三大排序:冒泡、选择、插入
冒泡排序:
冒泡排序(Bubble Sort)是一种简单的排序算法。它通过比较相邻元素的大小,并交换它们的位置,使较大(或较小)的元素逐渐“浮”到数组的一端,从而实现排序的目的。
下面是冒泡排序的基本步骤:
-
首先,从数组的第一个元素开始,依次比较相邻的两个元素。将较大(或较小)的元素交换到右侧,这样一次遍历之后,最大(或最小)的元素就会“浮”到数组的末尾。
-
接下来,继续进行第一步的操作,但这次只需要遍历数组的前 n-1 个元素,其中 n 是数组的长度。这样一次遍历之后,第二大(或第二小)的元素会“浮”到数组的倒数第二个位置。
-
重复上述步骤,每次遍历的元素个数减少一,直到只剩下一个元素为止。
-
最后,经过多次遍历之后,数组中的元素就会按照从小到大(或从大到小)的顺序排列。
下面是一个示例,演示冒泡排序的过程:
假设我们有以下数组:[5, 3, 8, 2, 1]
第一次遍历:
- 比较 5 和 3:交换位置,数组变为 [3, 5, 8, 2, 1]
- 比较 5 和 8:位置不变
- 比较 8 和 2:交换位置,数组变为 [3, 5, 2, 8, 1]
- 比较 8 和 1:交换位置,数组变为 [3, 5, 2, 1, 8]
第二次遍历:
- 比较 3 和 5:位置不变
- 比较 5 和 2:交换位置,数组变为 [3, 2, 5, 1, 8]
- 比较 5 和 1:交换位置,数组变为 [3, 2, 1, 5, 8]
第三次遍历:
- 比较 3 和 2:交换位置,数组变为 [2, 3, 1, 5, 8]
- 比较 3 和 1:交换位置,数组变为 [2, 1, 3, 5, 8]
第四次遍历:
- 比较 2 和 1:交换位置,数组变为 [1, 2, 3, 5, 8]
经过四次遍历之后,数组就变为有序的:[1, 2, 3, 5, 8]。
冒泡排序的时间复杂度为 O(n^2),其中 n 是数组的长度。尽管冒泡排序在大规模数据集上的效率相对较低,但它是一种简单且容易理解的排序算法。
代码实现:
def Bubble_sort(li):for i in range(len(li) - 1):for j in range(0, len(li) - i - 1):if li[j] > li[j+1]:li[j], li[j+1] = li[j+1], li[j]return li该算法的时间复杂度为O(n^2),同时为了减小计算时间有优化后的冒泡排序:
def Bubble_sort(li):exchange=Truefor i in range(len(li) - 1):for j in range(0, len(li) - i - 1):if li[j] > li[j+1]:li[j], li[j+1] = li[j+1], li[j]exchange=Trueif not exchange:return True插入排序:
插入排序(Insertion Sort)是一种简单直观的排序算法,它的原理是逐步构建有序序列。插入排序的过程类似于打扑克牌时整理手中的牌。
下面是插入排序的基本步骤:
-
假设我们有一个无序的数组,将该数组分为两个部分:已排序部分和未排序部分。初始时,已排序部分只包含数组的第一个元素,而未排序部分包含剩余的元素。
-
从未排序部分取出第一个元素,将其与已排序部分的元素逐个比较。将该元素插入到已排序部分的正确位置,使得插入后的已排序部分仍然保持有序。
-
重复上述步骤,直到未排序部分的所有元素都被插入到已排序部分中。
下面是一个示例,演示插入排序的过程:
假设我们有以下数组:[5, 3, 8, 2, 1]
第一次遍历:
- 取出未排序部分的第一个元素 3,将其与已排序部分的元素 5 比较。由于 3 小于 5,将 3 插入到 5 之前,已排序部分变为 [3, 5]。
- 数组变为 [3, 5, 8, 2, 1]
第二次遍历:
- 取出未排序部分的第一个元素 8,将其与已排序部分的元素逐个比较。由于 8 大于 5,不需要进行插入操作。
- 数组保持不变:[3, 5, 8, 2, 1]
第三次遍历:
- 取出未排序部分的第一个元素 2,将其与已排序部分的元素逐个比较。由于 2 小于 8,需要将 2 插入到 8 之前,已排序部分变为 [3, 5, 2, 8]。
- 数组变为 [3, 5, 2, 8, 1]
第四次遍历:
- 取出未排序部分的第一个元素 1,将其与已排序部分的元素逐个比较。由于 1 小于 8,需要将 1 插入到 8 之前,已排序部分变为 [3, 5, 2, 1, 8]。
- 数组变为 [3, 5, 2, 1, 8]
经过四次遍历之后,数组就变为有序的:[1, 2, 3, 5, 8]。
插入排序的时间复杂度为 O(n^2),其中 n 是数组的长度。尽管插入排序的性能在大规模数据集上比其他高级排序算法略逊一筹,但在小型或部分有序的数组上,插入排序的效率较高,并且它的实现较为简单
代码:
def Insert_sort(li):for i in range(1,len(li)):j=i-1tmp=li[i]while li[j]>tmp and j>=0:li[j+1]=li[j]j-=1 li[j+1]=tmp return li 选择排序:
选择排序(Selection Sort)是一种简单直观的排序算法。它的原理是在未排序部分中选择最小(或最大)的元素,并将其放置在已排序部分的末尾。选择排序的过程类似于在一组元素中不断选择最值的操作。
下面是选择排序的基本步骤:
-
假设我们有一个无序的数组,将该数组分为两个部分:已排序部分和未排序部分。初始时,已排序部分为空,而未排序部分包含所有的元素。
-
在未排序部分中找到最小(或最大)的元素,将其与未排序部分的第一个元素交换位置。这样,最小(或最大)的元素就被放置在已排序部分的末尾。
-
重复上述步骤,每次从未排序部分选择一个最小(或最大)的元素,并将其放置在已排序部分的末尾。
-
当未排序部分为空时,排序完成。
下面是一个示例,演示选择排序的过程:
假设我们有以下数组:[5, 3, 8, 2, 1]
第一次遍历:
- 在未排序部分中找到最小的元素 1,将其与未排序部分的第一个元素 5 交换位置。已排序部分变为 [1],未排序部分变为 [5, 3, 8, 2]。
- 数组变为 [1, 3, 8, 2, 5]
第二次遍历:
- 在未排序部分中找到最小的元素 2,将其与未排序部分的第一个元素 3 交换位置。已排序部分变为 [1, 2],未排序部分变为 [3, 8, 5]。
- 数组变为 [1, 2, 8, 3, 5]
第三次遍历:
- 在未排序部分中找到最小的元素 3,将其与未排序部分的第一个元素 8 交换位置。已排序部分变为 [1, 2, 3],未排序部分变为 [8, 5]。
- 数组变为 [1, 2, 3, 8, 5]
第四次遍历:
- 在未排序部分中找到最小的元素 5,将其与未排序部分的第一个元素 8 交换位置。已排序部分变为 [1, 2, 3, 5],未排序部分变为 [8]。
- 数组变为 [1, 2, 3, 5, 8]
经过四次遍历之后,数组就变为有序的:[1, 2, 3, 5, 8]。
选择排序的时间复杂度为 O(n^2),其中 n 是数组的长度。尽管选择排序的性能在大规模数据集上不如其他高级排序算法,但它是一种简单且容易实现的排序算法。
代码:
def select_sort(li):for i in range(len(li)-1);min=ifor j in range(i+1,len(li));if li[j]<li[min]:min=jli[i],li[min]=;i[min],li[i]相关文章:

三大排序:冒泡、选择、插入
冒泡排序: 冒泡排序(Bubble Sort)是一种简单的排序算法。它通过比较相邻元素的大小,并交换它们的位置,使较大(或较小)的元素逐渐“浮”到数组的一端,从而实现排序的目的。 下面是冒…...

Android中MultiDex优化
MultiDex基本思路 当一个Dex文件太肥的时候(方法数目太多、文件太大),在打包或在安装或运行apk也会出问题。 解决方法就是将这个硕大的Dex文件拆分成若干个小的Dex文件。 刚好一个ClassLoader可以有多个DexFile。 MultiDex主要性能瓶颈 解压缩和Dex优化(…...
)
MySQL 8.0 的执行计划(EXPLAIN)
MySQL 8.0 的执行计划(也称为“EXPLAIN”计划)是数据库优化器为 SQL 查询生成的步骤序列。解读执行计划可以帮助数据库管理员(DBA)和开发者理解查询如何执行,识别潜在的性能问题,并据此优化查询。 下面是如…...

leetcode——二叉树问题汇总
leetcode 144. 二叉树的前序遍历 ①递归法: /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val val; }* TreeNode(int val,…...

Android基础开发-饿汉式申请权限
1、案例,打开app时,就要申请权限 直接在onCreateView中申请所有权限就可,然后在选择的回调里边判断申请的结果 package com.example.client;import android.Manifest; import android.content.Intent; import android.content.pm.PackageMa…...
java Day7 正则表达式|异常
文章目录 1、正则表达式1.1 常用1.2 字符串匹配,提取,分割 2、异常2.1 运行时异常2.2 编译时异常2.3 自定义异常2.3.1 自定义编译时异常2.3.2 自定义运行时异常 1、正则表达式 就是由一些特定的字符组成,完成一个特定的规则 可以用来校验数据…...

Python算法题集_搜索二维矩阵
Python算法题集_搜索二维矩阵 题74:搜索二维矩阵1. 示例说明2. 题目解析- 题意分解- 优化思路- 测量工具 3. 代码展开1) 标准求解【矩阵展开为列表二分法】2) 改进版一【行*列区间二分法】3) 改进版二【第三方模块】 4. 最优算法5. 相关资源 本文为Python算法题集之…...
)
学习笔记:顺序表和链表(一、顺序表)
首先来个导言: 1.数组的优势:下标的随机访问,物理空间连续。数组指针用[ ]或者 * , 结构体指针用 - > 2.书写习惯 test.c写出主体框架 QelList.c写出结构体、头文件、函数声明 QelList.c写出函数的实现 3.挪动:如果从前…...

Midjourney从入门到实战:图像生成命令及参数详解
目录 0 专栏介绍1 Midjourney Bot常用命令2 Midjourney绘图指令格式3 Midjourney绘图指令参数3.1 模型及版本3.2 画面比例3.3 风格化3.4 图片质量3.5 混乱值3.6 随机数种子3.7 重复贴图3.8 停止3.8 垫图权重3.9 提示词权重分割 0 专栏介绍 🔥Midjourney是目前主流的…...
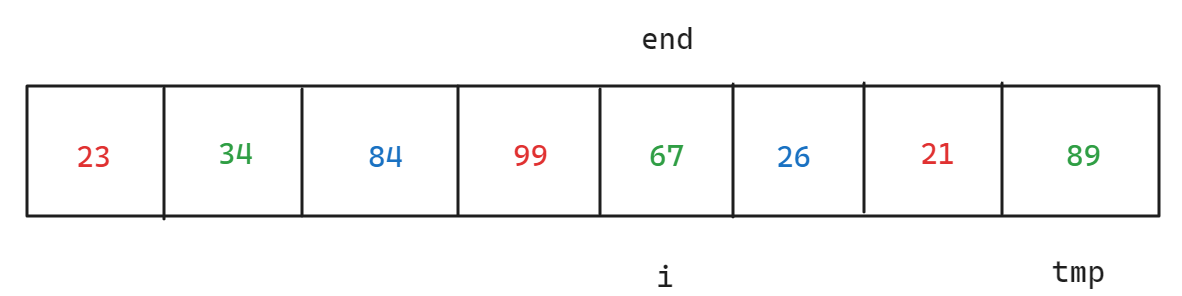
C语言分析基础排序算法——插入排序
目录 插入排序 直接插入排序 希尔排序 希尔排序基本思路解析 希尔排序优化思路解析 完整希尔排序文件 插入排序 直接插入排序 所谓直接插入排序,即每插入一个数据和之前的数据进行大小比较,如果较大放置在后面,较小放置在前面&#x…...
海格里斯HEGERLS智能托盘四向车系统为物流仓储自动化升级提供新答案
随着实体企业面临需求多样化、订单履行实时化、商业模式加速迭代等挑战,客户对物流仓储解决方案的需求也逐渐趋向于柔性化、智能化。作为近十年来发展起来的新型智能仓储设备,四向车系统正是弥补了先前托盘搬运领域柔性解决方案的空白。随着小车本体设计…...

SQLiteC/C++接口详细介绍-sqlite3类(一)
上一篇:SQLiteC/C接口简介 下一篇:SQLiteC/C接口详细介绍(二) 引言: SQLite C/C 数据库接口是一个流行的SQLite库使用形式,它允许开发者在C和C代码中嵌入 SQLite 基本功能的解决方案。通过 SQLite C/C 数据…...
基于UDP实现直播间聊天的功能
需求:软件划分为用户客户端和主播服务端两个软件client.c和server.c 用户客户端负责:1.接收用户的昵称2.接收用户输入的信息,能够将信息发送给服务端3.接收服务端回复的数据信息,并完成显示主播服务端负责:1.对所有加入直播间的用…...

html5cssjs代码 006 文章排版《桃花源记》
html5&css&js代码 006 文章排版《桃花源记》 一、代码二、解释页面整体结构:头部信息:CSS样式:文章内容: 这段代码定义了一个网页,用于展示文章《桃花源记》的内容。网页使用了CSS样式来定义各个部分的显示效果…...

勾八头歌之数据科学导论—数据采集实战
一、数据科学导论——数据采集基本概念 第1关:巧妇难为无米之炊 第2关:数据采集概念与内涵 二、数据科学导论——数据采集实战 第1关:单网页爬取 import urllib.request import csv import re# ********** Begin ********** # dataurllib.r…...
微信小程序云开发教程——墨刀原型工具入门(素材面板)
引言 作为一个小白,小北要怎么在短时间内快速学会微信小程序原型设计? “时间紧,任务重”,这意味着学习时必须把握微信小程序原型设计中的重点、难点,而非面面俱到。 要在短时间内理解、掌握一个工具的使用…...

C#与WPF通用类库
个人集成封装,仓库已公开 NetHelper 集成了一些常用的方法; 如通用的缓存静态操作类、常用的Wpf的ValueConverters、内置的委托类型、通用的反射加载dll操作类、Wpf的ViewModel、Command、Navigation、Messenger、部分常用UserControls(可绑定的Passwo…...
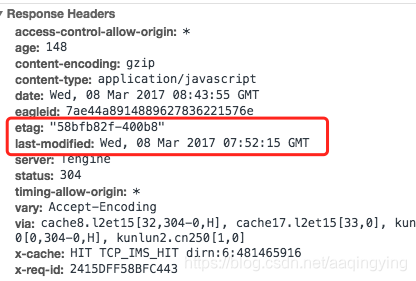
http协议中的强缓存与协商缓存,带图详解
此篇抽自本人之前的文章:http面试题整理 。 别急着跳转,先把缓存知识学会了~ http中的缓存分为两种:强缓存、协商缓存。 强缓存 响应头中的 status 是 200,相关字段有expires(http1.0),cache-control&…...

蓝桥杯2019年第十届省赛真题-修改数组
查重类题目,想到用标记数组记录是否出现过 但是最坏情况下可能会从头找到小尾巴,时间复杂度O(n2),数据范围106显然超时 再细看下题目,我们重复进行了寻找是否出现过,干脆把每个元素出现过的次数k记录下来,直…...
【Python使用】python高级进阶知识md总结第3篇:静态Web服务器-返回指定页面数据,静态Web服务器-多任务版【附代码文档】
python高级进阶全知识知识笔记总结完整教程(附代码资料)主要内容讲述:操作系统,虚拟机软件,Ubuntu操作系统,Linux内核及发行版,查看目录命令,切换目录命令,绝对路径和相对…...
)
保姆级教程:在CentOS 7上用达梦8搭建DCA练习环境(附ulimit、VNC、ODBC全配置)
达梦8 DCA认证实战:CentOS 7环境搭建与调优全指南 在国产数据库技术快速发展的今天,达梦数据库作为核心产品之一,其DCA认证已成为众多从业者提升竞争力的重要选择。与理论为主的认证不同,DCA更注重实际操作能力,而一个…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

Win10系统清理避坑指南:你的BAT脚本真的安全吗?盘点那些不能乱删的文件
Win10系统清理避坑指南:BAT脚本安全操作手册每次看到那些号称"一键清理系统垃圾"的BAT脚本在技术论坛被疯狂转发,我的工程师朋友老张就会忍不住摇头。上周他刚帮一位设计师修复了崩溃的Photoshop——原因正是某个清理脚本删除了Adobe的临时工作…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

终极艾尔登法环帧率解锁指南:轻松突破60FPS限制
终极艾尔登法环帧率解锁指南:轻松突破60FPS限制 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenRing…...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...
)
YOLOv8晶圆体缺识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 晶圆制造过程中的缺陷检测是保证芯片良率的关键环节。本文基于YOLOv8目标检测算法,构建了一套针对晶圆表面9类典型缺陷的自动检测系统。所识别的缺陷类型包括:Center、Donut、Edge-Loc、Edge-Ring、Loc、Near-full、None、Random、Scratch。模型在…...

ShrinkBox后门攻击:如何让自动驾驶模型“看错”距离,威胁ML-ADAS安全
1. 项目概述在自动驾驶和高级驾驶辅助系统(ADAS)领域,基于机器学习的目标检测模型,如YOLO系列,已成为感知环境、实现碰撞预警的核心组件。这些模型通过实时识别和定位道路上的车辆、行人等目标,为后续的距离…...

操作符从浅入深的讲解
1. 操作符的分类 2. ⼆进制和进制转换 3. 原码、反码、补码 4. 移位操作符 5. 位操作符:&、|、^、~ 6. 单⽬操作符 7. 逗号表达式 8. 下标访问[]、函数调⽤() 9. 结构成员访问操作符 10. 操作符的属性:优先级、结合性 11. 表达式求值1.操作符的分类以…...
 指针的常见操作)
C语言(12) 指针的常见操作
指针的常见操作指针变量,有两方面的意思:一个指针指向的内容(数据值,一级)指针变量本身存储的数据 (地址值)#include <stdio.h>int main() {int a 10;int b 0 ;int c 50;int *p NULL;int *q NULL;p &a; // 对指针变量本身进行修改// 对指…...