戴眼镜检测和识别2:Pytorch实现戴眼镜检测和识别(含戴眼镜数据集和训练代码)
Pytorch实现戴眼镜检测和识别(含戴眼镜数据集和训练代码)
目录
Pytorch实现戴眼镜检测和识别(含戴眼镜数据集和训练代码)
1.戴眼镜检测和识别方法
2.戴眼镜数据集
3.人脸检测模型
4.戴眼镜分类模型训练
(1)项目安装
(2)准备数据
(3)戴眼镜分类模型训练(Pytorch)
(4) 可视化训练过程
(5) 戴眼镜识别效果
(6) 一些优化建议
(7) 一些运行错误处理方法
5.项目源码下载(Python版)
6.项目源码下载(Android版)
这是项目《戴眼镜检测和识别》系列之《Pytorch实现戴眼镜检测和识别(含戴眼镜数据集和训练代码)》;项目基于深度学习框架Pytorch开发一个高精度,可实时的戴眼镜检测和识别算法( Eyeglasses Detection and recognition);项目源码支持模型有resnet18,resnet34,resnet50, mobilenet_v2以及googlenet等常见的深度学习模型,用户可自定义进行训练;准确率还挺高的,采用轻量级mobilenet_v2模型的戴眼镜检测和识别准确率也可以高达98.6217%左右,满足业务性能需求。

| 模型 | input size | Test准确率 |
| mobilenet_v2 | 112×112 | 98.6217% |
| googlenet | 112×112 | 98.7643% |
| resnet18 | 112×112 | 98.8118% |
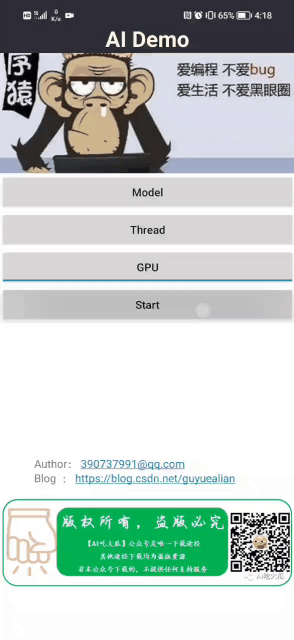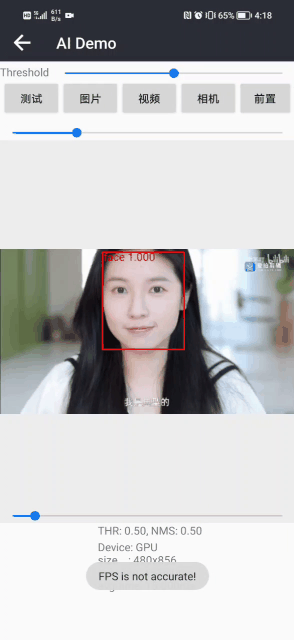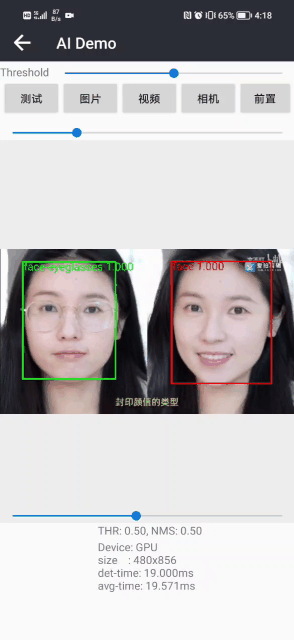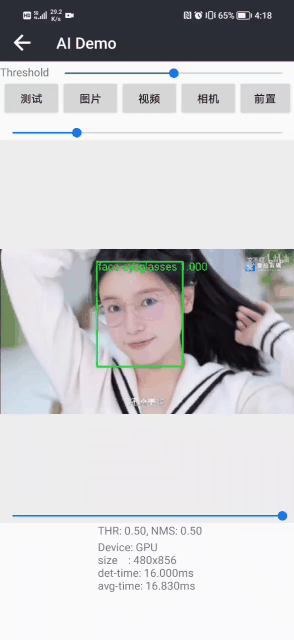
先展示一下,Python版本的戴眼镜检测和识别Demo效果(其中绿色框表示佩戴了眼镜,蓝色框表示未佩戴眼镜):

【尊重原创,转载请注明出处】 https://blog.csdn.net/guyuealian/article/details/129263640
更多项目《戴眼镜检测和识别》系列文章请参考:
- 戴眼镜检测和识别1:戴眼镜检测数据集(含下载链接): https://blog.csdn.net/guyuealian/article/details/129263537
- 戴眼镜检测和识别2:Pytorch实现戴眼镜检测和识别(含戴眼镜数据集和训练代码):https://blog.csdn.net/guyuealian/article/details/129263640
- 戴眼镜检测和识别3:Android实现戴眼镜检测和识别(含源码,可实时检测):https://blog.csdn.net/guyuealian/article/details/129263657
- 戴眼镜检测和识别4:C++实现戴眼镜检测和识别(含源码,可实时检测):https://blog.csdn.net/guyuealian/article/details/129263677
- 戴口罩人脸检测1:戴口罩人脸数据集:https://blog.csdn.net/guyuealian/article/details/125069926
- 戴口罩人脸检测2:Pytorch实现戴口罩人脸检测和戴口罩识别(含训练代码 戴口罩人脸数据集):https://blog.csdn.net/guyuealian/article/details/125428609
- 戴口罩人脸检测3:Android实现戴口罩人脸检测和戴口罩识别(附Android源码) :https://blog.csdn.net/guyuealian/article/details/128404379
- 安全帽检测1:佩戴安全帽数据集:https://blog.csdn.net/guyuealian/article/details/127331580
- 安全帽检测2:YOLOv5实现佩戴安全帽检测和识别(含佩戴安全帽数据集+训练代码):https://blog.csdn.net/guyuealian/article/details/127250780
- 安全帽检测3:Android实现佩戴安全帽检测和识别:https://blog.csdn.net/guyuealian/article/details/127345231
1.戴眼镜检测和识别方法
戴眼镜检测和识别方法有多种实现方案,这里采用最常规的方法:基于人脸检测+戴眼镜分类识别方法,即先采用通用的人脸检测模型,进行人脸检测,然后裁剪人脸区域,再训练一个戴眼镜分类器,对人脸是否戴眼镜进行分类识别(未戴眼镜和戴眼镜两个类别);
这样做的好处,是可以利用现有的人脸检测模型,而无需重新训练人脸检测模型,可减少人工标注成本低;而戴眼镜分类数据相对而言比较容易采集,分类模型可针对性进行优化。
2.戴眼镜数据集
项目已经收集了戴眼镜数据集(Eyeglasses-Dataset),总共约20000+张图片,分为eyeglasses-train训练集和eyeglasses-test测试集;其中训练集eyeglasses-train中,戴眼镜的人脸数据有10475张图片(标签为face-eyeglasses),不戴眼镜的人脸数据有12841张图片(标签为face);测试集eyeglasses-test戴眼镜和不戴眼镜的人脸数据各有1000张图片,共2000张图片。
所有数据都标注了人脸框,数据格式为VOC,其中戴眼镜的人脸框标注为face-eyeglasses,不戴眼镜的人脸框标注为face,该数据集可直接用于深度学习戴眼镜检测模型训练。为了方便分类模型训练,已经将eyeglasses-train和eyeglasses-test的人脸区域裁剪,并保存在crops目录中,该数据集可直接用于深度学习戴眼镜分类模型训练。
关于戴眼镜检测数据的使用说明请参考我的一篇博客:戴眼镜检测和识别1:戴眼镜检测数据集(含下载链接): https://blog.csdn.net/guyuealian/article/details/129263537

3.人脸检测模型
本项目人脸检测训练代码请参考:https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB
这是一个基于SSD改进且轻量化后人脸检测模型,很slim,整个模型仅仅1.7M左右,在普通Android手机都可以实时检测。人脸检测方法在网上有一大堆现成的方法可以使用,完全可以不局限我这个方法。

4.戴眼镜分类模型训练
准备好戴眼镜数据后,接下来就可以开始训练戴眼镜分类识别模型;项目模型支持resnet18,resnet34,resnet50, mobilenet_v2以及googlenet等常见的深度学习模型,考虑到后续我们需要将戴眼镜识别模型部署到Android平台中,因此项目选择计算量比较小的轻量化模型mobilenet_v2;如果不用端上部署,完全可以使用参数量更大的模型,如resnet50等模型。
(1)项目安装
整套工程项目基本结构如下:
.
├── classifier # 训练模型相关工具
├── configs # 训练配置文件
├── data # 训练数据
├── libs
│ ├── convert # 将模型转换为ONNX工具
│ ├── light_detector # 人脸检测
│ ├── detector.py # 人脸检测demo
│ └── README.md
├── demo.py # demo
├── README.md # 项目工程说明文档
├── requirements.txt # 项目相关依赖包
└── train.py # 训练文件项目依赖python包请参考requirements.txt,使用pip安装即可:
numpy==1.16.3
matplotlib==3.1.0
Pillow==6.0.0
easydict==1.9
opencv-contrib-python==4.5.2.52
opencv-python==4.5.1.48
pandas==1.1.5
PyYAML==5.3.1
scikit-image==0.17.2
scikit-learn==0.24.0
scipy==1.5.4
seaborn==0.11.2
tensorboard==2.5.0
tensorboardX==2.1
torch==1.7.1+cu110
torchvision==0.8.2+cu110
tqdm==4.55.1
xmltodict==0.12.0
basetrainer
pybaseutils==0.6.5项目安装教程请参考:项目开发使用教程和常见问题和解决方法
(2)准备数据
下载戴眼镜数据集eyeglasses-train和eyeglasses-tes,关于戴眼镜检测数据的使用说明请参考我的一篇博客:戴眼镜检测和识别1:戴眼镜检测数据集(含下载链接): https://blog.csdn.net/guyuealian/article/details/129263537
(3)戴眼镜分类模型训练(Pytorch)
项目在《Pytorch基础训练库Pytorch-Base-Trainer(支持模型剪枝 分布式训练)》基础上实现了戴眼镜和未戴眼镜二分类识别训练和测试,整套训练代码非常简单操作,用户只需要将相同类别的数据放在同一个目录下,并填写好对应的数据路径,即可开始训练了。
训练框架采用Pytorch,整套训练代码支持的内容主要有:
- 目前支持的backbone有:googlenet,resnet[18,34,50], ,mobilenet_v2等, 其他backbone可以自定义添加
- 训练参数可以通过(configs/config.yaml)配置文件进行设置
训练参数说明如下:
# 训练数据集,可支持多个数据集
train_data:- 'path/to/dataset/eyeglasses-train/face/crops'- 'path/to//dataset/eyeglasses-train/face-eyeglasses/crops'
# 测试数据集
test_data:- 'path/to/dataset/eyeglasses-test/face/crops'- 'path/to/dataset/eyeglasses-test/face-eyeglasses/crops'
# 类别文件
class_name: 'data/class_name.txt'
train_transform: "train" # 训练使用的数据增强方法
test_transform: "val" # 测试使用的数据增强方法
work_dir: "work_space/" # 保存输出模型的目录
net_type: "mobilenet_v2" # 骨干网络,支持:resnet18/50,mobilenet_v2,googlenet,inception_v3
width_mult: 1.0
input_size: [ 112,112 ] # 模型输入大小
rgb_mean: [ 0.5, 0.5, 0.5 ] # for normalize inputs to [-1, 1],Sequence of means for each channel.
rgb_std: [ 0.5, 0.5, 0.5 ] # for normalize,Sequence of standard deviations for each channel.
batch_size: 16
lr: 0.01 # 初始学习率
optim_type: "SGD" # 选择优化器,SGD,Adam
loss_type: "CrossEntropyLoss" # 选择损失函数:支持CrossEntropyLoss,LabelSmoothing
momentum: 0.9 # SGD momentum
num_epochs: 100 # 训练循环次数
num_warn_up: 3 # warn-up次数
num_workers: 4 # 加载数据工作进程数
weight_decay: 0.0005 # weight_decay,默认5e-4
scheduler: "multi-step" # 学习率调整策略
milestones: [ 20,50,80 ] # 下调学习率方式
gpu_id: [ 0 ] # GPU ID
log_freq: 50 # LOG打印频率
progress: True # 是否显示进度条
pretrained: True # 是否使用pretrained模型
finetune: False # 是否进行finetune开始训练,在终端输入:
python train.py -c configs/config.yaml
训练完成后,训练集的Accuracy在99%以上,测试集的Accuracy在98%左右
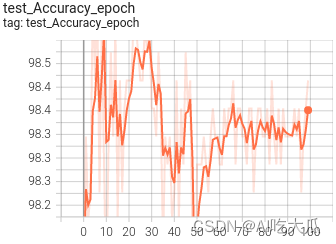
(4) 可视化训练过程
训练过程可视化工具是使用Tensorboard,在终端输入命令:
# 基本方法
tensorboard --logdir=path/to/log/
# 例如
tensorboard --logdir=work_space/mobilenet_v2_1.0_CrossEntropyLoss_20230228174645/log
可视化效果
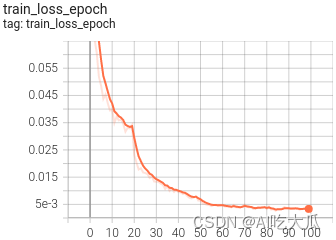
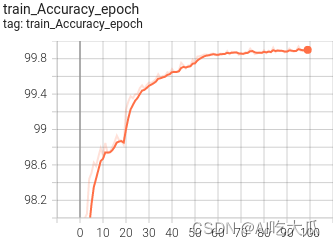
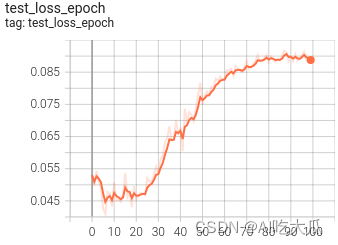
(5) 戴眼镜识别效果
训练完成后,训练集的Accuracy在99%以上,测试集的Accuracy在98%以上,下表给出已经训练好的三个模型,其中mobilenet_v2的准确率可以达到98.6217%,googlenet的准确率可以达到98.7643%,resnet18的准确率可以达到98.8118%
| 模型 | input size | Test准确率 |
| mobilenet_v2 | 112×112 | 98.6217% |
| googlenet | 112×112 | 98.7643% |
| resnet18 | 112×112 | 98.8118% |
-
测试图片文件
# 测试图片(Linux)
image_dir='data/test_image' # 测试图片的目录
model_file="data/pretrained/mobilenet_v2_1.0_CrossEntropyLoss_20230228174645/model/latest_model_099_98.4316.pth" # 模型文件
out_dir="output/" # 保存检测结果
python demo.py --image_dir $image_dir --model_file $model_file --out_dir $out_dir
Windows系统,请将$image_dir, $model_file ,$out_dir等变量代替为对应的变量值即可,如
# 测试图片(Windows)
python demo.py --image_dir 'data/test_image' --model_file "data/pretrained/mobilenet_v2_1.0_CrossEntropyLoss_20230228174645/model/latest_model_099_98.4316.pth" --out_dir "output/"
-
测试视频文件
# 测试视频文件(Linux)
video_file="data/video-test.mp4" # 测试视频文件,如*.mp4,*.avi等
model_file="data/pretrained/mobilenet_v2_1.0_CrossEntropyLoss_20230228174645/model/latest_model_099_98.4316.pth" # 模型文件
out_dir="output/" # 保存检测结果
python demo.py --video_file $video_file --model_file $model_file --out_dir $out_dir
-
测试摄像头
# 测试摄像头(Linux)
video_file=0 # 测试摄像头ID
model_file="data/pretrained/mobilenet_v2_1.0_CrossEntropyLoss_20230228174645/model/latest_model_099_98.4316.pth" # 模型文件
out_dir="output/" # 保存检测结果
python demo.py --video_file $video_file --model_file $model_file --out_dir $out_dir
戴眼镜检测和识别效果展示(其中绿色框表示佩戴了眼镜,蓝色框表示未佩戴眼镜)

(6) 一些优化建议
如果想进一步提高模型的性能,可以尝试:
- 清洗数据集(最重要):戴眼镜原始数据部分数据是通过网上爬取的,存在部分错误的图片,尽管鄙人已经清洗一部分了,但还是建议你,训练前,再次清洗数据集,不然会影响模型的识别的准确率。
- 增加训练的样本数据: 建议根据自己的业务场景,采集相关数据,提高模型泛化能力
- 使用参数量更大的模型: 本教程使用的是mobilenet_v2模型,属于比较轻量级的分类模型,采用更大的模型(如resnet50),理论上其精度更高,但推理速度也较慢。
- 尝试不同数据增强的组合进行训练
- 增加数据增强: 已经支持: 随机裁剪,随机翻转,随机旋转,颜色变换等数据增强方式,可以尝试诸如mixup,CutMix等更复杂的数据增强方式
- 样本均衡: 建议进行样本均衡处理
- 调超参: 比如学习率调整策略,优化器(SGD,Adam等)
- 损失函数: 目前训练代码已经支持:交叉熵,LabelSmoothing,可以尝试FocalLoss等损失函数
(7) 一些运行错误处理方法
-
cannot import name 'load_state_dict_from_url'
由于一些版本升级,会导致部分接口函数不能使用,请确保版本对应
torch==1.7.1
torchvision==0.8.2
或者将对应python文件将
from torchvision.models.resnet import model_urls, load_state_dict_from_url
修改为:
from torch.hub import load_state_dict_from_url
model_urls = {'mobilenet_v2': 'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth','resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth','resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth','resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth','resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth','resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth','resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth','resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth','wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth','wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth',
}
5.项目源码下载(Python版)
整套项目源码内容包含:
- 提供戴眼镜数据集:训练集eyeglasses-train中,戴眼镜的人脸数据有10475张图片(标签为face-eyeglasses),不戴眼镜的人脸数据有12841张图片(标签为face),测试集eyeglasses-test戴眼镜和不戴眼镜的人脸数据各有1000张图片,共2000张图片。
- 提供戴眼镜分类识别训练代码:train.py
- 提供戴眼镜分类识别测试代码:demo.py
- Demo支持图片,视频和摄像头测试
- 项目支持模型:resnet18,resnet34,resnet50, mobilenet_v2以及googlenet等常见的深度学习模型
- 项目源码自带训练好的模型文件,可直接运行测试: python demo.py
- 在普通电脑CPU/GPU上可以实时检测和识别
6.项目源码下载(Android版)
目前已经实现Android版本的戴眼镜检测和识别,详细项目请参考:戴眼镜检测和识别3:Android实现戴眼镜检测和识别(含源码,可实时检测):https://blog.csdn.net/guyuealian/article/details/129263657
Android戴眼镜检测和识别APP Demo体验:https://download.csdn.net/download/guyuealian/87524194
相关文章:
戴眼镜检测和识别2:Pytorch实现戴眼镜检测和识别(含戴眼镜数据集和训练代码)
Pytorch实现戴眼镜检测和识别(含戴眼镜数据集和训练代码) 目录 Pytorch实现戴眼镜检测和识别(含戴眼镜数据集和训练代码) 1.戴眼镜检测和识别方法 2.戴眼镜数据集 3.人脸检测模型 4.戴眼镜分类模型训练 (1)项目安装 (2)准…...

信息收集之Google Hacking
Google HackingGoogleHacking作为常用且方便的信息收集搜索引擎工具,它是利用谷歌搜索强大,可以搜出不想被看到的后台、泄露的信息、未授权访问,甚至还有一些网站配置密码和网站漏洞等。掌握了Google Hacking基本使用方法,或许下一…...

【面试题】如何避免使用过多的 if else?
大厂面试题分享 面试题库前后端面试题库 (面试必备) 推荐:★★★★★地址:前端面试题库一、引言相信大家听说过回调地狱——回调函数层层嵌套,极大降低代码可读性。其实,if-else层层嵌套,如下图…...
oneblog_justauth_三方登录配置【Gitee】
文章目录oneblog添加第三方平台gitee中创建三方应用完善信息oneblog添加第三方平台 1.oneblog管理端,点击左侧菜单 网站管理——>社会化登录配置管理 ,添加一个社会化登录 2.编辑信息如下,选择gitee平台后复制redirectUri,然后去gitee获取clientId和…...
33- PyTorch实现分类和线性回归 (PyTorch系列) (深度学习)
知识要点 pytorch最常见的创建模型的方式, 子类 读取数据: data pd.read_csv(./dataset/credit-a.csv, headerNone) 数据转换为tensor: X torch.from_numpy(X.values).type(torch.FloatTensor) 创建简单模型: from torch import nn model nn.Sequential(nn.Linear(15, 1…...
C++基础——Ubuntu下编写C++环境配置总结(C++基本简介、Ubuntu环境配置、编写简单C++例程)
【系列专栏】:博主结合工作实践输出的,解决实际问题的专栏,朋友们看过来! 《QT开发实战》 《嵌入式通用开发实战》 《从0到1学习嵌入式Linux开发》 《Android开发实战》 《实用硬件方案设计》 长期持续带来更多案例与技术文章分享…...

项目管理中,导致进度失控的五种错误
项目管理中对工期的控制主要是进度控制,在项目进行中中,由于项目时间跨度长,人员繁杂,如果管理不规范,就容易导致项目进度滞后,如何管理好施工进度是管理者需要解决的问题之一。 1、项目计划缺乏执行力 安…...

C# 中的abstract和virtual
重新理解了下关键字abstract,做出以下总结: 1.标记为abstract的类不能实例化,但是依然可以有构造函数,也可以重载构造函数,在子类中调用 2.abstract类中可以有abstract标记的方法和属性,也可以没有,被标记…...

第六十周总结——React数据管理
React数据管理 代码仓库 React批量更新 React中的批量更新就是将多次更新合并处理,最终只渲染一次,来获得更好的性能。 React18版本之前的批量更新 // react 17 react-dom 17 react-scripts 4.0.3 import * as ReactDOM from "react-dom"…...

Springboot之@Async异步指定自定义线程池使用
开发中会碰到一些耗时较长或者不需要立即得到执行结果的逻辑,比如消息推送、商品同步等都可以使用异步方法,这时我们可以用到Async。但是直接使用 Async 会有风险,当我们没有指定线程池时,他会默认使用其Spring自带的 SimpleAsync…...
- TS格式详解指南)
视频知识点(23)- TS格式详解指南
*《音视频开发》系列-总览*(点我) 一、格式简介 TS视频封装格式,是一种被广泛应用的多媒体文件格式。它的全称是MPEG2-TS,其中TS是“Transport Stream”的缩写。TS(Transport Stream)流是一种传输流,它由固定长度(188 字节)的 TS 包组成,TS 包是对PES包的一种封装方式…...
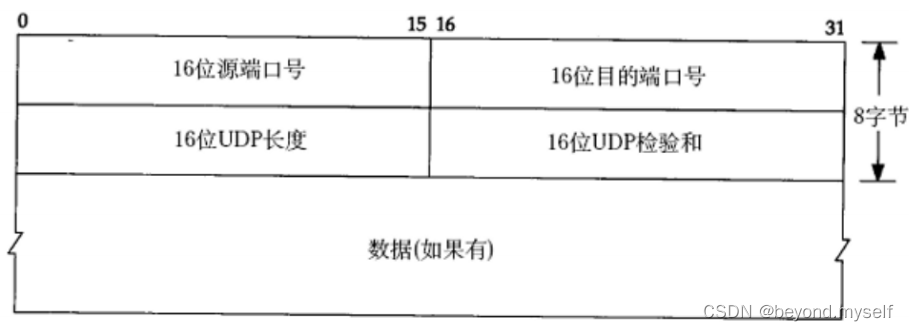
linux篇【16】:传输层协议<后序>
目录 六.滑动窗口 (1)发送缓冲区结构 (2)滑动窗口介绍 (3)滑动窗口不一定只会向右移动。滑动窗口可以变大也可以变小。 (4)那么如果出现了丢包, 如何进行重传? 这里分两种情况…...
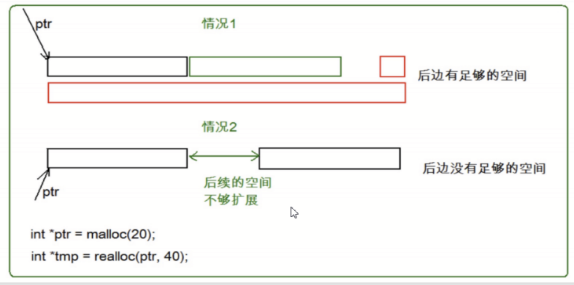
【C语言】动态内存管理
一.为什么存在动态内存分配? 我们已经掌握的内存开辟方式有:int val 20;//在栈空间上开辟四个字节 char arr[10] {0};//在栈空间上开辟10个字节的连续空间 但是上述的开辟空间的方式有两个特点: 1. 空间开辟大小是固定的。 2. 数组在申明的…...
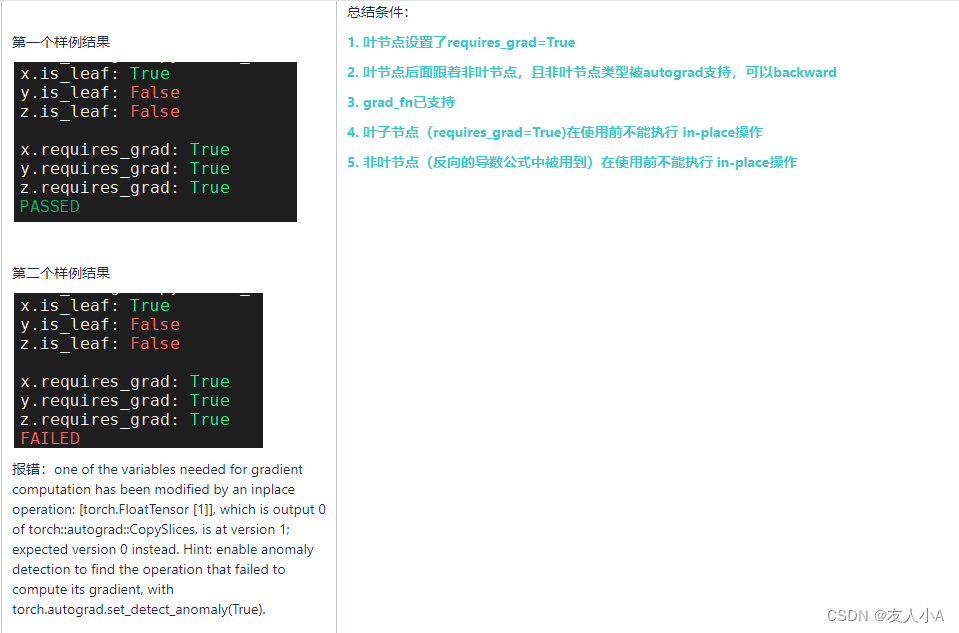
【Pytorch】AutoGrad个人理解
前提知识:[Pytorch] 前向传播和反向传播示例_友人小A的博客-CSDN博客 目录 简介 叶子节点 Tensor AutoGrad Functions 简介 torch.autograd是PyTorch的自动微分引擎(自动求导),为神经网络训练提供动力。torch.autograd需要对…...

华硕z790让独显和集显同时工作
系统用了一段时间,现在想让显卡主要做深度学习训练,集显用来连接显示器。却发现显示器接到集显接口无信号。 打售后客服也没有解决,现在把解决方案记录一下。 这是客服给的方案: 请开机后进BIOS---Advanced---System Agent (SA)…...

提高编程思维的python代码
1.通过函数取差。举例:返回有差别的列表元素 from math import floordef difference_by(a,b,fn):b set(map(fn, b))return [i for i in a if fn(i) not in b] print(difference_by([2.1, 1.2], [2.3, 3.4], floor))2.一行代码调用多个函数 def add(a, b):return …...

CSS背景background属性整理
1.background-color background-color属性:设置元素的背景颜色 2.background-position background-position属性:设置背景图像的起始位置,需要把 background-attachment 属性设置为 "fixed",才能保证该属性在 Firefo…...
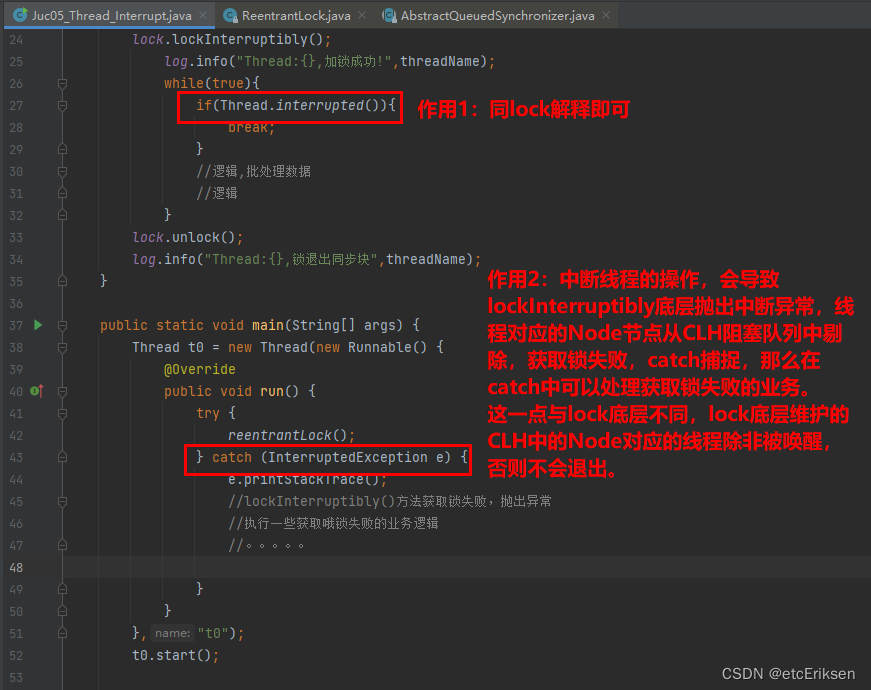
AQS底层源码深度剖析-Lock锁
目录 AQS底层源码深度剖析-Lock锁 ReentrantLock底层原理 为什么把获取锁失败的线程加入到阻塞队列中,而不是采取其它方法? 总结:三大核心原理 CAS是啥? 代码模拟一个CAS: 公平锁与非公平锁 可重入锁的应用场景&…...
网络编程(二)
6. TCP 三次握手四次挥手 HTTP 协议是 Hype Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web)服务器(sever)传输超文本到客户端(本地浏览器…...

访问学者进入美国哪些东西不能带?
随着疫情的稳定,各国签证的逐步放开,成功申请到国外访问学者、博士后如何顺利的进入国外,哪些东西不能带,下面就随知识人网小编一起看一看。一、畜禽肉类(Meats, Livestock and Poultry)不论是新鲜的、干燥的、罐头的、真空包装的…...
)
告别手动抢红包!用Kotlin写一个Android微信红包监听助手(附完整代码)
用Kotlin构建Android微信红包自动化工具:从原理到避坑指南 春节聚会时,你是否曾因低头抢红包错过亲友的精彩对话?工作群里的手气红包总在分神时一闪而过?作为一名Android开发者,其实可以用技术优雅解决这些烦恼。本文…...

在Python项目中管理多个Taotoken API Key实现访问控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Python项目中管理多个Taotoken API Key实现访问控制 在开发基于大语言模型的应用程序时,一个常见的需求是为不同的功…...

英雄联盟Akari助手:免费开源的终极游戏效率工具完整指南
英雄联盟Akari助手:免费开源的终极游戏效率工具完整指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟中繁琐的配…...

AP431比较器应用设计与动态响应优化
1. AP431作为比较器的设计背景与特性解析在模拟电路设计中,电压基准源和比较器是两个最基础的构建模块。AP431作为行业标准431系列的一员,最初的设计定位是精密电压基准源,用于替代传统齐纳二极管。其核心价值在于内部集成了一个高精度2.5V带…...

书成紫微动,律定凤凰驯:海棠山铁哥,用两部作品走完了千年谶语的路
书成紫微动,律定凤凰驯。 ——千年谶语,今终圆满。一、悬在文脉上空的千年谶语“书成紫微动,律定凤凰驯”自诞生之日起,这句庙堂吉颂便高悬于华夏文脉之上,无人可触、无人能落。 文人墨客解其字,玄学爱好者…...

从开源哲学到工程实践:探索Uncomfortable-filagree112/OpenViking的代码美学
1. 项目概述:当开源遇上“不适”的优雅最近在GitHub上闲逛,发现了一个名字相当有意思的项目:Uncomfortable-filagree112/OpenViking。初看这个标题,一股强烈的反差感扑面而来——“Uncomfortable”(不适)、…...

弃ReID跨镜,选镜像无感定位——打破跨镜追踪断链困局,实现全域精准无感感知
弃ReID跨镜,选镜像无感定位——打破跨镜追踪断链困局,实现全域精准无感感知在安防监控、智慧园区、商业综合体、交通枢纽等场景中,跨摄像头目标追踪是核心需求之一——无论是人员轨迹追溯、异常行为预警,还是资产安全管控、流量数…...

GBase 8c 在过程里记流水时要小心自治事务边界
GBase 8c 在过程里记流水时要小心自治事务边界 我最近看 GBase 8c 自治事务资料时,觉得它特别适合拿来讨论一个开发现场经常遇到的问题:业务过程失败了,排障流水也跟着回滚了。等真正去查问题时,只剩应用日志里几行模糊报错&#…...

Next.js企业级项目脚手架:架构设计、工程化实践与生产部署指南
1. 项目概述:一个为Next.js量身打造的企业级起点如果你正在寻找一个能让你快速启动Next.js项目,同时又不想在项目初期就陷入繁琐的脚手架搭建、代码规范配置和基础架构设计的泥潭,那么once-ui-system/nextjs-starter这个项目很可能就是你一直…...
)
【工具分享】9款漏扫工具来了!(内附学习笔记)
【工具分享】9款漏扫工具来了!(内附学习笔记) 以下所有这些工具都是捆绑在一起的Linux发行版,如Kali Linux或BackBox,所以我会建议您安装一个合适的Linux黑客系统,尤其是因为这些黑客工具可以(自…...