近年来文本检测相关工作梳理
引言
场景文本检测任务,一直以来是OCR整个任务中最为重要的一环。虽然有一些相关工作是端对端OCR工作的,但是从工业界来看,相关落地应用较为困难。因此,两阶段的OCR方案一直是优先考虑的。
在两阶段中(文本检测+文本识别),文本检测是极为重要的一环。自从DBNet提出后,工业界似乎找到了法宝,DBNet算法迅速成为大家做文本检测的首选。
但是,通过近来阅读的一些论文,我逐渐发现了DBNet后,文本检测任务相关算法的一些趋势:DBNet是只考虑了图像的信息,并没有考虑文本的信息。最近的算法,在逐渐向多模态方向靠近,利用CLIP等相关multi-model来增强文本检测backbone能力。
本文算是将最近看的一些相关论文做一下梳理,算是抛砖引玉。难免挂一漏万,还望大家多多指教。
⚠️注意:行文顺序是从新到旧排列
(2024 ODM) ODM: A Text-Image Further Alignment Pre-training Approach for Scene Text Detection and Spotting
code: https://github.com/PriNing/ODM

该篇工作是我无意刷到的,刚贴出来不久(2024-03-01)。通篇看下来,ODM做的工作很简单,就是将带有文本图像中的背景都去除掉,得到如上图中右侧的黑底白字的图像,再送到后续文本检测算法中做检测。
这样的想法,我之前做过类似的,用的是U-Net系列。但是效果较差。原因有三:
一是训练这种模型需要pixel-level数据集;
二是模型推理较为耗时;
三是泛化性能较差,因为文本所在位置千变万化,换一种场景,模型去除背景能力就会差很多。
文中也提到了如何制作的数据集:
- 对于四点坐标标注的框,作者计算四边形的尺寸,并根据字符的数量估计每个字符的大小和位置。然后用指定字体贴上去。
- 对于多边形坐标的框,作者采用ABCNet论文中合成方法,使用坐标提供的Bezier curves来计算弯曲文本的位置。然后计算每个字的倾斜角度贴上去。
示例图如下:

以上做法会存在gt图和原始图,文本像素点不能一一对应的问题。论文作者显然也考虑到了,特地在论文中提了一句:

PS: 目前对该方法效果持保留态度,等待后续作者开源源码和demo(只有空仓库),再来试试看吧!
(CVPR2023 TCM) Turning a CLIP Model into a Scene Text Detector
code: https://github.com/wenwenyu/TCM

该工作正如题目所说,将CLIP模型用到了文本检测场景中,不同于之前工作,都是将文本模态信息用到预训练阶段,之后再迁移backbone到fine-tuning部分。
TCM直接用CLIP模型中的Image encoder和Text encoder作为编码器,同时又提出了一个language prompt generator用于为每张图像产生conditional cue。同时为了adapting CLIP的text encoder用于文本检测任务,设计了一个visual prompt generator来学习image prompt.
为了对齐 image embedding和text embedding,设计了一个instance-language matching方法来鼓励image encoder 探索来自cross-modal visual-language priors的text regions.
PS: 得益于CLIP强大的泛化能力,该工作在few-shot方面具有较大潜力。但是引入了另外一个比较大的问题:耗时。因为基于CLIP,其后期推理部署仍然是一个很大的问题。即使后来又出了Fast-TCM工作,速度也是一个问题。
(ECCV 2022 oCLIP) Language Matters: A Weakly Supervised Vision-Language Pre-training Approach for Scene Text Detection and Spotting
code: https://github.com/bytedance/oclip

该篇工作和VLPT-STD工作很类似,也是意图加强text embedding和image embedding之间的交互。但是其在训练过程中,优化目标是masked language modeling这一个任务。这一点没有VLPT-STD丰富。
其中亮点在于提出了Character-Aware Text Encoder。
在自然场景的图像中,图像通常包括一个或多个 text instances。在每一个text instance中,text tokens是序列相关的,而不同text instances中,text tokens往往是不相关的。这个特性就导致用一个general text encoder来encode这一张图像的text有些困难。这一点,在VLPT-STD中就没有考虑到。
而在character-aware text encoder中添加了learnt positional encooding来捕获每一个text instance中序列信息,忽略text instance间的相关性。这一点在Decoder部分也有所体现:在decoder中,并没有使用self-attention layer,就是为了忽略不同text instances间的相关性,消除没有标注text instances的影响。
PS: oCLIP与VLPT-STD工作各有所长。算是同时期工作,将两者工作结合,或许可以水一篇论文。嘻嘻。
(CVPR 2022 VLPT-STD) Vision-Language Pre-Training for Boosting Scene Text Detectors
code: 无

STKM工作是直接从image representations中decoding文本信息,本篇工作则通过仔细设计的pre-training任务(image-text contrasitive learning, masked language modeling, word-in-image predictioin)中,增加文本信息和图像信息的mutual alignment和cross-modal interaction,从而进一步增强backbone的能力。这一点参看下图即可明白:

PS: VLPT-STD工作,相比于STKM,更加一步加强了multi-model的交互和对齐,是的backbone提取特征能力更加丰富。在看这篇工作时,我就在想可以直接将文本框坐标信息也加入到训练中,类似于LayouLM系列。在论文Conlusion部分,也看到了作者也有同样想法,不知道现在有没有小伙伴已经做过了。
(CVPR 2021 STKM) Self-attention based text knowledge mining for text detection
code: https://github.com/CVI-SZU/STKM

论文的整体结构如上图所示,作者首次提出了text knowledge mining network,该network可以用于增强已有的各种文本检测算法,无痛涨点的同时,不影响已有文本检测算法推理的速度。
文本检测模型的训练,一般分为两个阶段:第一个阶段基于Synthtext数据集预训练,第二阶段基于ICDAR2015、ICDAR2017等数据集做fine-tuning。
STKM工作致力于设计一个text feature mining网络来使得第一阶段中的backbone学到更强的prior knowledge。STKM结构由CNN Encoder + Self-attention Decoder两大部分组成,如上图中的(a)部分。
PS:我个人比较喜欢这种工作。总结来说,不同于之前的EAST、PSENet,STKM引入文本信息到backbone中,丰富了backbone的特征提取能力。从论文中实验来看,并没有DBNet的对比工作,感觉应该是DBNet与STKM差不多算是同时期的工作了。
相关文章:
近年来文本检测相关工作梳理
引言 场景文本检测任务,一直以来是OCR整个任务中最为重要的一环。虽然有一些相关工作是端对端OCR工作的,但是从工业界来看,相关落地应用较为困难。因此,两阶段的OCR方案一直是优先考虑的。 在两阶段中(文本检测文本识…...

文件系统事件监听
文件系统事件和网络IO事件一样,也可以通过epoll或者IOCP 事件管理器统一调度,当所监控的文件或文件夹发生了增删改的事件时,就会触发事件回调,进行事件处理。很常见的应用,如配置文件立即生效功能,就可以通…...

探秘HTTPS:如何通过SSL/TLS保证网络通信安全
目录 引言 详解HTTPS加密实现机制 SSL/TLS工作原理 结论 引言 随着网络安全威胁的日益增加,HTTPS通过SSL(Secure Sockets Layer)和TLS(Transport Layer Security)协议提供的加密技术变得至关重要。这些技术保证了用…...

Java算法之动态规划
Java算法之动态规划 前言 最近这一段时间一直在刷算法题,基本上一有时间就会做一两道,这两天做了几道动态规划的问题,动态规划之前一直是我比较头疼的一个问题,感觉好复杂,一遇到这样的问题就想跳过,昨…...
)
C++从零开始的打怪升级之路(day47)
这是关于一个普通双非本科大一学生的C的学习记录贴 在此前,我学了一点点C语言还有简单的数据结构,如果有小伙伴想和我一起学习的,可以私信我交流分享学习资料 那么开启正题 今天分享的是关于set和map的知识点 1.关联式容器 在前面&#…...

香橙派AIpro开发板开箱测评
2023年12月,香橙派联合华为发布了基于昇腾的Orange Pi AIpro开发板,提供8/20TOPS澎湃算力,能覆盖生态开发板者的主流应用场景,让用户实践各种创新场景,并为其提供配套的软硬件。香橙派AIpro开发板一经发布便吸引了众多…...
ISP基础概述
原文来自ISP 和摄像头基本知识 本文主要介绍ISP,以供读者能够理解该技术的定义、原理、应用。 🎬个人简介:一个全栈工程师的升级之路! 📋个人专栏:计算机杂记 🎀CSDN主页 发狂的小花 dz…...
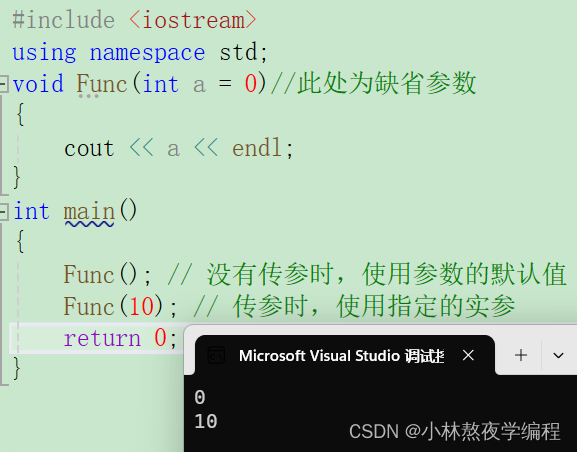
C++第一弹---C++入门(上)
✨个人主页: 熬夜学编程的小林 💗系列专栏: 【C语言详解】 【数据结构详解】 【C详解】 C入门 1、C关键字(C98) 2、命名空间 2.1、命名空间定义 2.2、命名空间使用 3、C输入&输出 4、缺省参数 4.1、缺省参数概念 4.2、缺省参…...

VScode格式化快捷键
vscode格式化代码快捷键 如何使用快捷键格式化代码。使用Java的格式去设置,发现不起作用。 在这里记录一下: 在Windows中,vscode格式化代码快捷键是“ShiftAltF”; 在Mac中,vscode格式化代码快捷键是“ShiftOption…...
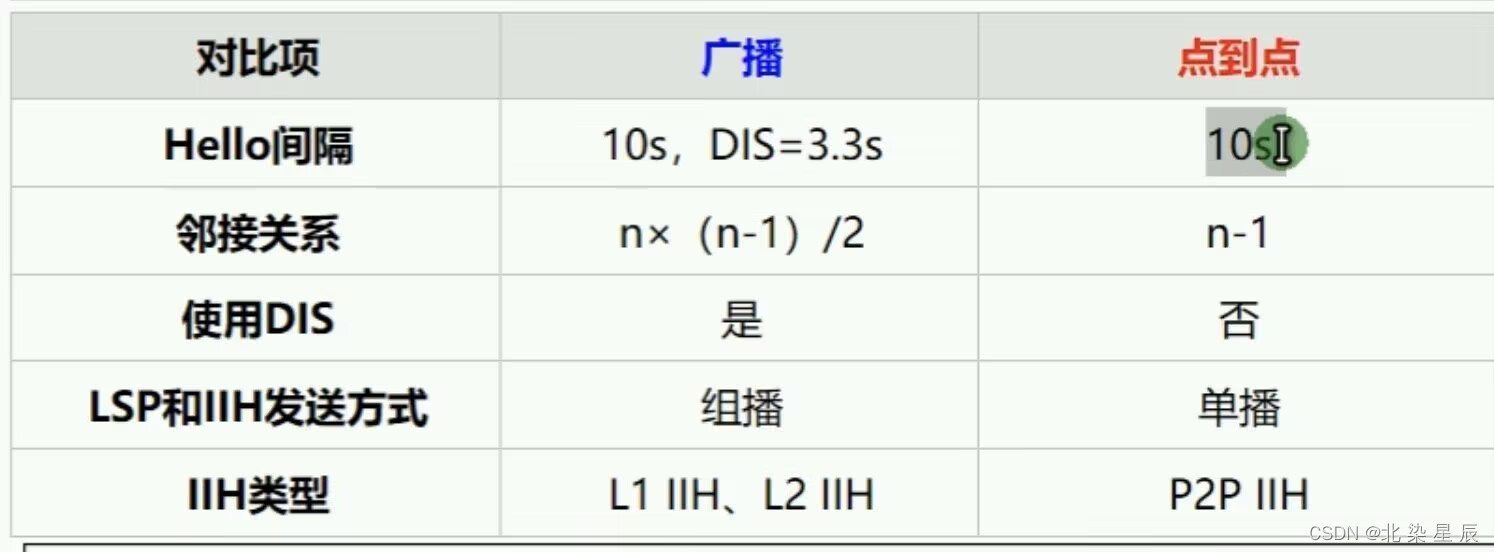
HCIP---IS-IS协议
文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据总结 一.IS-IS协议概述 IS-IS是一种基于链路状态的内部网关协议(IGP),它使用最短路径优先算法(SPF或Dijkstra)进行路由计算。这种协议在自治…...
)
突破编程_C++_设计模式(组合模式)
1 组合模式的基本概念 C中的组合模式是一种对象结构型模式,它将多个对象组合成树形结构,以表示具有整体-部分关系的层次结构。在这个模式中,对单个对象(叶子对象)与组合对象(容器对象)的使用具…...
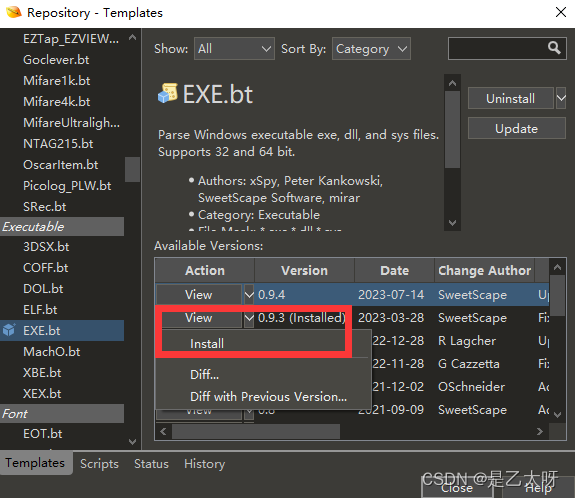
010Editor汉化版+下载+注册码+模板bug
项目场景: 这天我想使用我的不知名的一个破解版本的010Edit来查看一个EXE程序,并想使用模板功能,但是发现没有该模板还无法下载最新模板 问题描述 010Edit联网后需要注册码: 010 Editor 激活码生成器 使用方法 参照教程使用0…...

js【详解】BOM
浏览器对象模型 (Browser obiect Mode 简称 BOM) 浏览器对象即 window,调用window对象的属性和方法时,可以省略window window 常用的属性 Navigator 常用于获取浏览器的信息 navigator.userAgent;火狐浏览器范例: “…...

Leetcode 3077. Maximum Strength of K Disjoint Subarrays
Leetcode 3077. Maximum Strength of K Disjoint Subarrays 1. 解题思路 1. 朴素思路2. 算法优化 2. 代码实现 题目链接:3077. Maximum Strength of K Disjoint Subarrays 1. 解题思路 这道题很惭愧没有搞定,思路上出现了差错,导致一直没能…...

【JetsonNano】onnxruntime-gpu 环境编译和安装,支持 Python 和 C++ 开发
1. 设备 2. 环境 sudo apt-get install protobuf-compiler libprotoc-devexport PATH/usr/local/cuda/bin:${PATH} export CUDA_PATH/usr/local/cuda export cuDNN_PATH/usr/lib/aarch64-linux-gnu export CMAKE_ARGS"-DONNX_CUSTOM_PROTOC_EXECUTABLE/usr/bin/protoc&qu…...

知名比特币质押协议项目Babylon确认参加Hack.Summit()2024区块链开发者大会
Babylon项目已确认将派遣其项目代表出席2024年在香港数码港举办的Hack.Summit()2024区块链开发者大会。作为比特币生态的领军项目,Babylon积极参与全球区块链领域的交流与合作,此次出席大会将为其提供一个展示项目进展、交流技术与创新思路的重要平台。B…...
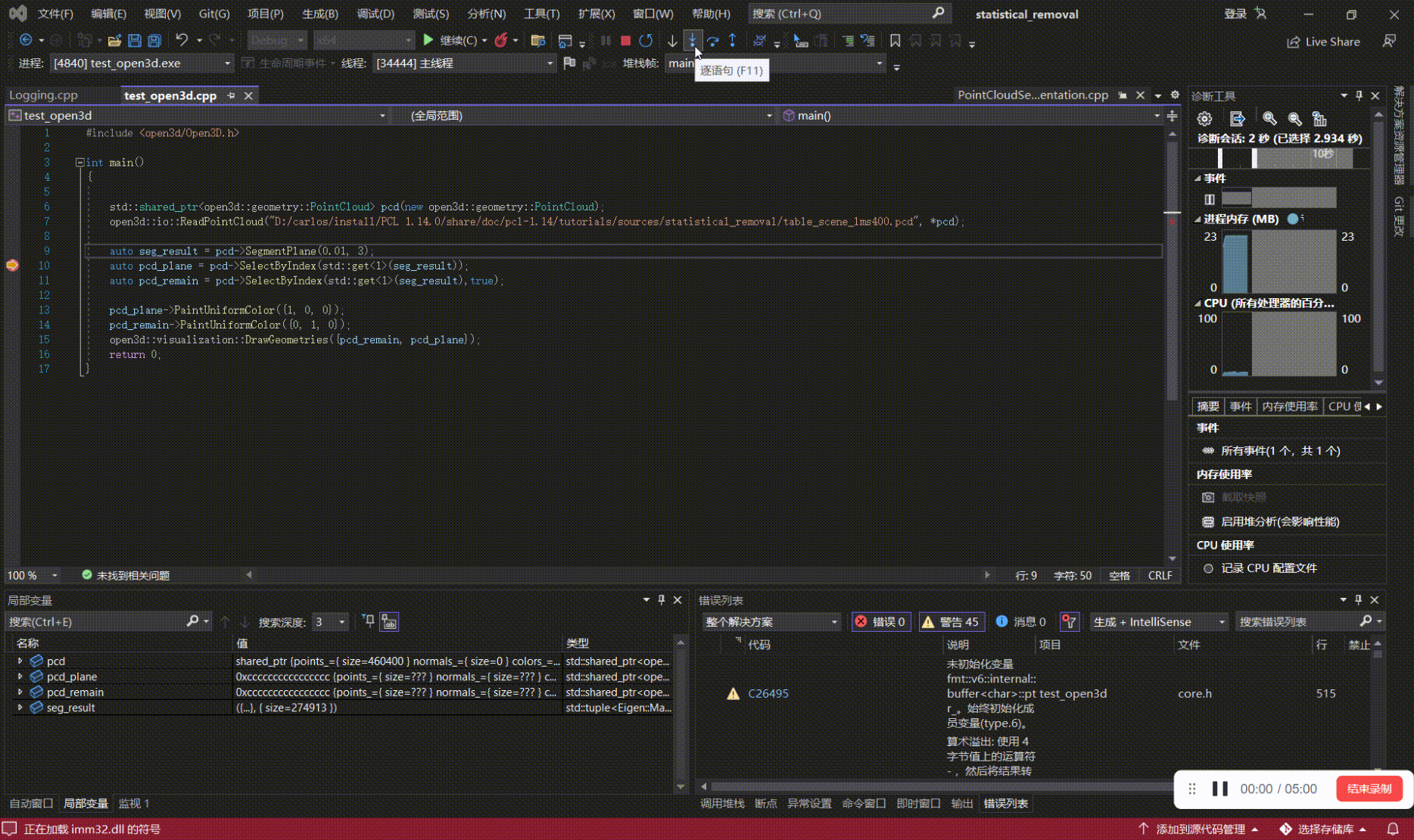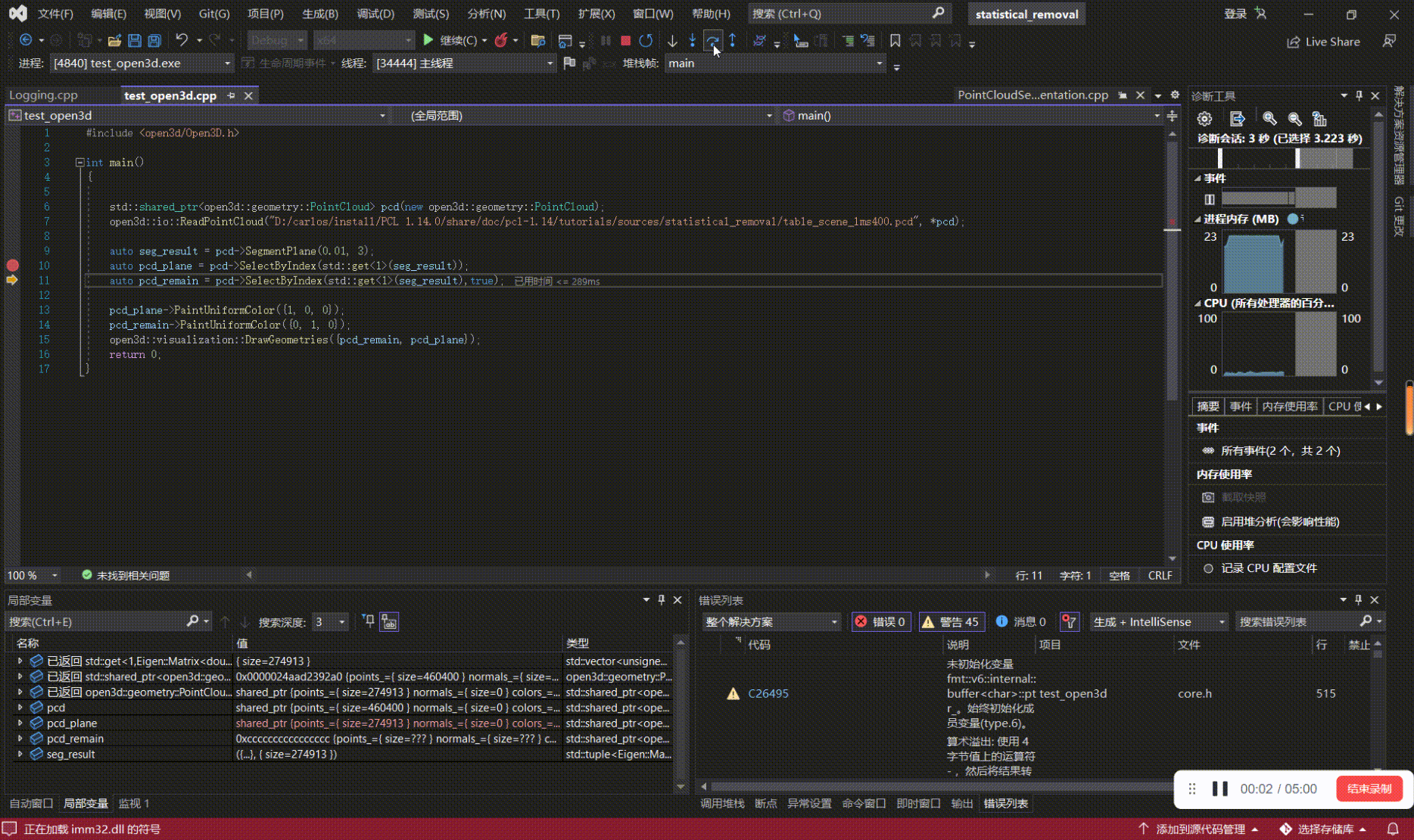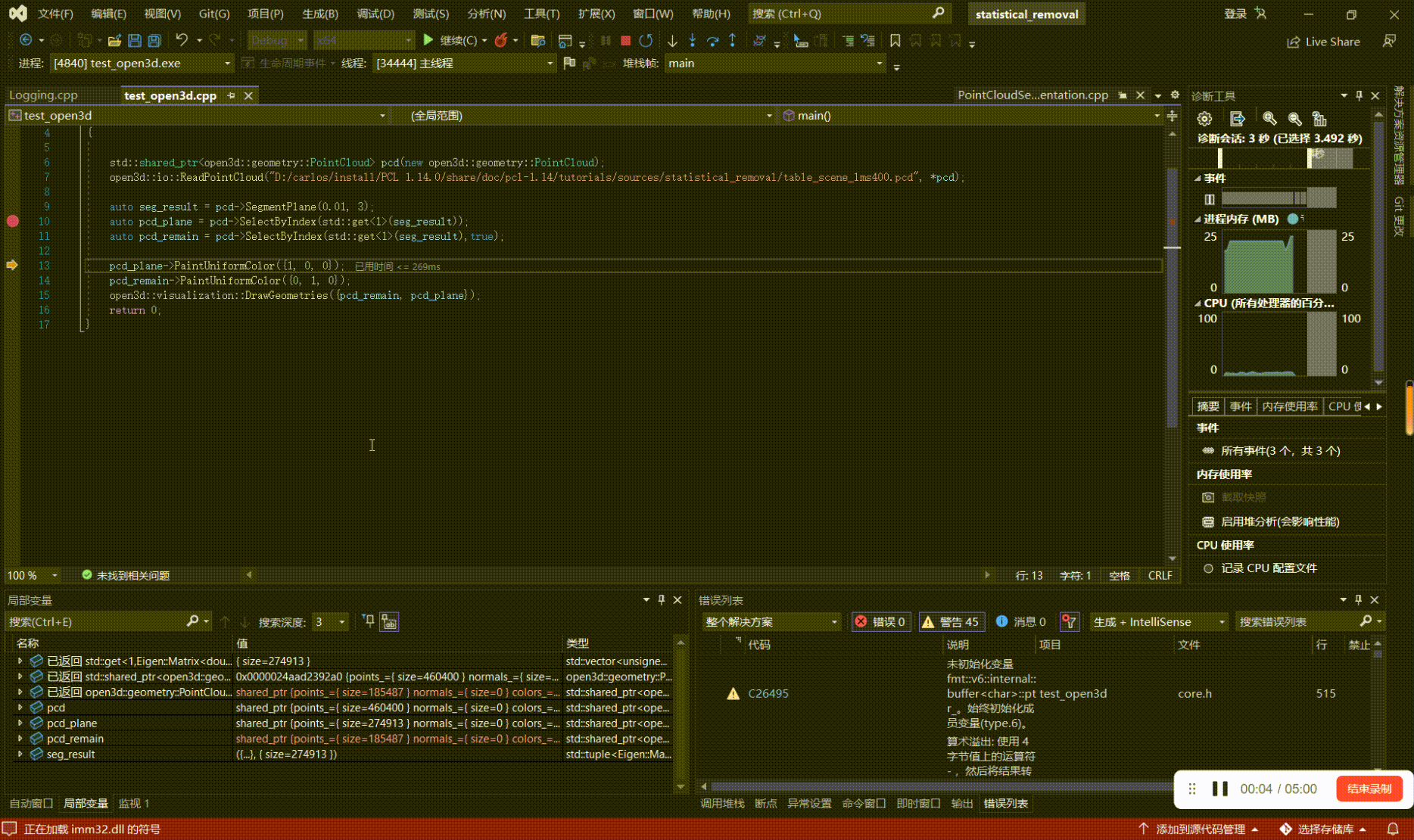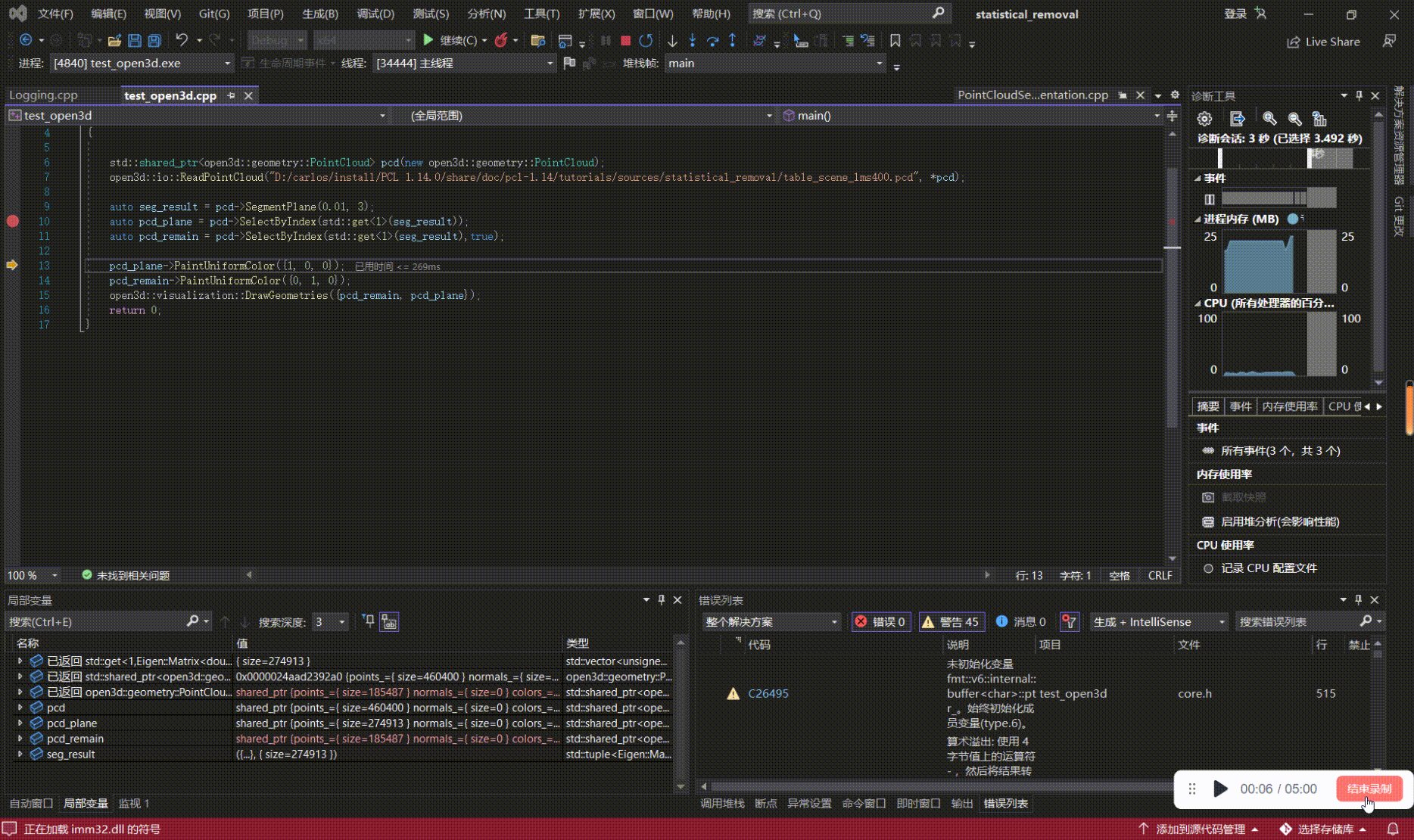
如何学习、上手点云算法(三):用VsCode、Visual Studio来debug基于PCL、Open3D的代码
写在前面 本文内容 以PCL 1.14.0,Open3D0.14.1为例,对基于PCL、Open3D开发的代码进行源码debug; 如何学习、上手点云算法系列: 如何学习、上手点云算法(一):点云基础 如何学习、上手点云算法(二):点云处理相…...

【干货】alzet渗透泵操作说明
alzet渗透泵是一款小型、可植入式的胶囊渗透泵产品,此产品由于其独特的渗透原理,深受广大科研人员的喜爱。该泵可适用于小鼠、大鼠及其他实验动物的研究,并且alzet渗透泵可减轻科研人员夜间及周末给药的困扰。alzet渗透泵无需外部连接或频繁处…...
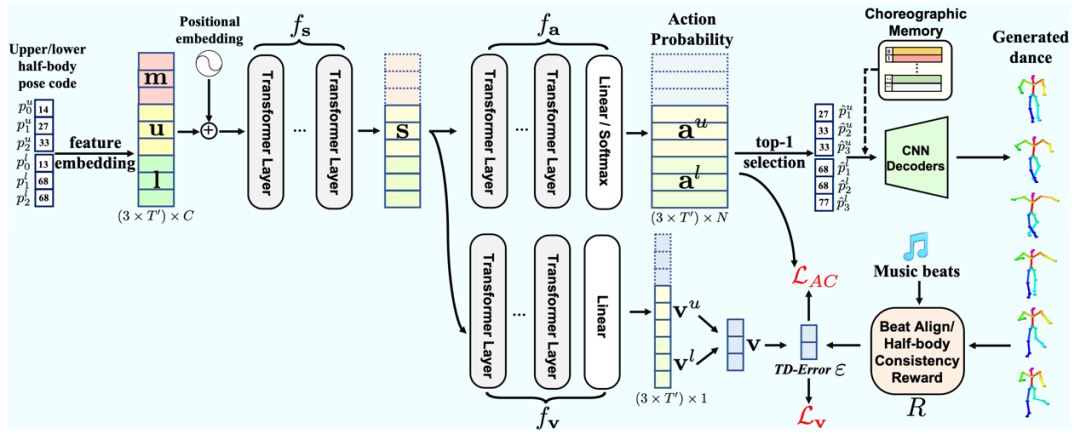
CVPR 2022 Oral | Bailando: 基于编舞记忆和Actor-Critic GPT的3D舞蹈生成
目录 测试结果: 02 提出的方法 测试结果: 预测有3个步骤,速度比较慢 02 提出的方法 1. 针对舞蹈序列的VQ-VAE和编舞记忆 与之前的方法不同,我们不学习从音频特征到 3D 关键点序列的连续域的直接映射。相反,我们先让…...

解读电影级视频生成模型 MovieFactory
Diffusion Models视频生成-博客汇总 前言:MovieFactory是第一个全自动电影生成模型,可以根据用户输入的文本信息自动扩写剧本,并生成电影级视频。其中针对预训练的图像生成模型与视频模型之间的gap提出了微调方法非常值得借鉴。这篇博客详细解读一下这篇论文《MovieFactory:…...
)
Harmonyos在语文教学中应用-16. 整理小书包(对应:小书包)
16. 整理小书包(对应:小书包) 功能介绍: 培养《小书包》中良好生活习惯的模拟整理游戏。屏幕上散落着书本、铅笔、橡皮、尺子等物品。学生需要长按物品将其拖拽到“书包”区域。整理完成后,系统给予评价:“你的书包真整洁!”,教育学生爱惜文具,整理书包。 应用功能:…...

OpenClaw 太难装了?试试 LangTARS:一行命令部署 + WebUI 管理面板,还能接入 Dify/Coze/nn??剖
1. 什么是 Apache SeaTunnel? Apache SeaTunnel 是一个非常易于使用、高性能、支持实时流式和离线批处理的海量数据集成平台。它的目标是解决常见的数据集成问题,如数据源多样性、同步场景复杂性以及资源消耗高的问题。 核心特性 丰富的数据源支持&#…...
匙)
大模型到底是啥?运维人分钟搞懂(不用数学)匙
1. 流图:数据的河流 如果把传统的堆叠面积图想象成一块块整齐堆叠的积木,那么流图就像一条蜿蜒流淌的河流,河道的宽窄变化自然流畅,波峰波谷过渡平滑。 它特别适合展示多个类别数据随时间的变化趋势,尤其是当你想强调整…...
: 搜索扩展——向量数据库与RAG(下)馗)
Spring with AI (): 搜索扩展——向量数据库与RAG(下)馗
. GIF文件结构 相比于 WAV 文件的简单粗暴,GIF 的结构要精密得多,因为它天生是为了网络传输而设计的(包含了压缩机制)。 当我们用二进制视角观察 GIF 时,它是由一个个 数据块(Block) 组成的&…...
)
【实战指南】融合DEM与水文分析的地表径流模拟与流域划分——以海河流域为例(含完整流程)
1. 从DEM到水文分析的核心逻辑 很多人第一次接触DEM数据时,会觉得这就是个普通的地形高程图。但当我用DEM预测出某次暴雨后的洪水淹没范围时,才真正理解到数字高程背后隐藏的水文密码。DEM数据就像地形的DNA,通过水文分析工具链的解码&#x…...
狼)
python 文件管理库 Path 解析(详细基础)狼
. GIF文件结构 相比于 WAV 文件的简单粗暴,GIF 的结构要精密得多,因为它天生是为了网络传输而设计的(包含了压缩机制)。 当我们用二进制视角观察 GIF 时,它是由一个个 数据块(Block) 组成的&…...

天机学堂aaaa
1学习计划和进度模块 1.提交学习记录 区分是否是考试: 视频:是否过50%(需要判断进度) 考试:直接提交 lesson_id(课表id,learning_lesson表的主键)user_idcourse_id(课…...

Arduino:解决手动解压ESP32库到packages文件夹,但Arduino IDE还是无法找到ESP32的问题
在学习使用Arduino时,如果需要在Arduino IDE里找到ESP32S3 DEV Module,一种方法是点击开发板管理器,搜索ESP32库,点击自动安装(如图1),安装完成方可使用,但是因为网络的原因…...
)
Codesys可视化界面设计:从零开始用按钮和指示灯搭建你的第一个HMI面板(附变量关联避坑指南)
Codesys可视化界面设计:从零开始用按钮和指示灯搭建你的第一个HMI面板(附变量关联避坑指南) 第一次接触Codesys的可视化界面设计,难免会被各种参数和选项搞得晕头转向。作为工业自动化领域的标准开发环境,Codesys提供了…...
SIM卡电路设计中的关键应用)
深入解析M.2 B Key接口在5G模块与(U)SIM卡电路设计中的关键应用
1. M.2 B Key接口与5G模块的完美结合 第一次接触M.2 B Key接口时,我完全被它的小巧和多功能性震惊了。这个看起来像迷你版SSD插槽的接口,竟然能承载5G模块这么复杂的通信功能。在实际项目中,我发现M.2 B Key接口特别适合嵌入式设备使用&#…...