【强化学习笔记一】初识强化学习(定义、应用、分类、性能指标、小车上山案例及代码)
文章目录
- 第1章 初识强化学习
- 1.1 强化学习及其关键元素
- 1.2 强化学习的应用
- 1.3 强化学习的分类
- 1.3.1 按任务分类
- 1.3.2 按算法分类
- 1.4 强化学习算法的性能指标
- 1.5 案例:基于Gym库的智能体/环境接口
- 1.5.1 安装Gym库
- 1.5.2 使用Gym库
- 1.5.3 小车上山
- 1.5.3.1 有限动作空间
- 1.5.3.2 连续动作空间
第1章 初识强化学习
1.1 强化学习及其关键元素
强化学习(Reinforcement Learning,RL)是根据奖励信号来改进策略的机器学习方法。如图所示,强化学习通常由两部分组成:智能体和环境。在一个强化学习系统中,智能体可以观察环境,并根据观测行动。在行动之后,能够获得奖励或付出代价。强化学习通过智能体与环境的交互记录来学习如何最大化奖励或最小化代价。强化学习的最大特点是在学习过程中没有正确答案,而是通过奖励信号来学习。
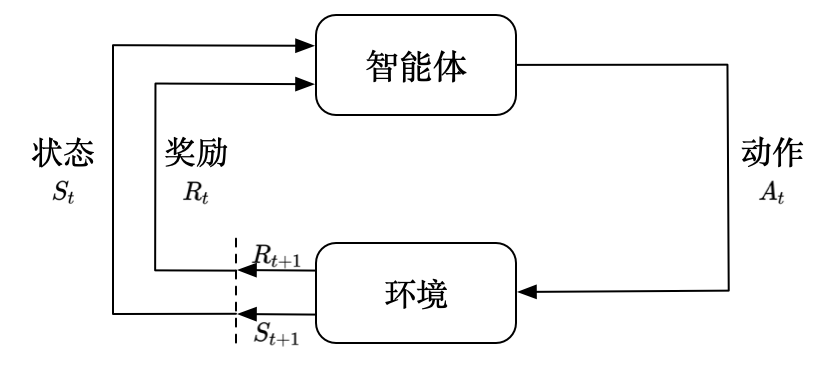
- 智能体和环境接口主要有以下两个环节:
❑智能体观测环境,可以获得环境的观测(observation),记为O,接着智能体决定要对环境施加的动作(action),记为A;
❑环境受智能体动作的影响,给出奖励(reward),记为R,并改变自己的状态(state),记为S。
在交互中,观测O、动作A和奖励R是智能体可以直接观测到的。
- 强化学习系统有以下关键元素:
❑奖励(reward)或代价(cost): 最大化在长时间里的总奖励,最小化代价是强化学习系统的学习目标。
❑策略(policy): 决策者会根据不同的观测决定采用不同的动作,这种从观测到动作的关系称为策略。强化学习的学习对象就是策略。
- 强化学习与监督学习的本质区别:
❑对于监督学习,学习者知道每个动作的正确答案是什么,可以通过逐步比对来学习;对于强化学习,学习者不知道每个动作的正确答案,只能通过奖励信号来学习,同时需要关注更加长远的奖励。与此同时,监督学习希望能将学习的结果运用到未知的数据,要求结果可推广、可泛化;强化学习的结果却可以用在训练的环境中。
1.2 强化学习的应用
❑棋盘游戏:棋盘游戏是围棋、黑白翻转棋、五子棋等桌上游戏的统称。棋盘AI的每一步往往没有绝对正确的答案,这正是强化学习所针对的场景。DeepMind公司使用强化学习研发出围棋AI AlphaGo先后战胜李世石、柯洁等围棋顶尖选手,引起了全社会的关注。后来,DeepMind又研发了棋盘游戏AI如AlphaZero和MuZero,它可以在围棋、日本将棋、国际象棋等多个棋盘游戏上达到最高水平,并远远超出人类的最高水平。
❑自动控制:自动控制问题通过控制机械设备(如机器人、机器手、平衡设备等)的行为来完成平衡、移动、抓取等任务。自动控制问题既可能是虚拟仿真环境中的问题,也可能是现实世界中出现的问题。基于强化学习的控制策略可以帮助解决这类控制问题。
1.3 强化学习的分类
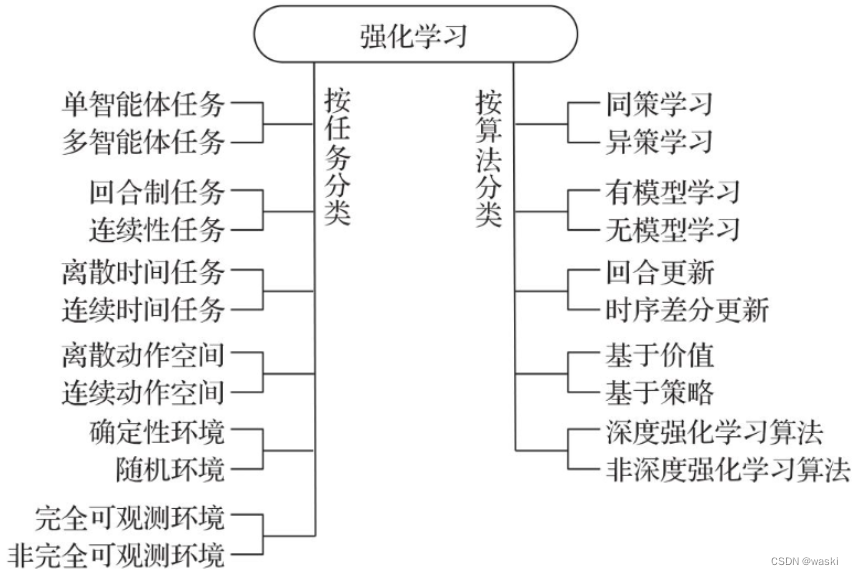
1.3.1 按任务分类
除了图中的分类外,有些问题需要同时考虑多个任务。同时针对多个任务的学习称为多任务强化学习(Multi-Task Reinforcement Learning,MTRL)。如果多个任务只是奖励的参数不同而其他方面都相同,则对这些任务的学习可以称为以目标为条件的强化学习(goal-conditioned reinforcement learning)。例如,有多个任务想要让机器人到达目的地,不同任务的目的地各不相同。那么这个目的地就可以看作每个任务的目标(goal),这多个任务合起来就可以看作以目标为条件的强化学习。如果要试图通过对某些任务进行学习,然后将学习的成果应用于其他任务,这样就和迁移学习结合起来,称为迁移强化学习(transfer reinforcement learning)。如果要通过学习其他任务的过程了解如何在未知的新任务中进行学习的知识,则称为元强化学习(meta reinforcement learning)。在多任务学习中,多个任务可能是随时间不断变化的。需要不断适应随时间变化的任务,称为在线学习(online reinforcement learning)或终身强化学习(lifelong reinforcement learning)。不过,在线学习并不是和离线学习相对的概念。实际上,**离线强化学习(offline reinforcement learning)是批强化学习(batch reinforcement learning)**的另外一种说法,是指在学习过程中不能和环境交互,只能通过其他智能体与环境的交互历史来学习。
1.3.2 按算法分类
❑同策学习(on policy)和异策学习(off policy): 同策学习从正在执行的策略中学习。异策学习则是从当前策略以外的策略中学习,例如通过之前的历史(可以是自己的历史,也可以是别人的历史)进行学习。
❑有模型(model-based)学习和无模型(model free)学习: 在学习的过程中,如果用到了环境的数学模型,则是有模型学习(可能是在学习前环境的模型就已经知道,也可能是通过学习来的);如果没有用到环境的数学模型,则是无模型学习(所有经验都是通过与真实环境交互得到的)。
❑回合更新(Monte Carlo update)和时序差分更新(temporal difference update): 回合更新是在回合结束后利用整个回合的信息进行更新学习,并且不使用局部信息;而时序差分更新不需要等回合结束,可以综合利用现有的信息和现有的估计进行更新学习。
❑基于价值(value based)、基于策略(policy based)和执行者/评论者(actor-critic)算法:基于价值的强化学习定义了状态或动作的价值,倾向于选择价值最大的状态或动作;基于策略的强化学习算法可以为动作分配概率分布,按照概率分布来执行动作。执行者/评论者算法同时利用了基于价值和基于策略的方法。策略梯度(policy gradient)算法是基于策略算法中最重要的一类,此外还有无梯度(gradient-free)算法。
❑深度强化学习(Deep Reinforcement Learning,DRL)算法和非深度强化学习算法: 如果一个算法解决了强化学习的问题,这个算法就是强化学习的算法。如果强化学习算法用到了深度学习(深度神经网络),则这种强化学习可以称为深度强化学习算法。例如,很多电动游戏AI需要读取屏幕显示并据此做出决策。对屏幕数据的解读可以采用卷积神经网络这一深度学习算法。这样的学习算法就是深度强化学习算法。
1.4 强化学习算法的性能指标
强化学习任务各种各样,每个算法都有自己的适用范围。一般而言,我们会看长期奖励及长期奖励在训练过程中的收敛状况,最常见的是给出长期奖励和学习曲线。另外,对于不同类型的强化学习的任务,特别是在线学习任务、离线学习任务、多任务等,每个类型也可能会有自己独特的性能指标。
按通常情况下的重要性排序,我们会关注下列指标:
❑长期奖励: 指将强化学习应用到目标任务或基准任务时,可以得到的长期奖励。它的定义有回报、平均奖励等。我们希望这个值的期望越大越好,均值相同的条件下会希望它的方差越小越好。
❑最优性和收敛性: 在理论上,特别关注强化学习算法是否能在给定的任务上收敛到最优解。能收敛到最优解自然是好的。
❑样本复杂度(sample complexity): 智能体和环境交互往往非常耗费资源,收集样本往往代价高昂,样本复杂度越小越好。对于离线强化学习算法,它仅仅使用历史样本就可以完成学习,并不需要与环境交互,这样的算法可以认为其“在线的”样本复杂度为0。甚至有些算法(比如模型价值迭代)仅仅靠模型就能得到最优策略,这种情况下不需要样本,严格来说它就不算强化学习算法。
❑遗憾(regret): 指在训练过程中每个回合的遗憾之和,其中每个回合的遗憾定义为实际获得的回合奖励和收敛后得到的回合奖励的差。遗憾越小越好。在线的任务会关注这个指标。
❑并行扩展性(scalability): 有些强化学习算法可以利用多个副本加快学习。我们遇到的强化学习任务往往比较复杂,如果能并行加速学习是很有帮助的。
❑收敛速度、训练时间与时间复杂度(time complexity): 在理论上,特别关注强化学习算法收敛速度是什么。如果用复杂度的记号来表示,则可以表示为时间复杂度。收敛速度越快越好,时间复杂度越小越好。
❑占用空间和空间复杂度(space complexity): 占用空间显然越小越好。有些应用场景比较关注用来存储和回放历史样本占用的空间,另外一些应用场景更在乎需要放置在GPU等特定计算硬件上的存储空间。
1.5 案例:基于Gym库的智能体/环境接口
Gym库(网址为https://www.gymlibrary.dev/)是OpenAI推出的强化学习实验环境库。它是目前最有影响力的强化学习环境库。它用Python语言实现了离散时间智能体/环境接口中的环境部分,实现了上百种环境,还支持自定义环境的扩展。整个项目是开源免费的,Gym的代码在GitHub上开源,网址为https://github.com/openai/gym。
1.5.1 安装Gym库
安装Gym和简单文本环境、经典控制环境的方法是在安装环境(比如Anaconda 3的管理员模式)里输入下列命令:
pip install gym[toy_text, classic_control, atari, accept-rom-license, other]
1.5.2 使用Gym库
- 首先要导入Gym库:
import gym
然后可以通过gym.make()函数来得到环境对象。每一个环境任务都有一个ID,如CartPole-v0、Taxi-v3等。任务名称最后的部分表示版本号。
- 获得任务
CartPole-v0的一个环境对象的代码为:
env=gym.make('CartPole-vo')
- 想要查看当前Gym库已经注册了哪些任务,可以使用以下代码:
print (gym.envs.registry)
每个任务都定义了自己的观测空间和动作空间。环境env的观测空间用env.observation_space表示,动作空间用env.action_space表示。Gym库提供了gym.spaces.Box类来表示空间,空间中的元素类型为np.array。元素个数有限的空间也可以用gym.spaces.Discrete类表示,空间中的元素类型为int。Gym还定义了其他空间类型。例如,环境CartPole-v0的观测空间是Box(4,),表示观测可以用形状为(4,)的np.array对象表示;环境CartPole-v0的动作空间是Discrete(2),表示动作取值自{0,1}。
- 初始化环境对象env:
env.reset()
返回初始观测observation和信息info。
- 使用环境对象的
step()方法来完成每一次的交互,让环境前进一步(往往放在循环结构里):
env.step(动作)
step()方法有一个参数,是动作空间中的一个动作。该方法返回值包括以下五个部分:
❑观测(observation): 表示观测,与env.reset()第一个返回值的含义相同。
❑奖励(reward): float类型的值。
❑回合终止指示(terminated): bool类型的数值。Gym库里的实验环境大多都是回合制的。这个返回值可以指示在当前动作后回合是否结束。如果回合结束了,可以通过env.reset()开始下一回合。
❑回合截断指示(truncated): bool类型的数值。无论是回合制任务还是连续型任务,我们都可以限制回合的最大步数,使其成为一个回合步数有限的回合制任务。当一个回合内的步数达到最大步数时,回合截断,该指示为True。还有一些情况,由于环境实现的限制,回合运行到某个步骤后资源不够了(比如内存不够了,或是超出了预先设计好的数据范围),这时只好对回合进行截断。
❑其他信息(info): dict类型的值,含有一些调试信息。不一定要使用这个信息。与env.reset()第二个返回值的含义相同。
- 然后,可以用下列语句以图形化的方法显示当前环境:
env.render()
- 环境使用完后,可以使用下列语句关闭环境:
env.close()
不使用env.close(),而是直接试图关闭图形界面窗口可能会导致内存不能释放,甚至死机。
- 对于有参考回合奖励参考阈值的环境,回合奖励参考阈值存储在下列变量中:
env.spec.reward_threshold
1.5.3 小车上山
本节通过一个完整的例子(经典的控制任务:小车上山)来学习如何与Gym库中的环境交互。
1.5.3.1 有限动作空间
- 首先我们来关注
有限动作空间的版本MountainCar-v0,查看其观测空间和动作空间:
# 代码地址:https://github.com/ZhiqingXiao/rl-book/tree/master/en2023/code
# 代码文件名:MountainCar-v0_ClosedForm.ipynb
import gym
env = gym.make('MountainCar-v0')
for key in vars(env.spec):logging.info('%s: %s', key, vars(env.spec)[key]) # 使用logging模块来打印可以同时输出时间戳,有助于了解程序运行时间(很多强化学习的算法运行时间很长)
for key in vars(env.unwrapped):logging.info('%s: %s', key, vars(env.unwrapped)[key])
运行结果:
00:00:00 [INFO] id: MountainCar-v0
00:00:00 [INFO] entry_point: gym.envs.classic_control:MountainCarEnv
00:00:00 [INFO] reward_threshold: -110.0 # 参考的回合奖励值reward_threshold是-110,如果连续100个回合(默认)的平均回合奖励大于-110,则认为这个任务被解决了。
00:00:00 [INFO] nondeterministic: False
00:00:00 [INFO] max_episode_steps: 200 # 每个回合的最大步数max_episode_steps是200
00:00:00 [INFO] order_enforce: True
00:00:00 [INFO] _kwargs: {}
00:00:00 [INFO] _env_name: MountainCar
00:00:00 [INFO] min_position: -1.2
00:00:00 [INFO] max_position: 0.6
00:00:00 [INFO] max_speed: 0.07
00:00:00 [INFO] goal_position: 0.5
00:00:00 [INFO] goal_velocity: 0
00:00:00 [INFO] force: 0.001
00:00:00 [INFO] gravity: 0.0025
00:00:00 [INFO] low: [-1.2 -0.07]
00:00:00 [INFO] high: [0.6 0.07]
00:00:00 [INFO] viewer: None
00:00:00 [INFO] action_space: Discrete(3) # 动作是取自{0,1,2}的int型数值。
00:00:00 [INFO] observation_space: Box([-1.2 -0.07], [0.6 0.07], (2,), float32) # 观测空间observation_space是Box(2,),所以观测是形状为(2,)的浮点型np.array。
00:00:00 [INFO] np_random: RandomState(MT19937)
00:00:00 [INFO] spec: EnvSpec(MountainCar-v0)
- 准备一个和环境交互的智能体
ClosedFormAgent类,使用step()方法实现决策功能。Gym里面一般没有智能体,智能体需要我们自己实现:
class CloseFormAgent:def __init__(self, _):passdef reset(self, mode=None):passdef step(self, observation, reward, terminated):position, velocity = observationlb = min(-0.09 * (position + 0.25) ** 2 + 0.03,0.3 * (position + 0.9) ** 4 - 0.008)ub = -0.07 * (position + 0.38) ** 2 + 0.07if lb < velocity < ub:# 它只能根据给定的数学表达式进行决策,并且不能有效学习,所以它并不是一个真正意义上的强化学习智能体类。action = 2 # 右推else:action = 0 # 左推return actiondef close(self):passagent = CloseFormAgent(env)
- 试图让智能体与环境交互:
# play_episode()函数可以让智能体和环境交互一个回合
# 参数seed可以是None或是一个int类型的变量,用作初始化回合的随机数种子。
# 参数mode是None或是str类型的变量'train'。如果是'train',同时智能体有学习功能,则试图让智能体进行学习。
# 参数render是bool类型变量,指示在运行过程中是否要图形化显示。如果函数参数render为True,那么在交互过程中会调用env.render()以显示图形化界面。
def play_episode(env, agent, seed=None, mode=None, render=False):observation, _ = env.reset(seed=seed)reward, terminated, truncated = 0., False, Falseagent.reset(mode=mode)episode_reward, elapsed_steps = 0., 0while True:action = agent.step(observation, reward, terminated)if render:env.render()if terminated or truncated:breakobservation, reward, terminated, truncated, _ = env.step(action)episode_reward += rewardelapsed_steps += 1agent.close()return episode_reward, elapsed_steps
# 这个函数返回episode_reward和elapsed_step,它们分别是float类型和int类型,表示智能体与环境交互一个回合的回合总奖励和交互步数。
- 系统性地评估智能体的性能:
# 求连续100个回合交互的平均回合奖励
logging.info('==== test ====')
episode_rewards = []
for episode in range(100):episode_reward, elapsed_steps = play_episode(env, agent)episode_rewards.append(episode_reward)logging.info('test episode %d: reward = %.2f, steps = %d',episode, episode_reward, elapsed_steps)
logging.info('average episode reward = %.2f ± %.2f',np.mean(episode_rewards), np.std(episode_rewards))env.close()
运行结果:
00:00:00 [INFO] ==== test ====
00:00:00 [INFO] test episode 0: reward = -105.00, steps = 105
00:00:00 [INFO] test episode 1: reward = -84.00, steps = 84
00:00:00 [INFO] test episode 2: reward = -133.00, steps = 133
00:00:00 [INFO] test episode 3: reward = -105.00, steps = 105
00:00:00 [INFO] test episode 4: reward = -105.00, steps = 105
00:00:00 [INFO] test episode 5: reward = -100.00, steps = 100
00:00:00 [INFO] test episode 6: reward = -104.00, steps = 104
00:00:00 [INFO] test episode 7: reward = -100.00, steps = 100
00:00:00 [INFO] test episode 8: reward = -105.00, steps = 105
00:00:00 [INFO] test episode 9: reward = -145.00, steps = 145
00:00:00 [INFO] test episode 10: reward = -105.00, steps = 105
00:00:00 [INFO] test episode 11: reward = -83.00, steps = 83
00:00:00 [INFO] test episode 12: reward = -103.00, steps = 103
00:00:00 [INFO] test episode 13: reward = -156.00, steps = 156
00:00:00 [INFO] test episode 14: reward = -84.00, steps = 84
00:00:00 [INFO] test episode 15: reward = -96.00, steps = 96
00:00:00 [INFO] test episode 16: reward = -104.00, steps = 104
00:00:00 [INFO] test episode 17: reward = -85.00, steps = 85
00:00:00 [INFO] test episode 18: reward = -105.00, steps = 105
00:00:00 [INFO] test episode 19: reward = -85.00, steps = 85
00:00:00 [INFO] test episode 20: reward = -89.00, steps = 89
00:00:00 [INFO] test episode 21: reward = -106.00, steps = 106
00:00:00 [INFO] test episode 22: reward = -104.00, steps = 104
00:00:00 [INFO] test episode 23: reward = -97.00, steps = 97
00:00:00 [INFO] test episode 24: reward = -86.00, steps = 86
00:00:00 [INFO] test episode 25: reward = -89.00, steps = 89
00:00:00 [INFO] test episode 26: reward = -92.00, steps = 92
00:00:00 [INFO] test episode 27: reward = -105.00, steps = 105
00:00:00 [INFO] test episode 28: reward = -103.00, steps = 103
00:00:01 [INFO] test episode 29: reward = -105.00, steps = 105
00:00:01 [INFO] test episode 30: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 31: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 32: reward = -103.00, steps = 103
00:00:01 [INFO] test episode 33: reward = -85.00, steps = 85
00:00:01 [INFO] test episode 34: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 35: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 36: reward = -85.00, steps = 85
00:00:01 [INFO] test episode 37: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 38: reward = -103.00, steps = 103
00:00:01 [INFO] test episode 39: reward = -105.00, steps = 105
00:00:01 [INFO] test episode 40: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 41: reward = -84.00, steps = 84
00:00:01 [INFO] test episode 42: reward = -106.00, steps = 106
00:00:01 [INFO] test episode 43: reward = -105.00, steps = 105
00:00:01 [INFO] test episode 44: reward = -84.00, steps = 84
00:00:01 [INFO] test episode 45: reward = -105.00, steps = 105
00:00:01 [INFO] test episode 46: reward = -85.00, steps = 85
00:00:01 [INFO] test episode 47: reward = -86.00, steps = 86
00:00:01 [INFO] test episode 48: reward = -146.00, steps = 146
00:00:01 [INFO] test episode 49: reward = -85.00, steps = 85
00:00:01 [INFO] test episode 50: reward = -105.00, steps = 105
00:00:01 [INFO] test episode 51: reward = -105.00, steps = 105
00:00:01 [INFO] test episode 52: reward = -86.00, steps = 86
00:00:01 [INFO] test episode 53: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 54: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 55: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 56: reward = -98.00, steps = 98
00:00:01 [INFO] test episode 57: reward = -84.00, steps = 84
00:00:01 [INFO] test episode 58: reward = -83.00, steps = 83
00:00:01 [INFO] test episode 59: reward = -105.00, steps = 105
00:00:01 [INFO] test episode 60: reward = -86.00, steps = 86
00:00:01 [INFO] test episode 61: reward = -105.00, steps = 105
00:00:01 [INFO] test episode 62: reward = -105.00, steps = 105
00:00:01 [INFO] test episode 63: reward = -176.00, steps = 176
00:00:01 [INFO] test episode 64: reward = -156.00, steps = 156
00:00:01 [INFO] test episode 65: reward = -105.00, steps = 105
00:00:01 [INFO] test episode 66: reward = -89.00, steps = 89
00:00:01 [INFO] test episode 67: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 68: reward = -85.00, steps = 85
00:00:01 [INFO] test episode 69: reward = -92.00, steps = 92
00:00:01 [INFO] test episode 70: reward = -105.00, steps = 105
00:00:01 [INFO] test episode 71: reward = -92.00, steps = 92
00:00:01 [INFO] test episode 72: reward = -106.00, steps = 106
00:00:01 [INFO] test episode 73: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 74: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 75: reward = -103.00, steps = 103
00:00:01 [INFO] test episode 76: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 77: reward = -83.00, steps = 83
00:00:01 [INFO] test episode 78: reward = -90.00, steps = 90
00:00:01 [INFO] test episode 79: reward = -100.00, steps = 100
00:00:01 [INFO] test episode 80: reward = -105.00, steps = 105
00:00:01 [INFO] test episode 81: reward = -90.00, steps = 90
00:00:01 [INFO] test episode 82: reward = -106.00, steps = 106
00:00:01 [INFO] test episode 83: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 84: reward = -150.00, steps = 150
00:00:01 [INFO] test episode 85: reward = -168.00, steps = 168
00:00:01 [INFO] test episode 86: reward = -103.00, steps = 103
00:00:01 [INFO] test episode 87: reward = -93.00, steps = 93
00:00:01 [INFO] test episode 88: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 89: reward = -103.00, steps = 103
00:00:01 [INFO] test episode 90: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 91: reward = -105.00, steps = 105
00:00:01 [INFO] test episode 92: reward = -105.00, steps = 105
00:00:01 [INFO] test episode 93: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 94: reward = -100.00, steps = 100
00:00:01 [INFO] test episode 95: reward = -86.00, steps = 86
00:00:01 [INFO] test episode 96: reward = -104.00, steps = 104
00:00:01 [INFO] test episode 97: reward = -88.00, steps = 88
00:00:01 [INFO] test episode 98: reward = -103.00, steps = 103
00:00:01 [INFO] test episode 99: reward = -105.00, steps = 105
00:00:01 [INFO] average episode reward = -102.61 ± 17.46
# ClosedFormAgent类对应的策略的平均回合奖励为-102.61,超过了奖励阈值-110。所以,智能体ClosedFormAgent解决了这个任务。
1.5.3.2 连续动作空间
- 首先我们来关注
连续动作空间的版本MountainCarContinuous-v0,查看其观测空间和动作空间:
# 代码地址:https://github.com/ZhiqingXiao/rl-book/tree/master/en2023/code
# 代码文件名:MountainCarContinuous-v0_ClosedForm.ipynb
env = gym.make('MountainCarContinuous-v0')
for key in vars(env):logging.info('%s: %s', key, vars(env)[key])
for key in vars(env.spec):logging.info('%s: %s', key, vars(env.spec)[key])
输出:
00:00:00 [INFO] env: <Continuous_MountainCarEnv<MountainCarContinuous-v0>>
00:00:00 [INFO] action_space: Box(-1.0, 1.0, (1,), float32) # 动作是形状为(1,)的np.array对象
00:00:00 [INFO] observation_space: Box(-1.2000000476837158, 0.6000000238418579, (2,), float32) # 观测是形状为(2,)的np.array对象
00:00:00 [INFO] reward_range: (-inf, inf)
00:00:00 [INFO] metadata: {'render.modes': ['human', 'rgb_array'], 'video.frames_per_second': 30}
00:00:00 [INFO] _max_episode_steps: 999 # 回合最大步数变为999步
00:00:00 [INFO] _elapsed_steps: None
00:00:00 [INFO] id: MountainCarContinuous-v0
00:00:00 [INFO] entry_point: gym.envs.classic_control:Continuous_MountainCarEnv
00:00:00 [INFO] reward_threshold: 90.0 # 成功求解的阈值变为90(需要在连续100回合的平均回合奖励超过90)
00:00:00 [INFO] nondeterministic: False
00:00:00 [INFO] max_episode_steps: 999
00:00:00 [INFO] _kwargs: {}
00:00:00 [INFO] _env_name: MountainCarContinuous
- 不同的任务往往需要使用不同的智能体来求解:
class ClosedFormAgent:def __init__(self, _):passdef reset(self, mode=None):passdef step(self, observation, reward, terminated):# 观测observation分解为位置position和速度velocity两个分量,然后用这两个分量决定的大小关系决定采用何种动作action。position, velocity = observationif position > -4 * velocity or position < 13 * velocity - 0.6:force = 1.else:force = -1.action = np.array([force,])return actiondef close(self):passagent = ClosedFormAgent(env)
- 同样对其设置交互函数,测试智能体的性能:
def play_episode(env, agent, seed=None, mode=None, render=False):observation, _ = env.reset(seed=seed)reward, terminated, truncated = 0., False, Falseagent.reset(mode=mode)episode_reward, elapsed_steps = 0., 0while True:action = agent.step(observation, reward, terminated)if render:env.render()if terminated or truncated:breakobservation, reward, terminated, truncated, _ = env.step(action)episode_reward += rewardelapsed_steps += 1agent.close()return episode_reward, elapsed_stepslogging.info('==== test ====')
episode_rewards = []
for episode in range(100):episode_reward, elapsed_steps = play_episode(env, agent)episode_rewards.append(episode_reward)logging.info('test episode %d: reward = %.2f, steps = %d',episode, episode_reward, elapsed_steps)
logging.info('average episode reward = %.2f ± %.2f',np.mean(episode_rewards), np.std(episode_rewards))env.close()
输出:
00:00:00 [INFO] ==== test ====
00:00:00 [INFO] test episode 0: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 1: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 2: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 3: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 4: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 5: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 6: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 7: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 8: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 9: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 10: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 11: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 12: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 13: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 14: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 15: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 16: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 17: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 18: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 19: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 20: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 21: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 22: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 23: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 24: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 25: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 26: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 27: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 28: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 29: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 30: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 31: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 32: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 33: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 34: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 35: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 36: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 37: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 38: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 39: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 40: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 41: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 42: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 43: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 44: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 45: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 46: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 47: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 48: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 49: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 50: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 51: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 52: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 53: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 54: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 55: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 56: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 57: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 58: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 59: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 60: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 61: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 62: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 63: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 64: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 65: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 66: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 67: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 68: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 69: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 70: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 71: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 72: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 73: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 74: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 75: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 76: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 77: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 78: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 79: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 80: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 81: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 82: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 83: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 84: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 85: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 86: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 87: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 88: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 89: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 90: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 91: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 92: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 93: reward = 93.30, steps = 67
00:00:00 [INFO] test episode 94: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 95: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 96: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 97: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 98: reward = 93.40, steps = 66
00:00:00 [INFO] test episode 99: reward = 93.30, steps = 67
00:00:00 [INFO] average episode reward = 93.35 ± 0.05
# 平均回合奖励大概在93左右,大于阈值90,所以这个智能体成功求解了MountainCarContinuous-v0任务
相关文章:
【强化学习笔记一】初识强化学习(定义、应用、分类、性能指标、小车上山案例及代码)
文章目录 第1章 初识强化学习1.1 强化学习及其关键元素1.2 强化学习的应用1.3 强化学习的分类1.3.1 按任务分类1.3.2 按算法分类 1.4 强化学习算法的性能指标1.5 案例:基于Gym库的智能体/环境接口1.5.1 安装Gym库1.5.2 使用Gym库1.5.3 小车上山1.5.3.1 有限动作空间…...

安卓面试准备汇总
java相关 面试-java基础相关-CSDN博客 android 基础相关 安卓基础面试题-CSDN博客 kotlin相关 android pms,cms,wms相关知识 android fragmework层的知识 项目相关的...

C#+datax实现定时增量同步
要使用C#和DataX实现定时增量同步,你可以使用以下步骤: 1. 安装DataX:首先,确保你已经安装了DataX。你可以从DataX的官方仓库中获取最新版本。 2. 配置DataX 任务:创建一个DataX任务,定义源(sou…...
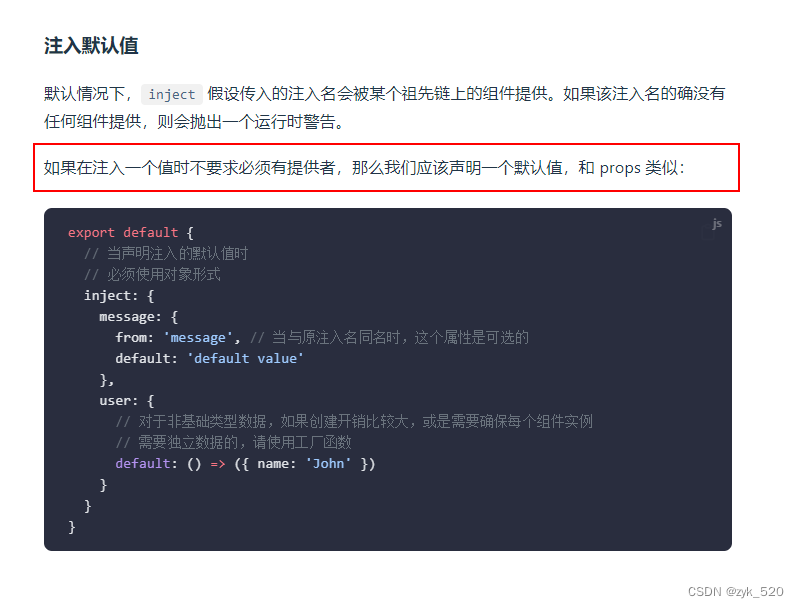
VUE实现Provide的计算属性
通过此篇可以学到: 如何使用Providerinject进行“跨代”传值如何实现一个计算属性的Provider如何解决告警“injection "xxxxx" not found. ” 一、描述 目前需要创建一个计算属性传入Provide,并且能够被其他组件Inject 二、实现 父组件 .…...
Spring Schedule:Spring boot整合Spring Schedule实战讲解定时发送邮件的功能
🎉🎉欢迎光临,终于等到你啦🎉🎉 🏅我是苏泽,一位对技术充满热情的探索者和分享者。🚀🚀 🌟持续更新的专栏《Spring 狂野之旅:从入门到入魔》 &a…...

Midjourney绘图欣赏系列(十)
Midjourney介绍 Midjourney 是生成式人工智能的一个很好的例子,它根据文本提示创建图像。它与 Dall-E 和 Stable Diffusion 一起成为最流行的 AI 艺术创作工具之一。与竞争对手不同,Midjourney 是自筹资金且闭源的,因此确切了解其幕后内容尚不…...

【C语言】人生重开模拟器
前言: 人生重开模拟器是前段时间非常火的一个小游戏,接下来我们将一起学习使用c语言写一个简易版的人生重开模拟器。 网页版游戏: 人生重开模拟器 (ytecn.com) 1.实现一个简化版的人生重开模拟器 (1) 游戏开始的时…...

船舶AIS监控网络-船位信息查询:实时查询船舶动态,服务于船舶安全航行管理、港口调度计划、物流、船代、货代。【AIS动态信息编写船舶轨迹】
文章目录 引言I 预备知识1.1 相关术语1.2 主要功能1.3 MongoDB和Es各自优势II 系统架构2.1 电子海图开源JavaScript包2.2 地图渲染库2.3 地图服务调用(天地图)2.4 在Elasticsearch(ES)中存储船舶轨迹数据III 数据同步方案3.1 基于 Binlog 实时同步3.2 数据迁移工具:Canal3.3…...
方法)
Axios 中的文件上传(Upload File)方法
Axios 提供了多种上传文件(Upload File)的方法,适用于不同的上传场景。以下是其中几种常用的方法: 1. 使用 FormData 对象FormData是一个用于创建表单数据的 API,可用于发送包含文件和其他表单数据的multipart/form-d…...
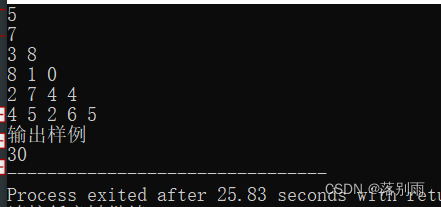
机试:数塔路径
问题描述: 代码示例: //数塔路径 #include <bits/stdc.h>using namespace std;int main(){ // 算法思想: // 逆推,将最下方和右下方的数字进行比较,哪个大则加上并更新,直至到根节点即为最大 int n;cin >> n; int nums[n1][n1]; // 输入数塔 for(int i 1;i < n…...
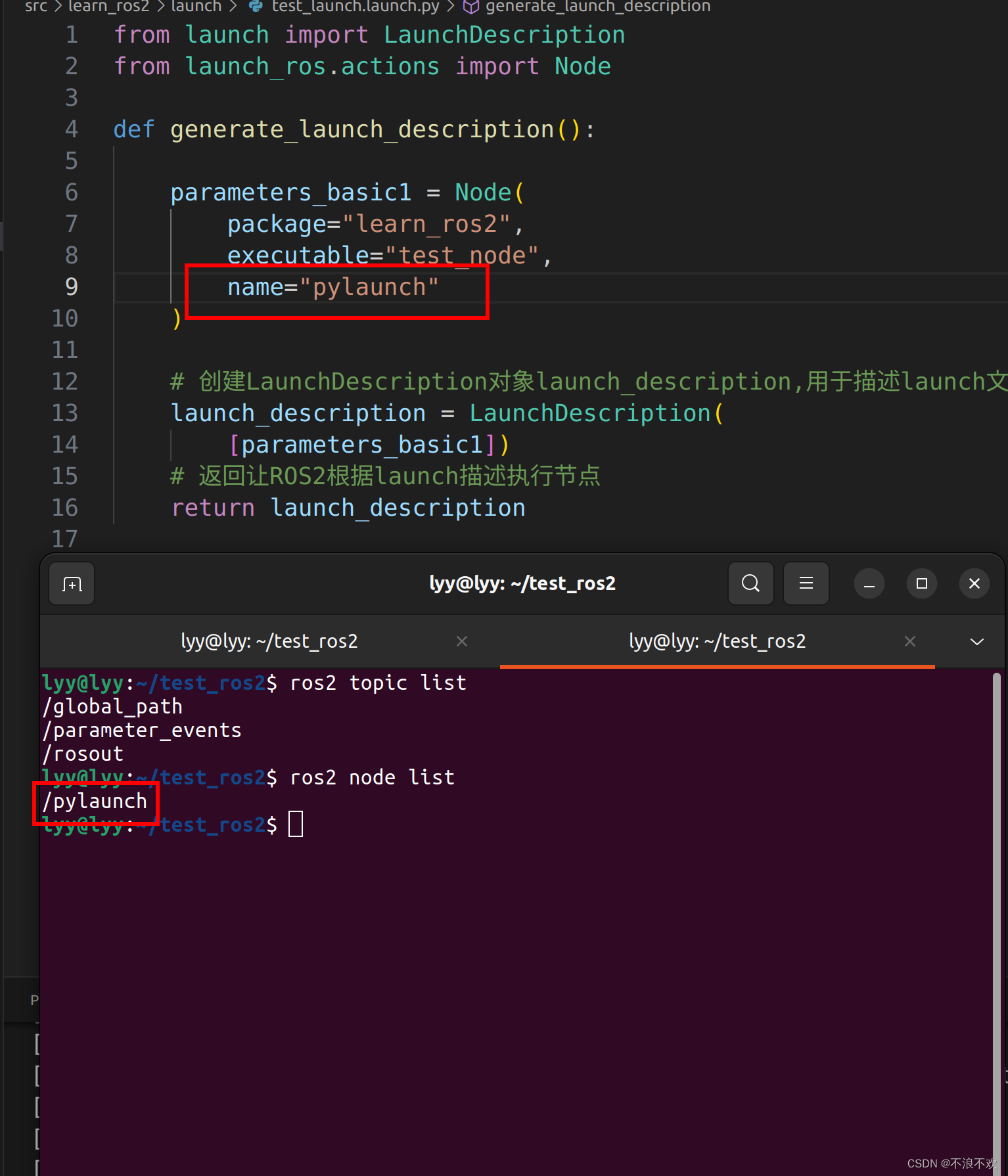
ROS2中launch编写及参数含义(xml、python)
ROS2系列文章目录 ROS2中nav_msgs/msg/Path 数据含义及使用 ROS2中std_msgs/msg/Header 数据含义及使用 ROS中TF变换详解 文章目录 ROS2系列文章目录ROS2中launch编写及参数含义(xml、python)一、ROS官方介绍二、实现案例1.编写主函数、CMakeLists.tx…...
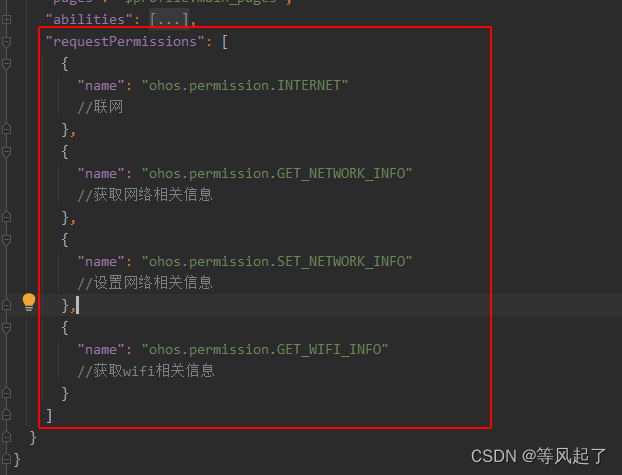
鸿蒙Socket通信示例(TCP通信)
前言 DevEco Studio版本:4.0.0.600 参考链接:OpenHarmony Socket 效果 TCPSocket 1、bind绑定本地IP地址 private bindTcpSocket() {let localAddress resolveIP(wifi.getIpInfo().ipAddress)console.info("111111111 localAddress: " …...

yolov5-v6.0详细解读
yolov5-v6.0详细解读 一、yolov5版本介绍二、网络结构2.1 Backbone特征提取部分2.1.1 ConvBNSiLU模块2.1.2 C3模块2.1.2.1 BottleNeck模块 2.1.3 SPPF模块 2.2 Neck特征融合部分2.2.1 FPN2.2.2 PANet 2.3Head模块 三、目标框回归3.1 yolo标注格式3.2 yolov4目标回归框3.3 yolov…...
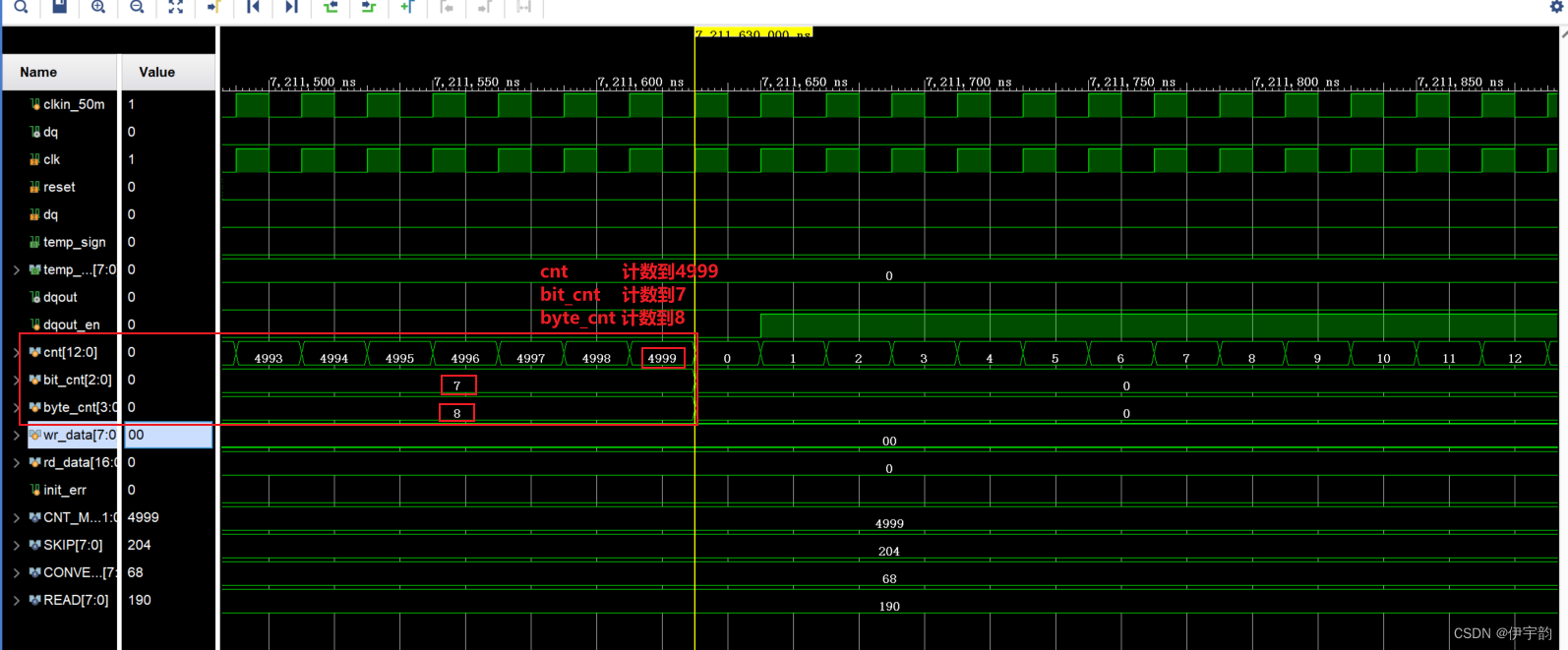
FPGA - 单总线协议(one-wire)
1,简介 单总线(one-wire)是美国 DALLAS 公司推出的外围串行扩展总线技术,与 SPI、I2C 等串行数据通信方式不同,它采用单根信号线,既传输时钟又传输数据,而且数据传输是双向的。它具有节省 I/O口…...
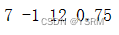
python的函数与类的定义
目录 1.函数 1.函数的定义 2.输入参数与输出参数的类型 3.输入和输出多个参数 1.普通参数 2.含有任意数量的参数 3.关键字参数 4.普通参数与多个参数的结合 2.类 1.类的定义 2.类的实例化 3.继承 1.函数 1.函数的定义 def 函数名(输入参数): 文档字符串 函数体 …...
Parade Series - WebRTC ( < 300 ms Low Latency ) T.B.D
Parade Series - FFMPEG (Stable X64) C:\Conda\parading-cam>ffmpeg -f dshow -i video"Surface Camera Front" -vcodec libx264 -preset:v ultrafast -tune:v zerolatency -an -rtsp_transport tcp -f rtsp://127.0.0.1:8554/cam0801...
【ARM】MDK在programming algorithm界面添加FLM
【更多软件使用问题请点击亿道电子官方网站查询】 1、 文档目标 解决在programming algorithm界面中无法添加想要的Flash编程算法的问题 2、 问题场景 在对于Debug进行Flash Download进行配置的时候,在programming algorithm界面中有对应的Flash编程算法。可以通过…...
springmvc学习笔记1
springmvc学习笔记part1 总概述图创建步骤创建project并在父工程中导入配置类添加为web工程检查maven配置写handller方法写配置类SpringMVC环境搭建项目部署关键步骤总结 具体设置路径设置注解接收参数(重点param参数接收路径参数接收json参数接收请求头接收和cooki…...
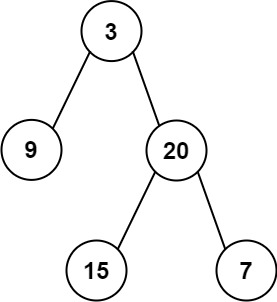
力扣106 从中序与后续遍历序列构造二叉树
文章目录 题目描述解题思路代码 题目描述 给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。 示例 1: 输入:inorder [9,3,15,20,7], …...
数字逻辑-时序逻辑电路一
一、实验目的 (1)熟悉触发器的逻辑功能及特性。 (2)掌握集成D和JK触发器的应用。 (3)掌握时序逻辑电路的分析和设计方法。 二、实验仪器及材料 三、实验内容及步骤 1、用D触发器(74LS74&am…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 [特殊字符]
LizzieYzy:你的智能围棋教练,让AI分析变得简单有趣 🎯 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy 还在为复盘找不到关键点而烦恼吗?想提升棋力却…...

GEP协议深度解读:AI智能体自我进化的基因工程
OpenAI 官宣全面支持MCP协议,标志着AI应用架构的"连接标准"已定。如果说MCP是AI时代的USB-C,解决了模型与工具的连接问题,那么GEP(Genome Evolution Protocol,基因组进化协议)则正在解决另一个更本质的问题——智能体的自我进化与生命周期管理。 作为下一代AI基…...

Taotoken的稳定性与低延迟在实时对话应用中的实际体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的稳定性与低延迟在实时对话应用中的实际体验 在开发需要快速响应的AI聊天应用时,后端API的稳定性和延迟表现是…...

Win11Debloat:Windows系统精简与隐私保护的专业解决方案
Win11Debloat:Windows系统精简与隐私保护的专业解决方案 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and …...

将deepseek v4 pro集成到codex桌面APP中使用
📕我是廖志伟,一名Java开发工程师、《Java项目实战——深入理解大型互联网企业通用技术》(基础篇)、(进阶篇)、《解密程序员的思维密码——沟通、演讲、思考的实践》作者、清华大学出版社签约作家、Java领域…...

音乐解锁工具:让加密音乐文件在任何设备自由播放
音乐解锁工具:让加密音乐文件在任何设备自由播放 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gi…...

DSP、FPGA、STM32大对决:谁才是嵌入式开发的“天选之子”?
在嵌入式开发的广阔天地里,DSP、FPGA 和 STM32(作为通用 MCU 的典型代表)可以说是三款绕不开的核心处理器。很多初学者甚至有一定经验的工程师在选择时都会陷入纠结:我的项目到底该选哪一个?为了帮你彻底理清思路&…...
)
Claude服务治理架构升级(生产环境零停机迁移实录)
更多请点击: https://codechina.net 第一章:Claude服务治理架构升级(生产环境零停机迁移实录) 为应对日益增长的推理请求量与多租户策略精细化需求,我们对Claude服务治理层实施了从单体API网关向云原生服务网格的平滑…...

如何用嘎嘎降AI处理金融学论文:金融学毕业论文降AI4.8元完整操作教程
如何用嘎嘎降AI处理金融学论文:金融学毕业论文降AI4.8元完整操作教程 第一次用降AI工具有很多不确定——传什么格式、选哪个模式、怎么验收。 这篇教程把金融学论文降AI教程的常见问题都覆盖了,主要基于嘎嘎降AI(www.aigcleaner.com&#x…...