代码随想录算法训练营第六天|242.有效的字母异位词 、349. 两个数组的交集 、 202. 快乐数、1. 两数之和
当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。哈希法是牺牲了空间换取了时间,要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。

当我们要使用集合来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的,如果需要集合是有序的,那么就用set,如果要求不仅有序还要有重复数据的话,那么就multiset。
而map 是一个key value 的数据结构,map中,对key是有限制,对value没有限制的。
242、有效的字母异位词
242、有效的字母异位词
介绍
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。

思路
暴力思路:两层for循环,一层for循环遍历字符串,另一个for循环遍历另一个字符串,看第一个for循环中的字符有没有出现过。
哈希法:数组(范围可控)、set(范围很大)、map(key--value)
本题中a-z中ASCII码是连续的。a可以对应到数组下标位0的位置,z可以对应到数据下表为25的位置。因此,可以定义一个数组hash[26];
用该数组统计第一个字符串里每个字符出现的频率。然后第二个字符串每个字符出现的频率在数组的基础上做减法。如果最后数组hash中的所有元素都为0,那么就是有效字母异位词。

//定义哈希数组,默认该数组中的值为0
int hash[26];
for(i=0;i<s.size;i++){hash[s[i]-'a']++;
}
for(i=0;i<t.size;i++){hash[t[i]-'a']--;}
for(i=0;i<26;i++){if(hash[i]!=0)return false;
}
return true;代码
class Solution {
public:bool isAnagram(string s, string t) {int hash[26] = {0};for(int i=0;i<s.size();i++){hash[s[i]-'a']++;}for(int i=0;i<t.size();i++){hash[t[i]-'a']--;}for(int i=0;i<26;i++){if(hash[i]!=0)return false;}return true;}
};349、两个数组的交集
349、两个数组的交集
介绍
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。

思路一 数值很大使用set
若数值很大,可以使用set来做哈希映射。若数值很大,但是分布很分散,也可以用set。
将nums1数组放到哈希表里,然后遍历nums2的元素,查看每个元素是否在哈希表中出现,若出现,则放到新数组中,并且最后要去重。
set在C++中:
set
unordered_set(无限存装的数组) 做映射和取值操作时效率最高
multi_set
unordered_set result (unordered_set会自动做去重)
unordered_set number_set(nums1) //直接把nums1数组转变为unordered_set存储结构
//使用num2在number_set中做遍历查询操作
for(i=0;i<nums2.size'i++){if(number_set.find(nums2[i]) != nums_set.end()) //如果找到了该元素result.inset(nums2[i])
}
return vector(result...)思路二 数值较小使用数组
定义一个1005的数组
unordered_set result;
int hash[1005]={0}
//把nums1处理成哈希表结构
for(i=0;i<nums1.size;i++){hash[nums1[i]] =1;
}
//遍历nums2
for(i=0;i<nums2.size;i++){if(hash[nums2[i]] == 1)result.insert(nums2[i])
}代码
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {unordered_set<int> result;//unordered_set会自动去重unordered_set<int> nums_set(nums1.begin(),nums1.end());for(int i=0;i<nums2.size();i++){//find方法如果没找到该元素在哈希表中,则会返回endif(nums_set.find(nums2[i])!=nums_set.end())result.insert(nums2[i]);}return vector<int>(result.begin(),result.end());}
};class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {unordered_set<int> result;//unordered_set会自动去重int hash[1005] = {0};//把nums1处理成哈希表结构for(int i=0;i<nums1.size();i++){hash[nums1[i]] = 1;}//遍历nums2for(int i=0;i<nums2.size();i++){if(hash[nums2[i]]==1)result.insert(nums2[i]);}return vector<int>(result.begin(),result.end());}
};202、快乐数
202、快乐数
介绍


思路
如何求一个数中每一位的平方和。
明确无限循环的概念,即如果新的平方和在之前的计算中出现过(因此可以想到使用哈希表),那么这就算一个无限循环。
代码
class Solution {
public:int getSum(int n){int sum = 0;while(n){sum = sum + (n%10)*(n%10);n = n/10;}return sum;}bool isHappy(int n) {unordered_set<int> set;//定义存储每次的平方和while(1){int sum = getSum(n);if(sum == 1)return true;// 如果这个sum在set中出现过,那么就说明陷入无限循环,要立即跳出if(set.find(sum)!=set.end()){return false;}else{set.insert(sum);}n = sum;}}
};1、两数之和
1、两数之和
介绍
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。


思路
每当遇到要判断这个元素是否出现过的第一反应就应该是哈希法。
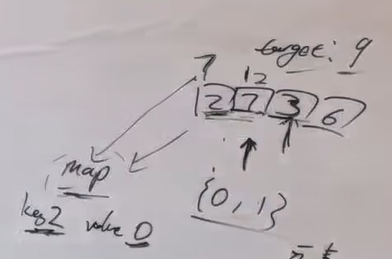
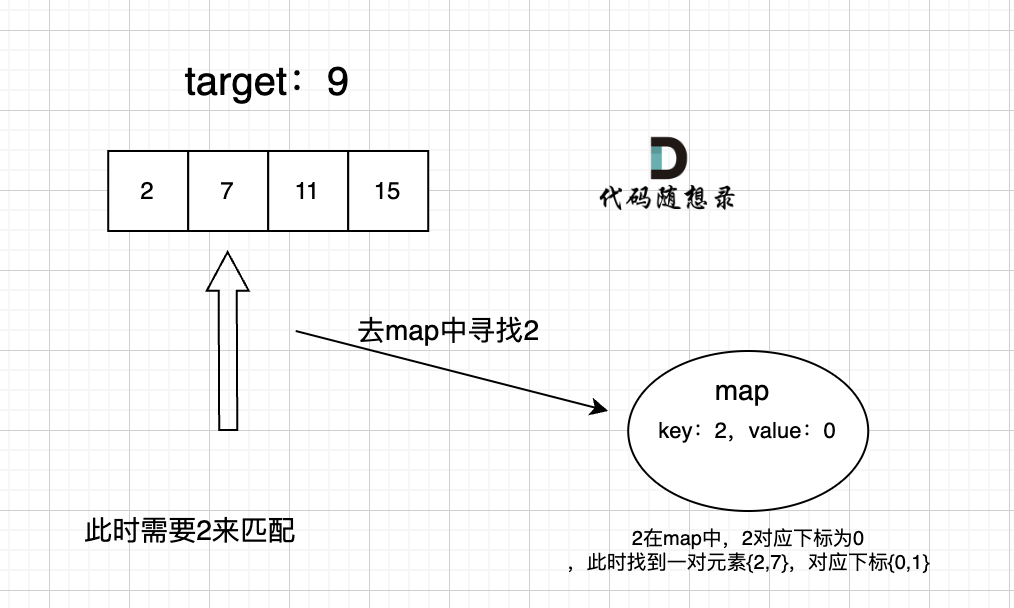
例如:如果遍历到3,就应该判断前面是否遍历过6。
如何判断是否遍历过?将遍历过的元素加入到一个集合里。每次遍历新元素x的时候,在这个集合里判断9-x是否出现过。
集合---采用一种哈希表的结构--由于不仅要找一个元素,还要知道这个元素在原数组中的下标,所以应该选用map结构。

map的key和value---思考我们查找的是什么,我们查找的是一个元素是否出现过,那么就应该将元素作为map中的key。(map能以很快的速度查找key【这里的元素】是否在map中出现过)
map在该题中是存放我们遍历过的元素。
//map--unordered_map(存和读效率最高)--multi_map
//首先定义一个map,要定义该map的key和value,用于存放遍历过的元素
unordered_map(int,int) map;
for(i=0;i<nums.size;i++){//查询每个元素是否在map中s = target - nums[i] //要查询的keyiter = map.find(s);if(iter!=map.end()) //如果要查询的key在map中出现过return {iter->value,i};map.insert(nums[i],i);//把遍历过的元素加入到map中
}
return {};代码
class Solution {
public:vector<int> twoSum(vector<int>& nums, int target) {std::unordered_map<int,int> map;for(int i=0;i<nums.size();i++){//查询每个元素是否在map中int s = target - nums[i];auto iter = map.find(s);if(iter!=map.end())return {iter->second,i};map.insert(pair<int,int>(nums[i],i));}return {};}
};相关文章:
代码随想录算法训练营第六天|242.有效的字母异位词 、349. 两个数组的交集 、 202. 快乐数、1. 两数之和
当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。哈希法是牺牲了空间换取了时间,要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。当我们要使用集合来解决哈希问题的时候,优先使用…...
【STL】模拟实现list
目录 1、list介绍 所要实现类及其成员函数接口总览 2、结点类的模拟实现 基本框架 构造函数 3、迭代器类的模拟实现 迭代器类存在的意义 3.1、正向迭代器 基本框架 默认成员函数 构造函数 运算符重载 --运算符重载 !运算符重载 运算符重载 *运算符重载 …...

Spring Cloud Alibaba全家桶(五)——微服务组件Nacos配置中心
前言 本文小新为大家带来 微服务组件Nacos配置中心 相关知识,具体内容包括Nacos Config快速开始指引,搭建nacos-config服务,Config相关配置,配置的优先级,RefreshScope注解等进行详尽介绍~ 不积跬步,无以至…...

【微信小程序】-- 页面事件 - 下拉刷新(二十五)
💌 所属专栏:【微信小程序开发教程】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! &…...
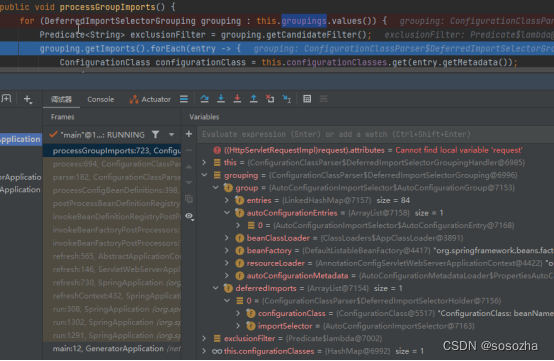
springboot启动过程加载数据笔记(springboot3)
SpringApplication AbstractApplicationContext PostProcessorRegistrationDelegate ConfigurationClassPostProcessor ConfigurationClassParser 一堆循环和调用 ComponentScanAnnotationParser扫描 processConfigurationClass.doProcessConfigurationClass(configClass, so…...

中文代码86
PK 嘚釦 docProps/PK 嘚釦諿A眎 { docProps/app.xml漅薾?糤?D?v拢W4揣狤"攃e9 睔貣m*:PAz韒g?项弇}R珁湧4嶱 ]I禑菦?櫮戵\U佳 珩 ]铒e礎??X(7弅锿?jl筀儸偛佣??z窊梈ZT炰攷 ?\ 銒沆?状尧绥>蕮 ?斬殕{do]?o乗YX?:??罢秗,泿)怟 …...
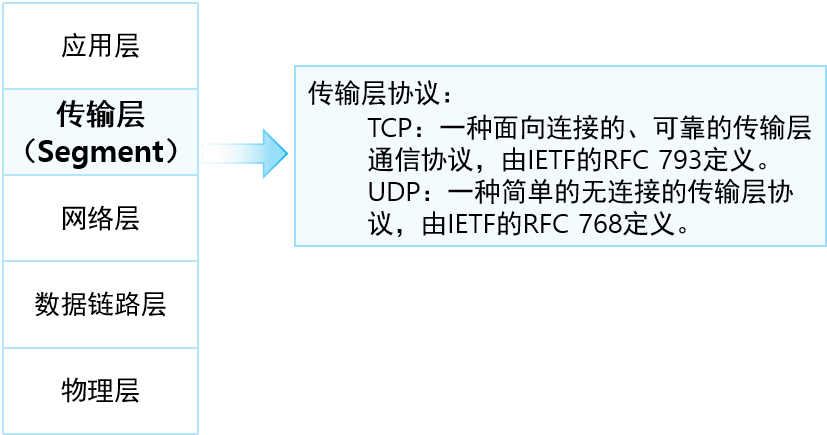
网络参考模型
OSI参考模型 应用层 不服务于任何其他层,就是位APP提供相应的服务,不如HTTP、域名解析DNS提供服务表示层 1.使得应用数据能够被不同的系统(Windows\Linux)进行识别和理解 2.数据的解码和编码、数据的加密与解密、数据的压缩和解…...

Spark Tungsten
Spark Tungsten数据结构Unsafe Row内存页管理全阶段代码生成火山迭代模型WSCG运行时动态生成Tungsten (钨丝计划) : 围绕内核引擎的改进: 数据结构设计全阶段代码生成(WSCG,Whole Stage Code Generation) 数据结构 Tungsten 在…...

2023年总结的web前端学习路线分享(学习导读)
如果你打开了这篇文章,说明你是有兴趣想了解前端的这个行业的,以下是博主2023年总结的一些web前端的学习分享路线,如果你也想从事前端或者有这方面的想法的,请接着往下看! 前端发展前景 前端入门 巩固基础 前端工程…...
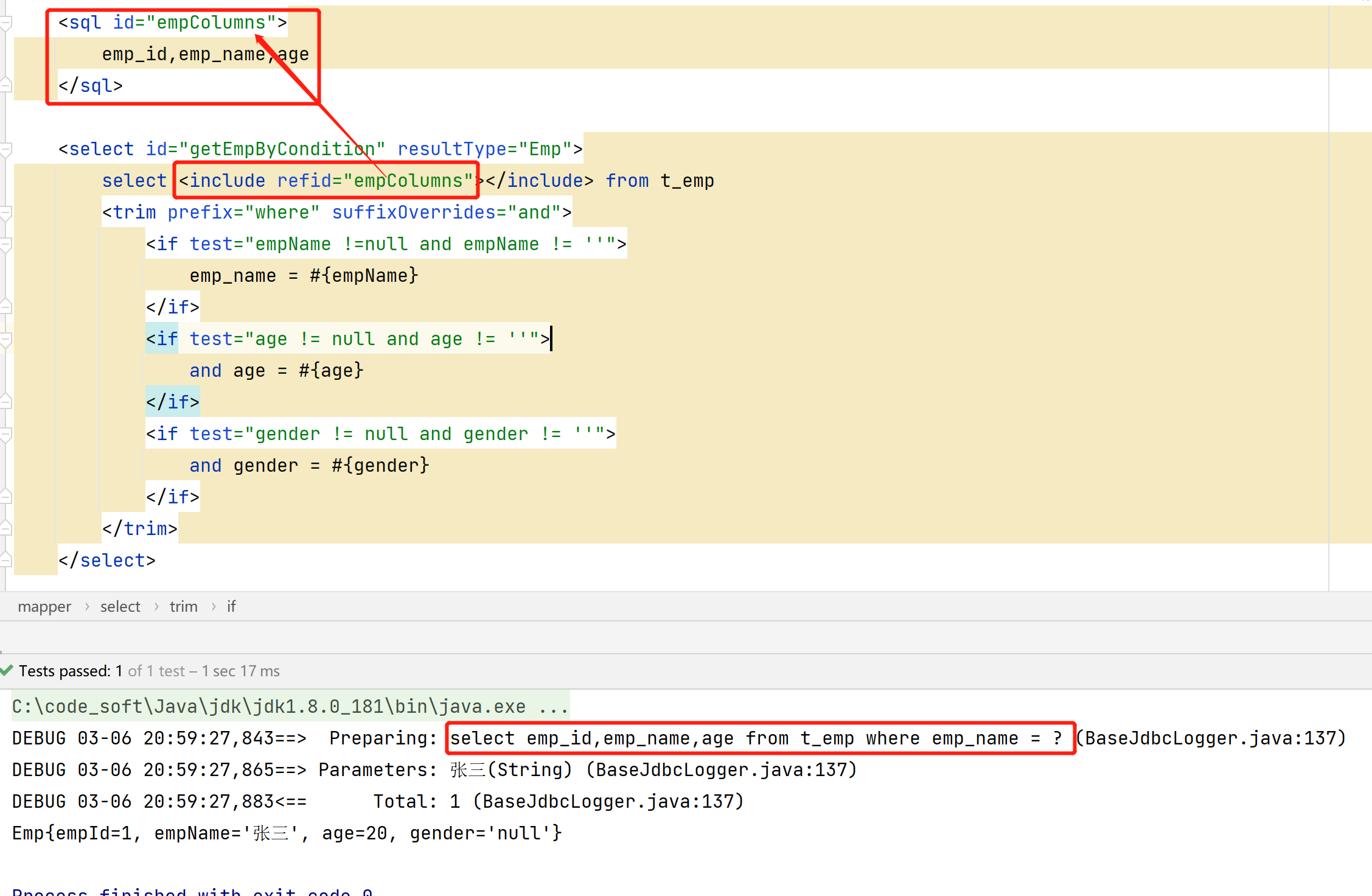
MyBatis学习笔记(十) —— 动态SQL
10、动态SQL MyBatis框架的动态SQL技术是一种根据特定条件动态拼装SQL语句的功能,它存在的意义是为了解决拼接SQL语句字符串的痛点问题。 动态SQL: 1、if 标签:通过test属性中的表达式判断标签中的内容是否有效(是否会拼接到sql中…...

剑指 Offer 55 - II. 平衡二叉树
剑指 Offer 55 - II. 平衡二叉树 难度:easy\color{Green}{easy}easy 题目描述 输入一棵二叉树的根节点,判断该树是不是平衡二叉树。如果某二叉树中任意节点的左右子树的深度相差不超过1,那么它就是一棵平衡二叉树。 示例 1: 给定二叉树 […...
一文吃透前端低代码的 “神仙生活”
今天来说说前端低代码有多幸福? 低代码是啥?顾名思义少写代码…… 这种情况下带来的幸福有:代码写得少,bug也就越少(所谓“少做少错”),因此开发环节的两大支柱性工作“赶需求”和“修bug”就…...
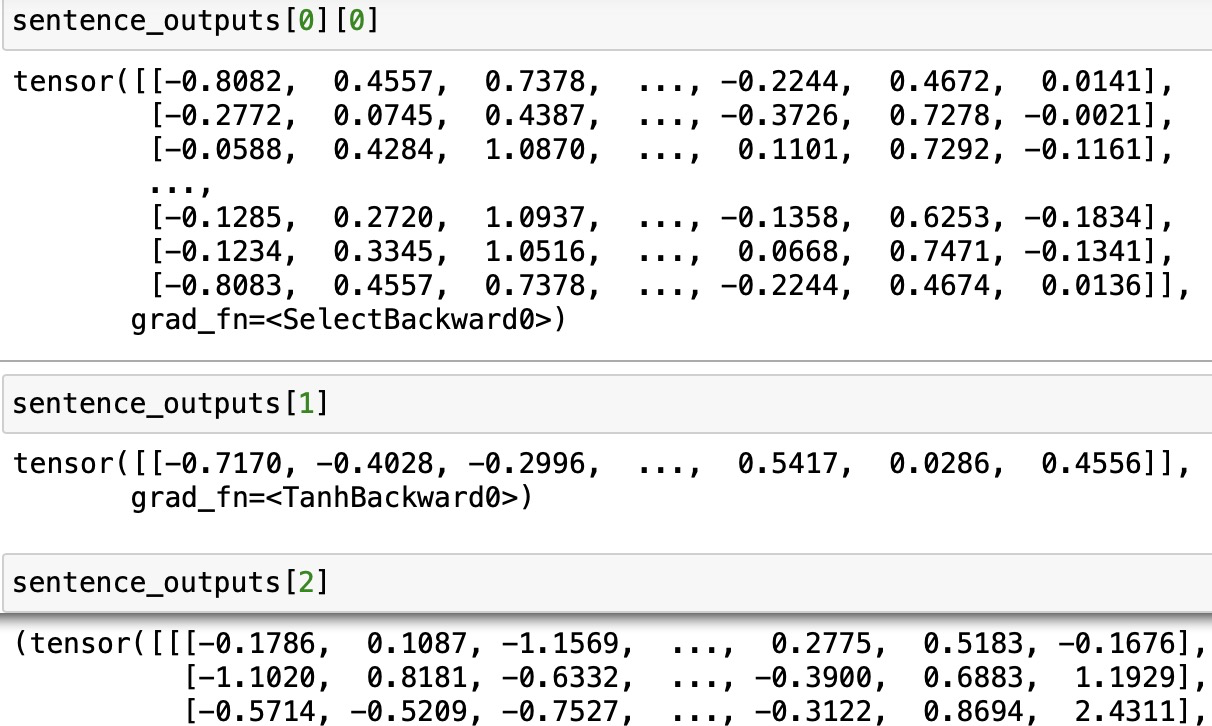
【深度学习】预训练语言模型-BERT
1.BERT简介 BERT是一种预训练语言模型(pre-trained language model, PLM),其全称是Bidirectional Encoder Representations from Transformers。下面从语言模型和预训练开始展开对预训练语言模型BERT的介绍。 1-1 语言模型 语言模型 …...
C++类的组合
C类的组合什么是类的组合初始化参数列表使用类的组合案例分析组合构造和析构顺序问题this指针基本用法和作用什么是类的组合 类的组合就是以另一个对象为数据成员,这种情况称为类的组合 1.优先使用类的组合,而不是继承 2.组合表达式的含义 一部分关系 初…...
的配置与使用)
2.伪随机数生成器(ctr_drbg)的配置与使用
零、随机数应用 生成盐,用于基于口令的密码 生成密钥,用于加密和认证 生成一次性整数Nonce,防止重放攻击 生成初始化向量IV 构成 种子,真随机数生成器的种子来源于物理现象 内部状态,种子用来初始化内部状态 一、真随机数和伪随机数 1.区别 随机数在安全技术中通常被用于…...

CentOS7 切换图形模式和多用户命令行模式
备注: 主机名 hw 含义:hardware 缩写,意思是硬件(物理机) 文章目录1、查看源头2、查看当前系统运行模式3、设置系统运行模式为多用户命令行模式4、查看当前系统运行模式5、重启系统6、确认当前系统运行模式7、设置系统…...

在linux上用SDKMan对Java进行多版本管理
在linux上用SDKMan对Java进行多版本管理 有一个工具叫SDKMan,它允许我们这样做。官方网站这样描述: TIP: "SDKMan 是一个工具,用于在大多数基于Unix的系统上管理多个软件开发工具包的并行版本。它提供了一个方便的命令行接口(CLI)和API,…...
、Gson(JsonObject)区别)
JSONObject、fastJson(JsonObject)、Gson(JsonObject)区别
概述 Java中并没有内置的 JSON 解析,需要使用第三方类库 fastJson :阿里巴巴的JSON 库,优势在于解析速度快,解析效率高,可以轻松处理大量的 JSON 数据JackSon : 社区十分活跃,spring框架默认使…...

如何在CSDN中使用ChatGPT
本篇文章致力于帮助大家理解和使用ChatGPT(现在CSDN改成”C知道“了)。简介ChatGPT是OpenAI公司开发的一种大型语言模型。它是一种基于Transformer架构的深度学习模型,可以对语言进行建模和生成。它可以处理问答、对话生成、文本生成等多种任…...
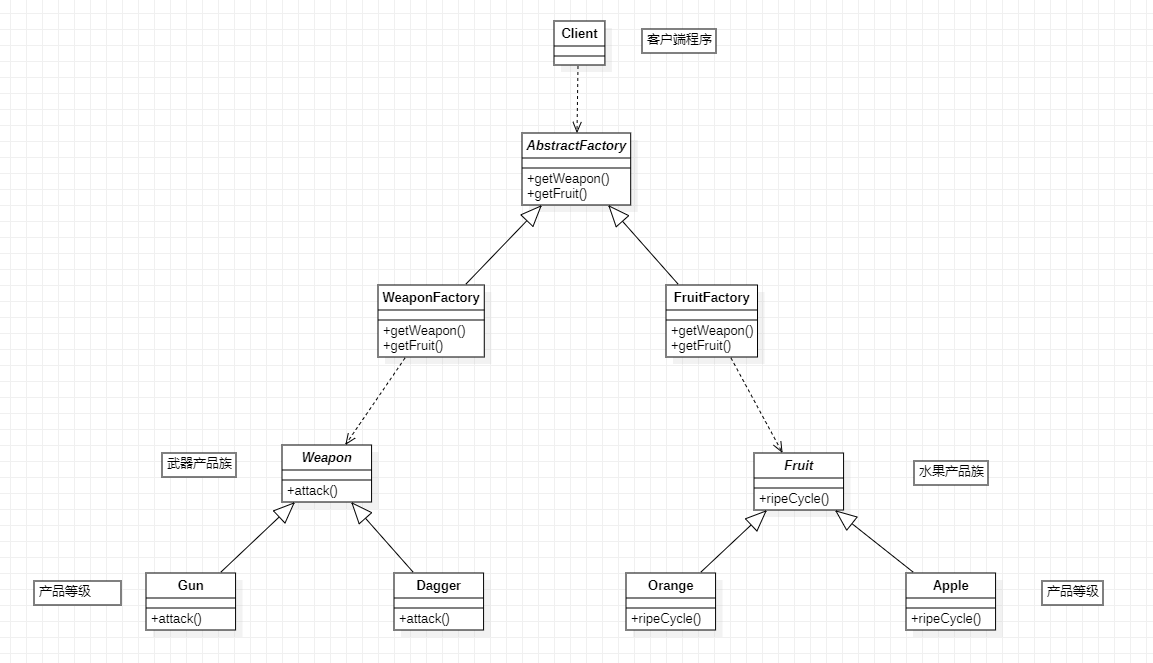
【Spring6】| GoF之工厂模式
目录 一:GoF之工厂模式 1. 工厂模式的三种形态 2. 简单工厂模式 3. 工厂方法模式 4. 抽象工厂模式(了解) 一:GoF之工厂模式 (1)GoF(Gang of Four),中文名——四人组…...
)
别再死记硬背了!用Python手把手带你画一棵哈夫曼树(附完整代码)
用Python动态构建哈夫曼树:从理论到可视化的完整实践指南 在计算机科学中,数据压缩是一个永恒的话题。想象一下,当你需要传输大量数据时,如何用最少的比特数表示最多的信息?这就是哈夫曼编码要解决的问题。传统的教科书…...

工业触控一体机选型与Linux应用开发全解析
1. 项目概述:当工业现场需要一块“聪明”的屏幕最近在跟进一个智慧工厂的MES(制造执行系统)终端升级项目,客户现场的老式工控机搭配笨重的显示器,不仅布线杂乱,操作响应慢,而且维护起来极其麻烦…...

打造极致氛围感编码环境:从视觉、听觉到工作流的全栈实践指南
1. 项目概述:当“氛围感”遇上“编码”,一个宝藏仓库的诞生如果你和我一样,是个对开发环境、工具流和“仪式感”有执念的程序员,那你肯定不止一次地折腾过自己的IDE主题、终端配色、字体,甚至桌面的壁纸和音乐。我们内…...

ARM SCTLR2_EL2寄存器解析与虚拟化安全控制
1. ARM SCTLR2_EL2寄存器架构解析SCTLR2_EL2是ARMv8/v9架构中EL2(Hypervisor)级别的扩展系统控制寄存器,作为标准SCTLR_EL2的补充,它通过掩码位机制实现了对关键系统功能的细粒度控制。这个64位寄存器主要包含两类功能字段&#x…...

GitHub仓库自动化同步工具xpull:原理、配置与实战应用
1. 项目概述:一个被低估的GitHub数据同步利器 如果你经常在GitHub上管理多个仓库,或者需要将某个仓库的特定分支、标签甚至整个提交历史同步到另一个仓库,那么你很可能经历过手动操作的繁琐。无论是为了备份、镜像、还是将上游的更新合并到自…...

Flutter 表单处理完全指南
Flutter 表单处理完全指南 引言 表单是移动应用中不可或缺的一部分,Flutter 提供了强大的表单处理能力。本文将深入探讨 Flutter 表单的各种用法和高级技巧。 基础概念回顾 核心组件 Form: 表单容器TextFormField: 文本输入字段FormState: 表单状态管理GlobalKey: 全…...

超长上下文时代来临:百万Token窗口实测,我的工作流彻底变了
前言:一个让我彻底改变工作方式的实验 2026年初,我做了一件以前根本不敢想的事:把一份长达800页的技术规范文档,直接塞进了一个大模型的上下文窗口,然后让它帮我找出其中所有与安全性相关的条款,并逐条解释…...

政务知识图谱 + 大模型:打造可解释、可信任 AI
在数字政务加速迈向智能化的今天,AI 技术已深度渗透到政务服务、社会治理、机关办公等各个场景,从智能问答、政策解读到辅助决策、风险预警,AI 正在成为提升政务效能、优化服务体验的核心力量。但与此同时,传统 AI 技术在政务领域…...

用Adafruit MONSTER M4SK改造Boglin玩具:赋予经典怪物互动电子眼
1. 项目概述:当经典玩具遇上开源硬件如果你和我一样,对上世纪80年代那些造型古怪、充满想象力的玩具情有独钟,同时又是个喜欢动手折腾的创客,那么这个项目绝对能让你兴奋起来。今天我们要聊的,是如何让一个几乎被遗忘的…...

Arduino ESP32终极配置指南:5步解决环境搭建难题
Arduino ESP32终极配置指南:5步解决环境搭建难题 【免费下载链接】arduino-esp32 Arduino core for the ESP32 family of SoCs 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 Arduino ESP32是专为ESP32系列芯片设计的开源开发板支持包&am…...