使用 SPL 高效实现 Flink SLS Connector 下推
作者:潘伟龙(豁朗)
背景
日志服务 SLS 是云原生观测与分析平台,为 Log、Metric、Trace 等数据提供大规模、低成本、实时的平台化服务,基于日志服务的便捷的数据接入能力,可以将系统日志、业务日志等接入 SLS 进行存储、分析;阿里云 Flink 是阿里云基于 Apache Flink 构建的大数据分析平台,在实时数据分析、风控检测等场景应用广泛。阿里云 Flink 原生支持阿里云日志服务 SLS 的 Connector,可以在阿里云 Flink 平台将 SLS 作为源表或者结果表使用。
在阿里云 Flink 配置 SLS 作为源表时,默认会消费 SLS 的 Logstore 数据进行动态表的构建,在消费的过程中,可以指定起始时间点,消费的数据也是指定时间点以后的全量数据;在特定场景中,往往只需要对某类特征的日志或者日志的某些字段进行分析处理,此类需求可以通过 Flink SQL 的 WHERE 和 SELECT 完成,这样做有两个问题:
1)Connector 从源头拉取了过多不必要的数据行或者数据列造成了网络的开销;
2)这些不必要的数据需要在 Flink 中进行过滤投影计算,这些清洗工作并不是数据分析的关注的重点,造成了计算的浪费。
对于这种场景,有没有更好的办法呢?
答案是肯定的,SLS 推出了 SPL 语言, 可以高效的对日志数据的清洗,加工。 这种能力也集成在了日志消费场景,包括阿里云 Flink 中 SLS Connector,通过配置 SLS SPL 即可实现对数据的清洗规则,在减少网络传输的数据量的同时,也可以减少 Flink 端计算消耗。
接下来对 SPL 及 SPL 在阿里云 Flink SLS Connector 中应用进行介绍及举例。
SLS SPL 介绍
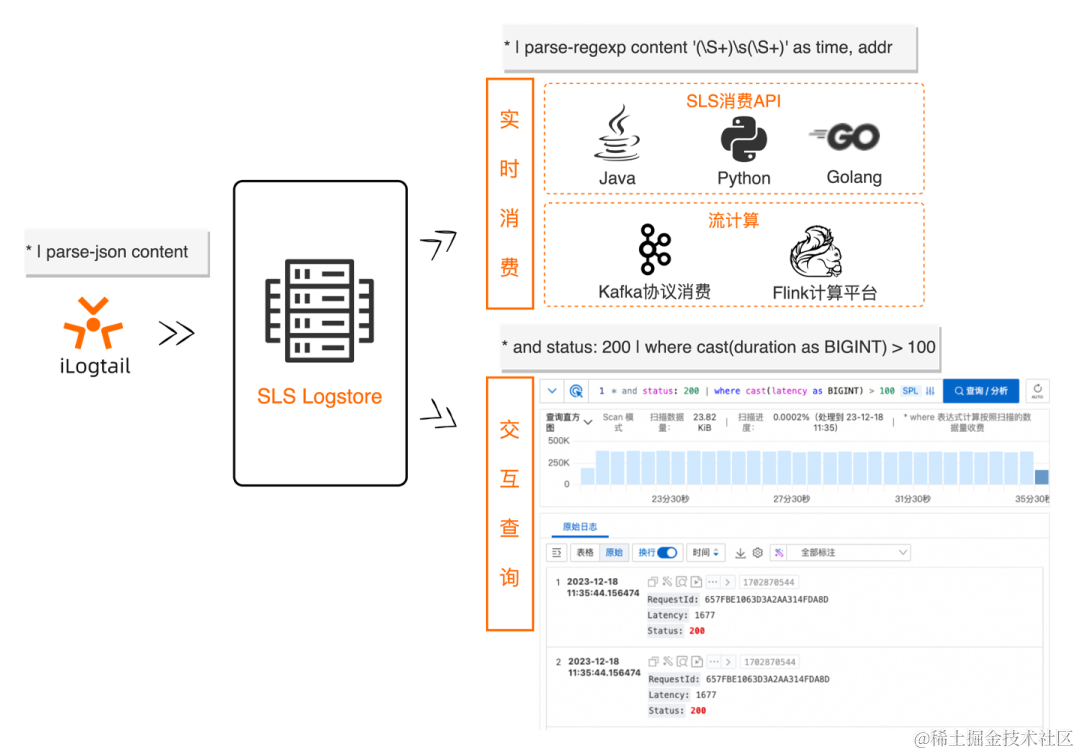
SLS SPL 是日志服务推出的一款针对弱结构化的高性能日志处理语言,可以同时在 Logtail 端、查询扫描、流式消费场景使用,具有交互式、探索式、使用简洁等特点。
SPL 基本语法如下:
<data-source>
| <spl-cmd> -option=<option> -option ... <expression>, ... as <output>, ...
| <spl-cmd> ...
| <spl-cmd> ...
< spl-cmd > 是 SPL 指令,支持行过滤、列扩展、列裁剪、正则取值、字段投影、数值计算、JSON、CSV 等半结构化数据处理,具体参考 SPL 指令 [ 1] 介绍,具体来说包括:
结构化数据 SQL 计算指令:
支持行过滤、列扩展、数值计算、SQL 函数调用
- extend 通过 SQL 表达式计算结果产生新字段
- where 根据 SQL 表达式计算结果过滤数据条目
*
| extend latency=cast(latency as BIGINT)
| where status='200' AND latency>100
字段操作指令:
支持字段投影、字段重名、列裁剪
- project 保留与给定模式相匹配的字段、重命名指定字段
- project-away 保留与给定模式相匹配的字段、重命名指定字段
- project-rename 重命名指定字段,并原样保留其他所有字段
*
| project-away -wildcard "__tag__:*"
| project-rename __source__=remote_addr
非结构化数据提取指令:
支持 JSON、正则、CSV 等非结构化字段值处理
- parse-regexp 提取指定字段中的正则表达式分组匹配信息
- parse-json 提取指定字段中的第一层 JSON 信息
- parse-csv 提取指定字段中的 CSV 格式信息
*
| parse-csv -delim='^_^' content as time, body
| parse-regexp body, '(\S+)\s+(\w+)' as msg, user
SPL 在 Flink SLS Connector 中的原理介绍
阿里云 Flink 支持 SLS Connector,通过 SLS Connector 实时拉取 SLS 中 Logstore 的数据,分析后的数据也可以实时写入 SLS,作为一个高性能计算引擎,Flink SQL 也在越来越广泛的应用在 Flink 计算中,借助 SQL 语法可以对结构化的数据进行分析。
在 SLS Connector 中,可以配置日志字段为 Flink SQL 中的 Table 字段,然后基于 SQL 进行数据分析;在未支持 SPL 配置之前,SLS Connector 会实时消费全量的日志数据到 Flink 计算平台,当前消费方式有如下特点:
- 在 Flink 中计算的往往不需要所有的日志行,比如在安全场景中,可能仅需要符合某种特征的数据,需要进行日志进行过滤,事实上不需要的日志行也会被拉取,造成网络带宽的浪费。
- 在 Flink 中计算的一般是特定的字段列,比如在 Logstore 中有 30 个字段,真正需要在 Flink 计算的可能仅有 10 个字段,全字段的拉取造成了网络带宽的浪费。
在以上场景中,可能会增加并不需要的网络流量和计算开销,基于这些特点,SLS 将 SPL 的能力集成到 SLS Connector 的新版本中,可以实现数据在到达 Flink 之前已经进行了行过滤和列裁剪,这些预处理能力内置在 SLS 服务端,可以达到同时节省网络流量与 Flink 计算(过滤、列裁剪)开销的目的。
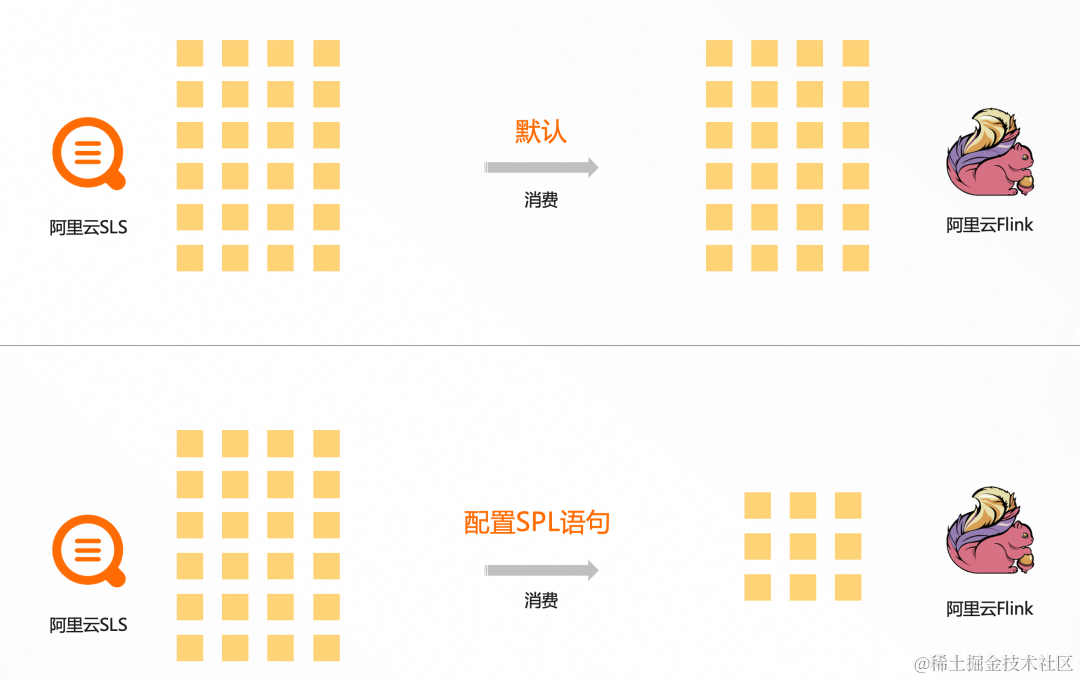
原理对比
- 未配置 SPL 语句时:Flink 会拉取 SLS 的全量日志数据(包含所有列、所有行)进行计算,如图 1。
- 配置 SPL 语句时:SPL 可以对拉取到的数据如果 SPL 语句包含过滤及列裁剪等,Flink 拉取到的是进行过滤和列裁剪后部分数据进行计算,如图 2。
在 Flink 中使用 SLS SPL
接下来以一个 Nginx 日志为例,来介绍基于 SLS SPL 的能力来使用 Flink。为了便于演示,这里在 Flink 控制台配置 SLS 的源表,然后开启一个连续查询以观察效果。在实际使用过程中,可以直接修改 SLS 源表,保留其余分析和写出逻辑。
接下来介绍下阿里云 Flink 中使用 SPL 实现行过滤与列裁剪功能。
在 SLS 准备数据
- 开通 SLS,在 SLS 创建 Project,Logstore,并创建具有消费 Logstore 的权限的账号 AK/SK。
- 当前 Logstore 数据使用 SLS 的的 SLB 七层日志模拟接入方式产生模拟数据,其中包含 10 多个字段。
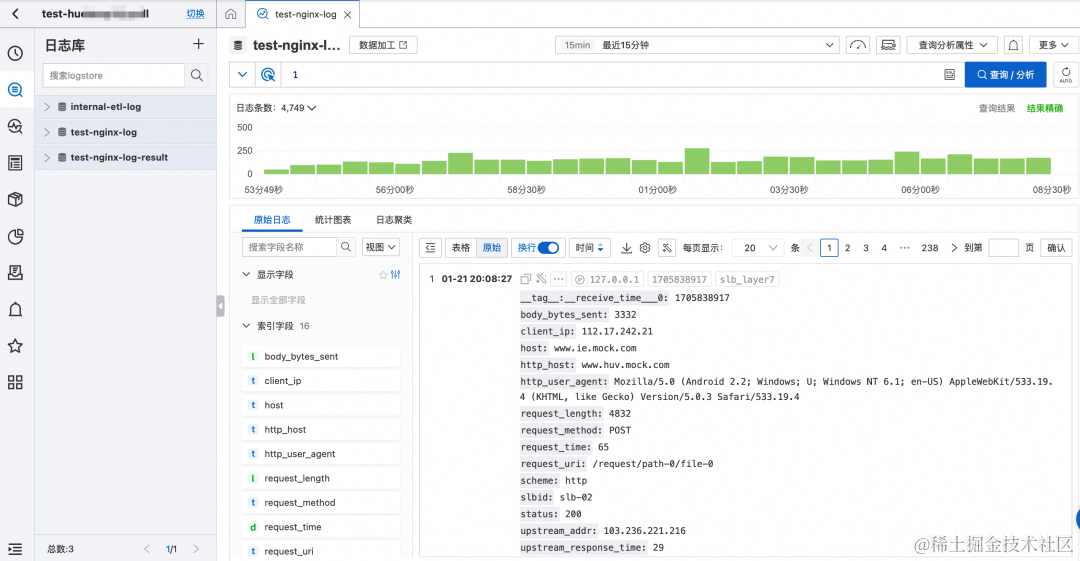
模拟接入会持续产生随机的日志数据,日志内容示例如下:
{"__source__": "127.0.0.1","__tag__:__receive_time__": "1706531737","__time__": "1706531727","__topic__": "slb_layer7","body_bytes_sent": "3577","client_ip": "114.137.195.189","host": "www.pi.mock.com","http_host": "www.cwj.mock.com","http_user_agent": "Mozilla/5.0 (Windows NT 6.2; rv:22.0) Gecko/20130405 Firefox/23.0","request_length": "1662","request_method": "GET","request_time": "31","request_uri": "/request/path-0/file-3","scheme": "https","slbid": "slb-02","status": "200","upstream_addr": "42.63.187.102","upstream_response_time": "32","upstream_status": "200","vip_addr": "223.18.47.239"
}
Logstore 中 slbid 字段有两种值:slb-01 和 slb-02,对 15 分钟的日志数据进行 slbid 统计,可以发现 slb-01 与 slb-02 数量相当。
行过滤场景
在数据处理中过滤数据是一种常见需求,在 Flink 中可以使用 filter 算子或者 SQL 中的 where 条件进行过滤,使用非常方便;但是在 Flink 使用 filter 算子,往往意味着数据已经通过网络进入 Flink 计算引擎中,全量的数据会消耗着网络带宽和 Flink 的计算性能,这种场景下,SLS SPL 为 Flink SLS Connector 提供了一种支持过滤“下推”的能力,通过配置 SLS Connector 的 query 语句中,过滤条件,即可实现过滤条件下推。避免全量数据传输和全量数据过滤计算。

创建 SQL 作业
在阿里云 Flink 控制台创建一个空白的 SQL 的流作业草稿,点击下一步,进入作业编写。
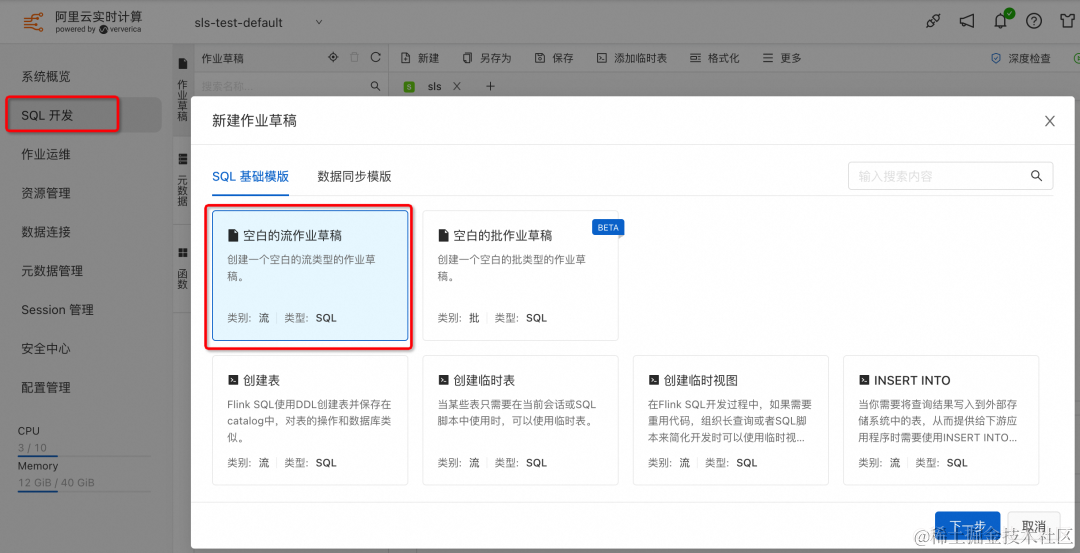
在作业草稿中输入如下创建临时表的语句:
CREATE TEMPORARY TABLE sls_input(request_uri STRING,scheme STRING,slbid STRING,status STRING,`__topic__` STRING METADATA VIRTUAL,`__source__` STRING METADATA VIRTUAL,`__timestamp__` STRING METADATA VIRTUAL,__tag__ MAP<VARCHAR, VARCHAR> METADATA VIRTUAL,proctime as PROCTIME()
) WITH ('connector' = 'sls','endpoint' ='cn-beijing-intranet.log.aliyuncs.com','accessId' = '${ak}','accessKey' = '${sk}','starttime' = '2024-01-21 00:00:00','project' ='${project}','logstore' ='test-nginx-log','query' = '* | where slbid = ''slb-01'''
);
- 这里为了演示方便,仅设置 request_uri、scheme、slbid、status 和一些元数据字段作为表字段。
- a k 、 {ak}、 ak、{sk}、${project} 替换为具有 Logstore 消费权限的账号。
- endpoint:填写同地域的 SLS 的私网地址。
- query:填写 SLS 的 SPL 语句,这里填写了 SPL 的过滤语句:* | where slbid = ‘‘slb-01’’,注意在阿里云 Flink 的 SQL 作业开发中,字符串需要使用英文单引号进行转义。
连续查询及效果
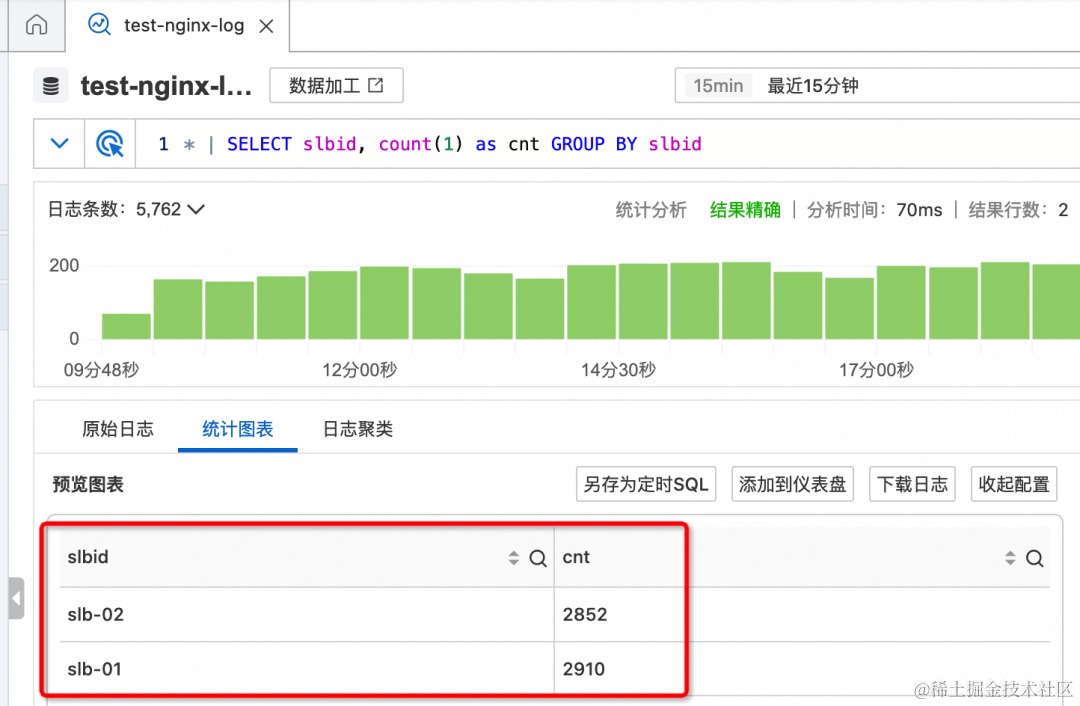
在作业中输入分析语句,按照 slbid 进行聚合查询,动态查询会根据日志的变化,实时刷新数字。
SELECT slbid, count(1) as slb_cnt FROM sls_input GROUP BY slbid
点击右上角调试按钮,进行调试,可以看到结果中 slbid 的字段值,始终是 slb-01。
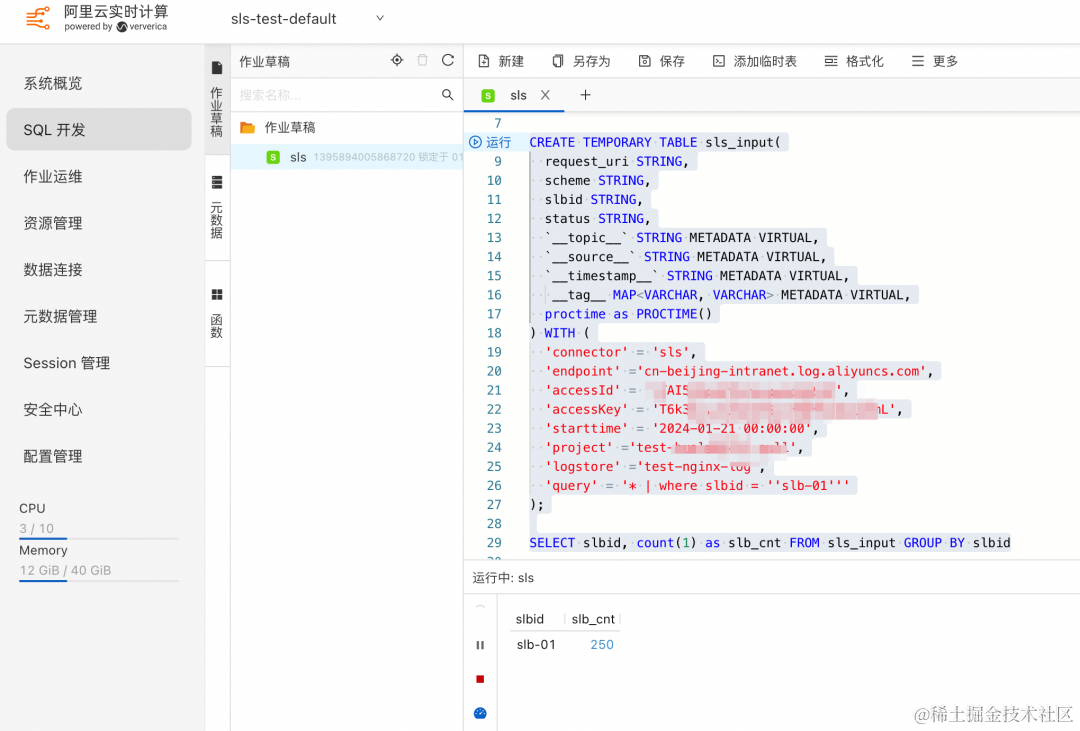
可以看出设置了 SPL 语句后,sls_input 仅包含 slbid=‘slb-01’ 的数据,其他不符合条件的数据被过滤掉了。
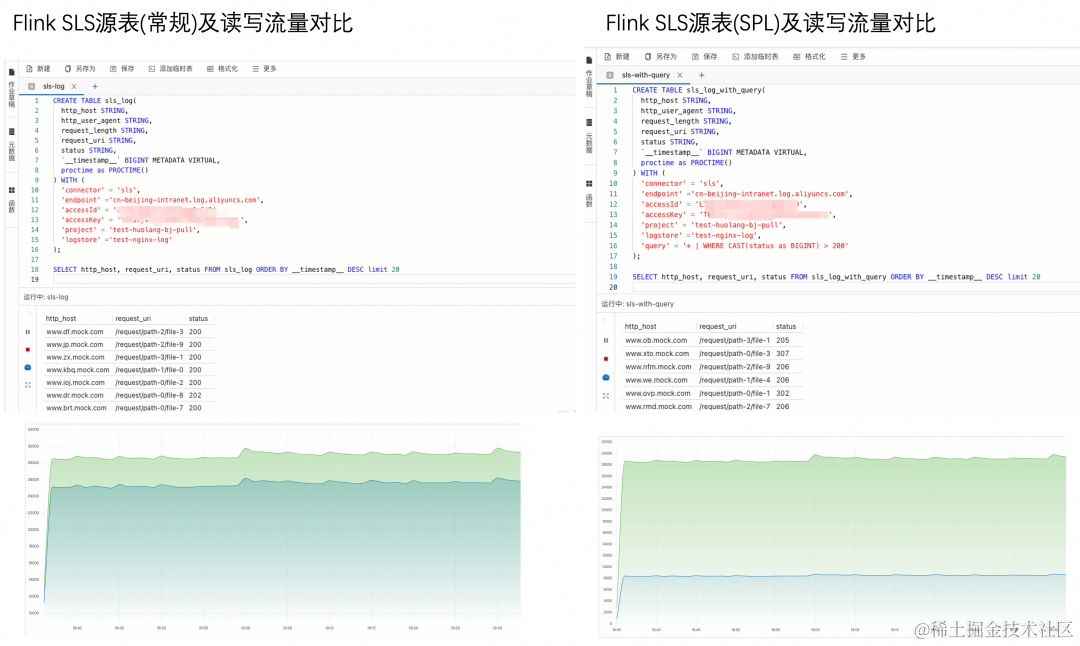
流量对比
使用 SPL 后,可以看出在 SLS 的写流量不变的情况下,Flink 对 SLS 的读流量有大幅度下降;同时在过滤占主要很多 Flink CU 的场景下,经过过滤后,Flink CU 也会有相应的降低。
列裁剪场景
在数据处理中列裁剪也是一种常见需求,在原始数据中,往往会有全量的字段,但是实际的计算只需要特定的字段;类似需要在 Flink 中可以使用 project 算子或者 SQL 中的 select 进行列裁剪与变换,使用 Flink 使用 project 算子,往往意味着数据已经通过网络进入 Flink 计算引擎中,全量的数据会消耗着网络带宽和 Flink 的计算性能,这种场景下,SLS SPL 为 Flink SLS Connector 提供了一种支持投影下推的能力,通过配置 SLS Connector 的 query 参数,即可实现投影字段下推。避免全量数据传输和全量数据过滤计算。
创建 SQL 作业
创建步骤同行过滤场景,在作业草稿中输入如下创建临时表的语句,这里 query 参数配置进行了修改,在过滤的基础上增加了投影语句,可以实现从 SLS 服务端仅拉取特定字段的内容。
CREATE TEMPORARY TABLE sls_input(request_uri STRING,scheme STRING,slbid STRING,status STRING,`__topic__` STRING METADATA VIRTUAL,`__source__` STRING METADATA VIRTUAL,`__timestamp__` STRING METADATA VIRTUAL,__tag__ MAP<VARCHAR, VARCHAR> METADATA VIRTUAL,proctime as PROCTIME()
) WITH ('connector' = 'sls','endpoint' ='cn-beijing-intranet.log.aliyuncs.com','accessId' = '${ak}','accessKey' = '${sk}','starttime' = '2024-01-21 00:00:00','project' ='${project}','logstore' ='test-nginx-log','query' = '* | where slbid = ''slb-01'' | project request_uri, scheme, slbid, status, __topic__, __source__, "__tag__:__receive_time__"'
);
为了效果,下面分行展示语句中配置,在 Flink 语句中任然需要单行配置。
*
| where slbid = ''slb-01''
| project request_uri, scheme, slbid, status, __topic__, __source__, "__tag__:__receive_time__"
上面使用了 SLS SPL 的管道式语法来实现数据过滤后投影的操作,类似 Unix 管道,使用|符号将不同指令进行分割,上一条指令的输出作为下一条指令的输入,最后的指令的输出表示整个管道的输出。
连续查询及效果
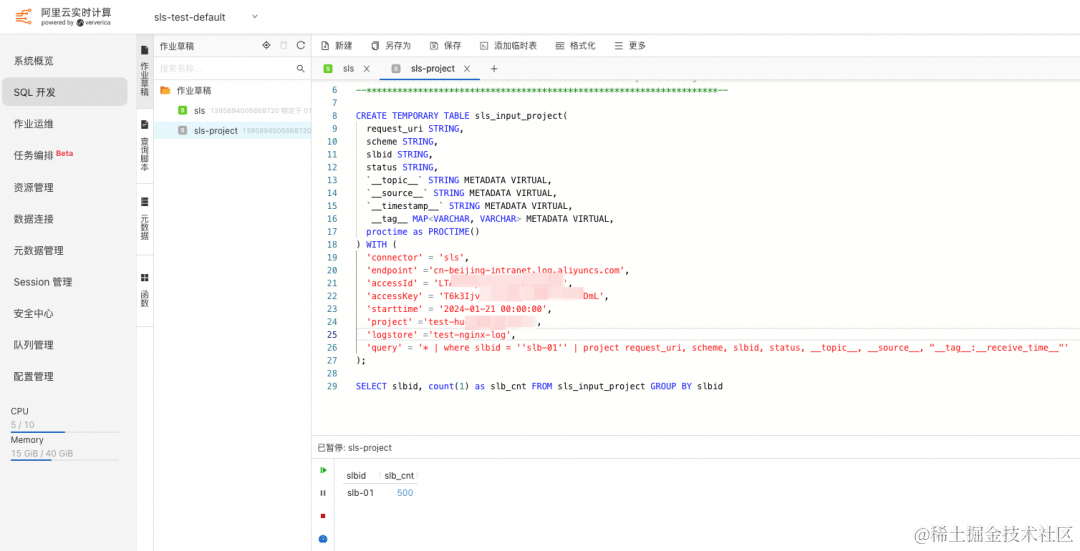
在作业中输入分析语句,可以看到,结果与行过滤场景结果类似。
SELECT slbid, count(1) as slb_cnt FROM sls_input_project GROUP BY slbid
🔔 注意: 这里与行过滤不同的是,上面的行过滤场景会返回全量的字段,而当前的语句令 SLS Connector 只返回特定的字段,再次减少了数据的网络传输。
SPL 还可以做什么
- 上述实例中演示了使用 SLS SPL 的过滤和投影功能来实现 SLS Connector 的“下推”功能,可以有效地减少网络流量和 Flink CU 的使用。可以避免在 Flink 进行计算之前,进行额外的过滤和投影计算消耗。
- SLS SPL 的功能不止于过滤与投影,SLS SPL 完整支持的语法可以参考文档:SPL 指令 [ 1] 。同时,SPL管道式语法已全面支持在 Flink Connector 中进行配置。
- SLS SPL 支持对于数据进行预处理,比如正则字段、JSON 字段,CSV 字段展开;数据格式转换,列的增加和减少;过滤等。除了用于消费场景,在 SLS 的 Scan 模式与采集端都会应用场景,以便用户在采集端、消费端都可以使用 SPL 的能力。
相关链接:
[1] SPL 指令
https://help.aliyun.com/zh/sls/user-guide/spl-instruction?spm=a2c4g.11186623.0.0.33f35a3dl8g8KD
[2] 日志服务概述
https://help.aliyun.com/zh/sls/product-overview/what-is-log-service
[3] SPL 概述
https://help.aliyun.com/zh/sls/user-guide/spl-overview
[4] 阿里云 Flink Connector SLS
https://help.aliyun.com/zh/flink/developer-reference/log-service-connector
相关文章:
使用 SPL 高效实现 Flink SLS Connector 下推
作者:潘伟龙(豁朗) 背景 日志服务 SLS 是云原生观测与分析平台,为 Log、Metric、Trace 等数据提供大规模、低成本、实时的平台化服务,基于日志服务的便捷的数据接入能力,可以将系统日志、业务日志等接入 …...
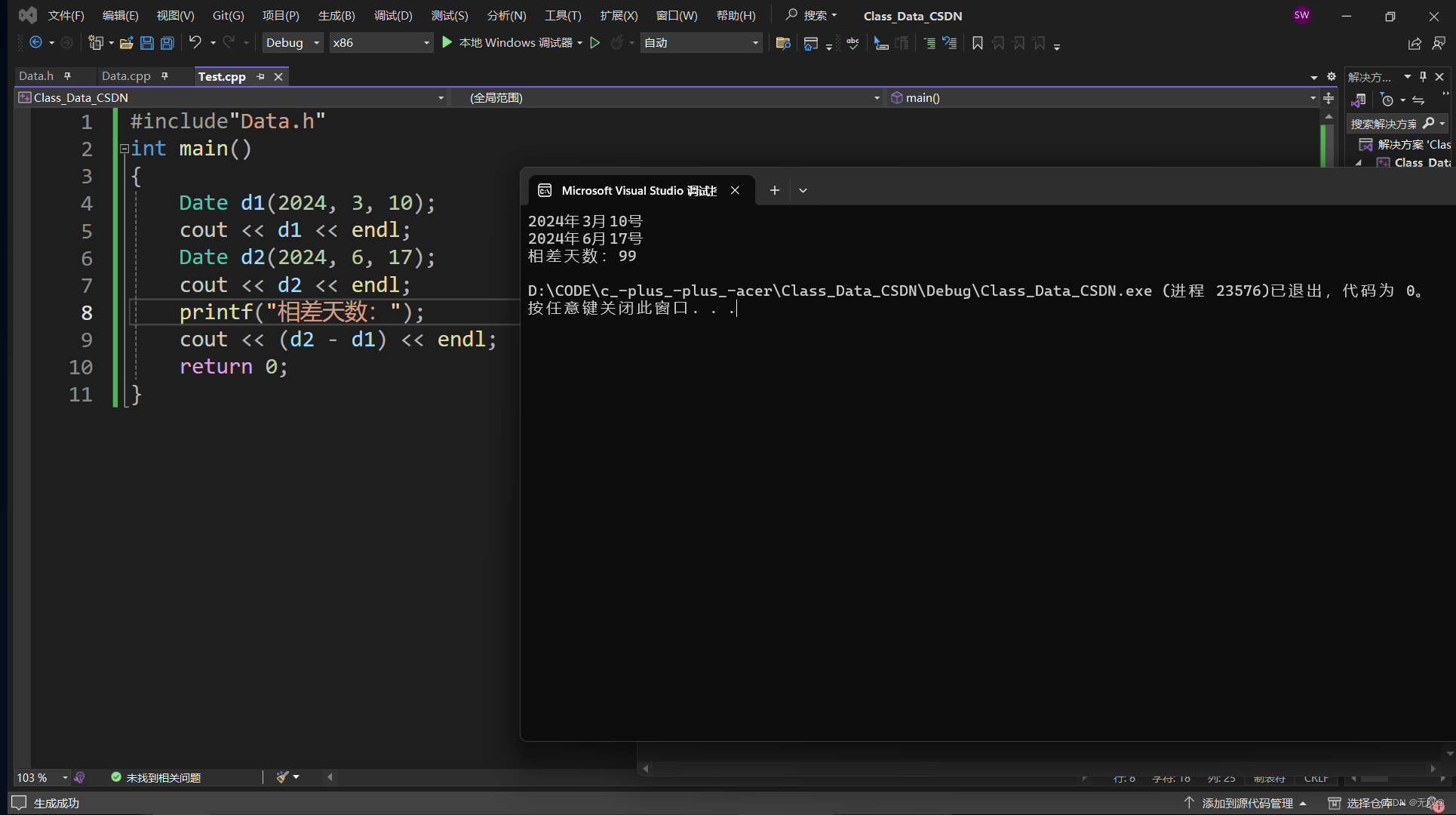
《日期类》的模拟实现
目录 前言: 头文件类与函数的定义Date.h 实现函数的Date.cpp 测试Test.cpp 运行结果: 前言: 我们在前面的两章初步学习认识了《类与对象》的概念,接下来我们将实现一个日期类,是我们的知识储备更加牢固。 头文件…...
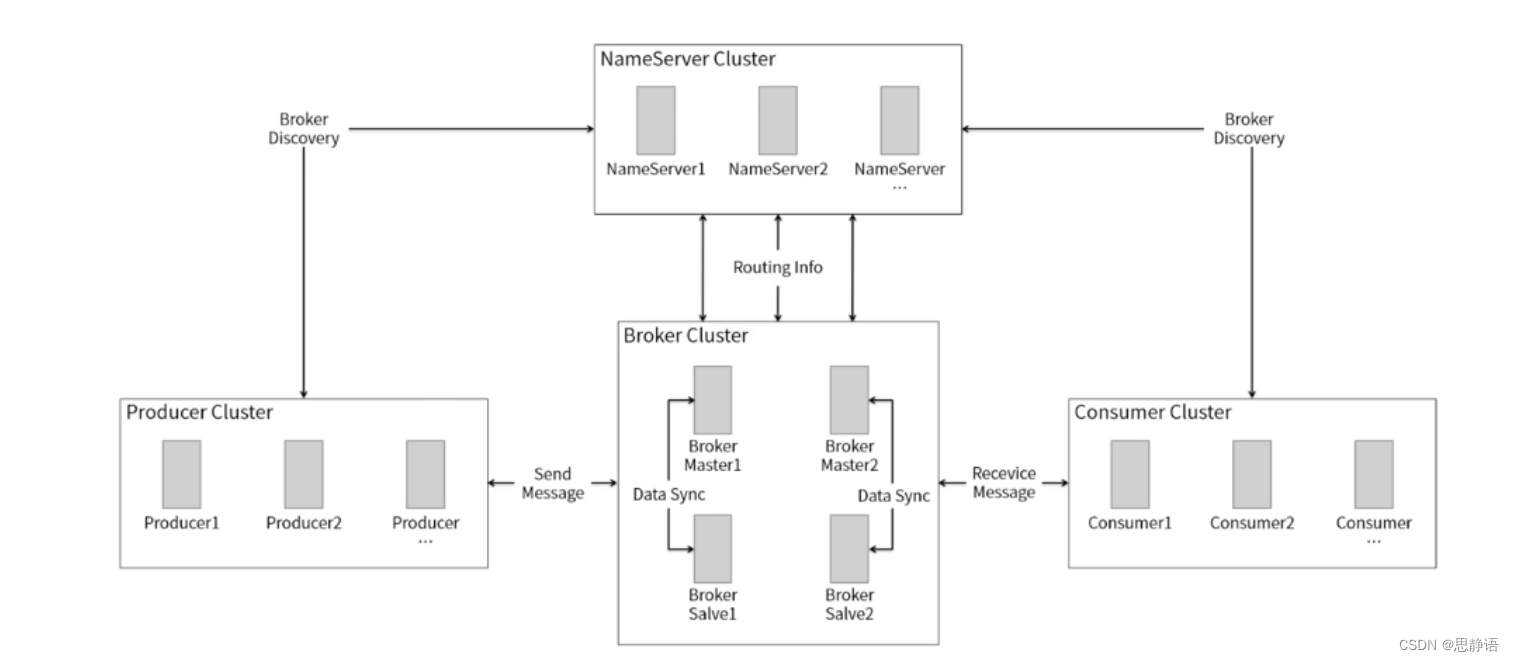
RocketMQ架构详解
文章目录 概述RocketMQ架构rocketmq的工作流程Broker 高可用集群刷盘策略 概述 RocketMQ一个纯java、分布式、队列模型的开源消息中间件,前身是MetaQ,是阿里研发的一个队列模型的消息中间件,后开源给apache基金会成为了apache的顶级开源项目…...

【AI视野·今日NLP 自然语言处理论文速览 第八十二期】Tue, 5 Mar 2024
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 5 Mar 2024 (showing first 100 of 175 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers Key-Point-Driven Data Synthesis with its Enhancement on Mathematica…...

windows 两个服务器远程文件夹同步,支持文件新增文件同步、修改文件同步、删除文件同步,根据文件大小和时间戳判断文件是否修改 python脚本
在Python中实现Windows两个服务器之间的文件夹同步,包括文件新增、修改和删除的同步,可以使用paramiko库进行SSH连接以及SFTP传输,并结合文件大小和时间戳判断文件是否发生过变化。以下是包含删除文件同步逻辑的完整脚本示例: im…...

vite项目修改node_modules
问题详情 在使用某个依赖的时候遇到了bug,提交issue后不想一直等待到作者更新版本,所以寻求临时自己解决 问题解决 在node_modules里找到需要修改的依赖,修改想要修改的代码 修改后记得保存 然后在node_modules里找到.vite文件夹&#x…...
NLP神器Transformers入门简单概述
在这篇博客中,我们将深入探索 🤗 Transformers —— 一个为 PyTorch、TensorFlow 和 JAX 设计的先进机器学习库。🤗 Transformers 提供了易于使用的 API 和工具,使得下载和训练前沿的预训练模型变得轻而易举。利用预训练模型不仅能减少计算成本和碳足迹,还能节省从头训练…...

微信小程序-wxml语法
介绍 WXML(WeiXin Markup Language)是框架设计的一套标签语言,可以进行页面布局,声明事件,数据绑定,条件判断。 语法 数据绑定 <view> {{message}} </view>// page.js Page({data: { // 状态…...

网络层转发分组的过程
分组转发都是基于目的主机所在网络的,这事因为互联网上的网络数远小于主机数,这样可以极大的压缩转发表的大小。当分组到达路由器后,路由器根据目的IP地址的网络地址前缀查找转发表,确定下一跳应当到哪个有路由器。因此࿰…...
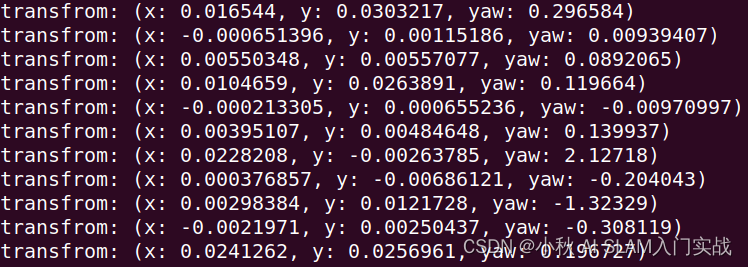
计算两帧雷达数据之间的变换矩阵
文章目录 package.xmlCMakeLists.txtpoint_cloud_registration.cc运行结果 package.xml <?xml version"1.0"?> <package format"2"><name>point_cloud_registration</name><version>0.0.0</version><descriptio…...

2. gin中间件注意事项、路由拆分与注册技巧
文章目录 一、中间件二、Gin路由简介1、普通路由2、路由组 三、路由拆分与注册1、基本的路由注册2、路由拆分成单独文件或包3、路由拆分成多个文件4、路由拆分到不同的APP 一、中间件 在日常工作中,经常会有一些计算接口耗时和限流的操作,如果每写一个接…...

R语言复现:如何利用logistic逐步回归进行影响因素分析?
Logistic回归在医学科研、特别是观察性研究领域,无论是现况调查、病例对照研究、还是队列研究中都是大家经常用到的统计方法,而在影响因素研究筛选自变量时,大家习惯性用的比较多的还是先单后多,P<0.05纳入多因素研究&…...
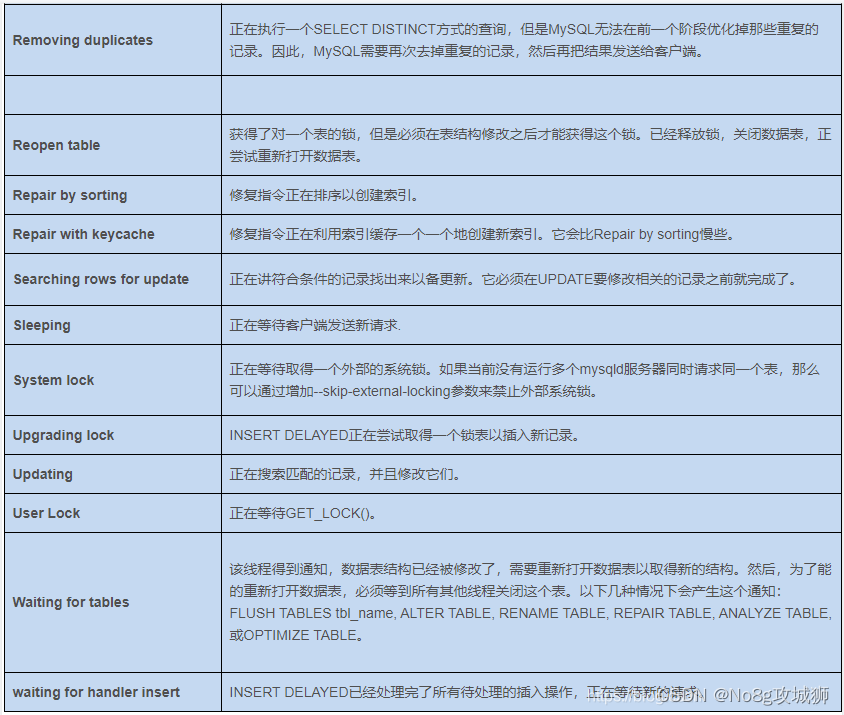
【MySQL使用】show processlist 命令详解
show processlist 命令详解 一、命令含义二、命令返回参数三、Command值解释四、State值解释五、参考资料 一、命令含义 对于一个MySQL连接,或者说一个线程,任何时刻都有一个状态,该状态表示了MySQL当前正在做什么。SHOW PROCESSLIST 命令的…...
分类算法(Classification algorithms)
逻辑回归(logical regression): 逻辑回归这个名字听上去好像应该是回归算法的,但其实这个名字只是在历史上取名有点区别,但实际上它是一个完全属于是分类算法的。 我们为什么要学习它呢?在用我们的线性回归时会遇到一…...

深度学习-Softmax 回归 + 损失函数 + 图片分类数据集
Softmax 回归 损失函数 图片分类数据集 1 softmax2 损失函数1均方L1LossHuber Loss 3 图像分类数据集4 softmax回归的从零开始实现 1 softmax Softmax是一个常用于机器学习和深度学习中的激活函数。它通常用于多分类问题,将一个实数向量转换为概率分布。Softmax函…...
)
分布式锁从0到1落地实现01(mysql/redis/zk)
1 准备数据库表 CREATE TABLE user ( id bigint(20) NOT NULL COMMENT 主键ID, name varchar(30) DEFAULT NULL COMMENT 姓名, age int(11) DEFAULT NULL COMMENT 年龄, email varchar(50) DEFAULT NULL COMMENT 邮箱, PRIMARY KEY (id) ) ENGINEInnoDB DEFAULT CHARSETutf8;I…...

安全运营方案的基本框架和关键要素
一、前言 阐述安全运营方案的目的和重要性。强调安全运营与组织整体战略目标的关联。 二、安全运营原则 确立安全运营的基本原则,如保密性、完整性和可用性。明确安全责任划分,确保各部门和人员履行安全职责。 三、安全风险评估与管理 进行全面的安…...
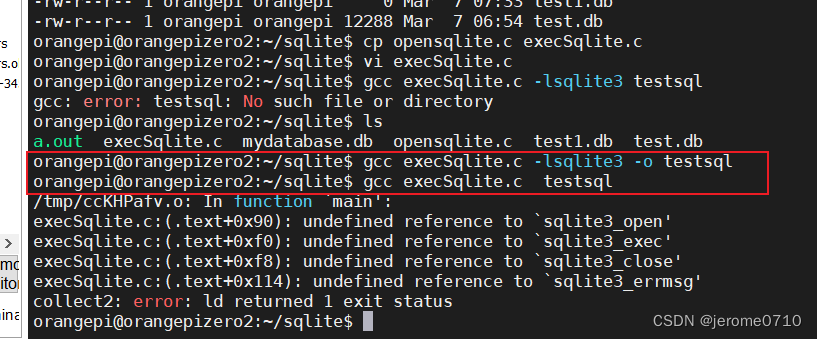
用C语言执行SQLite3的gcc编译细节
错误信息: /tmp/cc3joSwp.o: In function main: execSqlite.c:(.text0x100): undefined reference to sqlite3_open execSqlite.c:(.text0x16c): undefined reference to sqlite3_exec execSqlite.c:(.text0x174): undefined reference to sqlite3_close execSqlit…...
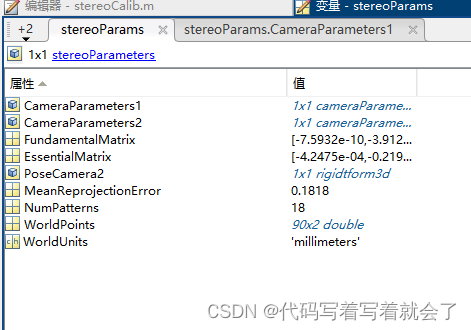
matlab双目相机标定-需要什么参数、怎么获得
相机标定目的:获得相机内参、外参、畸变系数,摄像头的内参(f,1/dx,1/dy,cx,cy)、畸变参数(k1,k2,k3,p1,p1)和外参(R,t),用于接下来的双目校正和深度图生成从而实现二维到三维的转换。 相机标定方法:opencv 双目相机标定以及立体…...
)
大型语言模型的智能助手:检索增强生成(RAG)
背景 在人工智能的浪潮中,大型语言模型(LLMs)如GPT系列和LLama系列在自然语言处理(NLP)领域取得了显著成就。它们能够完成复杂的语言任务,如文本摘要、机器翻译、甚至创作诗歌。然而,这些模型在…...

War3地图编辑器进阶:利用炮火攻击实现混乱伤害技能的完整指南
War3地图编辑器进阶:炮火攻击实现混乱伤害技能的深度解析 在魔兽争霸3地图编辑器的世界里,创造独特技能是每位地图作者的必修课。传统技能往往受限于固定伤害值或特定攻击类型,而今天我们要探讨的是一种突破常规的方法——利用炮火攻击地面机…...

Java的java.util.random.RandomGeneratorFactory随机数生成器工厂选择
Java中的随机数生成器工厂选择指南 在现代软件开发中,高质量的随机数生成对密码学、模拟测试和游戏开发等领域至关重要。Java在JDK 17中引入了java.util.random.RandomGeneratorFactory,为开发者提供了更灵活、高效的随机数生成器选择机制。本文将围绕该…...

Python自动化实现自动关机重启,告别加班后忘关电脑
不知道你有没有遇到过这种情况:下班了,电脑还在跑着下载或者编译,结果人走了电脑开了一整夜。或者临时有事要离开,想让电脑跑完任务自动关机。 今天分享一个我写了很久一直在用的自动化脚本——Python定时关机重启管理工具,支持: 定时关机 延迟关机 定时重启 取消关机 任…...

开超市做门头都需要注意那几点
开超市的门头核心就一件事:远看醒目、近看放心、路人一眼知道是超市、城管物业都能过。 一、风格与定位(决定档次) 社区超市 简洁、干净、亲民、明亮 关键词:生活超市、便民超市、生鲜超市、便利店 生鲜 / 综合超市 偏生活化&…...

【实战解析】Learn2Reg2021 Task 01:3D腹部MR-CT多模态配准挑战与数据集应用
1. 理解3D腹部MR-CT多模态配准的核心挑战 第一次接触医学图像配准的朋友可能会问:为什么要把CT和MRI这两种扫描结果对齐?简单来说,CT像X光片一样擅长显示骨骼结构,而MRI对软组织成像更清晰。当医生需要同时参考两种影像做手术规划…...

Linux IO编程 搭建开发环境 学习笔记
虚拟机网络模式配置 Ubuntu 联网时,稳定的网络连接是基础前提!虚拟机里的这些网络模式(桥接、NAT、仅主机、自定义、LAN段),决定了 Ubuntu 虚拟机如何跟主机、外部网络打通;选对模式,既能让 Ubuntu 联网装软件,又能让主…...

NR - Slot Configuration: Understanding TDD-UL-DL Patterns and Flexible Symbols
1. 5G NR时隙配置基础:TDD模式的核心逻辑 想象一下双向车道上的红绿灯控制系统——这就是5G NR中TDD(时分双工)模式的基本工作原理。在无线通信系统中,上下行资源分配就像车道的方向切换,需要精确的时间控制。我参与过…...
,Anthropic5大架构入门到精通,看这篇就够了!)
多智能体搭建基础教程(非常详细),Anthropic5大架构入门到精通,看这篇就够了!
写在前面 单个智能体对于长推理、复杂任务的完成率有限,但是面对多智能体系统不知道如何选择运行模型,Anthropic写了篇如何选择多智能体方案的文章,下面是全文。 Anthropic发现,部分团队在选择模式时,往往更看重“技…...

AXI协议深度解析:非对齐传输的实现与优化策略
1. 非对齐传输的本质与挑战 第一次接触AXI协议的非对齐传输时,我盯着波形图看了整整三天才恍然大悟。所谓非对齐传输,就像搬家时遇到家具尺寸和房门宽度不匹配的情况——你的32位数据包想从0x1002这个"门框"挤进去,但标准对齐地址…...

STM32新手必看:Simulink+STM32CubeMX联合生成串口代码的5个常见坑点
STM32开发实战:Simulink与STM32CubeMX联合开发中的串口通信避坑指南 当Simulink的算法仿真遇上STM32CubeMX的硬件抽象层配置,这种强强联合的开发模式正在改变嵌入式开发的效率边界。但理想很丰满,现实却很骨感——我第一次尝试用这对组合生成…...