RocketMQ架构详解
文章目录
- 概述
- RocketMQ架构
- rocketmq的工作流程
- Broker 高可用集群
- 刷盘策略
概述
RocketMQ一个纯java、分布式、队列模型的开源消息中间件,前身是MetaQ,是阿里研发的一个队列模型的消息中间件,后开源给apache基金会成为了apache的顶级开源项目,具有高性能、高可靠、高实时、分布式特点。
RocketMQ是阿里开源的分布式消息中间件,跟其它中间件相比,RocketMQ的特点是纯JAVA实现;集群和HA实现相对简单;在发生宕机和其它故障时消息丢失率更低。
RocketMQ架构
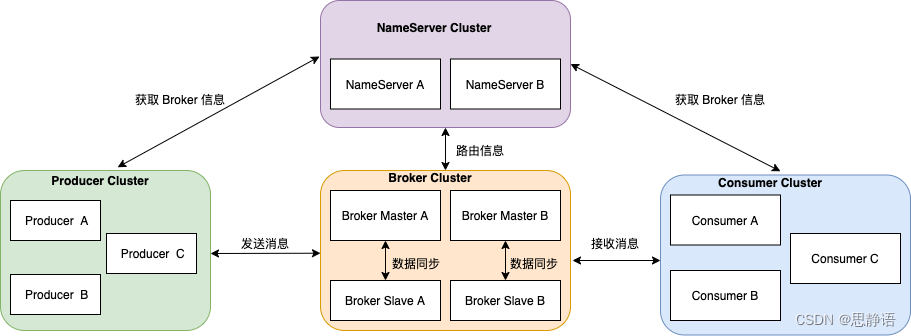
● Producer:消息生产者
● Consumer:消费者
● Broker:MQ 服务,负责接收、分发消息
● NameServer:负责 MQ 服务之间的协调
整体架构中包含四种角色
● Producer :消息发布的角色,Producer 通过 MQ 的负载均衡模块选择相应的 Broker 集群队列进行消息投递,投递的过程支持快速失败并且低延迟。
● Consumer :消息消费的角色,支持以 push 推,pull 拉两种模式对消息进行消费。
● NameServer :名字服务是一个非常简单的 Topic 路由注册中心,其角色类似 Dubbo 中的 zookeeper ,支持 Broker 的动态注册与发现。
● BrokerServer :Broker 主要负责消息的存储、投递和查询以及服务高可用保证
Producer
消息生产者,位于用户的进程内,Producer通过NameServer获取所有Broker的路由信息,根据负载均衡策略选择将消息发到哪个Broker,然后调用Broker接口提交消息。
Producer Group
生产者组,简单来说就是多个发送同一类消息的生产者称之为一个生产者组。
Consumer
消息消费者,位于用户进程内。Consumer通过NameServer获取所有broker的路由信息后,向Broker发送Pull请求来获取消息数据。Consumer可以以两种模式启动,广播(Broadcast)和集群(Cluster),广播模式下,一条消息会发送给所有Consumer,集群模式下消息只会发送给一个Consumer。
Consumer Group
消费者组,和生产者类似,消费同一类消息的多个 Consumer 实例组成一个消费者组。
Topic
Topic用于将消息按主题做划分,Producer将消息发往指定的Topic,Consumer订阅该Topic就可以收到这条消息。Topic跟发送方和消费方都没有强关联关系,发送方可以同时往多个Topic投放消息,消费方也可以订阅多个Topic的消息。在RocketMQ中,Topic是一个上逻辑概念。消息存储不会按Topic分开。
Message
代表一条消息,使用MessageId唯一识别,用户在发送时可以设置messageKey,便于之后查询和跟踪。一个 Message 必须指定 Topic,相当于寄信的地址。Message 还有一个可选的 Tag 设置,以便消费端可以基于 Tag 进行过滤消息。也可以添加额外的键值对,例如你需要一个业务 key 来查找 Broker 上的消息,方便在开发过程中诊断问题。
Tag
标签可以被认为是对 Topic 进一步细化。一般在相同业务模块中通过引入标签来标记不同用途的消息。
Broker
Broker是RocketMQ的核心模块,负责接收并存储消息,同时提供Push/Pull接口来将消息发送给Consumer。Consumer可选择从Master或者Slave读取数据。多个主/从组成Broker集群,集群内的Master节点之间不做数据交互。Broker同时提供消息查询的功能,可以通过MessageID和MessageKey来查询消息。Borker会将自己的Topic配置信息实时同步到NameServer。
Queue
Topic和Queue是1对多的关系,一个Topic下可以包含多个Queue,主要用于负载均衡。发送消息时,用户只指定Topic,Producer会根据Topic的路由信息选择具体发到哪个Queue上。Consumer订阅消息时,会根据负载均衡策略决定订阅哪些Queue的消息。
Offset
RocketMQ在存储消息时会为每个Topic下的每个Queue生成一个消息的索引文件,每个Queue都对应一个Offset记录当前Queue中消息条数。
NameServer
NameServer可以看作是RocketMQ的注册中心,它管理两部分数据:集群的Topic-Queue的路由配置;Broker的实时配置信息。其它模块通过Nameserv提供的接口获取最新的Topic配置和路由信息。
● Producer/Consumer :通过查询接口获取Topic对应的Broker的地址信息
● Broker : 注册配置信息到NameServer, 实时更新Topic信息到NameServer
rocketmq的工作流程
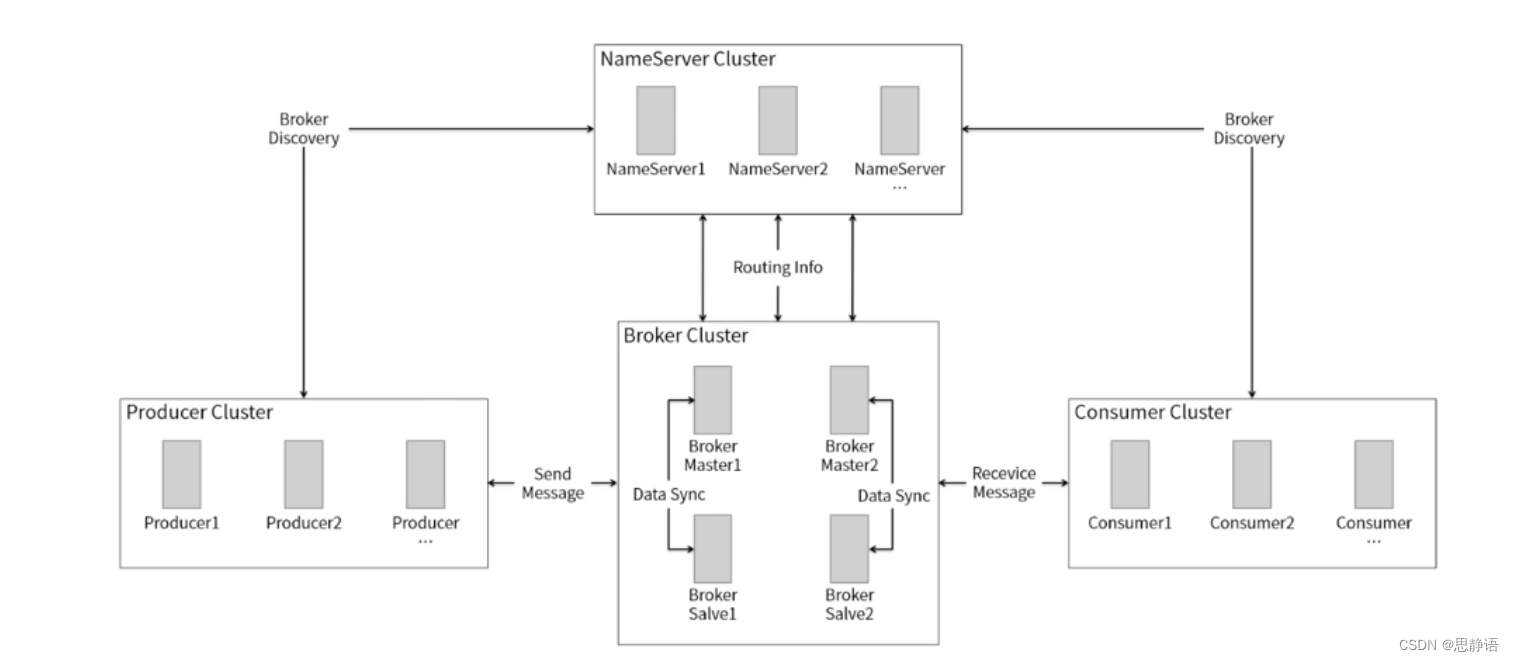
RocketMQ 是一个分布式消息中间件系统,其工作流程可以简单描述如下:
- Producer 发送消息:
生产者(Producer)通过发送消息到指定的 Topic(主题)。消息可以包含任意类型的数据,通常以键值对的形式发送。 - Broker 存储消息:
接收到消息的 Broker 节点将消息存储到对应的队列中。消息在 Broker 中以顺序存储,每个 Topic 可以有多个队列,用于水平扩展和提高并发处理能力。 - Consumer 消费消息:
消费者(Consumer)订阅感兴趣的 Topic,并从 Broker 获取消息进行消费。消费者可以以不同的消费模式(如广播模式、集群模式)消费消息。 - 消息过滤和路由:
RocketMQ 支持根据 Tag 进行消息过滤,消费者可以根据 Tag 过滤出需要的消息。此外,RocketMQ 还支持消息路由,确保相同 Key 的消息被发送到同一个队列,保证消息的有序性。 - 消息顺序保证:
RocketMQ 提供有序消息功能,确保消息按照发送顺序被消费。通过设置 MessageQueueSelector 接口实现消息的有序发送和消费。 - 高可用性和容错:
RocketMQ 集群部署方式支持主备架构,可以保证消息队列的高可用性和容错性。当 Master 节点宕机时,会自动选举一个 Slave 节点作为新的 Master,保证服务的持续性。 - 监控和管理:
RocketMQ 提供了丰富的监控和管理工具,可以实时监控消息发送和消费情况,查看集群健康状态,帮助用户及时发现和解决问题。
总的来说,RocketMQ 的工作流程包括消息生产、存储、消费、过滤、路由、顺序保证等环节,通过这些环节协同工作,实现了高性能、可靠性的消息传递和处理机制。
Broker 高可用集群
Broker 通过主从集群来实现消息高可用。跟 Kafka 不同的是,RocketMQ 并没有 Master 节点选举功能,而是采用多 Master 多 Slave 的集群架构。Producer 写入消息时写入 Master 节点,Slave 节点主动从 Master 节点拉取数据来保持跟 Master 节点的数据一致。
Consumer 消费消息时,既可以从 Master 节点拉取数据,也可以从 Slave 节点拉取数据。 到底是从 Master 拉取还是从 Slave 拉取取决于 Master 节点的负载和 Slave 的同步情况 。如果 Master 负载很高,Master 会通知 Consumer 从 Slave 拉取消息,而如果 Slave 同步消息进度延后,则 Master 会通知 Consumer 从 Master 拉取数据。总之,从 Master 拉取还是从 Slave 拉取由 Master 来决定。
如果 Master 节点发生故障,RocketMQ 会使用基于 raft 协议的 DLedger 算法来进行主从切换。Broker 每隔 30s 向 Name Server 发送心跳,Name Server 如果 120s 没有收到心跳,就会判断 Broker 宕机了
刷盘策略
RocketMQ 采用灵活的刷盘策略。
异步刷盘
消息写入 CommitLog 时,并不会直接写入磁盘,而是先写入PageCache 缓存中,然后用后台线程异步把消息刷入磁盘。异步刷盘策略就是消息写入 PageCache 后立即返回成功,这样写入效率非常高。如果能容忍消息丢失,异步刷盘是最好的选择。
同步刷盘
即使同步刷盘,RocketMQ 也不是每条消息都要刷盘,线程将消息写入内存后,会请求刷盘线程进行刷盘,但是刷盘线程并不会只把当前请求的消息刷盘,而是会把待刷盘的消息一同刷盘。同步刷盘策略保证了消息的可靠性,但是也降低了吞吐量,增加了延迟。
相关文章:
RocketMQ架构详解
文章目录 概述RocketMQ架构rocketmq的工作流程Broker 高可用集群刷盘策略 概述 RocketMQ一个纯java、分布式、队列模型的开源消息中间件,前身是MetaQ,是阿里研发的一个队列模型的消息中间件,后开源给apache基金会成为了apache的顶级开源项目…...

【AI视野·今日NLP 自然语言处理论文速览 第八十二期】Tue, 5 Mar 2024
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 5 Mar 2024 (showing first 100 of 175 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers Key-Point-Driven Data Synthesis with its Enhancement on Mathematica…...

windows 两个服务器远程文件夹同步,支持文件新增文件同步、修改文件同步、删除文件同步,根据文件大小和时间戳判断文件是否修改 python脚本
在Python中实现Windows两个服务器之间的文件夹同步,包括文件新增、修改和删除的同步,可以使用paramiko库进行SSH连接以及SFTP传输,并结合文件大小和时间戳判断文件是否发生过变化。以下是包含删除文件同步逻辑的完整脚本示例: im…...

vite项目修改node_modules
问题详情 在使用某个依赖的时候遇到了bug,提交issue后不想一直等待到作者更新版本,所以寻求临时自己解决 问题解决 在node_modules里找到需要修改的依赖,修改想要修改的代码 修改后记得保存 然后在node_modules里找到.vite文件夹&#x…...
NLP神器Transformers入门简单概述
在这篇博客中,我们将深入探索 🤗 Transformers —— 一个为 PyTorch、TensorFlow 和 JAX 设计的先进机器学习库。🤗 Transformers 提供了易于使用的 API 和工具,使得下载和训练前沿的预训练模型变得轻而易举。利用预训练模型不仅能减少计算成本和碳足迹,还能节省从头训练…...

微信小程序-wxml语法
介绍 WXML(WeiXin Markup Language)是框架设计的一套标签语言,可以进行页面布局,声明事件,数据绑定,条件判断。 语法 数据绑定 <view> {{message}} </view>// page.js Page({data: { // 状态…...

网络层转发分组的过程
分组转发都是基于目的主机所在网络的,这事因为互联网上的网络数远小于主机数,这样可以极大的压缩转发表的大小。当分组到达路由器后,路由器根据目的IP地址的网络地址前缀查找转发表,确定下一跳应当到哪个有路由器。因此࿰…...
计算两帧雷达数据之间的变换矩阵
文章目录 package.xmlCMakeLists.txtpoint_cloud_registration.cc运行结果 package.xml <?xml version"1.0"?> <package format"2"><name>point_cloud_registration</name><version>0.0.0</version><descriptio…...

2. gin中间件注意事项、路由拆分与注册技巧
文章目录 一、中间件二、Gin路由简介1、普通路由2、路由组 三、路由拆分与注册1、基本的路由注册2、路由拆分成单独文件或包3、路由拆分成多个文件4、路由拆分到不同的APP 一、中间件 在日常工作中,经常会有一些计算接口耗时和限流的操作,如果每写一个接…...

R语言复现:如何利用logistic逐步回归进行影响因素分析?
Logistic回归在医学科研、特别是观察性研究领域,无论是现况调查、病例对照研究、还是队列研究中都是大家经常用到的统计方法,而在影响因素研究筛选自变量时,大家习惯性用的比较多的还是先单后多,P<0.05纳入多因素研究&…...
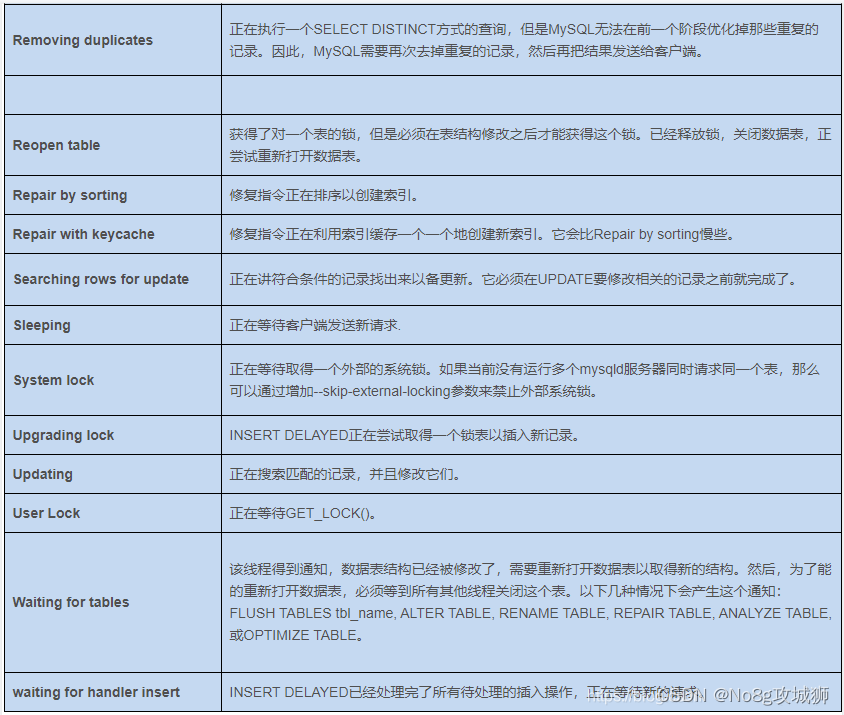
【MySQL使用】show processlist 命令详解
show processlist 命令详解 一、命令含义二、命令返回参数三、Command值解释四、State值解释五、参考资料 一、命令含义 对于一个MySQL连接,或者说一个线程,任何时刻都有一个状态,该状态表示了MySQL当前正在做什么。SHOW PROCESSLIST 命令的…...
分类算法(Classification algorithms)
逻辑回归(logical regression): 逻辑回归这个名字听上去好像应该是回归算法的,但其实这个名字只是在历史上取名有点区别,但实际上它是一个完全属于是分类算法的。 我们为什么要学习它呢?在用我们的线性回归时会遇到一…...

深度学习-Softmax 回归 + 损失函数 + 图片分类数据集
Softmax 回归 损失函数 图片分类数据集 1 softmax2 损失函数1均方L1LossHuber Loss 3 图像分类数据集4 softmax回归的从零开始实现 1 softmax Softmax是一个常用于机器学习和深度学习中的激活函数。它通常用于多分类问题,将一个实数向量转换为概率分布。Softmax函…...
)
分布式锁从0到1落地实现01(mysql/redis/zk)
1 准备数据库表 CREATE TABLE user ( id bigint(20) NOT NULL COMMENT 主键ID, name varchar(30) DEFAULT NULL COMMENT 姓名, age int(11) DEFAULT NULL COMMENT 年龄, email varchar(50) DEFAULT NULL COMMENT 邮箱, PRIMARY KEY (id) ) ENGINEInnoDB DEFAULT CHARSETutf8;I…...

安全运营方案的基本框架和关键要素
一、前言 阐述安全运营方案的目的和重要性。强调安全运营与组织整体战略目标的关联。 二、安全运营原则 确立安全运营的基本原则,如保密性、完整性和可用性。明确安全责任划分,确保各部门和人员履行安全职责。 三、安全风险评估与管理 进行全面的安…...
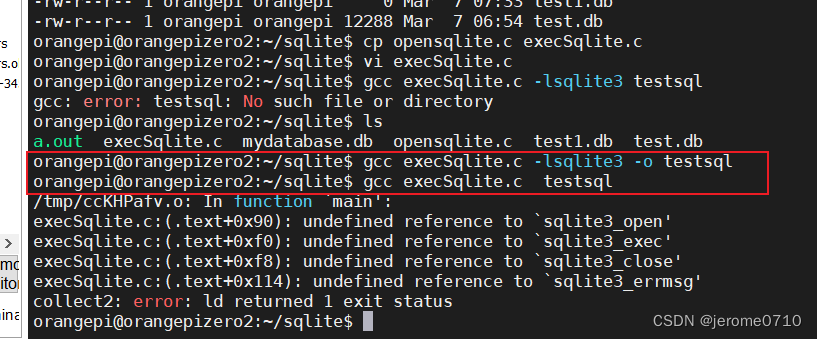
用C语言执行SQLite3的gcc编译细节
错误信息: /tmp/cc3joSwp.o: In function main: execSqlite.c:(.text0x100): undefined reference to sqlite3_open execSqlite.c:(.text0x16c): undefined reference to sqlite3_exec execSqlite.c:(.text0x174): undefined reference to sqlite3_close execSqlit…...
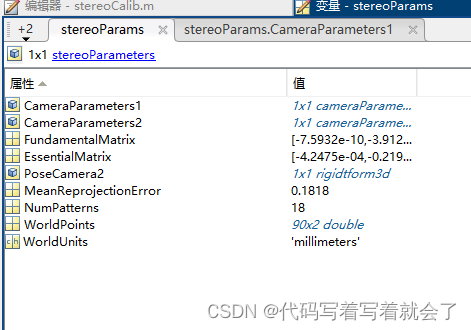
matlab双目相机标定-需要什么参数、怎么获得
相机标定目的:获得相机内参、外参、畸变系数,摄像头的内参(f,1/dx,1/dy,cx,cy)、畸变参数(k1,k2,k3,p1,p1)和外参(R,t),用于接下来的双目校正和深度图生成从而实现二维到三维的转换。 相机标定方法:opencv 双目相机标定以及立体…...
)
大型语言模型的智能助手:检索增强生成(RAG)
背景 在人工智能的浪潮中,大型语言模型(LLMs)如GPT系列和LLama系列在自然语言处理(NLP)领域取得了显著成就。它们能够完成复杂的语言任务,如文本摘要、机器翻译、甚至创作诗歌。然而,这些模型在…...
Ubuntu 安装谷歌拼音输入法
一、Fcitx 安装 在Ubuntu 下,谷歌拼音输入法是基于Fcitx输入法的。所以,首先需要安装Fcitx。一般来说,Ubuntu最新版中都默认安装了Fcitx,但是为了确保一下,我们可以在系统终端中运行如下命令: sudo apt ins…...
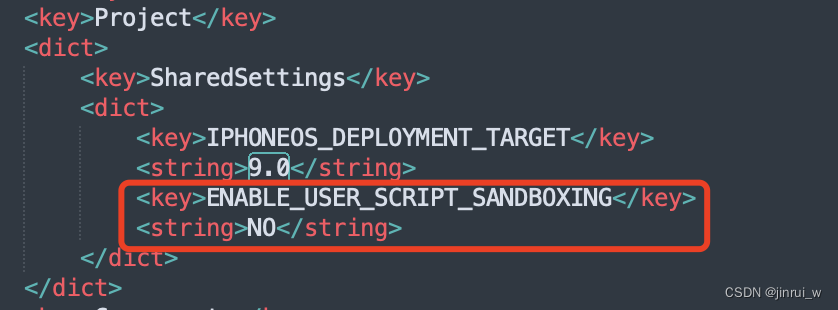
修改MonkeyDev默认配置适配Xcode15
上一篇文章介绍了升级Xcode15后,适配MonkeyDev的一些操作,具体操作可以查看:Xcode 15 适配 MonkeyDev。 但是每次新建项目都要去修改那些配置,浪费时间和精力,这篇文章主要介绍如何修改MonkeyDev的默认配置࿰…...

Wan2.2-I2V-A14B参数详解:duration/resolution/prompt长度对显存影响分析
Wan2.2-I2V-A14B参数详解:duration/resolution/prompt长度对显存影响分析 1. 模型与硬件环境概述 Wan2.2-I2V-A14B是一款先进的文生视频模型,能够根据文本描述生成高质量视频内容。本分析基于专为RTX 4090D 24GB显存优化的私有部署镜像环境,…...

低门槛语音AI落地:SenseVoice-Small ONNX非技术人员使用指南
低门槛语音AI落地:SenseVoice-Small ONNX非技术人员使用指南 你是不是也觉得语音转文字很麻烦?要么得联网上传录音,担心隐私泄露;要么本地工具配置复杂,一堆命令行看得人头疼;要么识别出来的文字没有标点&…...

【Bootloader实战解析】基于UDS与CAN实现单片机固件无感升级
1. 为什么需要无感固件升级? 想象一下你的手机系统更新:点击"立即安装"后,系统自动下载更新包,重启时完成安装,整个过程无需连接电脑或使用特殊工具。这种"无感升级"体验在汽车电子和工业控制领域…...
)
从零到自动化:用FastAPI+Requests打造你的第一个接口测试平台(告别Postman手动点点点)
从零构建企业级接口自动化测试平台:FastAPIRequests实战指南 在当今快速迭代的软件开发周期中,接口测试已成为保障产品质量的关键环节。传统手工测试工具如Postman虽然直观易用,但面对频繁变更的接口和大量回归测试场景时,往往显得…...

从零部署Orbbec Gemini2:ROS2 Humble环境下的驱动配置与多话题数据解析
1. 环境准备与驱动安装 最近在做一个机器人项目,需要用到Orbbec Gemini2(原DaBai DCL)深度相机。折腾了两天才把ROS2驱动搞定,这里把完整过程记录下来,希望能帮到同样在配置这款相机的朋友。 1.1 系统要求检查 首先确认…...

Windows 下部署与配置 Hermes Agent 完全指南:AI 智能体、OpenRouter、LLM、本地大模型、WSL2、自动化、自进化 AI、Ollama、Claude 3.5、GPT-4
本文内容深度融合相关以下技术相关词的汇,放在文章开头以便于您快速阅读以及学习: 平台:Windows、WSL2核心项目:Hermes AgentAI 能力:AI 智能体(AI Agent)、自进化 AI、自动化任务、代码解释器、…...

如何快速为旧iPhone降级:Legacy-iOS-Kit完整使用指南
如何快速为旧iPhone降级:Legacy-iOS-Kit完整使用指南 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit 你…...

含分布式电源的IEEE33节点配电网潮流计算程序功能说明
含分布式电源的IEEE33节点配电网的潮流计算程序,程序考虑了风光接入下的潮流计算问题将风光等效为PQV PI等节点处理,采用牛拉法开展潮流计算,而且程序都有注释 –以下内容属于A解读,有可能是一本正经的胡说八道,仅供参…...

ZephyrOS实战:从心率计示例剖析Bluetooth LE服务构建
1. 从零认识ZephyrOS与BLE心率计开发 第一次接触ZephyrOS的蓝牙开发时,我对着官方文档和示例代码发了半天呆——这个实时操作系统对蓝牙协议栈的封装方式确实和传统嵌入式开发不太一样。就拿最经典的心率计示例(peripheral_hr)来说࿰…...

驾校 AI 招生谁靠谱?懂驾培又懂 AI 才是关键
驾校 AI 招生谁靠谱?懂驾培又懂 AI 才是关键作者:安道利当下驾培行业,传统地推、硬广、老带新的招生效率持续下滑,获客成本飙升、线索转化率低迷,AI 招生已成为驾校破局的必选项。但市场上 AI 招生服务商鱼龙混杂&…...