mybatis-plus整合spring boot极速入门
使用mybatis-plus整合spring boot,接下来我来操作一番。
一,创建spring boot工程
勾选下面的选项
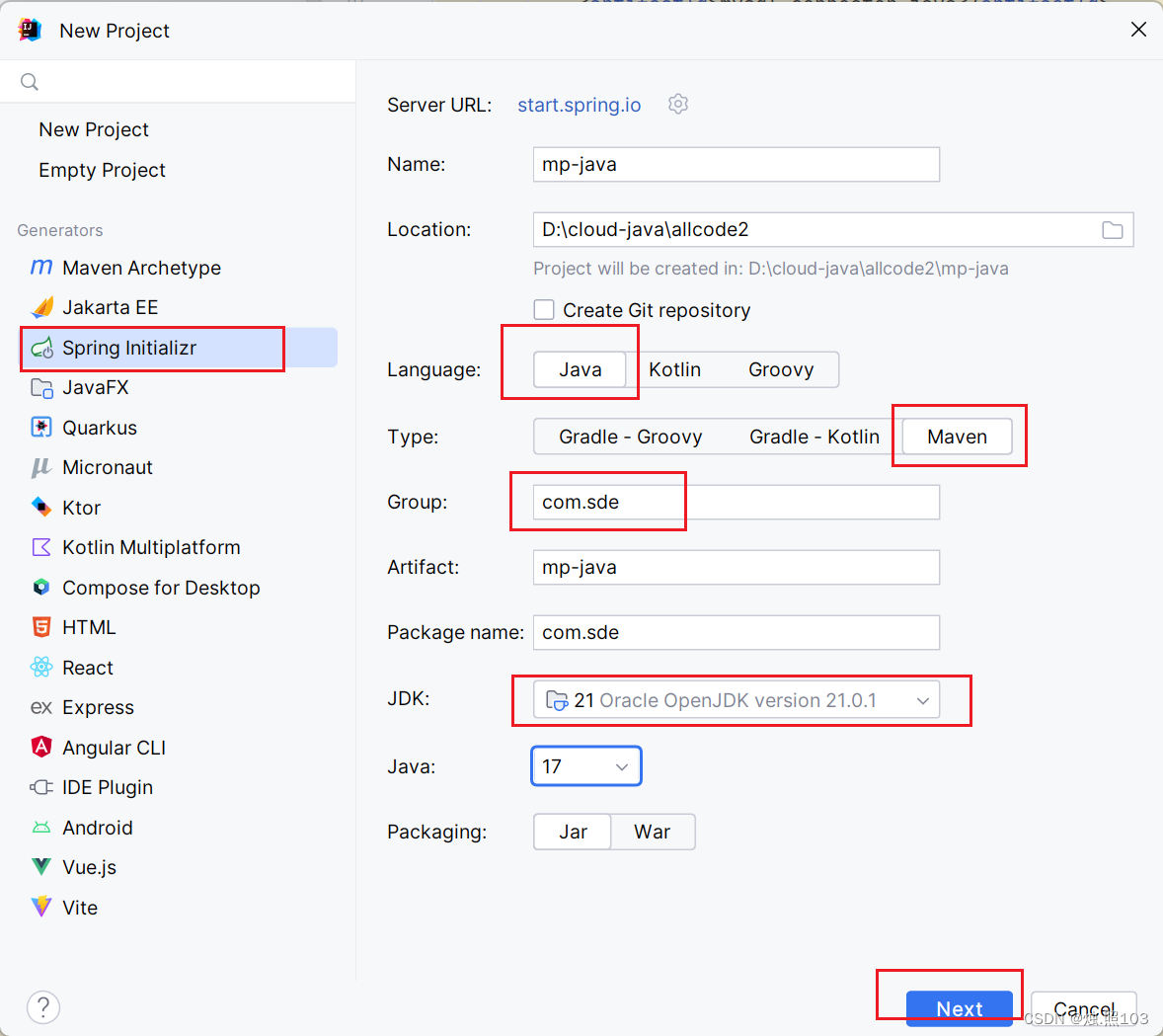
紧接着,还有springboot和依赖我们需要选。
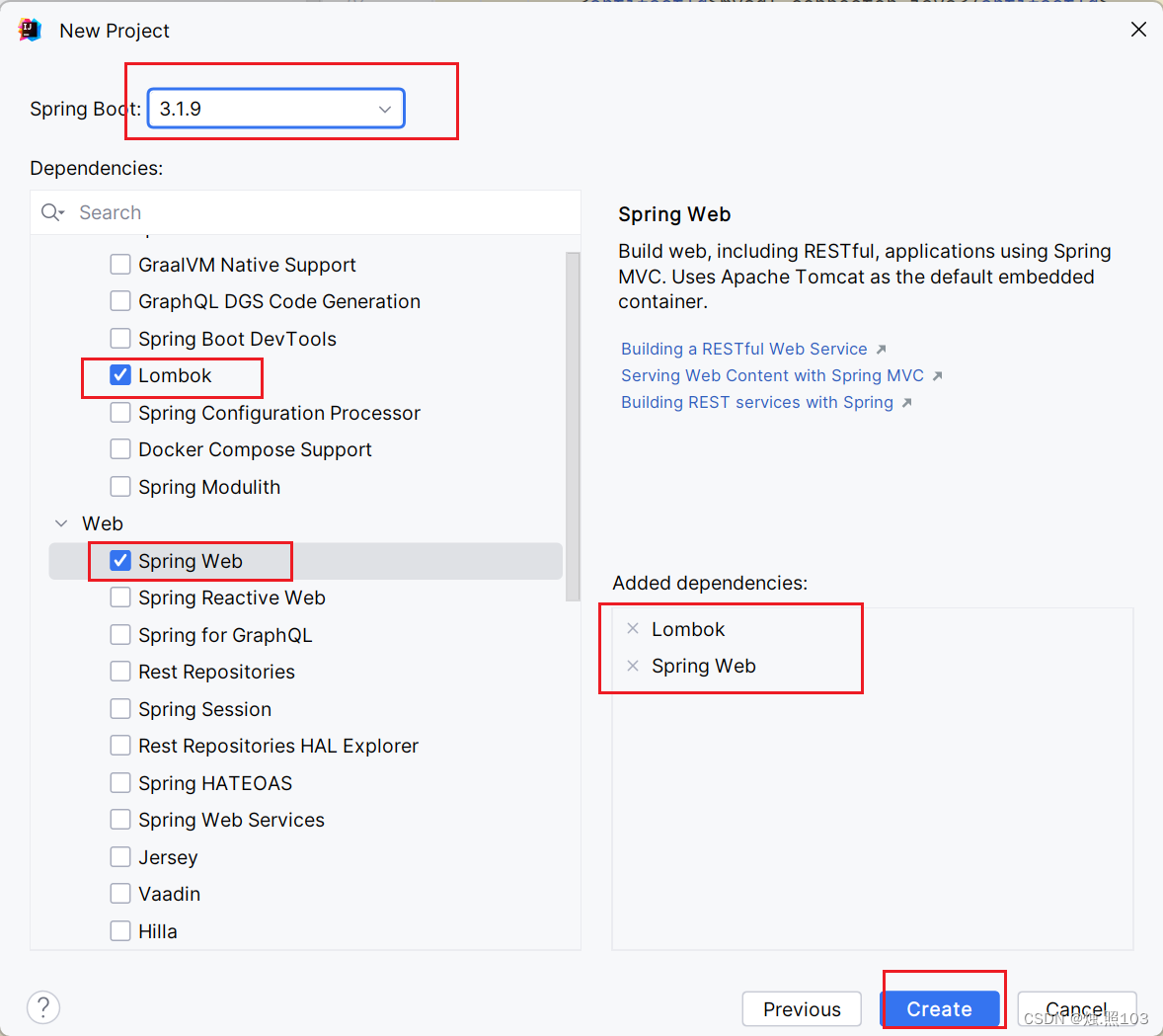
这样我们就创建好了我们的spring boot,项目。
简化目录结构:
我们发现,这些零碎文件很多,占时用不到的,就先删除。
看看简化后的,项目目录结构。
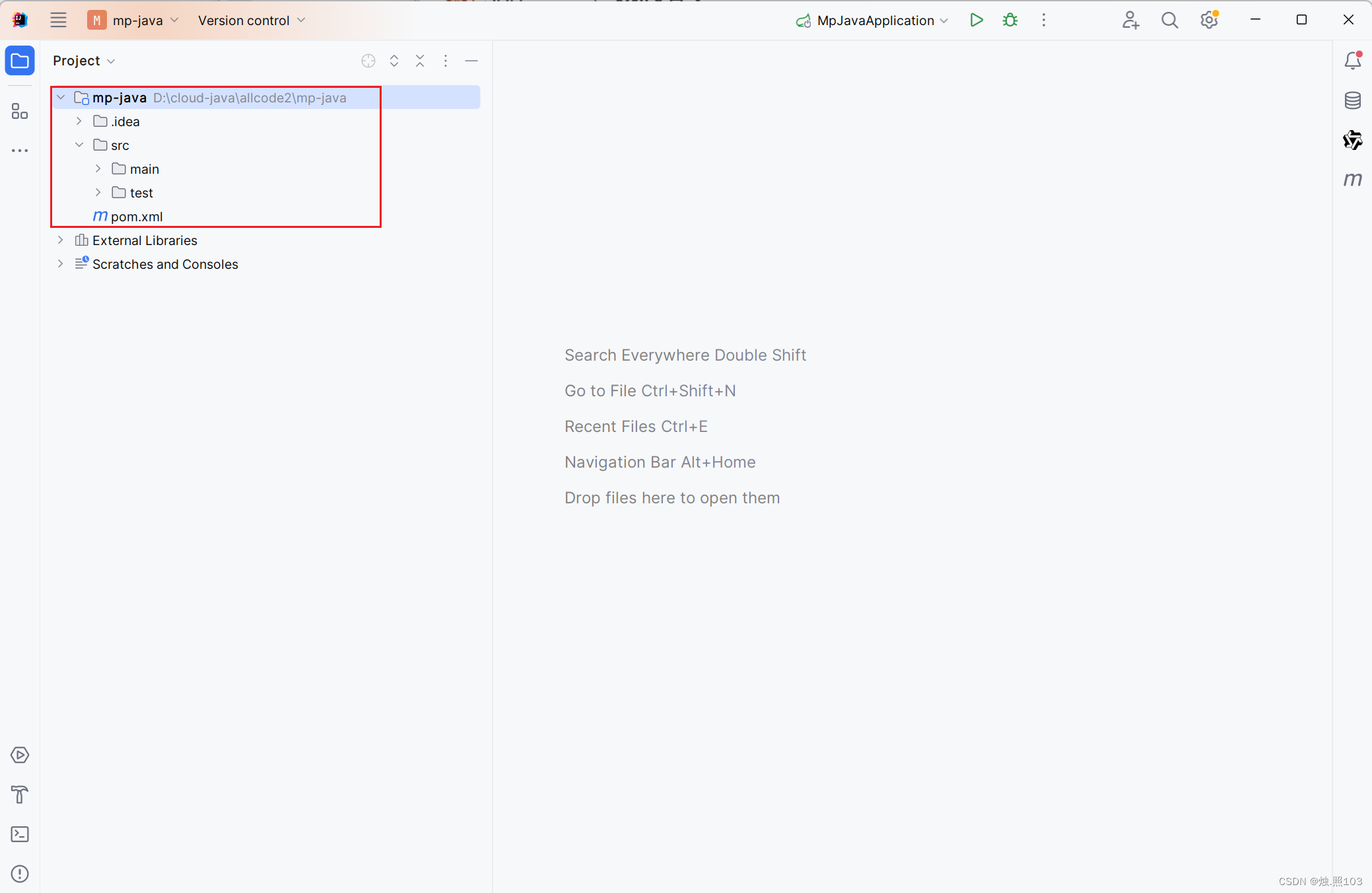
修改boot项目版本:
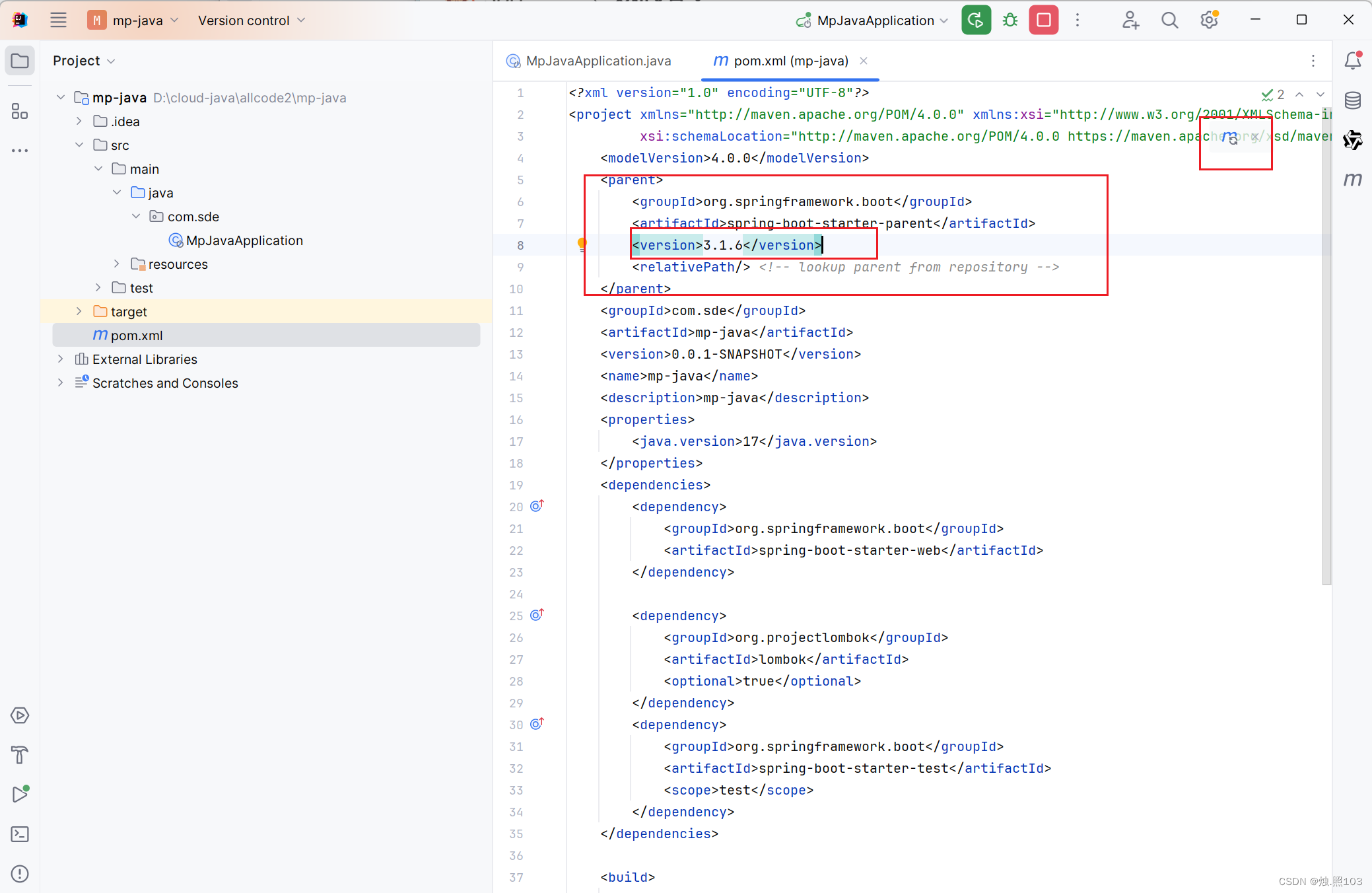
启动项目:
找到启动来,把我们的项目跑起来。

可以看到项目是正常启动的
二,添加依赖
添加mybatis-plus依赖:

<!--mybatis-plus依赖--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.5</version></dependency>添加mysql依赖:
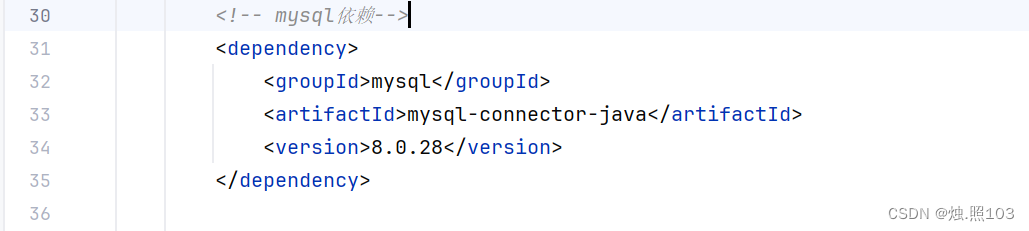
<!-- mysql依赖--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.28</version></dependency>yml文件的配置:
把一properties结尾的文件,改成yml结尾的格式
 改后的效果:
改后的效果:
我添加了下面的配置:
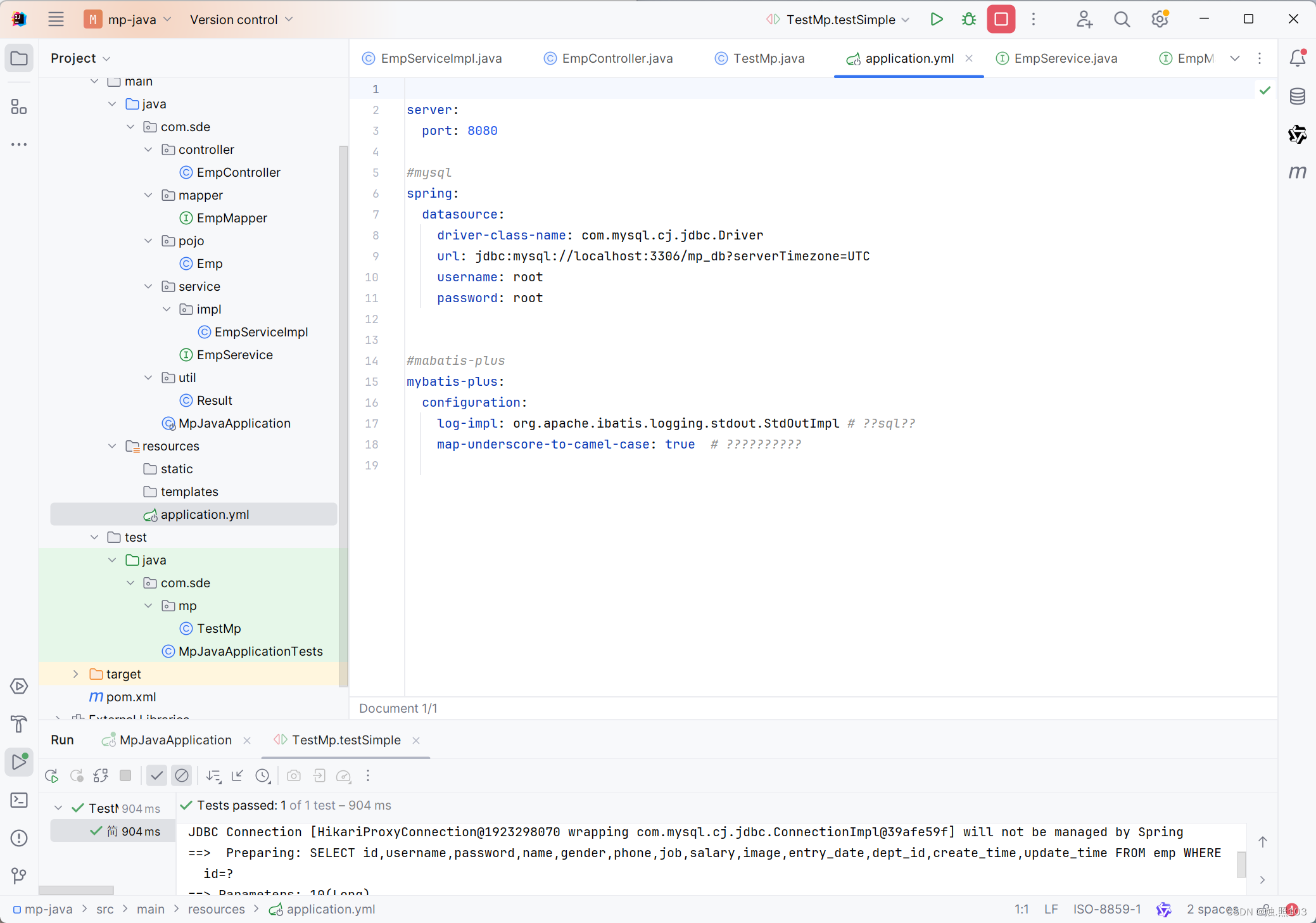
#项目的端口
server:port: 8080#mysql配置
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/mp_db?serverTimezone=UTCusername: rootpassword: root#mabatis-plus的配置
mybatis-plus:configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 打印sql日志map-underscore-to-camel-case: true # 是否开启驼峰命名转换运行项目:
项目还是正常启动的
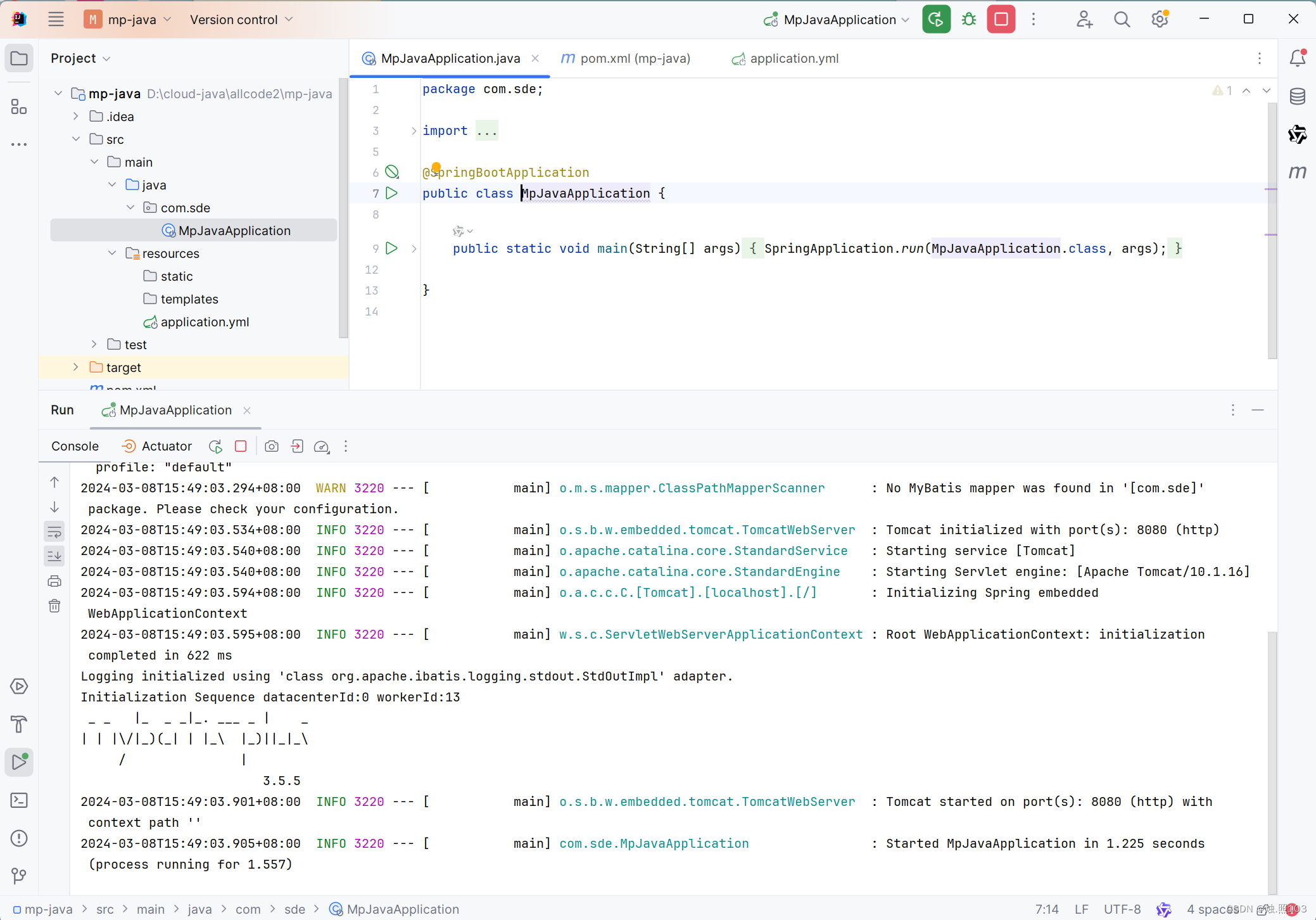
三,创建各种业务层
我们把mapper,service,controller,utils都创建好,看看目录结构。
Emp实体类
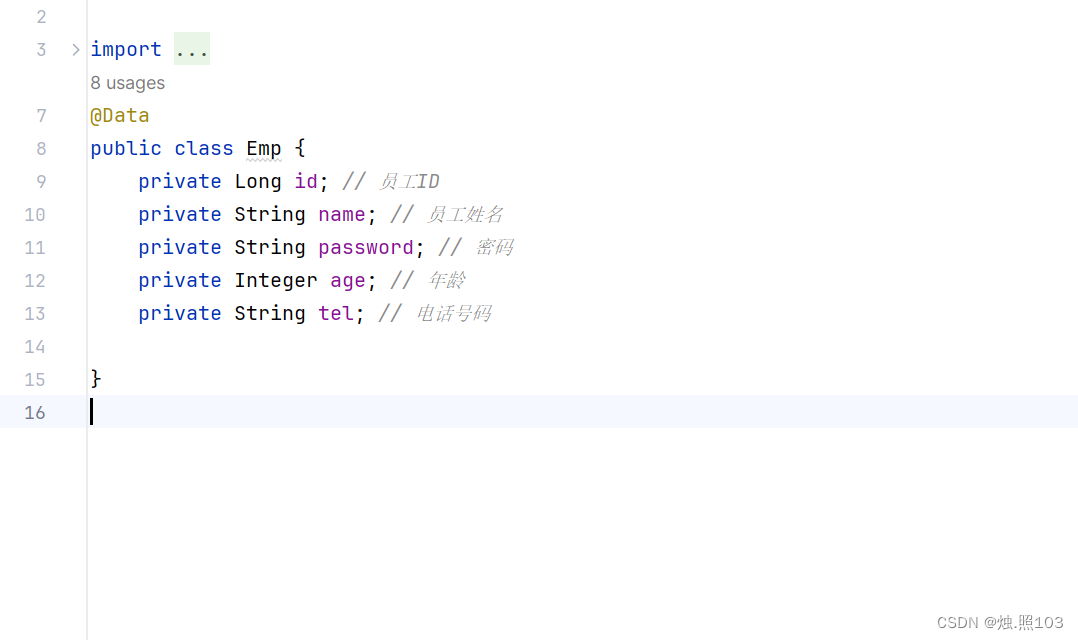
代码:
@Data
public class Emp {private Long id; // 员工IDprivate String name; // 员工姓名private String password; // 密码private Integer age; // 年龄private String tel; // 电话号码}mapper接口:
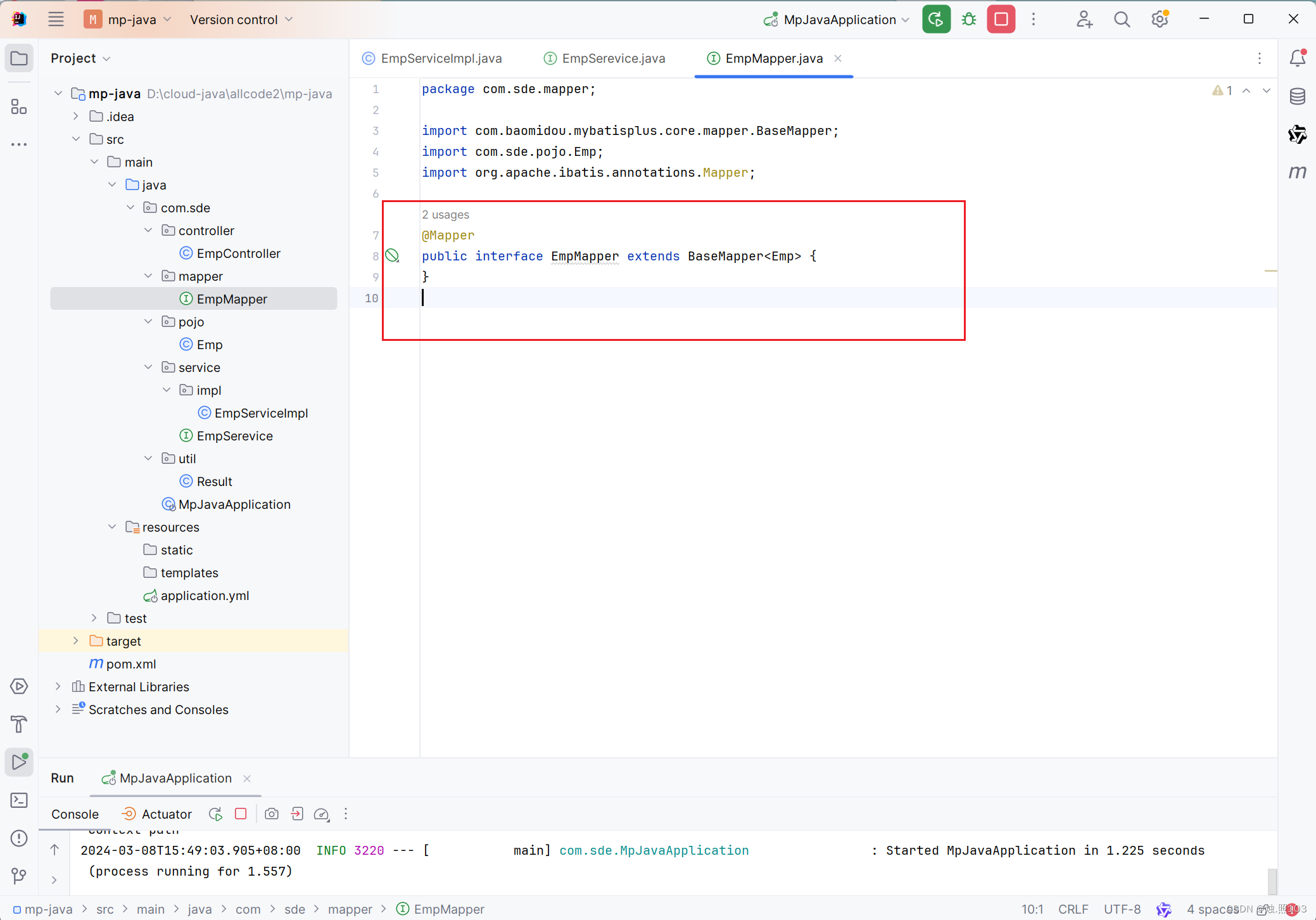
代码:
@Mapper
public interface EmpMapper extends BaseMapper<Emp> {
}EmpService接口:

代码:
public interface EmpSerevice extends IService<Emp> {
}EmpServiceImpl:实现类
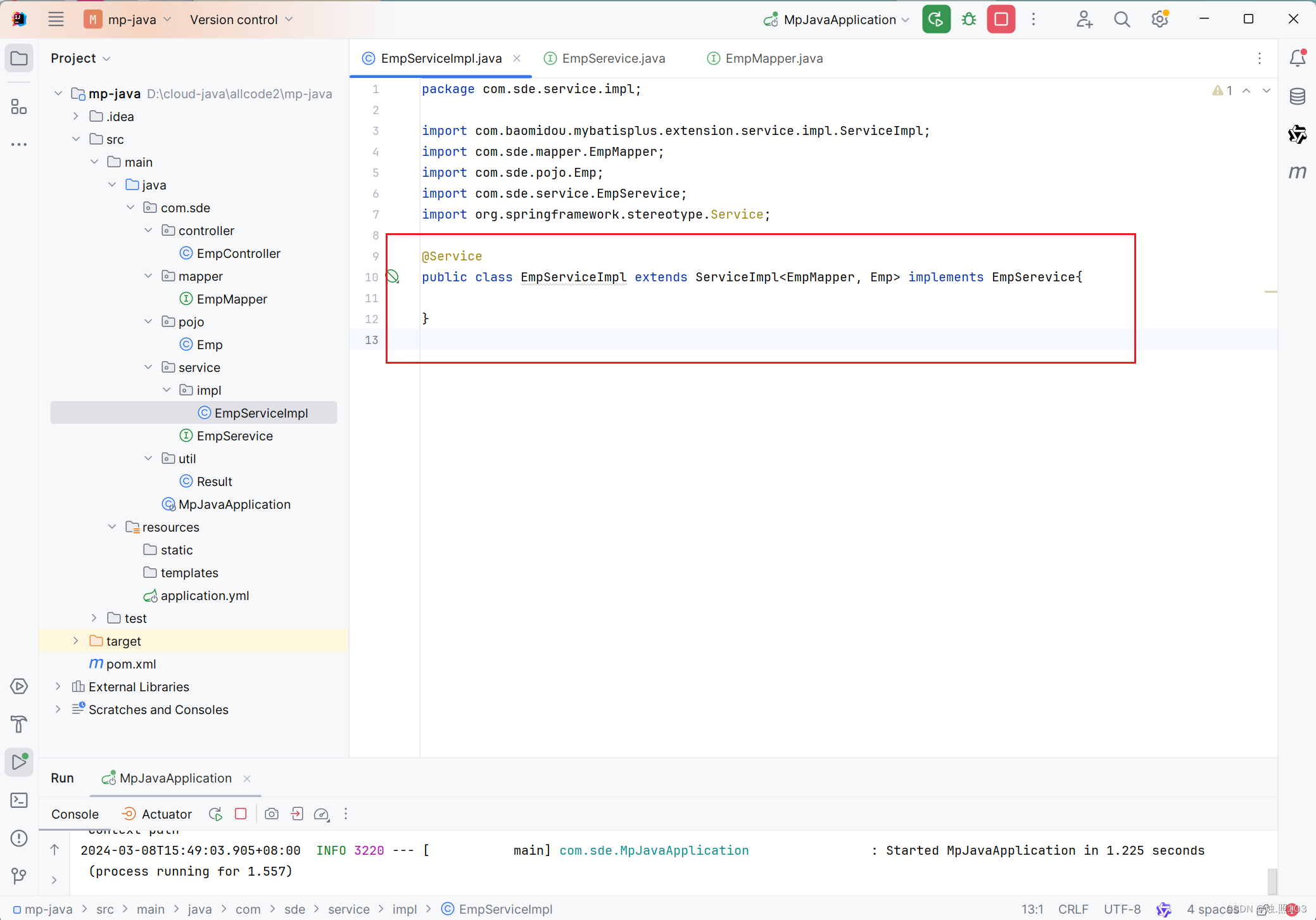
代码:
@Service
public class EmpServiceImpl extends ServiceImpl<EmpMapper, Emp> implements EmpSerevice{}EmpController类:
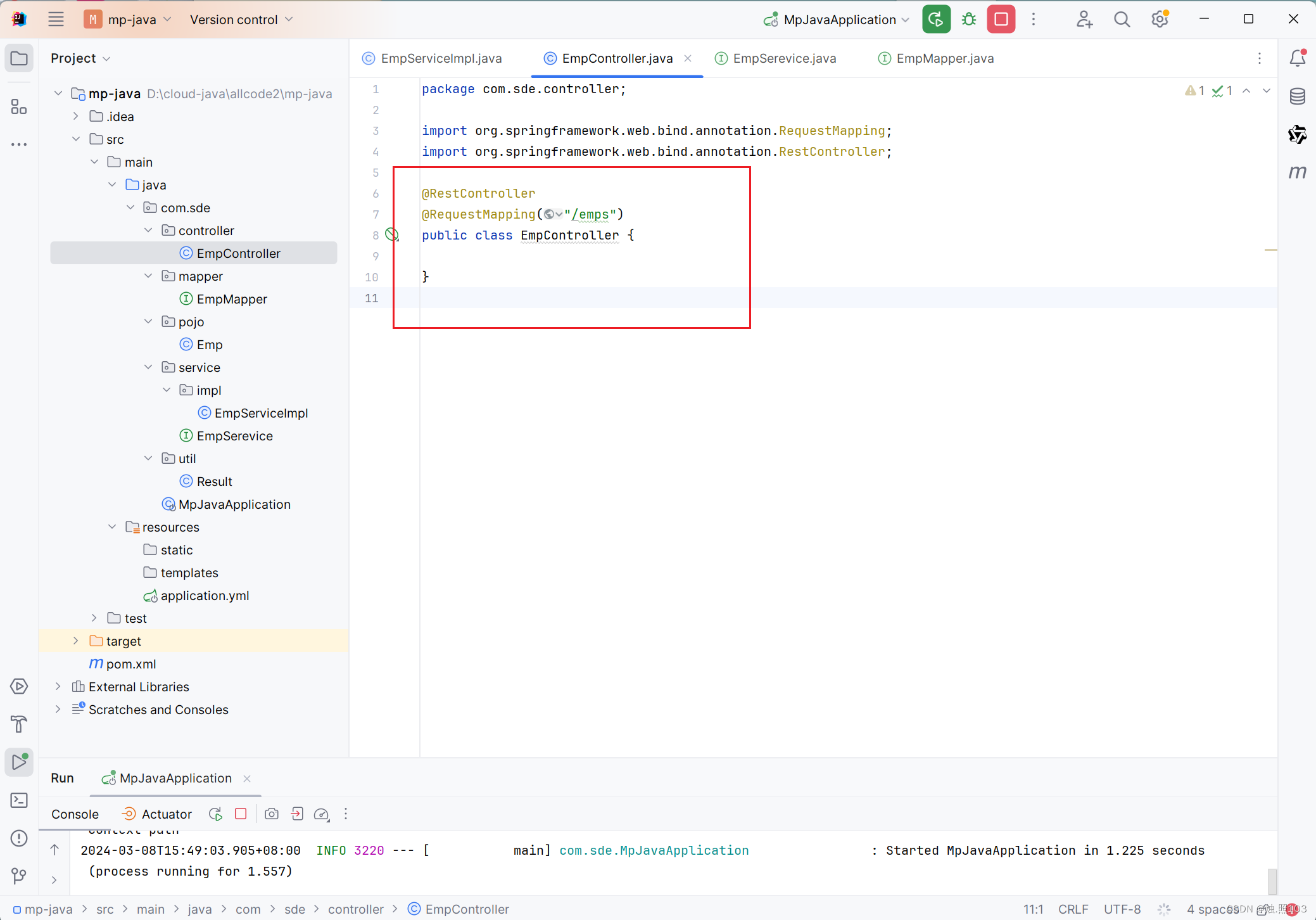
代码:
@RestController
@RequestMapping("/emps")
public class EmpController {}新建一个测试类:
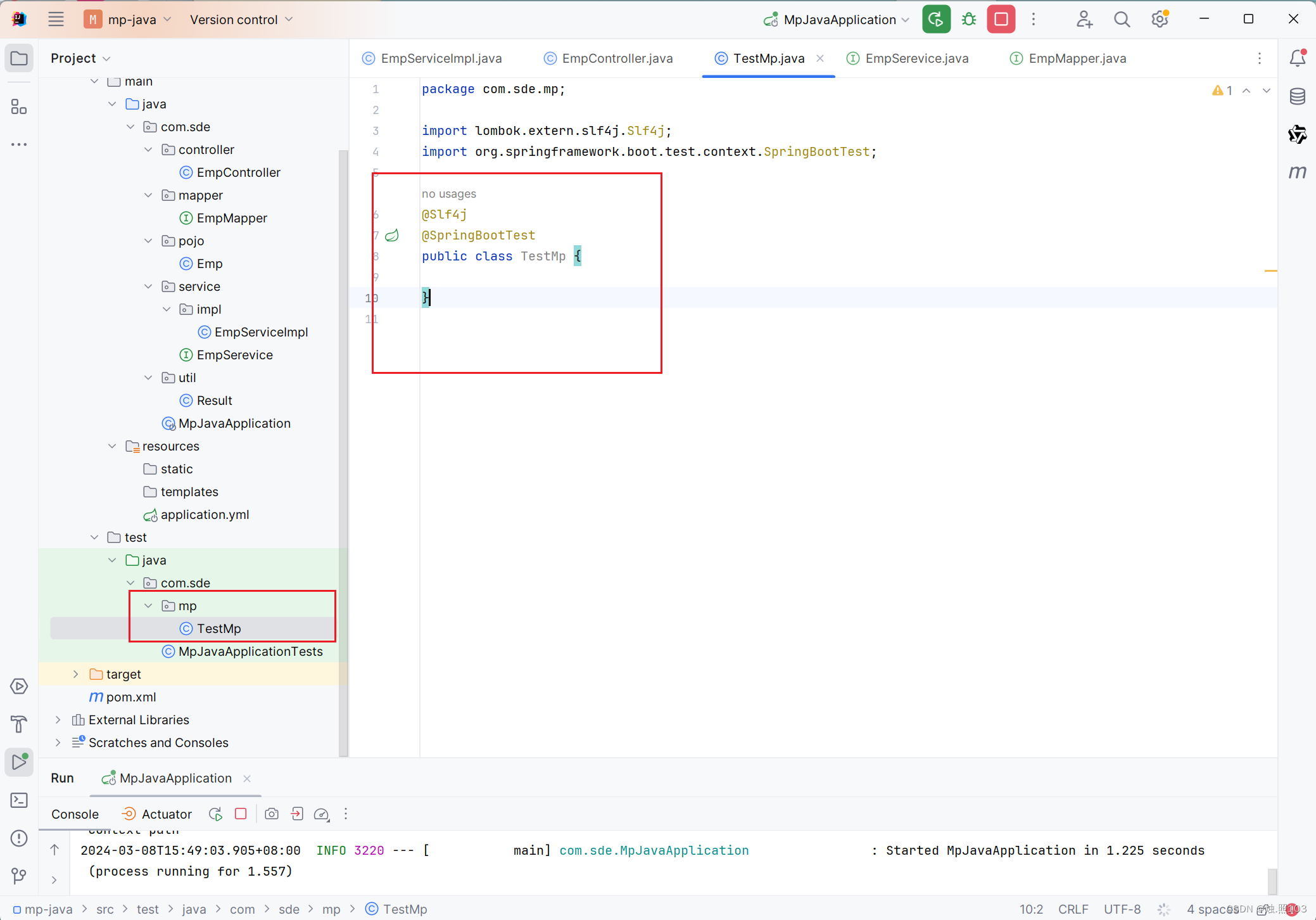
代码:
@Slf4j
@SpringBootTest
public class TestMp {}四,测试mybatis-plus的service层接口:
测试查询:
mp的service提供的查询方法:
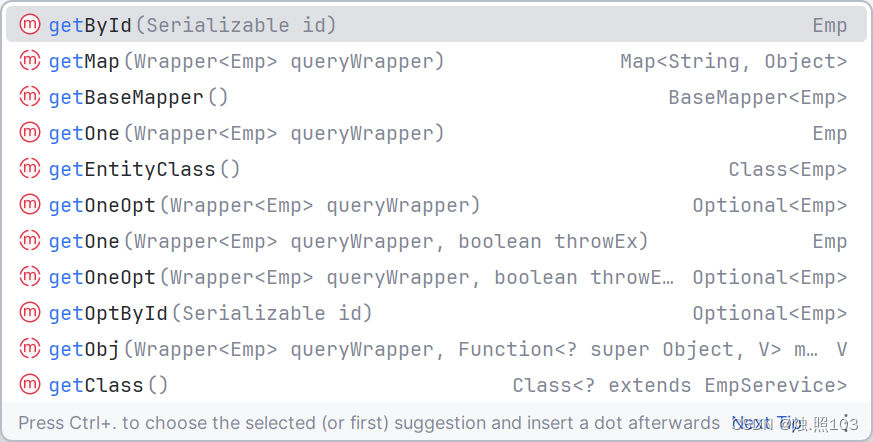
getById 通常用于表示根据ID获取数据的方法 。
getOne 通常用于查询符合条件的单条记录。
getMap 根据wrapper条件,可以查询多条数据。
查询常用的拼接关系条件:
通常是写 wrapper里面的:
就比如 >, >=, < ,<= ,=
- gt:大于
- ge:大于等于
- lt:小于
- le:小于等于
- eq:等于

还有一些模糊查询用到的:

like 模糊查询类似于 like '%XXX%'
likeLeft 左边模糊查询 like '%XXX'
likeRight 右边模糊查询 类似于 like 'XXX%'
notLike 返回的模糊查询条件中,都不包含某条件。 no like '%XXX%'
notLikeLeft 返回的模糊查询条件中,左边不包含某条件。not like '%XXX'
notLikeRight 返回的模糊查询条件中,右边不包含某条件。not like 'XXX%'
查询条件的排序:
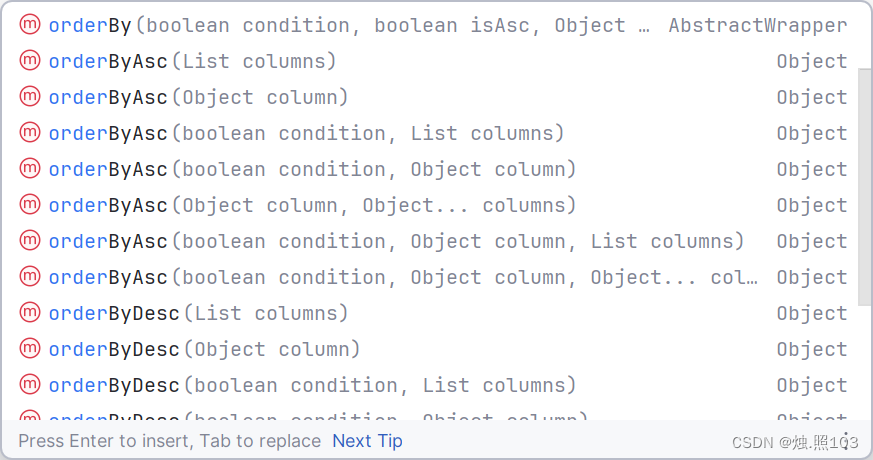
orderBy 根据什么字段排序,自己决定升序还是降序
orderByAsc 根据条件成立的字段,升序
orderByDesc 根据条件成立的字段,降序
单个无条件查询:

代码:
@Test@DisplayName("简单的测试")void testSimple() {//调用empservice的根据id查询的方法Emp emp = empSerevice.getById(1);//输出结果System.out.println(emp);}查看结果:

单个拼接条件查询:

代码:
@Test@DisplayName("单个测试")void testGetOne(){//1,构造查询条件QueryWrapper wrapper = new QueryWrapper();wrapper.eq("id",1);//2,调用接口查询Emp emp = empSerevice.getOne(wrapper);//打印数据System.out.println(emp);}查看结果:

多条件拼接查询:

代码:
@Test@DisplayName("多条件拼接查询")void testMoreQuery(){//1,创建查询条件QueryWrapper wrapper = new QueryWrapper();wrapper.ge("age",8);wrapper.like("name","张");//2,调用方法查询Map map = empSerevice.getMap(wrapper);//3,打印结果System.out.println(map);}查询不包含某个条件返回多条数据:

代码:
@Test@DisplayName("测试不包含条件的模糊查询")void testWrapper(){//1,创建查询条件QueryWrapper wrapper = new QueryWrapper();wrapper.notLike("name","张"); //结果中不能包含 张//2,调用service接口Map map = empSerevice.getMap(wrapper);//3,打印结果System.out.println(map);}结果:
 测试in包含的条件:
测试in包含的条件:

代码:
@Test@DisplayName("测试in包含带的条件")void testExiste(){//1,创建查询条件QueryWrapper wrapper = new QueryWrapper();wrapper.in("id",1,2,3);//2,调用接口查询Map map = empSerevice.getMap(wrapper);//3,打印结果System.out.println(map);}结果:

排序查询:
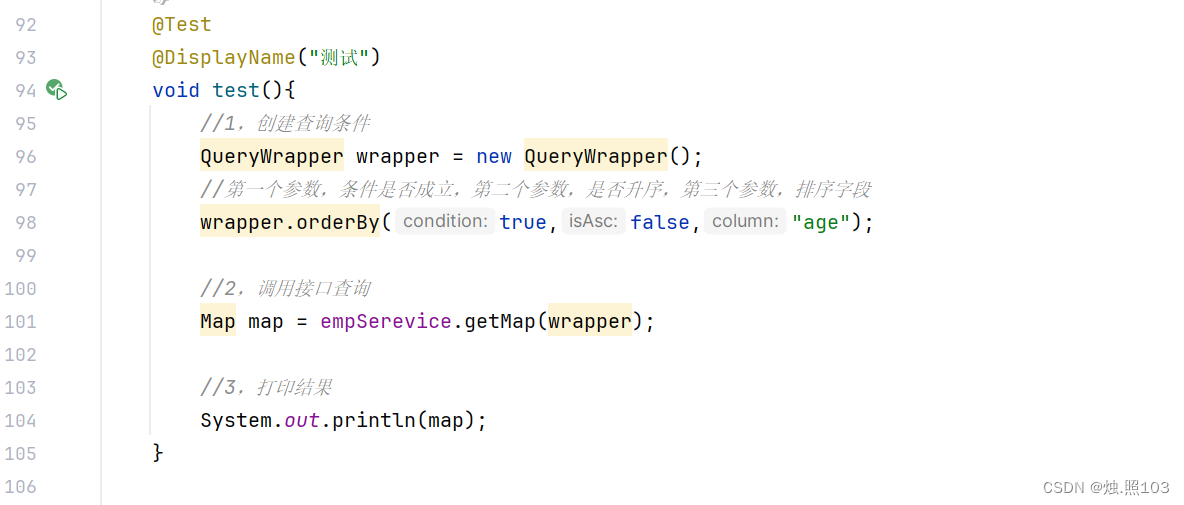
代码:
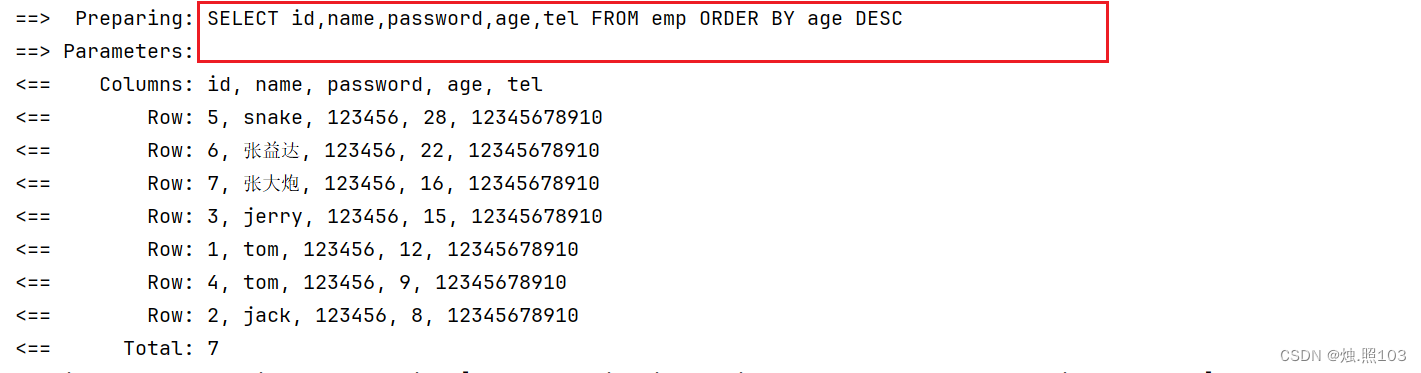
@Test@DisplayName("测试")void test(){//1,创建查询条件QueryWrapper wrapper = new QueryWrapper();//第一个参数,条件是否成立,第二个参数,是否升序,第三个参数,排序字段wrapper.orderBy(true,false,"age");//2,调用接口查询Map map = empSerevice.getMap(wrapper);//3,打印结果System.out.println(map);}结果:
测试lamdba方式的查询:
为什么要使用lamdba的这中方式呢,因为这样就可以避免我们写死,要插叙条件的字段了。要是后面修改,实体类的属性,就能避免很多麻烦。
单个查询:

代码:
@Test@DisplayName("单个查询")void getById(){//1,调用接口查询Emp emp = empSerevice.getById(3L);//2,打印结果System.out.println(emp);}结果:

简单条件查询:

代码:
@Test@DisplayName("lamdba的简单查询")void testLamdba(){//1,创建查询条件LambdaQueryWrapper<Emp> lambdaQuery = new LambdaQueryWrapper<>();lambdaQuery.eq(Emp::getId,1);//2,调用接口Emp emp = empSerevice.getOne(lambdaQuery);//3,打印结果System.out.println(emp);}结果:

复杂条件查询(一):

代码:
@Test@DisplayName("复杂条件查询")void testMoreQuery(){//1,创建查询条件LambdaQueryWrapper<Emp> lambdaQuery = new LambdaQueryWrapper<>();//查询姓名包含张,年龄大于等于8,小于等于30lambdaQuery.like(Emp::getName,"张");lambdaQuery.ge(Emp::getAge,8);lambdaQuery.le(Emp::getAge,30);//2,调用接口Map<String, Object> map = empSerevice.getMap(lambdaQuery);//3,打印结果System.out.println(map);}结果:

复杂查询(二)

代码:
@Test@DisplayName("复杂条件查询")void testMoreQuery2(){//1,创建查询条件LambdaQueryWrapper<Emp> lambdaQuery = new LambdaQueryWrapper<>();//查询密码包含6并且,名字中包含j,年龄大于8岁,小于20岁lambdaQuery.like(Emp::getPassword,"6");lambdaQuery.like(Emp::getName,"j");lambdaQuery.ge(Emp::getAge,8);lambdaQuery.le(Emp::getAge,20);//2,,调用接口Map<String, Object> map = empSerevice.getMap(lambdaQuery);//3,打印结果System.out.println(map);}结果:

测试删除:
mybatis-plus也给我们提供了很多的,删除的方法。
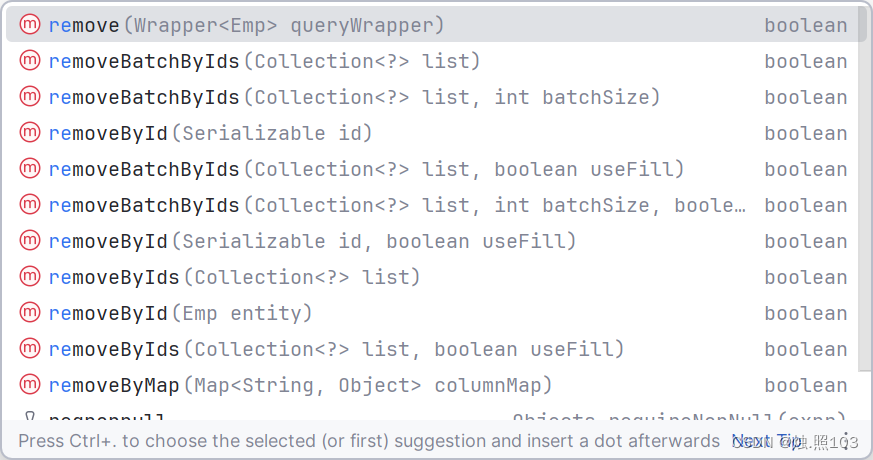
remove 根据条件删除
removeBatchByIds 批量删除
removeById 根据id单个删除
测试单个删除:

代码:
@Test@DisplayName("测试单个删除")void TestById(){//1,调用接口boolean b = empSerevice.removeById(1L);//打印结果if (b){System.out.println("删除成功");}}结果:

根据条件删除:
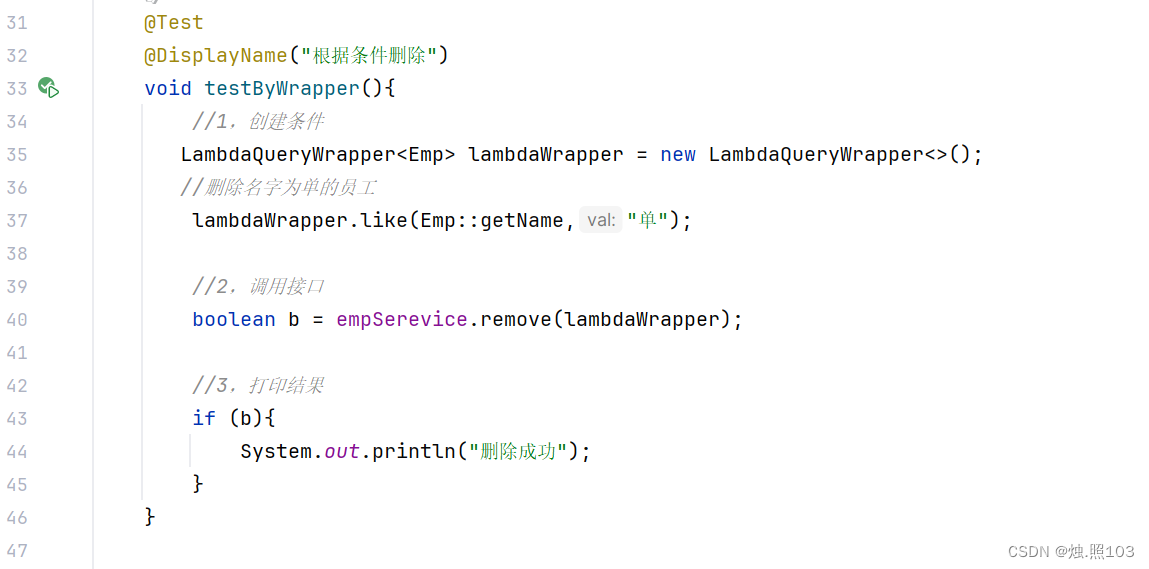
代码:
@Test@DisplayName("根据条件删除")void testByWrapper(){//1,创建条件LambdaQueryWrapper<Emp> lambdaWrapper = new LambdaQueryWrapper<>();//删除名字为单的员工lambdaWrapper.like(Emp::getName,"单");//2,调用接口boolean b = empSerevice.remove(lambdaWrapper);//3,打印结果if (b){System.out.println("删除成功");}}结果:

根据复杂条件批量删除:

代码:
@Test@DisplayName("根据复杂条件批量删除")void TestByWrapperBatch(){//1,创建条件LambdaQueryWrapper<Emp> lambdaWrapper = new LambdaQueryWrapper<>();//删除年龄22岁,密码包含6,且名字中是姓张的lambdaWrapper.eq(Emp::getAge,22).like(Emp::getPassword,"6").like(Emp::getName,"张");//2,调用接口boolean b = empSerevice.remove(lambdaWrapper);//3,打印结果if (b){System.out.println("删除成功");}}结果:

根据ID批量删除:

代码:
@Test@DisplayName("根据id批量删除")void testBatchById(){//1,调用接口boolean b = empSerevice.removeBatchByIds(List.of(2L, 3L, 4L));//打印结果if (b){System.out.println("删除成功");}}结果:

测试新增(添加):
mubatis-plus也为我们提供了很多现成的,新增方法。
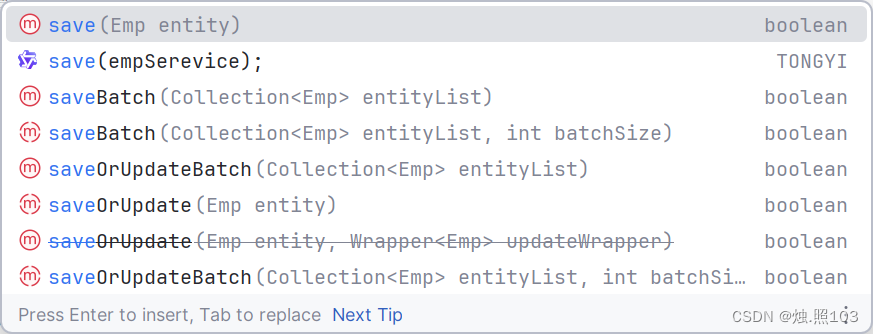
save 就是一个简单的新增方法
saveBatch 批量新增
saveOrUpdate 存在就修改,不存在就新增
简单的新增:
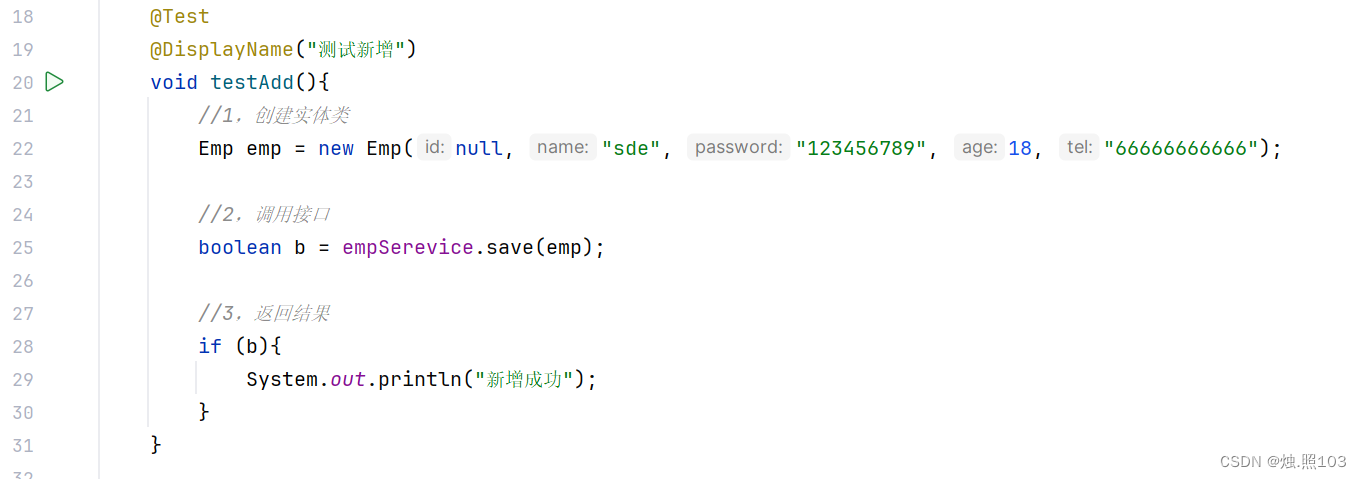
代码:
@Test@DisplayName("测试新增")void testAdd(){//1,创建实体类Emp emp = new Emp(null, "sde", "123456789", 18, "66666666666");//2,调用接口boolean b = empSerevice.save(emp);//3,返回结果if (b){System.out.println("新增成功");}}结果:

批量新增:
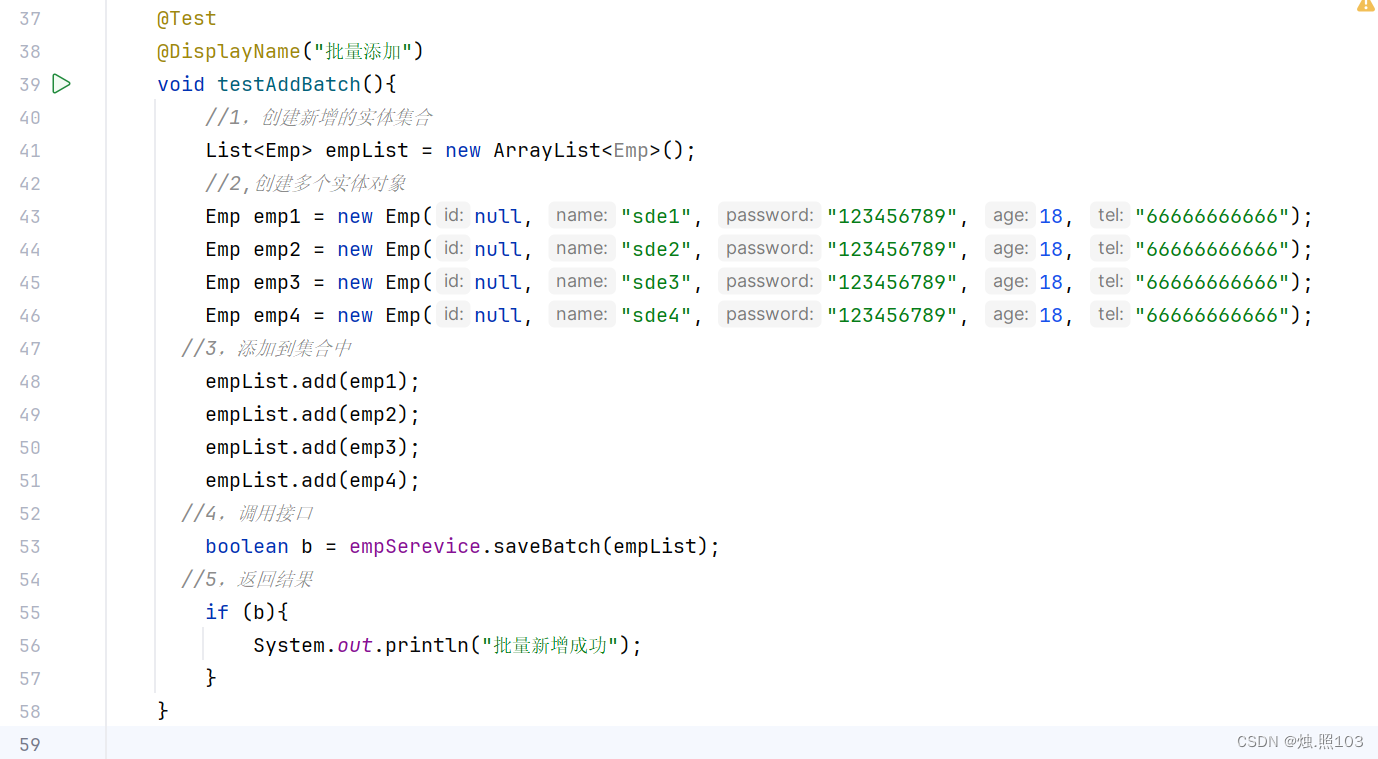
代码:
@Test@DisplayName("批量添加")void testAddBatch(){//1,创建新增的实体集合List<Emp> empList = new ArrayList<Emp>();//2,创建多个实体对象Emp emp1 = new Emp(null, "sde1", "123456789", 18, "66666666666");Emp emp2 = new Emp(null, "sde2", "123456789", 18, "66666666666");Emp emp3 = new Emp(null, "sde3", "123456789", 18, "66666666666");Emp emp4 = new Emp(null, "sde4", "123456789", 18, "66666666666");//3,添加到集合中empList.add(emp1);empList.add(emp2);empList.add(emp3);empList.add(emp4);//4,调用接口boolean b = empSerevice.saveBatch(empList);//5,返回结果if (b){System.out.println("批量新增成功");}}结果:
 新增或者修改:
新增或者修改:
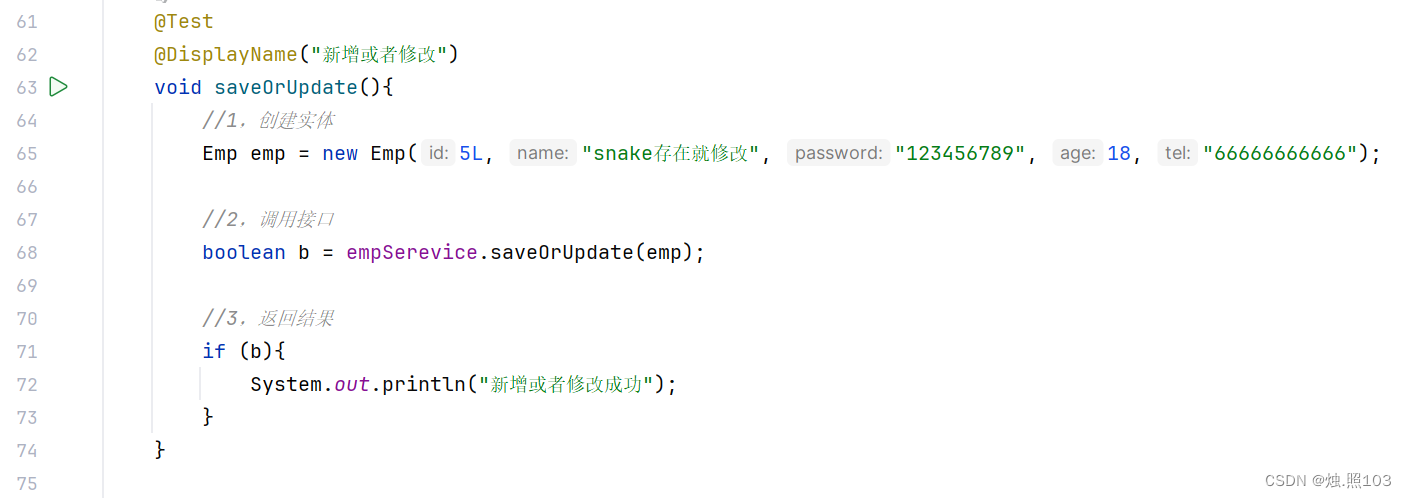
代码:
@Test@DisplayName("新增或者修改")void saveOrUpdate(){//1,创建实体Emp emp = new Emp(5L, "snake存在就修改", "123456789", 18, "66666666666");//2,调用接口boolean b = empSerevice.saveOrUpdate(emp);//3,返回结果if (b){System.out.println("新增或者修改成功");}}结果:

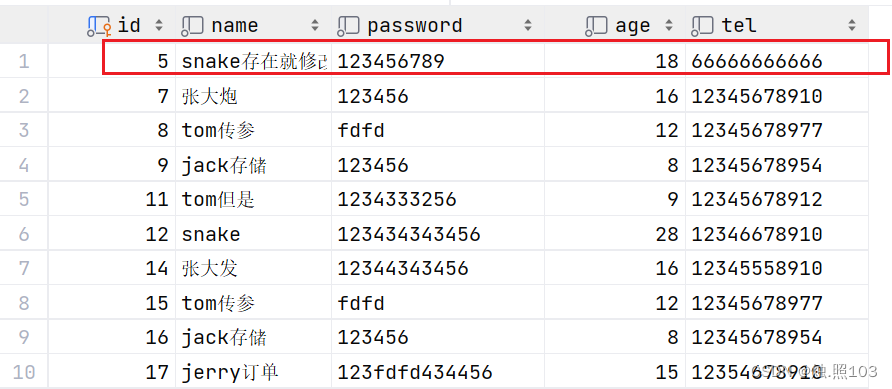
我们看看数据库是修改还是新增了
很明显是新增了
测试修改:
mybatis-plus也给我们提供了很多修改的方法:
updateById 根据id修改
update 根据条件修改,第一个参数是实体类,第二个参数是wrapper
根据ID修改:
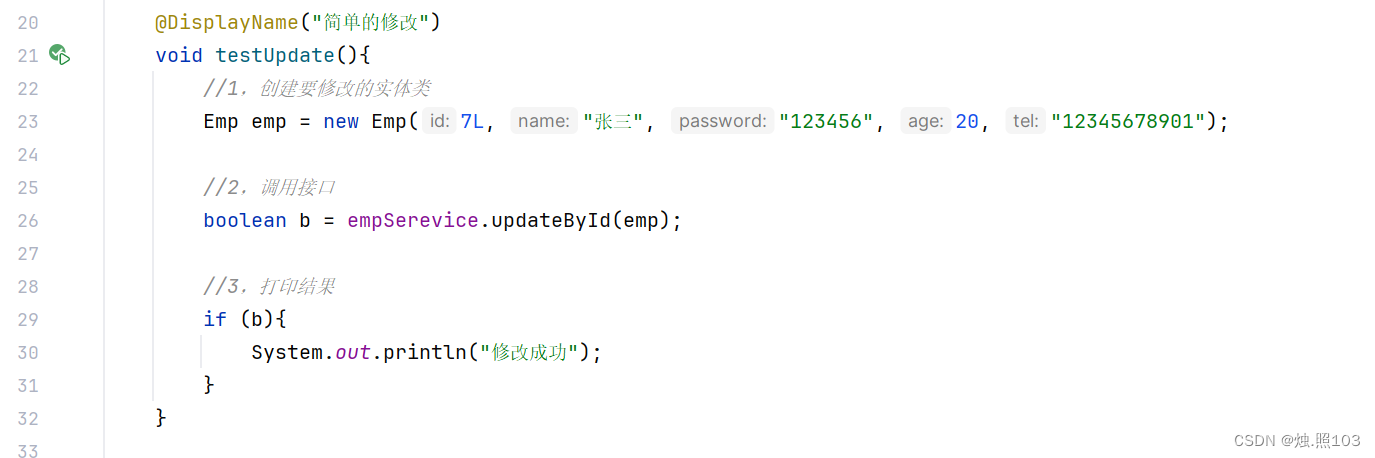
代码:
@Test@DisplayName("简单的修改")void testUpdate(){//1,创建要修改的实体类Emp emp = new Emp(7L, "张三", "123456", 20, "12345678901");//2,调用接口boolean b = empSerevice.updateById(emp);//3,打印结果if (b){System.out.println("修改成功");}}结果:

根据条件修改:
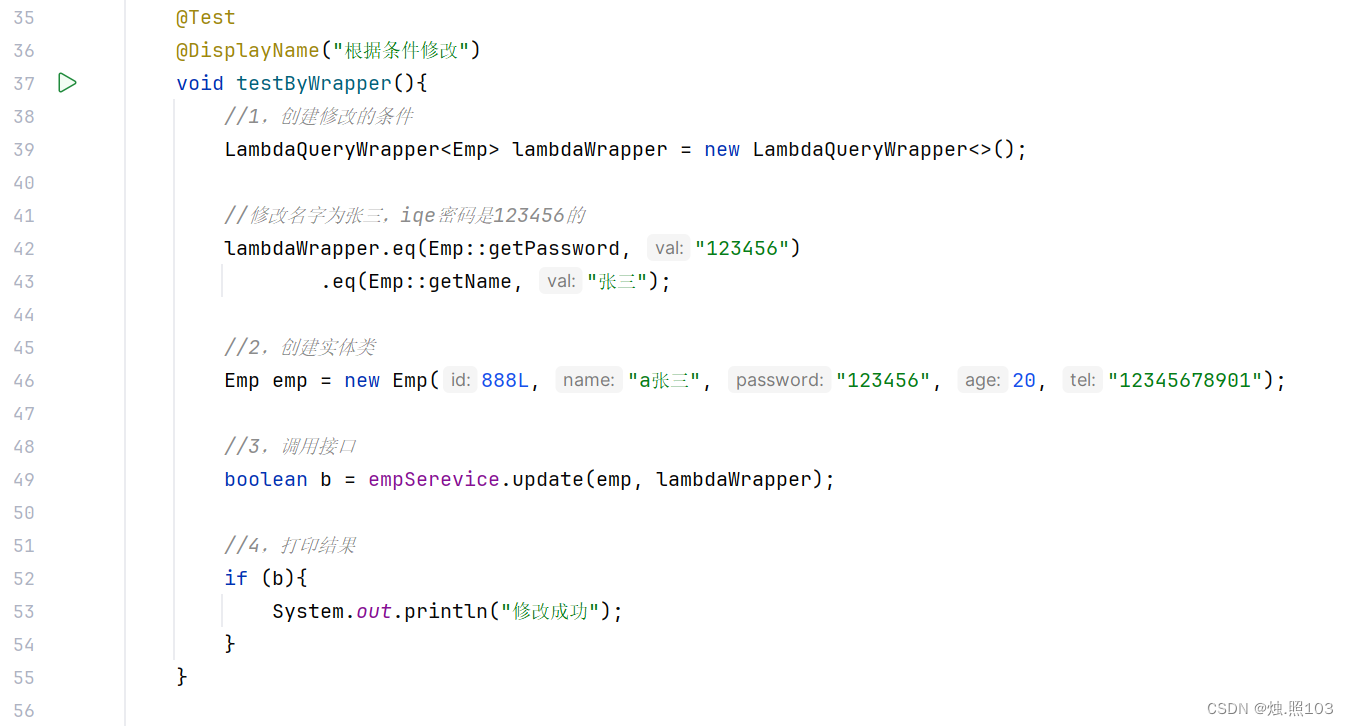
代码:
@Test@DisplayName("根据条件修改")void testByWrapper(){//1,创建修改的条件LambdaQueryWrapper<Emp> lambdaWrapper = new LambdaQueryWrapper<>();//修改名字为张三,iqe密码是123456的lambdaWrapper.eq(Emp::getPassword, "123456").eq(Emp::getName, "张三");//2,创建实体类Emp emp = new Emp(888L, "a张三", "123456", 20, "12345678901");//3,调用接口boolean b = empSerevice.update(emp, lambdaWrapper);//4,打印结果if (b){System.out.println("修改成功");}}结果:
 注意不会修改·id
注意不会修改·id

修改或者新增:
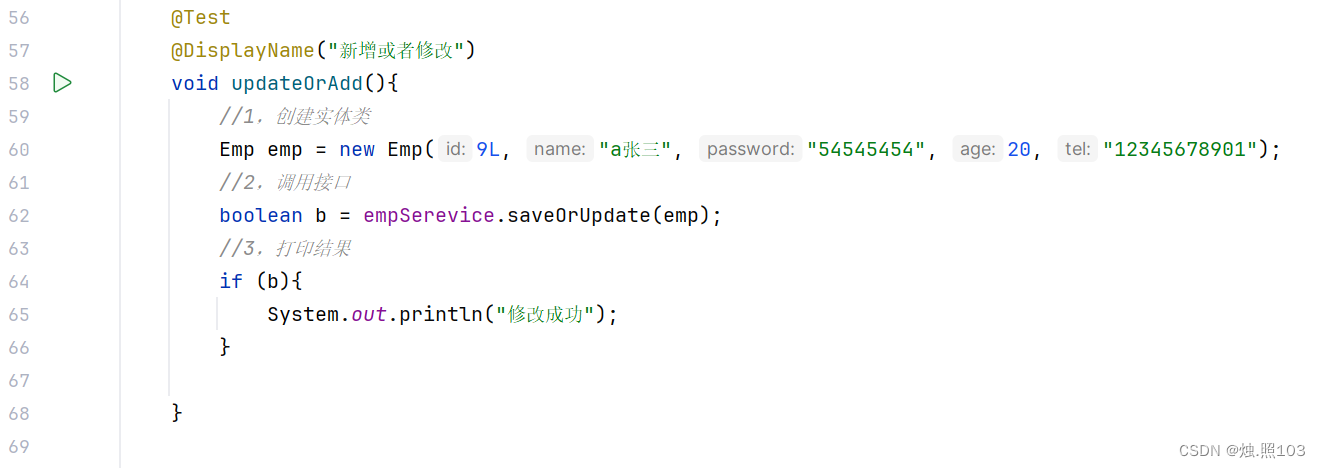
代码:
@Test@DisplayName("新增或者修改")void updateOrAdd(){//1,创建实体类Emp emp = new Emp(9L, "a张三", "54545454", 20, "12345678901");//2,调用接口boolean b = empSerevice.saveOrUpdate(emp);//3,打印结果if (b){System.out.println("修改成功");}}结果:

五,测试mybatis-plus的mapper层接口:
测试查询:
单个查询:

代码:
@Test@DisplayName("单个查询")void testSelect() {//1,创建查询条件LambdaQueryWrapper<Emp> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.eq(Emp::getId, 7);//2,调用接口Emp emp = empMapper.selectOne(queryWrapper);//3,打印结果System.out.println(emp);}结果:

批量查询:

代码:
@Test@DisplayName("批量查询")void testSelectList(){//1,创建查询条件LambdaQueryWrapper<Emp> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.in(Emp::getId, 6,7,8,9);//2,调用接口List<Emp> empList = empMapper.selectList(queryWrapper);//3,打印结果System.out.println(empList);}结果:
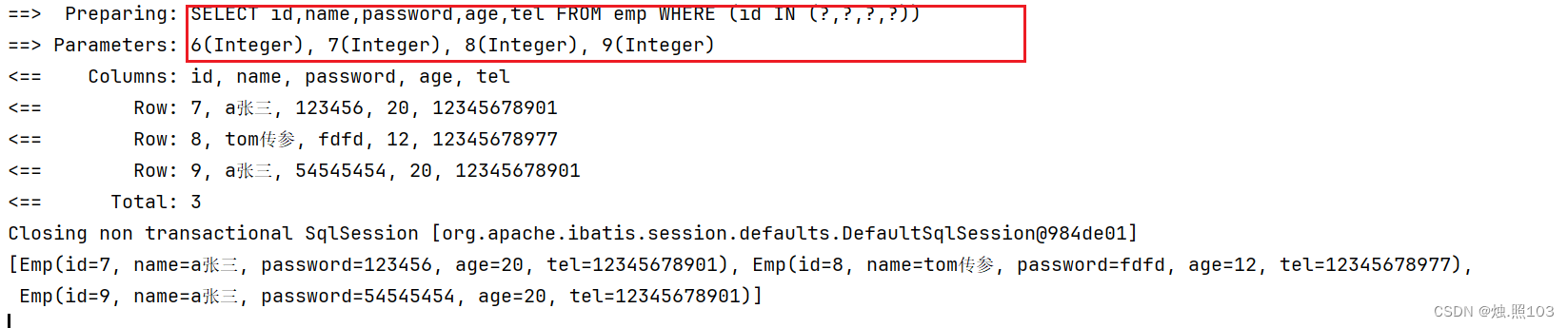
查询数据个数:

@Test@DisplayName("简单查询")void testSimple() {//1,创建查询条件LambdaQueryWrapper<Emp> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.like(Emp::getName, "张");//2,调用接口Long count = empMapper.selectCount(queryWrapper);//3,打印结果System.out.println(count);}结果:

测试删除:
单个删除:

代码:
@Test@DisplayName("单个删除")void testById(){//1,调用接口int count = empMapper.deleteById(7L);//2,打印结果System.out.println(count);}结果:

批量删除:

代码:
@Test@DisplayName("批量删除")void testDelByIds(){//1,创建一个集合List<Integer> ids = List.of(6,7,8,9,10);//2,调用接口int count = empMapper.deleteBatchIds(ids);//3,打印结果System.out.println(count);}结果:

测试新增:
单个添加:
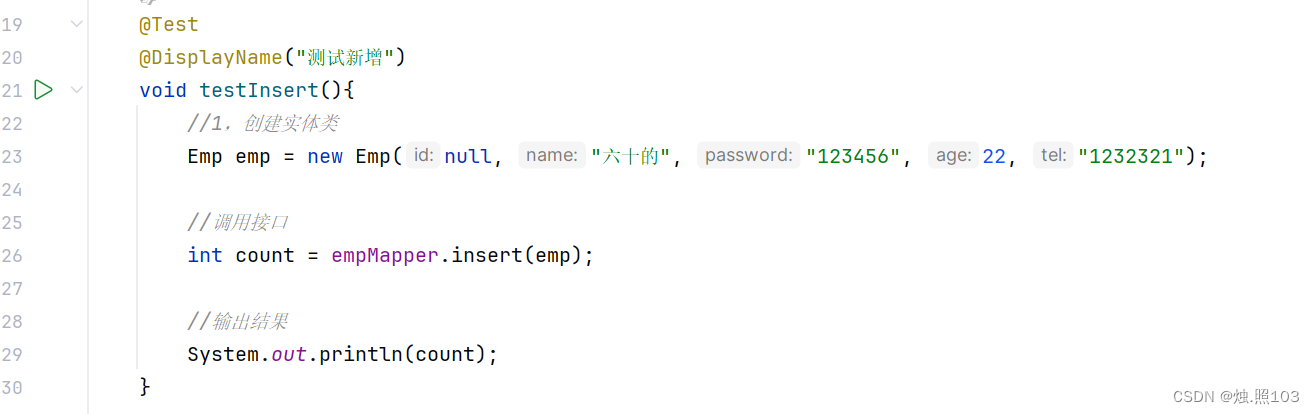
代码:
@Test@DisplayName("测试新增")void testInsert(){//1,创建实体类Emp emp = new Emp(null, "六十的", "123456", 22, "1232321");//调用接口int count = empMapper.insert(emp);//输出结果System.out.println(count);}结果:

测试修改:

代码:
@Test@DisplayName("测试修改")void update(){//1,创建条件LambdaQueryWrapper<Emp> queryWrapper = new LambdaQueryWrapper<Emp>();//名字中包含张的都修改queryWrapper.like(Emp::getName, "张");//2,创建实体类Emp emp = new Emp(null, "张三", "43434343434", 34, "1222222");//3,调用结果int count = empMapper.update(emp,queryWrapper);//4,输出返回值System.out.println(count);}结果:

根据id修改:
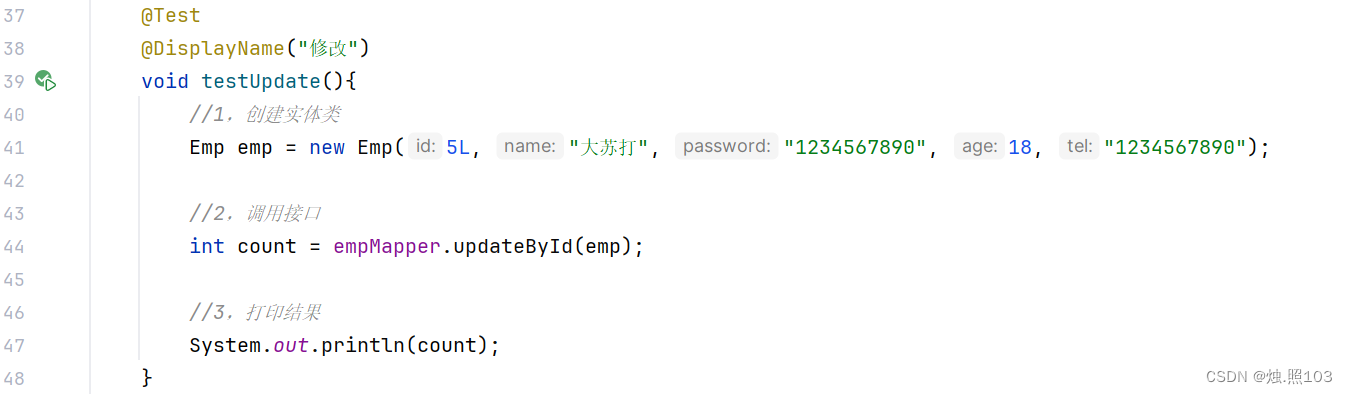
@Test@DisplayName("修改")void testUpdate(){//1,创建实体类Emp emp = new Emp(5L, "大苏打", "1234567890", 18, "1234567890");//2,调用接口int count = empMapper.updateById(emp);//3,打印结果System.out.println(count);}结果:

六,常见注解:
@TableName注解:
描述:表名注解,标识实体类对于的表
使用位置:实体类类名上面
示例:
@TableName("user")
public class User {private Long id;private String name;
}@TableId注解:
描述:主键注解;用于标记实体类中的主键字段
使用位置:实体类中属性之上
示例:
@TableName("user")
public class User {@TableIdprivate Long id;private String name;
}TableId注解有两个属性:
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 表名 |
| type | Enum | 否 | IdType.NONE | 指定主键类型 |
IdType支持的类型:
| 值 | 描述 |
|---|---|
| AUTO | 数据库 ID 自增 |
| NONE | 无状态,该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT) |
| INPUT | insert 前自行 set 主键值 |
| ASSIGN_ID | 分配 ID(主键类型为 Number(Long 和 Integer)或 String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法) |
| ASSIGN_UUID | 分配 UUID,主键类型为 String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID(默认 default 方法) |
比较常用的也就是下面这三个:
AUTO:利用数据库的id自增长
INPUT:手动生成id
ASSIGN_ID:雪花算法生成Long类型的全局唯一id,这是默认的ID策略
测试IdType的AUTO:
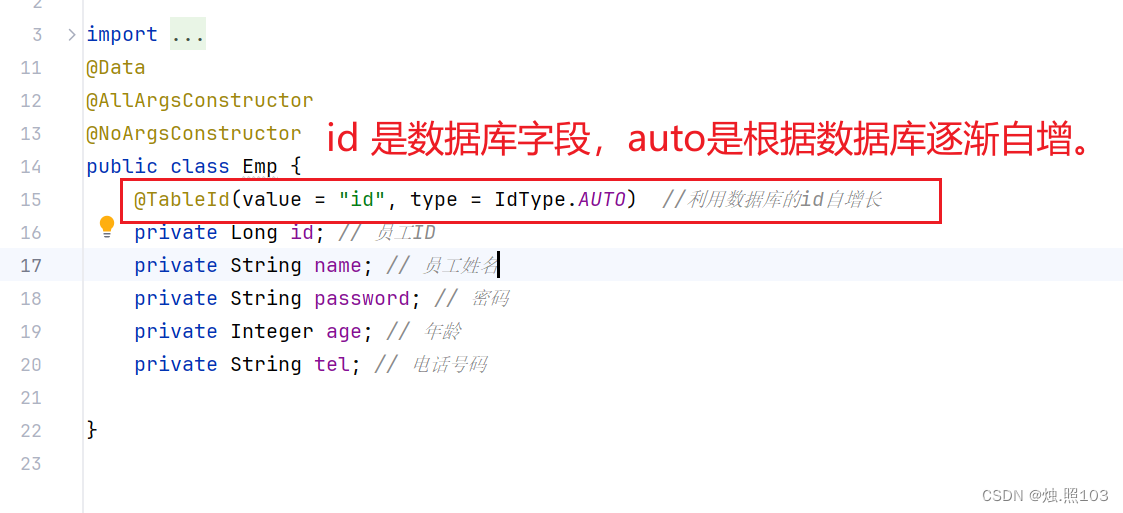
emp实体类:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Emp {@TableId(value = "id", type = IdType.AUTO) //利用数据库的id自增长private Long id; // 员工IDprivate String name; // 员工姓名private String password; // 密码private Integer age; // 年龄private String tel; // 电话号码}看看数据库的数据:

测试效果:
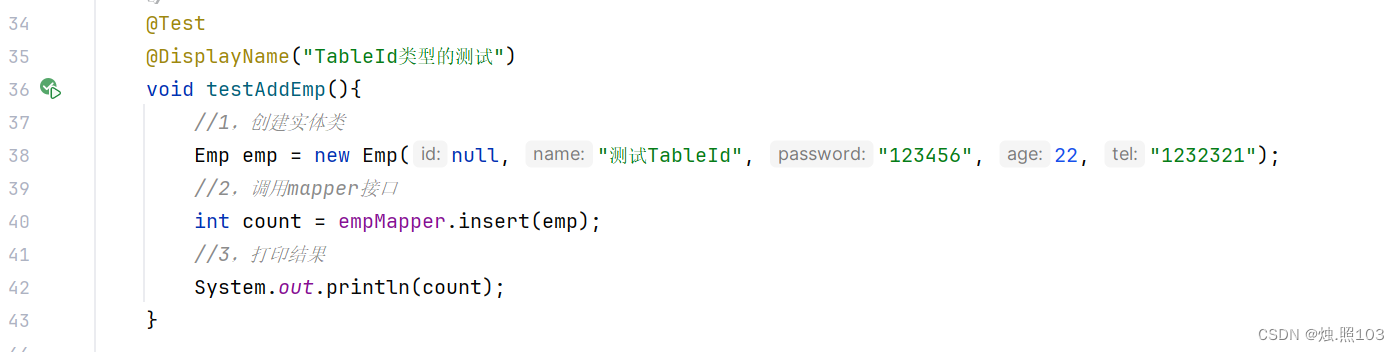
代码:
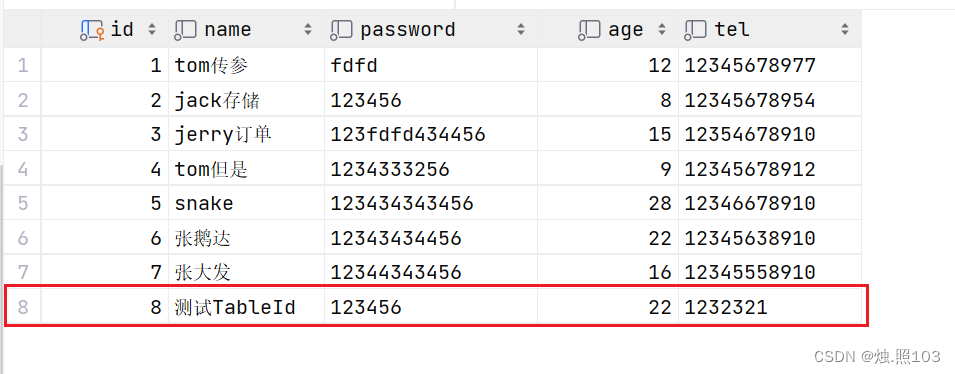
@Test@DisplayName("TableId类型的测试")void testAddEmp(){//1,创建实体类Emp emp = new Emp(null, "测试TableId", "123456", 22, "1232321");//2,调用mapper接口int count = empMapper.insert(emp);//3,打印结果System.out.println(count);}数据库的变化:
id从7,到8了。
测试IdType的INPUT:
实体类:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Emp {@TableId(value = "id", type = IdType.INPUT) //自己设置主键idprivate Long id; // 员工IDprivate String name; // 员工姓名private String password; // 密码private Integer age; // 年龄private String tel; // 电话号码}测试:
代码:
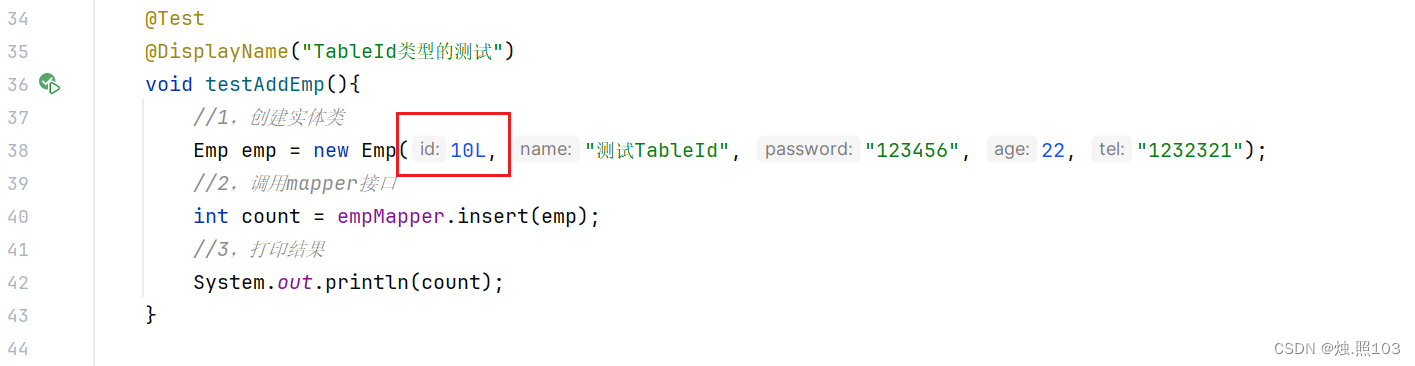
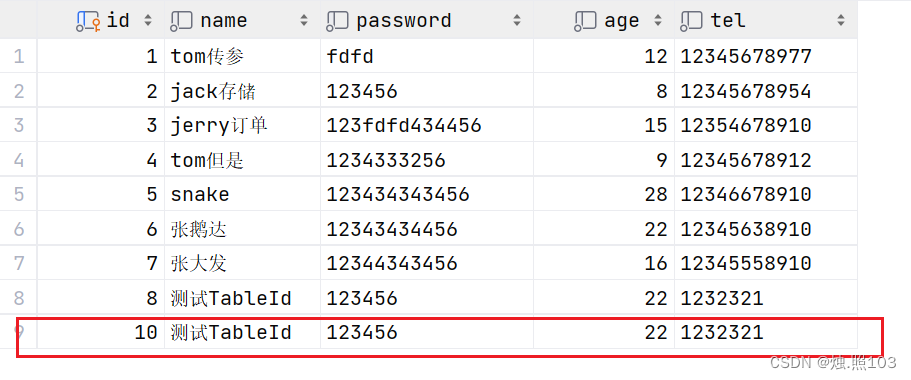
@Test@DisplayName("TableId类型的测试")void testAddEmp(){//1,创建实体类Emp emp = new Emp(10L, "测试TableId", "123456", 22, "1232321");//2,调用mapper接口int count = empMapper.insert(emp);//3,打印结果System.out.println(count);}看看数据库:
主键ID已经变成了我们自己输入的10
测试IdType的ASSIGN_ID:
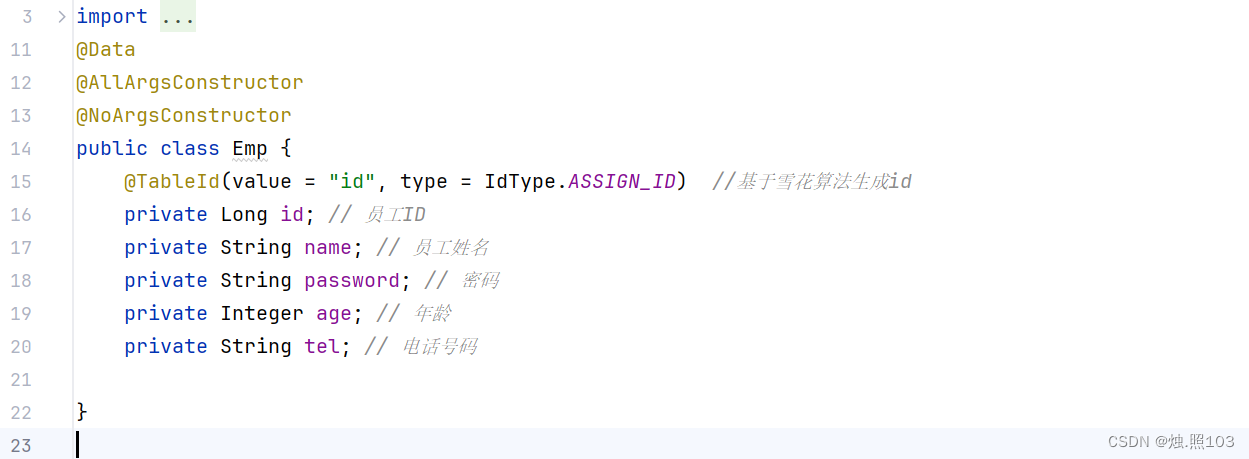
实体类:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Emp {@TableId(value = "id", type = IdType.ASSIGN_ID) //基于雪花算法生成idprivate Long id; // 员工IDprivate String name; // 员工姓名private String password; // 密码private Integer age; // 年龄private String tel; // 电话号码}测试:
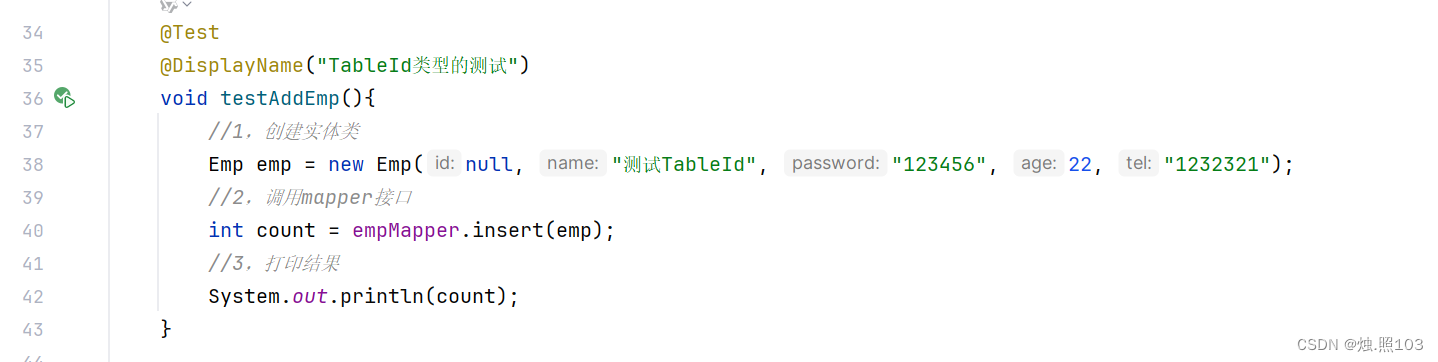
代码:
@Test@DisplayName("TableId类型的测试")void testAddEmp(){//1,创建实体类Emp emp = new Emp(null, "测试TableId", "123456", 22, "1232321");//2,调用mapper接口int count = empMapper.insert(emp);//3,打印结果System.out.println(count);}效果:
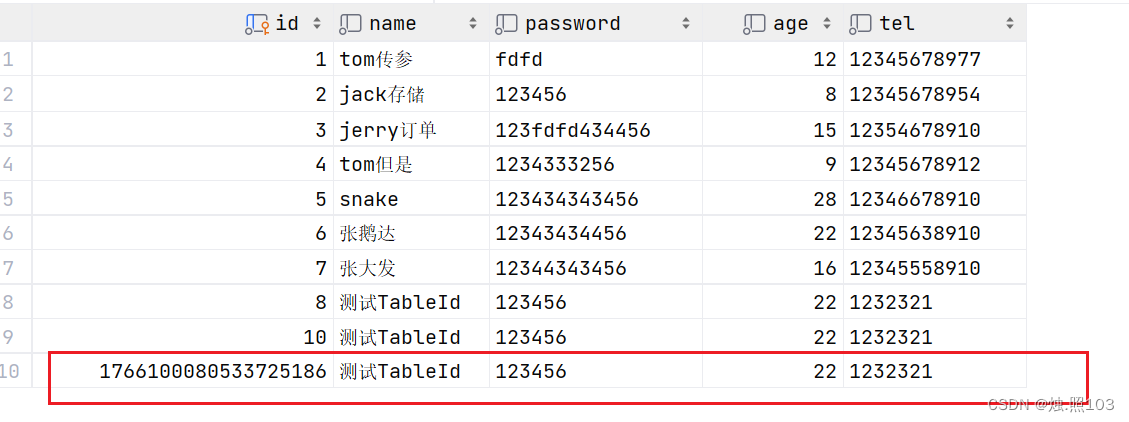
七,常见配置:
mybatis-plus也支持基于yaml文件的自定义配置,详见官方文档:使用配置 | MyBatis-Plus
大多数的配置都有默认值,因此我们都无需配置。但还有一些是没有默认值的,例如:
-
实体类的别名扫描包
-
全局id类型
mybatis-plus:type-aliases-package: com.sde.mp.domain.poglobal-config:db-config:id-type: auto # 全局id类型为自增长需要注意的是,MyBatisPlus也支持手写SQL的,而mapper文件的读取地址可以自己配置:
mybatis-plus:mapper-locations: "classpath*:/mapper/**/*.xml" # Mapper.xml文件地址,当前这个是默认值。八,分页插件:
在未引入分页插件的情况下,
MybatisPlus是不支持分页功能的,IService和BaseMapper中的分页方法都无法正常起效。 所以,我们必须配置分页插件。
配置分页插件:
在我们的包下,新建一个config包,然后编写一个MybatisConfig的配置类
代码:
public class MybatisConfig {
}配置Mybatis-plus的分页拦截器:

代码:
//在类上添加这个注解
@Configuration
public class MybatisConfig {//配置Mybatisplus的分页拦截器@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));return interceptor;}}测试分页:
简单测试:
在查询之间我们先看一下,我数据库的数据情况。
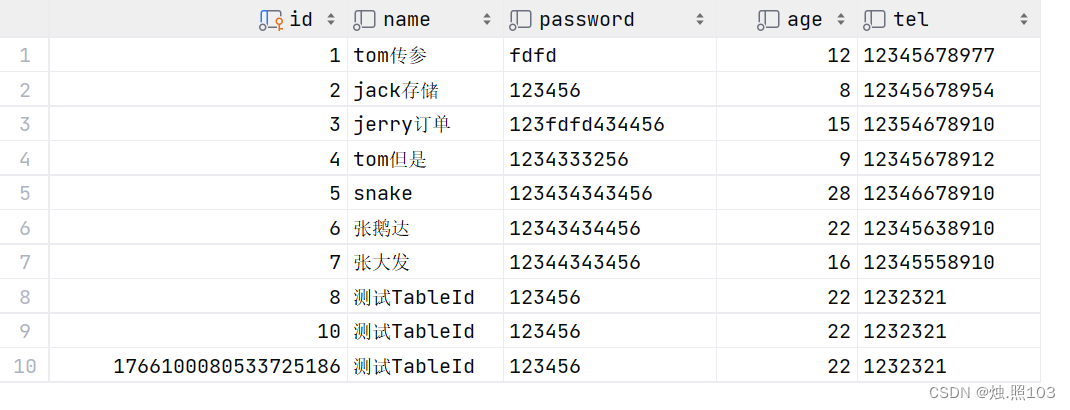
编写测试代码:
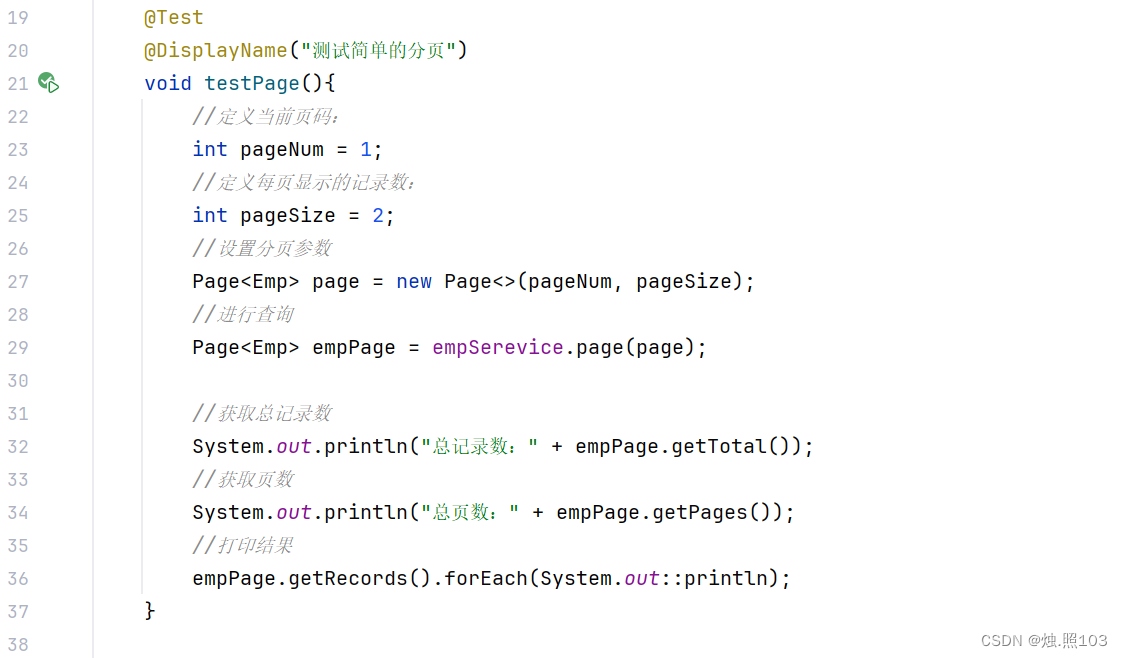
代码:
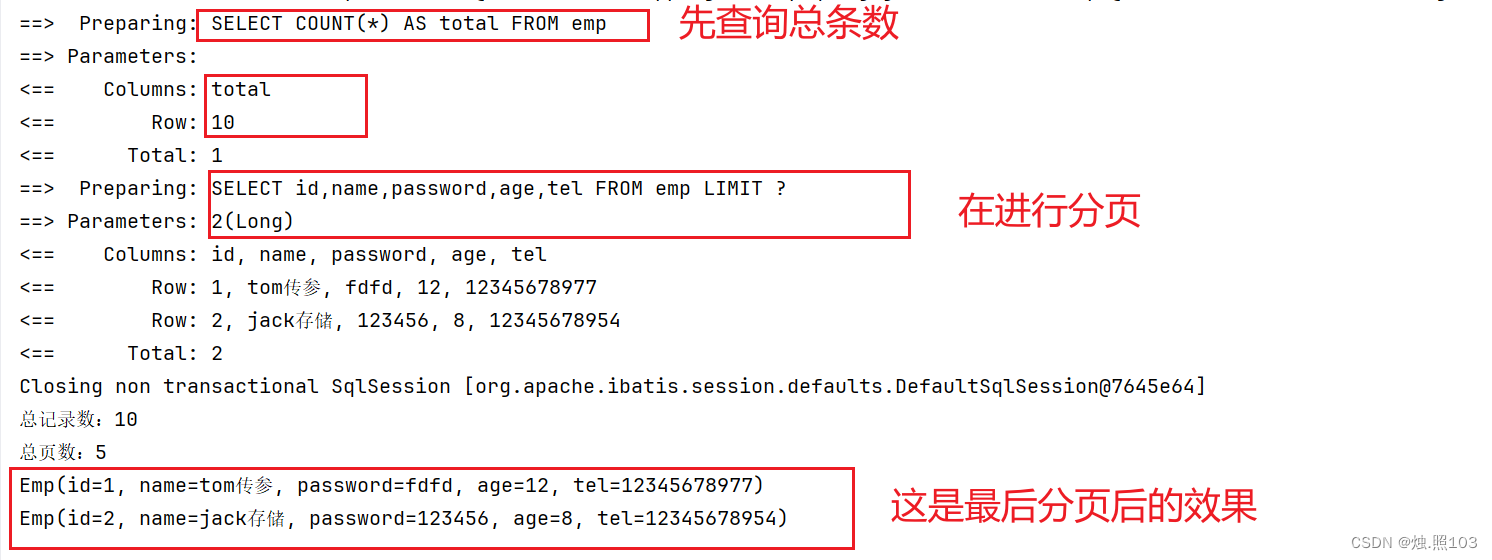
@Test@DisplayName("测试简单的分页")void testPage(){//定义当前页码:int pageNum = 1;//定义每页显示的记录数:int pageSize = 2;//设置分页参数Page<Emp> page = new Page<>(pageNum, pageSize);//进行查询Page<Emp> empPage = empSerevice.page(page);//获取总记录数System.out.println("总记录数:" + empPage.getTotal());//获取页数System.out.println("总页数:" + empPage.getPages());//打印结果empPage.getRecords().forEach(System.out::println);}结果:
简化写法:
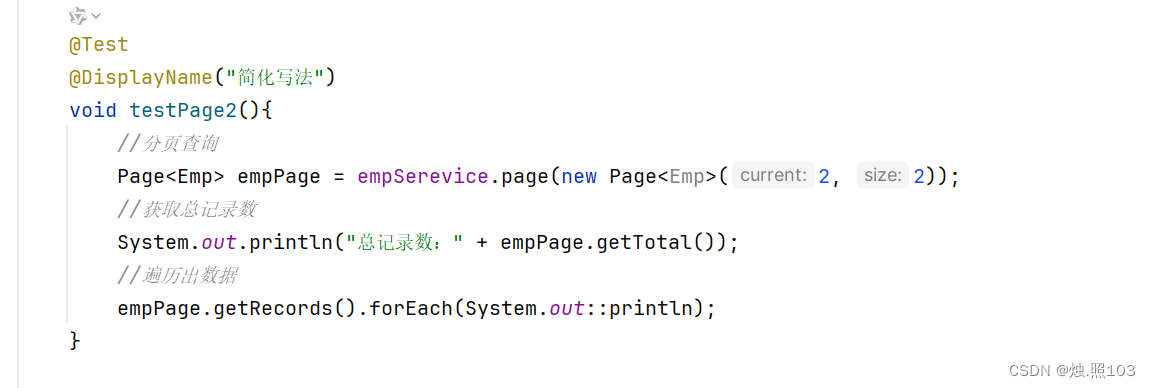
代码:
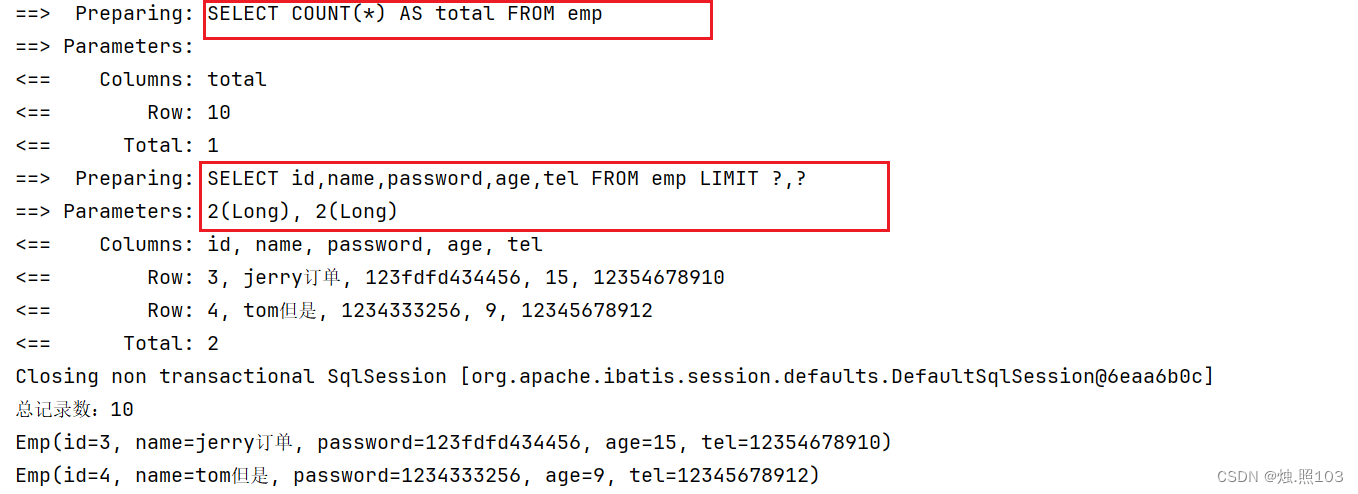
@Test@DisplayName("简化写法")void testPage2(){//分页查询Page<Emp> empPage = empSerevice.page(new Page<Emp>(2, 2));//获取总记录数System.out.println("总记录数:" + empPage.getTotal());//遍历出数据empPage.getRecords().forEach(System.out::println);}结果:
自定义条件分页查询:
编写查询参数实体类:
empQueryDto类

代码:
@Data
public class EmpQueryDto {private String name; // 员工姓名private Integer age; // 年龄private String tel; // 电话号码private Integer pageNum;// 当前页码private Integer pageSize;// 每页显示条数
}编写EmpController
条件分页查询的getEmpPage方法:

现在EmpService还没有写,empPage这个方法。报错先不用管
代码:
@Slf4j
@RestController
@RequestMapping("/emps")
public class EmpController {@Autowiredprivate EmpSerevice empService;@GetMapping("/page")public Result getEmpPage(EmpQueryDto query){log.info("接收到的参数;"+query);Page<Emp> empPage = empService.empPage(query);return Result.success(empPage);}}编写EmpService接口

代码:
public interface EmpSerevice extends IService<Emp> {/*** 条件分页查询用户信息* @param query* @return*/Page<Emp> empPage(EmpQueryDto query);
}EmpServiceImpl实现类:
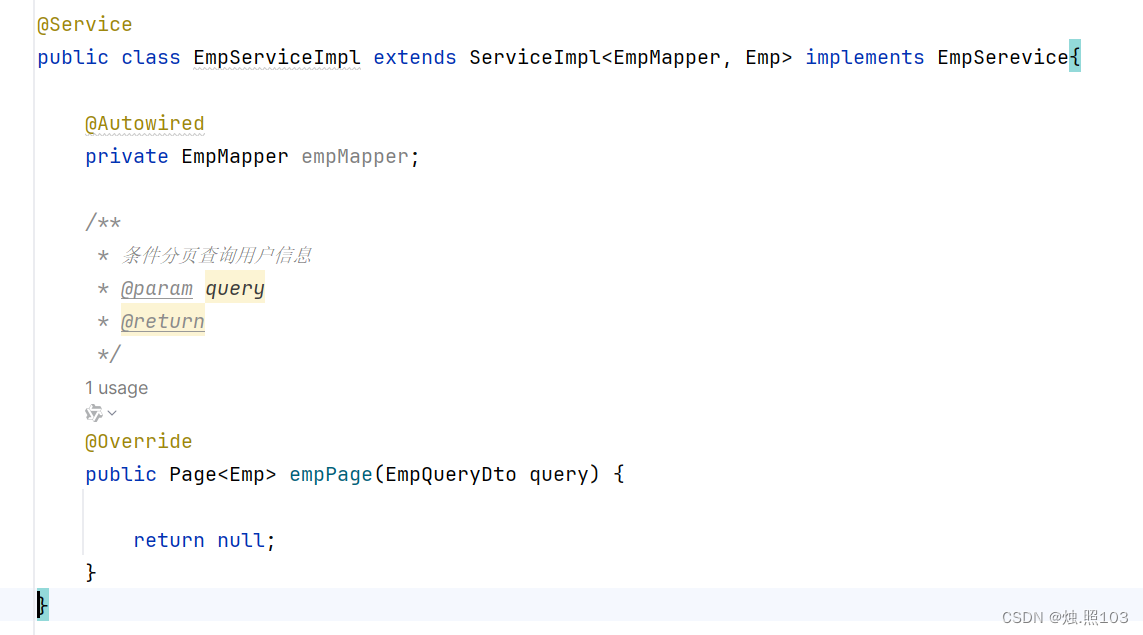
代码:
@Service
public class EmpServiceImpl extends ServiceImpl<EmpMapper, Emp> implements EmpSerevice{@Autowiredprivate EmpMapper empMapper;/*** 条件分页查询用户信息* @param query* @return*/@Overridepublic Page<Emp> empPage(EmpQueryDto query) {return null;}
}实现ServiceImpl层的方法:
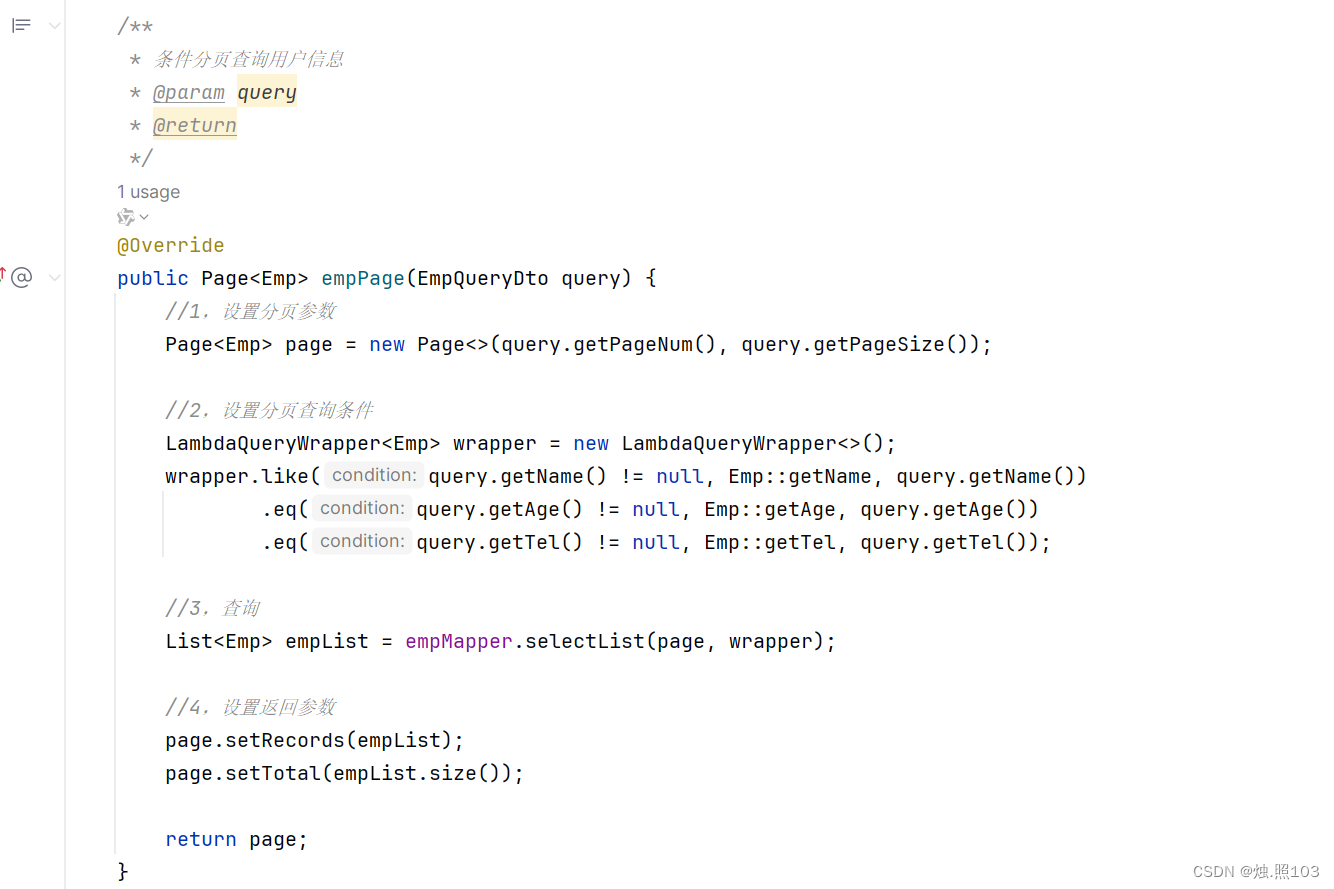
代码:
@Overridepublic Page<Emp> empPage(EmpQueryDto query) {//1,设置分页参数Page<Emp> page = new Page<>(query.getPageNum(), query.getPageSize());//2,设置分页查询条件LambdaQueryWrapper<Emp> wrapper = new LambdaQueryWrapper<>();wrapper.like(query.getName() != null, Emp::getName, query.getName()).eq(query.getAge() != null, Emp::getAge, query.getAge()).eq(query.getTel() != null, Emp::getTel, query.getTel());//3,查询List<Emp> empList = empMapper.selectList(page, wrapper);//4,设置返回参数page.setRecords(empList);page.setTotal(empList.size());return page;}测试结果:
在ApiFox里面设置查询的参数
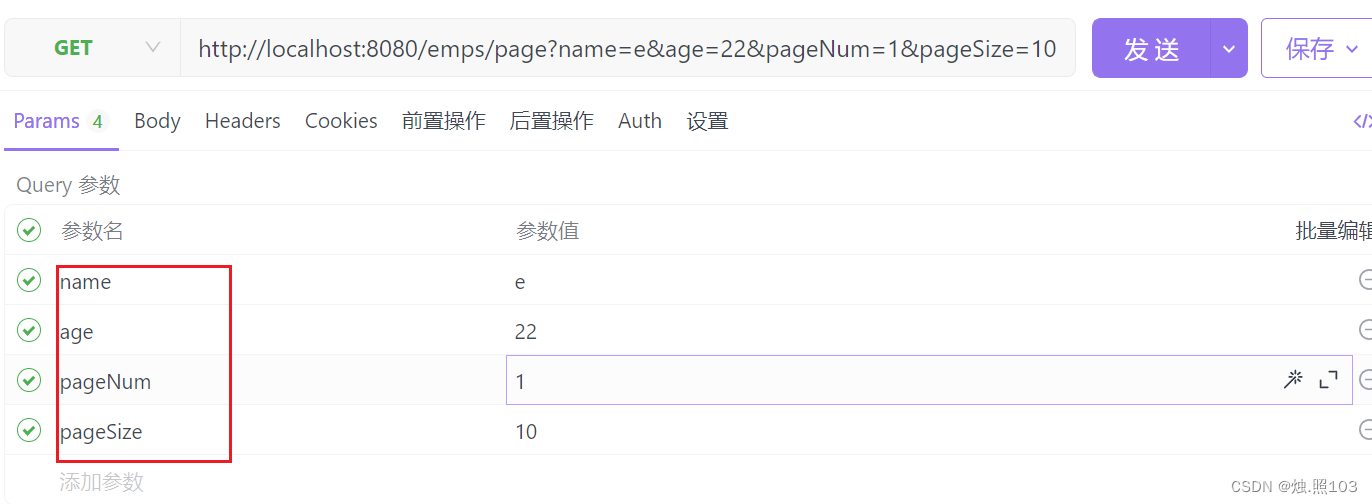
看看怎么执行的:
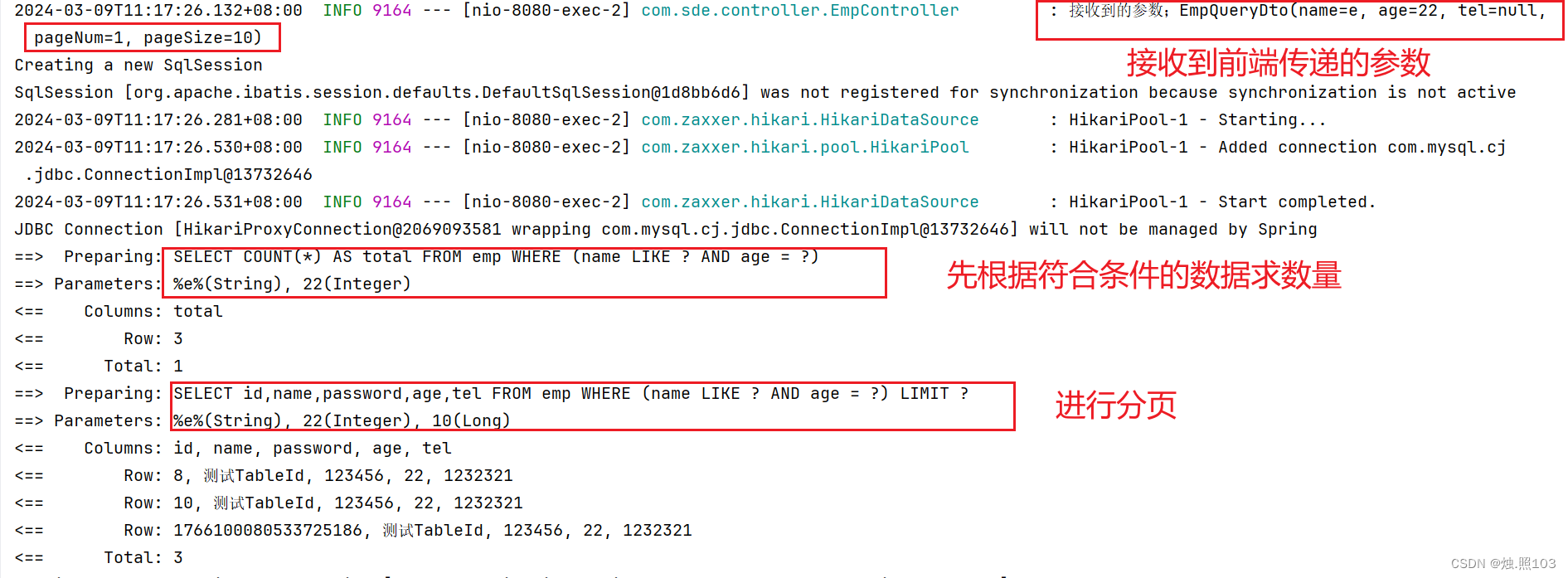
在ApiFox里面看看返回的数据:
{"code": 1,"msg": null,"data": {"records": [{"id": 8,"name": "测试TableId","password": "123456","age": 22,"tel": "1232321"},{"id": 10,"name": "测试TableId","password": "123456","age": 22,"tel": "1232321"},{"id": 1766100080533725186,"name": "测试TableId","password": "123456","age": 22,"tel": "1232321"}],"total": 3,"size": 10,"current": 1,"pages": 1}
}九,代码生成器:
在使用MybatisPlus以后,基础的Mapper、Service、PO代码相对固定,重复编写也比较麻烦。因此MybatisPlus官方提供了代码生成器根据数据库表结构生成PO、Mapper、Service等相关代码。
安装插件:
方式一:在Idea的plugins市场中搜索并安装MyBatisPlus插件(插件不太稳定,建议按照官网方式):
点击Settings,找到plugins,搜索mybatisplus这个插件
然后重启Idea就可以了
方式二:上述的图形界面插件,存在不稳定因素;所以建议使用代码方式生成。官网安装说明。在项目中 pom.xml 添加依赖如下:
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-generator</artifactId><version>3.5.3.1</version><scope>test</scope></dependency><dependency><groupId>org.freemarker</groupId><artifactId>freemarker</artifactId><version>2.3.32</version><scope>test</scope></dependency>使用:
使用图形界面方式的直接打开设置数据信息和填写其它界面中需要的内容即可。
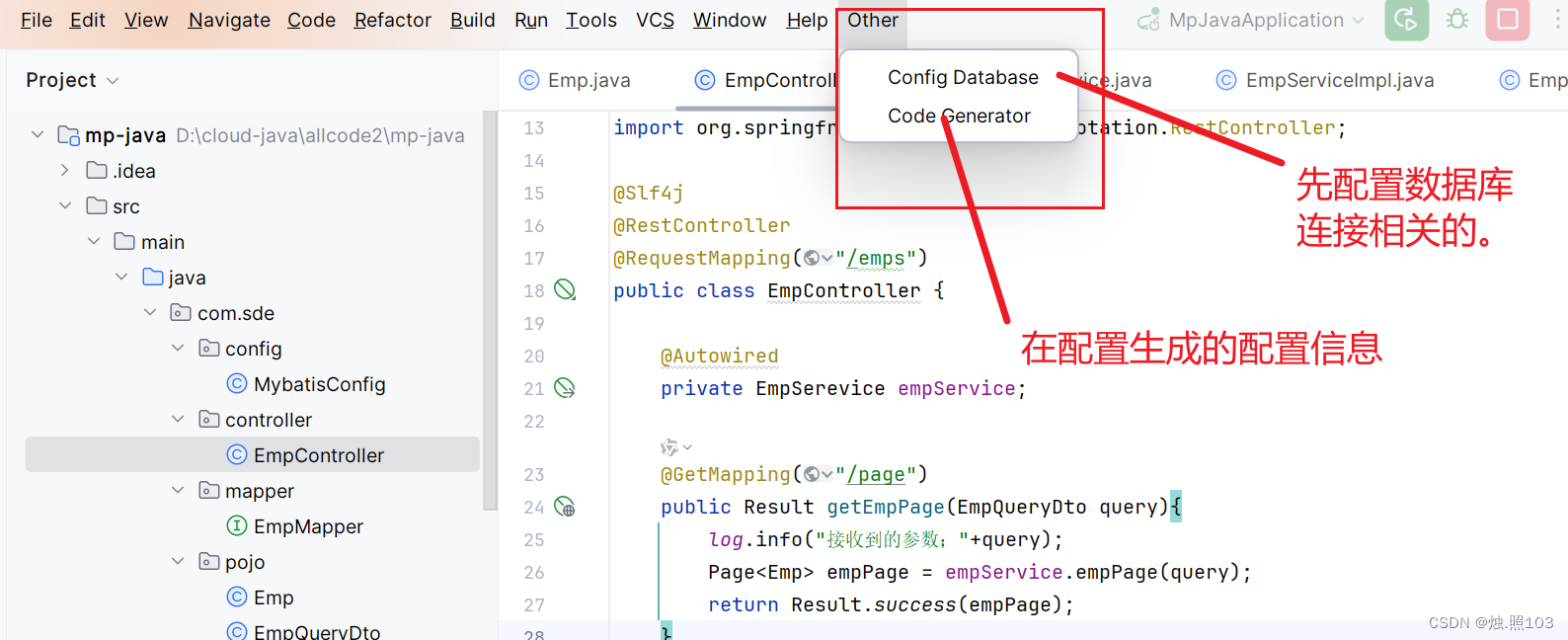
在新版IDEA中;入口在 others这个里面:
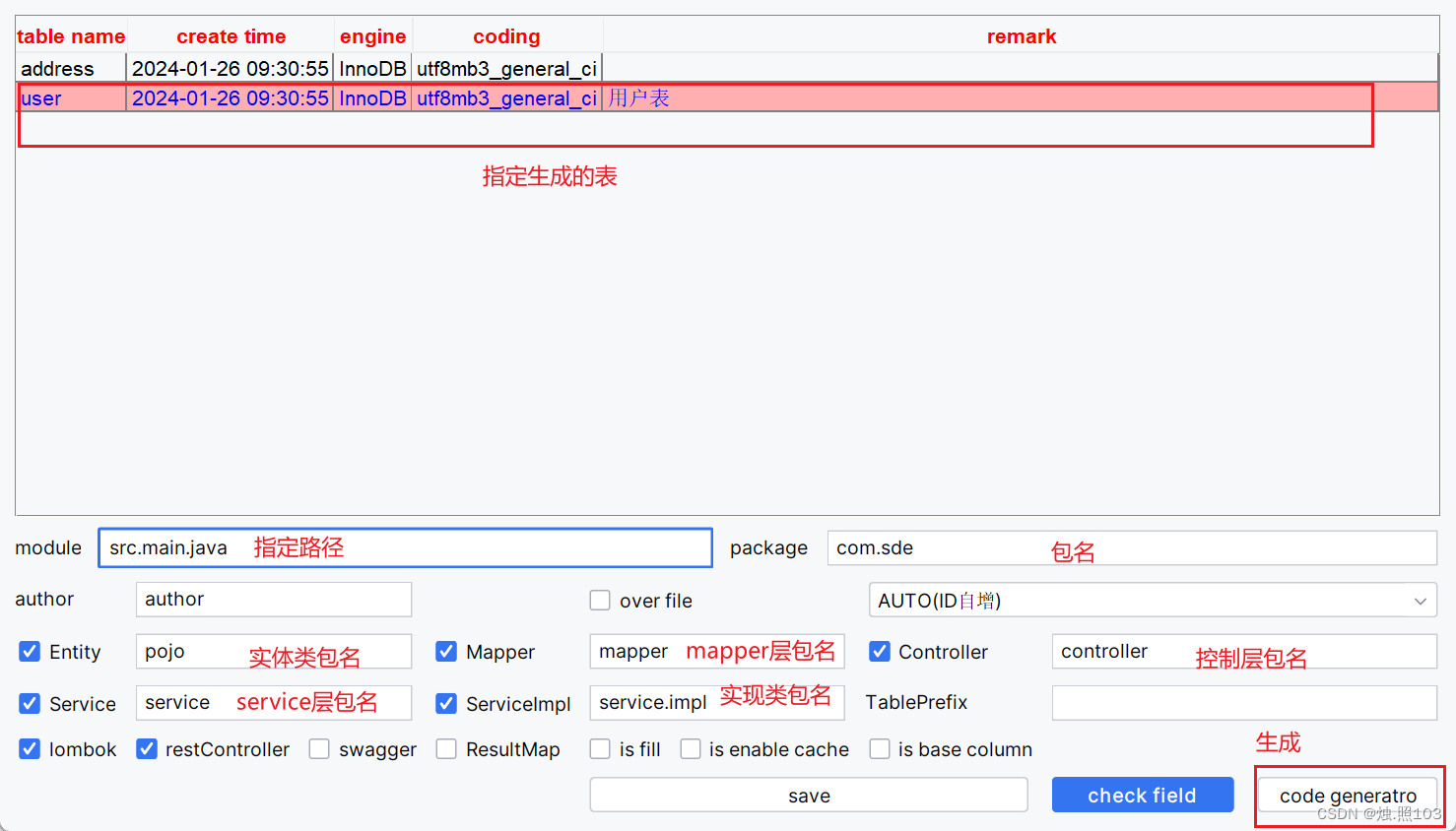
使用图形工具生成:
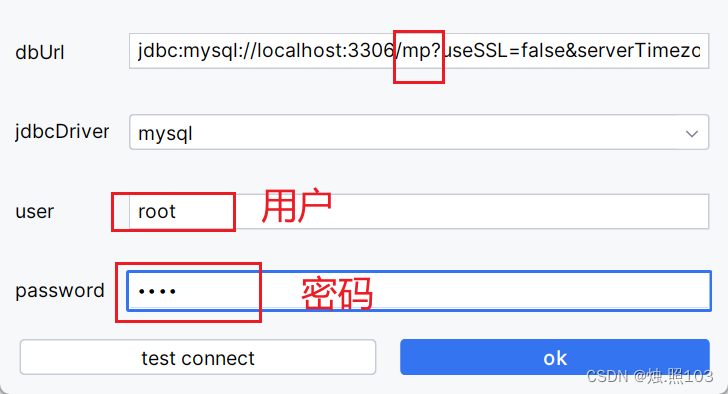
设置连接数据库的配置信息:
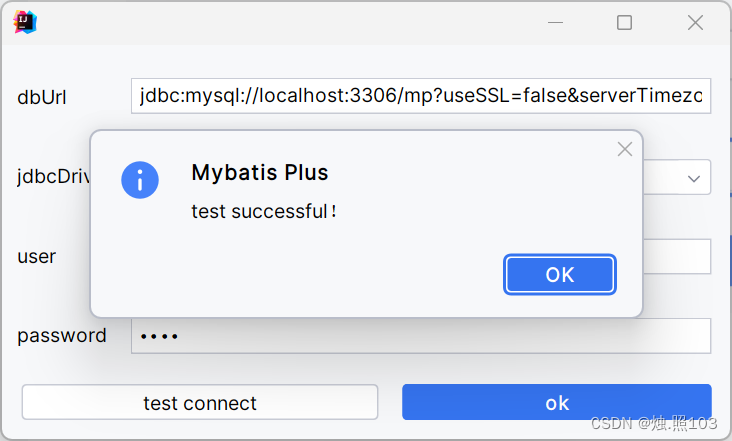
点击测试连接:
可以看到 test successful连接成功了
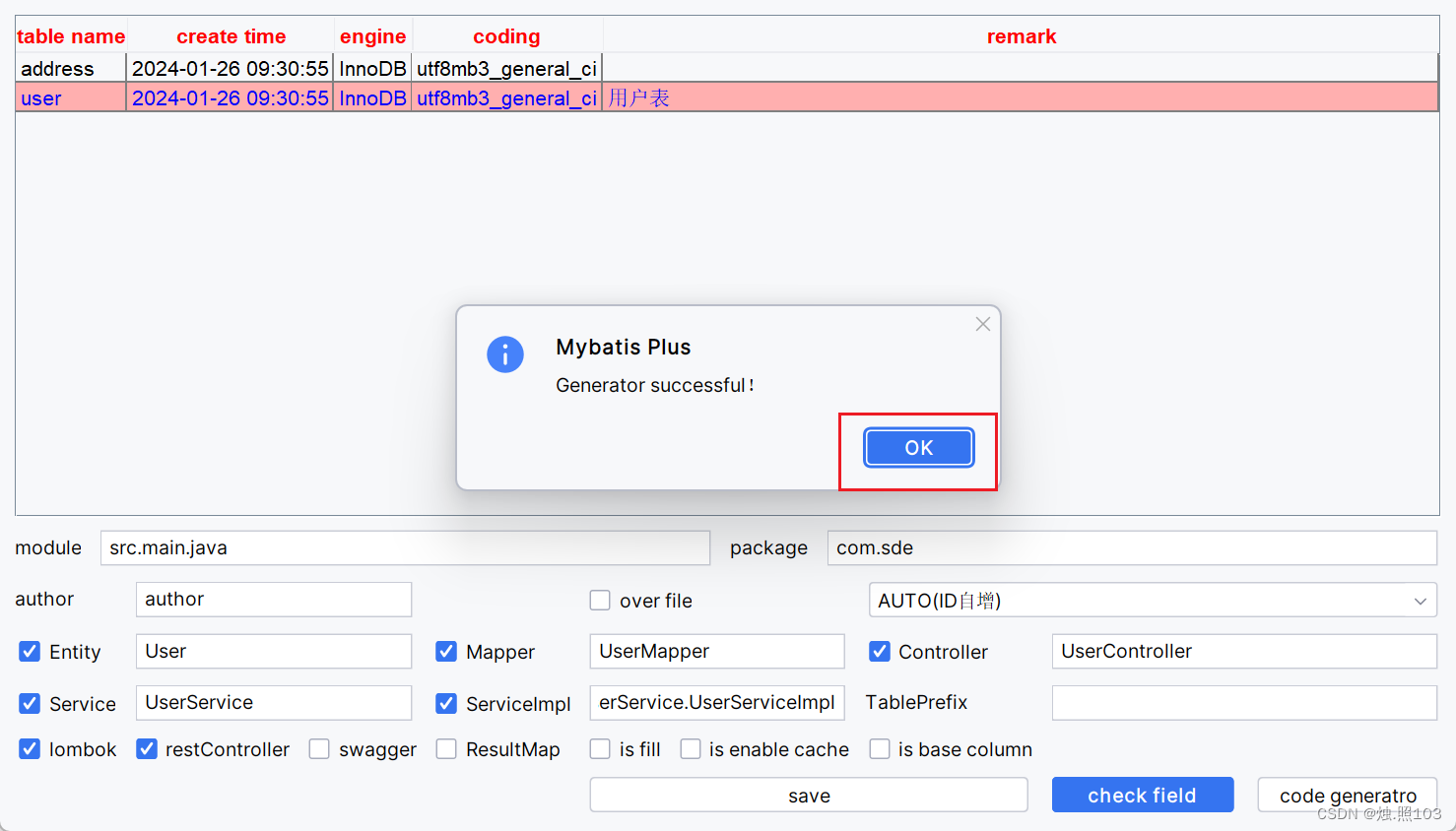
使用介绍:
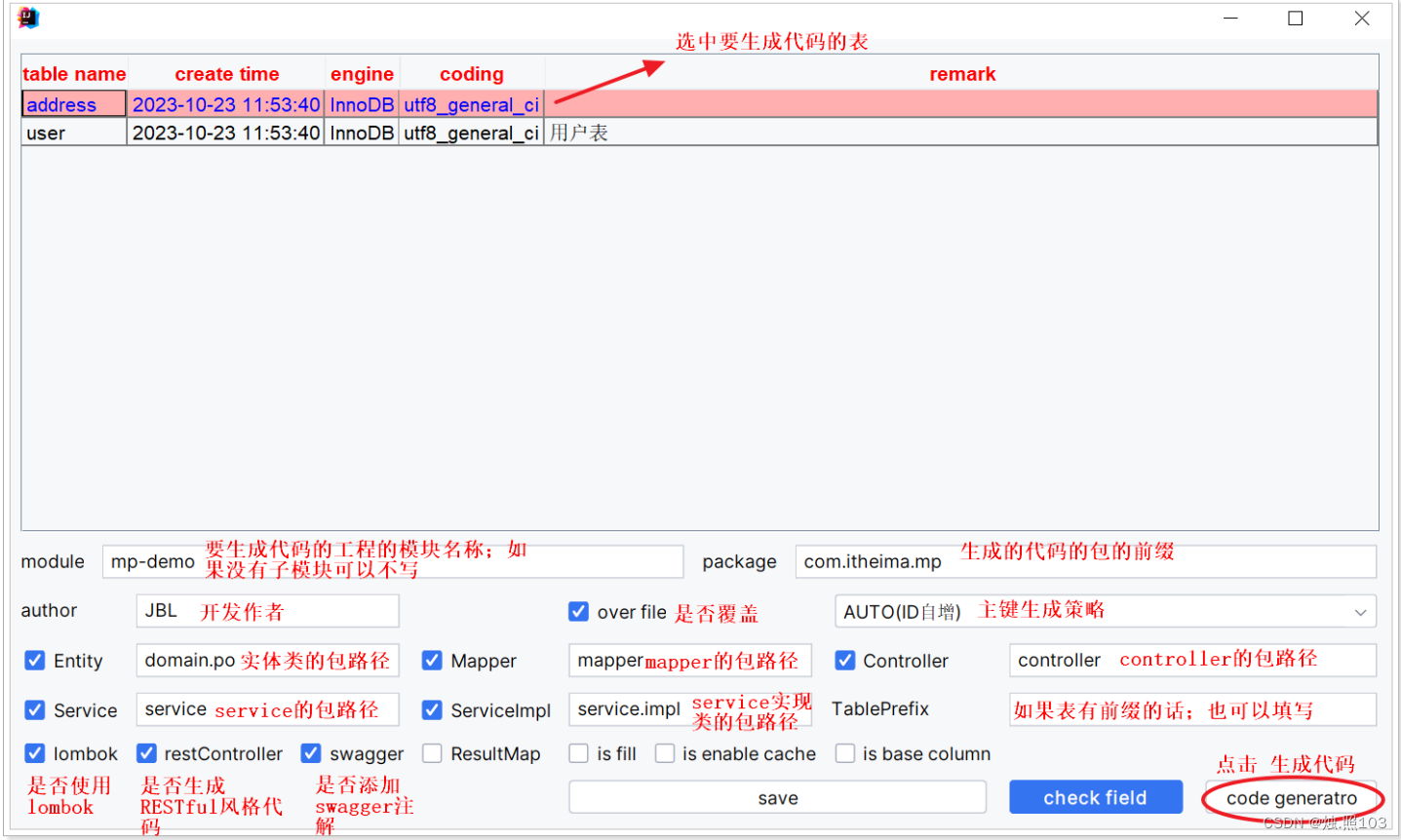
成功标志:
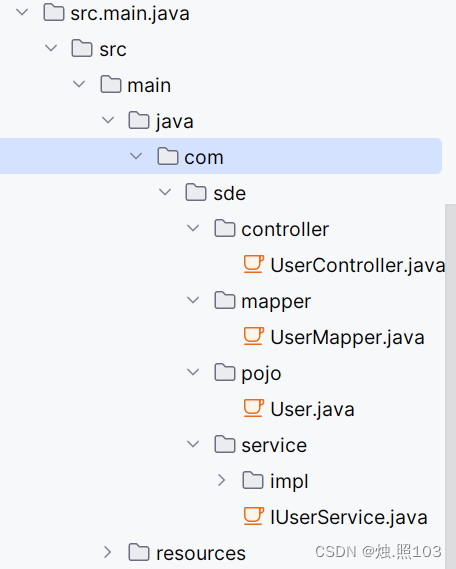
目录结构
使用代码生成:
1,添加依赖:
2,写一个测试类,名字为MybatisPlusGenTest的类
代码:
public class MybatisPlusGenTest {}3,添加生成的配置信息:
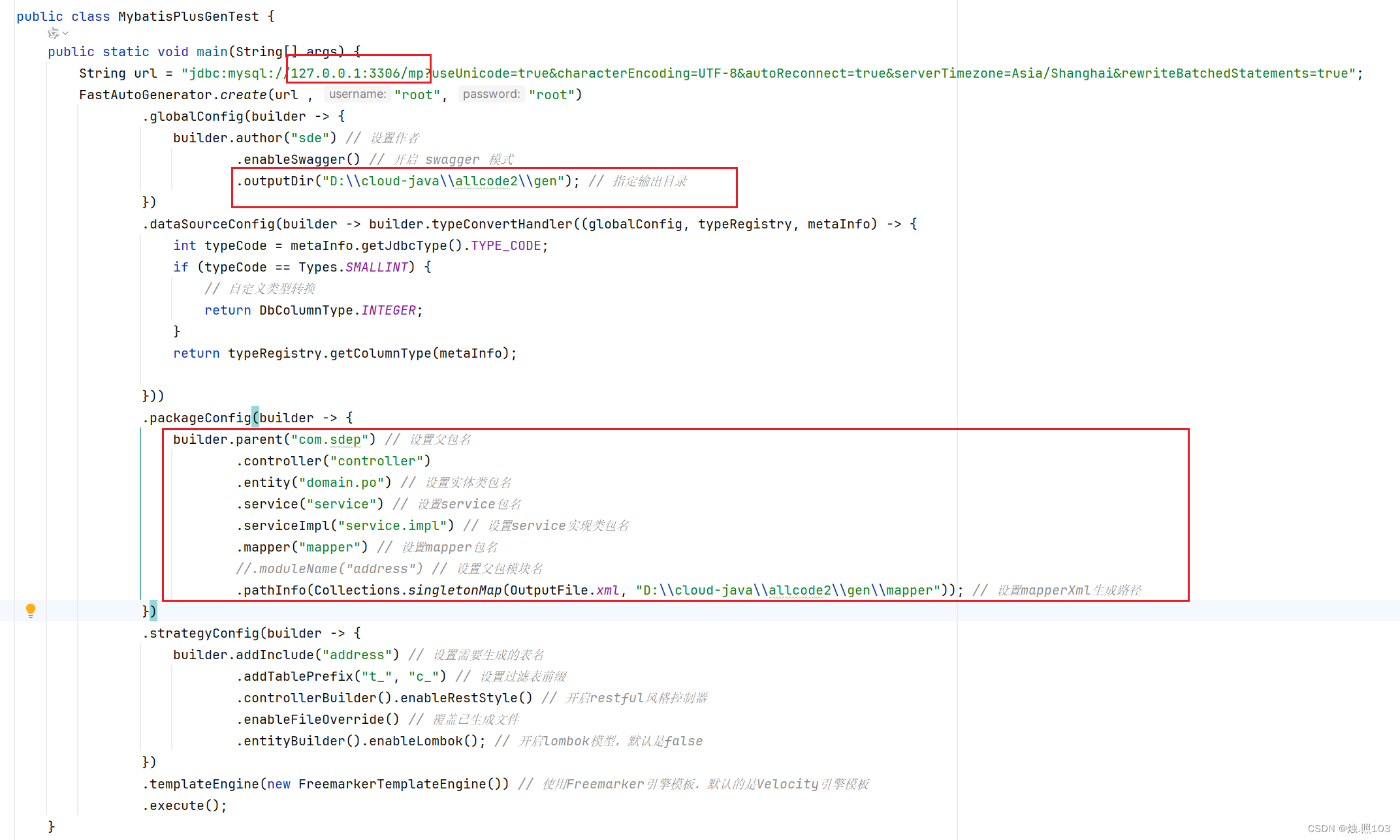
代码:
public static void main(String[] args) {String url = "jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true";FastAutoGenerator.create(url , "root", "root").globalConfig(builder -> {builder.author("sde") // 设置作者.enableSwagger() // 开启 swagger 模式.outputDir("D:\\cloud-java\\allcode2\\gen"); // 指定输出目录}).dataSourceConfig(builder -> builder.typeConvertHandler((globalConfig, typeRegistry, metaInfo) -> {int typeCode = metaInfo.getJdbcType().TYPE_CODE;if (typeCode == Types.SMALLINT) {// 自定义类型转换return DbColumnType.INTEGER;}return typeRegistry.getColumnType(metaInfo);})).packageConfig(builder -> {builder.parent("com.sdep") // 设置父包名.controller("controller").entity("domain.po") // 设置实体类包名.service("service") // 设置service包名.serviceImpl("service.impl") // 设置service实现类包名.mapper("mapper") // 设置mapper包名//.moduleName("address") // 设置父包模块名.pathInfo(Collections.singletonMap(OutputFile.xml, "D:\\cloud-java\\allcode2\\gen\\mapper")); // 设置mapperXml生成路径}).strategyConfig(builder -> {builder.addInclude("address") // 设置需要生成的表名.addTablePrefix("t_", "c_") // 设置过滤表前缀.controllerBuilder().enableRestStyle() // 开启restful风格控制器.enableFileOverride() // 覆盖已生成文件.entityBuilder().enableLombok(); // 开启lombok模型,默认是false}).templateEngine(new FreemarkerTemplateEngine()) // 使用Freemarker引擎模板,默认的是Velocity引擎模板.execute();}将生成的实体、Mapper、Service、Controller等对应的类放置到项目中。即可
4,点击运行:
5,查看生成的目录:
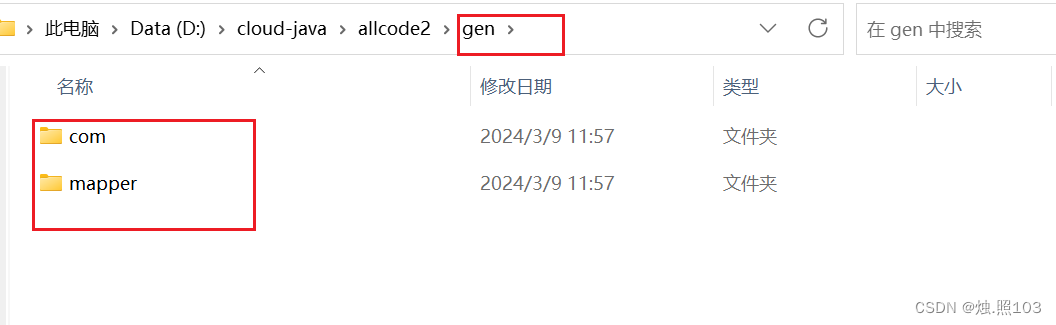
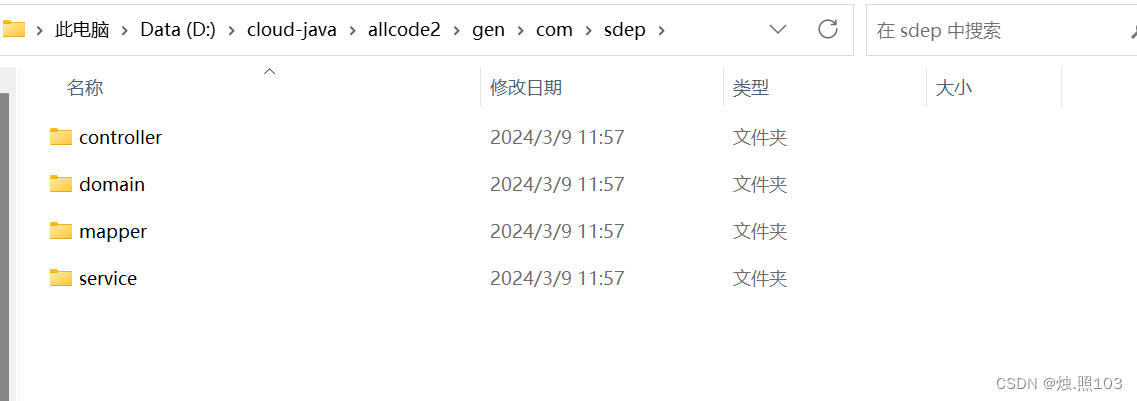
完整版的代码生成器,代码:
public class MybatisPlusGeneratorTest {public static void main(String[] args) {String url = "jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true";FastAutoGenerator.create(url , "root", "root").globalConfig(builder -> {builder.author("JBL") // 设置作者.enableSwagger() // 开启 swagger 模式.outputDir("D:\\itcast\\generatedCode"); // 指定输出目录}).dataSourceConfig(builder -> builder.typeConvertHandler((globalConfig, typeRegistry, metaInfo) -> {int typeCode = metaInfo.getJdbcType().TYPE_CODE;if (typeCode == Types.SMALLINT) {// 自定义类型转换return DbColumnType.INTEGER;}return typeRegistry.getColumnType(metaInfo);})).packageConfig(builder -> {builder.parent("com.itheima.mp") // 设置父包名.controller("controller").entity("domain.po") // 设置实体类包名.service("service") // 设置service包名.serviceImpl("service.impl") // 设置service实现类包名.mapper("mapper") // 设置mapper包名//.moduleName("address") // 设置父包模块名.pathInfo(Collections.singletonMap(OutputFile.xml, "D:\\itcast\\generatedCode\\mapper")); // 设置mapperXml生成路径}).strategyConfig(builder -> {builder.addInclude("address") // 设置需要生成的表名.addTablePrefix("t_", "c_") // 设置过滤表前缀.controllerBuilder().enableRestStyle() // 开启restful风格控制器.enableFileOverride() // 覆盖已生成文件.entityBuilder().enableLombok(); // 开启lombok模型,默认是false}).templateEngine(new FreemarkerTemplateEngine()) // 使用Freemarker引擎模板,默认的是Velocity引擎模板.execute();}
}十,静态工具类:
使用Db实现如下需求:
1、根据id查询用户;
2、查询名字中包含o且年龄大于8岁的;
3、更新用户名为tom的年龄为18
测试根据ID查询:
代码:
@SpringBootTest
public class DbTest {@Test@DisplayName("根据id查询用户")public void testById(){Emp emp = Db.getById(1L, Emp.class);System.out.println(emp);}
}结果:

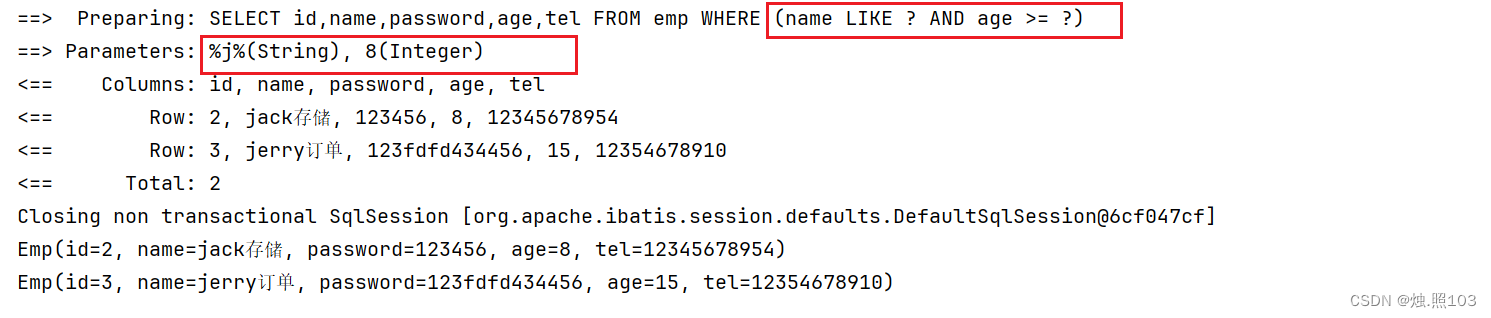
测试查询名字中包含j且年龄大于8岁的

代码:
@Test@DisplayName("测试查询名字中包含j且年龄大于8岁的")void testWrapper(){//查询参数设置List<Emp> empList = Db.lambdaQuery(Emp.class).like(Emp::getName, "j").ge(Emp::getAge, 8).list();//遍历empList.forEach(emp -> System.out.println(emp));}结果:
更新用户名为tom的年龄为18

代码:
@Test@DisplayName("更新用户名为tom的年龄为18")void testUpdate(){Db.lambdaUpdate(Emp.class).set(Emp::getAge, 18).eq(Emp::getName, "tom").update();}结果:
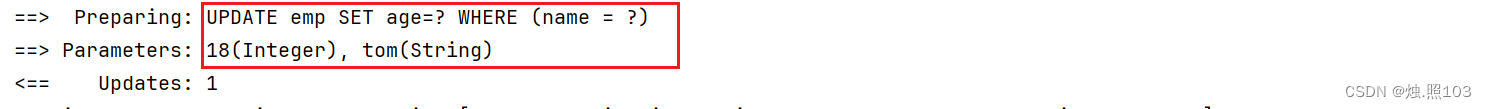
相关文章:
mybatis-plus整合spring boot极速入门
使用mybatis-plus整合spring boot,接下来我来操作一番。 一,创建spring boot工程 勾选下面的选项 紧接着,还有springboot和依赖我们需要选。 这样我们就创建好了我们的spring boot,项目。 简化目录结构: 我们发现&a…...

Kafka|处理 Kafka 消息重复的有效措施
文章目录 消息重复场景生产者端Kafka Broker消费者端 如何防止消息重复 消息重复是 Kafka 系统中另一个常见的问题,可能发生在生产者、Broker 或消费者三个方面。下面我们来讨论一些可能导致消息重复的场景以及如何处理。 消息重复场景 生产者端 重试机制导致消息…...
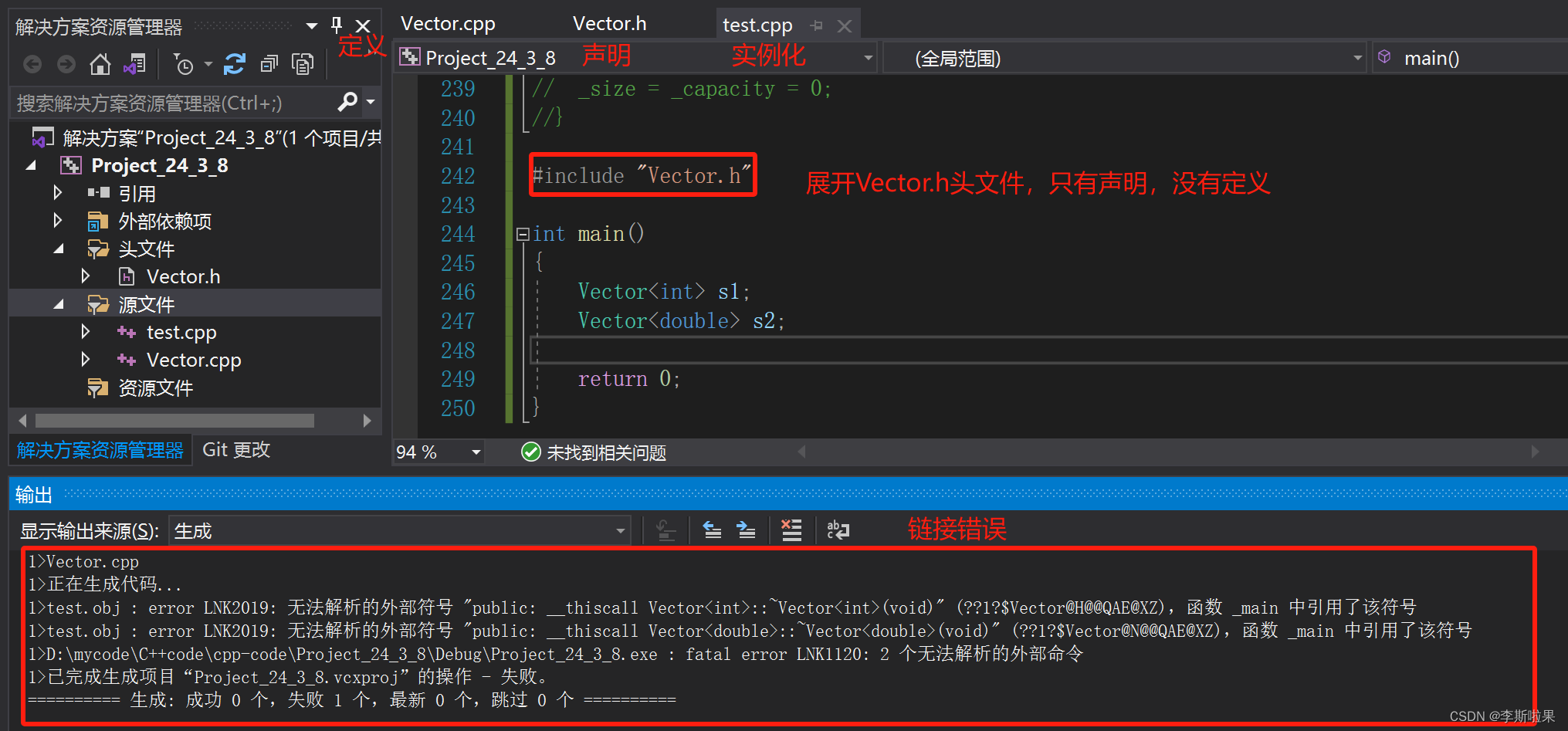
【C++】函数模板和类模板
目录 1.泛型编程 2.函数模板 2.1函数模板的定义格式 2.2函数模板的实例化 2.3函数模板参数的匹配原则 3.类模板 3.1类模板的定义格式 3.2类模板的实例化 3.3模板的分离编译 1.泛型编程 泛型编程:编写与类型无关的通用代码,是代码复用的一种手段…...
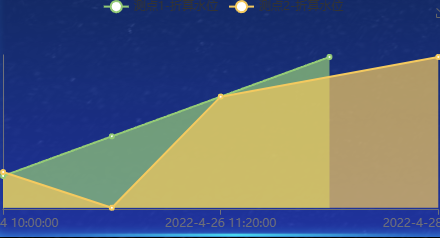
Echarts 配置项 series 中的 data 是多维度
文章目录 需求分析 需求 如下图数据格式所示,现要求按照该格式进行绘制折线图 分析 在绘制折线图时,通常我们的 series 中的 data 数据是这样的格式 option {title: {text: Stacked Area Chart},tooltip: {trigger: axis,axisPointer: {type: cross…...
快速了解Redis
Redis是什么? Redis是一个数据库,是一个跨平台的非关系型数据库,Redis完全开源,遵守BSD协议。它通过键值对(Key-Value)的形式存储数据。 与传统数据库不同的是 Redis 的数据是存在内存中的 ,也就是它是内存数据库&am…...

1.2_2 OSI参考模型
文章目录 1.2_2 OSI参考模型一、概述(一)ISO/OSI参考模型是怎么来的?(二)ISO/OSI参考模型(三)ISO/OSI参考模型解释通信过程 二、各层功能及协议(一)应用层(第…...
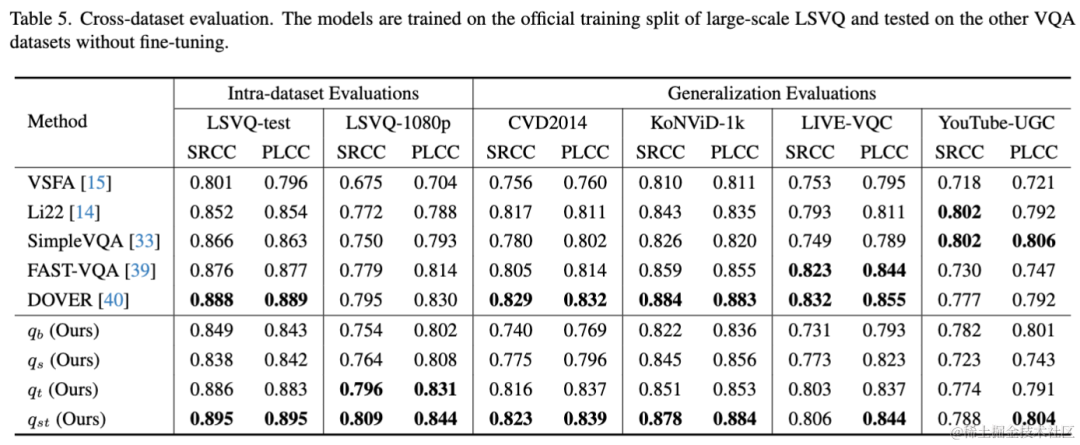
CVPR 2024 | Modular Blind Video Quality Assessment:模块化无参视频质量评估
无参视频质量评估 (Blind Video Quality Assessment,BVQA) 在评估和改善各种视频平台并服务用户的观看体验方面发挥着关键作用。当前基于深度学习的模型主要以下采样/局部块采样的形式分析视频内容,而忽视了实际空域分辨率和时域帧率对视频质量的影响&am…...

C++指针(五)完结篇
个人主页:PingdiGuo_guo 收录专栏:C干货专栏 前言 相关文章:C指针(一)、C指针(二)、C指针(三)、C指针(四)万字图文详解! 本篇博客是介…...

使用registry镜像创建私有仓库
通过安装Docker后,Docker官网提供的registry镜像简单搭建一套本地私有仓库 1.通过registry镜像 ,做端口映射,创建一个容器,通过容器内的一个目录来创建私有仓库 并且将容器内仓库与本地路径做挂载 [rootnode1 ~]# docker run -d…...

前端发展史与优秀编程语言
前端开发是互联网技术领域中的一个重要分支,负责构建用户直接交互的网页和应用程序界面。随着互联网的发展,前端技术经历了多个阶段的演变,从最初的简单静态页面到如今的复杂交互式应用,不断推动着用户体验的提升和网页功能的丰富…...

利用SQL Server 进行报表统计的关键SQL语句与函数
在数据库应用中,报表统计是一项至关重要的任务,它为企业提供了数据洞察和决策支持。SQL Server作为一种强大的关系型数据库管理系统,提供了丰富的SQL语句和函数,可用于高效地进行报表统计。本文将介绍一些常用的SQL语句和函数&…...

【目标检测】旋转目标检测COCO格式标注转DOTAv1格式
DOTAv1数据集格式: imagesource:imagesource gsd:gsd x1, y1, x2, y2, x3, y3, x4, y4, category, difficult x1, y1, x2, y2, x3, y3, x4, y4, category, difficult ... imagesource: 图片来源 gsd: 分辨率 x1, y1, x2, y2, x3, y3, x4, y4:四边形的四…...

数据结构与算法:链式二叉树
上一篇文章我们结束了二叉树的顺序存储,本届内容我们来到二叉树的链式存储! 链式二叉树 1.链式二叉树的遍历1.1二叉树的前序,中序,后序遍历1.2 三种遍历方法代码实现 2. 获取相关个数2.1获取节点个数2.2获取叶节点个数2.3 获取树的…...

SpringMVC中接收参数总结
目录 一、引子 二、注解解析 RequestParam 一、要求形参名请求参数名,或者是请求实体类时(已有实体类),可以不需要加该注解 二、请求参数名!参数名时,需要写该注解RequestParam,其中 三、一名多值的情…...
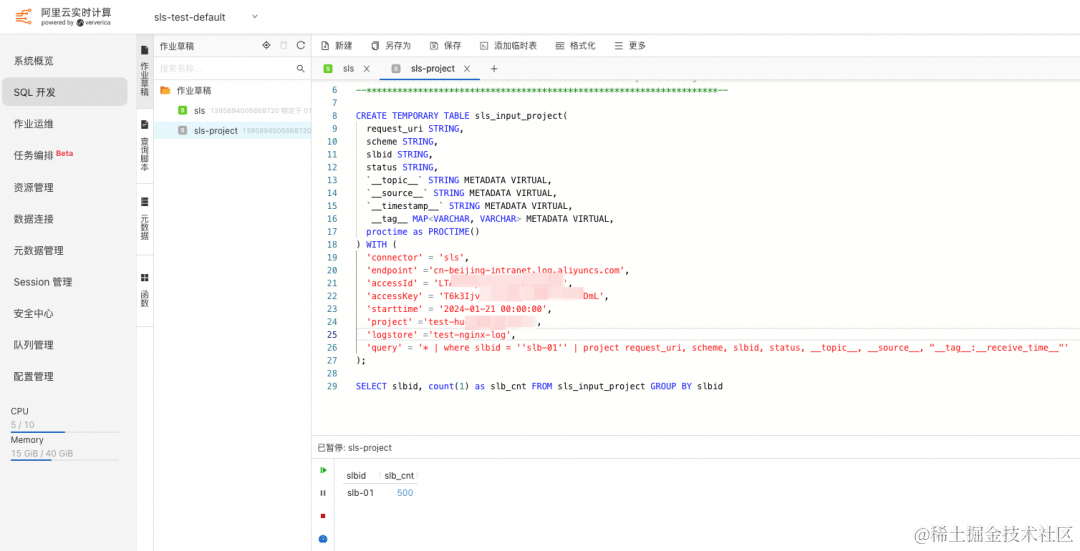
使用 SPL 高效实现 Flink SLS Connector 下推
作者:潘伟龙(豁朗) 背景 日志服务 SLS 是云原生观测与分析平台,为 Log、Metric、Trace 等数据提供大规模、低成本、实时的平台化服务,基于日志服务的便捷的数据接入能力,可以将系统日志、业务日志等接入 …...
《日期类》的模拟实现
目录 前言: 头文件类与函数的定义Date.h 实现函数的Date.cpp 测试Test.cpp 运行结果: 前言: 我们在前面的两章初步学习认识了《类与对象》的概念,接下来我们将实现一个日期类,是我们的知识储备更加牢固。 头文件…...
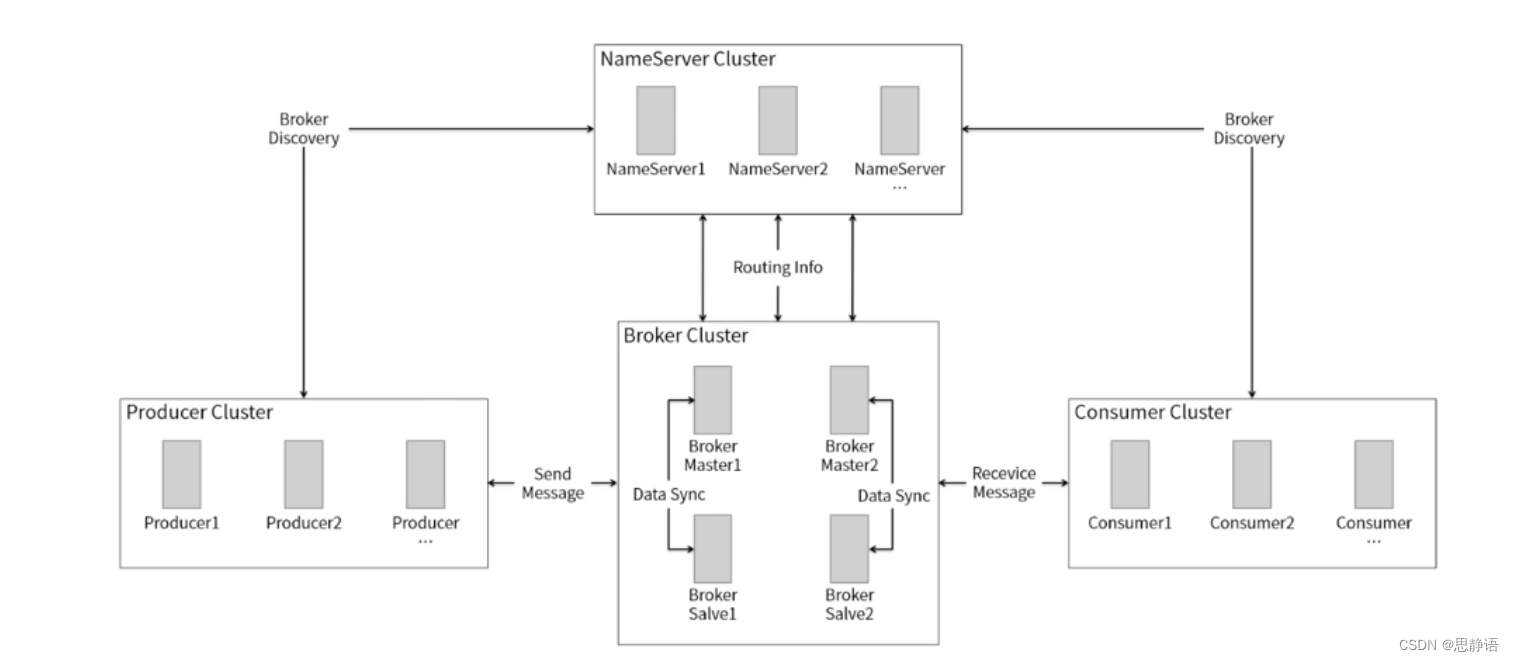
RocketMQ架构详解
文章目录 概述RocketMQ架构rocketmq的工作流程Broker 高可用集群刷盘策略 概述 RocketMQ一个纯java、分布式、队列模型的开源消息中间件,前身是MetaQ,是阿里研发的一个队列模型的消息中间件,后开源给apache基金会成为了apache的顶级开源项目…...

【AI视野·今日NLP 自然语言处理论文速览 第八十二期】Tue, 5 Mar 2024
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 5 Mar 2024 (showing first 100 of 175 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers Key-Point-Driven Data Synthesis with its Enhancement on Mathematica…...

windows 两个服务器远程文件夹同步,支持文件新增文件同步、修改文件同步、删除文件同步,根据文件大小和时间戳判断文件是否修改 python脚本
在Python中实现Windows两个服务器之间的文件夹同步,包括文件新增、修改和删除的同步,可以使用paramiko库进行SSH连接以及SFTP传输,并结合文件大小和时间戳判断文件是否发生过变化。以下是包含删除文件同步逻辑的完整脚本示例: im…...

vite项目修改node_modules
问题详情 在使用某个依赖的时候遇到了bug,提交issue后不想一直等待到作者更新版本,所以寻求临时自己解决 问题解决 在node_modules里找到需要修改的依赖,修改想要修改的代码 修改后记得保存 然后在node_modules里找到.vite文件夹&#x…...

2026奇点大会闭门报告流出:图像描述生成正面临“语义坍缩”危机,这4类业务场景已触发告警
第一章:2026奇点智能技术大会:图像描述生成 2026奇点智能技术大会(https://ml-summit.org) 核心任务与技术演进 图像描述生成(Image Captioning)在2026奇点智能技术大会上被确立为多模态理解的关键落地范式。本届大会展示的最新…...

低门槛语音AI落地:SenseVoice-Small ONNX非技术人员使用指南
低门槛语音AI落地:SenseVoice-Small ONNX非技术人员使用指南 你是不是也觉得语音转文字很麻烦?要么得联网上传录音,担心隐私泄露;要么本地工具配置复杂,一堆命令行看得人头疼;要么识别出来的文字没有标点&…...

【毕设】毕业生实习与就业管理系统
💟博主:程序员俊星:CSDN作者、博客专家、全栈领域优质创作者 💟专注于计算机毕业设计,大数据、深度学习、Java、小程序、python、安卓等技术领域 📲文章末尾获取源码数据库 🌈还有大家在毕设选题…...

【三维重建】【3DGS系列】【深度学习】从概率密度到几何形体:3D高斯椭球的数学构建与可视化
1. 从概率密度到几何形体:3D高斯椭球的数学本质 第一次接触3D高斯泼溅(3DGS)技术时,最让我困惑的就是为什么一个概率分布函数能表示三维几何体。后来在复现论文代码时才发现,这背后的数学之美就藏在多维高斯分布的等概率密度面中。想象一下捏…...

从理论到实践:深入解析Matlab cameraParameters对象及其在相机标定中的应用
1. 相机标定与cameraParameters对象基础 当你第一次接触计算机视觉项目时,相机标定可能是最让你头疼的环节之一。想象一下,你用相机拍摄了一张棋盘格照片,但发现边缘出现了明显的弯曲变形——这就是典型的镜头畸变现象。而cameraParameters对…...

Twisted Trial测试框架终极指南:异步代码单元测试的7个最佳实践
Twisted Trial测试框架终极指南:异步代码单元测试的7个最佳实践 Twisted Trial是Python中最强大的异步单元测试框架,专为测试基于Twisted的事件驱动网络应用程序而设计。作为Twisted框架的官方测试组件,Trial扩展了Python标准库的unittest模…...

DICOM坐标系转换实战:从像素空间到解剖空间的精准映射
1. DICOM坐标系转换的核心概念 第一次接触DICOM影像处理时,我被各种坐标系搞得晕头转向。直到在手术导航项目中踩了几个坑才明白,坐标系转换是医学影像分析的基石。简单来说,DICOM标准定义了三种关键坐标系: 像素坐标系࿱…...

实战教程:星图平台私有化部署Qwen3-VL:30B,实现本地AI多模态能力
实战教程:星图平台私有化部署Qwen3-VL:30B,实现本地AI多模态能力 1. 项目概述与准备工作 1.1 为什么选择Qwen3-VL:30B? Qwen3-VL:30B是目前最强大的开源多模态大模型之一,具备300亿参数规模,能够同时处理文本和图像…...

实战教程:用Python脚本突破百度网盘限速,实现高速下载的终极方案
实战教程:用Python脚本突破百度网盘限速,实现高速下载的终极方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘那蜗牛般的下载速度抓狂…...

如何用ViGEmBus虚拟游戏控制器驱动解决Windows游戏兼容性难题
如何用ViGEmBus虚拟游戏控制器驱动解决Windows游戏兼容性难题 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否遇到过这样的情况:心爱的游戏…...