ElasticSearch深度分页问题如何解决
文章目录
- 概述
- 解决方法
- 深度分页方式from + size
- 深度分页之scroll
- search_after
- 三种分页方式比较
概述
Elasticsearch 的深度分页问题是指在大数据集上进行大量分页查询时可能导致的性能下降和资源消耗增加的情况。这种情况通常发生在需要访问大量数据的情形下,比如用户进行长时间滚动查看或者需要遍历大量数据的操作。
深度分页问题通常会导致性能下降的原因有以下几点:
- 数据的大量跳过和读取:在深度分页查询中,Elasticsearch 需要跳过大量的文档记录才能到达目标页,这会导致大量的 IO 操作和资源消耗。
- 分布式搜索的成本:在分布式环境下,合并和排序大量数据的成本会很高。
- 数据热点:深度分页可能导致部分节点负载过高,增加了数据热点的风险。
解决方法
- 使用 Scroll API:Elasticsearch 提供了 Scroll API 来支持大数据集的深度分页查询。使用 Scroll API 可以创建一个快照,允许在保持搜索上下文的情况下连续检索大量数据,而不需要重新执行原始查询。这样可以避免深度分页带来的性能问题。
- 使用游标分页:类似于 Scroll API,游标分页也可以用于大数据集的分页查询。它允许客户端在多个请求之间保持打开的搜索上下文,从而避免了深度分页的性能问题。
- 基于数据模型的优化:考虑使用基于数据模型的优化方法,比如预聚合、数据摘要等方式,来提前计算和存储一些聚合结果,从而减少深度分页查询的计算成本。
- 使用游标/分页组合:结合游标和分页的方式,可以在大数据集上进行分页操作而不至于影响性能。
- 优化查询需求:考虑是否真正需要进行大数据集的深度分页操作,是否可以通过其他途径满足业务需求,从而避免深度分页问题。
- 基于数据模型的优化:可以考虑对数据模型进行优化,预先计算和存储一些聚合结果或摘要信息,从而减少深度分页查询的计算成本。
- 使用 Search After:Search After 是一种用于获取某个特定文档之后的文档的方式,可以结合排序字段的值来实现分页操作,避免了跳过大量文档记录的性能开销。
- 避免深度分页:在设计应用程序时,尽量避免需要深度分页的场景,可以通过其他方式满足业务需求,比如聚合查询、更精确的过滤条件等。
- 优化索引设计:合理设计索引结构、字段映射、分片设置等,可以提高搜索性能,从而减轻深度分页带来的性能压力。
- 限制每页返回的文档数量:在进行分页查询时,可以限制每页返回的文档数量,避免一次性返回大量数据,从而减少性能消耗。
总的来说,针对 Elasticsearch 的深度分页问题,需要综合考虑数据访问方式、业务需求以及 Elasticsearch 提供的查询和分页机制,选择合适的方式来解决深度分页问题,并且在实际应用中需要进行充分的性能测试和优化。
在Elasticsearch中进行深度分页操作是一种常见的需求,但是如果使用传统的分页方式会比较耗时,可能会导致性能问题。为了解决这个问题,Elasticsearch提供了一些深度分页方案,主要包括以下几种:
深度分页方式from + size+深度分页之scroll+search_after参数
深度分页方式from + size
es 默认采用的分页方式是 from+ size 的形式,在深度分页的情况下,这种使用方式效率是非常低的,比如我们执行如下查询
GET /student/student/_search
{"query":{"match_all": {}},"from":5000,"size":10
}
意味着 es 需要在各个分片上匹配排序并得到5010条数据,协调节点拿到这些数据再进行排序等处理,然后结果集中取最后10条数据返回。
我们会发现这样的深度分页将会使得效率非常低,因为我只需要查询10条数据,而es则需要执行from+size条数据然后处理后返回。
其次:es为了性能,限制了我们分页的深度,es目前支持的最大的 max_result_window = 10000;也就是说我们不能分页到10000条数据以上。
例如:
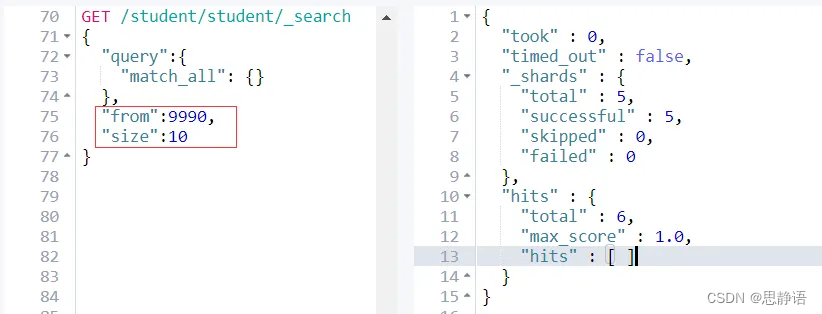
from + size <= 10000所以这个分页深度依然能够执行。
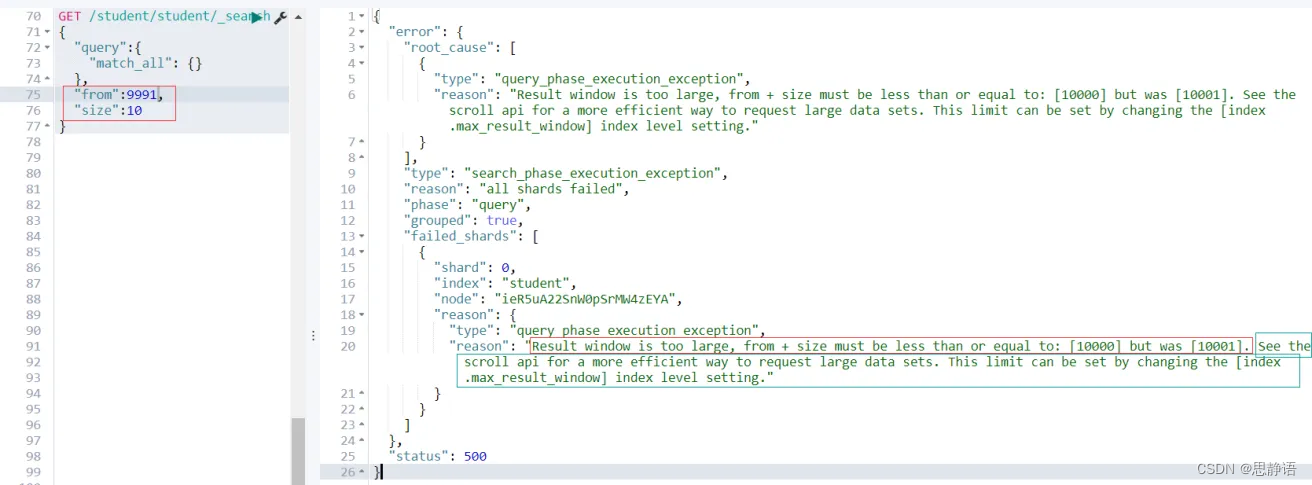
继续看上图,当size + from > 10000;es查询失败,并且提示
Result window is too large, from + size must be less than or equal to: [10000] but was [1001]
接下来看还有一个很重要的提示
See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting
有关请求大数据集的更有效方法,请参阅滚动api。这个限制可以通过改变[索引]来设置。哦呵,原来es给我们提供了另外的一个API scroll。难道这个 scroll 能解决深度分页问题?
深度分页之scroll
在es中如果我们分页要请求大数据集或者一次请求要获取较大的数据集,scroll都是一个非常好的解决方案。
使用scroll滚动搜索,可以先搜索一批数据,然后下次再搜索一批数据,以此类推,直到搜索出全部的数据来scroll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的。每次发送scroll请求,我们还需要指定一个scroll参数,指定一个时间窗口,每次搜索请求只要在这个时间窗口内能完成就可以了。
一个滚屏搜索允许我们做一个初始阶段搜索并且持续批量从Elasticsearch里拉取结果直到没有结果剩下。这有点像传统数据库里的cursors(游标)。
滚屏搜索会及时制作快照。这个快照不会包含任何在初始阶段搜索请求后对index做的修改。它通过将旧的数据文件保存在手边,所以可以保护index的样子看起来像搜索开始时的样子。这样将使得我们无法得到用户最近的更新行为。
scroll的使用很简单
执行如下curl,每次请求两条。可以定制 scroll = 5m意味着该窗口过期时间为5分钟。
GET /student/student/_search?scroll=5m
{"query": {"match_all": {}},"size": 2
}
{"_scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAC0YFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtGRZpZVI1dUEyMlNuVzBwU3JNVzR6RVlBAAAAAAAALRsWaWVSNXVBMjJTblcwcFNyTVc0ekVZQQAAAAAAAC0aFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtHBZpZVI1dUEyMlNuVzBwU3JNVzR6RVlB","took" : 0,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 6,"max_score" : 1.0,"hits" : [{"_index" : "student","_type" : "student","_id" : "5","_score" : 1.0,"_source" : {"name" : "fucheng","age" : 23,"class" : "2-3"}},{"_index" : "student","_type" : "student","_id" : "2","_score" : 1.0,"_source" : {"name" : "xiaoming","age" : 25,"class" : "2-1"}}]}
}
在返回结果中,有一个很重要的
_scroll_id
在后面的请求中我们都要带着这个 scroll_id 去请求。
现在student这个索引中共有6条数据,id分别为 1, 2, 3, 4, 5, 6。当我们使用 scroll 查询第4次的时候,返回结果应该为kong。这时我们就知道已经结果集已经匹配完了。
继续执行3次结果如下三图所示。
GET /_search/scroll
{"scroll":"5m","scroll_id":"DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAC0YFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtGRZpZVI1dUEyMlNuVzBwU3JNVzR6RVlBAAAAAAAALRsWaWVSNXVBMjJTblcwcFNyTVc0ekVZQQAAAAAAAC0aFmllUjV1QTIyU25XMHBTck1XNHpFWUEAAAAAAAAtHBZpZVI1dUEyMlNuVzBwU3JNVzR6RVlB"
}
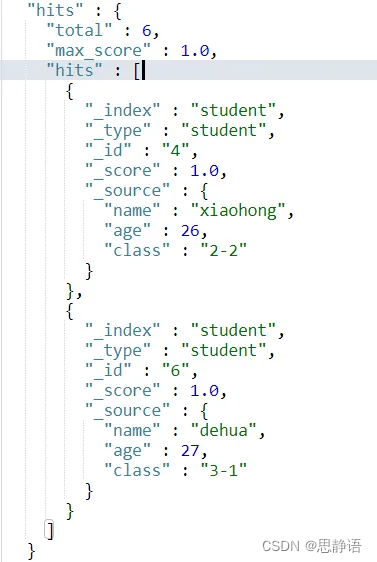

由结果集我们可以发现最终确实分别得到了正确的结果集,并且正确的终止了scroll。
search_after
from + size的分页方式虽然是最灵活的分页方式,但是当分页深度达到一定程度将会产生深度分页的问题。scroll能够解决深度分页的问题,但是其无法实现实时查询,即当scroll_id生成后无法查询到之后数据的变更,因为其底层原理是生成数据的快照。这时 search_after应运而生。其是在es-5.X之后才提供的。
search_after 是一种假分页方式,根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,但是只要能表示其唯一性就可以。
为了演示,我们需要给上文中的student索引增加一个uid字段表示其唯一性。
执行如下查询:
GET /student/student/_search
{"query":{"match_all": {}},"size":2,"sort":[{"uid": "desc"}]
}
结果集:
View Code
下一次分页,需要将上述分页结果集的最后一条数据的值带上。
GET /student/student/_search
{"query":{"match_all": {}},"size":2,"search_after":[1005],"sort":[{"uid": "desc"}]
}
这样我们就使用search_after方式实现了分页查询。
三种分页方式比较
| 分页方式 | 性能 | 优点 | 缺点 | 场景 |
|---|---|---|---|---|
| from + size | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll | 中 | 解决了深度分页问题 | 无法反应数据的实时性(快照版本) | 维护成本高,需要维护一个 scroll_id海量数据的导出(比如笔者刚遇到的将es中20w的数据导入到excel)需要查询海量结果集的数据 |
| search_after | 高 | 性能最好不存在深度分页问题能够反映数据的实时变更 | 实现复杂,需要有一个全局唯一的字段连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果 | 海量数据的分页 |
相关文章:
ElasticSearch深度分页问题如何解决
文章目录 概述解决方法深度分页方式from size深度分页之scrollsearch_after 三种分页方式比较 概述 Elasticsearch 的深度分页问题是指在大数据集上进行大量分页查询时可能导致的性能下降和资源消耗增加的情况。这种情况通常发生在需要访问大量数据的情形下,比如用…...

景安空间不支持指定运行目录tp5
/WEB/public/.htaccess配置 <IfModule mod_rewrite.c> Options FollowSymlinks -Multiviews RewriteEngine on RewriteCond %{REQUEST_FILENAME} !-d RewriteCond %{REQUEST_FILENAME} !-f RewriteRule ^(.*)$ index.php?s$1 [QSA,PT,L] </IfModule>. 2./WEB/.ht…...
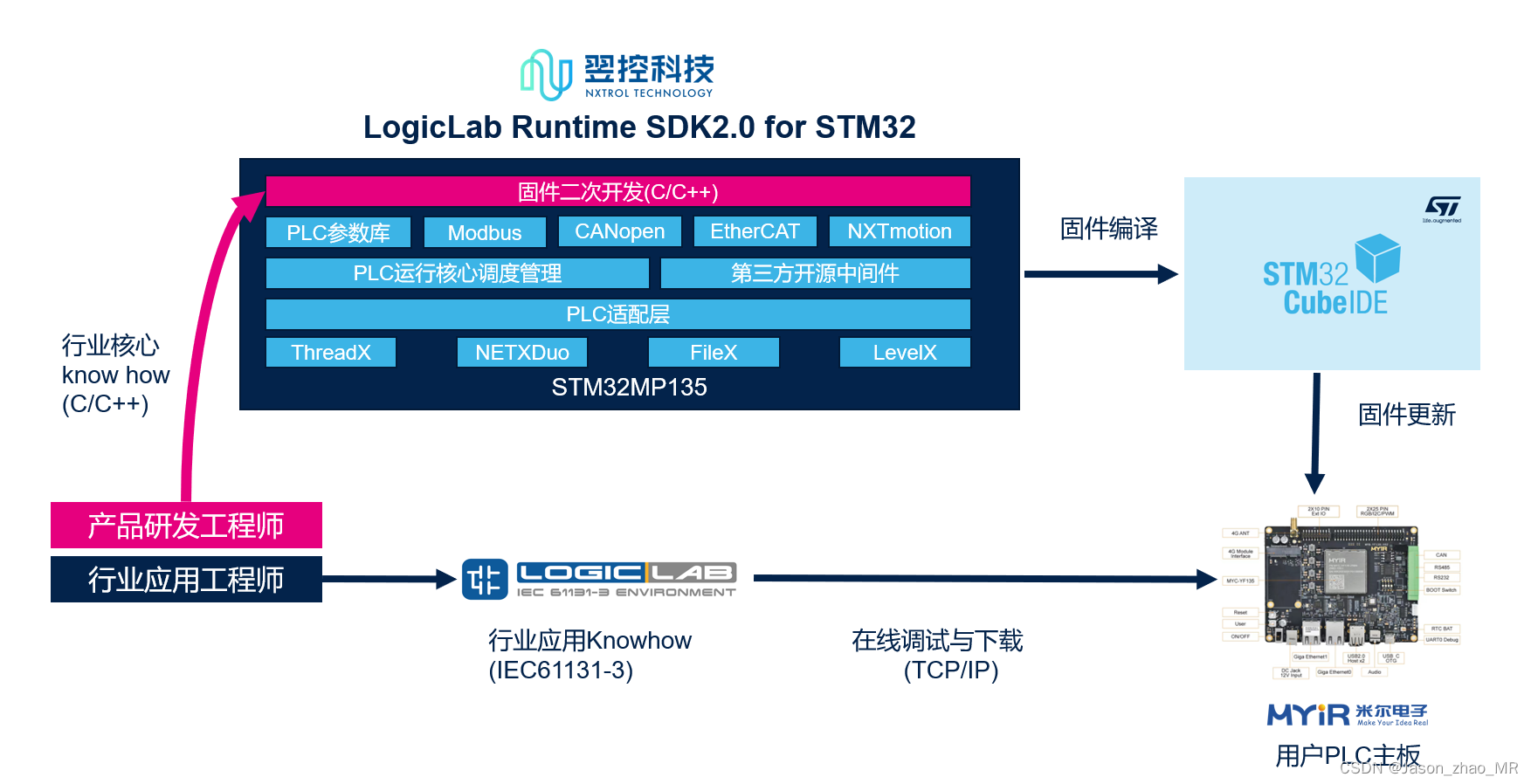
开放式高实时高性能PLC控制器解决方案-基于米尔电子STM32MP135
前言 随着工业数字化进程加速与IT/OT深入融合,不断增加的OT核心数据已经逐步成为工业自动化行业的核心资产,而OT层数据具备高实时、高精度、冗余度高、数据量大等等特点,如何获取更加精准的OT数据对数字化进程起到至关重要的作用,…...

【MySQL】-MVCC多版本并发控制
1、当前读 select 不加锁状态,当前读快照读 2、快照读 在select加锁下,读取数据后,形成快照。每个事务都会形成自己的快照内容 SELECT * FROM xx_table LOCK IN SHARE MODE;SELECT * FROM xx_table FOR UPDATE;INSERT INTO xx_table ...D…...
mangoDB:2024安装
mangoDB:2024安装 mangoDB: 下载链接 取消勾选 配置环境变量 启动服务 同级目录下创建一个db文件夹 然后执行命令,启动服务 mongod --dbpath D:\environment\mango\db访问http://localhost:27017/ 出现下面的就是安装成功 2然后在管理员权限下给mango服务重…...
微服务day06-Docker
Docker 大型项目组件较多,运行环境也较为复杂,部署时会碰到一些问题: 依赖关系复杂,容易出现兼容性问题 开发、测试、生产环境有差异 1.什么是Docker? 大型项目组件很多,运行环境复杂,部署时会遇到各种…...

喜马拉雅后端一面
1.自我介绍 2.项目拷打 2.1 为什么要用分布式锁? 2.2 用唯一索引能不能保证一人一单,和你的分布式锁比起来怎么用? 2.3 分布式锁是在事务开启前加还是事务开始后 2.4 讲讲你的布隆过滤器是怎么自定义实现的 2.5 讲讲你的Redis和数据库的数据一…...

Open3D 生成空间3D椭圆点云
目录 一、算法原理二、代码实现三、结果展示本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫与GPT。 一、算法原理 设椭圆在 X O Y XOY XO...

huggingface快速下载
方法一:但是这个方法会卡主 pip install -U huggingface_hub pip install -U hf-transfer export HF_HUB_ENABLE_HF_TRANSFER1 (Linux,可以写入bashrc或zshrc) export HF_ENDPOINThttps://hf-mirror.com huggingface-cli dow…...
Java - Spring MVC 实现跨域资源 CORS 请求
据我所知道的是有三种方式:Tomcat 配置、拦截器设置响应头和使用 Spring MVC 4.2。 设置 Tomcat 这种方式就是引用别人封装好的两个 jar 包,配置一下web.xml就行了。我也并不推荐,这里放两个我在网上找到的配置相关文章,感兴趣可…...

宝妈做什么兼职副业好?适合她们的有哪些?执行力才是关键
现在的宝妈,生完孩子以后,尤其是宝宝上幼儿园之前,为了照顾宝宝,不能去外面上班,所以很多妈妈都为孩子做出了很大的牺牲,但同时又要承担着家庭经济的压力,尤其是现在注重个性独立的时代…...
RK3568 xhci主控挂死问题
串口日志 rootjenet:~# [18694.115430] xhci-hcd xhci-hcd.1.auto: xHCI host not responding to stop endpoint command. [18694.125667] xhci-hcd xhci-hcd.1.auto: xHCI host controller not responding, assume dead [18694.125977] xhci-hcd xhci-hcd.1.auto: HC died; c…...

CircuitBreaker断路器(服务熔断,服务降级)
分布式系统面临的问题: 复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免地失败。 1.服务雪崩 多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务ÿ…...
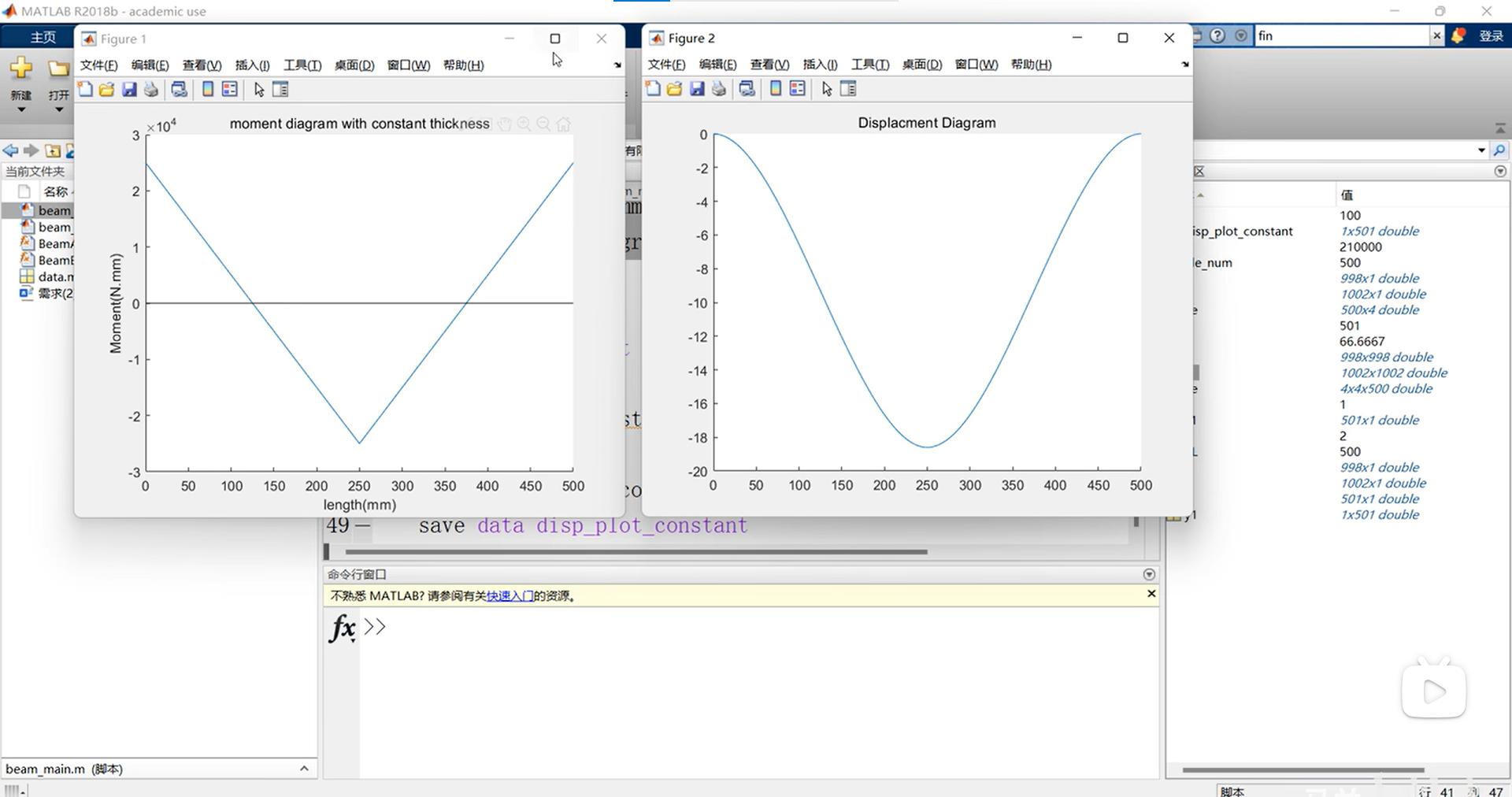
平面纯弯梁单元Matlab有限元编程 |欧拉梁单元| 简支梁|悬臂梁|弯矩图 |变形图| Matlab源码 | 视频教程
专栏导读 作者简介:工学博士,高级工程师,专注于工业软件算法研究本文已收录于专栏:《有限元编程从入门到精通》本专栏旨在提供 1.以案例的形式讲解各类有限元问题的程序实现,并提供所有案例完整源码;2.单元…...

LeetCode_Hot100_栈_155最小栈_Python
题目 设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。 实现 MinStack 类: MinStack() 初始化堆栈对象。void push(int val) 将元素val推入堆栈。void pop() 删除堆栈顶部的元素。int top() 获取堆栈顶部的元素。i…...

力扣每日一题 找出数组的第 K 大和 小根堆 逆向思维(TODO:二分+暴搜)
Problem: 2386. 找出数组的第 K 大和 文章目录 思路复杂度💖 小根堆💖 TODO:二分 暴搜 思路 👨🏫 灵神题解 复杂度 时间复杂度: 添加时间复杂度, 示例: O ( n ) O(n) O(n) 空间复杂度: 添加空间复杂…...
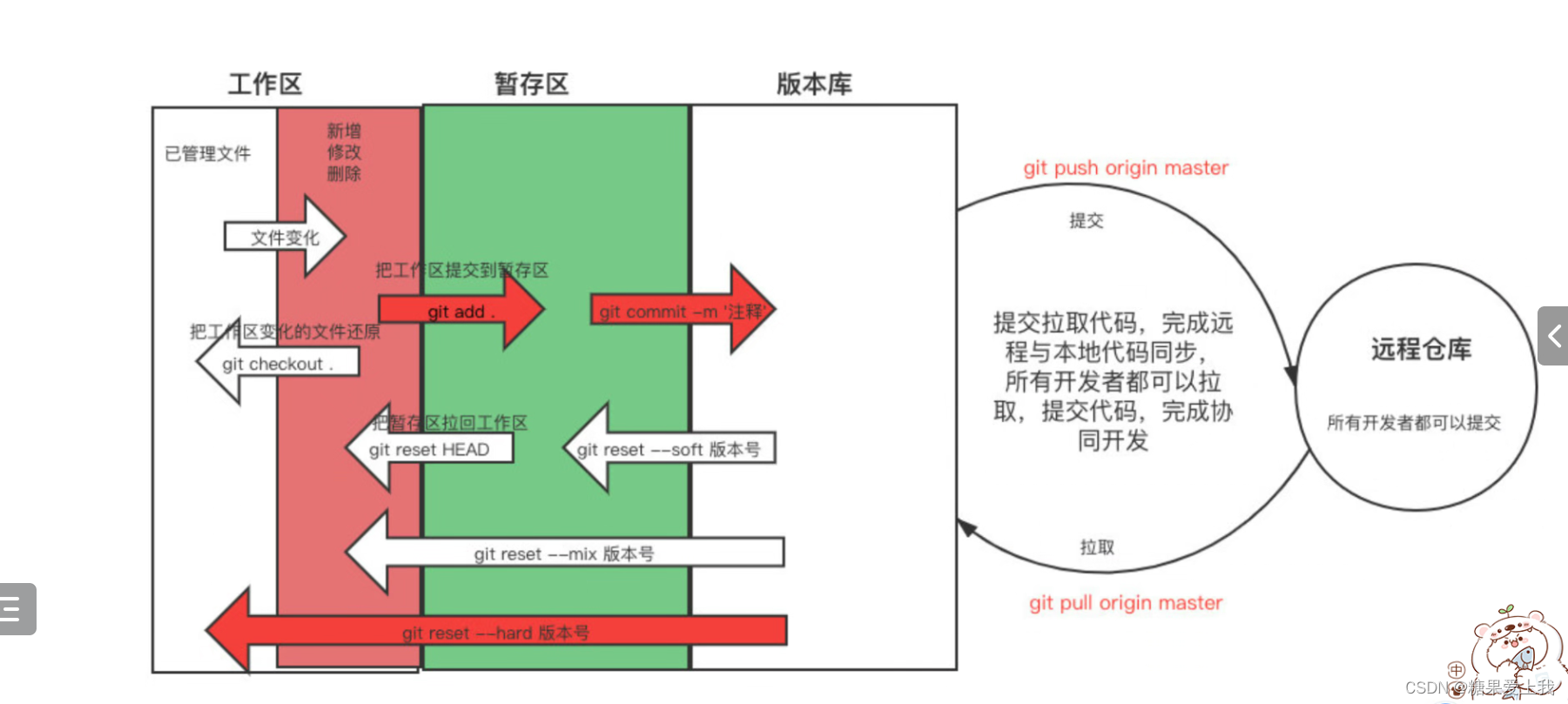
Git的介绍
导出项目依赖 # 以后项目给别人需要导出项目依赖,放在项目路径下,以后在运行项目前,先安装依赖 一般约定俗成都叫 requirements.txt,但是会有别的:req.txt | dev.txt # 两种方式: 1、虚拟环境所有装的第三方&…...

websocket+心跳
1.直接上代码 let ws //websocket实例 let lockReconnect false //避免重复连接 let wsUrl //初始化websocket getWebSocketurl() async function getWebSocketurl() {try {// const data await getInfo()sid.value localStorage.getItem(Refresh-Token)wsUrl ws://192.…...
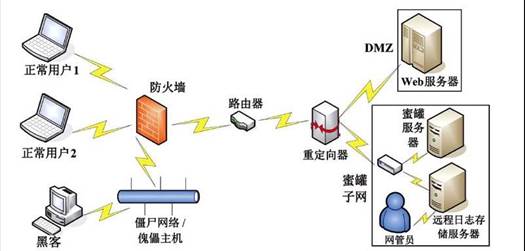
人工智能在信息系统安全中的运用
一、 概述 对于企业和消费者来讲,人工智能是非常有用的工具,那又该如何使用人工智能技术来保护敏感信息?通过快速处理数据并预测分析,AI可以完成从自动化系统到保护信息的所有工作。尽管有些黑客利用技术手段来达到自己的目的,但…...

[python3] 装饰器
装饰器是Python中一种特殊的语法,用于在不修改原函数代码的情况下,为函数添加额外的功能。 装饰器基于函数闭包和函数作为第一类对象的特性实现。 原理: Python中的装饰器本质上是一个函数或类,它接受一个函数作为参数࿰…...

IP5385:一颗芯片实现30W-100W全协议兼容的移动电源革命
1. 一颗芯片如何颠覆移动电源行业? 还记得五年前出门必带的"充电宝三件套"吗?充电宝本体、专用充电线、还有那个永远找不到的充电头。现在我的背包里只需要一根C to C线,就能给手机、笔记本甚至无人机快速回血——这背后正是IP5385…...

【CTF】【二进制分析】深入解析JPG文件结构:从段标识到霍夫曼编码
1. JPG文件结构基础:二进制视角下的图片解剖 第一次用WinHex打开JPG文件时,满屏的十六进制代码可能会让你头皮发麻。但别担心,这些看似杂乱的数据其实遵循着严格的规范。就像拆解乐高积木,只要找到关键连接点,整个结构…...

终极城通网盘解析指南:3步获取高速直连地址的完整教程
终极城通网盘解析指南:3步获取高速直连地址的完整教程 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否曾经因为城通网盘的龟速下载而抓狂?面对那些需要等待数小时才能完成…...

手把手教你用Qwen3-ASR-0.6B:上传音频秒出文字,无需代码配置
手把手教你用Qwen3-ASR-0.6B:上传音频秒出文字,无需代码配置 还在为语音转文字发愁吗?下载软件、配置环境、调试代码、处理报错……一套流程下来,热情早就被消磨殆尽了。今天,我要给你介绍一个完全不同的体验…...

优必选上调出货目标至5000台:万台级量产在即,供应链企业专利“补位”正当时
优必选上调出货目标至5000台:万台级量产在即,供应链企业专利“补位”正当时成都余行10000项创新清单,助零部件企业快速切入人形机器人万亿供应链2026年,优必选将这一年定位为“大规模商业化”之年。Walker S系列出货目标从原计划的…...

基于Qwen3-ASR-1.7B的语音搜索系统:Elasticsearch集成方案
基于Qwen3-ASR-1.7B的语音搜索系统:Elasticsearch集成方案 语音搜索正在改变我们获取信息的方式,但如何让机器准确理解语音内容并快速返回相关结果?本文将带你构建一个高效的语音搜索系统,结合Qwen3-ASR-1.7B的语音识别能力和Elas…...

智能合约安全
智能合约安全:区块链世界的守护盾 在区块链技术快速发展的今天,智能合约已成为去中心化应用(DApp)的核心组件。由于其不可篡改的特性,一旦部署后漏洞难以修复,智能合约的安全问题显得尤为重要。从The DAO事…...

Go语言的runtime.MemProfile
Go语言作为一门高效、简洁的编程语言,其内存管理机制一直是开发者关注的焦点。runtime.MemProfile作为Go运行时提供的强大工具,能够帮助开发者深入分析程序的内存使用情况,从而优化性能、排查内存泄漏等问题。本文将围绕runtime.MemProfile展…...

GPT-OSS-20B快速部署实战:从下载到对话的完整流程
GPT-OSS-20B快速部署实战:从下载到对话的完整流程 1. 引言:为什么选择GPT-OSS-20B? 在当今AI技术快速发展的时代,找到一个既强大又易于部署的开源大语言模型并非易事。GPT-OSS-20B作为OpenAI推出的重量级开放模型,凭…...

音视频质量评估
音视频质量评估:数字时代的视听体验守护者 在数字化时代,音视频内容已成为人们日常生活的重要组成部分,无论是流媒体平台、视频会议,还是在线教育,高质量的视听体验直接影响用户满意度。由于网络环境、编码技术、设备…...