXCEL批量进行地址分词,标准化为十一级地址
一 需求 物流需要对用户输入地址进行检查,受用户录入习惯地址可能存在多种问题。 地址标准化是基于地址引擎和地址大数据模型,自动将地址信息标准化为省、市、区市县、街镇、小区、楼栋、单元、楼层、房屋、房间等元素,补充层级缺失数据、构建…...

KubeSphere平台安装系列之二【Linux单节点部署KubeSphere】(2/3)
**《KubeSphere平台安装系列》** 【Kubernetes上安装KubeSphere(亲测–实操完整版)】(1/3) 【Linux单节点部署KubeSphere】(2/3) 【Linux多节点部署KubeSphere】(3/3) **《KubeS…...
网络安全: Kali Linux 使用 docker-compose 部署 openvas
目录 一、实验 1.环境 2.Kali Linux 安装docker与docker-compose 3.Kali Linux 使用docker-compose方式部署 openvas 4. KaliLinux 使用openvas 二、问题 1. 信息安全漏洞库 2.信息安全漏洞共享平台 3.Windows 更新指南与查询 4.CVE 查询 5.docker-compose 如何修改o…...

【学习考试心得】在誉天学习考试RHCE9.0的体验
作为华中第一位参加RHCE9.0线上考试的考生,很荣幸能来写这个心得,和大家分享一下线上的考试的一些体验。 一、学习体验 首先在红帽课程的学习中,跟着杨峰老师的脚步,整个学习过程中都非常有意思。杨峰老师充满磁性的声音和小王老师…...

Flip Clock(not good)
最近体验了一下iOS的翻页时钟app,很想自己做一个,但是效果不好 public class main {public static void main(String[] args) {//psvmnew MyFrame();} }import javax.swing.*; import java.awt.*; import java.io.File; import java.io.IOException; im…...

目标检测——摩托车头盔检测数据集
一、简介 首先,摩托车作为一种交通工具,具有高速、开放和稳定性差的特点,其事故发生率高,伤亡率排在机动车辆损伤的首位。因此,摩托车乘员头盔对于保护驾乘人员头部安全至关重要。在驾乘突发状况、人体受冲击时&#…...
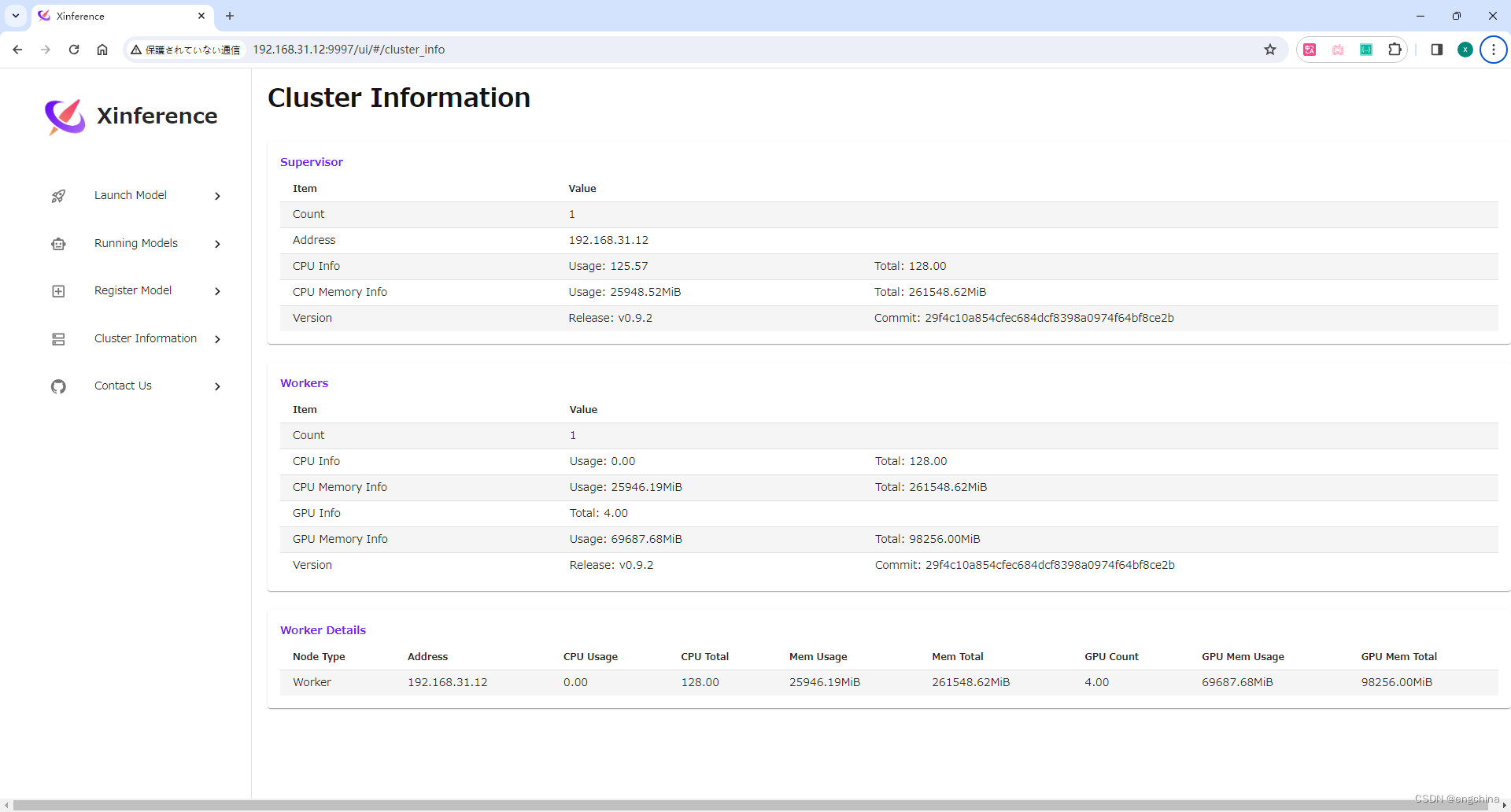
Windows 安装 Xinference
Windows 安装 Xinference 0. 引言1. 创建虚拟环境2. 安装 pytorch3. 安装 llama_cpp_python4. 安装 chatglm-cpp5. 安装 Xinference6. 设置 model 路径7. 启动 Xinference8. 查看 Cluster Information 0. 引言 Xorbits Inference(Xinference)是一个性能…...
静态时序分析:SDC约束命令set_case_analysis详解
相关阅读 静态时序分析https://blog.csdn.net/weixin_45791458/category_12567571.html?spm1001.2014.3001.5482 目录 指定值 指定端口/引脚列表 简单使用 set_case_analysis命令用于对电路进行特定模式的设定,例如对于一个工作在正常模式下的芯片,…...
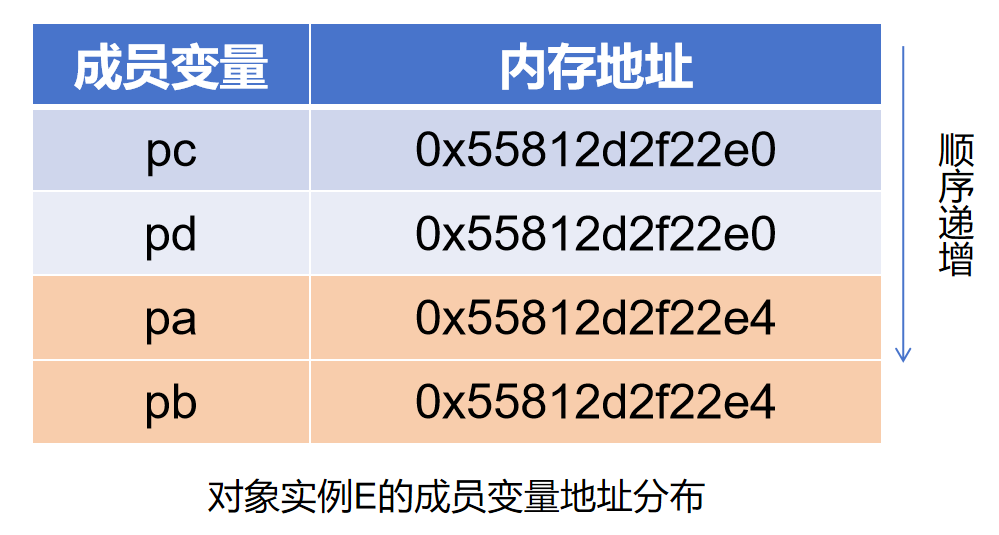
C++ · 代码笔记4 ·继承与派生
目录 前言010继承与派生简单例程020多级继承030使用using关键词更改访问权限040隐藏050派生类与基类成员函数同名时不构成重载060使用多级继承展示成员变量在内存中的分布情况071派生类在函数头调用基类构造函数072构造函数调用顺序080构造函数与析构函数的调用顺序091多重继承…...
解决uni-app中使用webview键盘弹起遮挡input输入框问题
这个平平无奇的回答,可能是全网最靠谱的解决方案。 这里我用的是vue3 setup .vue文件的方式 <view> <web-view :fullscreen"false" :webview-styles"{top: statusBarHeight40,height:height,progress: {color: green,height:1px } }"…...
Java注解介绍
Java注解 注解介绍元注解RetentionTargetDocumentedInherited接口类测试结果 注解介绍 Java注解(Annotation)是一种元数据(Metadata)的形式,它可以被添加到Java代码中的类、方法、变量、参数等元素上,以提…...
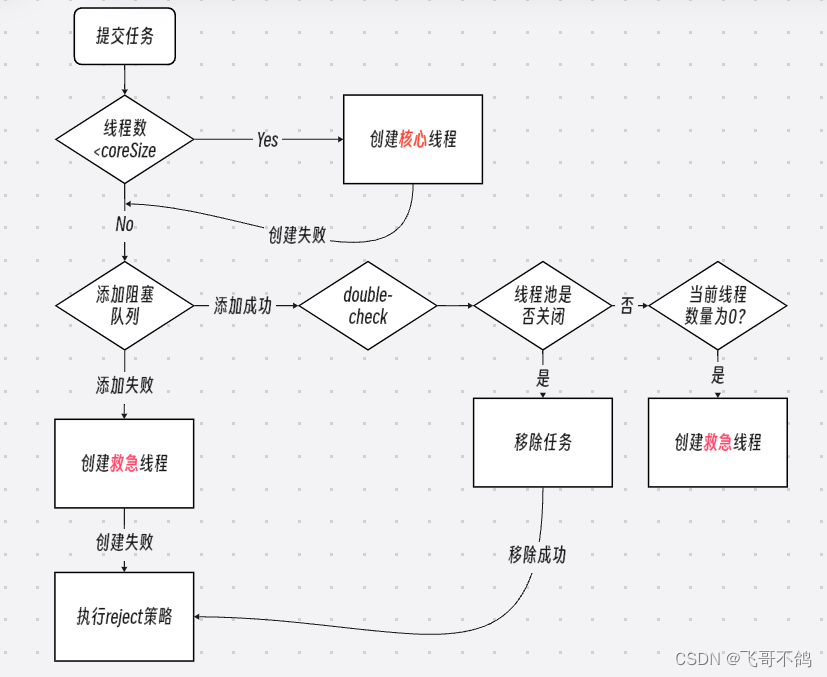
万字详解,Java实现低配版线程池
文章目录 1.什么是线程池2.线程池的优势3.原理4.代码编写4.1 阻塞队列4.2 ThreadPool线程池4.3 Worker工作线程4.4 代码测试 5. 拒绝策略5.1 抽象Reject接口5.2 BlockingQueue新增tryPut方法5.3 修改ThreadPool的execute方法5.4 ThreadPool线程池构造函数修改5.5 拒绝策略实现1…...

挂耳式蓝牙耳机哪家的好用?购买耳机前必须了解的几大要点
随着健康意识的提升,越来越多的人开始热衷于运动。运动不仅能够增强体质,对于我们这些忙碌的上班族而言,它也是一种极佳的减压方式。经过一天的辛勤工作,能够在户外跑步,让汗水带走压力,实在是一种享受。在…...

故障排查详解
故障排查详解 本章导读 系统故障不可避免,但快速定位和解决问题的能力决定了系统的可用性。本章系统讲解OOM、CPU飙升、死锁等常见故障的排查方法与工具使用,帮助读者建立完整的故障排查体系,从"盲人摸象"进化到"精准定位"。 学习目标: 目标1:掌握JDK…...

魔兽争霸3终极优化方案:用WarcraftHelper解决现代系统兼容性问题
魔兽争霸3终极优化方案:用WarcraftHelper解决现代系统兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代电…...

递归神经网络与RTRL算法原理及优化实践
1. 递归神经网络与RTRL算法基础解析递归神经网络(RNN)与传统前馈神经网络的核心差异在于其反馈连接结构。这种结构赋予了RNN独特的"记忆"能力,使其能够处理时间序列数据中的动态模式。图1展示了二者的架构差异:前馈网络…...

MacBook M1/M2芯片上,用Python 3.10手动安装PyTorch全家桶的保姆级避坑指南
MacBook M1/M2芯片Python 3.10环境配置:PyTorch全家桶精准安装实战手册 当你在M1/M2芯片的MacBook上打开终端,输入那行看似简单的pip install torch命令时,系统报错的那一刻,可能就开启了一场令人头疼的依赖关系迷宫之旅。作为深…...

多速率信号处理:采样率转换与高效实现技术
1. 多速率信号处理基础概念多速率信号处理是数字信号处理领域的一项核心技术,它研究如何高效地改变离散时间信号的采样率。在现实工程应用中,我们经常需要在不同采样率的系统之间转换信号,例如将CD音质的44.1kHz音频转换为DVD标准的48kHz。传…...

SymPyBotics实战:如何为你的Scara或Delta机器人快速生成最小惯性参数集?
SymPyBotics实战:Scara与Delta机器人最小惯性参数集生成指南 在机器人动力学参数辨识领域,工程师们常常面临一个核心挑战:如何从复杂的全参数模型中提取出真正影响系统行为的核心参数集?这个问题对于Scara和Delta这类高速精密机器…...

颠覆性突破:如何在Windows上无缝运行Android应用的终极指南
颠覆性突破:如何在Windows上无缝运行Android应用的终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾渴望在Windows电脑上直接运行心仪的And…...

在Petalinux里像操作内存一样控制FPGA逻辑:ZYNQ7020 AXI_EMC Linux驱动开发指南
在Petalinux中实现用户空间直接操控FPGA逻辑:ZYNQ7020 AXI_EMC开发实战 当我们需要在ZYNQ平台上实现PS与PL的高效交互时,传统的内核驱动开发模式往往会成为性能瓶颈。想象一下这样的场景:你的FPGA逻辑需要实时响应来自Linux应用层的控制信号&…...

别再只盯着PSNR了!图像修复/超分实战中,SSIM、LPIPS、FID到底该怎么选?
图像修复与超分实战:如何科学选择评估指标? 当你熬了几个通宵训练出的超分辨率模型在测试集上PSNR值爆表,但生成的图像却让产品经理皱起眉头说"看起来怪怪的"时,作为工程师的你是否感到困惑?这种"指标很…...

ENVI 5.3在Win10/Win11安装踩坑实录:MSVC_2010报错、license消失、远程桌面打不开,一次搞定
ENVI 5.3在Win10/Win11安装全攻略:从报错排查到系统级优化 第一次在Windows 10或11上安装ENVI 5.3的经历,对很多遥感领域的从业者来说简直是一场噩梦。我清楚地记得那个深夜,实验室只剩下我一个人对着屏幕上反复出现的MSVC_2010安装失败提示束…...