gitlab-ci_cd语法CICD
工作原理
1、将代码托管在git
2、在项目根目录创建ci文件.gitlan-ci.yml 在文件中指定构建,测试和部署脚本
3、gitlab将检测到他并使用名为git Runner的工具运行脚本
4、脚本被分组为作业,他们共同组成了一个管道
gitlab-ci的脚本执行,需要自定义按照对应的gitlab-runner来执行,代码push之后 webhook检测到代码变化就会触发gitlan-ci,分配到各个Runner来运行相应的脚本script
gitlab Runner
类型
shared 共享类型,运行整个平台项目的作业(gitlab)
group 项目组类型,运行特定group下的所有项目的作业(group)
sprcific 项目类型,运行指定的项目作业(project)
状态
locked 锁定状态,无法运行项目作业
paused 暂停状态,暂时不会接收新的作业
流水线语法
job(作业)
在每个项目中,使用名为.gitlab-ci.yml的YML文件配置Gitlab CL/CD管道,在文件中可以定义一个或多个作业(job)每个作业必须具有唯一名称(不能使用关键字),每个作业是独立运行的,作业定义了在约束条件下进行相关操作,每个作业至少要包含一个script.
例:
job1:
script: "execute-script-for-job1"
job2:
script: "execute-script-for-job2"
这里定义了两个作业,每个作业运行不同命令,命令可以是shell或脚本
script
(运行shell或者脚本)
列:
job1:
script:
- uname -a
- bundle exec rspec
注意:有时script命令需要用单引号或双引号引起来,例如,包含冒号命令(:)需要加引号,以便被包裹的YAML解析器知道来解释整个事情作为一个字符串,而不是一个"“键:值”"对,使用特殊字符是消息::,{,},[,],,,&,*,#,?,|,-,<,>,=,!,%,@,```
before_script
用于定义一个命令,在该命令在每个作业之前运行。必须是一个数组。知道的scripy与脚本中知道的任何脚本串联在一起,并在单个shell中一起执行
before_script失败导致整个作业失败,其他作业将不再执行。作业失败不会影响after_script
after_script
用于定义将每个作业(包括失败的作业)之后运行的命令
这必须是一个数组
指定的脚本在新的shell中执行,与任何before_script或script脚本分开
before_script或script执行失败不影响after_script执行
stages
用于定义作业可以使用的阶段,并且是全局定义
同一阶段的作业并行运行,不同阶段按顺序执行
stages:
- build
- test
- codescan
- deploy
.pre&.post
.pre始终是整个管道的第一运行阶段,.post始终是整个管道的最后一个运行阶段。用户定义的阶段都在两者之间运行。.pre和.post的顺序无法更改。如果管道仅包含.pre或.post阶段的作业,则不会创建管道
codescan:
stage: .pre
tags:
- build
only:
- master
script:
- echo "codescan"
stage
按job定义的,并且依赖与全局定义的stages。它允许将作业分为不同的阶段,并且统一stage作业可以并行执行
varibales
定义变量,pipeline变量、job变量。job变量优先级最大
tags
指定runner
用于从允许该项目的所有Runner列表中选择指定的Runner,在Runner注册期间,你可以指定Runner的标签
windows job:
stage:
- build
tags:
- windows
script:
- echo Hello,%$USERNAME%:
osx job:
stage:
- build
tags:
- osx
script:
- echo "Hello, $USER:"
allow_failure(允许失败)
allpw_failure允许作业失败,默认值为false,启用后如果作业失败,改作业将在用户界面显示橙色警告,但是,管道的逻辑流程将任务作业成功/通过,并且不会被阻塞。假设所有其他作业均成功,则改作业的阶段及其管道将显示相同的橙色警告。但是,管理的提交将被标记为"通过",而不会发出警告。
windows job:
stage:
- build
tags:
- windows
script:
- echo Hello,%$USERNAME%:
allow_failure: true
when(控制作业允许)
on_success 前面阶段中的所有作业都成功时才执行作业,默认值
on_failure 当前面阶段出现失败时执行
always 总是执行作业
manual 手动执行作业
delayed 延迟执行作业
retry(重试)
配置在失败的情况下重试作业的次数
当作也失败并配置了retry,将再次处理该作业,直到达到retry关键字指定的次数
如果当retry设置为2,斌却作业在第二次允许成功(第一次重试),则不会再次重试,retry值必须是一个正整数,等于或大于0,小于或等于2(最多两次重试,总共允许三次)
retry-重试-精确匹配错误
默认情况下,在失败情况下重试作业,max:最大重试次数 when:重试失败的错误类型
always :在发生任何故障时重试(默认).
unknown_failure :当失败原因未知时。
script_failure :脚本失败时重试。
api_failure :API失败重试。
stuck_or_timeout_failure :作业卡住或超时时。
runner_system_failure :运行系统发生故障。
missing_dependency_failure: 如果依赖丢失。
runner_unsupported :Runner不受支持。
stale_schedule :无法执行延迟的作业。
job_execution_timeout :脚本超出了为作业设置的最大执行时间。
archived_failure :作业已存档且无法运行。
unmet_prerequisites :作业未能完成先决条件任务。
scheduler_failure :调度程序未能将作业分配给运行scheduler_failure。
data_integrity_failure :检测到结构完整性问题。
例:
unittest:
stage: test
tags:
- build
only:
- master
script:
- ech "run test"
retry:
max: 2
when:
- script_failure
timeout-超时
作业级别的超时可以超过项目级别超时,但不能超过Runner特定的超时
build:
script: build.sh
timeout: 3hours 30minutes
test:
script: rspec
timeout: 3h 30m
timeout-超时-runner超时
如果小于项目定义超时时间将具有优先权,此功能可用于通过设置大超时(例如一个星期)来防止Shared Runner被项目占用。未配置时 Runner将不会覆盖项目超时
示列1:运行程序超时大于项目超时
runner超时设置为24小时,项目的CI/CD超时设置为2小时。
该工作将在2小时后超时
示例2:未配置运行程序超时
runner不设置超时时间,项目的CI/CD超时设置为2小时
该工作将在2小时后超时
示例3:运行程序超时小于项目超时
runner超时设置为30分钟,项目的CI/CD超时设置为2小时
工作在30分钟后超时
parallel-并行作业
配置要并行运行的作业实例数,此值必须大于或等于2并且小于或等于50
这将创建n个并行运行的同一作业实例、他们从job_name 1/n到job_name n/n依次命名
only&ecxept限制分支标签
only和ecxept用分支策略来限制jobs构建
only定义那些分支和标签的git项目将会被job执行
ecxept定义那些分支和标签的git项目将不会被job执行
job:
#use regexp
only:
- /^issue-.*$/
#use specli keyword
ecxept:
- branches
rules-构建规则
rules允许按顺序苹果单个规则,直到匹配并为作业动态提供属性
rules不能与only/except组合使用
可用规则
if (如果条件匹配)
changes (指定文件发生变化)
exists (指定文件存在)
列:rules-if-条件匹配
如果DOMAIN的值匹配,则需要手动运行
不匹配on_success
条件判断从上到下,匹配即停止
多条件匹配可以使用&&||
variables:
DOMAIN: example.com
codescan:
stage: codescan
tags:
- build
script:
- echo "codescan"
- sellp 5;
#parallel:5
rules:
- if:'$DOMAIN == "example.com"'
when: manual
when: on_success
rules-changes-文件变化
接受文件路径数组
如果提交jenkinsfile文件发送的变化则为true
codescan:
stage: codescan
tags:
- build
script:
- echo "codescan"
- sleep 5;
#parallel:5
rules:
- changes:
- jenkinsfile
when: manual
- if:'$DOMAIN == "example.com"'
when: on_success
- when: on_success
rules-allow_failure-允许失败
使用rules-allow_failure: true
rules:在不停止管道本身的情况虚啊允许作业失败或手动作业等待操作
job:
script "echo Hello,Rules"
rules:
- if:'$CI_meRGE_REQUEST_TARGET_BRABCH_NAME == "master"'
when: manual
allow_failure
workflow-rules-管道创建
定价workflow关键字适用于整个管道,并将确定是否创建管道
when:可以三个字为always或never,如果未提供,则默认值未always
variables:
DOMAIN: example.com
workflow:
rules:
- if: '$DOMAIN == "example.com"'
- when: always
cache-缓存
存储编译项目所需运行时的依赖项,指定项目工作空间钟需要在job之间缓存吃的文件目录
全局cache定义在job之外,针对所有job生效。job钟cache优先于全局
cache:paths
在job build中定义缓存,将会缓存target目录下的所有,jar文件
挡在全局定义了cache:paths会被job覆盖,一下实例将缓存target
build:
script: test
cache:
paths:
- target/*.jar
cache:
paths:
- my/files
build:
script: echo "Hello"
cache:
key: build
paths:
- target/
由于缓存是在job之间共享的,如果不同的job使用不同的路径就出现了缓存覆盖的问题
如何让不同的job缓存不同的cache呢
设置不同的cache:key
cache:key-缓存标记
为缓存做个标记,可以配置job、分支为key来实现分支、作业特定的缓存
为不同job定义了不同的cache:key时,会为每个job分配一个独立的cache
cache:key变量可以使用任何预定义变量,默认default
从gitlab9.0开始 默认情况下所有内容都在管道和作业之间共享
按分支设置缓存
cache:
key: ${CI_COMMIT_REF_SLUG}
cache:key:files-文件变化自动创建缓存
files: 文件发送变化自动重新生成缓存(files最多指定两个文件),提交的时候检查指定的文件
根据指定的文件生成密钥计算sha校验和,如果文件未改变值为default
cache:
key:
files:
- Gemfile.lock
- package.json
paths:
- endor/ruby
- node_modules
cache:key:prefix-组合生成sha校验和
prefix: 允许给定prefix的值与指定文件生成的密钥组合
在这里定义了全局的cache,如果文件发送变化则值未repec-xxx11122211,如未发生变化未rspec-default
cache:
key:
files:
- Gemfile.lock
prefix: $(CI_JOB_NAME)
path:
- vendor/ruby
rspec:
script:
- bundle exec rspec
cache:policy-缓存策略
默认在执行开始下载文件,并在结束时重新上传文件
policy:pull跳过下载步骤,policy:push跳过上传步骤
artifacts-制品
用于指定在作业成功或者失败是应附加到作业的文件或目录的列表,作业完成后工件将被发送到gitlab,并可在gitlab ui中下载
artifacts:
paths:
- target/
例:
default-job:
script:
- mvn test -U
except:
- tags
release-job:
script:
- mvn package -U
artifacts:
path:
- target/*.war
oniy:
- tags
artifacts:expose_as-MR展示制品
关键字expose_as可用于在合并请求UI中公开作业工件
每个合并请求最多可以公开10个作业工件
列:
test:
script:
- echo 1
aritifacts:
expose_as:'artifact 1'
patchs:
- path/to/file.txt
artifacts:name-制品名称
通过name指令定义所创建的弓箭存档的名称,可以为每个档案使用唯一的名称
artifacts:name默认名称是artifacts,下载artifacts改为artifacts.zip
列:
job:
artifacts:
name: "$CI_JOB_NAME"
patchs:
- binaries/
job:
artifacts:
name: "$CI_COMMIT_REF_NAME"
paths:
- binaries/
artifacts:when-制品创建条件
用于在作业失败时或成功上传工件
on_success仅在作业成功时上载工件 默认值
on_failure仅在作业失败时上传工件
always 上传工件,无论作业状态如何
例:
job1:
artifacts:
when: on_failure
job2:
artifacts:
when: on_success
job3:
artifacts:
when: always
artifacts:expire_in-制品保留时间
制品的有效期,从上传和存储到gitlab的时间算起,如果未定义过期时间,则默认为30天
expire_in的值以秒为单位的警告时间,除非提供了单位
例:
job:
artifacts:
expire_in: 1 week
artifacts:reports:junit-单元测试报告
收集junit单元测试报告,收藏JUnit报告将作为工作上传到gitlab,并将自动显示在合并请求中
列:
build:
stage: build
tags:
- build
only:
- master
script:
- mvn test
- mvn cobertura:cobertura
- ls target
artifacts:
name: "$CI_JOB_NAME-$CI_COMMIT"_REF_NAME"
when: on_success
expose_api: 'artifact 1'
paths:
- target/*,jar
reports
junit: target/surefire-reports/TEST-*.xml
dependencies-获取制品
定义要获取工件的作业列表,只能从当前阶段之前执行的阶段定义作业,定义一个空数组将跳过下载该作业的任何工件将不会考虑先前作业的状态,因此,如果它失败或是未运行的手动作业,则不会发生错误。如果设置未依赖项的工作工件已过期或删除,那么依赖项作业将失败。
列:
unittest:
dependencies:
- build
needs-阶段并行
可无序执行作业,无需按阶段顺序运行某些作业,可以让多个阶段同时运行。
如果needs:设置为指向因only/except规则而未实例化的作业,或者不存在,则创建管道时会出现YML错误
列:
module-a-test:
stage: test
script:
- echo "Hello"
- sleep 10
needs:
- job: "module-a-build"
needs-制品下载
在使用needs可通过artifacts: true或artifacts: false来控制工件下载,默认不知道为true
列:
module-a-test:
stage: test
script:
- echo "Hello"
- sleep 10
needs:
- job: "module-a-build"
artifacts: true
include:local-引入本地配置
可以允许引入外部YAML文件,文件具有扩展名.yml或yaml
使用合并功能可以自定义和覆盖包含本地定义的CI/CD配置
引入同一存储库中得文件,使用相对于根目录得完整路径进行引用,与配置文件在同一分支上使用
列:
ci/localci.yml
stages:
- deploy
deployjob:
stage: deploy
script:
- echo 'deploy'
include:
local: 'ci/localci.yml'
include:file-引入其他项目配置
引入另外项目master分支的.gitlab-ci.yml配置
include:
- project: <项目名称>
ref: master
file: '.gitlab-ci.yml'
include-template-引入官方配置
https://gitlab.com/gitlab-org/gitlab/tree/master/lib/gitlab/ci/templates
include:
- template: AUTO-DevOps.gitlab-ci.yml
include:remote-引入远程配置
用于通过HTTP/HTTPS包含来自其他位置的文件,并使用完整URL进行引用,远程文件必须可以通过简单的GET请求公开访问,因为不支持远程URL中的身份验证
include:
- remote: 'https://gitlab.com/awesome-project/raw/master/.gitlan-ci-template.yml'
extends-继承作业配置
.tests:
script: mvn test
stage: test
only:
refs:
- tags
testjob:
extends: .tests
script: mvn clent test
only:
cariables:
- $RSPEC
testjob:
stage: test
script: mvn clent test
only:
variables:
- $RSPEC
refs:
- tags
extends&include
这将运行名为useTenplate的作业,该作业运行echo Hello 如.template作业中所定义,并使用本地作业中所定义的apline Docker映射
aa.yml
.template:
script:
- echo Hello
include: aa.yml
useTemplate:
image: alpine
extends: .template
trigger管道触发
当gitlab从trigger定义创建的作业启动时,将创建一个下游管道,允许创建多项目管道和子项目管道,将trigger于when:monual一起使用会导致报错
多项目管道:跨多个项目设置流水线,以便一个项目中的管道可以触发另一个项目中的管道
父子管道:在同一项目管道可以触发一组同时运行的子管道,子管道仍然按照阶段顺序执行其每个作业,但是可以自由地继续执行各个阶段,而不必等待父管道中无关的作业完成
image
默认在注册runner的时候需要填写一个基础的镜像,请记住一点只要使用执行器为docker类型的runner所以的操作运行都会在容器中运行,如果全局指定了images则所以作业使用此image创建容器并在其中运行,全局未指定image,再次查看job中是否有指定,如果有此job按照指定镜像创建容器并运行,没有则使用注册runner时指定的默认镜像
build:
image: 镜像名称:标签
stage: build
tags:
- aws
- docker
script:
- ls
- sleep 2
- mvn clen package
- sleep 10
depal:
stage: deplay
tags:
- aws
script:
- echo "deplay"
services
工作期间运行的另一个docker镜像,并link到image关键字定义的docker镜像。这样就可以在构建期间访问服务映像
服务映像可以运行任何程序,但是最常见的用例是运行数据库容器,例如mysql,与每次按照项目时都安装mysql相比 使用现有的映像并将其作为附加容器运行更容易,更快捷
services:
- name: mysql:latest
alias: mysql-1 #别名
environment
工作期间运行的另一个docker映像,并link到image关键字定义的docker映像,这样在构建期间访问服务映像
deolay to production:
stage: deplay
script: git push production HEAD:master
environment:
name: production #部署环境名称
url: http://prod.example.com #部署环境地址
inherit
使用或禁用全局定义的环境变量(variables)或默认值(default)
使用true、false觉得是否使用,默认为true
inherit:
default: false
variables: false
继承其中的一部分变量或默认值使用list
inherit:
default:
- parameter1
- parameter1
variables: false
- VARIABLE1
- VARIABLE2
创建CI模板库
1.创建一个git仓库用于存放模版
2.创建一个template目录存放所有pipeline的模版
3.创建一个jobs目录存放job模版
这样我们可以将一些maven,ant,gradle,npm工具通过一个job模版和不同的构建命令实现,templates的好处时我们在其中定义了模版流水线,这些流水线可以直接让项目使用,当遇到个性化项目的时候就可以在当前姓名创建.gitlab-ci.yml文件来引用模版文件,再进一步实现个性化需要
工具链集成
后端项目Maven集成
环境基础配置:
首先在jobs目录创建一个build.yml,然后在里面编写build作业模版
.build:
stages: build
tags:
- build
script:
- $BUILD_SHELL
- ls
然后在template目录中创建maven流水线模版。templates/java-pipeline.yml
include:
- project: 'demo/demo-gitlabci-service'
ref: master
file: 'jobs/build.yml'
variables:
BUILD_SHELL: 'mvn clean package -DskipTests' #构建命令
TEST_SHELL: 'mvn test' #测试命令
CACHE_DIR: 'target/' #构建缓存
cache:
paths:
- ${CACHE_DIR}
stages:
- build
build:
stage: build
extends: .build
工具链集成-代码质量管理平台集成
SonarQube自动扫描
安装sonarscanner
https://docs.sonarqube.org/latest/setup/get-started-2-minutes/
相关文章:

gitlab-ci_cd语法CICD
工作原理 1、将代码托管在git 2、在项目根目录创建ci文件.gitlan-ci.yml 在文件中指定构建,测试和部署脚本 3、gitlab将检测到他并使用名为git Runner的工具运行脚本 4、脚本被分组为作业,他们共同组成了一个管道gitlab-ci的脚本执行,需要自…...

python 蓝桥杯之动态规划入门
文章目录 DFS滑行(DFS 记忆搜索) 思路: 要思考回溯怎么写(入参与返回值、递归到哪里,递归的边界和入口) DFS 滑行(DFS 记忆搜索) 代码分析: 学会将输入的数据用二维列表…...
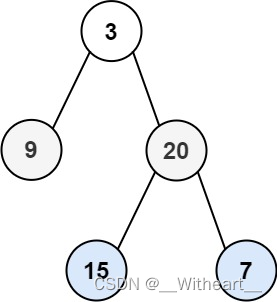
[LeetCode][102]二叉树的层序遍历——遍历结果中每一层明显区分
题目 102. 二叉树的层序遍历 给定二叉树的根节点 root,返回节点值的层序遍历结果。即逐层地,从左到右访问所有节点。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]] 示例 2: 输入…...

GIS之深度学习10:运行Faster RCNN算法
(未完成,待补充) 获取Faster RCNN源码 (开源的很多,论文里也有,在这里不多赘述) 替换自己的数据集(图片标签文件) (需要使用labeling生成标签文件…...

appium2的一些配置
appium-desktop不再维护之后,需要使用appium2。 1、安装appium2 命令行输入npm i -g appium。安装之后输入appium或者appium-server即可启动appium 2、安装安卓/ios的驱动 安卓:appium driver install uiautomator2 iOS:appium driver i…...
基于springboot+vue实现高校学生党员发展管理系统项目【项目源码+论文说明】
基于springboot实现高校学生党员发展管理系统演示 摘要 随着高校学生规模的不断扩大,高校内的党员统计及发展管理工作面临较大的压力,高校信息化建设的不断优化发展也进一步促进了系统平台的应用,借助系统平台可以实现更加高效便捷的党员信息…...
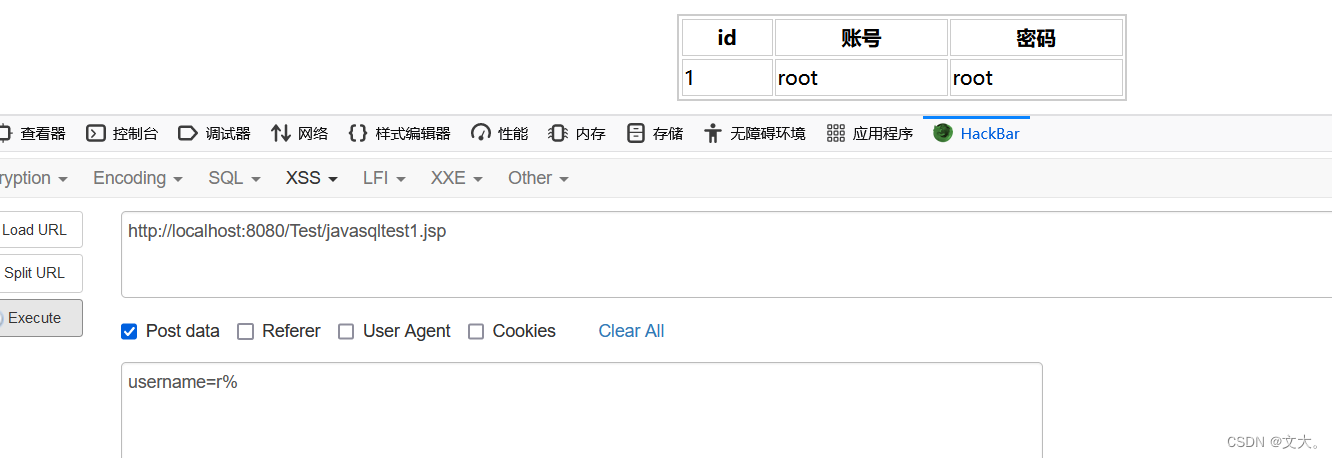
Java代码审计安全篇-常见Java SQL注入
前言: 堕落了三个月,现在因为被找实习而困扰,着实自己能力不足,从今天开始 每天沉淀一点点 ,准备秋招 加油 注意: 本文章参考qax的网络安全java代码审计,记录自己的学习过程,还希望…...

C#实现快速排序算法
C#实现快速排序算法 以下是C#中的快速排序算法实现示例: using System;class QuickSort {// 快速排序入口函数public static void Sort(int[] array){QuickSortRecursive(array, 0, array.Length - 1);}// 递归函数实现快速排序private static void QuickSortRecu…...
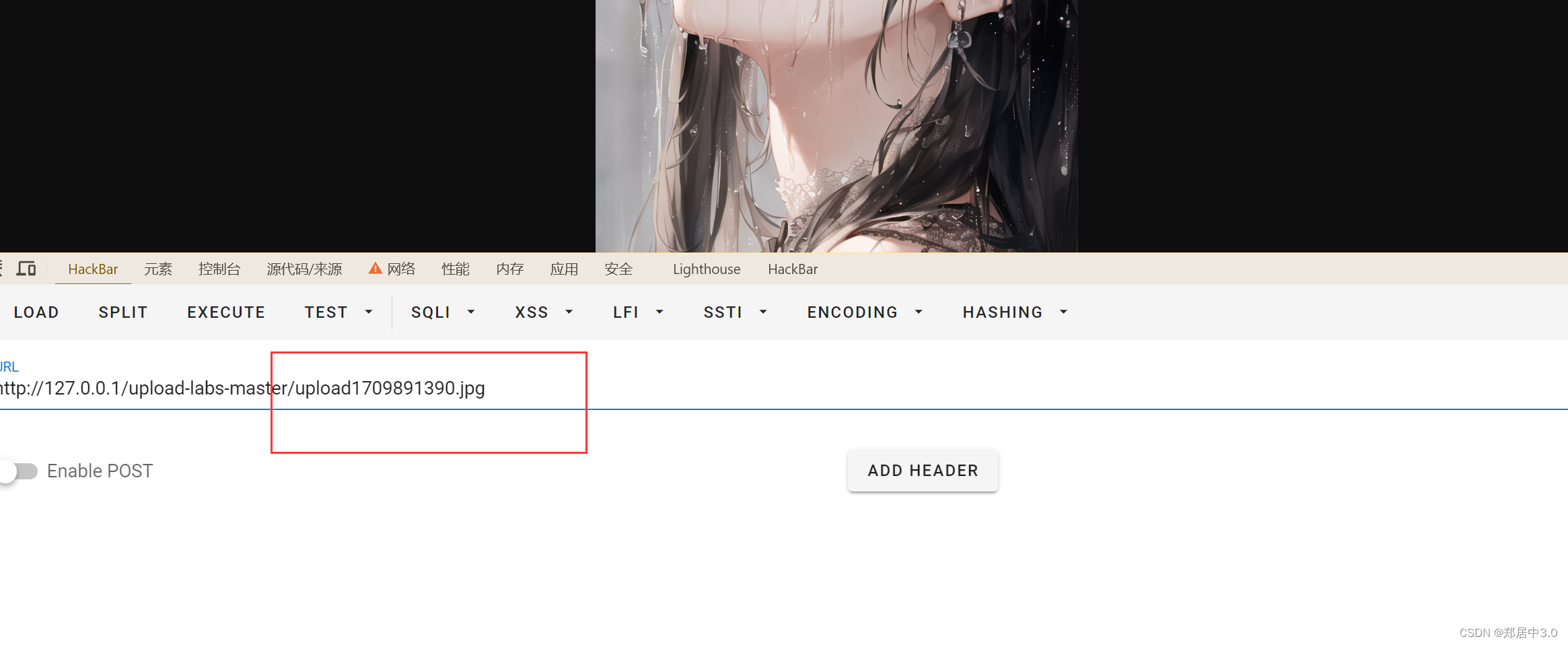
upload-labs通关记录
文章目录 前言 1.pass-012.pass-023.pass-034.pass-045.pass-056.pass-067.pass-078.pass-089.pass-0910.pass-1011.pass-1112.pass-1213.pass-1314.pass-1415.pass-1516.pass-1617.pass-1718.pass-1819.pass-19 前言 本篇文章记录upload-labs中,所有的通过技巧和各…...
Nginx实现高并发
注:文章是4年前在自己网站上写的,迁移过来了。现在看我之前写的这篇文章,描述得不是特别详细,但描述了Nginx的整体架构思想。如果对Nginx玩得透得或者想了解深入的,可以在网上找找其他的文章。 ......................…...

华为荣耀终端机试真题
文章目录 一 、字符展开(200分)1.1 题目描述1.2 解题思路1.3 解题代码二、共轭转置处理(100分)2.1 题目描述2.3 源码内容一 、字符展开(200分) 1.1 题目描述 // 64 位输出请用 printf(“%lld”)给定一个字符串,字符串包含数字、大小写字母以及括号(包括大括号、中括号…...
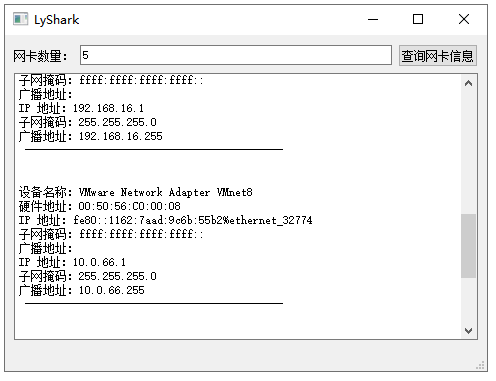
C++ Qt开发:QNetworkInterface网络接口组件
Qt 是一个跨平台C图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本章将重点介绍如何运用QNetworkInterface组件实现查询详细的…...
Luajit 2023移动版本编译 v2.1.ROLLING
文章顶部有编好的 2.1.ROLLING 2023/08/21版本源码 Android 64 和 iOS 64 luajit 目前最新的源码tag版本为 v2.1.ROLLING on Aug 21, 2023应该是修正了很多bug, 我是出现下面问题才编的. cocos2dx-lua 游戏 黑屏 并报错: [LUA ERROR] bad light userdata pointer 编…...

c++ 常用新特性总结【c++11】,【c++14】,【c++17】,【c++20】
文章目录 常用的c11新特性1.自动推导类型(auto)2.lambda表达式3.智能指针4.范围for循环5.右值引用 - 移动语义6.类型别名7.constexpr8.static_assert(静态断言)9.nullptr10.列表初始化11.继承构造函数12.显示虚函数重载(override)13.final14.变长模板参数15.新的容器与算法16.强…...
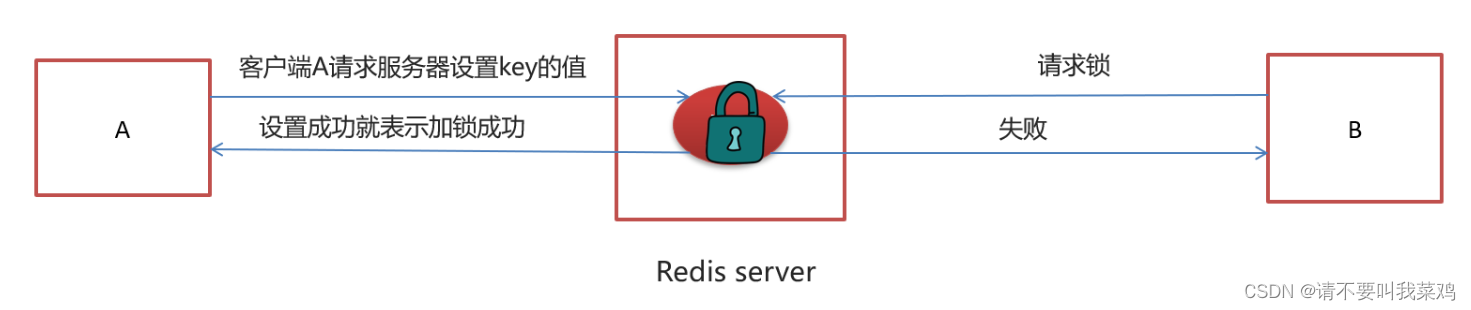
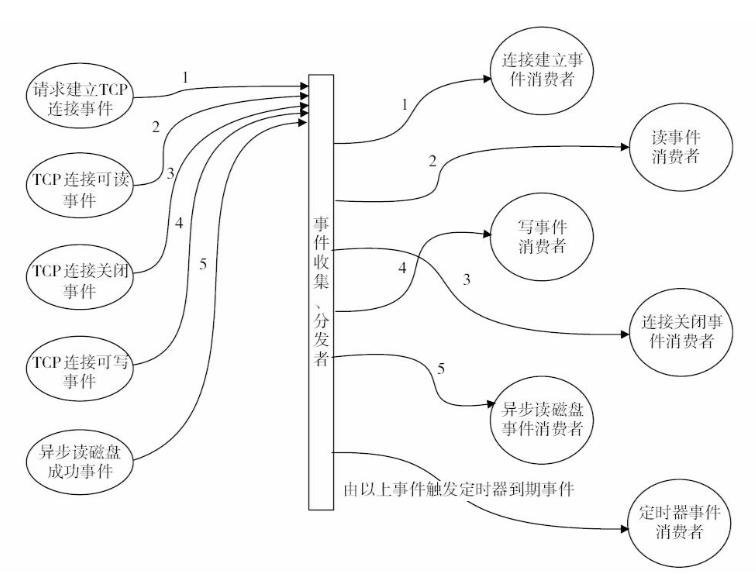
Feign实现微服务间远程调用续;基于Redis实现消息队列用于延迟任务的处理,Redis分布式锁的实现;(黑马头条Day05)
目录 延迟任务和定时任务 使用Redis设计延迟队列原理 点评项目中选用list和zset两种数据结构进行实现 如何缓解Redis内存的压力同时保证Redis中任务能够被正确消费不丢失 系统流程设计 使用Feign实现微服务间的任务消费以及文章自动审核 系统微服务功能介绍 提交文章-&g…...

CSS 常见属性设置
一. 文本属性 1.1. 装饰线 text-decoration text-decoration有如下常见取值: none:无任何装饰线(可以去除a元素默认的下划线)underline:下划线overline:上划线line-through:中划线(删除线&…...
docker学习入门
1、docker简介 docker官网: www.docker.com dockerhub官网: hub.docker.com docker文档官网:docs.docker.com Docker是基于Go语言实现的云开源项目。 Docker的主要目标是:Build, Ship and Run Any App, Anywhere(构建&…...
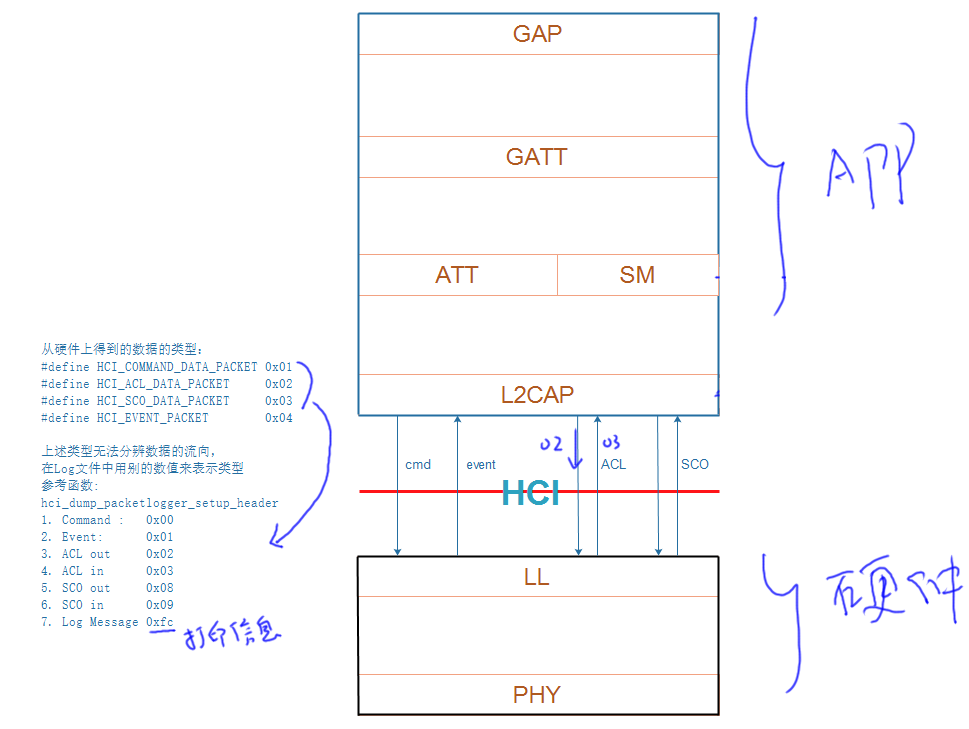
蓝牙系列七:开源蓝牙协议栈BTStack数据处理
继续蓝牙系列的研究。 在上篇博客,通过阅读BTStack的源码,大体了解了其框架,对于任何一个BTStack的应用程序都有一个main函数,这个main函数是统一的。这个main函数做了某些初始化之后,最终会调用到应用程序提供的btstack_main,在btstack_main里面首先做一些初始化,然后…...

数据仓库作业一:第1章 绪论
目录 一、给出下列英文短语或缩写的中文名称,并简述其含义。二、简述操作型数据与分析型数据的主要区别。三、简述数据仓库的定义。四、简述数据仓库的特征。五、简述主题的定义。六、简述元数据的概念。七、简述数据挖掘的主要任务。八、简述数据挖掘的主要步骤。九…...

spring aop中获取request和response
Spring AOP 操作中如何使用request和response 实际使用时,如果方法一不行,请使用方法二 方法一 HttpServletRequest request ((ServletRequestAttributes) RequestContextHolder.getRequestAttributes()).getRequest(); HttpServletResponse respons…...

避坑指南:用vprbs做SerDes链路仿真时,你的PRBS序列真的设对了吗?
高速SerDes验证实战:vprbs参数配置与PRBS序列生成深度解析 在高速串行接口(SerDes)验证领域,PRBS(伪随机二进制序列)测试堪称链路性能评估的"黄金标准"。作为芯片验证工程师,我们经常需要在Cadence仿真环境中使用analogLib库的vprb…...

别再只盯着PSNR了!图像修复/超分实战中,SSIM、LPIPS、FID到底该怎么选?
图像修复与超分实战:如何科学选择评估指标? 当你熬了几个通宵训练出的超分辨率模型在测试集上PSNR值爆表,但生成的图像却让产品经理皱起眉头说"看起来怪怪的"时,作为工程师的你是否感到困惑?这种"指标很…...

告别Office依赖!用Qt和QXlsx 1.4.3独立读写Excel的保姆级教程
告别Office依赖!用Qt和QXlsx 1.4.3独立读写Excel的保姆级教程 在跨平台应用开发中,处理Excel文件一直是个令人头疼的问题。传统方案依赖Office或WPS组件,不仅增加部署复杂度,在Linux服务器、嵌入式设备等环境中更是难以实现。本文…...
)
Spring Boot 4.0 Agent-Ready 架构安全配置清单(含12项必须关闭的默认危险行为、8个JVM Agent签名验证checklist)
第一章:Spring Boot 4.0 Agent-Ready 架构安全演进全景图Spring Boot 4.0 将 JVM Agent 集成能力作为核心架构契约,重构了类加载、字节码增强与运行时可观测性之间的信任边界。其安全演进并非简单叠加防护层,而是通过“零信任代理模型”&…...

5个实用技巧:用NHSE轻松定制你的动物森友会岛屿
5个实用技巧:用NHSE轻松定制你的动物森友会岛屿 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE NHSE(Animal Crossing: New Horizons save editor)是一款专业的…...
看单色图了!手把手教你玩转OpenCV通道分离与合并的3个实战场景)
别再只会用cv2.split()看单色图了!手把手教你玩转OpenCV通道分离与合并的3个实战场景
OpenCV通道操作实战:从滤镜设计到植物识别的创意应用 在图像处理领域,通道分离与合并看似基础,实则蕴含着巨大的创意潜力。许多开发者掌握了cv2.split()和cv2.merge()的基本用法后,往往止步于简单的通道查看操作,却忽…...

Hearthstone-Script终极指南:如何用Java/Kotlin打造智能炉石传说自动化脚本
Hearthstone-Script终极指南:如何用Java/Kotlin打造智能炉石传说自动化脚本 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 在炉石传说这款…...

ROS可视化界面卡住?手把手教你解决WSL2+Ubuntu 20.04中rviz的Segmentation fault和X11连接问题
WSL2ROS可视化工具崩溃全解析:从X11原理到实战修复 每次满怀期待地在WSL2中键入rviz命令,却只等来一个闪烁的光标或冰冷的"Segmentation fault"提示——这种挫败感恐怕每个ROS开发者都深有体会。本文将带您深入X11转发的技术腹地,用…...
)
PYTHON学习笔记12(os模块)
OS文件/目录方法os模块是python标准库中的一个重要模块,提供了与操作系统交互的功能,通过此模块可以执行文件操作、目录操作、环境变量管理、进程管理等任务。os模块是跨平台的,可以在不同的操作系统使用相同的代码。使用os模块之前ÿ…...

5大核心功能深度解析:NVIDIA Profile Inspector显卡驱动配置完全指南
5大核心功能深度解析:NVIDIA Profile Inspector显卡驱动配置完全指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专业的显卡驱动配置工具,能…...