Python算法题集_搜索二维矩阵
Python算法题集_搜索二维矩阵
- 题74:搜索二维矩阵
- 1. 示例说明
- 2. 题目解析
- - 题意分解
- - 优化思路
- - 测量工具
- 3. 代码展开
- 1) 标准求解【矩阵展开为列表+二分法】
- 2) 改进版一【行*列区间二分法】
- 3) 改进版二【第三方模块】
- 4. 最优算法
- 5. 相关资源
本文为Python算法题集之一的代码示例
题74:搜索二维矩阵
1. 示例说明
-
给你一个满足下述两条属性的
m x n整数矩阵:- 每行中的整数从左到右按非严格递增顺序排列。
- 每行的第一个整数大于前一行的最后一个整数。
给你一个整数
target,如果target在矩阵中,返回true;否则,返回false。示例 1:
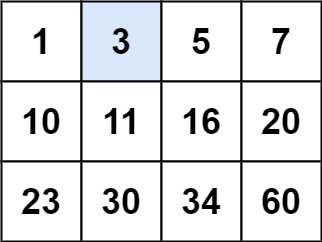
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3 输出:true示例 2:
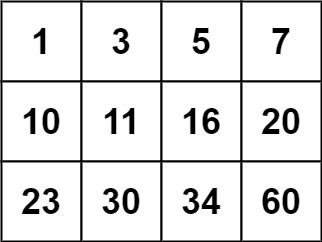
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 13 输出:false提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 100-104 <= matrix[i][j], target <= 104
2. 题目解析
- 题意分解
- 本题是在已排序二维矩阵中查找目标数字
- 最快方式就是二分法
- 优化思路
-
通常优化:减少循环层次
-
通常优化:增加分支,减少计算集
-
通常优化:采用内置算法来提升计算速度
-
分析题目特点,分析最优解
-
本题的已排序二维矩阵可以连成排序一维列表,实现一维列表二分法
-
本题的二维矩阵首尾可以连成排序一维列表,定位具体行之后,在具体行中再进行二分查找
-
可以考虑使用排序列表操作模块
bisect
-
- 测量工具
- 本地化测试说明:LeetCode网站测试运行时数据波动很大【可把页面视为功能测试】,因此需要本地化测试解决数据波动问题
CheckFuncPerf(本地化函数用时和内存占用测试模块)已上传到CSDN,地址:Python算法题集_检测函数用时和内存占用的模块- 本题本地化超时测试用例自己生成,详见章节【最优算法】,代码文件包含在【相关资源】中
3. 代码展开
1) 标准求解【矩阵展开为列表+二分法】
将矩阵展开为列表,再通过二分法查找目标数值是否存在
页面功能测试,马马虎虎,超过53%
import CheckFuncPerf as cfpclass Solution:def searchMatrix_base(self, matrix, target):if not matrix:return Falseimaxrow, imaxcol, listval = len(matrix), len(matrix[0]), []for iIdx in range(len(matrix)):listval.extend(matrix[iIdx])ileft, iright = 0, len(listval) - 1while ileft <= iright:imid = (iright - ileft) // 2 + ileftif target == listval[imid]:return Trueif target < listval[imid]:iright = imid - 1else:ileft = imid + 1return FalseaSolution = Solution()
result = cfp.getTimeMemoryStr(aSolution.searchMatrix_base, mapnums, itarget)
print(result['msg'], '执行结果 = {}'.format(result['result']))# 运行结果
函数 searchMatrix_base 的运行时间为 12768.90 ms;内存使用量为 467828.00 KB 执行结果 = True
2) 改进版一【行*列区间二分法】
将下标换算为行*最大列数+列,将矩阵换算为0 -> 行 * 列的线性区间,在这个区间通过二分法查找目标数值是否存在
页面功能测试,马马虎虎,超过33%
import CheckFuncPerf as cfpclass Solution:def searchMatrix_ext1(self, matrix, target):if not matrix:return Falseimaxrow, imaxcol = len(matrix), len(matrix[0])ileft, iright = 0, imaxrow * imaxcol - 1while ileft <= iright:imid = (ileft + iright) // 2mid_row, mid_col = imid // imaxcol, imid % imaxcolif matrix[mid_row][mid_col] == target:return Trueelif matrix[mid_row][mid_col] < target:ileft = imid + 1elif matrix[mid_row][mid_col] > target:iright = imid - 1return FalseaSolution = Solution()
result = cfp.getTimeMemoryStr(aSolution.searchMatrix_ext1, mapnums, itarget)
print(result['msg'], '执行结果 = {}'.format(result['result']))# 运行结果
函数 searchMatrix_ext1 的运行时间为 0.00 ms;内存使用量为 12.00 KB 执行结果 = True
3) 改进版二【第三方模块】
将矩阵展开为列表,再使用排序列表操作模块bisect来查找插入位置
页面功能测试,性能一般,超过82%
import CheckFuncPerf as cfpclass Solution:def searchMatrix_ext2(self, matrix, target):if not matrix:return Falseimaxrow, imaxcol, listval = len(matrix), len(matrix[0]), []for iIdx in range(len(matrix)):listval.extend(matrix[iIdx])from bisect import bisect_leftipos = bisect_left(listval, target)if ipos == imaxrow * imaxcol:return Falsereturn listval[ipos] == targetaSolution = Solution()
result = cfp.getTimeMemoryStr(aSolution.searchMatrix_ext2, mapnums, itarget)
print(result['msg'], '执行结果 = {}'.format(result['result']))# 运行结果
函数 searchMatrix_ext2 的运行时间为 0.00 ms;内存使用量为 12.00 KB 执行结果 = True
4. 最优算法
根据本地日志分析,最优算法为第2种方式【行*列区间二分法】searchMatrix_ext1
本题测试数据,似乎能推出以下结论:
- 二分法查询性能非常夸张,简直是瞬间定位【1亿的数组,1毫秒定位】
- 数据的迁移【从矩阵->列表】耗时耗内存,这也是
大数据兴起的原因之一【数据的迁移代价远高于计算代价】 - 第三方模块的函数消耗内存非常小
import random
imaxrow, imaxcol, istart = 10000, 10000, 0
mapnums = [[0 for x in range(imaxcol)] for y in range(imaxrow)]
for irow in range(imaxrow):for icol in range(imaxcol):istart += random.randint(0, 6)mapnums[irow][icol] = istart
itarget = mapnums[imaxrow//2][imaxcol//2]
aSolution = Solution()
result = cfp.getTimeMemoryStr(aSolution.searchMatrix_base, mapnums, itarget)
print(result['msg'], '执行结果 = {}'.format(result['result']))
result = cfp.getTimeMemoryStr(aSolution.searchMatrix_ext1, mapnums, itarget)
print(result['msg'], '执行结果 = {}'.format(result['result']))
result = cfp.getTimeMemoryStr(aSolution.searchMatrix_ext2, mapnums, itarget)
print(result['msg'], '执行结果 = {}'.format(result['result']))# 算法本地速度实测比较
函数 searchMatrix_base 的运行时间为 12768.90 ms;内存使用量为 467828.00 KB 执行结果 = True
函数 searchMatrix_ext1 的运行时间为 0.00 ms;内存使用量为 12.00 KB 执行结果 = True
函数 searchMatrix_ext2 的运行时间为 6336.15 ms;内存使用量为 1508.00 KB 执行结果 = True
5. 相关资源
本文代码已上传到CSDN,地址:Python算法题源代码_LeetCode(力扣)_搜索二维矩阵
一日练,一日功,一日不练十日空
may the odds be ever in your favor ~
相关文章:
Python算法题集_搜索二维矩阵
Python算法题集_搜索二维矩阵 题74:搜索二维矩阵1. 示例说明2. 题目解析- 题意分解- 优化思路- 测量工具 3. 代码展开1) 标准求解【矩阵展开为列表二分法】2) 改进版一【行*列区间二分法】3) 改进版二【第三方模块】 4. 最优算法5. 相关资源 本文为Python算法题集之…...
)
学习笔记:顺序表和链表(一、顺序表)
首先来个导言: 1.数组的优势:下标的随机访问,物理空间连续。数组指针用[ ]或者 * , 结构体指针用 - > 2.书写习惯 test.c写出主体框架 QelList.c写出结构体、头文件、函数声明 QelList.c写出函数的实现 3.挪动:如果从前…...

Midjourney从入门到实战:图像生成命令及参数详解
目录 0 专栏介绍1 Midjourney Bot常用命令2 Midjourney绘图指令格式3 Midjourney绘图指令参数3.1 模型及版本3.2 画面比例3.3 风格化3.4 图片质量3.5 混乱值3.6 随机数种子3.7 重复贴图3.8 停止3.8 垫图权重3.9 提示词权重分割 0 专栏介绍 🔥Midjourney是目前主流的…...
C语言分析基础排序算法——插入排序
目录 插入排序 直接插入排序 希尔排序 希尔排序基本思路解析 希尔排序优化思路解析 完整希尔排序文件 插入排序 直接插入排序 所谓直接插入排序,即每插入一个数据和之前的数据进行大小比较,如果较大放置在后面,较小放置在前面&#x…...
海格里斯HEGERLS智能托盘四向车系统为物流仓储自动化升级提供新答案
随着实体企业面临需求多样化、订单履行实时化、商业模式加速迭代等挑战,客户对物流仓储解决方案的需求也逐渐趋向于柔性化、智能化。作为近十年来发展起来的新型智能仓储设备,四向车系统正是弥补了先前托盘搬运领域柔性解决方案的空白。随着小车本体设计…...

SQLiteC/C++接口详细介绍-sqlite3类(一)
上一篇:SQLiteC/C接口简介 下一篇:SQLiteC/C接口详细介绍(二) 引言: SQLite C/C 数据库接口是一个流行的SQLite库使用形式,它允许开发者在C和C代码中嵌入 SQLite 基本功能的解决方案。通过 SQLite C/C 数据…...
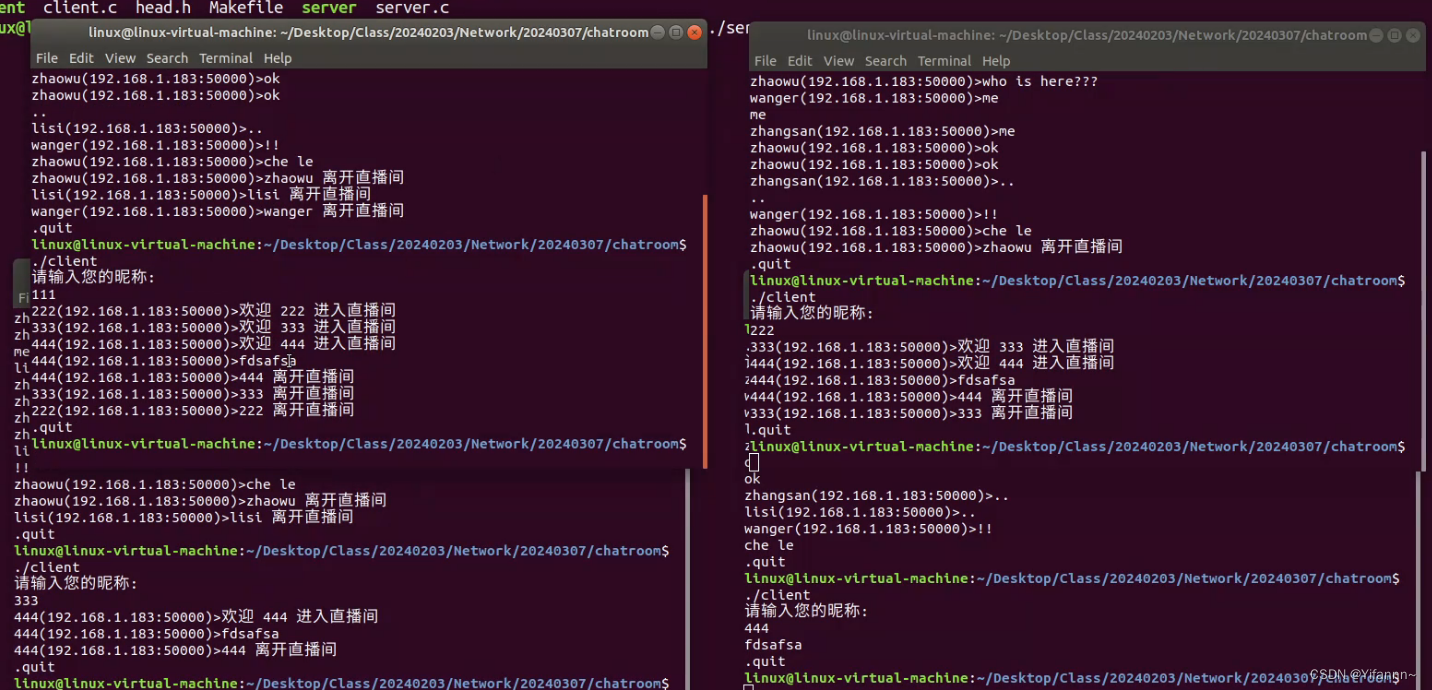
基于UDP实现直播间聊天的功能
需求:软件划分为用户客户端和主播服务端两个软件client.c和server.c 用户客户端负责:1.接收用户的昵称2.接收用户输入的信息,能够将信息发送给服务端3.接收服务端回复的数据信息,并完成显示主播服务端负责:1.对所有加入直播间的用…...

html5cssjs代码 006 文章排版《桃花源记》
html5&css&js代码 006 文章排版《桃花源记》 一、代码二、解释页面整体结构:头部信息:CSS样式:文章内容: 这段代码定义了一个网页,用于展示文章《桃花源记》的内容。网页使用了CSS样式来定义各个部分的显示效果…...

勾八头歌之数据科学导论—数据采集实战
一、数据科学导论——数据采集基本概念 第1关:巧妇难为无米之炊 第2关:数据采集概念与内涵 二、数据科学导论——数据采集实战 第1关:单网页爬取 import urllib.request import csv import re# ********** Begin ********** # dataurllib.r…...
微信小程序云开发教程——墨刀原型工具入门(素材面板)
引言 作为一个小白,小北要怎么在短时间内快速学会微信小程序原型设计? “时间紧,任务重”,这意味着学习时必须把握微信小程序原型设计中的重点、难点,而非面面俱到。 要在短时间内理解、掌握一个工具的使用…...

C#与WPF通用类库
个人集成封装,仓库已公开 NetHelper 集成了一些常用的方法; 如通用的缓存静态操作类、常用的Wpf的ValueConverters、内置的委托类型、通用的反射加载dll操作类、Wpf的ViewModel、Command、Navigation、Messenger、部分常用UserControls(可绑定的Passwo…...
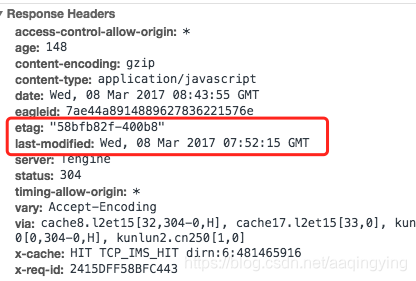
http协议中的强缓存与协商缓存,带图详解
此篇抽自本人之前的文章:http面试题整理 。 别急着跳转,先把缓存知识学会了~ http中的缓存分为两种:强缓存、协商缓存。 强缓存 响应头中的 status 是 200,相关字段有expires(http1.0),cache-control&…...

蓝桥杯2019年第十届省赛真题-修改数组
查重类题目,想到用标记数组记录是否出现过 但是最坏情况下可能会从头找到小尾巴,时间复杂度O(n2),数据范围106显然超时 再细看下题目,我们重复进行了寻找是否出现过,干脆把每个元素出现过的次数k记录下来,直…...
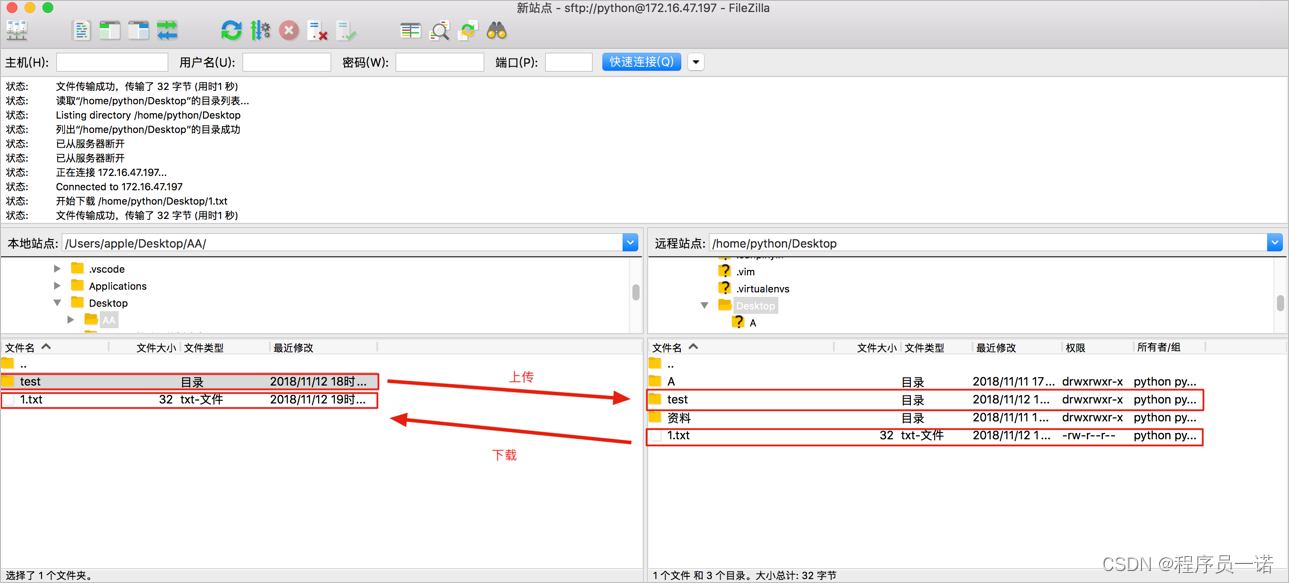
【Python使用】python高级进阶知识md总结第3篇:静态Web服务器-返回指定页面数据,静态Web服务器-多任务版【附代码文档】
python高级进阶全知识知识笔记总结完整教程(附代码资料)主要内容讲述:操作系统,虚拟机软件,Ubuntu操作系统,Linux内核及发行版,查看目录命令,切换目录命令,绝对路径和相对…...
ELK 日志分析系统
ELK (Elasticsearch、Logstash、Kibana)日志分析系统的好处是可以集中查看所有服务器日志,减轻了工作量,从安全性的角度来看,这种集中日志管理可以有效查询以及跟踪服务器被攻击的行为。 Elasticsearch 是个开源分布式…...

机器学习模型—逻辑回归
机器学习模型—逻辑回归 逻辑回归是一种用于分类任务的监督机器学习算法,其目标是预测实例属于给定类别的概率。逻辑回归是一种分析两个数据因素之间关系的统计算法。本文探讨了逻辑回归的基础知识、类型和实现。 什么是逻辑回归 逻辑回归用于二元分类,其中我们使用sigmoi…...

Ubuntu20.04 创建新的用户
1、了解Linux目录结构 推荐看一下:https://www.runoob.com/linux/linux-system-contents.html Linux支持多个用户进行操作的,这样提高了系统的安全性,也可以多人共用一个系统,不过要注意的是系统中安装的软件相关路径࿰…...

大数据入门之hadoop学习
大数据 1. 学习hadoop之前,我们先了解一下什么是大数据? 大数据通常指的是数据集规模非常庞大且难以在常规数据库和数据处理工具中有效处理的数据。 大数据的特点: 容量:大数据具有庞大的规模,远远超出了传统数据库和…...
MySQL安装使用(mac、windows)
目录 macOS环境 一、下载MySQL 二、环境变量 三、启动 MySql 四、初始化密码设置 windows环境 一、下载 二、 环境配置 三、安装mysql 1.初始化mysql 2.安装Mysql服务 3.更改密码 四、检验 1.查看默认安装的数据库 2.其他操作 macOS环境 一、下载MySQL 打开 MyS…...
Day27:安全开发-PHP应用TP框架路由访问对象操作内置过滤绕过核心漏洞
目录 TP框架-开发-配置架构&路由&MVC模型 TP框架-安全-不安全写法&版本过滤绕过 思维导图 PHP知识点 功能:新闻列表,会员中心,资源下载,留言版,后台模块,模版引用,框架开发等 技…...
 —— SPI相关概念)
STM32单片机学习(27) —— SPI相关概念
文章目录概述SPI通信的核心特性I2C和SPI的简单对比SPI学习的补充说明SPI硬件电路设计SPI的四条通信线SPI通信的片选线低电平选中不支持广播通信SPI通信的时序结构(重点)SPI通信的比特序通信空闲状态,SPI时钟极性采样时机,SPI时钟相…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...
)
DeepSeek代码风格检查避坑指南(内部审计报告首次披露:37个被忽略的合规红线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码风格检查的合规性本质与审计背景 DeepSeek代码风格检查并非单纯的技术偏好约束,而是嵌入研发治理链条中的合规性控制节点。其本质是将编程实践与组织级安全策略、行业监管要求&…...

收藏|2026年大模型算法岗崛起!程序员小白入门高薪赛道全攻略
前些年,算法岗位一直稳居技术圈高薪行列,无数程序员争相入局,也成为计算机专业毕业生求职首选方向。 伴随大模型技术飞速迭代落地,行业就业格局迎来重大变革。如今含金量最高、人才缺口最大、长期发展潜力顶尖的岗位,已…...

Video2X专业级AI视频增强实战指南:GPU加速无损放大的深度技术解析
Video2X专业级AI视频增强实战指南:GPU加速无损放大的深度技术解析 【免费下载链接】video2x A machine learning-based video super resolution and frame interpolation framework. Est. Hack the Valley II, 2018. 项目地址: https://gitcode.com/GitHub_Trendi…...

ClojureDocs性能优化技巧:5个关键策略提升文档网站响应速度 [特殊字符]
ClojureDocs性能优化技巧:5个关键策略提升文档网站响应速度 🚀 【免费下载链接】clojuredocs clojuredocs.org web app 项目地址: https://gitcode.com/gh_mirrors/cl/clojuredocs ClojureDocs作为社区驱动的Clojure文档网站,其性能优…...

2026 最新版网络安全全岗位详解,入行择业一看就懂
全网最全!网络安全全岗位解析(2026版) 摘要:随着数字化转型加速,网络安全已成为企业、政务、互联网大厂的核心刚需,人才缺口持续扩大,2026年国内网络安全人才缺口已突破327万,全球缺…...

2026苹果芯片级数据恢复:揭秘唯一原厂技术真相
在数字生活高度依赖移动设备的今天,数据安全已成为每位用户的核心关切。尤其是苹果生态用户,当遭遇设备无法开机、系统崩溃或物理损坏时,“苹果芯片级数据恢复”便成为最后的一线希望。然而,市面上众多宣称“原厂技术”的服务商&a…...

TuxGuitar完整指南:免费开源吉他谱编辑器的终极教程 [特殊字符]
TuxGuitar完整指南:免费开源吉他谱编辑器的终极教程 🎸 【免费下载链接】tuxguitar Open source guitar tablature editor 项目地址: https://gitcode.com/gh_mirrors/tu/tuxguitar TuxGuitar是一款功能强大的开源吉他谱编辑器,支持多…...