数据结构与算法:链式二叉树
上一篇文章我们结束了二叉树的顺序存储,本届内容我们来到二叉树的链式存储!
链式二叉树
- 1.链式二叉树的遍历
- 1.1二叉树的前序,中序,后序遍历
- 1.2 三种遍历方法代码实现
- 2. 获取相关个数
- 2.1获取节点个数
- 2.2获取叶节点个数
- 2.3 获取树的高度
- 2.4 计算第K层节点个数
- 3.寻找某个节点
- 4.用前序遍历建造一个二叉树
- 5.二叉树的销毁
- 6.链式二叉树的层序遍历
- 7.判断是否为完全二叉树
1.链式二叉树的遍历
首先我们定义二叉树节点内容:
typedef int BTDataType;typedef struct BinaryTreeNode
{BTDataType data;struct BinartTreeNode* left;struct BinartTreeNode* right;
}TreeNode;
每个节点包含两个指针,指向左子树和右子树
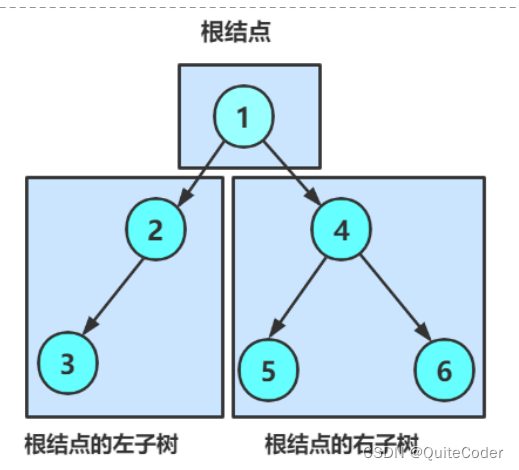
左右子树的节点又可以细分为:根,左子树,右子树
1.1二叉树的前序,中序,后序遍历
前序遍历、中序遍历和后序遍历。这些遍历方式指的是节点访问的顺序。
- 前序遍历:在前序遍历中,我们首先访问根节点,然后递归地进行左子树的前序遍历,接着递归地进行右子树的前序遍历。
- 中序遍历:中序遍历中,我们首先递归地进行左子树的中序遍历,然后访问根节点,最后递归地进行右子树的中序遍历。
- 后序遍历:后序遍历中,我们首先递归地进行左子树的后序遍历,然后递归地进行右子树的后序遍历,最后访问根节点。
我们以一颗树为例来展开讨论
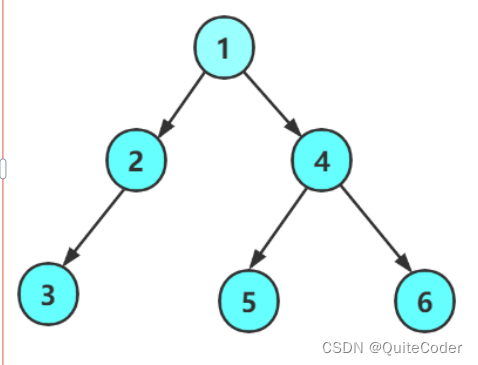
首先讨论前序遍历:
在前序遍历中,我们首先访问根节点,然后是左子树,最后是右子树。
对于上述树的前序遍历,遍历顺序将是:
- 访问根节点 1
- 访问左子节点 2
- 访问左子节点 2 的左子节点 3
- 左子节点3的左子树为空,返回到3
- 访问完3的左子树访问3的右子树,为空,返回到3
- 2的左子树访问完,访问2的右子树,为空,返回到2
- 1的左子树访问完成,回到1访问右子树4
- 访问4的左子树5,再访问5的左,5的左为空,则返回,访问5的右,再返回到5
- 4的左子树遍历完成,访问右子树6,6的左右都为空,访问结束
如果用N来代表空,我们可以表示出访问顺序:
1 2 3 N N N 4 5 N N 6 N N
接下来讨论中序遍历
在中序遍历中,我们首先遍历左子树,然后访问根节点,最后遍历右子树
遍历顺序:
- 首先访问左子树,1的左子树2,再到2的左子树3,3的左子树为NULL,访问空,返回到三,再访问节点3,根访问后到右子树NULL,所以开始访问顺序为:
N 3 N
- 访问完2的左子树,再按照顺序访问根节点2,再访问2的右子树N
N 3 N 2 N
- 访问完1的左子树,访问节点1,再访问1的右子树,而右子树4部分优先访问左子树,所以先访问到5的左子树NULL,再访问5节点和5的右子树NULL
N 3 N 2 N 1 N 5 N
- 访问完4的左子树,访问根节点4,再访问4的右子树,右子树优先访问左子树部分,即6的左子树NULL,再到6节点,最后访问6的右子树NULL
N 3 N 2 N 1 N 5 N 4 N 6 N
最后我们来看后序遍历:
- 首先访问1的左子树,在子树中,首先访问 2 的左子树,3的左子树为空NULL,访问后访问3的右子树NULL,再访问根节点3
N N 3
- 访问完2的左子树后,访问2的右子树NULL,再访问节点2
N N 3 N 2
- 访问完1的左子树,再访问1的右子树,子树中,先访问4的左子树,5组成的子树部分,先访问5的左子树NULL,再访问5的右子树NULL,最后访问根节点5
N N 3 N 2 N N 5
- 4的左子树访问完成后,访问4的右子树,子树部分6,先访问6的左右NULL,再访问根节点6
N N 3 N 2 N N 5 N N 6
- 4的左右子树访问完成,访问根节点4
- 1的左右子树访问完成,访问根节点1
N N 3 N 2 N N 5 N N 6 4 1
1.2 三种遍历方法代码实现
接下来我们硬代码构造一个上图的树,来完成我们三种遍历方式的代码
TreeNode* CreatTreeNode(int x)
{TreeNode* node = (TreeNode*)malloc(sizeof(TreeNode));node->data = x;node->left = NULL;node->right = NULL;return node;
}
TreeNode* FCreatTree()
{TreeNode* node1 = CreatTreeNode(1);TreeNode* node2 = CreatTreeNode(2);TreeNode* node3 = CreatTreeNode(3);TreeNode* node4 = CreatTreeNode(4);TreeNode* node5 = CreatTreeNode(5);TreeNode* node6 = CreatTreeNode(6);node1->left = node2;node1->right = node4;node2->left = node3;node4->left = node5;node4->right = node6;return node1;
}
在上述三种方法的讨论中我们可以知道,三种遍历是用递归方法来完成的
前序遍历,首先访问当前节点(根节点),然后递归地进行左子树的前序遍历,最后递归地进行右子树的前序遍历
代码如下:
void PrevOrder(TreeNode* root)
{if (root == NULL){printf("N ");return;}printf("%d ", root->data);PrevOrder(root->left);PrevOrder(root->right);
}
- 如果遇到节点为空,则打印N 并返回
- 注意:这里是递归进行的,返回是指返回到上一层函数
printf("%d ", root->data);首先访问根节点PrevOrder(root->left);访问左子树,进入左子树里面又分为先访问根节点,再访问左子树PrevOrder(root->right);访问完左子树后,访问右子树
我们可以画出递归展开图来加深理解
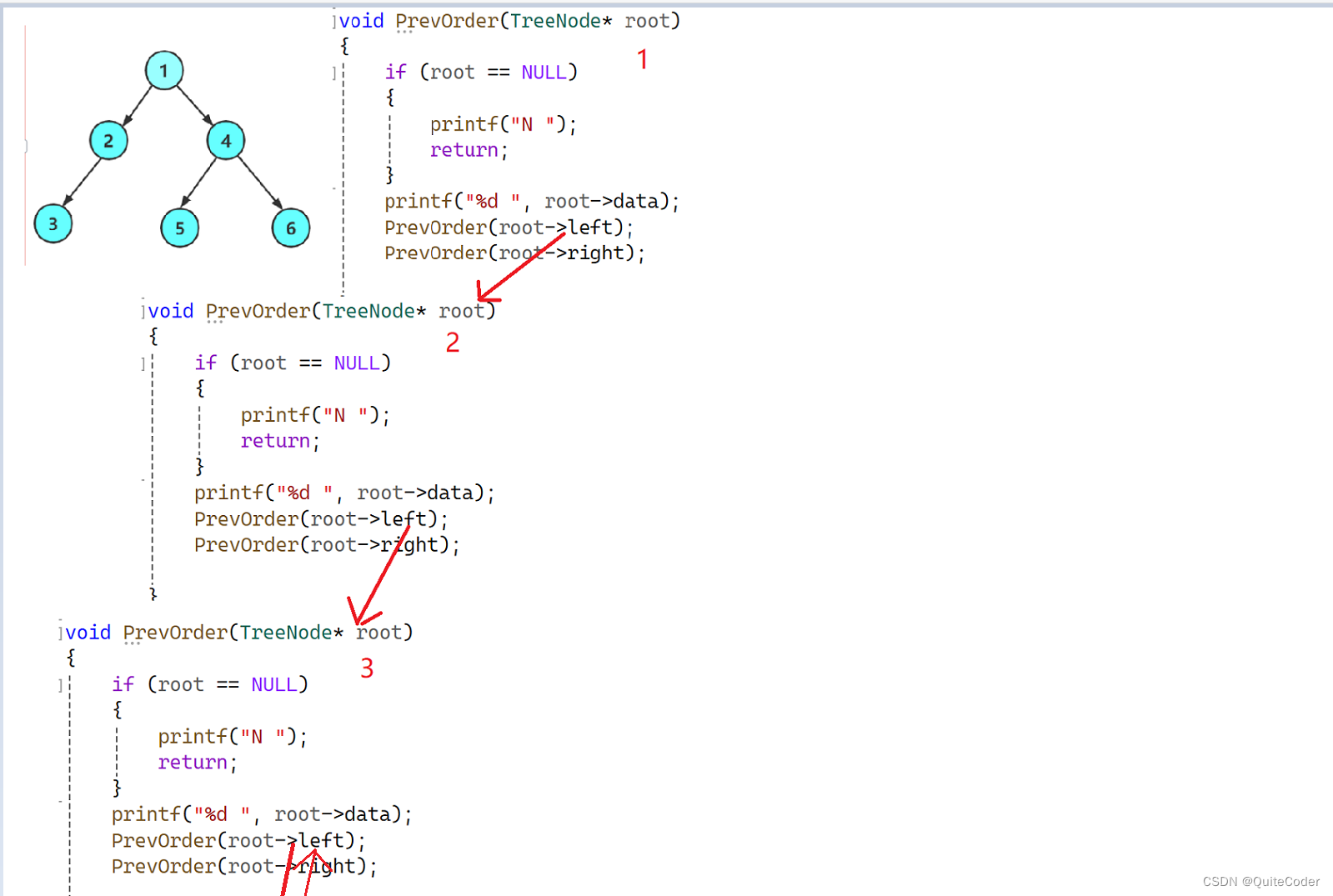
由1先访问根节点1,再到左子树2,2访问完根节点,到左子树3

3访问左子树为空,返回到上一层函数,接着访问3的右子树

3函数结束,返回到上一层函数,来对2的右子树进行访问,以此类推
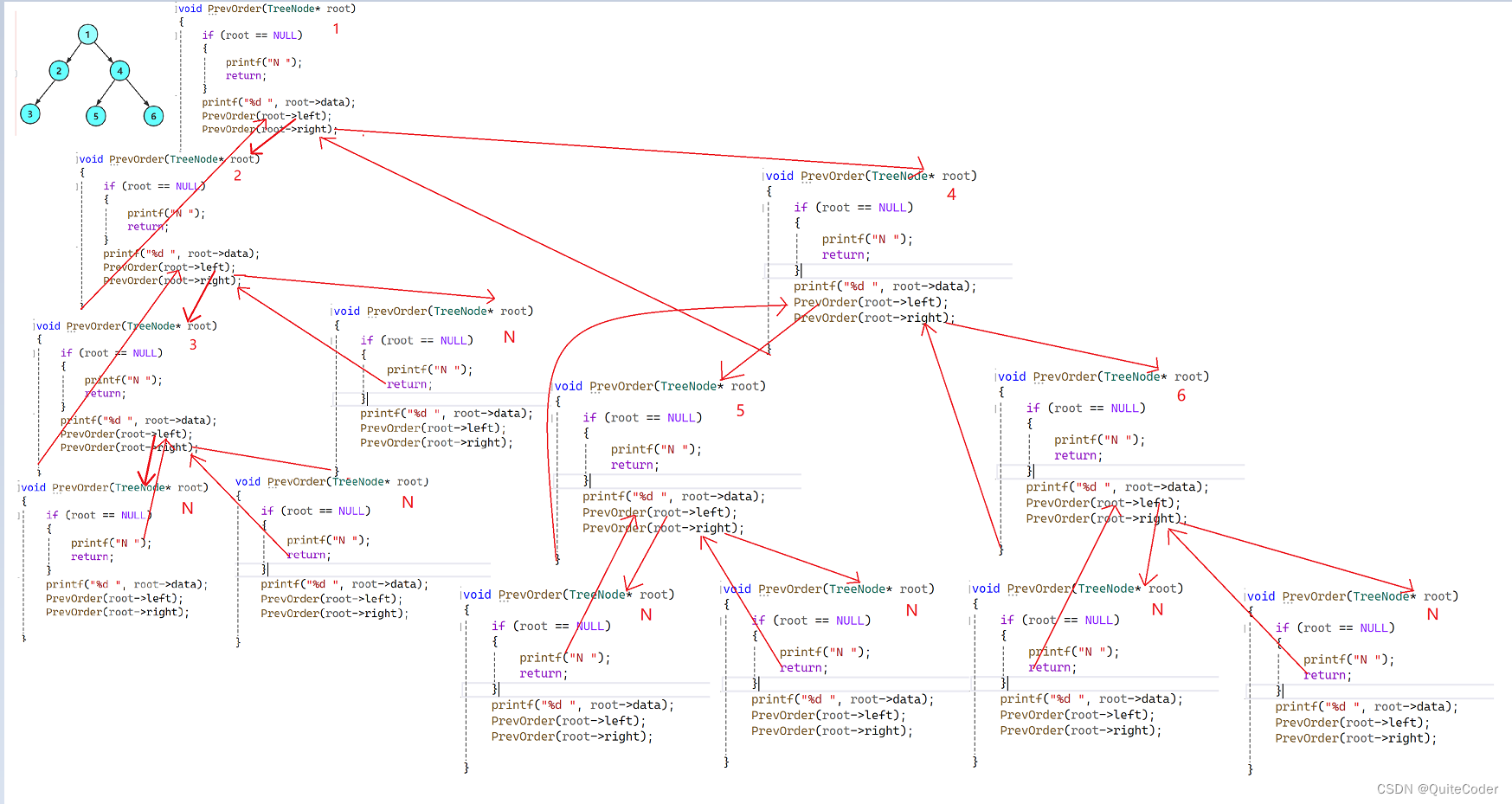
递归展开图可以更好的帮我们理解递归的过程
有了上述的讲解,中序遍历和后续遍历则变得很简单了
中序遍历代码:
void InOrder(TreeNode* root)
{if (root == NULL){printf("N ");return;}InOrder(root->left);printf("%d ", root->data);InOrder(root->right);
}
InOrder(root->left);先访问左子树printf("%d ", root->data);左子树访问完后访问根节点InOrder(root->right);最后访问右子树
后序遍历代码:
void PostOrder(TreeNode* root)
{if (root == NULL){printf("N ");return;}PostOrder(root->left);PostOrder(root->right);printf("%d ", root->data);
}
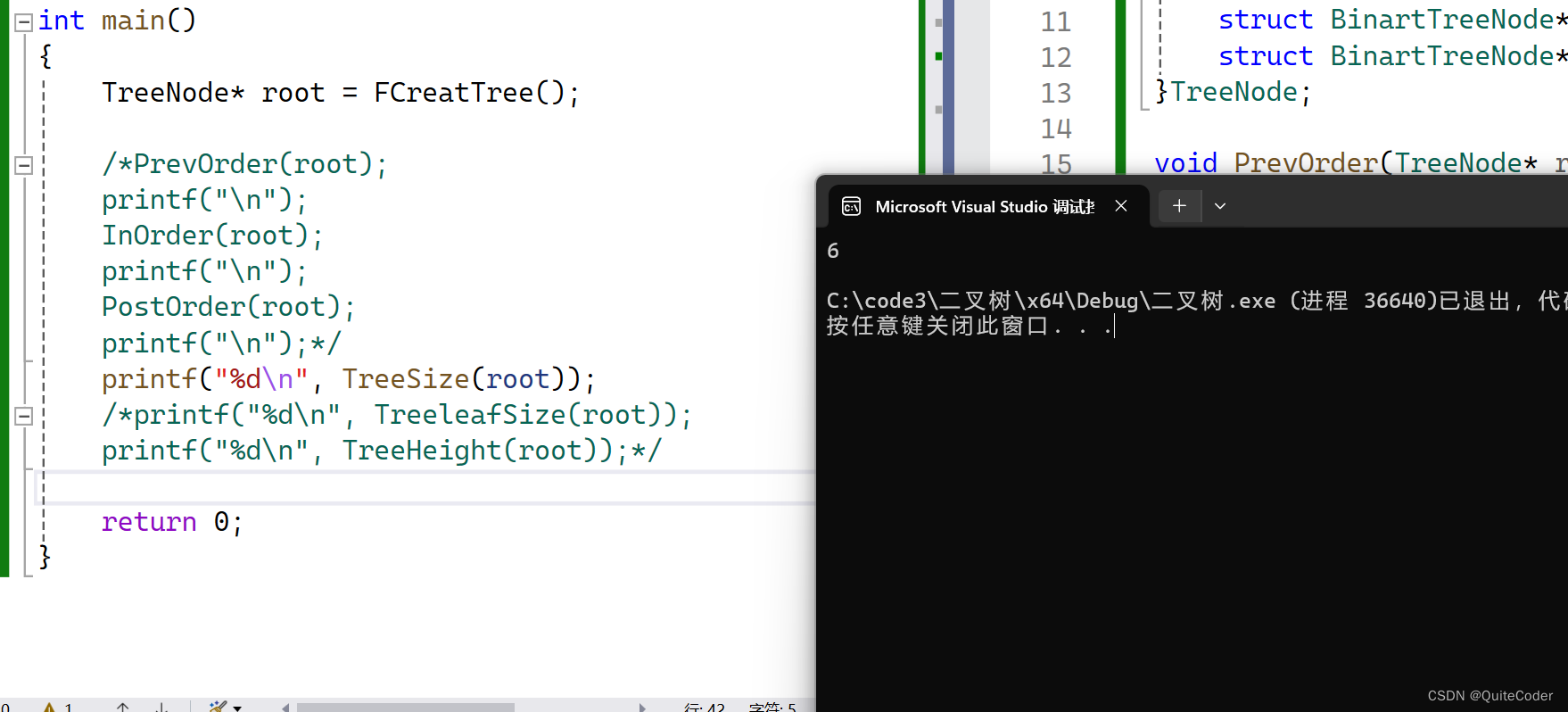
代码测试如下:

与刚刚讨论结果一致!
2. 获取相关个数
2.1获取节点个数
获取二叉树节点个数的核心思想是基于递归遍历整个树并计数。基于二叉树的性质,我们可以采用分治法:二叉树的节点总数是其左子树的节点数加上右子树的节点数,再加上根节点本身
基本步骤:
- 递归的基准情况:如果当前节点为NULL,意味着到达了叶子节点的外部(空树),返回0。
- 递归分解问题:递归地计算左子树的节点个数和右子树的节点个数。
- 合并结果:将左子树的节点数和右子树的节点数相加,然后加1(代表当前节点),得到的总和就是整个二叉树的节点个数。
int TreeSize(TreeNode* root)
{if (root == NULL){return 0;}return 1 + TreeSize(root->left) + TreeSize(root->right);
}
在上面的代码中,TreeSize函数会递归地遍历整棵树,每遇到一个非空节点,就通过递归计算它的左右子树的节点数,然后将这两个数加起来,并加上1(当前节点)。通过这种方式,当递归遍历完整棵树后,我们就可以得到二叉树的节点总数。
我们还可以用三目运算符简化上述代码:
int TreeSize(TreeNode* root)
{
return root==NULL?0:TreeSize(root->left)+1+TreeSize(root->right);
}
测试代码,以上树为例:
1/ \2 4/ / \
3 5 6
2.2获取叶节点个数
获取二叉树中叶节点(叶子节点)个数的思路与获取节点总数相似,但关注的是那些没有子节点的节点。叶子节点定义为没有左右子树的节点。基于递归的方法,我们可以遍历整棵树,并在遇到叶子节点时对计数器进行增加。
- 递归的基准情况:如果当前节点为NULL,意味着到达叶子节点的外部(空树),直接返回0。
- 识别叶子节点:如果当前节点既没有左子树也没有右子树,意味着它是一个叶子节点,因此返回1。
- 递归分解问题:如果当前节点不是叶子节点,递归地计算左子树的叶子节点个数和右子树的叶子节点个数。
- 合并结果:将左子树的叶子节点数和右子树的叶子节点数相加,得到的和就是整个二叉树的叶子节点个数
int TreeleafSize(TreeNode* root)
{if (root == NULL){return 0;}if (root->left == NULL && root->right == NULL){return 1;}else{return TreeleafSize(root->left) + TreeleafSize(root->right);}
}
对于每一个节点,算法检查是否它是一个叶子节点:如果是,返回1;否则,继续在它的左右子树中寻找叶子节点并计数。最终,通过对所有找到的叶子节点进行计数,我们可以得到整个二叉树的叶子节点数。
测试:
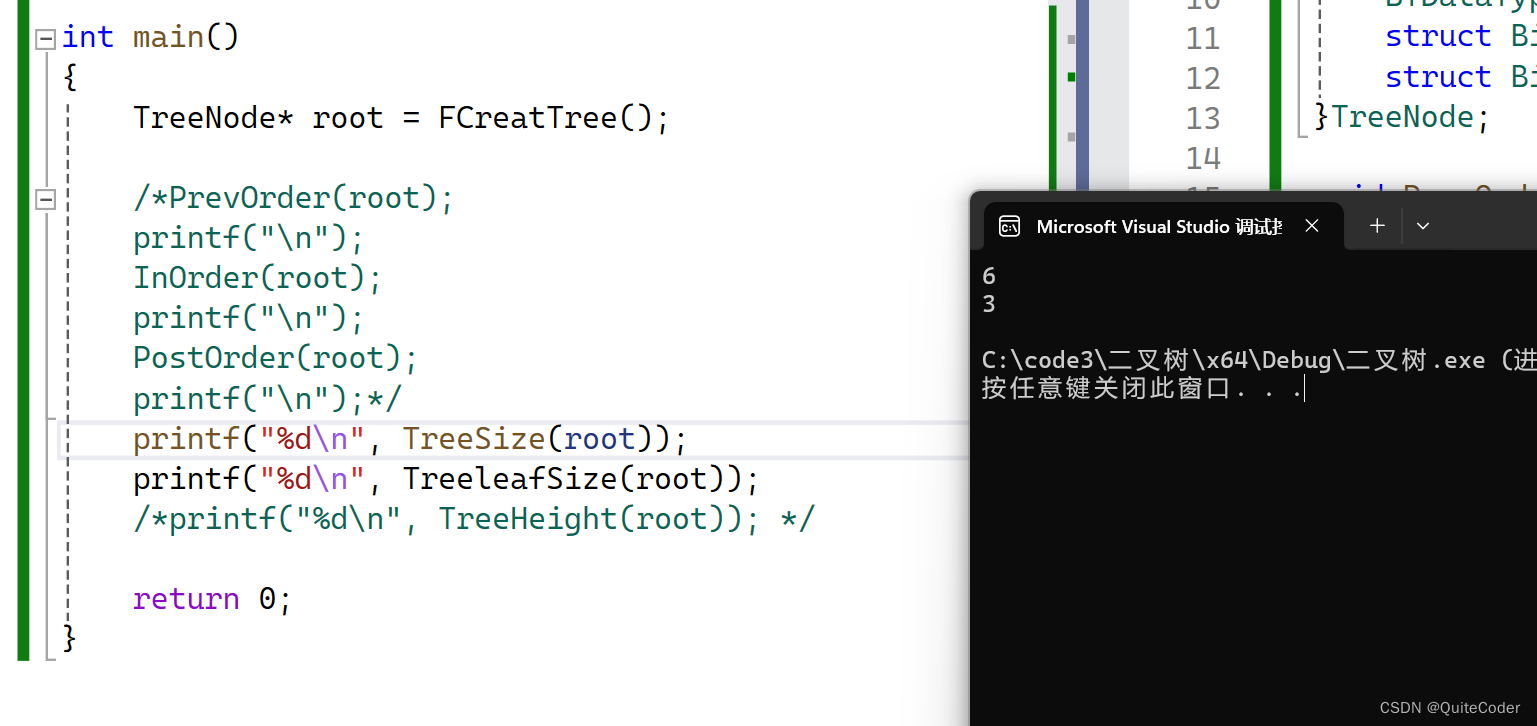
2.3 获取树的高度
获取二叉树的高度(或深度)的基本思路是遵循分治法原则,即递归地计算二叉树每个节点的左右子树的高度,并从中选择最大的一个,然后加1(当前节点在路径上增加的高度)来得到以该节点为根的子树的总高度。树的总高度即是从根节点到最远叶子节点的最长路径上的节点数。
- 递归基准:如果当前的节点为NULL,意味着到达了叶子节点的外部(空树),其高度为0。
- 递归地检查:递归地计算左子树的高度和右子树的高度。
- 选择最大的子树高度并加上当前节点:从左子树和右子树的高度中选择更大的一个,然后加1(当前节点本身)来得到整个子树的高度。
首先我们来看这串代码
int TreeHeight(TreeNode* root) {if (root == NULL){return 0;}TreeHeight(root->left);TreeHeight(root->right);return (TreeHeight(root->left) > TreeHeight(root->right) ? TreeHeight(root->left) : TreeHeight(root->right)) + 1;
}
这串代码有很大的缺陷
三目运算符对 TreeHeight(root->left) 和 TreeHeight(root->right) 各调用了两次。对于每一个非叶子节点,它的左右子树高度都被计算了两遍。这种重复计算对于简单的树结构可能不明显,但对于较大的二叉树来说,就会导致大量不必要的计算,进而降低程序的运行效率。
改进:
int TreeHeight(TreeNode* root) {if (root == NULL){return 0;}int leftHeight = TreeHeight(root->left);int rightHeight = TreeHeight(root->right);return (leftHeight > rightHeight ? leftHeight : rightHeight) + 1;
}
2.4 计算第K层节点个数
计算二叉树第 (k) 层的节点个数同样可以采用递归的方法来解决。这个问题可以拆分为:计算某节点左子树的第 (k-1) 层节点个数和右子树的第 (k-1) 层节点个数的和,因为从当前节点的视角看,它的子树的层数都少了一层。
int TreeKcount(TreeNode* root, int k)
{if (root == NULL||k<1){return 0;}if (k == 1){return 1;}return TreeKcount(root->left, k - 1) + TreeKcount(root->right, k - 1);
}
当达到第 1 层时,若二叉树非空,则第1层的节点数肯定是1(即当前节点),因为每次递归减少1层,直到递归到目标层级
- 当我们要求的是第1层的节点数量时(即树的根节点),且树非空,那么节点数量为1。
- 当 k 值大于1时,我们通过递归调用来求解左右子树在第 (k-1) 层的节点数量,然后将它们相加得到答案。
- 通过递归减少 k 的值,我们逐渐深入到树中更深的层次,直到 k 减至1,这时我们就到达了目标层,并可以直接计算节点数量。
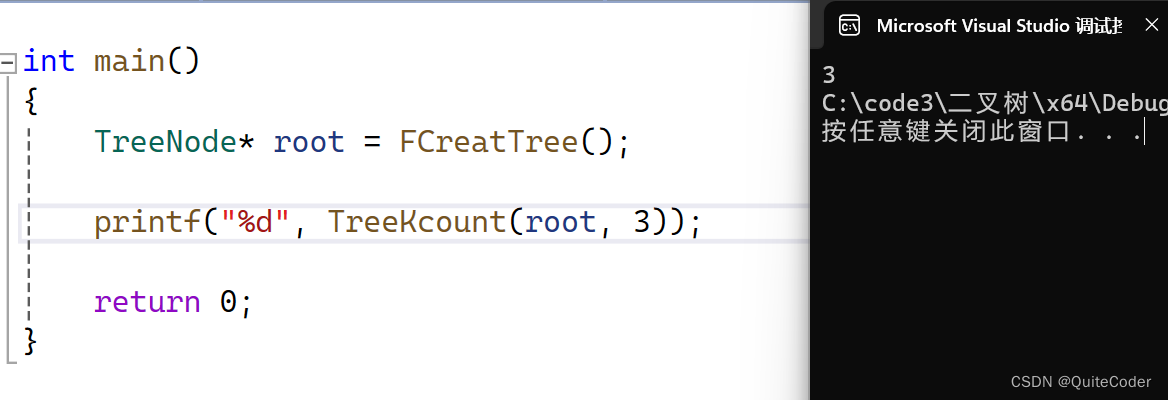
测试代码:
1/ \2 4/ / \
3 5 6
3.寻找某个节点
在二叉树中寻找值为 x 的节点可以通过递归方法来实现。本质上,这是一种深度优先搜索(DFS)策略。思路是从根节点开始,先检查根节点的值是否等于 x,如果是,就返回当前节点。如果不是,就先在左子树中递归查找,如果左子树中找到了,就直接返回结果;如果左子树中没有找到,再在右子树中查找。如果整棵树都没找到,最终返回 NULL 表示不存在值为 x 的节点。
TreeNode* TreeFind(TreeNode* root, BTDataType x)
{if (root == NULL)return NULL;if (root->data == x)return root;TreeNode* tmp1 = TreeFind(root->left, x);TreeNode* tmp2 = TreeFind(root->right, x);if (tmp1){return tmp1;}if (tmp2){return tmp2;}return NULL;
}
假设我们寻找3
1/ \2 4/ / \3 5 6
-
开始于根节点(值为1):首先检查根节点的值,它是1,不等于我们要找的值3。
-
递归搜索左子树(值为2的节点):进入下一层,移至节点值2,检查这个节点,它也不是我们要找的值。
-
递归搜索左子树的左子树(值为3的节点):继续递归进入下一层,移至节点值3,这个节点是我们要找的,因为它的值等于3。函数返回这个节点的地址
这里简单解释一下这段代码的含义:
if (tmp1) {return tmp1;
}
if (tmp2) {return tmp2;
}
return NULL;
-
tmp1和tmp2分别是对当前节点的左子树和右子树递归执行TreeFind函数后得到的结果。tmp1是左子树中查找的结果,而tmp2是右子树中查找的结果。 -
if (tmp1)检查左子树递归查找的结果。如果tmp1不为NULL,这意味着在左子树中找到了值为x的节点,因此直接返回该节点。这里的if (tmp1)、 -
如果tmp1为NULL,表明左子树中没有找到目标节点,程序将继续检查tmp2,即右子树递归查找的结果。同理,如果tmp2不为NULL(if (tmp2)),意味着在右子树中找到了值为x的节点,函数则返回该节点。
-
如果两个条件判断if (tmp1)和if (tmp2)都不成立,即tmp1和tmp2都为NULL,表示在当前节点的左右子树中都没有找到值为x的节点,那么函数最终返回NULL,表示查找失败。
4.用前序遍历建造一个二叉树
在上述铺垫后,我们来做一个题:
通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树
这里的#可以当做前面讲的NULL
首先我们定义函数;
TreeNode* CreatTree(BTDataType* a, int *pi);
- 字符串"ABD##E#H##CF##G##",按照前序遍历构建二叉树,其中’A’是根节点,继续按照根-左-右的顺序解析字符串。
'A'的左子节点是'B','B'的左子节点是'D'。'D'的左右子节点都是空("##"), 这表示’D’是叶子节点。- 回到
'B’,'B'的右子节点是'E'。'E'的左子节点为空(由"#"表示),右子节点是’H’。'H’的左右子节点也都是空。 - 回到根节点
'A',它的右子节点是'C'。'C'的左子节点为空,右子节点是'F'。'F’的左右子节点都是空。 - 最后,
'C'的右子节点是'G',同样,'G’的左右子节点都是空
得到的树结构如下:
A/ \B C/ \ \
D E F\ \H G
代码如下:
TreeNode* CreatTree(char* a, int* pi)
{if (a[*pi] == '#'){*pi++;return NULL;}TreeNode* root = (TreeNode*)malloc(sizeof(TreeNode));if (root == NULL){perror("malloc fail");exit(-1);}root->data = a[(*pi)++];root->left = CreatTree(a, pi);root->right = CreatTree(a, pi);return root;
}
这里TreeNode的数据类型需要从int 改为char,我们将typedef后面的int修改即可
typedef char BTDataType;typedef struct BinaryTreeNode
{BTDataType data;struct BinartTreeNode* left;struct BinartTreeNode* right;
}TreeNode;
5.二叉树的销毁
void DestroyTree(TreeNode* root) {if (root == NULL) {return;}DestroyTree(root->left); // 销毁左子树DestroyTree(root->right); // 销毁右子树free(root); // 释放当前节点
}
当你调用DestroyTree并传入树的根节点时,函数首先检查是否给定的节点(在最初的调用中,这是根节点)为NULL。如果不是,它会递归地调用自身来销毁左子树和右子树。完成这些递归调用之后,返回到最初的调用层次时,它会释放根节点本身占用的内存。
- 检查root是否为NULL。如果是,说明已经处理到了空子树,函数返回。
- 递归调用DestroyTree(root->left);销毁左子树。这将遍历到最左侧的叶子节点,沿途经过的每个节点的左子树都将被先递归调用DestroyTree处理。
- 递归调用DestroyTree(root->right);销毁右子树。每个节点的右子树同样会经历相同的递归处理。
- 最后,经过左子树和右子树的递归处理后,回到当前的节点,并使用
free(root);释放掉该节点占用的内存。
尽管根节点被销毁,但原始root变量本身在函数返回后仍然存在,只是它现在成为了一个悬空指针。为了安全起见,调用完DestroyTree之后,应该手动将root设置为NULL
例如:
int main() {TreeNode* root = FCreatTree()DestroyTree(root);root = NULL; return 0;
}
如果不想手动设置为NULL,只用一个DestroyTree函数来解决,这里意味着我们需要在函数里面实现置空过程,意味着我们要修改指针,则需要传参二级指针:
void DestroyTree(TreeNode** root) {if (*root == NULL) {return;}DestroyTree(&((*root)->left));DestroyTree(&((*root)->right));free(*root);*root = NULL; // 将调用方的根节点指针置为NULL
}
6.链式二叉树的层序遍历
层序遍历(Level Order Traversal)是指按照从上到下、从左到右的顺序访问二叉树的每个节点。这种遍历方式可以保证二叉树中每个节点的访问顺序正好对应其在树中的层次和位置。层序遍历通常借助于队列这一数据结构来实现。
所以要想实现层序遍历,首先得有队列的函数,在前几节内容中我们已经对其讲解,这里直接引用其代码:
void QueueInit(Queue* pq)
{assert(pq);pq->phead = pq->ptail = NULL;pq->size=0;
}
void QueuePush(Queue* pq, QDataType x)
{assert(pq);QNode* newnode = (QNode*)malloc(sizeof(QNode));if (newnode == NULL){perror("malloc fail");return;}newnode->val = x;newnode->next = NULL;if (pq->ptail == NULL){pq->ptail = pq->phead = newnode;}else{pq->ptail->next = newnode;pq->ptail = newnode;}pq->size++;
}
void QueuePop(Queue* pq) {assert(pq); // 确保 pq 不是 NULLif (pq->phead == NULL) return; // 如果队列为空,则没有元素可以弹出QNode* temp = pq->phead; // 临时保存队列头部节点的地址,以便后续释放内存pq->phead = pq->phead->next; // 更新头指针指向下一个节点free(temp); // 释放原头节点占据的内存temp = NULL;if (pq->phead == NULL) { // 如果弹出之后队列变为空,则尾指针也要更新为 NULLpq->ptail = NULL;}pq->size--; // 更新队列大小
}
QDataType QueueFront(Queue* pq)
{assert(pq); // 确保 pq 不是 NULLassert(pq->phead != NULL);return pq->phead->val; }
QDataType QueueBack(Queue* pq) {assert(pq != NULL); // 确保队列指针不为NULLassert(pq->ptail != NULL); // 确保队列不为空,即队尾指针不为NULL// 返回队列尾部元素的值return pq->ptail->val;
}
bool QueueEmpty(Queue* pq)
{assert(pq);return pq->phead == NULL;
}
int QueueSize(Queue* pq)
{assert(pq);return pq->size;
}
void QueueDestroy(Queue* pq)
{assert(pq);QNode* cur = pq->phead;while (cur){QNode* next = cur->next;free(cur);cur = next;}pq->phead = pq->ptail = NULL;pq->size = 0;
}
队列在层序遍历中的使用是由于其先进先出(First In First Out, FIFO)的特性,这保证了树的节点能够按照从上到下、从左到右的顺序进行访问,这里解释为什么要用队列进行层序遍历:
- 在层序遍历过程中,我们首先访问根节点,然后是根节点的子节点(从左到右),接着是子节点的子节点,以此类推。队列能够保证节点的访问顺序正好符合这一层级结构,因为我们总是先将左子节点加入队列,然后是右子节点。当从队列中取出一个节点时,它的子节点已经按照正确的顺序排在后面
实现步骤:
- 初始化:创建一个队列,将根节点入队
- 循环执行以下操作,直到队列为空:
- 将队头的节点出队,并访问该节点
- 如果该节点有左子节点,则将左子节点入队
- 如果该节点有右子节点,则将右子节点入队
我们思考一下,这里队列里面放的是什么,节点还是节点的值?
这里放入的是节点,如果只放入节点的值,则找不到下一个节点,所以这里我们需要修改队列的typedef类型!
typedef struct BinaryTreeNode* QDataType;
typedef struct QueueNode
{QDataType val;struct QueueNode* next;
}QNode;
typedef struct Queue
{QNode* phead;QNode* ptail;int size;
}Queue;
接下来实现代码:
void LevelOrder(TreeNode* root)
{Queue q;QueueInit(&q);if (root != NULL){QueuePush(&q, root);}while (!QueueEmpty(&q)){TreeNode* front = QueueFront(&q);QueuePop(&q);printf("%d ", front->data);if (front->left != NULL)QueuePush(&q, front->left);if (front->right != NULL)QueuePush(&q, front->right);}QueueDestroy(&q);
}
我们来进行分析:
以最开始的那棵树为例子:
1/ \2 4/ / \3 5 6
让我们展开遍历的过程:
- 开始时,队列状态:1
- 取出1,打印1,加入1的左子节点2和右子节点4,队列状态:2, 4
- 取出2,打印2,加入2的左子节点3,队列状态:4, 3
- 取出4,打印4,加入4的左子节点5和右子节点6,队列状态:3, 5, 6
- 取出3,打印3,队列状态:5, 6
- 取出5,打印5,队列状态:6
- 取出6,打印6,队列空
打印顺序:1, 2, 4, 3, 5, 6。
7.判断是否为完全二叉树
判断一棵树是否为完全二叉树,可以利用层序遍历的思想。完全二叉树的特点是,除了最后一层外,每一层都是完全填满的,且最后一层的所有节点都集中在左侧。在层序遍历过程中,如果遇到了一个节点,其有右子节点而无左子节点,那么这棵树肯定不是完全二叉树;另外,如果遇到了一个节点并非左右子节点都有,那么所有接下来遍历到的节点都必须是叶子节点。
我们再原有层序遍历代码上修改即可:
bool BinaryTreeComplete(TreeNode* root)
{Queue q;QueueInit(&q);if (root != NULL){QueuePush(&q, root);}while (!QueueEmpty(&q)){TreeNode* front = QueueFront(&q);QueuePop(&q);if (front == NULL)break;QueuePush(&q, front->left);QueuePush(&q, front->right);}while (!QueueEmpty(&q)){TreeNode* front = QueueFront(&q);QueuePop(&q);if (front){QueuePop(&q);return false;}}QueueDestroy(&q);return true;
}
第一部分:将所有节点(包括空节点)按层序添加到队列中
- 首先,初始化一个队列 q。
- 如果根节点不为空,则将根节点添加到队列中。
- 接下来进入一个循环,直到队列为空。在这个循环中:
- 从队列中弹出一个节点(记为 front)。
- 如果 front 是 NULL,即遇到了第一个空节点,则退出循环。这是因为在完全二叉树中,一旦按层序遍历遇到空节点,其后的所有节点也应该是空的。
- 如果 front 非空,将其左右子节点(即使是空的)添加到队列中。这样做是为了保证即使是空节点也按照层序顺序排列。
第二部分:检查队列中剩余的所有节点是否都是空的
退出第一部分的循环后,理论上队列中剩下的所有节点应该都是空节点(如果是完全二叉树的话)。因此,接下来的循环会遍历队列中剩余的所有节点:
从队列中弹出一个节点(记为 front)。
如果 front 是非空的,说明在遇到第一个空节点之后还有非空节点,这违反了完全二叉树的性质。因此,函数返回 false。
如果循环顺利结束,没有遇到任何非空节点,说明这棵树是一棵完全二叉树,函数返回 true。
本节内容到此结束!!感谢大家阅读!!!

相关文章:
数据结构与算法:链式二叉树
上一篇文章我们结束了二叉树的顺序存储,本届内容我们来到二叉树的链式存储! 链式二叉树 1.链式二叉树的遍历1.1二叉树的前序,中序,后序遍历1.2 三种遍历方法代码实现 2. 获取相关个数2.1获取节点个数2.2获取叶节点个数2.3 获取树的…...

SpringMVC中接收参数总结
目录 一、引子 二、注解解析 RequestParam 一、要求形参名请求参数名,或者是请求实体类时(已有实体类),可以不需要加该注解 二、请求参数名!参数名时,需要写该注解RequestParam,其中 三、一名多值的情…...
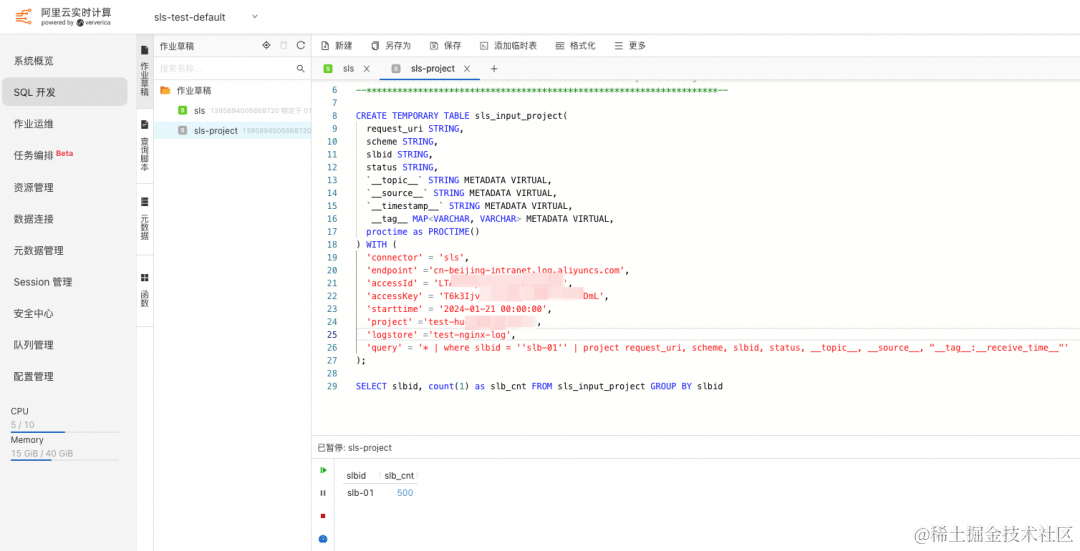
使用 SPL 高效实现 Flink SLS Connector 下推
作者:潘伟龙(豁朗) 背景 日志服务 SLS 是云原生观测与分析平台,为 Log、Metric、Trace 等数据提供大规模、低成本、实时的平台化服务,基于日志服务的便捷的数据接入能力,可以将系统日志、业务日志等接入 …...
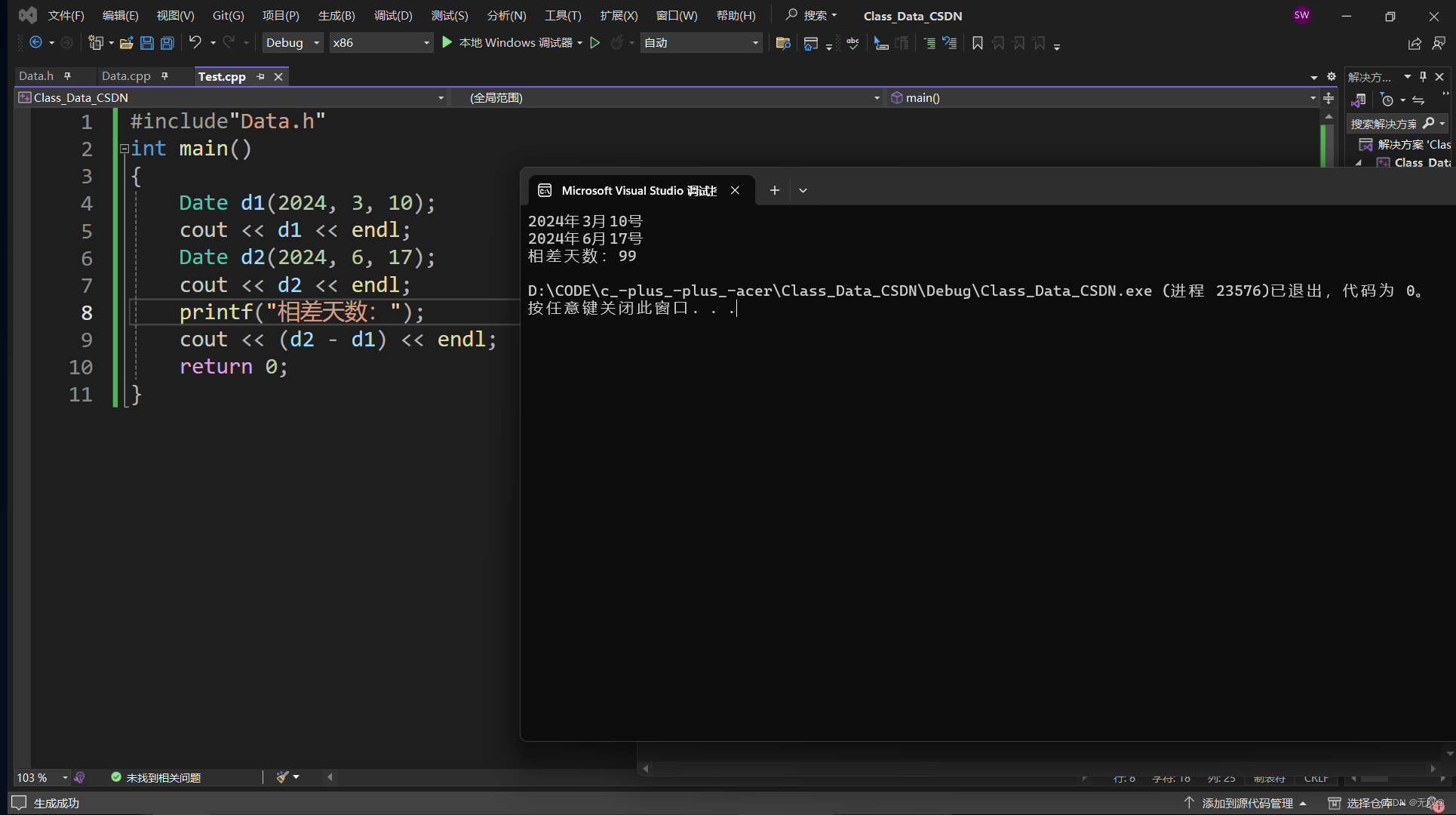
《日期类》的模拟实现
目录 前言: 头文件类与函数的定义Date.h 实现函数的Date.cpp 测试Test.cpp 运行结果: 前言: 我们在前面的两章初步学习认识了《类与对象》的概念,接下来我们将实现一个日期类,是我们的知识储备更加牢固。 头文件…...
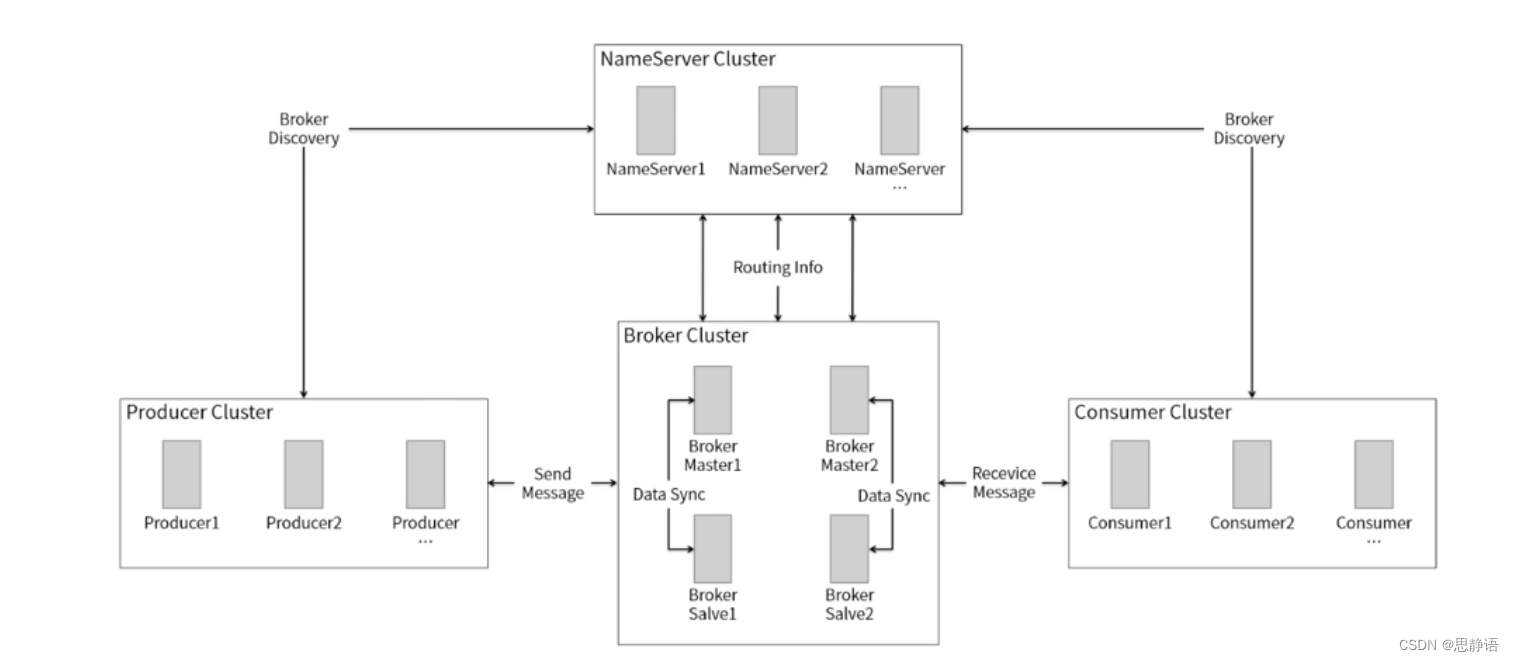
RocketMQ架构详解
文章目录 概述RocketMQ架构rocketmq的工作流程Broker 高可用集群刷盘策略 概述 RocketMQ一个纯java、分布式、队列模型的开源消息中间件,前身是MetaQ,是阿里研发的一个队列模型的消息中间件,后开源给apache基金会成为了apache的顶级开源项目…...

【AI视野·今日NLP 自然语言处理论文速览 第八十二期】Tue, 5 Mar 2024
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 5 Mar 2024 (showing first 100 of 175 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers Key-Point-Driven Data Synthesis with its Enhancement on Mathematica…...

windows 两个服务器远程文件夹同步,支持文件新增文件同步、修改文件同步、删除文件同步,根据文件大小和时间戳判断文件是否修改 python脚本
在Python中实现Windows两个服务器之间的文件夹同步,包括文件新增、修改和删除的同步,可以使用paramiko库进行SSH连接以及SFTP传输,并结合文件大小和时间戳判断文件是否发生过变化。以下是包含删除文件同步逻辑的完整脚本示例: im…...

vite项目修改node_modules
问题详情 在使用某个依赖的时候遇到了bug,提交issue后不想一直等待到作者更新版本,所以寻求临时自己解决 问题解决 在node_modules里找到需要修改的依赖,修改想要修改的代码 修改后记得保存 然后在node_modules里找到.vite文件夹&#x…...
NLP神器Transformers入门简单概述
在这篇博客中,我们将深入探索 🤗 Transformers —— 一个为 PyTorch、TensorFlow 和 JAX 设计的先进机器学习库。🤗 Transformers 提供了易于使用的 API 和工具,使得下载和训练前沿的预训练模型变得轻而易举。利用预训练模型不仅能减少计算成本和碳足迹,还能节省从头训练…...

微信小程序-wxml语法
介绍 WXML(WeiXin Markup Language)是框架设计的一套标签语言,可以进行页面布局,声明事件,数据绑定,条件判断。 语法 数据绑定 <view> {{message}} </view>// page.js Page({data: { // 状态…...

网络层转发分组的过程
分组转发都是基于目的主机所在网络的,这事因为互联网上的网络数远小于主机数,这样可以极大的压缩转发表的大小。当分组到达路由器后,路由器根据目的IP地址的网络地址前缀查找转发表,确定下一跳应当到哪个有路由器。因此࿰…...
计算两帧雷达数据之间的变换矩阵
文章目录 package.xmlCMakeLists.txtpoint_cloud_registration.cc运行结果 package.xml <?xml version"1.0"?> <package format"2"><name>point_cloud_registration</name><version>0.0.0</version><descriptio…...

2. gin中间件注意事项、路由拆分与注册技巧
文章目录 一、中间件二、Gin路由简介1、普通路由2、路由组 三、路由拆分与注册1、基本的路由注册2、路由拆分成单独文件或包3、路由拆分成多个文件4、路由拆分到不同的APP 一、中间件 在日常工作中,经常会有一些计算接口耗时和限流的操作,如果每写一个接…...

R语言复现:如何利用logistic逐步回归进行影响因素分析?
Logistic回归在医学科研、特别是观察性研究领域,无论是现况调查、病例对照研究、还是队列研究中都是大家经常用到的统计方法,而在影响因素研究筛选自变量时,大家习惯性用的比较多的还是先单后多,P<0.05纳入多因素研究&…...
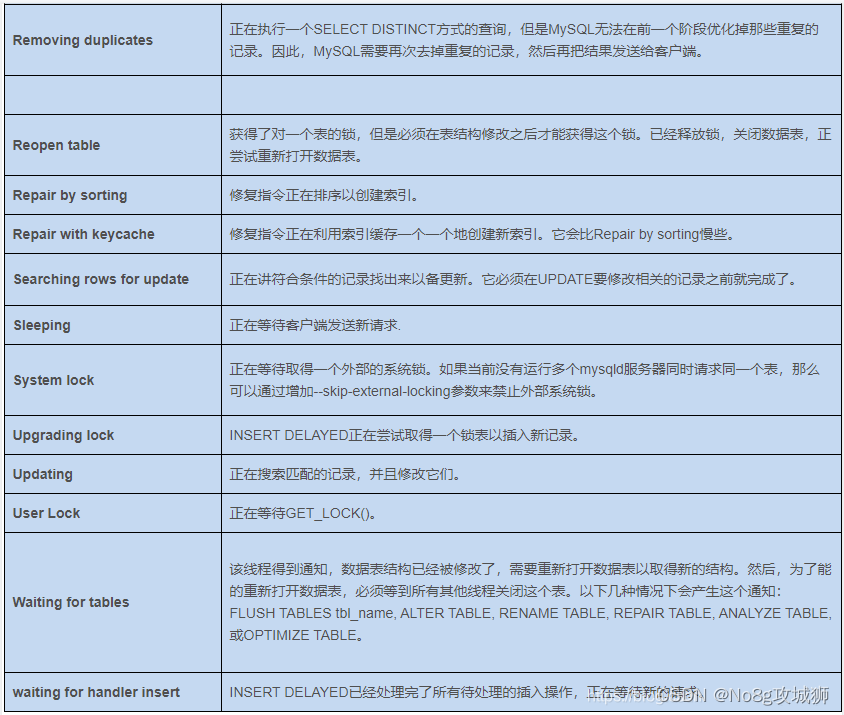
【MySQL使用】show processlist 命令详解
show processlist 命令详解 一、命令含义二、命令返回参数三、Command值解释四、State值解释五、参考资料 一、命令含义 对于一个MySQL连接,或者说一个线程,任何时刻都有一个状态,该状态表示了MySQL当前正在做什么。SHOW PROCESSLIST 命令的…...
分类算法(Classification algorithms)
逻辑回归(logical regression): 逻辑回归这个名字听上去好像应该是回归算法的,但其实这个名字只是在历史上取名有点区别,但实际上它是一个完全属于是分类算法的。 我们为什么要学习它呢?在用我们的线性回归时会遇到一…...

深度学习-Softmax 回归 + 损失函数 + 图片分类数据集
Softmax 回归 损失函数 图片分类数据集 1 softmax2 损失函数1均方L1LossHuber Loss 3 图像分类数据集4 softmax回归的从零开始实现 1 softmax Softmax是一个常用于机器学习和深度学习中的激活函数。它通常用于多分类问题,将一个实数向量转换为概率分布。Softmax函…...
)
分布式锁从0到1落地实现01(mysql/redis/zk)
1 准备数据库表 CREATE TABLE user ( id bigint(20) NOT NULL COMMENT 主键ID, name varchar(30) DEFAULT NULL COMMENT 姓名, age int(11) DEFAULT NULL COMMENT 年龄, email varchar(50) DEFAULT NULL COMMENT 邮箱, PRIMARY KEY (id) ) ENGINEInnoDB DEFAULT CHARSETutf8;I…...

安全运营方案的基本框架和关键要素
一、前言 阐述安全运营方案的目的和重要性。强调安全运营与组织整体战略目标的关联。 二、安全运营原则 确立安全运营的基本原则,如保密性、完整性和可用性。明确安全责任划分,确保各部门和人员履行安全职责。 三、安全风险评估与管理 进行全面的安…...
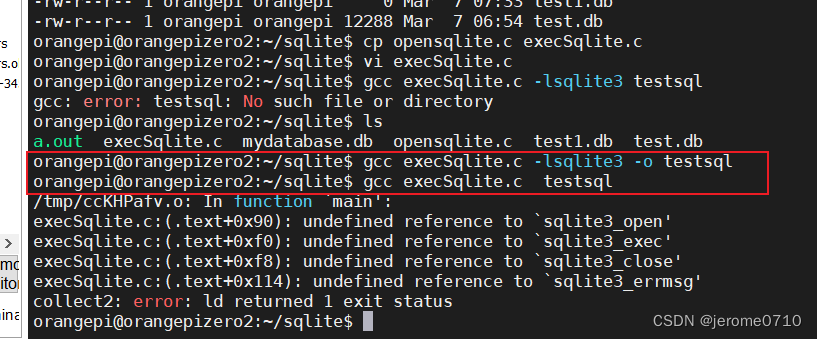
用C语言执行SQLite3的gcc编译细节
错误信息: /tmp/cc3joSwp.o: In function main: execSqlite.c:(.text0x100): undefined reference to sqlite3_open execSqlite.c:(.text0x16c): undefined reference to sqlite3_exec execSqlite.c:(.text0x174): undefined reference to sqlite3_close execSqlit…...

【紧急预警】AIAgent“隐性失效”正在蔓延!SITS2026定义4类伪可靠陷阱及实时检测方案
第一章:SITS2026总结:构建可靠AIAgent的关键要素 2026奇点智能技术大会(https://ml-summit.org) 构建可靠AI Agent并非仅依赖更大参数量或更强算力,而需在系统性工程层面筑牢四大支柱:可验证的推理链、受控的工具调用、上下文感知…...

React Native应用发布苹果商店:解决hermes.framework的dSYM缺失问题
1. 为什么React Native应用发布苹果商店会报dSYM缺失错误 最近在帮团队处理React Native应用上架苹果商店时,遇到了一个让人头疼的问题。打包上传后,苹果商店后台报错提示:"The archive did not include a dSYM for the hermes.framewor…...

INTERFACE AZI-132B接口模块
INTERFACE AZI-132B 接口模块INTERFACE AZI-132B 是一款用于工业自动化系统中的接口模块,主要用于实现设备之间的信号连接与数据传输,适用于PLC及各类控制系统的接口扩展应用。用于工业自动化控制系统属于信号接口与通信模块支持多通道信号输入处理可实现…...

深入解析Frida Hook dlopen:动态库加载监控与反调试绕过实战
1. 动态库加载与Frida Hook基础 动态库(.so文件)是Android应用的重要组成部分,它们包含了应用的核心功能逻辑。在Android系统中,动态库的加载主要通过dlopen和android_dlopen_ext这两个函数完成。理解这两个函数的工作原理&#x…...

终极指南:ROPgadget如何成为9大CPU架构的二进制分析利器
终极指南:ROPgadget如何成为9大CPU架构的二进制分析利器 【免费下载链接】ROPgadget This tool lets you search your gadgets on your binaries to facilitate your ROP exploitation. ROPgadget supports ELF, PE and Mach-O format on x86, x64, ARM, ARM64, Pow…...

MoveIt Servo 如何通过 FollowJointTrajectoryControllerHandle Action Server 通信
一、通信架构图textMoveIt Servo (moveit_servo node)↓ MoveItSimpleControllerManager (插件管理器)↓ FollowJointTrajectoryControllerHandle (您看到的这个类)↓ [内部创建 Action Client]↓ ROS 2 Action Client (自动生成)↓ [通过 ROS 2 Action 协议]↓ 您的 Action Se…...

从零构建ARM64嵌入式Linux:内核裁剪与最小根文件系统实践
1. ARM64嵌入式Linux开发环境搭建 在开始构建ARM64嵌入式Linux系统之前,我们需要准备一个合适的开发环境。我建议使用Ubuntu 20.04 LTS作为开发主机系统,因为这个版本有很好的软件包支持和社区资源。 首先安装必要的交叉编译工具链: sudo …...

Java String 类详解
Java String 类详解 引言 Java中的String类是Java编程语言中最为常用的类之一。它代表字符串,是Java中处理文本数据的核心组件。在Java中,字符串是不可变的,这意味着一旦创建了一个字符串对象,就不能修改它。本文将详细介绍Java String类的特点、用法和注意事项。 Strin…...

华为等团队揭秘:机器人“预知未来“比“见多识广“更可靠?
这项由华为技术有限公司联合多伦多大学共同完成的研究发表于2026年的arXiv预印本平台,论文编号为arXiv:2603.22078v2。有兴趣深入了解的读者可以通过该编号查询完整论文内容。在机器人技术飞速发展的今天,如何让机器人在复杂多变的真实环境中稳定工作&am…...
)
SAP CO模块实战:成本控制范围配置全流程解析(OKKP-Maintain Controlling Area)
1. 成本控制范围配置的核心价值 刚接触SAP CO模块时,我对"成本控制范围"这个概念也是一头雾水。直到参与了一个制造业项目,才真正理解它的重要性。简单来说,成本控制范围就像是你家客厅的智能电表,能精确统计每个区域的…...