郭炜老师mooc第十一章数据分析和展示(numpy,pandas, matplotlib)
多维数组库numpy

numpy创建数组的常用函数

# numpy数组import numpy as np #以后numpy简写为np
print(np.array([1,2,3])) #>>[1 2 3]
print(np.arange(1,9,2)) #>>[1 3 5 7] 不包括9
print(np.linspace(1,10,4)) #>>[ 1. 4. 7. 10.]
# linespace(x,y,n),创建一个由区间[x,y]的n-1等分点构成的一维数组,包含x和yprint(np.random.randint(10,20,[2,3]))
#>>[[12 19 12]
#>> [19 13 10]]print(np.random.randint(10,20,5)) #>>[12 19 19 10 13]
a = np.zeros(3)
print(a) #>>[ 0. 0. 0.]
print(list(a)) #>>[0.0, 0.0, 0.0]
# 列表每个元素之间有一个逗号隔开a = np.zeros((2,3),dtype=int) #创建一个2行3列的元素都是整数0的数组
print(a)numpy数组常用属性和函数
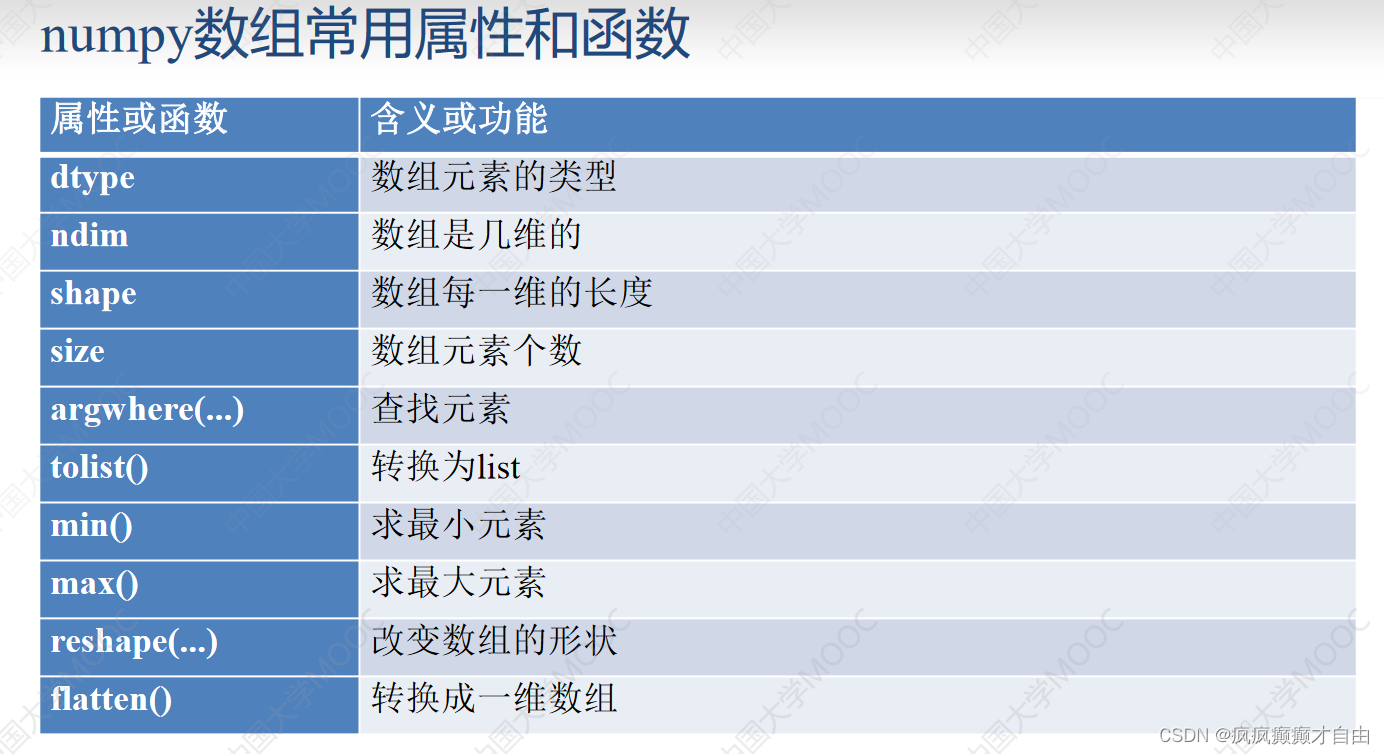
# numpy数组常用属性和函数import numpy as np
b = np.array([i for i in range(12)])
#b是[ 0 1 2 3 4 5 6 7 8 9 10 11]
print(b)a = b.reshape((3,4)) #转换成3行4列的数组,b不变
print(len(a)) #>>3 a有3行
print(a.size) #>>12 a的元素个数是12
print(a.ndim) #>>2 a是2维的
print(a.shape) #>>(3, 4) a是3行4列
print(a.dtype) #>>int32 a的元素类型是32位的整数
L = a.tolist() #转换成列表,a不变
print(L)
#>>[[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11]]
b = a.flatten() #转换成一维数组
print(b) #>>[ 0 1 2 3 4 5 6 7 8 9 10 11 ]numpy数组元素的增删

# numpy添加数组元素import numpy as np
a = np.array((1,2,3)) #a是[1 2 3]
b = np.append(a,10) #a不会发生变化
print(a)
print(b) #>>[ 1 2 3 10]
print(np.append(a,[10,20])) #>>[ 1 2 3 10 20]
c = np.zeros((2,3),dtype=int) #c是2行3列的全0数组
print(np.append(a,c)) #>>[1 2 3 0 0 0 0 0 0]
print(np.concatenate((a,[10,20],a)))
#>>[ 1 2 3 10 20 1 2 3]
print(np.concatenate((c,np.array([[10,20,30]]))))
#c拼接一行[10,20,30]得新数组
print(np.concatenate((c,np.array([[1,2],[10,20]])),axis=1))
#c的第0行拼接了1,2两个元素、第1行拼接了10,20两个新元素后得到新数素# numpy删除数组元素import numpy as np
a = np.array((1,2,3,4))
b = np.delete(a,1) #删除a中下标为1的元素,a不会改变
print(b) #>>[1 3 4]
b = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
print("b删除前:\n",b,"\nb删除后:")print("按行删除:\n", np.delete(b,1,axis=0)) #删除b的第1行得新数组print("按列删除:\n", np.delete(b,1,axis=1)) #删除b的第1行得新数组#>>[[ 1 2 3 4]
#>> [ 9 10 11 12]]
print(np.delete(b,1,axis=1)) #删除b的第1列得新数组
print(np.delete(b,[1,2],axis=0)) #删除b的第1行和第2行得新数组
print(np.delete(b,[1,3],axis=1)) #删除b的第1列和第3列得新数组在numpy数组中查找元素
- np.argwhere( a ):返回非0的数组元组的索引,其中a是要索引数组的条件。
- np.where(condition) 当where内只有一个参数时,那个参数表示条件,当条件成立时, where返回的是每个符合condition条件元素的坐标,返回的是以元组的形式。
# 在numpy数组中查找元素import numpy as np
a = np.array((1,2,3,5,3,4))
print("a: ", a)pos = np.argwhere(a==3) #pos是[[2] [4]]
print(pos)
# np.argwhere( a ):返回非0的数组元组的索引,其中a是要索引数组的条件。a = np.array([[1,2,3],[4,5,2]])
print(2 in a) #>>True
pos = np.argwhere(a==2) #pos是[[0 1] [1 2]]
print(pos)b = a[a>2] #抽取a中大于2的元素形成一个一维数组
print(b) #>>[3 4 5]
a[a > 2] = -1 #a变成[[ 1 2 -1] [-1 -1 2]]
print(a)
numpy数组的切片
numpy数组的切片是“视图”,是原数组的一部分,而非一部分的拷贝
# numpy数组的切片是“视图”,是原数组的一部分,而非一部分的拷贝import numpy as np
a = np.arange(8) #a是[0 1 2 3 4 5 6 7]
b = a[3:6] #注意,b是a的一部分
print(b) #>>[3 4 5]
c = np.copy(a[3:6]) #c是a的一部分的拷贝
b[0] = 100 #会修改a
print(a) #>>[ 0 1 2 100 4 5 6 7]
print(c) #>>[3 4 5] c不受b影响
a = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]])
print("a:\n", a)b = a[1:3,1:4] #b是>>[[ 6 7 8] [10 11 12]]
print("b:\n", b)数据分析库pandas
Pandas 属于 Python 第三方数据处理库,它基于 NumPy 构建而来,主要用于数据的处理与分析。我们知道对于机器学习而言数据是尤为重要,如果没有数据就无法训练模型。Pandas 提供了一个简单高效的 DataFrame 对象(类似于电子表格),它能够完成数据的清洗、预处理以及数据可视化工作等。除此之外,Pandas 能够非常轻松地实现对任何文件格式的读写操作,比如 CSV 文件、json 文件、excel 文件。(小伟学长:第三节 基本人工智能工具的介绍与使用 · 语雀)
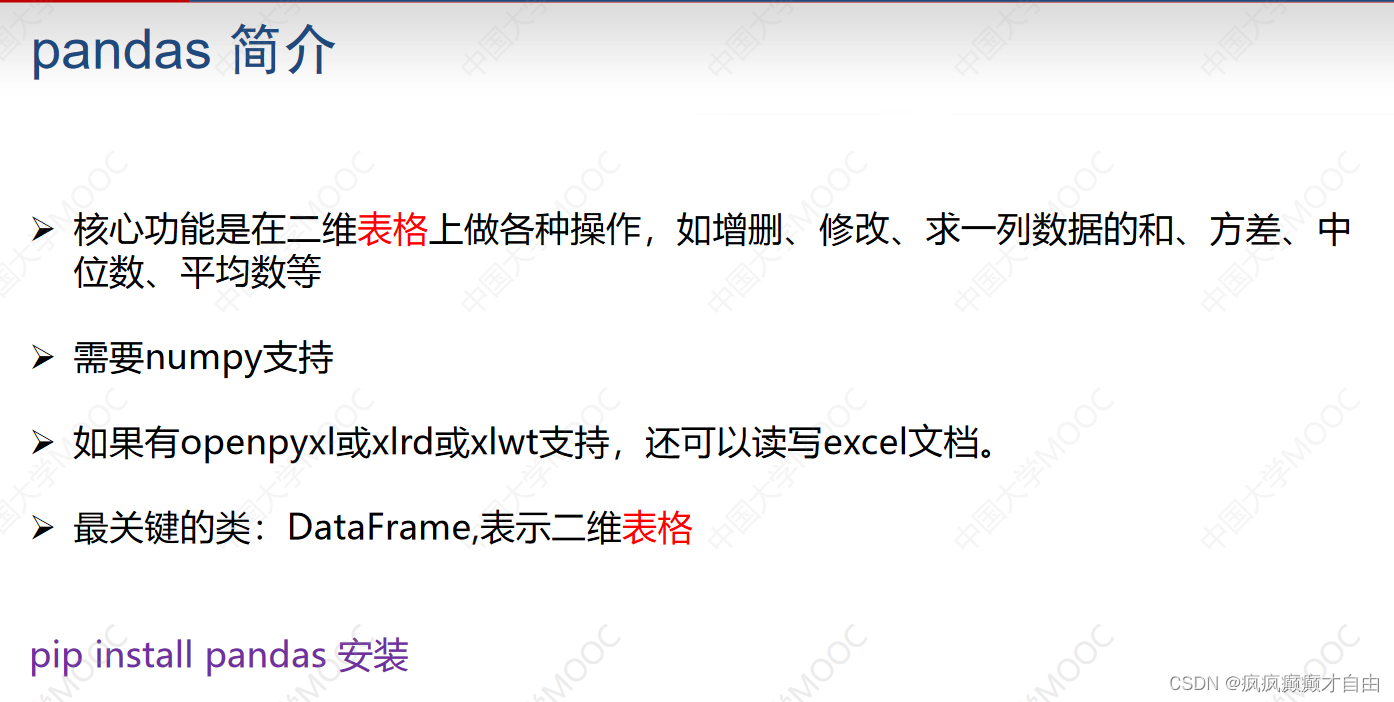
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
Pandas 主要的数据结构是 Series(一维)与 DataFrame(二维)
Series是带标签的一维数组,可存储整数、浮点数、字符串、Python 对象等类型的数据,轴标签统称为索引.。
Pandas会默然用0到n-1来作为series的index,但也可以自己指定index(可以把index理解为dict里面的key)。
Series的使用
import pandas as pd
s = pd.Series(data = [80, 90, 100], index = ['Chinese', 'Math', 'English'])
# pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
# Pandas 主要的数据结构是 Series(一维)与 DataFrame(二维)print(s)for x in s:print(x, end = ' ') # x是data,不输出index
print("#####################")print(s['Chinese'], s[1])
print(s[0:2]['Math'])
print(s['Math':'English'][1])
for i in range(len(s.index)): #>>语文 数学 英语print(s.index[i],end = " $ ")
print('')
s['体育'] = 110 #在尾部添加元素,标签为'体育',值为110
s.pop('Math') #删除标签为'数学’的元素
s2 = s._append(pd.Series(120,index = ['政治'])) #不改变s
# pandas在0.20.0后移除这个append方法,你可以使用 _append 来替换append。print(s2['Chinese'],s2['政治']) #>>80 120
print(list(s2)) #>>[80, 100, 110, 120]print("s:\n", s)
print(s.sum(),s.min(),s.mean(),s.median())
#>>290 80 96.66666666666667 100.0 输出和、最小值、平均值、中位数
print(s.idxmax(),s.argmax()) #>>体育 2 输出最大元素的标签和下标DataFrame的使用
DataFrame是带行列标签的二维表格,它的每一列都是一个Series
pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
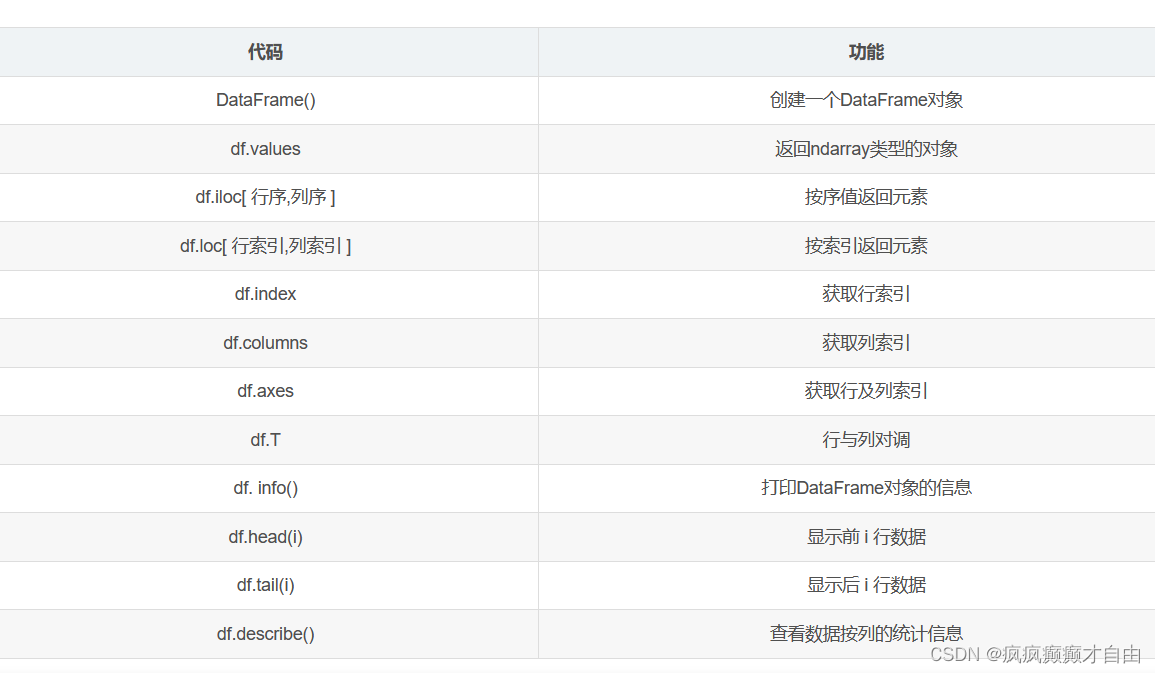
【参考文章】:Pandas DataFrame的基本属性详解_pd.dataframe()有哪些参数-CSDN博客
DataFrame的构造和访问
# DataFrame的构造和访问
# DataFrame是带行列标签的二维表格,它的每一列都是一个Seriesimport pandas as pd
pd.set_option('display.unicode.east_asian_width',True)
#输出对齐方面的设置scores = [['男',108,115,97],['女',115,87,105],['女',100,60,130],['男',112,80,50]]
names = ['刘一哥','王二姐','张三妹','李四弟']
courses = ['性别','语文','数学','英语']
df = pd.DataFrame(data=scores,index = names,columns = courses)
# pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)print("df:")
print(df)print("df.values:")
print(df.values)
print("**************")print(df.values[0][1],type(df.values))#>>108 <class 'numpy.ndarray'>
print(list(df.index)) #>>['刘一哥', '王二姐', '张三妹', '李四弟']
print(list(df.columns)) #>>['性别', '语文', '数学', '英语']
print(df.index[2],df.columns[2]) #>>张三妹 数学
s1 = df['语文'] #s1是个Series,代表'语文'那一列
print("语文那一列:")
print(s1)print(s1['刘一哥'],s1[0]) #>>108 108 刘一哥语文成绩
print(df['语文']['刘一哥']) #>>108 列索引先写
s2 = df.loc['王二姐'] #s2也是个Series,代表“王二姐”那一行
print(s2['性别'],s2['语文'],s2[2])
#>>女 115 87 王二姐的性别、语文和数学分数
DataFrame的切片:
#DataFrame的切片:
#iloc[行选择器, 列选择器] 用下标做切片
#loc[行选择器, 列选择器] 用标签做切片
#DataFrame的切片是视图
df2 = df.iloc[1:3] #行切片,是视图,选1,2两行
df2 = df.loc['王二姐':'张三妹'] #和上一行等价
print(df2)df2 = df.iloc[:,0:3] #列切片(是视图),选0、1、2三列
df2 = df.loc[:,'性别':'数学'] #和上一行等价
print(df2)df2 = df.iloc[:2,[1,3]] #行列切片
df2 = df.loc[:'王二姐',['语文','英语']] #和上一行等价
print(df2)df2 = df.iloc[[1,3],2:4] #取第1、3行,第2、3列
df2 = df.loc[['王二姐','李四弟'],'数学':'英语'] #和上一行等价
print(df2)
DataFrame的分析统计
# DataFrame的分析统计print("---下面是DataFrame的分析和统计---")
print(df.T) #df.T是df的转置矩阵,即行列互换的矩阵
print(df.sort_values('语文',ascending=False)) #按语文成绩降序排列
# sort_values(....inplace=True,axis=1....) 则原地排序,将各列排序print(df.iloc[:, 1:].sum()['语文'],df.iloc[:, 1:].mean()['数学'],df.iloc[:, 1:].median()['英语'])
# >>435 85.5 101.0 语文分数之和、数学平均分、英语中位数
print(df.iloc[:, 1:].min()['语文'],df.iloc[:, 1:].max()['数学'])
#>>100 115 语文最低分,数学最高分print(df.iloc[:, 1:].max(axis = 1)['王二姐']) #>>115 王二姐的最高分科目的分数
print(df['语文'].idxmax()) #>>王二姐 语文最高分所在行的标签
print(df['数学'].argmin()) #>>2 数学最低分所在行的行号
print(df.loc[(df['语文'] > 100) & (df['数学'] >= 85)])
DataFrame的修改和增删
# DataFrame的修改和增删print("---下面是DataFrame的增删和修改---")
df.loc['王二姐','英语'] = df.iloc[0,1] = 150 #修改王二姐英语和刘一哥语文成绩df['物理'] = [80,70,90,100] #为所有人添加物理成绩这一列
df.insert(1,"体育",[89,77,76,45]) #为所有人插入体育成绩到第1列
df.loc['李四弟'] = ['男',100,100,100,100,100] #修改李四弟全部信息
df.loc[:,'语文'] = [20,20,20,20] #修改所有人语文成绩
df.loc['钱五叔'] = ['男',100,100,100,100,100] #加一行
df.loc[:,'英语'] += 10 #>>所有人英语加10分
df.columns = ['性别','体育','语文','数学','English','物理'] #改列标签
print(df)删除函数是axis=0表示行,axis = 1表示列。
除了delete用axis=0表示行以外,其他的大部分函数都是axis=1来表示行。
链接:axis = 0,axis = 1到底表示按行计算还是按列计算-CSDN博客
df.drop( ['体育','物理'],axis=1, inplace=True) #删除体育和物理成绩
df.drop( '王二姐',axis = 0, inplace=True) #删除 王二姐那一行
print(df)用pandas读excel文档,读取的每张工作表都是一个DataFrame
# 用pandas读excel文档,读取的每张工作表都是一个DataFrameimport pandas as pdpd.set_option('display.unicode.east_asian_width',True)dt = pd.read_excel(r"D:\桌面\excel.xlsx",sheet_name=[0], index_col=0)#读取第0和第1张工作表df = dt[0] #dt是字典,df是DataFrame
print(df.iloc[0,0]) #>>4080 4080
print(df)不想写了,把郭炜老师的讲义截屏下来,后面想深入学习再来看。



pandas读写csv文件

matplotlib
绘制基本直方图
matplotlib.pyplot.figure():
- Create a new figure, or activate an existing figure.
- 功能: 创建一个新的图形 或激活一个已有的图形
- **注意: 若不添加描述,默认图形描述为figure1; **
函数原型 subplot(nrows, ncols, index, **kwargs),一般我们只用到前三个参数,将整个绘图区域分成 nrows 行和 ncols 列,而 index 用于对子图进行编号。
add_subplot方法的参数是一个三位数:
百位上的数代表画布上下分成几块
十位上的数代表画布左右分成几块
个位上的数代表该块副画布的编号

【参考链接】python matplotlib fig = plt.figure() fig.add_subplot()-CSDN博客
ax.set_title:设置图片的标题;
set_title(self, label, fontdict=None, loc=’center’, pad=None, **kwargs)
参数说明:
fontdict: 一个字典,比如fontdict={‘size’:16}
loc: 位于中间还是两边,可以是center, left, rightax.set_xlabel:设置图片x轴的名称
ax.set_ylabel:设置图片y轴的名称
ax.set_xticks(x_ticks):设置图片x轴的刻度
ax.set_xticklabels(labels):设置图片x轴刻度上的标签
注:
ax.set系列函数 的语法与 plt 等效
ax.set_ylabel() plt.ylabel()
ax.set_xlabel() plt.xlabel()
ax.set_xticks() plt.xticks()
绘制基本直方图:
# 绘制基本直方图import matplotlib.pyplot as plt #以后 plt 等价于 matplotlib.pyplot
from matplotlib import rcParams
'''
rcParams 是 Matplotlib 库中的一个字典对象,用于存储和管理全局的默认参数配置。
在 Matplotlib 中,可以通过修改 rcParams 中的参数值来改变图形的默认行为。这些参数包括
图形的颜色、线型、线宽、字体样式、图像分辨率等。
rcParams 的全称是“runtime configuration parameters”,它在运行时控制着 Matplotlib 的行为。
通过修改 rcParams 中的参数,您可以自定义 Matplotlib 的默认设置,使其符合您的需求,
而无需在每个图形绘制时都手动指定这些参数。
'''rcParams['font.family'] = rcParams['font.sans-serif'] = 'SimHei'
#设置中文支持,中文字体为简体黑体ax = plt.figure().add_subplot() #建图,获取子图对象ax
'''
add_subplot方法的参数是一个三位数:
百位上的数代表画布上下分成几块
十位上的数代表画布左右分成几块
个位上的数代表该块副画布的编号
'''ax.bar(x = (0.2,0.6,0.8,1.2),height = (1,2,3,0.5), width = 0.1)
#x表示4个柱子中心横坐标分别是0.2,0.6,0.8,1.2
#height表示4个柱子高度分别是1,2,3,0.5
#width表示柱子宽度0.1'''
ax.bar(x, height, width, bottom, align)
该函数的参数说明,如下表所示:
x 一个标量序列,代表柱状图的x坐标,默认x取值是每个柱状图所在的中点位置,或者也可以是柱状图左侧边缘位置。
height 一个标量或者是标量序列,代表柱状图的高度。
width 可选参数,标量或类数组,柱状图的默认宽度值为 0.8。
bottom 可选参数,标量或类数组,柱状图的y坐标默认为None。
algin 有两个可选项 {“center”,“edge”},默认为 ‘center’,该参数决定 x 值位于柱状图的位置。
该函数的返回值是一个 Matplotlib 容器对象,该对象包含了所有柱状图。
'''
ax.set_title ('我的直方图') #设置标题
'''
ax.set_title:设置图片的标题;
set_title(self, label, fontdict=None, loc=’center’, pad=None, **kwargs)
参数说明:
fontdict: 一个字典,比如fontdict={‘size’:16}
loc: 位于中间还是两边,可以是center, left, rightax.set_xlabel:设置图片x轴的名称
ax.set_ylabel:设置图片y轴的名称
ax.set_xticks(x_ticks):设置图片x轴的刻度
ax.set_xticklabels(labels):设置图片x轴刻度上的标签
'''plt.show()
绘制横向直方图:
barh(y, width, height=0.8, left=None, *, align='center', **kwargs)
matplotlib.pyplot.barh()绘制的都是水平条形图
y,width,height与bar()里的x,height,width相反
left等同于bar()里的bottom 不同的时left作用于x轴,bottom作用于y轴
其他参数作用与bar()参数一致
# 绘制横向直方图import matplotlib.pyplot as plt #以后 plt 等价于 matplotlib.pyplot
from matplotlib import rcParams
'''
rcParams 是 Matplotlib 库中的一个字典对象,用于存储和管理全局的默认参数配置。
在 Matplotlib 中,可以通过修改 rcParams 中的参数值来改变图形的默认行为。这些参数包括
图形的颜色、线型、线宽、字体样式、图像分辨率等。
rcParams 的全称是“runtime configuration parameters”,它在运行时控制着 Matplotlib 的行为。
通过修改 rcParams 中的参数,您可以自定义 Matplotlib 的默认设置,使其符合您的需求,
而无需在每个图形绘制时都手动指定这些参数。
'''# rcParams['font.family'] = rcParams['font.sans-serif'] = 'SimHei'
#设置中文支持,中文字体为简体黑体ax = plt.figure().add_subplot() #建图,获取子图对象ax
'''
add_subplot方法的参数是一个三位数:
百位上的数代表画布上下分成几块
十位上的数代表画布左右分成几块
个位上的数代表该块副画布的编号
'''ax.barh(y = (0.2,0.6,0.8,1.2),width = (1,2,3,0.5), height = 0.1)
'''
barh(y, width, height=0.8, left=None, *, align='center', **kwargs)matplotlib.pyplot.barh()绘制的都是水平条形图y,width,height与bar()里的x,height,width相反left等同于bar()里的bottom 不同的时left作用于x轴,bottom作用于y轴其他参数作用与bar()参数一致
'''ax.set_title ('我的直方图') #设置标题
'''
ax.set_title:设置图片的标题;
set_title(self, label, fontdict=None, loc=’center’, pad=None, **kwargs)
参数说明:
fontdict: 一个字典,比如fontdict={‘size’:16}
loc: 位于中间还是两边,可以是center, left, rightax.set_xlabel:设置图片x轴的名称
ax.set_ylabel:设置图片y轴的名称
ax.set_xticks(x_ticks):设置图片x轴的刻度
ax.set_xticklabels(labels):设置图片x轴刻度上的标签
'''plt.show()
绘制堆叠直方图
# 绘制堆叠直方图import matplotlib.pyplot as plt
ax = plt.figure().add_subplot()
labels = ['Jan', 'Feb', 'Mar', 'Apr']
num1 = [20, 30, 15, 35] #Dept1的数据
num2 = [15, 30, 40, 20] #Dept2的数据
cordx = range(len(num1)) #x轴刻度位置
rects1 = ax.bar(x = cordx, height=num1, width=0.5, color='red',label="Dept1")
rects2 = ax.bar(x = cordx, height=num2, width=0.5, color='green',label="Dept2", bottom=num1)
# ax.bar(x, height, width, bottom, align)ax.set_ylim(0, 100) #y轴坐标范围
ax.set_ylabel("Profit") #y轴含义(标签)
ax.set_xticks(cordx) #设置x轴刻度位置,也就是在坐标轴下多出来的一竖
ax.set_xticklabels(labels) #设置x轴刻度下方文字
ax.set_xlabel("In year 2020") #x轴含义(标签)
ax.set_title("My Company") #设置图像名
'''
ax.set系列函数 的语法与 plt 等效
ax.set_ylabel() plt.ylabel()
ax.set_xlabel() plt.xlabel()
ax.set_xticks() plt.xticks()
'''ax.legend(loc = 2) #在右上角显示图例说明
'''
ax.legend()作用:在图上标明一个图例,用于说明每条曲线的文字显示
legend()有一个loc参数,用于控制图例的位置。 比如 plot.legend(loc=2) ,
这个位置就是4象项中的第二象项,也就是左上角。 loc可以为1,2,3,4 这四个数字。
'''plt.show()绘制对比直方图(有多组数据)
# 绘制对比直方图(有多组数据)import matplotlib.pyplot as plt
ax = plt.figure(figsize=(10,5)).add_subplot()#建图,获取子图对象ax
ax.set_ylim(0,400) #指定y轴坐标范围
ax.set_xlim(0,80) #指定x轴坐标范围#以下是3组直方图的数据
x1 = [7, 17, 27, 37, 47, 57] #第一组直方图每个柱子中心点的横坐标
x2 = [13, 23, 33, 43, 53, 63] #第二组直方图每个柱子中心点的横坐标
x3 = [10, 20, 30, 40, 50, 60]
y1 = [41, 39, 13, 69, 39, 14] #第一组直方图每个柱子的高度
y2 = [123, 15, 20, 105, 79, 37] #第二组直方图每个柱子的高度
y3 = [124, 91, 204, 264, 221, 175]rects1 = ax.bar(x1, y1, facecolor='red', width=3, label = 'Iphone')
rects2 = ax.bar(x2, y2, facecolor='green', width=3, label = 'Huawei')
rects3 = ax.bar(x3, y3, facecolor='blue', width=3, label = 'Xiaomi')ax.set_xticks(x3) #x轴在x3中的各坐标点下面加刻度
ax.set_xticklabels(('A1','A2','A3','A4','A5','A6')) #指定x轴上每一刻度下方的文字
ax.legend() #显示右上角三组图的说明def label(ax,rects): #在rects的每个柱子顶端标注数值for rect in rects:height = rect.get_height()ax.text(rect.get_x() + rect.get_width()/2, height+14, str(height),rotation=90) #文字旋转90度
# rect.get_x()获取rect这一条形左边的x坐标的值'''ax.text(x, y, s, fontdict=None, withdash=False, **kwargs):文本注释,只能填写文本 ;x,y:注释的坐标位置(标量)s:注释的内容(字符串) fontdict:重新设置注释内容的文本格式,包括字体颜色、背景大小和颜色、字体大小等(字典)withdash:创建一个替代注释内容“s”的对象,参照英文单词解释,这应该是一个破折号 ;rotation是kwargs中的一个参数rotation: [ angle in degrees| 'vertical'(垂直的) | 'horizontal(水平的)' ] '''label(ax,rects1)
label(ax,rects2)
label(ax,rects3)
plt.show()
绘制折线和散点图
# 绘制折线和散点图import math,random
import matplotlib.pyplot as pltrcParams['font.family'] = rcParams['font.sans-serif'] = 'SimHei'
#设置中文支持,中文字体为简体黑体0def drawPlot(ax):xs = [i / 100 for i in range(1500)] #1500个点的横坐标,间隔0.01ys = [10*math.sin(x) for x in xs]#对应曲线y=10*sin(x)上的1500个点的y坐标ax.plot(xs,ys,"red",label = "Beijing") #画曲线y=10*sin(x)ys = list(range(-18,18))random.shuffle(ys) #将ys打乱ax.scatter(range(16), ys[:16], c = "blue") #画散点ax.plot(range(16), ys[:16], "blue", label="Shanghai") #画折线ax.legend() #显示右上角的各条折线说明ax.set_xticks(range(16)) #x轴在坐标0,1...15处加刻度ax.set_xticklabels(range(16)) #指定x轴每个刻度下方显示的文字ax = plt.figure(figsize=(10, 4),dpi=100).add_subplot() #图像长宽和清晰度(dpi)
drawPlot(ax)
plt.show()饼状图
matplotlib.pyplot.pie(x, explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, shadow=False, labeldistance=1.1, startangle=0, radius=1, counterclock=True, wedgeprops=None, textprops=None, center=(0, 0), frame=False, rotatelabels=False, *, normalize=True, data=None)


参考文章:python绘制饼图的方法详解_python_脚本之家
# 绘制饼图import matplotlib.pyplot as plt
def drawPie(ax):lbs = ('A', 'B', 'C', 'D') #四个扇区的标签sectors = [16, 29.55, 44.45, 10] #四个扇区的份额(百分比)expl = [0, 0.1, 0, 0] #四个扇区的突出程度ax.pie(x=sectors, labels=lbs, explode=expl, autopct='%.2f', shadow=True, labeldistance=1.1,pctdistance = 0.6,startangle = 90)'''matplotlib.pyplot.pie(x, explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, shadow=False, labeldistance=1.1, startangle=0, radius=1, counterclock=True, wedgeprops=None, textprops=None, center=(0, 0), frame=False, rotatelabels=False, *, normalize=True, data=None)'''ax.set_title("pie sample") #饼图标题ax = plt.figure().add_subplot()
drawPie(ax)
plt.show()绘制雷达图(了解)
# 绘制雷达图import matplotlib.pyplot as plt
from matplotlib import rcParams #处理汉字用
def drawRadar(ax):pi = 3.1415926labels = ['EQ','IQ','人缘','魅力','财富','体力'] #6个属性的名称attrNum = len(labels) #attrNum是属性种类数,此处等于6data = [7,6,8,9,8,2] #六个属性的值angles = [2*pi*i/attrNum for i in range(attrNum)]#angles是以弧度为单位的6个属性对应的6条半径线的角度angles2 = [x * 180/pi for x in angles]#angles2是以角度为单位的6个属性对应的半径线的角度ax.set_ylim(0, 10) #限定半径线上的坐标范围ax.set_thetagrids(angles2,labels,fontproperties="SimHei" )#绘制6个属性对应的6条半径ax.fill(angles,data,facecolor= 'g',alpha=0.25) #填充,alpha:透明度'''matplotlib.pyplot.fill(*args, data=None, **kwargs)*args:这个参数主要填写有序数对和颜色。每个多边形可以使用x坐标和y坐标构造,只要把这些点连接一起,再把里面的空间进行指定的颜色填充。ax.fill(x, y) # 使用默认的颜色填充一个多边形ax.fill(x, y, “b”) # 使用蓝色填充一个多边形ax.fill(x, y, x2, y2) # 使用默认颜色填充两个多边形ax.fill(x, y, “b”, x2, y2, “r”) # 一个蓝色,一个红色'''rcParams['font.family'] = rcParams['font.sans-serif'] = 'SimHei'
#处理汉字
ax = plt.figure().add_subplot(projection = "polar") #生成极坐标形式子图
drawRadar(ax)
plt.show()
绘制多层雷达图(了解)
# 绘制多层雷达图import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.family'] = rcParams['font.sans-serif'] = 'SimHei'pi = 3.1415926
labels = ['EQ','IQ','人缘','魅力','财富','体力'] #6个属性的名称
attrNum = len(labels)
names = ('张三','李四','王五')
data = [[0.40,0.32,0.35], [0.85,0.35,0.30],
[0.40,0.32,0.35], [0.40,0.82,0.75],
[0.14,0.12,0.35], [0.80,0.92,0.35]] #三个人的数据angles = [2*pi*i/attrNum for i in range(attrNum)]
angles2 = [x * 180/pi for x in angles]ax = plt.figure().add_subplot(projection = "polar")
ax.fill(angles,data,alpha= 0.25)
ax.set_thetagrids(angles2,labels)
ax.set_title('三巨头人格分析',y = 1.05) #y指明标题垂直位置
ax.legend(names,loc=(0.95,0.9)) #画出右上角不同人的颜色说明
plt.show()
一个窗口绘制多幅图:
matplotlib.pyplot 模块提供了 subplot2grid(),该函数能够在画布的特定位置创建 axes 对象(即绘图区域)。不仅如此,它还可以使用不同数量的行、列来创建跨度不同的绘图区域。与subplot() 和 subplots() 函数不同,subplot2gird()函数以非等分的形式对画布进行切分,并按照绘图区域的大小来展示最终绘图结果。
plt.subplot2grid(shape, location, rowspan, colspan)参数含义如下:
- shape:把该参数值规定的网格区域作为绘图区域;
- location:在给定的位置绘制图形,初始位置 (0,0) 表示第1行第1列;
- rowsapan/colspan:这两个参数用来设置让子区跨越几行几列。
# 一个窗口绘制多幅图:
#程序中的import、汉字处理及drawRadar、drawPie、drawPlot函数略,见前面程序fig = plt.figure(figsize=(8,8))
ax = fig.add_subplot(2,2,1) #窗口分割成2*2,取位于第1个方格的子图
drawPie(ax)ax = fig.add_subplot(2,2,2,projection = "polar")
drawRadar(ax)ax = plt.subplot2grid((2, 2), (1, 0), colspan=2)
#或写成: ax = fig.add_subplot(2,1,2)'''
plt.subplot2grid(shape, location, rowspan, colspan)
参数含义如下:shape:把该参数值规定的网格区域作为绘图区域;location:在给定的位置绘制图形,初始位置 (0,0) 表示第1行第1列;rowsapan/colspan:这两个参数用来设置让子区跨越几行几列。
'''drawPlot(ax)plt.figtext(0.05,0.05,'subplot sample') #显示左下角的图像标题
plt.show()相关文章:
郭炜老师mooc第十一章数据分析和展示(numpy,pandas, matplotlib)
多维数组库numpy numpy创建数组的常用函数 # numpy数组import numpy as np #以后numpy简写为np print(np.array([1,2,3])) #>>[1 2 3] print(np.arange(1,9,2)) #>>[1 3 5 7] 不包括9 print(np.linspace(1,10,4)) #>>[ 1. 4. 7. 10.] # linespace(x,y,n)&…...
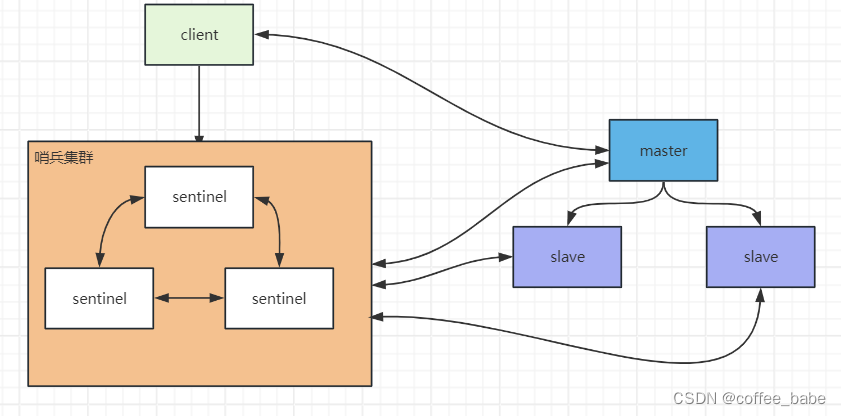
Redis主从架构和管道Lua(一)
Redis主从架构 架构 Redis主从工作原理 如果为master配置了一个slave,不管这个slave是否是第一次连接上Master,它都会发送一个PSYNC命令给master请求复制数据。master受到PSYNC命令,会在后台进行数据持久化通过bgsave生成最新的 RDB快照文件,持久化期间…...

GTH手册学习注解
CPLL的动态配置 终于看到有这个复位功能了 QPLL SWITCHing需要复位 器件级RESET没发现有管脚引出来 两种复位方式,对应全复位和器件级复位 对应的复位功能管脚 改那个2分频的寄存器说明段,复位是自动发生的?说明可能起效了,但是分…...

html5cssjs代码 002 50以内的加法算式
html5&css&js代码 002 一些基本概念 50以内的加法算式 一、代码二、解释 50以内的加法算式。 一、代码 <!DOCTYPE html> <html lang"en"> <head><title>50以内的加法算式</title><meta charset"UTF-8"><m…...
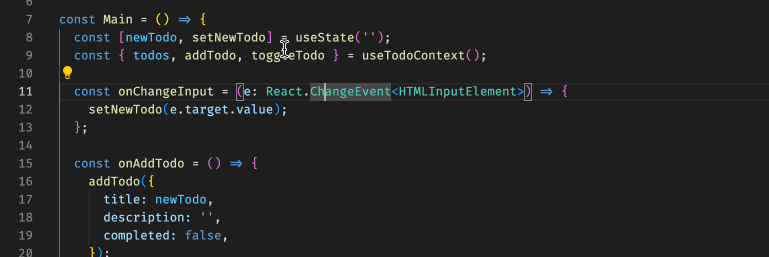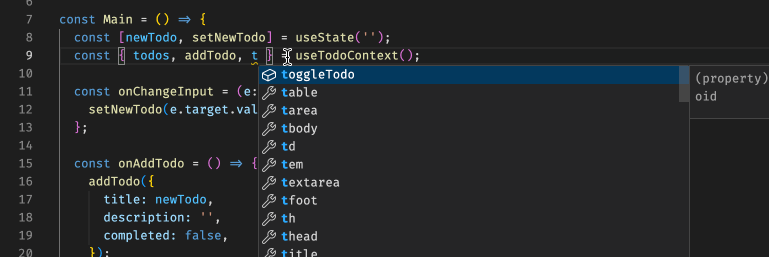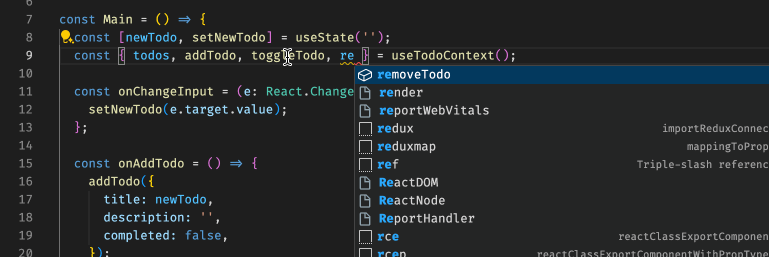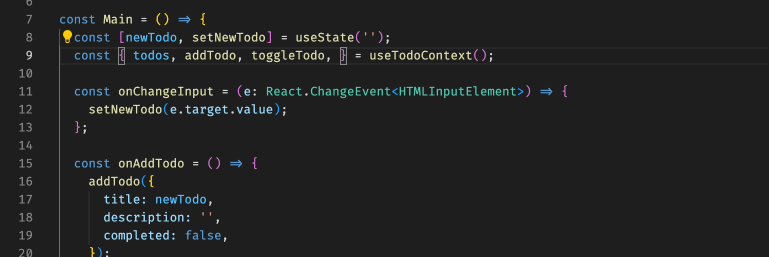
[React 进阶系列] React Context 案例学习:使用 TS 及 HOC 封装 Context
[React 进阶系列] React Context 案例学习:使用 TS 及 HOC 封装 Context 具体 context 的实现在这里:[React 进阶系列] React Context 案例学习:子组件内更新父组件的状态。 根据项目经验是这样的,自从换了 TS 之后,…...

网络编程:网络编程基础
一、网络发展 1.TCP/IP两个协议阶段 TCP/IP协议已分成了两个不同的协议: 用来检测网络传输中差错的传输控制协议TCP 专门负责对不同网络进行2互联的互联网协议IP 2.网络体系结构 OSI体系口诀:物链网输会示用 2.1网络体系结构概念 每一层都有自己独…...
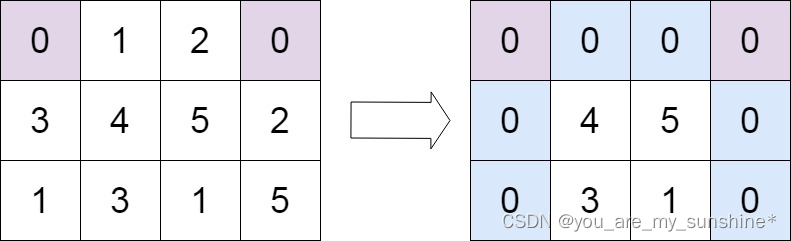
力扣热题100_矩阵_73_矩阵置零
文章目录 题目链接解题思路解题代码 题目链接 73.矩阵置零 给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。 示例 1: 输入:matrix [[1,1,1],[1,0,1],[1,1,1]] 输出&…...

C++程序设计-第四/五章 函数和类和对象【期末复习|考研复习】
前言 总结整理不易,希望大家点赞收藏。 给大家整理了一下C程序设计中的重点概念,以供大家期末复习和考研复习的时候使用。 C程序设计系列文章传送门: 第一章 面向对象基础 第四/五章 函数和类和对象 第六/七/八章 运算符重载/包含与继承/虚函…...
C#快速入门基础
本篇文章从最基础的C#编程开始学习,经过非常优秀的面向对象编程思想和方法的学习,为C#编程打下基础。 第 01 章 C#开发环境之VS使用和.NET平台基础 1.1 Visual Studio 开发环境 1.1.1 硬件环境 i5CPUi5CPU(建议 4核 4线程或以上 ࿰…...
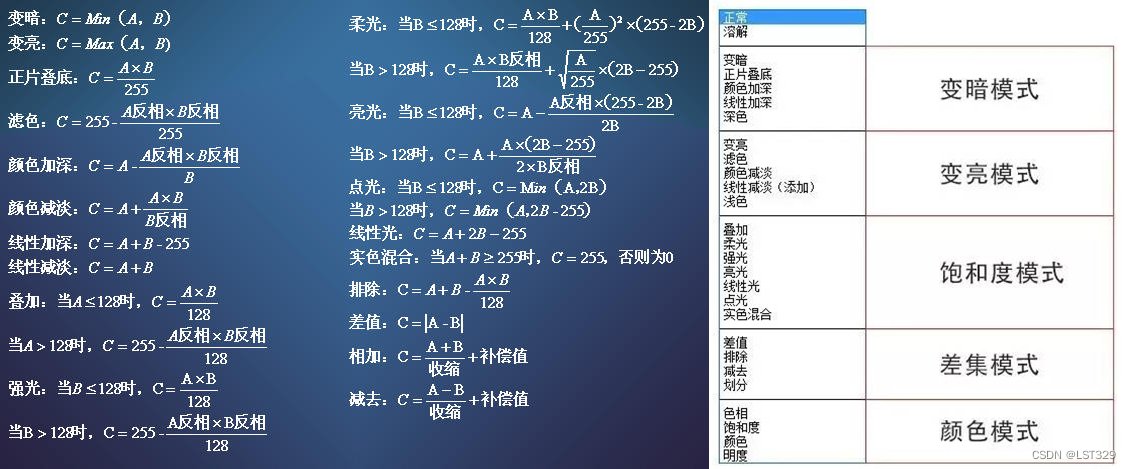
UnityShader常用算法笔记(颜色叠加混合、RGB-HSV-HSL的转换、重映射、UV序列帧动画采样等,持续更新中)
一.颜色叠加混合 1.Blend混合 // 正常,透明度混合 Normal Blend SrcAlpha OneMinusSrcAlpha //柔和叠加 Soft Additive Blend OneMinusDstColor One //正片叠底 相乘 Multiply Blend DstColor Zero //两倍叠加 相加 2x Multiply Blend DstColor SrcColor //变暗…...
Vue3调用钉钉api,内嵌H5微应用单点登录对接
钉钉内嵌H5微应用单点登录对接 https://open.dingtalk.com/document/isvapp/obtain-the-userid-of-a-user-by-using-the-log-free 前端需要的代码 1、安装 dingtalk-jsapi npm install dingtalk-jsapi2、在所需页面引入 import * as dd from dingtalk-jsapi; // 引入钉钉a…...
UE5 局域网联机,寻找会话失败。
目录 参考资料: 尝试解决办法 1.1在【项目名.Build.cs】脚本中添加该行,添加后关闭编辑器,重新生成解决方案。编辑 2.检查是否在同一个C类子网 参考资料: 1.Cant find session in LAN - Programming & Scripting / Mul…...
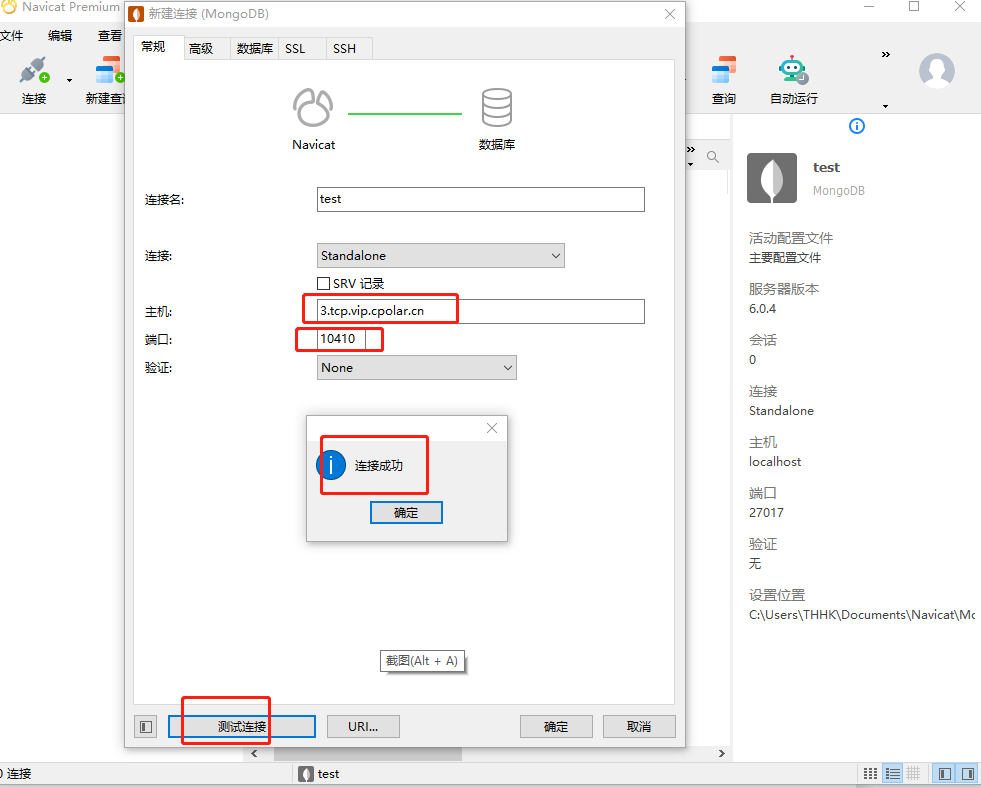
Windows系统安装MongoDB并结合内网穿透实现公网访问本地数据库
文章目录 前言1. 安装数据库2. 内网穿透2.1 安装cpolar内网穿透2.2 创建隧道映射2.3 测试随机公网地址远程连接 3. 配置固定TCP端口地址3.1 保留一个固定的公网TCP端口地址3.2 配置固定公网TCP端口地址3.3 测试固定地址公网远程访问 前言 MongoDB是一个基于分布式文件存储的数…...
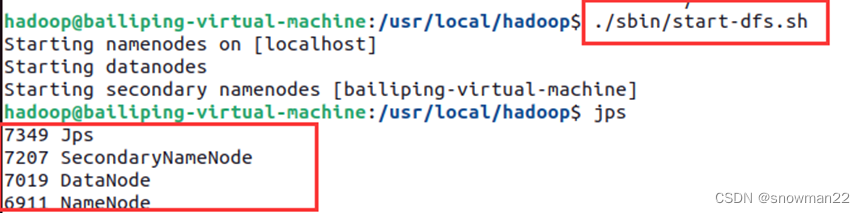
Hadoop伪分布式配置--没有DataNode或NameNode
一、原因分析 重复格式化NameNode 二、解决方法 1、输入格式化NameNode命令,找到data和name存放位置 ./bin/hdfs namenode -format 2、删除data或name(没有哪个删哪个) sudo rm -rf data 3、重新格式化NameNode 4、重新启动即可。...

柚见第十期(后端队伍接口详细设计)
创建队伍 用户可以 创建 一个队伍,设置队伍的人数、队伍名称(标题)、描述、超时时间 P0 队长、剩余的人数 聊天? 公开 或 private 或加密 信息流中不展示已过期的队伍 请求参数是否为空?是否登录,未登录不…...

【李沐论文精读】GPT、GPT-2和GPT-3论文精读
论文: GPT:Improving Language Understanding by Generative Pre-Training GTP-2:Language Models are Unsupervised Multitask Learners GPT-3:Language Models are Few-Shot Learners 参考:GPT、GPT-2、GPT-3论文精读…...
新版Android Studio火烈鸟 在新建项目工程时 无法选java的语言模板解决方法
前言 最近下载最新版androidstudio时 发现不能勾选java语言模板了 如果快速点击下一步 新建项目 默认是kotlin语言模板 这可能和google主推kt语言有关 勾选1 如图所示 如果勾选 No Activity 这个模板 是可以选java语言模板的 但是里面没有默认的Activity 勾选2 和以前的用法…...
操作记录(踩坑))
github(不是git啊)操作记录(踩坑)
专栏介绍与文章目录-CSDN博客 github是程序员绕不开的东西。 网站打不开? 向雇主或有关部门申请合法信道连接互联网。 明明账号密码都对却登录失败? 向雇主或有关部门申请合法信道连接互联网。 重置密码失败? 向雇主或有关部门申请合法信道…...
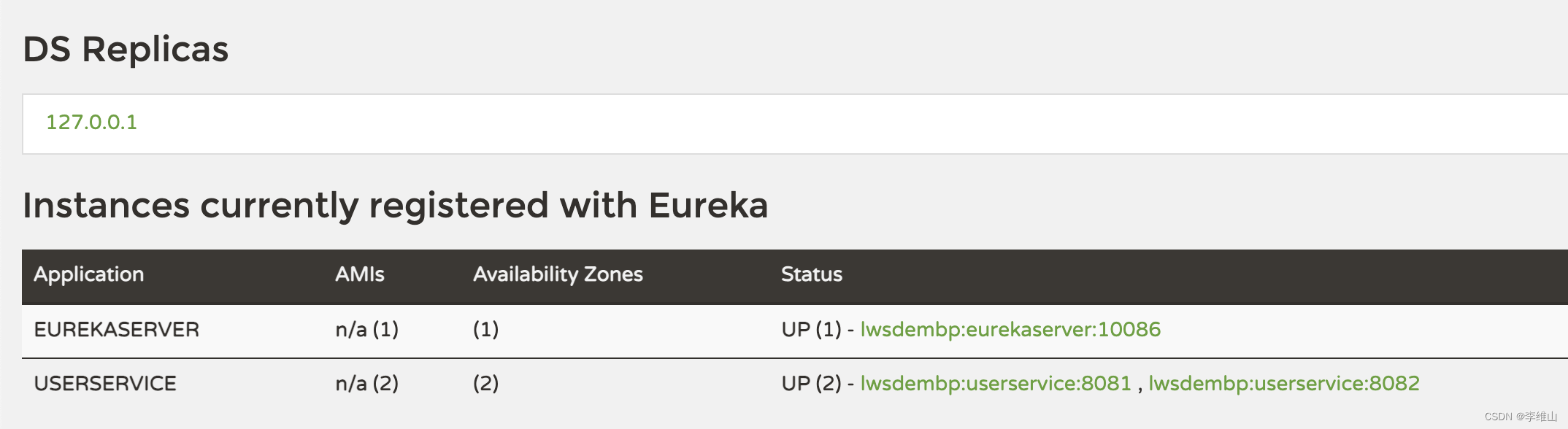
【SpringCloud微服务实战01】Eureka 注册中心
前言 在 Eureka 架构中,微服务角色有两类: EurekaServer :服务端,注册中心 记录服务信息 心跳监控 EurekaClient :客户端 Provider :服务提供者,例如案例中的 user-service …...

Python之函数进阶-柯里化
Python之函数进阶-柯里化 柯里化是一种将多参数函数转化为单参数高阶函数的技术。 具体来说,柯里化过程会将一个接受多个参数的函数,转换成一系列接受一个参数的函数,这些函数在内部组合起来,最终完成原函数的运算。 柯里化是一…...

Leetcode 剑指 Offer II 172. 统计目标成绩的出现次数
题目难度: 简单 原题链接 今天继续更新 Leetcode 的剑指 Offer(专项突击版)系列, 大家在公众号 算法精选 里回复 剑指offer2 就能看到该系列当前连载的所有文章了, 记得关注哦~ 题目描述 某班级考试成绩按非严格递增顺序记录于整数数组 scoresÿ…...

2026年AI写作辅助软件实测排行,哪款真正适合写论文?
2026 年学术 AI 论文工具已形成全流程、理工 / 社科、英文 / 中文、免费 / 付费的清晰分化。综合实测排行与场景适配,千笔AI 是中文全能首选,DeepSeek 学术版是理工开源首选,毕业之家是国内毕业专属首选。 一、2026 年实测排行 TOP5ÿ…...

哈夫曼树:高效压缩数据的秘密武器
引言在前面的树系列中,我们学习了二叉搜索树、AVL 树和红黑树——它们都是为了高效查找而设计的。今天要讲的哈夫曼树,目的完全不同:它是为了压缩数据而生。哈夫曼树(Huffman Tree),又称最优二叉树…...

掌握AI技能配置技巧 大幅提升日常办公开发效率
P.S. 目前国内还是很缺AI人才的,希望更多人能真正加入到AI行业,共同促进行业进步,增强我国的AI竞争力。想要系统学习AI知识的朋友可以看看我精心打磨的教程 http://blog.csdn.net/jiangjunshow,教程通俗易懂,高中生都能…...

为什么你的ChatGPT演讲稿总被说“像机器人”?深度拆解人类共情节奏建模与提示词嵌入技术
更多请点击: https://intelliparadigm.com 第一章:为什么你的ChatGPT演讲稿总被说“像机器人”? 当你精心调用 ChatGPT 生成一篇 800 字的 TED 风格演讲稿,满怀期待地朗读给同事听,却收到一句扎心反馈:“很…...

CleanMyWechat:一键解放你的PC微信存储空间
CleanMyWechat:一键解放你的PC微信存储空间 【免费下载链接】CleanMyWechat 自动删除 PC 端微信缓存数据,包括从所有聊天中自动下载的大量文件、视频、图片等数据内容,解放你的空间。 项目地址: https://gitcode.com/gh_mirrors/cl/CleanMy…...

智能体通信的序列化标准探索:JSON、ProtoBuf与自定义格式的效率之争
智能体通信的「快递员之战」:JSON、ProtoBuf与自定义格式的效率深度探索 关键词 智能体通信、序列化/反序列化、JSON、Protocol Buffers、自定义二进制格式、传输效率、编码效率、跨语言兼容 摘要 在人工智能多智能体系统(Multi-Agent System, MAS)、大语言模型(LLM)驱…...

如何快速掌握游戏MOD制作:LSLib开源工具箱的终极指南
如何快速掌握游戏MOD制作:LSLib开源工具箱的终极指南 【免费下载链接】lslib Tools for manipulating Divinity Original Sin and Baldurs Gate 3 files 项目地址: https://gitcode.com/gh_mirrors/ls/lslib 你是否曾经梦想过修改《神界原罪》或《博德之门3》…...

终极指南:如何将普通智能音箱改造成AI语音助手
终极指南:如何将普通智能音箱改造成AI语音助手 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 您是否想过,家中那台只会简…...

从‘拍脑袋’到‘有章法’:用Python实战Embedded与Wrapper方法,为你的模型精准选特征
从‘拍脑袋’到‘有章法’:Python实战Embedded与Wrapper方法的高阶特征选择指南在金融风控和医疗诊断这类对模型精度要求严苛的领域,数据科学家们常常面临这样的困境:当特征数量膨胀到数百甚至上千维时,盲目依赖过滤法选特征就像在…...