GPU性能测试中的张量和矩阵运算

正文共:888 字 7 图,预估阅读时间:1 分钟
前面我们使用PyTorch将Tesla M4跑起来之后(成了!Tesla M4+Windows 10+Anaconda+CUDA 11.8+cuDNN+Python 3.11),一直有个问题,那就是显存容量的问题。
测试中,使用的Python脚本中有这样几行:
size = (10240, 10240)
input_cpu = torch.randn(size)
input_gpu = input_cpu.to(torch.device('cuda'))其中,torch是深度学习框架PyTorch库的一个常用缩写;randn是PyTorch中的一个函数,用于生成具有标准正态分布(也称为高斯分布)的随机数(均值为0,方差为1);而size定义了生成张量的形状和大小,(10240, 10240)表示创建一个二维张量,第一维度有1024行,第二维度有1024列,得到一个1024*1024的矩阵,每个点对应一个浮点数,一共有1,048,576个浮点数。
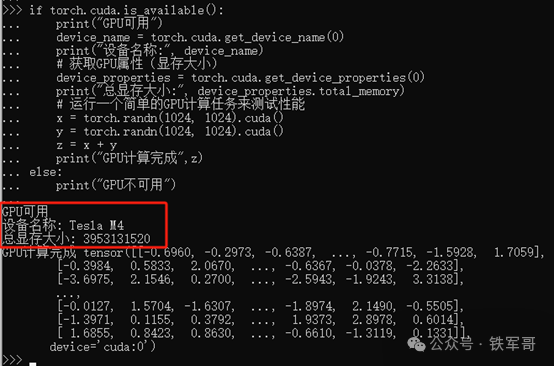
从输出的数值来看,每个浮点数有4位小数点,整数位至少为1位,还分正负,最多有20万种可能,如果按照2为底数来计算,至少需要2的16次方(262144)才能包含;通过查阅资料,randn生成的浮点数使用float32保存,占用4字节空间。
于是,当我们将张量定义到(102400, 102400)时,出现了内存不足的情况,提示需要41,943,040,000字节,这么算下来每个浮点数确实是占用4字节大小的内存。
当我们将张量定义到(51200, 51200)时,出现了显存不足的情况,提示需要9.77 GB的显存。如果也按照每个浮点数占用4字节大小,一共是10,485,760,000字节,按照1024进制计算,一共是9.765625 GB,跟提示的9.77 GB相符。
如此说来,执行等量的运算,CPU运算占用的内存与GPU运算占用的显存是一样的,那Tesla M4这4 GB的小显存有点吃亏啊,看来得换成24 GB的大显存才好使啊,但是24 GB显存的Tesla P40是全高双插槽的GPU,得换大个的服务器才能使,还得再等等。
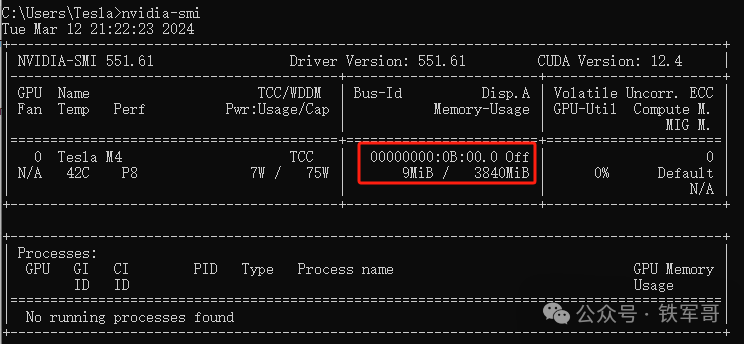
而按照回显显示的3840MB(3953131520字节)大小,最多可以分配31436*31436个浮点数,实际设置成(30000,30000)执行一下。
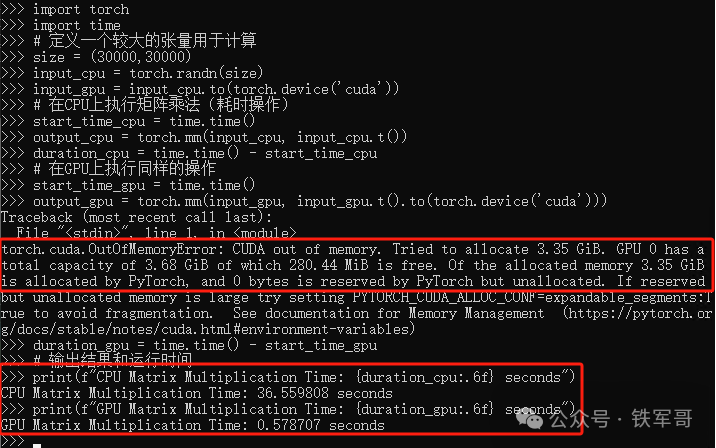
提示CUDA out of memory,还是超了,虽然只需要3.35 GB显存,但为什么会超呢?而且运算中有提示,显存的3.35 GB已经分配给了PyTorch(Of the allocated memory 3.35 GiB is allocated by PyTorch),那为什么会需要两个3.35 GB显存呢?
报错是在output_gpu = torch.mm(input_gpu, input_gpu.t().to(torch.device('cuda')))后面,在这条命令里:
input_gpu是已经在CUDA GPU设备上的张量,对应input_gpu = input_cpu.to(torch.device('cuda')),表示将位于CPU上的张量input_cpu 转移到GPU设备上,约等于input_gpu = torch.randn(size),但实际效果有所不同,具体等会看;
input_gpu.t()中的.t()用于计算并返回张量的转置(行变成列、列变成行);
torch.mm()函数则是进行矩阵乘法运算,即对input_gpu与它的转置input_gpu.t()进行矩阵乘法运算。
那要这么看,我是不是可以仅对GPU进行运算?
import torch
import time
output_gpu = None
size = (30000,30000)
input_gpu = torch.randn(size)
start_time_gpu = time.time()
output_gpu = torch.mm(input_gpu, input_gpu.t())
duration_gpu = time.time() - start_time_gpu
output_gpu = None
print(f"GPU Matrix Multiplication Time: {duration_gpu:.6f} seconds")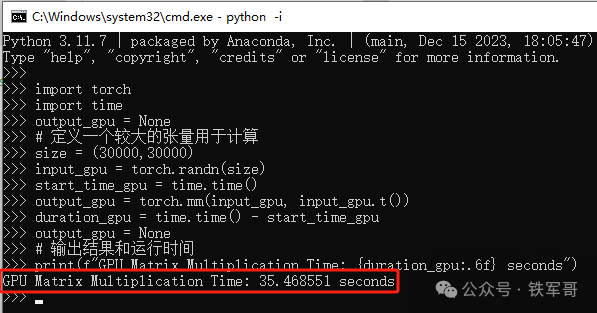
难道可行?这次GPU没有报错,但出现了一个问题,没有调用GPU设备,还是使用CPU运算的。
调用GPU设备试一下。
import torch
import time
size = (30000,30000)
input_gpu = torch.randn(size, device=torch.device('cuda'))
start_time_gpu = time.time()
output_gpu = torch.mm(input_gpu, input_gpu.t())
duration_gpu = time.time() - start_time_gpu
output_gpu = None
print(f"GPU矩阵乘法运行时间: {duration_gpu:.6f} 秒")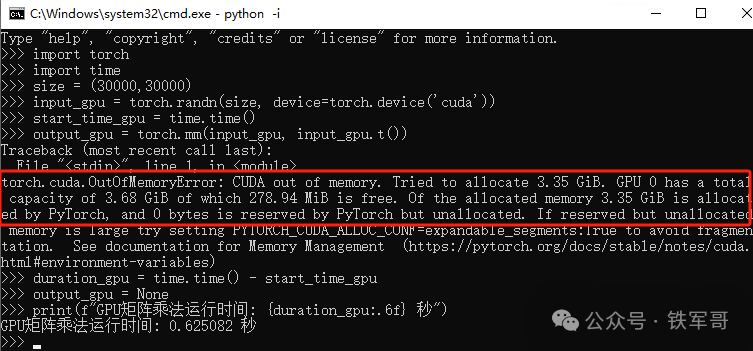
接下来,我们考虑为什么会占用2个3.35 GB,应该是input_gpu占用了3.35 GB,之后input_gpu.t()又要占用3.35 GB,导致显存不足;及时如此,生成的结果还可能会占用1个3.35 GB,这样一来,显存明显就不够了。
这样的话,实际应该按照1920 MB来计算张量,也就是(21000,21000),测试一下。
import torch
import time
size = (21000,21000)
input_gpu = torch.randn(size, device=torch.device('cuda'))
start_time_gpu = time.time()
output_gpu = torch.mm(input_gpu, input_gpu.t())
duration_gpu = time.time() - start_time_gpu
print(f"GPU矩阵乘法运行时间: {duration_gpu:.6f} 秒")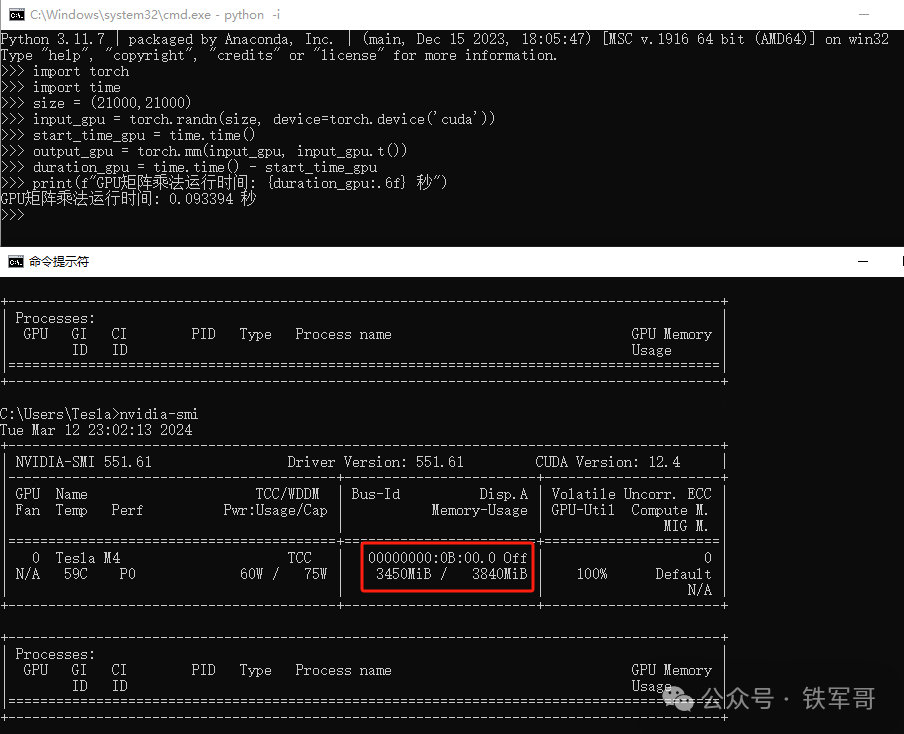
果然,就是这个原因,(21000,21000)实际对应1682 MB显存,两倍的话就是3364 MB,加上一部分其他占用,与最终的3450 MB差不多。
按照这个张量,再对比一下CPU和GPU的性能。
import torch
import time
size = (21000,21000)
input_cpu = torch.randn(size)
input_gpu = input_cpu.to(torch.device('cuda'))
# 在CPU上执行矩阵乘法(耗时操作)
start_time_cpu = time.time()
output_cpu = torch.mm(input_cpu, input_cpu.t())
duration_cpu = time.time() - start_time_cpu
# 在GPU上执行同样的操作
start_time_gpu = time.time()
output_gpu = torch.mm(input_gpu, input_gpu.t().to(torch.device('cuda')))
duration_gpu = time.time() - start_time_gpu
print(f"CPU矩阵乘法运行时间: {duration_cpu:.6f} 秒")
print(f"GPU矩阵乘法运行时间: {duration_gpu:.6f} 秒")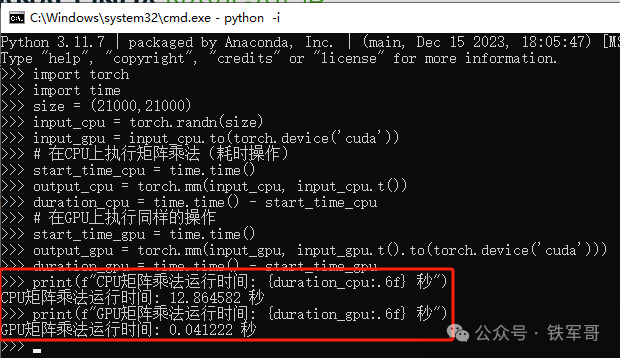
CPU耗时为GPU的312倍,说明GPU的运算效率大约是CPU的312倍吧。

长按二维码
关注我们吧


成了!Tesla M4+Windows 10+Anaconda+CUDA 11.8+cuDNN+Python 3.11
人工智能如何发展到AIGC?解密一份我四年前写的机器学习分享材料
一起学习几个简单的Python算法实现
MX250笔记本安装Pytorch、CUDA和cuDNN
复制成功!GTX1050Ti换版本安装Pytorch、CUDA和cuDNN
Windows Server 2019配置多用户远程桌面登录服务器
Windows Server调整策略实现999999个远程用户用时登录
RDP授权119天不够用?给你的Windows Server续个命吧!
使用Python脚本实现SSH登录设备
配置VMware实现从服务器到虚拟机的一键启动脚本
CentOS 7.9安装Tesla M4驱动、CUDA和cuDNN
使用vSRX测试一下IPsec VPN各加密算法的性能差异
相关文章:
GPU性能测试中的张量和矩阵运算
正文共:888 字 7 图,预估阅读时间:1 分钟 前面我们使用PyTorch将Tesla M4跑起来之后(成了!Tesla M4Windows 10AnacondaCUDA 11.8cuDNNPython 3.11),一直有个问题,那就是显存容量的问…...

Linux运维_Bash脚本_编译安装FreeRDP-3.3.0
Linux运维_Bash脚本_编译安装FreeRDP-3.3.0 Bash (Bourne Again Shell) 是一个解释器,负责处理 Unix 系统命令行上的命令。它是由 Brian Fox 编写的免费软件,并于 1989 年发布的免费软件,作为 Sh (Bourne Shell) 的替代品。 您可以在 Linux…...

CMake官方教程4--使用表达式生成器
1. 使用表达式生成器产生警告 CMakeList.txt cmake_minimum_required(VERSION 3.15)project(Tutorial VERSION 1.0)add_library(tutorial_compiler_flags INTERFACE) target_compile_features(tutorial_compiler_flags INTERFACE cxx_std_11)set(gcc_like_cxx "$<COM…...

git for windows
记录,git svn混用,检出代码时出错及解决方案, 执行命令: git svn clone svn_project_url 报错: certificate problem.(R)eject,accept (t)emporarily or accept (p)ermanently 解决: 在弹框中 输入P …...
C++实验 面向对象编程
一、实验目的: 掌握类中静态成员的定义方法,初始化方法,使用方法; 掌握类的友元说明方法,理解友元的使用特点 二、实验内容: 1、编写程序,统计某旅馆住宿客人的总数,要求输入客人…...

VC++ 设置网卡接口MTU大小
在 Windows C/C 之中一共有三种方法可以设置网卡的MTU大小。 方法一: SetIpInterfaceEntry 法 static bool SetInterfaceMtu2(int interface_index, int mtu) noexcept{PIP_ADAPTER_ADDRESSES pAddresses NULL;ULONG ulBufLen 0;GetAdaptersAddresses(AF_UNSPEC…...

dpdk-19.11 对向量指令的使用情况分析
不同向量指令识别关键字 __m128i sse uint64x2_t neon __m256i avx2 __m512i avx512 vector altivec dpdk 向量收发包函数 支持 arm neno 向量收发包函数的 pmd 驱动 bnxt hns3 i40e ixgbe mlx5 virtio 支持 sse 向量收发包函数的 pmd 驱动 axgbe hinic fm10k bnxt i40e …...

使用CIP采集欧姆龙EtherNet/IP从入门到精通
本文将会从以下几个方面介绍 1.CIP是什么 2.EtherNet/IP通信是什么 3.CIP通信报文解析 4.使用CIP常用的方法和功能介绍(UCMM) 5.自己封装了一个类,只要知道标签名称,和数据类型即可读写数据 6.demo展示 1.CIP是什么 CIP通信…...

企业如何高效管理微信里的客户?
对于企业来说,懂得高效管理微信列表的客户是非常重要的一件事,只有把客户管理好了,才能更好地提高客户的满意度和忠诚度,我们的销售业务才能顺利进行。 那么,应该怎样管理才能算是高效管理呢?下面就给大家…...
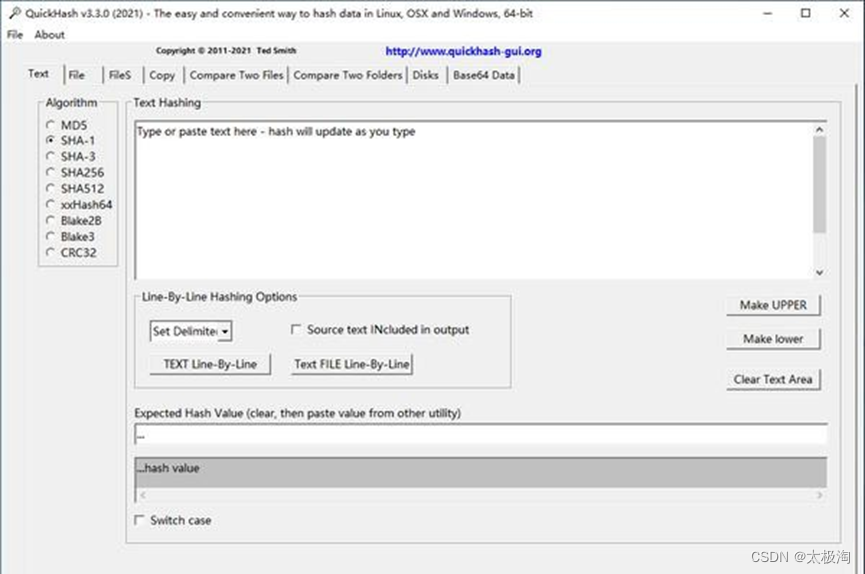
怎么在windows系统上查看kylinos的md5、sha1、sha256值
背景 当前信创行业正如火如荼进行中,当下载kylinos镜像到windows系统下,如何核对镜像是否有损坏,确保文件不被篡改,需要使用工具计算md5、sha1、sha256、sha512值,并与出库邮件中的md5比对。 QuickHash GUI软件简介 QuickHash GUI是一款开源代码的哈希工具,注意哈希能够…...
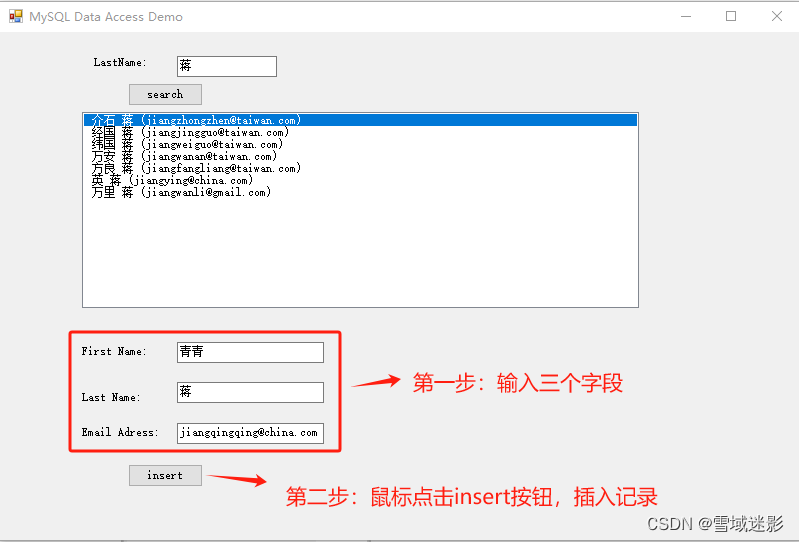
Windows中在C#中使用Dapper和Mysql.Data库连接MySQL数据库
Windows中在C#中使用Dapper和Mysql.Data库连接MySQL数据库 在Windows中使用C#连接Mysql数据库比较简单,可以直接使用MySql.Data库,目前最新版本为:8.3.0。 当然也可以结合MySql.Data和Dapper库一起使用,目前Dapper的最新版本为&a…...

大一专科,物联网专业,变态成长偏方!
最近看到一个大一,物联网专业的学生提问: 印象中,物联网专业2011年才有的,正好是我毕业那年。 我大概看过物联网专业要学的内容,总结下来就是,比软件不如计算机,比硬件知识不如电子。 不知道老师…...
MyBatis入门(JDBC规范,MyBatis,连接池,Lombok)【详解】
目录 一、JDBC规范【了解】 1. JDBC介绍 2. JDBC示例 3. JDBC的问题 二、MyBatis入门【重点】 1. Mybatis是什么 2. Mybatis使用步骤 3. Mybatis入门案例 1.创建SpringBoot工程 2.创建Mapper 3.功能测试 三、连接池【了解】 1. 什么是连接池 2. 有哪些数据库连接池…...

Vue3--数据和方法
data 组件的 data 选项是一个函数。Vue 在创建新组件实例的过程中会自动调用此函数。 data选项通常返回一个对象,然后 Vue 会通过响应性系统将其包裹起来,并以 $data 的形式存储在组件实例中。 <!DOCTYPE html> <html lang"en"&g…...

网络编程面试题
一、什么是IP地址 1.IP地址是主机在网路中的唯一标识,,当主机从一个网络切换到另一个网络时,会更改IP地址,同样的IP地址也是路由器进行路由选择的标识 2.IP地址的分类 IPV4:采用4字节无符号整数存储 IPV6ÿ…...

移动端区分点击和长按
为了适配移动端,图片加入touchstart,touchend,并加了 e.preventDefault() 屏蔽默认菜单。 然而突然发现移动端图片的链接无响应了,PC端没问题。 而且功能需要区分点击和长按。 原生js如何判断移动端的tap,dbltap,lo…...
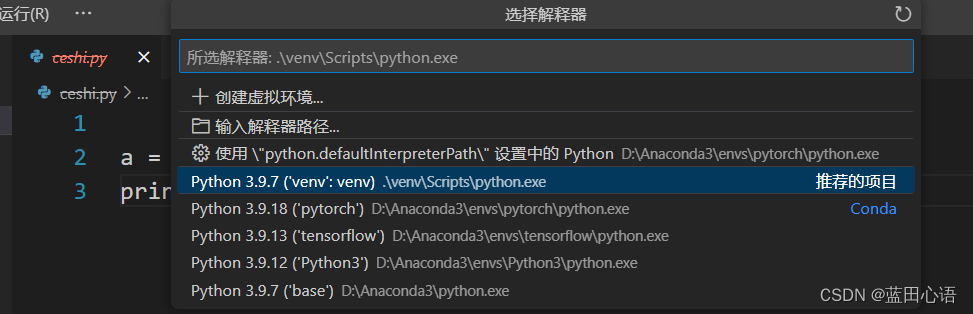
虚拟环境的激活
(此博客仅用于我记录虚拟环境的激活方法) 虚拟环境的激活命令: venv/Scripts/activate 在F:\git repo\Database-Course-Design 这个文件夹中启动命令行 这个文件夹中含有虚拟环境venv 输入命令venv/Scripts/activate,就得到下面的结果: 此时就激活了虚拟环境&…...

宏集案例 | 风电滑动轴承齿轮箱内多点温度采集与处理
前言 风力发电机组中的滑动轴承齿轮箱作为关键的传动装置,承担着将风能转化为电能的重要角色。齿轮箱内多点温度的实时监测可以有效地预防设备故障和性能下降。实时监测齿轮箱内多点温度可以有效地预防设备故障和性能下降。 为了确保风力发电机组的安全稳定运行&a…...

linux 16进制写入
1.简单用法[推荐] echo 001122334455 | xxd -r -ps > test // 6 个字节xxd // xxd 命令用于用二进制或十六进制显示文件的内容 -r // 把xxd的十六进制输出内容转换回原文件的二进制内容 -ps // 以 postscript的连续十六进制转储输出,这也叫做纯十六进…...

代码随想录算法训练营第60天| Leetcode 84.柱状图中最大的矩形
文章目录 Leetcode 84.柱状图中最大的矩形 Leetcode 84.柱状图中最大的矩形 题目链接:Leetcode 84.柱状图中最大的矩形 题目描述: 给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。求在该柱状…...

Maxwell 磁芯损耗模型怎么选?Power Ferrite vs B-P Curve
🔖 开篇一句话总结 Power Ferrite:用斯坦梅茨公式算损耗,简单高效,适合标准铁氧体材料快速估算。 B-P Curve:直接用实测数据点插值,精度更高,适合非标准材料或追求极致仿真的场景。 一、底层逻辑有什么不一样? 🔹 Power Ferrite:公式拟合的 “标准模板” 它基于经…...

Cosm算法突破:Gset最大Ising问题求解新纪元
1. Cosm算法突破:Gset最大Ising问题求解新纪元在组合优化领域,Gset基准问题集已经困扰了研究者25年之久。这些看似简单的数学问题背后,隐藏着从无人机集群实时决策到超大规模集成电路设计等众多实际应用的优化需求。作为NP难问题的典型代表&a…...

Claude Desktop for Linux SSH助手集成:远程开发环境配置
Claude Desktop for Linux SSH助手集成:远程开发环境配置 【免费下载链接】claude-desktop-debian Claude Desktop for Linux 项目地址: https://gitcode.com/GitHub_Trending/cl/claude-desktop-debian Claude Desktop for Linux是一款专为Linux系统打造的A…...

ARM架构中APB外设与External PPB空间部署解析
1. APB系统外设与External PPB空间的关系解析在嵌入式系统设计中,APB(Advanced Peripheral Bus)作为ARM架构中广泛使用的低速外设总线,其常规部署位置通常位于SoC内部。但近年来,随着异构计算和模块化设计的普及,将APB外设放置在E…...

Cortex-R52多集群中断处理机制与优化实践
1. Cortex-R52多集群中断处理机制解析在嵌入式实时系统中,Cortex-R52处理器因其确定性中断响应能力而广受青睐。当设计采用多集群架构时,中断处理机制面临独特挑战——每个集群内置的GIC模块如何协同工作?这直接关系到系统实时性能的边界。关…...

Blender 3MF插件:实现CAD到3D打印的无缝转换完整指南
Blender 3MF插件:实现CAD到3D打印的无缝转换完整指南 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 在3D打印和数字制造领域,3D Manufacturing F…...
)
ISTA 7D-2007 全解析|运输包装温度循环测试标准(CSDN 完整版)
前言ISTA 7D-2007 是 ISTA 7 系列包装研发测试标准,专注于温控运输包装的温度环境模拟测试,用于评估保温箱、冷藏包、冷链包装在高低温循环环境下的隔热保温性能。该标准提供冬季 / 夏季、国内 / 国际、24h/48h/72h多套温度循环曲线,覆盖快递…...

DS4Windows终极指南:如何让PlayStation手柄在Windows上完美运行
DS4Windows终极指南:如何让PlayStation手柄在Windows上完美运行 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 想在Windows电脑上畅玩所有游戏,却只有PlayStation…...

Unity WebGL性能优化实战:内存管理、WASM调优与Shader变体精简
1. 这不是“把游戏搬上网”那么简单:为什么《疯狂特技赛车2》的Web化是Unity引擎能力边界的试金石 你肯定见过那种“Unity WebGL导出一键搞定”的教程,点几下Build Settings,勾上WebGL,等十分钟编译完,拖进浏览器——然…...
、共享锁、排他锁、乐观锁、悲观锁、死锁、Hive 中的锁)
数据库锁机制:表锁、行锁(Oracle 默认)、共享锁、排他锁、乐观锁、悲观锁、死锁、Hive 中的锁
数据库锁机制是控制并发访问数据的关键技术。本文系统介绍了锁的概念、分类和应用场景:1)锁通过限制并发访问确保数据一致性,类比厕所门锁机制;2)按粒度分为表锁(适合批量操作)、行锁࿰…...