k8s学习之路 | Day20 k8s 工作负载 Deployment(下)
文章目录
- 3. HPA 动态扩缩容
- 3.1 HPA
- 3.2 安装 metrics-server
- 3.3 验证指标收集
- 3.4 扩缩容的实现
- 3.5 增加负载
- 3.6 降低负载
- 3.7 更多的度量指标
- 4. 金丝雀部署
- 4.1 蓝绿部署
- 4.2 金丝雀部署
- 4.3 金丝雀部署的实现
- 5. Deployment 状态与排查
- 5.1 进行中的 Deployment
- 5.2 完成的 Deployment
- 5.3 失败的 Deployment
- 5.4 对失败 Deployment 的操作
3. HPA 动态扩缩容
3.1 HPA
Horizontal Pod Autoscaler 可以根据 CPU 利用率自动扩缩 ReplicationController、 Deployment、ReplicaSet 或 StatefulSet 中的 Pod 数量
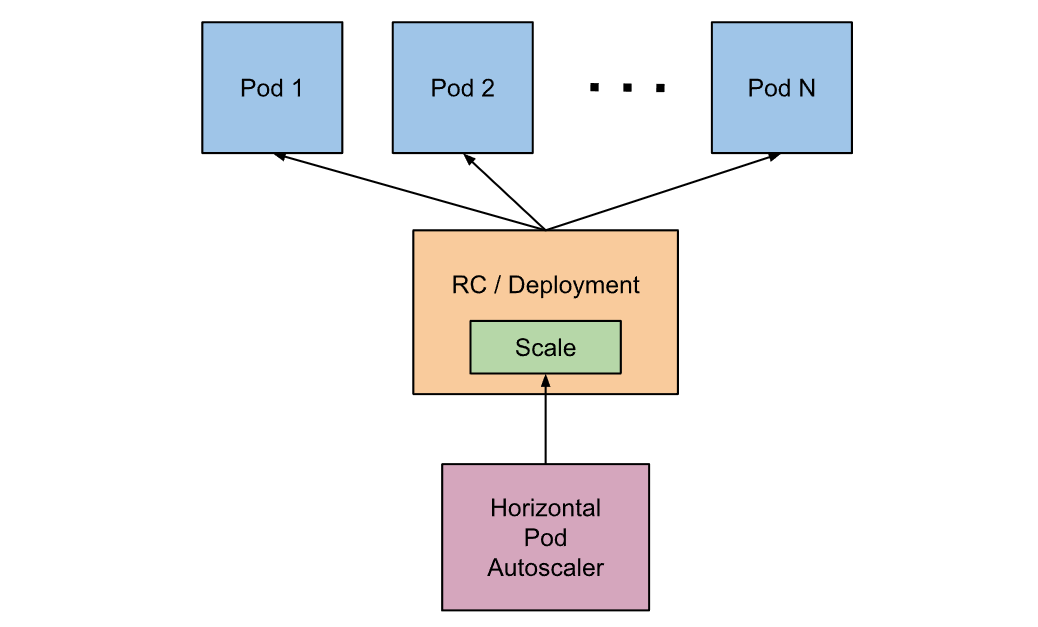
HorizontalPodAutoscaler(简称 HPA ) 自动更新工作负载资源(例如 Deployment 或者 StatefulSet), 目的是自动扩缩工作负载以满足需求。
水平扩缩意味着对增加的负载的响应是部署更多的 Pod。 这与 “垂直(Vertical)” 扩缩不同,对于 Kubernetes, 垂直扩缩意味着将更多资源(例如:内存或 CPU)分配给已经为工作负载运行的 Pod。
如果负载减少,并且 Pod 的数量高于配置的最小值, HorizontalPodAutoscaler 会指示工作负载资源(Deployment、StatefulSet 或其他类似资源)缩减。
3.2 安装 metrics-server
有关 metrics-server 地址:https://github.com/kubernetes-sigs/metrics-server#readme
Metrics Server是 k8s 内置自动缩放管道的可扩展、高效的容器资源度量源。
Metrics Server 从 Kubelets 收集资源度量,并通过Metrics API在Kubernetes apiserver中公开这些度量,供Horizontal Pod Autoscaler和Vertical Pod Autocaler使用。kubectl top还可以访问Metrics API,从而更容易调试自动缩放管道。
准备 yaml 文件
##### metrics-server.yaml
apiVersion: v1
kind: ServiceAccount
metadata:labels:k8s-app: metrics-servername: metrics-servernamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:labels:k8s-app: metrics-serverrbac.authorization.k8s.io/aggregate-to-admin: "true"rbac.authorization.k8s.io/aggregate-to-edit: "true"rbac.authorization.k8s.io/aggregate-to-view: "true"name: system:aggregated-metrics-reader
rules:
- apiGroups:- metrics.k8s.ioresources:- pods- nodesverbs:- get- list- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:labels:k8s-app: metrics-servername: system:metrics-server
rules:
- apiGroups:- ""resources:- pods- nodes- nodes/stats- namespaces- configmapsverbs:- get- list- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:labels:k8s-app: metrics-servername: metrics-server-auth-readernamespace: kube-system
roleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccountname: metrics-servernamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:labels:k8s-app: metrics-servername: metrics-server:system:auth-delegator
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: system:auth-delegator
subjects:
- kind: ServiceAccountname: metrics-servernamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:labels:k8s-app: metrics-servername: system:metrics-server
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: system:metrics-server
subjects:
- kind: ServiceAccountname: metrics-servernamespace: kube-system
---
apiVersion: v1
kind: Service
metadata:labels:k8s-app: metrics-servername: metrics-servernamespace: kube-system
spec:ports:- name: httpsport: 443protocol: TCPtargetPort: httpsselector:k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:labels:k8s-app: metrics-servername: metrics-servernamespace: kube-system
spec:selector:matchLabels:k8s-app: metrics-serverstrategy:rollingUpdate:maxUnavailable: 0template:metadata:labels:k8s-app: metrics-serverspec:containers:- args:- --cert-dir=/tmp- --kubelet-insecure-tls- --secure-port=4443- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname- --kubelet-use-node-status-portimage: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/metrics-server:v0.4.3imagePullPolicy: IfNotPresentlivenessProbe:failureThreshold: 3httpGet:path: /livezport: httpsscheme: HTTPSperiodSeconds: 10name: metrics-serverports:- containerPort: 4443name: httpsprotocol: TCPreadinessProbe:failureThreshold: 3httpGet:path: /readyzport: httpsscheme: HTTPSperiodSeconds: 10securityContext:readOnlyRootFilesystem: truerunAsNonRoot: truerunAsUser: 1000volumeMounts:- mountPath: /tmpname: tmp-dirnodeSelector:kubernetes.io/os: linuxpriorityClassName: system-cluster-criticalserviceAccountName: metrics-servervolumes:- emptyDir: {}name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:labels:k8s-app: metrics-servername: v1beta1.metrics.k8s.io
spec:group: metrics.k8s.iogroupPriorityMinimum: 100insecureSkipTLSVerify: trueservice:name: metrics-servernamespace: kube-systemversion: v1beta1versionPriority: 100
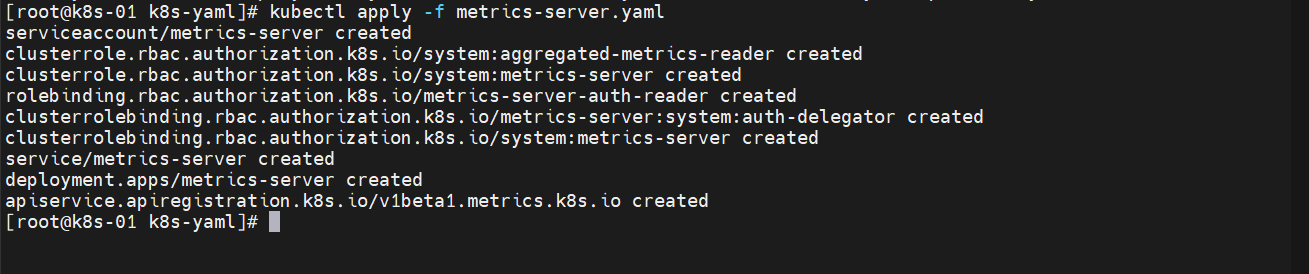
查看一下状态
kubectl get pod -n kube-system
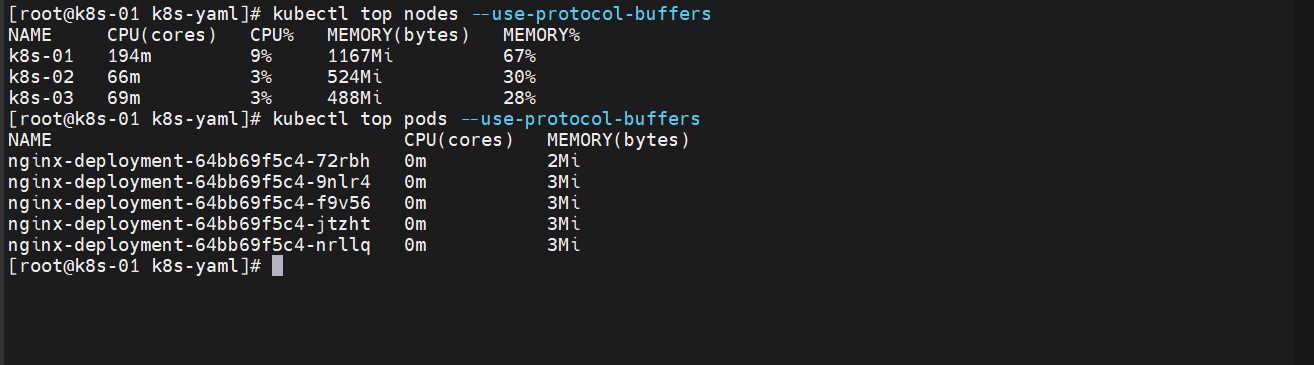
查看一下指标
##节点使用情况
kubectl top nodes --use-protocol-buffers##pod使用情况
kubectl top pods --use-protocol-buffers
3.3 验证指标收集
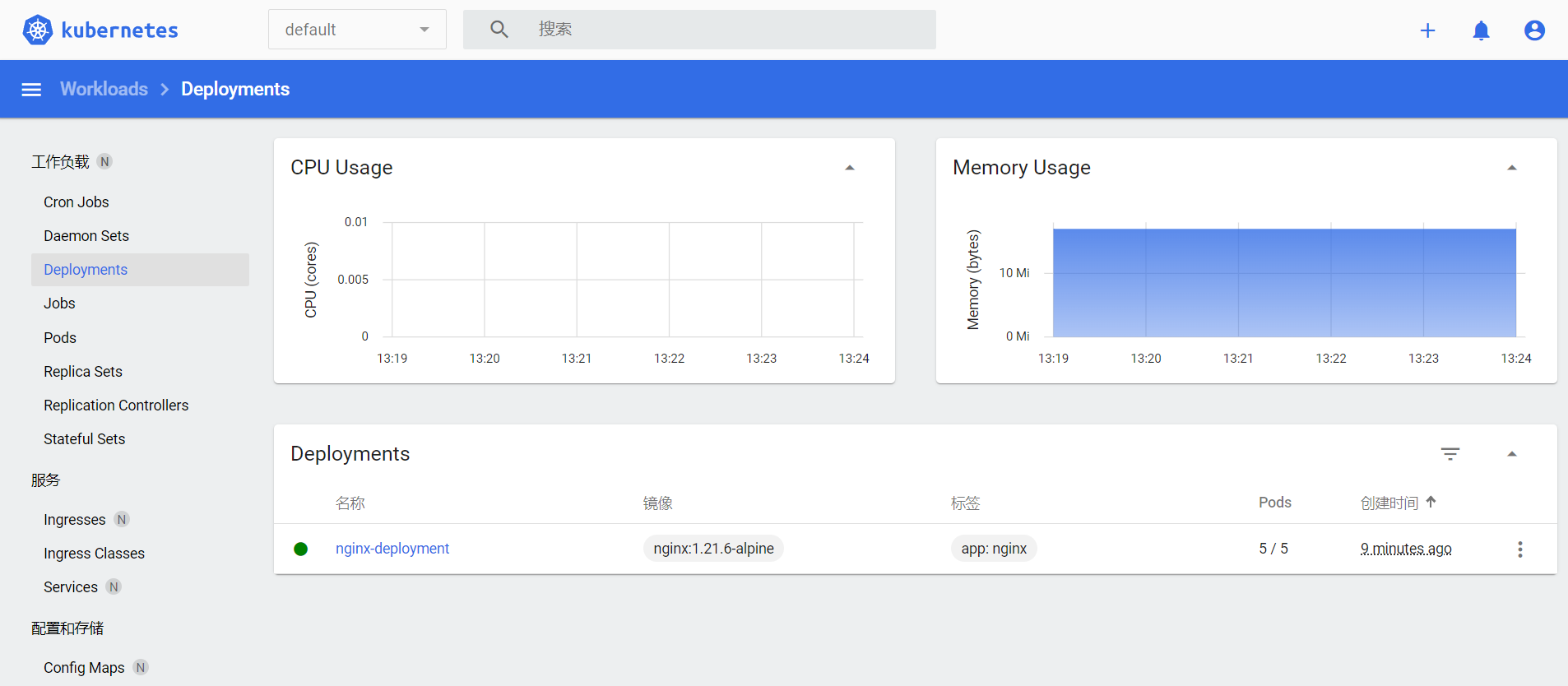
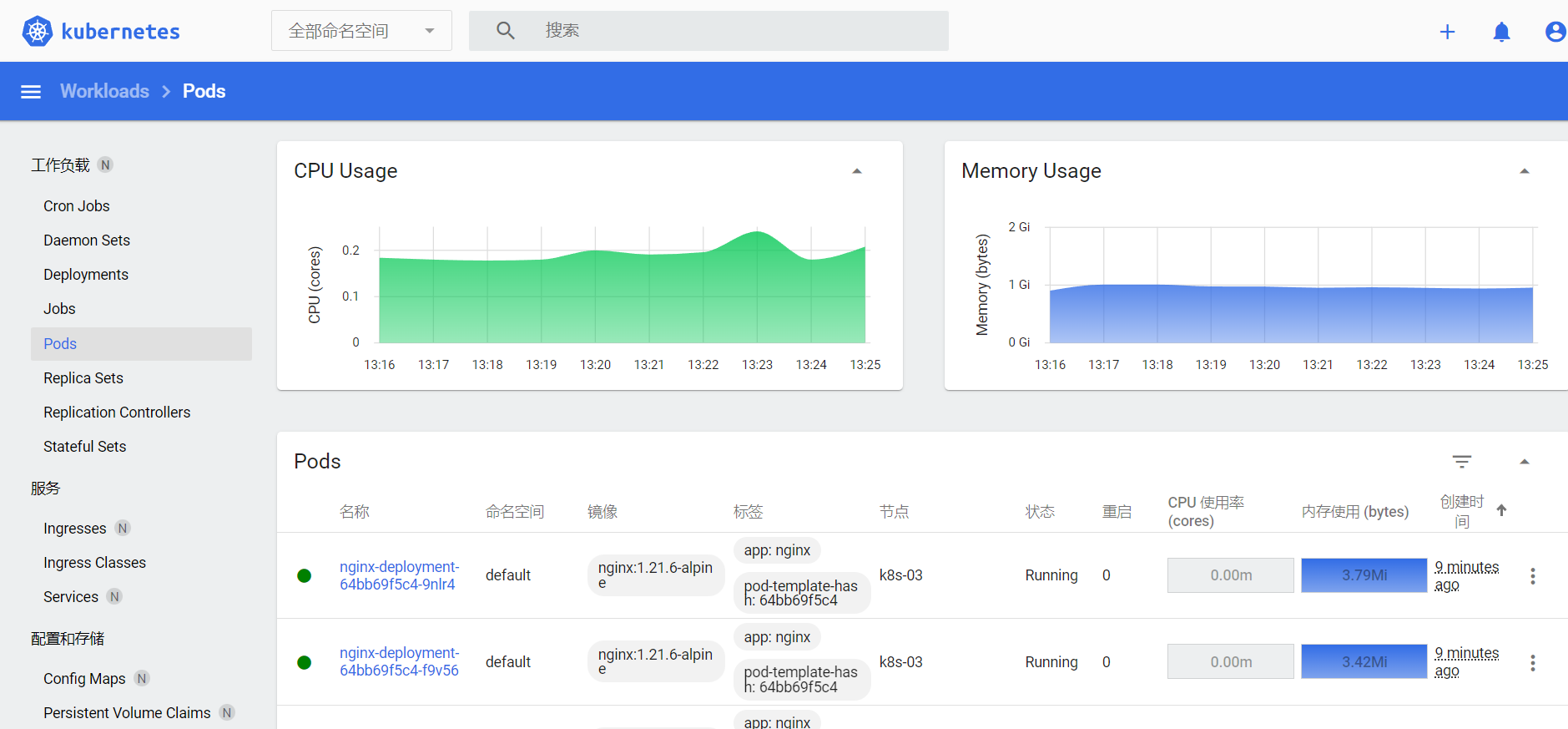
我们可以登陆 Dashboard 上去查看信息收集
3.4 扩缩容的实现
HPA 也是 k8s 中的一种资源,就是写这个资源的 yaml 文件来实现的

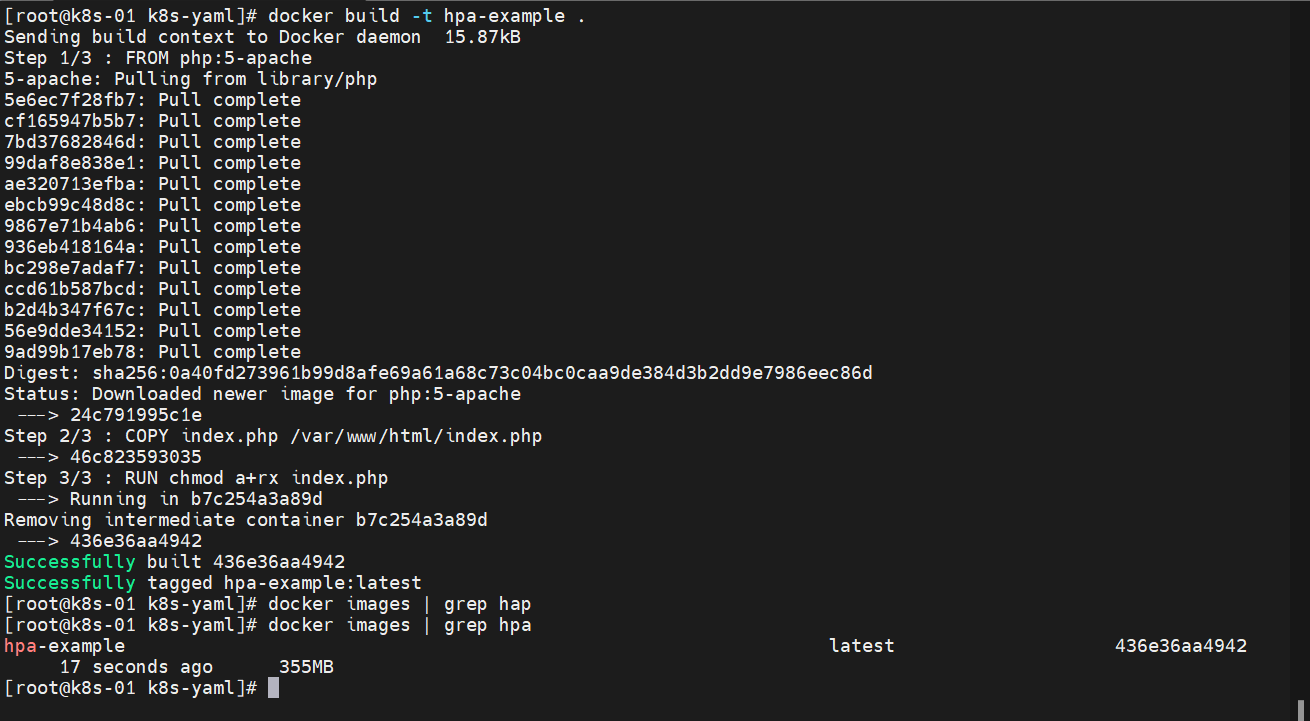
准备一个镜像
来自1.21版本的k8s 官方文档
FROM php:5-apache
COPY index.php /var/www/html/index.php
RUN chmod a+rx index.php
index.php 文件内容
<?php$x = 0.0001;for ($i = 0; $i <= 1000000; $i++) {$x += sqrt($x);}echo "OK!";
?>
构建一下这个镜像:docker build -t hpa-example .
准备 Deployment
###hpa-example.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: php-apache
spec:selector:matchLabels:run: php-apachereplicas: 1template:metadata:labels:run: php-apachespec:containers:- name: php-apacheimagePullPolicy: Neverimage: hpa-exampleports:- containerPort: 80resources:limits:cpu: 500mrequests:cpu: 200m
---
apiVersion: v1
kind: Service
metadata:name: php-apachelabels:run: php-apache
spec:ports:- port: 80selector:run: php-apache
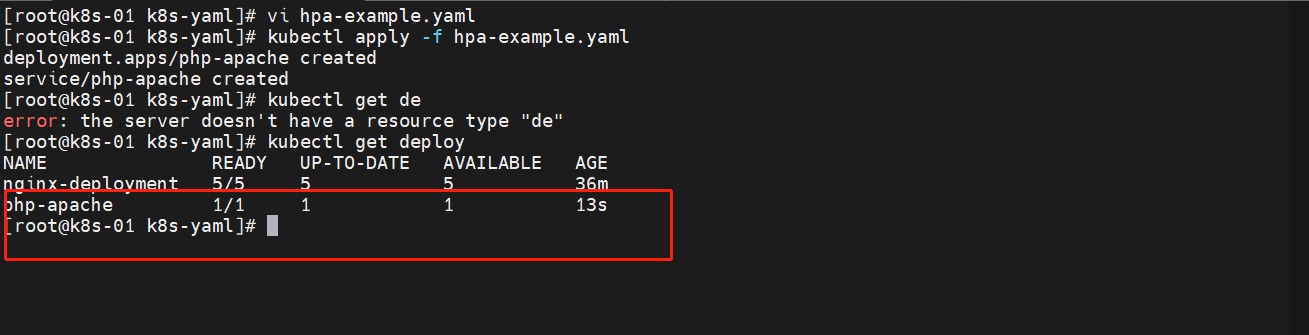
启动一下
编写 HPA
怎么写这个东西呢?直接描述就行了 kubectl explain hpa
如果不是整合第三方的话,这个资源能写的信息很少
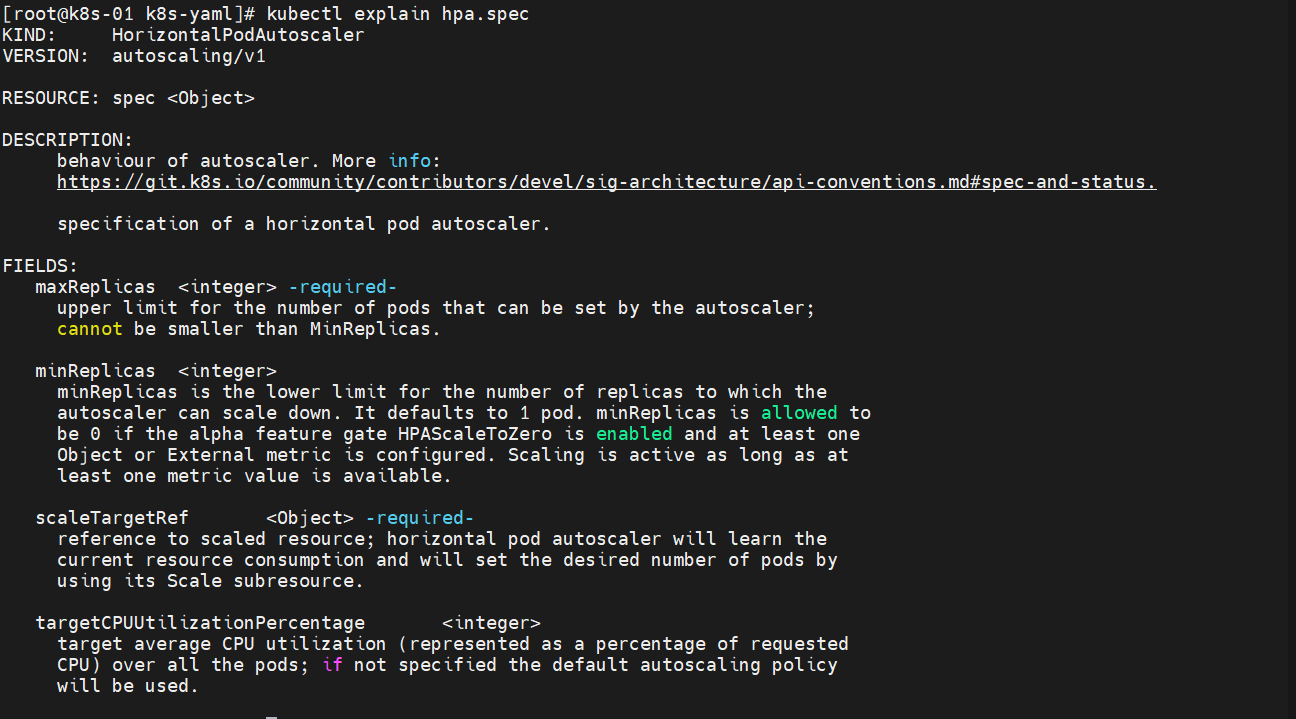
FIELDS:maxReplicas <integer> -required- ## 自动缩放器可设置的数量上限,不能小于Minupper limit for the number of pods that can be set by the autoscaler;cannot be smaller than MinReplicas.minReplicas <integer>minReplicas is the lower limit for the number of replicas to which theautoscaler can scale down. It defaults to 1 pod. minReplicas is allowed tobe 0 if the alpha feature gate HPAScaleToZero is enabled and at least oneObject or External metric is configured. Scaling is active as long as atleast one metric value is available.scaleTargetRef <Object> -required- ##缩放资源类型reference to scaled resource; horizontal pod autoscaler will learn thecurrent resource consumption and will set the desired number of pods byusing its Scale subresource.targetCPUUtilizationPercentage <integer> ##目标平均CPU利用率target average CPU utilization (represented as a percentage of requestedCPU) over all the pods; if not specified the default autoscaling policywill be used.apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata: ##元数据name: php-apache
spec:maxReplicas: 10 ##最大10个minReplicas: 1 ##最小1个scaleTargetRef:apiVersion: apps/v1kind: Deployment ##资源类型,将于动态扩缩容的目标引用name: php-apachetargetCPUUtilizationPercentage: 50 ## 目标CPU使用率就扩容,低于就缩容
创建一下 HPA
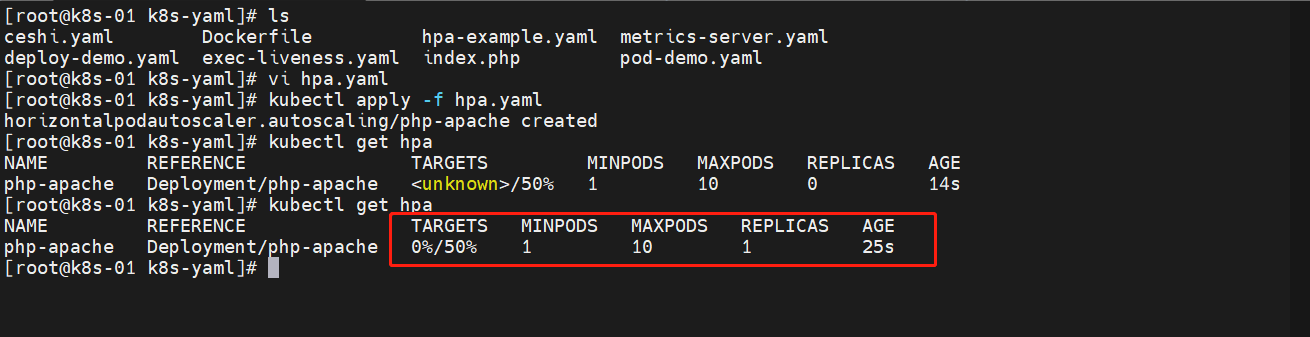
3.5 增加负载
动态监控一下
kubectl get hpa -w
kubectl get pod -l run=php-apache -w
增加负载
##一直访问
while true;do curl 10.96.169.3;done
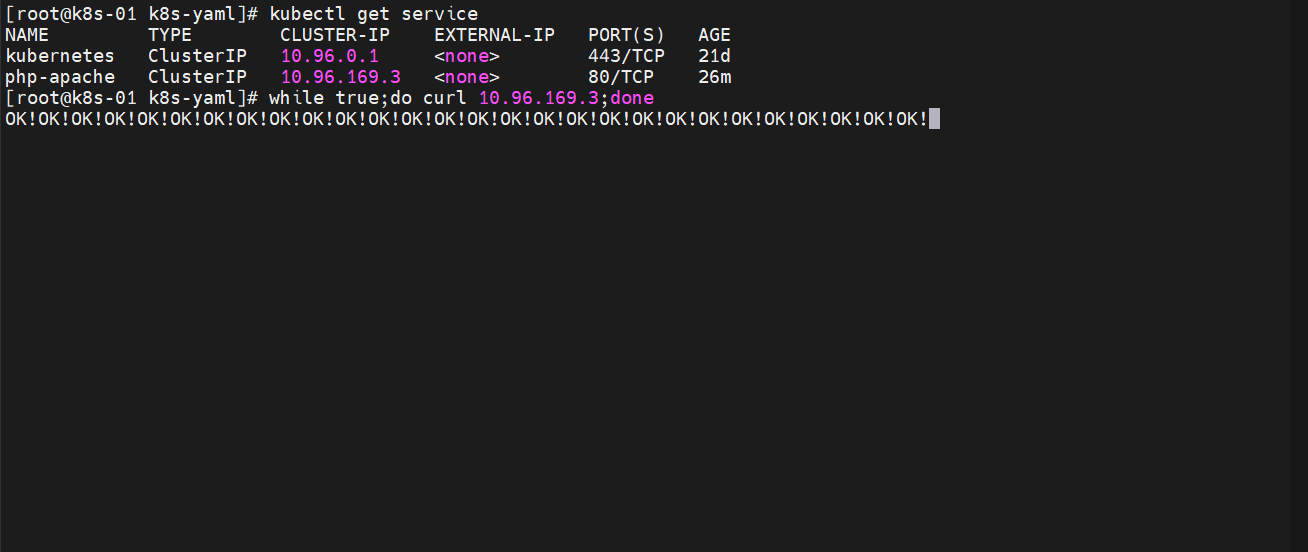
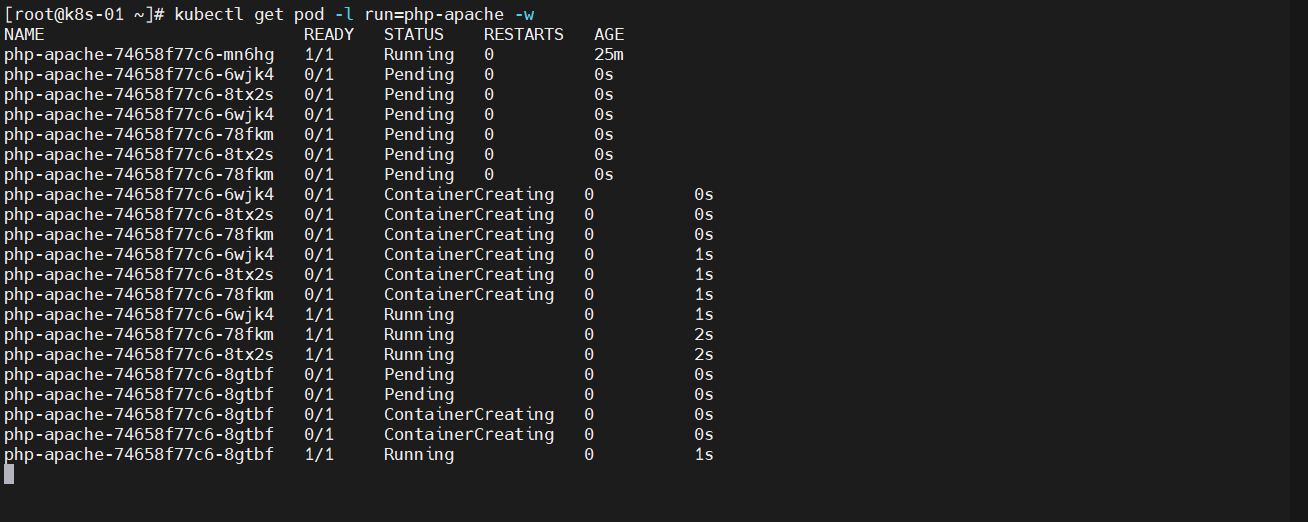
动态观察结果
运行一段发现负载升高,实现了自动扩容


3.6 降低负载
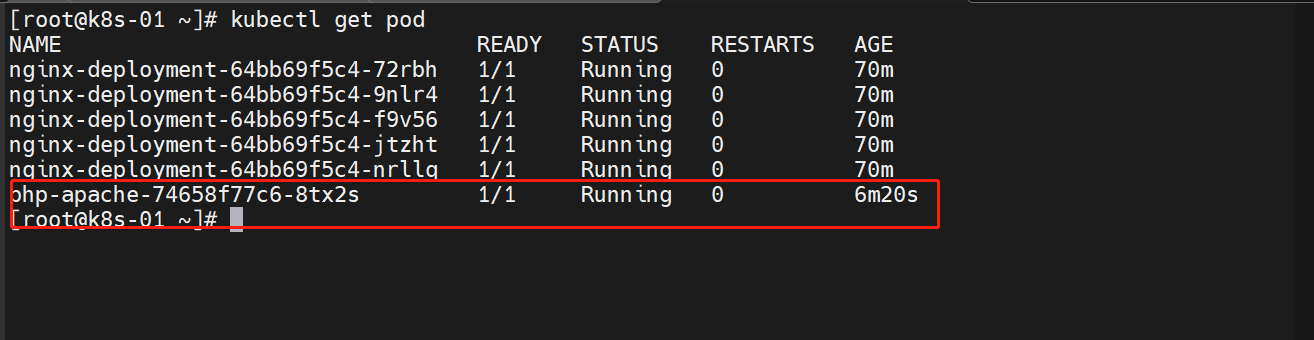
Ctrl + C 取消循环后,资源利用率会降下去,但是会有一个缓冲时间才会进行缩容
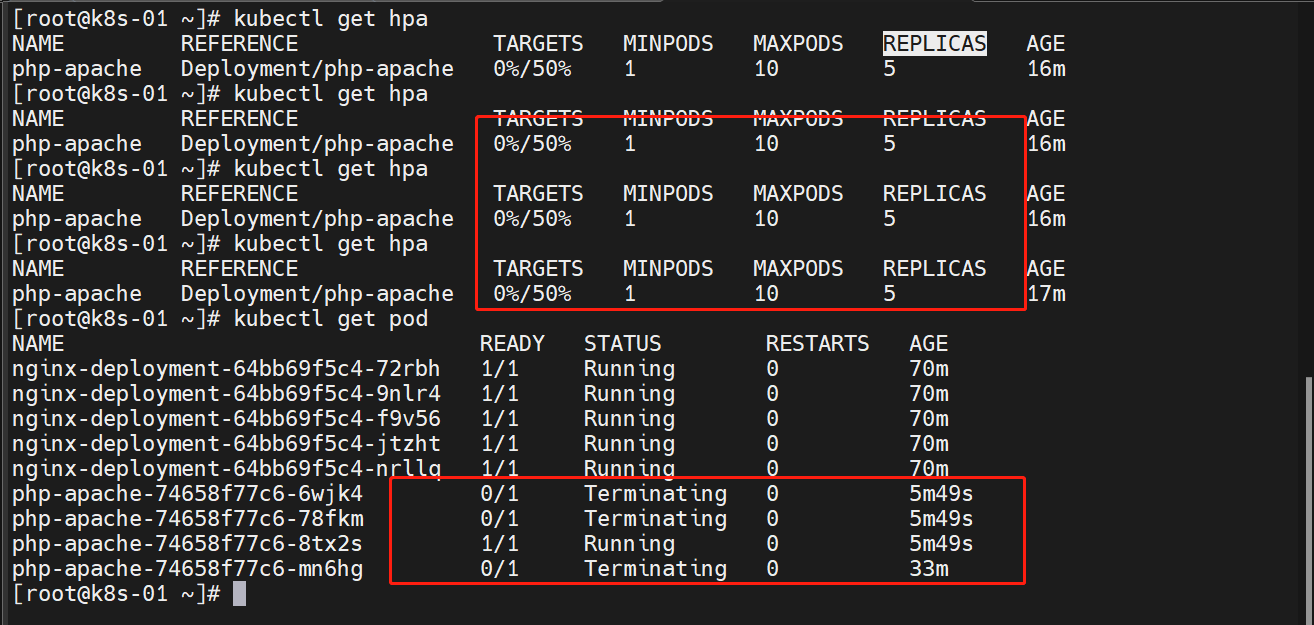
等一段时间后(好像是5分钟),最终会缩容到一个
3.7 更多的度量指标
有很多度量指标,参考最新版本的地址:https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/#autoscaling-on-multiple-metrics-and-custom-metrics
基于多项度量指标和自定义度量指标自动扩缩
4. 金丝雀部署
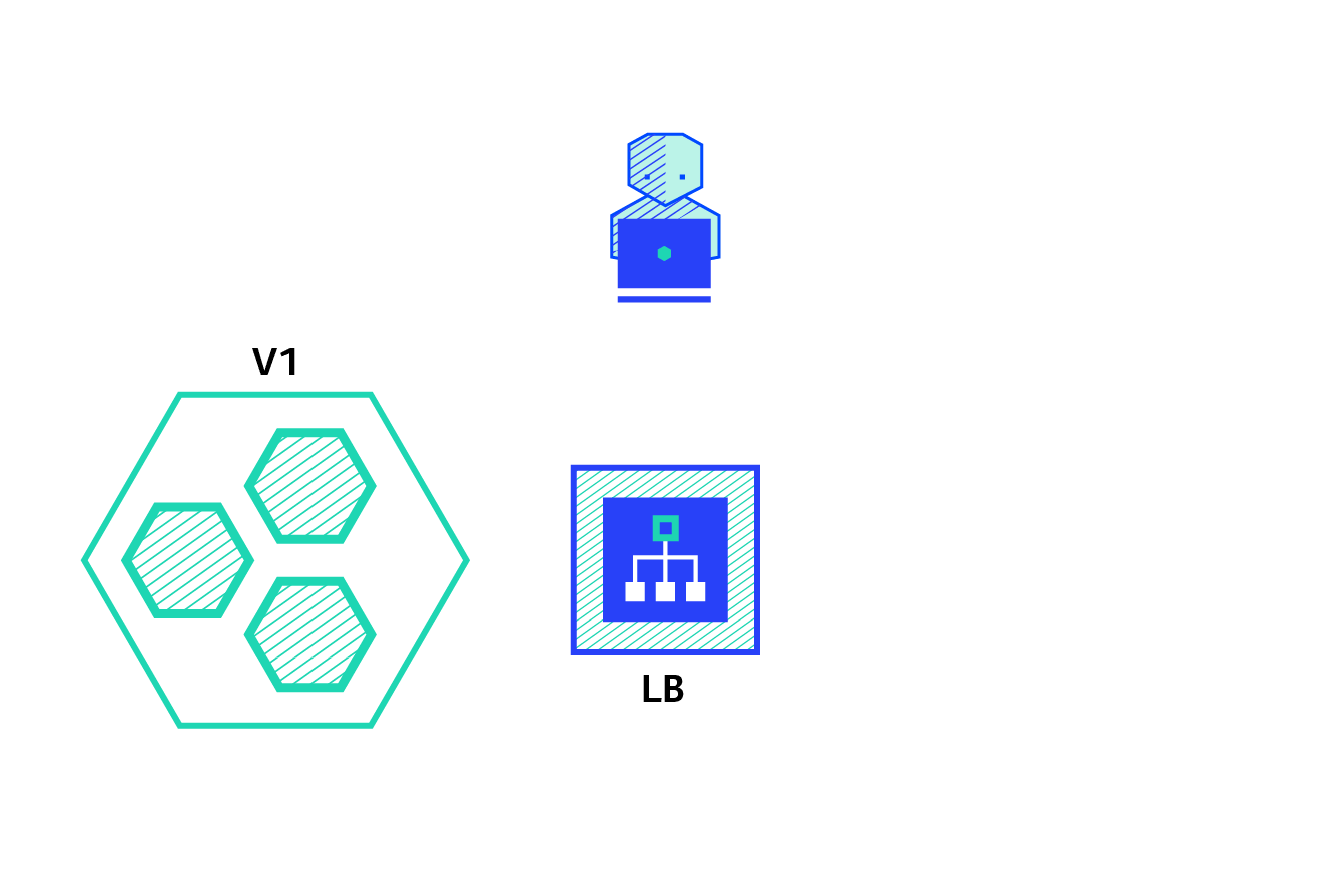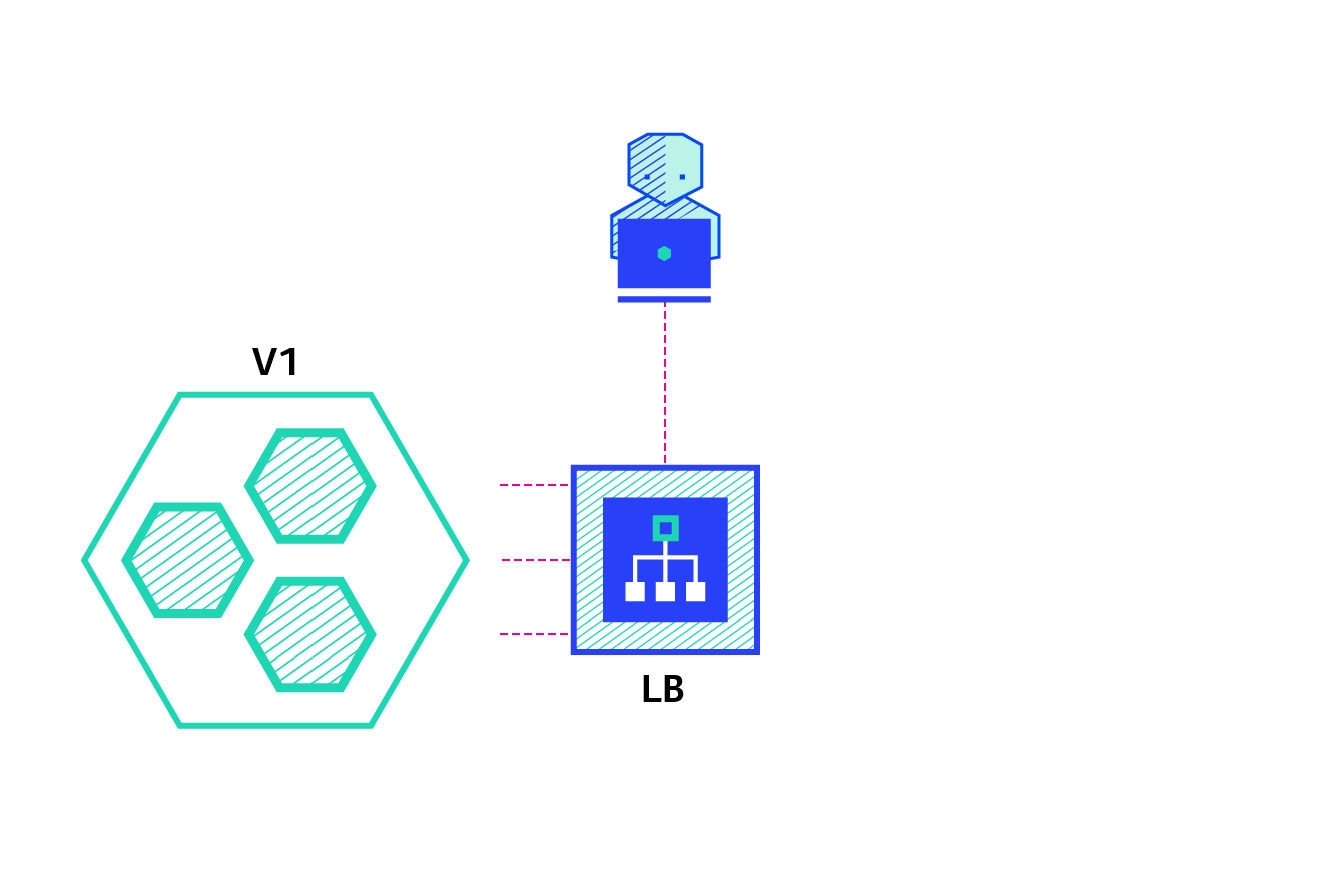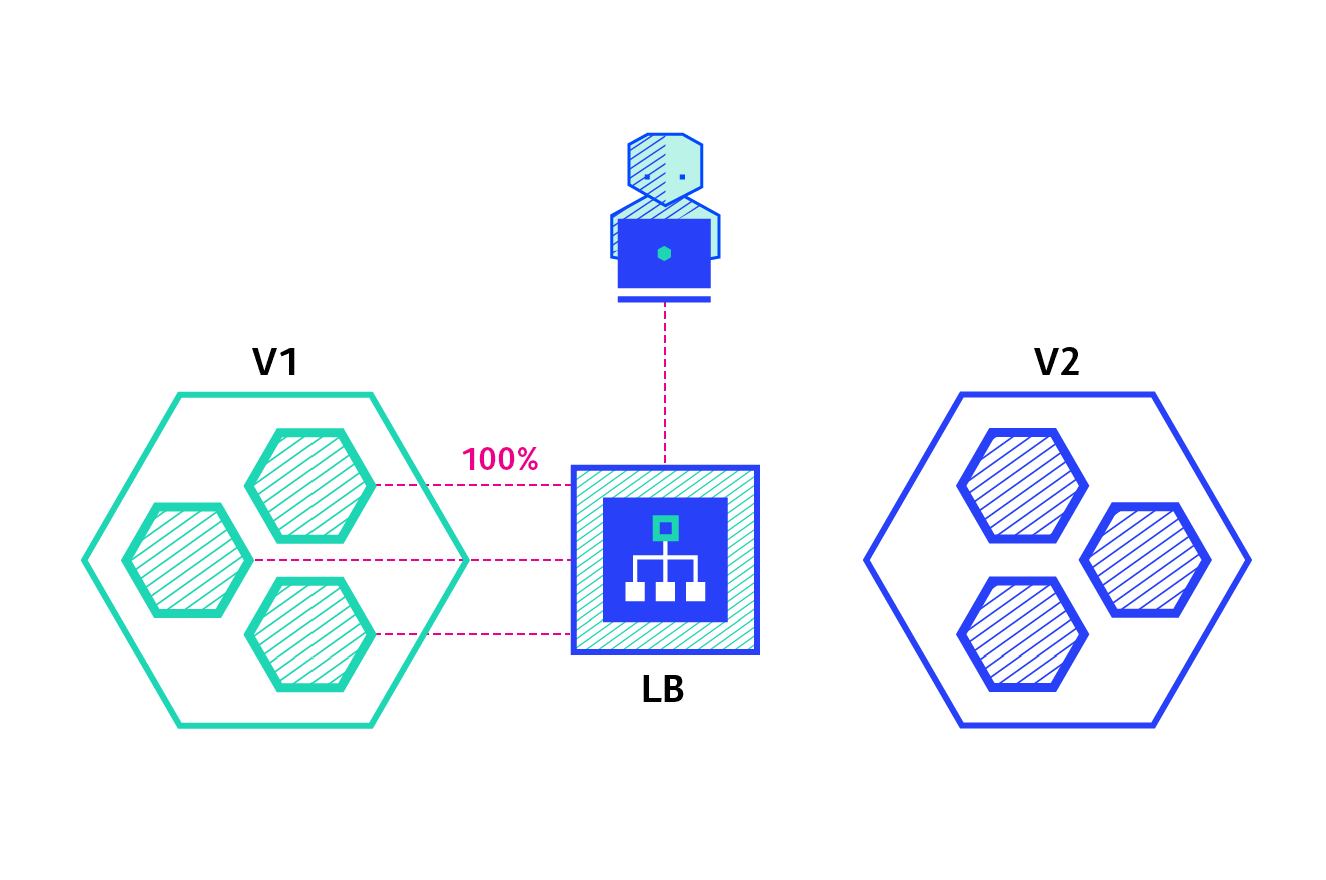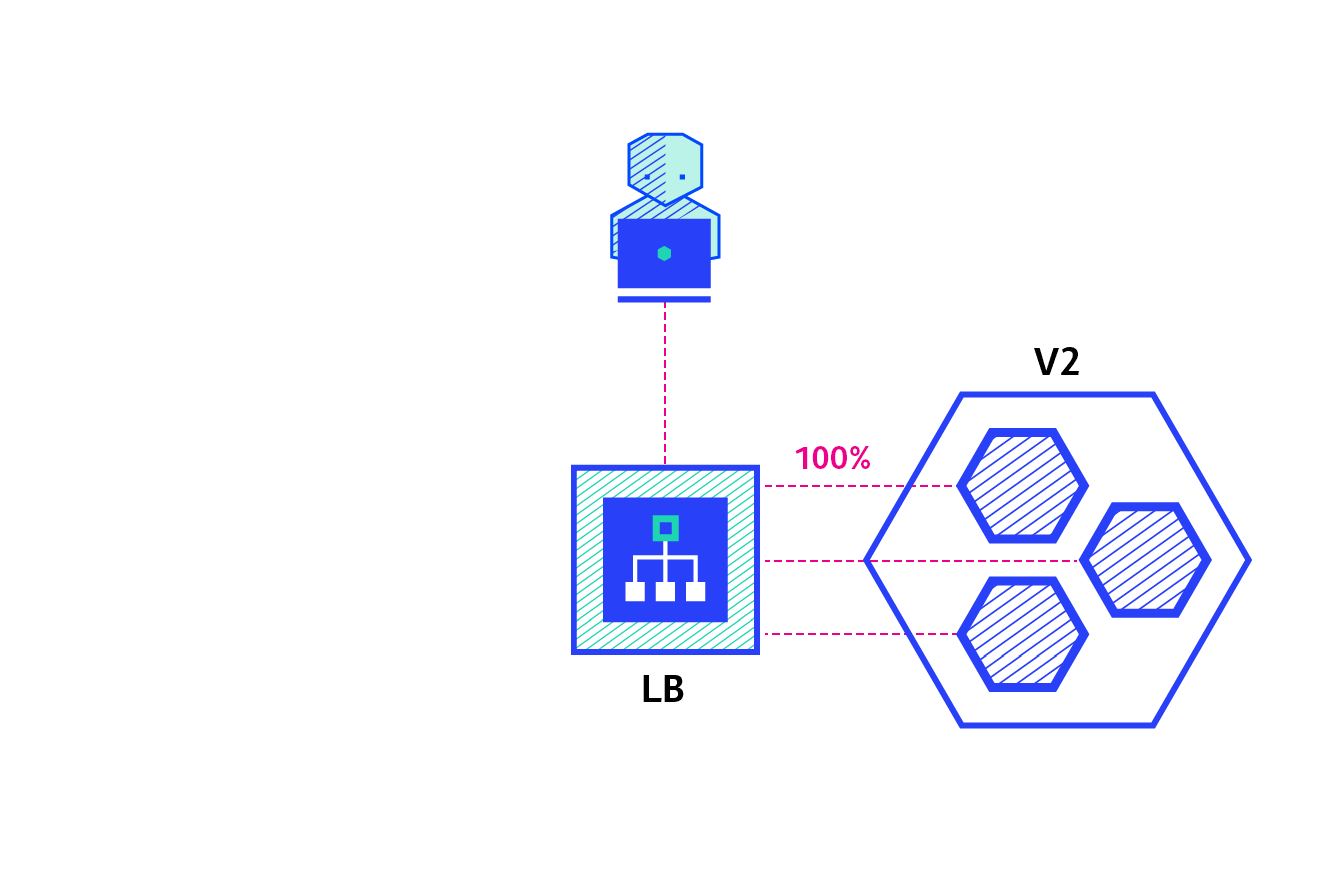
4.1 蓝绿部署
- 系统存在两个版本:V1 和 V2(绿和蓝)
- 将一些流量请求发往蓝色的版本的,如果发现是对的,就将系统切换到蓝版本
4.2 金丝雀部署
金丝雀部署来源于矿场的一个场景:矿工进矿洞之前会放入金丝雀,金丝雀对瓦斯气体很敏感,如果放进去了没有叽叽喳喳声音,矿工就不会进去了
- 现在有2个版本:V1 和 V2
- 先部署一个 V2 版本,请求流量会走向 V1和 V2
- 再逐渐增加 V2 数量,将全部流量走向 V2,销毁 V1
与滚动发布相比
滚动发布:
- 也都是同时存在2个版本,都能接受流量
- 滚动发布短时间就直接结束了,不能直接控制新老版本的存活时间
4.3 金丝雀部署的实现
首先准备一个 service
- 选择“app: canary-nginx”标签进行一个对外负载访问
##canary-test.yaml
apiVersion: v1
kind: Service
metadata:name: canary-testnamespace: default
spec:selector:app: canary-nginxtype: NodePort ## 浏览器可以直接访问ports:- name: canary-testport: 80 ### targetPort: 80 ## Pod的访问端口protocol: TCPnodePort: 31666 ## 浏览器访问端口
准备三个版本镜像
##v1版本:nginx-demo1
FROM nginx
ENV version="v1"
RUN echo $version > /usr/share/nginx/html/index.html##v2版本:nginx-demo2
FROM nginx
ENV version="v2"
RUN echo $version > /usr/share/nginx/html/index.html##v3版本:nginx-demo3
FROM nginx
ENV version="v3"
RUN echo $version > /usr/share/nginx/html/index.html
构建镜像
docker build -t nginx:demo1 .
准备一个 v1 版本的 Deployment
###canary-deploy-demo1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: canary-dep-v1namespace: defaultlabels:app: canary-dep-v1
spec:selector:matchLabels:app: canary-nginxversion: v1replicas: 1template:metadata:labels:app: canary-nginxversion: v1spec:containers:- name: nginximage: nginx:demo1imagePullPolicy: Never
创建一次 Deployment
kubectl apply -f canary-deploy-demo1.yaml
访问检查

再启动一个v2版本
###canary-deploy-demo2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: canary-dep-v2namespace: defaultlabels:app: canary-dep-v2
spec:selector:matchLabels:app: canary-nginxversion: v2replicas: 1template:metadata:labels:app: canary-nginxversion: v2spec:containers:- name: nginximage: nginx:demo2imagePullPolicy: Never
访问一下
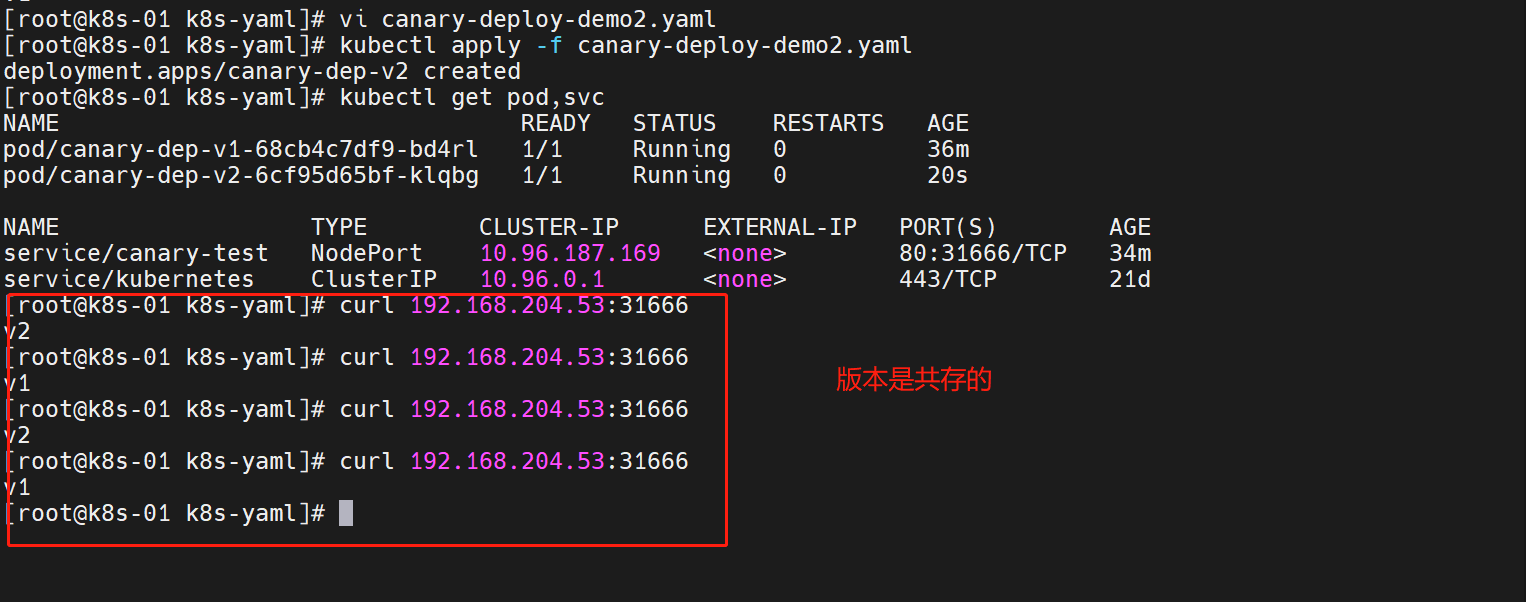
v2版本没问题,我们进行一个扩容操作
##更改canary-deploy-demo2.yaml的.spec.replicas字段信息replicas: 5
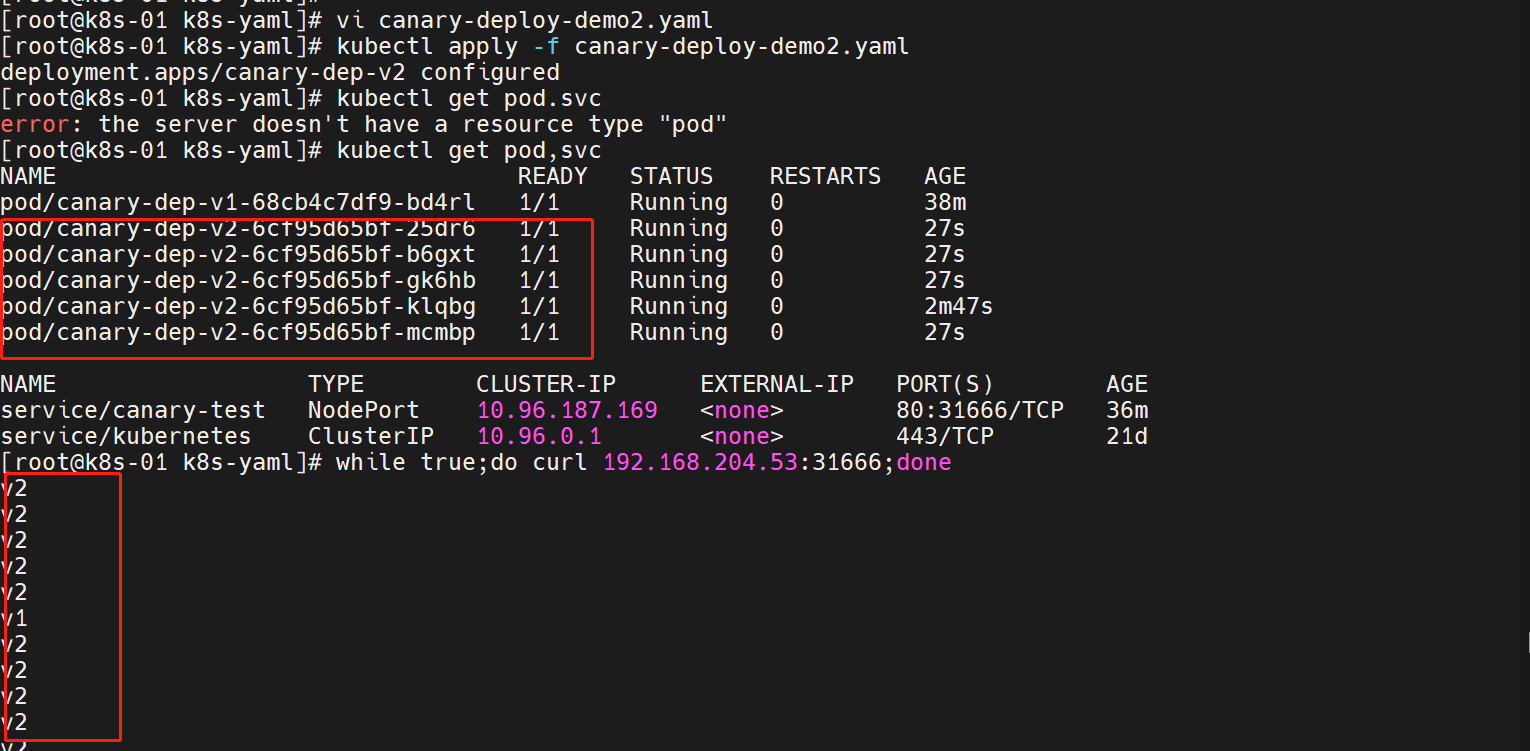
这个时候,通往 v2 版本的流量就增加了
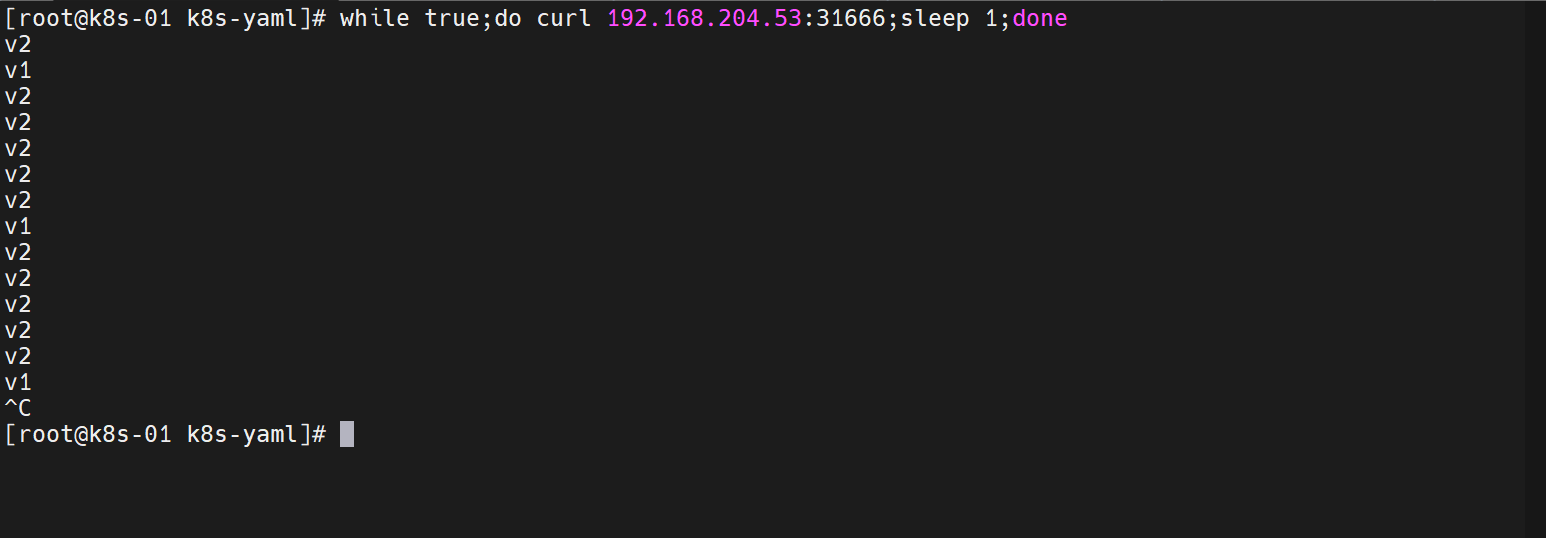
我们的新版本就OK,就可以删除v1版本了
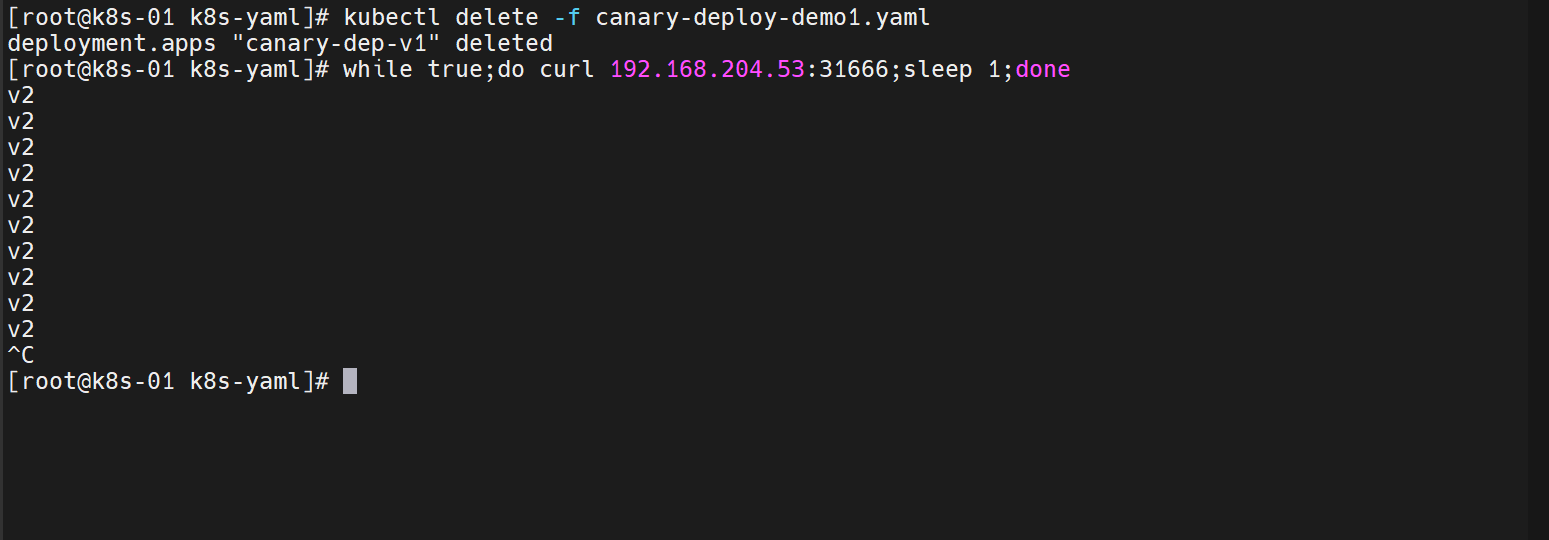
5. Deployment 状态与排查
5.1 进行中的 Deployment
执行下面的任务期间,Kubernetes 标记 Deployment 为进行中(Progressing)_:
- Deployment 创建新的 ReplicaSet
- Deployment 正在为其最新的 ReplicaSet 扩容
- Deployment 正在为其旧有的 ReplicaSet(s) 缩容
- 新的 Pod 已经就绪或者可用(就绪至少持续了 MinReadySeconds 秒)。
当上线过程进入“Progressing”状态时,Deployment 控制器会向 Deployment 的 .status.conditions 中添加包含下面属性的状况条目:
type: Progressingstatus: "True"reason: NewReplicaSetCreated|reason: FoundNewReplicaSet|reason: ReplicaSetUpdated
监视 Deployment 进度:kubectl rollout status deploy nginx-deployment
5.2 完成的 Deployment
当 Deployment 具有以下特征时,Kubernetes 将其标记为完成(Complete);
- 与 Deployment 关联的所有副本都已更新到指定的最新版本,这意味着之前请求的所有更新都已完成。
- 与 Deployment 关联的所有副本都可用。
- 未运行 Deployment 的旧副本。
当上线过程进入“Complete”状态时,Deployment 控制器会向 Deployment 的 .status.conditions 中添加包含下面属性的状况条目:
type: Progressingstatus: "True"reason: NewReplicaSetAvailable
5.3 失败的 Deployment
Deployment 可能会在尝试部署其最新的 ReplicaSet 受挫,一直处于未完成状态。 造成此情况一些可能因素如下:
- 配额(Quota)不足
- 就绪探测(Readiness Probe)失败
- 镜像拉取错误
- 权限不足
- 限制范围(Limit Ranges)问题
- 应用程序运行时的配置错误
描述性查看 Deployment 情况:kubectl describe deployment nginx-deployment
5.4 对失败 Deployment 的操作
可应用于已完成的 Deployment 的所有操作也适用于失败的 Deployment。 你可以对其执行扩缩容、回滚到以前的修订版本等操作,或者在需要对 Deployment 的 Pod 模板应用多项调整时,将 Deployment 暂停。
清理策略
可以在 Deployment 中设置 .spec.revisionHistoryLimit 字段以指定保留此 Deployment 的多少个旧有 ReplicaSet。其余的 ReplicaSet 将在后台被垃圾回收。 默认情况下,此值为 10。
将此字段设置为 0 将导致 Deployment 的所有历史记录被清空,造成 Deployment 将无法回滚
万能的排错方式:kubectl describe xxxxxx
相关文章:
k8s学习之路 | Day20 k8s 工作负载 Deployment(下)
文章目录3. HPA 动态扩缩容3.1 HPA3.2 安装 metrics-server3.3 验证指标收集3.4 扩缩容的实现3.5 增加负载3.6 降低负载3.7 更多的度量指标4. 金丝雀部署4.1 蓝绿部署4.2 金丝雀部署4.3 金丝雀部署的实现5. Deployment 状态与排查5.1 进行中的 Deployment5.2 完成的 Deployment…...

考研复试——操作系统
文章目录操作系统1. 操作系统的特征:2. 进程与线程的关系以及区别3. 简述进程和程序的区别4. 进程的常见状态?以及各种状态之间的转换条件?5. 进程的调度算法有哪些?6. 什么是死锁?产生条件?如何避免死锁&a…...

Java ~ Collection/Executor ~ LinkedBlockingDeque【源码】
一 LinkedBlockingDeque(链接阻塞双端队列)类源码及机制详解 类 LinkedBlockingDeque(链接阻塞双端队列)类(下文简称链接阻塞双端队列)是BlockingDeqeue(阻塞双端队列)接口的唯一实现…...

【前缀和】截断数组、K倍区间、激光炸弹
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...

函数编程:强大的 Stream API
函数编程:强大的 Stream API 每博一文案 只要有人的地方,世界就不会是冰冷的,我们可以平凡,但绝对不可以平庸。—————— 《平凡的世界》人活着,就得随时准备经受磨难。他已经看过一些书,知道不论是普通…...

企业架构图之业务架构图
在TOGAF的世界里面,所有的架构思想都可以通过下面三种类型的图形进行表示。 目录(Catalogs)矩阵(Matrix)图 (Diagram) 其架构图的本质就是用来进行沟通交流,通过架构图和业务团队进…...

监控易网络管理:网络流量分析
1、什么是网络流量分析2、网络流量分析的作用3、为什么要用网络流量分析功能,如何开启什么是网络流量分析简单的来说,网络流量分析就是捕捉网络中流动的数据包,并通过查看包内部数据以及进行相关的协议、流量、分析、统计等,协助发…...
RHCSA-文件内容显示(3.6)
查看命令 cat:显示文件内容 cat -n:显示文件内容的同时显示编号 tac:倒叙查看 head 文件名 (默认显示前10行):显示前10行 tail:显示末尾行数信息 more:查看文件信息,从头…...

Qt多线程文件查找器
⭐️我叫恒心,一名喜欢书写博客的研究生在读生。 原创不易~转载麻烦注明出处,并告知作者,谢谢!!! 这是一篇近期会不断更新的博客欧~~~ 有什么问题的小伙伴 欢迎留言提问欧。 Qt多线程文件查找器 前言 最近在实现一些代码功能的时候,需要找一些多线程样例来学习,于是就…...
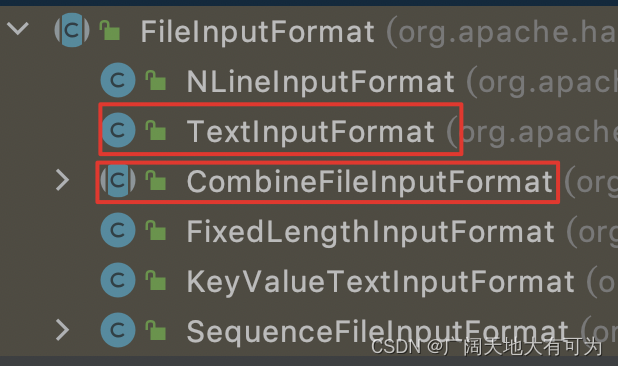
源码阅读笔记 InputFormat、FileInputFormat、CombineTextInputFormat
1. InputFormat InputFormat是MapReduce框架提供的用来处理job输入的基类 它主要定义了三个功能: 1.验证job输入是否合法 2.对输入文件进行逻辑切片(InputSplit),然后将每个切片分发给单独的MapTask 3.提供切片读取器(Re…...

二值图像骨架线提取
二值图像骨架线提取HilditchThin算法Rosenfeld算法OpenCV_Contrib中的算法示例其他细化算法查表法HilditchThin的另一种算法参考二值图像骨架线提取算法:HilditchThin算法、Rosenfeld算法、OpenCV_Contrib中的算法 HilditchThin算法 1、使用的8邻域标记为ÿ…...

规划数据指标体系方法(上)——OSM 模型
之前我已经有写过文章讲了数据指标体系的搭建思路,但有同学还是不太清楚要从何入手,今天我就来跟大家讲一讲搭建数据指标体系之前第一步要先做的事情——规划数据指标体系。 规划数据指标体系,在业内有三种比较常见的方法,分别是&…...

做程序界中的死神,继续提升灵力上限
标题解读:标题中的死神,是源自《死神》动漫里面的角色,斩魂刀是死神的武器,始解是斩魂刀的初始解放形态,卐解是斩魂刀的觉醒解放形态,也是死神的大招。意旨做程序界中程序员的佼佼者,一步一步最…...
[数据结构]:11-冒泡排序(顺序表指针实现形式)(C语言实现)
目录 前言 已完成内容 冒泡排序实现 01-开发环境 02-文件布局 03-代码 01-主函数 02-头文件 03-PSeqListFunction.cpp 04-SortCommon.cpp 05-SortFunction.cpp 结语 前言 此专栏包含408考研数据结构全部内容,除其中使用到C引用外,全为C语言代…...

Java实验报告经验总结
每一段是每一次实验报告写的经验总结,一共是一学期的内容 文章目录一二三四五六一 ~~~~~分析:这次做程序中也出了不少问题,究其根本还是没有理解清楚各语句功能和其应用。 ~~~~~比如说:当我们在定义浮点数时,数字的后面…...

ESP32使用TCP HTTP访问API接口JSON解析获取数据
ESP32使用TCP HTTP访问API接口JSON解析获取数据API接口代码解析获取时间代码烧录效果总结API接口 单片机常用的API接口基本都是返回的一串JSON格式的数据,这里以ESP32联网获取时间信息作为获取API数据的示例,以便后续移植使用。 很多功能性的API接…...
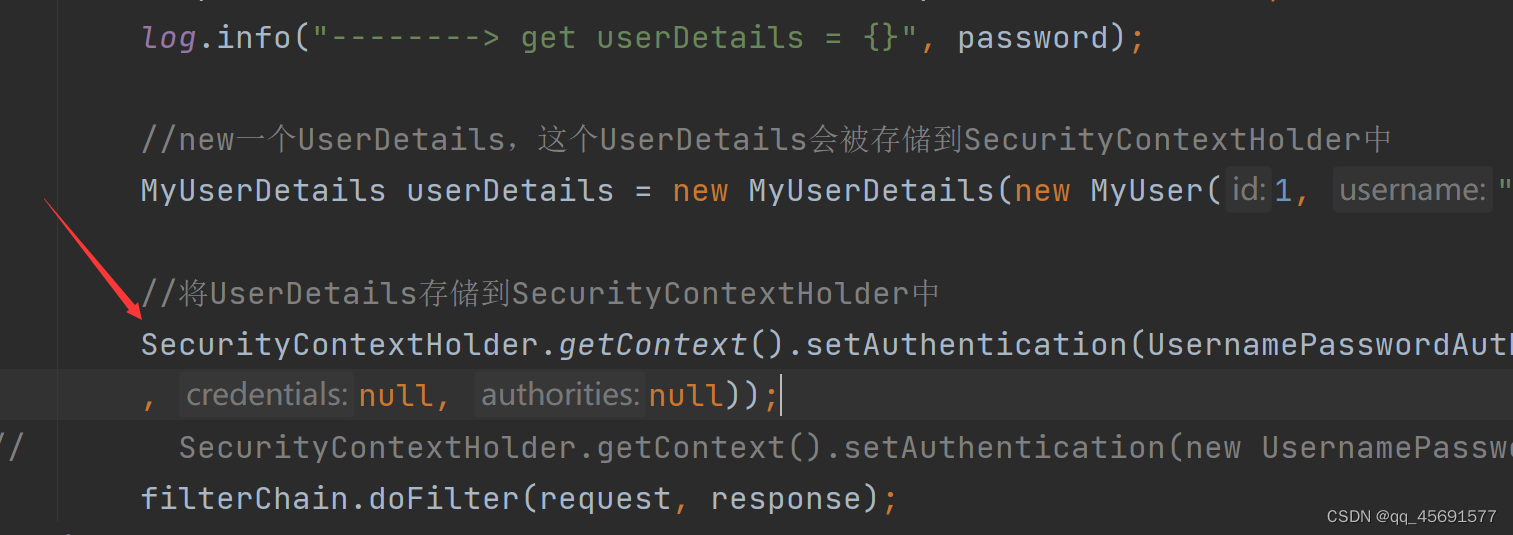
spring security 实现自定义认证和登录(4):使用token进行验证
前面我们实现了给客户端下发token,虽然客户端拿到了token,但我们还没处理客户端下一次携带token请求时如何验证,我们想要实现拿得到token之后,只需要验证token,不需要用户再携带用户名和密码了。 1. 禁用 UsernamePass…...
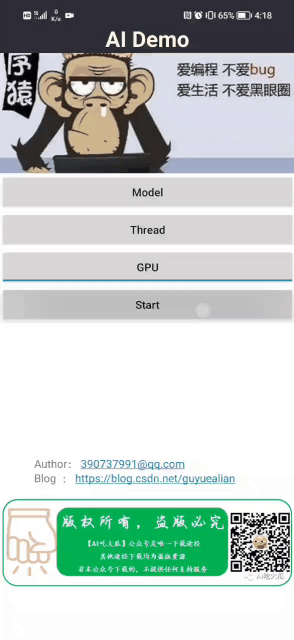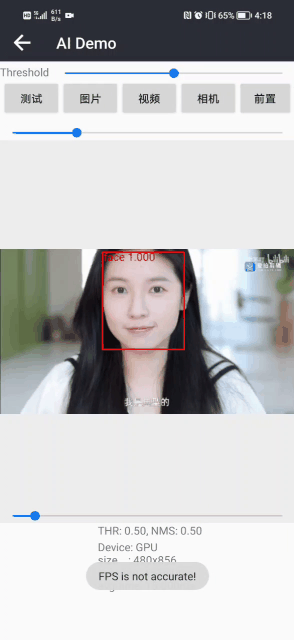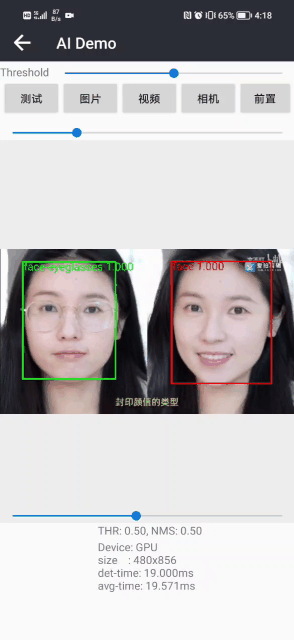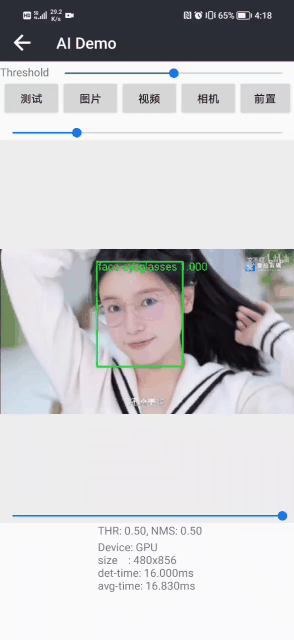
戴眼镜检测和识别2:Pytorch实现戴眼镜检测和识别(含戴眼镜数据集和训练代码)
Pytorch实现戴眼镜检测和识别(含戴眼镜数据集和训练代码) 目录 Pytorch实现戴眼镜检测和识别(含戴眼镜数据集和训练代码) 1.戴眼镜检测和识别方法 2.戴眼镜数据集 3.人脸检测模型 4.戴眼镜分类模型训练 (1)项目安装 (2)准…...

信息收集之Google Hacking
Google HackingGoogleHacking作为常用且方便的信息收集搜索引擎工具,它是利用谷歌搜索强大,可以搜出不想被看到的后台、泄露的信息、未授权访问,甚至还有一些网站配置密码和网站漏洞等。掌握了Google Hacking基本使用方法,或许下一…...

【面试题】如何避免使用过多的 if else?
大厂面试题分享 面试题库前后端面试题库 (面试必备) 推荐:★★★★★地址:前端面试题库一、引言相信大家听说过回调地狱——回调函数层层嵌套,极大降低代码可读性。其实,if-else层层嵌套,如下图…...

用Asian Beauty Z-Image Turbo做古风头像:简单三步生成独一无二的东方美学作品
用Asian Beauty Z-Image Turbo做古风头像:简单三步生成独一无二的东方美学作品 想象一下,你的社交媒体头像不再是一张普通的自拍或卡通形象,而是一幅充满东方韵味的古风艺术作品——可能是唐代仕女的温婉,宋代文人的儒雅…...

GitHub协作开发:AnythingtoRealCharacters2511动漫转真人开源项目实践
GitHub协作开发:AnythingtoRealCharacters2511动漫转真人开源项目实践 1. 项目介绍与准备 AnythingtoRealCharacters2511是一个专门将动漫角色转换为真实人像的开源项目,基于先进的AI图像生成技术。这个项目在GitHub上开源,让开发者可以共同…...

GodotPckTool 终极指南:如何在命令行中高效管理Godot游戏资源包
GodotPckTool 终极指南:如何在命令行中高效管理Godot游戏资源包 【免费下载链接】GodotPckTool Standalone tool for extracting and creating Godot .pck files 项目地址: https://gitcode.com/gh_mirrors/go/GodotPckTool 你是否曾经需要在不启动Godot引擎…...

Optick多线程性能分析:游戏引擎中的并发性能优化实战
Optick多线程性能分析:游戏引擎中的并发性能优化实战 【免费下载链接】optick C Profiler For Games 项目地址: https://gitcode.com/gh_mirrors/op/optick Optick是一款专为游戏开发打造的C性能分析工具,能够精准捕捉多线程应用中的性能瓶颈&…...

Godep历史意义揭秘:Go依赖管理工具的开创者如何改变开发方式
Godep历史意义揭秘:Go依赖管理工具的开创者如何改变开发方式 【免费下载链接】godep dependency tool for go 项目地址: https://gitcode.com/gh_mirrors/go/godep Godep作为Go语言依赖管理工具的开创者,在Go生态系统的演进历程中扮演了至关重要的…...
)
Pyspark环境搭建及案例(Windows)
Windows环境下开发pyspark程序 一、环境准备:Anaconda Python 虚拟环境 1. 安装 Anaconda(推荐) 下载地址:https://www.anaconda.com/products/distribution 安装时选择“Add Anaconda to PATH”会更方便。 2、新建虚拟环境 使…...

35AE92 GJR5137200R0005电子模块
35AE92 GJR5137200R0005 电子模块是一款工业控制系统用的电子控制模块,通常用于西门子或ABB等自动化设备中,承担信号处理、控制逻辑执行及系统接口功能。开头:35AE92 GJR5137200R0005电子模块是工业自动化控制系统的重要组成部分,…...

【ROS2 基础】ROS2与Colcon核心指令速查手册与避坑指南
为了在 ROS2 的日常开发中提升效率,本文为您整理了一份结构化的核心指令速查清单。去除了冗长的理论,直击实战痛点,并附带了多平台差异、性能优化数据以及常见报错的修复方案。 文章目录[TOC]一、 快速入门:3步跑通基础流程二、 版…...

终极Win11Debloat优化指南:简单4步让你的Windows 11飞起来
终极Win11Debloat优化指南:简单4步让你的Windows 11飞起来 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter an…...

爱毕业aibiye等8款智能应用显著改善了论文撰写体验,编程与学术研究流程更加顺畅
文章总结表格(工具排名对比) 工具名称 核心优势 aibiye 精准降AIGC率检测,适配知网/维普等平台 aicheck 专注文本AI痕迹识别,优化人类表达风格 askpaper 快速降AI痕迹,保留学术规范 秒篇 高效处理混AIGC内容&…...