java操作HBase
创建一个学生信息表,用来存储学生的姓名(姓名作为行键,且假设姓名不会重复)以及考试成绩,其中考试成绩(score)是一个列族,存储了各个科目的考试成绩。然后向student中添加数据
1、HBase依赖
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>2.2.0</version>
</dependency>
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>2.2.0</version>
</dependency>
2、HBase数据源
package com.example.demo.config;import com.example.demo.service.ICodeService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;import java.util.HashMap;
import java.util.List;
import java.util.Map;@Component
@Order(1)
public class NmsHBaseSource implements ApplicationRunner {// 管理HBase的配置信息public static Configuration conf;// 管理HBase的连接public static Connection conn;// 管理HBase数据库的连接public static Admin admin;@Overridepublic void run(ApplicationArguments args) throws Exception {conf = HBaseConfiguration.create();System.setProperty("HADOOP_USER_NAME", "hadoop");conf.set("HADOOP_USER_NAME", "hadoop");conf.set("hbase.root.dir", "hdfs://master:9000/hbase");conf.set("hbase.zookeeper.quorum", "master");//配置Zookeeper的ip地址conf.set("hbase.zookeeper.property.clientPort", "2181");//配置zookeeper的端口conn = ConnectionFactory.createConnection(conf);admin = conn.getAdmin();}/*** 关闭所有连接** @throws IOException 可能出现的异常*/public static void close() throws IOException {if (admin != null)admin.close();if (conn != null)conn.close();}/*** 创建表* @param myTableName 表名* @param colFamily 列族名的数组* @throws IOException 可能出现的异常*/public static void createTable(String myTableName, String[] colFamily) throws IOException {TableName tableName = TableName.valueOf(myTableName);if (admin.tableExists(tableName)) {logger.info(myTableName + "表已经存在");} else {//HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName);//for (String str : colFamily) {// HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(str);// hTableDescriptor.addFamily(hColumnDescriptor);//}//admin.createTable(hTableDescriptor);TableDescriptorBuilder tableDescriptor = TableDescriptorBuilder.newBuilder(tableName); for (String str : colFamily) {ColumnFamilyDescriptor columnFamily = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(str)).build();// 构建列族对象 tableDescriptor.setColumnFamily(columnFamily); // 设置列族}admin.createTable(tableDescriptor.build()); // 创建表}}/*** 添加数据* @param tableName 表名* @param rowkey 行键* @param colFamily 列族* @param col 列* @param value 值* @throws IOException 可能出现的异常*/public static void insertData(String tableName,String rowkey,String colFamily,String col,String value) throws IOException {Table table = conn.getTable(TableName.valueOf(tableName));Put put = new Put(rowkey.getBytes());put.addColumn(colFamily.getBytes(),col.getBytes(),value.getBytes());table.put(put);table.close();}/*** 根据行键删除数据* @param tableName 表名* @param rowkey 行键* @throws IOException 可能出现的异常*/public static void deleteData(String tableName,String rowkey) throws IOException {Table table = conn.getTable(TableName.valueOf(tableName));Delete delete = new Delete(rowkey.getBytes());table.delete(delete);table.close();}/*** 获取数据* @param tableName 表名* @param rowkey 行键* @param colFamily 列族* @param col 列* @throws IOException 可能出现的异常*/public static void getData(String tableName,String rowkey,String colFamily,String col) throws IOException {Table table = conn.getTable(TableName.valueOf(tableName));Get get = new Get(rowkey.getBytes());get.addColumn(colFamily.getBytes(),col.getBytes());Result result = table.get(get);System.out.println(new String(result.getValue(colFamily.getBytes(),col.getBytes())));table.close();}public static void main(String[] args) throws IOException {init();createTable("student",new String[]{"score"});insertData("student","zhangsan","score","English","69");insertData("student","zhangsan","score","Math","86");insertData("student","zhangsan","score","Computer","77");getData("student","zhangsan","score","Computer");close();}
}3、Hbase过滤器查询
过滤器可以分为两种:比较过滤器和专用过滤器
比较过滤器
LESS —— 小于
LESS_OR_EQUAL —— 小于等于
EQUAL —— 等于
NOT_EQUAL —— 不等于
GREATER_OR_EQUAL —— 大于等于
GREATER —— 大于
NO_OP —— 排除所有
专用过滤器
BinaryComparator —— 匹配完整字节数组,Bytes.compareTo(byte[])
BinaryPrefixComparator —— 匹配字节数组前缀
NullComparator —— 判断给定的是否为空
BitComparator —— 按位比较
RegexStringComparator —— 提供一个正则的比较器,仅支持 EQUAL 和非EQUAL
SubstringComparator —— 判断提供的子串是否出现在value中
-
3.1、ResultScanner结果处理handleResultScanner
/*** ResultScanner结果解析*/
public void handleResultScanner(ResultScanner scanner) throws IOException {//因为ResultScanner类继承了迭代器//使用增强for循环遍历for (Result rs : scanner) {String id = Bytes.toString(rs.getRow());System.out.println("当前行的rowkey为:" + id);//继续增强for循环得到每一行中的每一个单元格(列)//获取一行中的所有单元格for (Cell cell : rs.listCells()) {//获取该单元格属于的列簇String family = Bytes.toString(CellUtil.cloneFamily(cell));//获取该单元格的列名String colName = Bytes.toString(CellUtil.cloneQualifier(cell));//获取该单元格的列值String value = Bytes.toString(CellUtil.cloneValue(cell));System.out.println(family + ":" + colName + "的值为:" + value);}
String name = Bytes.toString(rs.getValue("info".getBytes(), "name".getBytes()));String age = Bytes.toString(rs.getValue("info".getBytes(), "age".getBytes()));String gender = Bytes.toString(rs.getValue("info".getBytes(), "gender".getBytes()));String clazz = Bytes.toString(rs.getValue("info".getBytes(), "clazz".getBytes()));System.out.println("学号:" + id + ",姓名:" + name + ",年龄:" + age + ",性别:" + gender + ",班级:" + clazz);}3.2、rowKey过滤器RowFilter
/*** 行键过滤器* 通过RowFilter与BinaryComparator过滤比rowKey 1500100010小的所有值出来*/
@Test
public void RowFilter1(){try {//获取表的实例TableName students = TableName.valueOf("students");Table studentTable = conn.getTable(students);
BinaryComparator binaryComparator = new BinaryComparator("1500100010".getBytes());
//创建一个行键过滤器的对象RowFilter rowFilter = new RowFilter(CompareOperator.LESS, binaryComparator);
Scan scan = new Scan();scan.setFilter(rowFilter);
ResultScanner scanner = studentTable.getScanner(scan);handleResultScanner(scanner);
} catch (IOException e) {e.printStackTrace();}
}3.3、列族过滤器FamilyFilter
/*** 通过FamilyFilter与SubstringComparator查询列簇名包含in的所有列簇下面的数据*/
@Test
public void FamilyFilter1(){try {//获取表的实例TableName students = TableName.valueOf("students");Table studentTable = conn.getTable(students);
//创建一个比较器对象//只要列簇名中包含了in,就把该列簇下的所有列查询出来SubstringComparator substringComparator = new SubstringComparator("in");
//创建列簇过滤器FamilyFilter familyFilter = new FamilyFilter(CompareOperator.EQUAL, substringComparator);
Scan scan = new Scan();scan.setFilter(familyFilter);
//获取数据ResultScanner scanner = studentTable.getScanner(scan);handleResultScanner(scanner);
} catch (IOException e) {e.printStackTrace();}
}/*** 通过FamilyFilter与 BinaryPrefixComparator 过滤出列簇以i开头的列簇下的所有数据**/
@Test
public void FamilyFilter2(){try {//获取表的实例TableName students = TableName.valueOf("students");Table studentTable = conn.getTable(students);
//创建前缀比较器BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator("i".getBytes());
//创建列簇过滤器FamilyFilter familyFilter = new FamilyFilter(CompareOperator.EQUAL, binaryPrefixComparator);
Scan scan = new Scan();scan.setFilter(familyFilter);
ResultScanner scanner = studentTable.getScanner(scan);handleResultScanner(scanner);
} catch (IOException e) {e.printStackTrace();}
}3.4、列过滤器QualifierFilter
/*** 通过QualifierFilter与SubstringComparator查询列名包含ge的列的值**/
@Test
public void QualifierFilter1(){try {//获取表的实例TableName students = TableName.valueOf("students");Table studentTable = conn.getTable(students);
//创建包含比较器//age//genderSubstringComparator substringComparator = new SubstringComparator("ge");
//创建一个列过滤器QualifierFilter qualifierFilter = new QualifierFilter(CompareOperator.EQUAL, substringComparator);
Scan scan = new Scan();scan.setFilter(qualifierFilter);
ResultScanner scanner = studentTable.getScanner(scan);handleResultScanner(scanner);
} catch (IOException e) {e.printStackTrace();}
}/**** 通过QualifierFilter与SubstringComparator查询列名包含ge的列的值*/
@Test
public void QualifierFilter2(){try {//获取表的实例TableName students = TableName.valueOf("students");Table studentTable = conn.getTable(students);
SubstringComparator substringComparator = new SubstringComparator("am");
//创建列过滤器QualifierFilter qualifierFilter = new QualifierFilter(CompareOperator.EQUAL, substringComparator);
Scan scan = new Scan();scan.setFilter(qualifierFilter);
ResultScanner scanner = studentTable.getScanner(scan);handleResultScanner(scanner);
} catch (IOException e) {e.printStackTrace();}
}3.5、列值过滤器ValueFilter
/*** 通过ValueFilter与BinaryPrefixComparator过滤出所有的cell中值以 "张" 开头的学生*/
@Test
public void ValueFilter1() {try {//获取表的实例TableName students = TableName.valueOf("students");Table studentTable = conn.getTable(students);
//创建前缀比较器BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator("张".getBytes());
//创建列值过滤器的对象ValueFilter valueFilter = new ValueFilter(CompareOperator.EQUAL, binaryPrefixComparator);
Scan scan = new Scan();scan.setFilter(valueFilter);
ResultScanner scanner = studentTable.getScanner(scan);
//因为ResultScanner类继承了迭代器//使用增强for循环遍历
// for (Result rs : scanner) {
// String id = Bytes.toString(rs.getRow());
// System.out.println("当前行的rowkey为:" + id);
// //继续增强for循环得到每一行中的每一个单元格(列)
// //获取一行中的所有单元格
// for (Cell cell : rs.listCells()) {
// //获取该单元格属于的列簇
// String family = Bytes.toString(CellUtil.cloneFamily(cell));
// //获取该单元格的列名
// String colName = Bytes.toString(CellUtil.cloneQualifier(cell));
// //获取该单元格的列值
// String value = Bytes.toString(CellUtil.cloneValue(cell));
// System.out.println(family + ":" + colName + "的值为:" + value);
// }
// }
handleResultScanner(scanner);} catch (IOException e) {e.printStackTrace();}
}/*** 过滤出文科的学生,只会返回以文科开头的数据列,其他列的数据不符合条件,不会返回*/
@Test
public void ValueFilter12(){try {//获取表的实例HTableInterface students = conn.getTable("students");
//创建正则比较器RegexStringComparator regexStringComparator = new RegexStringComparator("^文科.*");
//创建列值过滤器ValueFilter valueFilter = new ValueFilter(CompareFilter.CompareOp.EQUAL, regexStringComparator);
Scan scan = new Scan();scan.setFilter(valueFilter);
ResultScanner scanner = students.getScanner(scan);handleResultScanner(scanner);
} catch (IOException e) {e.printStackTrace();}
}3.6、单列值过滤器 SingleColumnValueFilter
/*** 单列值过滤器* SingleColumnValueFilter会返回满足条件的cell所在行的所有cell的值(即会返回一行数据)** 通过SingleColumnValueFilter与查询文科班所有学生信息*/
@Test
public void SingleColumnValueFilter(){try {//获取表的实例TableName students = TableName.valueOf("students");Table studentTable = conn.getTable(students);
//创建一个正则比较器RegexStringComparator regexStringComparator = new RegexStringComparator("^文科.*");
//创建单列值过滤器对象SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter("info".getBytes(),"clazz".getBytes(),CompareOperator.EQUAL,regexStringComparator);
Scan scan = new Scan();scan.setFilter(singleColumnValueFilter);
ResultScanner scanner = studentTable.getScanner(scan);handleResultScanner(scanner);
} catch (IOException e) {e.printStackTrace();}
}3.7、列值排除过滤器SingleColumnValueExcludeFilter
/*** 列值排除过滤器* 与SingleColumnValueFilter相反,会排除掉指定的列,其他的列全部返回** 通过SingleColumnValueExcludeFilter与BinaryComparator查询文科一班所有学生信息,最终不返回clazz列*/
@Test
public void SingleColumnValueExcludeFilter(){try {//获取表的实例TableName students = TableName.valueOf("students");Table studentTable = conn.getTable(students);
//创建一个二进制比较器BinaryComparator binaryComparator = new BinaryComparator("文科一班".getBytes());
//创建一个列值排除过滤器SingleColumnValueExcludeFilter singleColumnValueExcludeFilter = new SingleColumnValueExcludeFilter("info".getBytes(),"clazz".getBytes(),CompareOperator.EQUAL,binaryComparator);
Scan scan = new Scan();scan.setFilter(singleColumnValueExcludeFilter);
ResultScanner scanner = studentTable.getScanner(scan);handleResultScanner(scanner);
} catch (IOException e) {e.printStackTrace();}
}3.8、rowKey前缀过滤器PrefixFilter
/*** rowkey前缀过滤器** 通过PrefixFilter查询以150010008开头的所有前缀的rowkey*/
@Test
public void PrefixFilter(){try {//获取表的实例TableName students = TableName.valueOf("students");Table studentTable = conn.getTable(students);
//创建rowkey前缀过滤器PrefixFilter prefixFilter = new PrefixFilter("150010008".getBytes());Scan scan = new Scan();
scan.setFilter(prefixFilter);ResultScanner scanner = studentTable.getScanner(scan);handleResultScanner(scanner);
} catch (IOException e) {e.printStackTrace();}
}3.9、分页过滤器PageFilter
/*** 分页过滤器* 分页有两个条件* pageNum 第几页* pageSize 每页有几条*/
@Test
public void pageFilter() throws IOException {int pageNum = 3;int pageSize = 2;/*分为两种情况判断:第一页其他页*/if (pageNum == 1){Scan scan = new Scan();//设置起始rowKeyscan.setStartRow("".getBytes());//设置最大的返回结果,返回pageSize条scan.setMaxResultSize(pageSize);//分页过滤器PageFilter pageFilter = new PageFilter(pageSize);scan.setFilter(pageFilter);ResultScanner resultScanner = table.getScanner(scan);for (Result result : resultScanner) {byte[] row = result.getRow();System.out.println("数据的rowKey为" + Bytes.toString(row));List<Cell> cells = result.listCells();for (Cell cell : cells) {byte[] qualifier = cell.getQualifier();byte[] family = cell.getFamily();byte[] value = cell.getValue();//id列和age列是整型数据if ("f1".equals(Bytes.toString(family)) && "id".equals(Bytes.toString(qualifier)) || "age".equals(Bytes.toString(value))){System.out.println("列族为"+Bytes.toString(family)+"列名为"+Bytes.toString(qualifier)+"列值为"+Bytes.toInt(value));} else {System.out.println("列族为"+Bytes.toString(family)+"列名为"+Bytes.toString(qualifier)+"列值为"+Bytes.toString(value));}}}} else {String startRow = "";Scan scan = new Scan();/*第二页的起始rowKey = 第一页的结束rowKey + 1第三页的起始rowKey = 第二页的结束rowKey + 1*/int resultSize = (pageNum - 1) * pageSize + 1;scan.setMaxResultSize(resultSize);//设置一次性往前扫描5条,最后一个rowKey是第三页起始rowKeyPageFilter pageFilter = new PageFilter(resultSize);scan.setFilter(pageFilter);//resultScanner里面有5条数据ResultScanner scanner = table.getScanner(scan);for (Result result : scanner) {//获取rowKeybyte[] row = result.getRow();//最后一次循环遍历 rowKey为0005startRow = Bytes.toString(row);}Scan scan1 = new Scan();scan1.setStartRow(startRow.getBytes());scan1.setMaxResultSize(pageSize);PageFilter pageFilter1 = new PageFilter(pageSize);scan1.setFilter(pageFilter1);ResultScanner scanner1 = table.getScanner(scan1);for (Result result : scanner1) {byte[] row = result.getRow();System.out.println("数据的rowKey为" + Bytes.toString(row));List<Cell> cells = result.listCells();for (Cell cell : cells) {// byte[] qualifier = cell.getQualifier();// byte[] family = cell.getFamily();// byte[] value = cell.getValue();String family = Bytes.toString(CellUtil.cloneFamily(cell));//获取该单元格的列名String colName = Bytes.toString(CellUtil.cloneQualifier(cell));//获取该单元格的列值String value = Bytes.toString(CellUtil.cloneValue(cell));//id列和age列是整型数据if ("f1".equals(Bytes.toString(family)) && "id".equals(Bytes.toString(qualifier)) || "age".equals(Bytes.toString(value))){System.out.println("列族为"+Bytes.toString(family)+"列名为"+Bytes.toString(qualifier)+"列值为"+Bytes.toInt(value));} else {System.out.println("列族为"+Bytes.toString(family)+"列名为"+Bytes.toString(qualifier)+"列值为"+Bytes.toString(value));}}}}
}
3.10、多过滤器综合查询FilterList
/*** 通过运用4种比较器过滤出姓于,年纪大于23岁,性别为女,且是理科的学生。** 正则比较器 RegexStringComparator* 包含比较器 SubstringComparator* 二进制前缀比较器 BinaryPrefixComparator* 二进制比较器 BinaryComparator**/
@Test
public void FilterData1(){try {//获取表的实例TableName students = TableName.valueOf("students");Table studentTable = conn.getTable(students);
/*** 第一个过滤器,过滤出是理科开头的班级*/RegexStringComparator regexStringComparator = new RegexStringComparator("^理科.*");//单列值过滤器SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter("info".getBytes(), "clazz".getBytes(),CompareOperator.EQUAL, regexStringComparator);
/*** 第二个过滤器,过滤出性别是女生的*/
SubstringComparator substringComparator = new SubstringComparator("女");SingleColumnValueFilter singleColumnValueFilter1 = new SingleColumnValueFilter("info".getBytes(), "gender".getBytes(),CompareOperator.EQUAL, substringComparator);
/*** 第三个过滤器,过滤出年龄大于23岁的*/BinaryComparator binaryComparator = new BinaryComparator("20".getBytes());SingleColumnValueFilter singleColumnValueFilter2 = new SingleColumnValueFilter("info".getBytes(), "age".getBytes(),CompareOperator.GREATER, binaryComparator);
/*** 第四个过滤器,过滤出姓于的学生*/BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator("于".getBytes());SingleColumnValueFilter singleColumnValueFilter3 = new SingleColumnValueFilter("info".getBytes(), "name".getBytes(),CompareOperator.EQUAL, binaryPrefixComparator);
Scan scan = new Scan();
//要想实现多个需求同时过滤,就需要创建多个过滤器,添加到一个过滤器列表中//然后将过滤器列表传给扫描器scanFilterList filterList = new FilterList();filterList.addFilter(singleColumnValueFilter);filterList.addFilter(singleColumnValueFilter1);filterList.addFilter(singleColumnValueFilter2);filterList.addFilter(singleColumnValueFilter3);
scan.setFilter(filterList);
ResultScanner scanner = studentTable.getScanner(scan);
handleResultScanner(scanner);
} catch (IOException e) {e.printStackTrace();}
}/*** 过滤出学号是以15001001开头的文科学生*/
@Test
public void filterData2(){try {//获取表的实例TableName students = TableName.valueOf("students");Table studentTable = conn.getTable(students);
/*** 创建第一个过滤器,过滤是以15001001开头的rowkey*/BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator("15001001".getBytes());//创建行键过滤器RowFilter rowFilter = new RowFilter(CompareOperator.EQUAL, binaryPrefixComparator);
/*** 创建第二个过滤器,过滤出文科的学生*/RegexStringComparator regexStringComparator = new RegexStringComparator("^文科.*");SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter("info".getBytes(), "clazz".getBytes(),CompareOperator.EQUAL,regexStringComparator);
FilterList filterList = new FilterList();filterList.addFilter(rowFilter);filterList.addFilter(singleColumnValueFilter);
Scan scan = new Scan();scan.setFilter(filterList);ResultScanner scanner = studentTable.getScanner(scan);handleResultScanner(scanner);
} catch (IOException e) {e.printStackTrace();}
}相关文章:

java操作HBase
创建一个学生信息表,用来存储学生的姓名(姓名作为行键,且假设姓名不会重复)以及考试成绩,其中考试成绩(score)是一个列族,存储了各个科目的考试成绩。然后向student中添加数据 1、HB…...
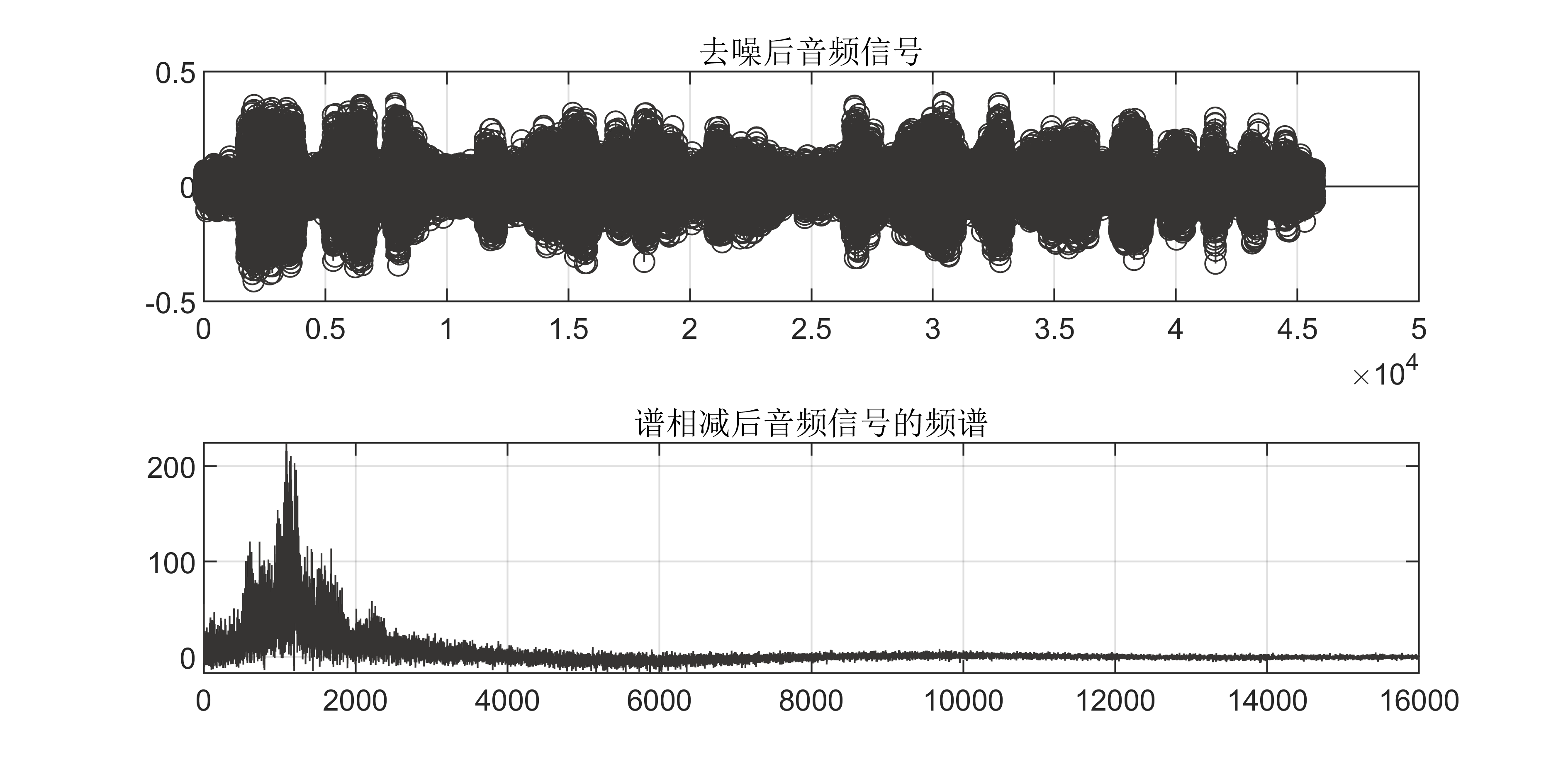
【MATLAB】语音信号识别与处理:移动中位数滤波算法去噪及谱相减算法呈现频谱
1 基本定义 移动中位数滤波算法是一种基于中位数的滤波方法,它通过对信号进行滑动窗口处理,每次取窗口内的中位数作为当前点的估计值,以去除噪声。该算法的主要思想是利用中位数的鲁棒性,对信号中的噪声进行有效的消除。 具体来说…...

浏览器 实现文件下载 完成回调 兼容ie11
首先保证 改文件资源能够通过get请求或者 post请求拿到,基于此基础上我们可以实现得知下载完成后的回调 代码如下 const getFileAndCallback (url, callback) > {//定义执行作用域const that this;//首先 初始化一个原生ajax对象const xhr new XMLHttpReques…...

鸿蒙Harmony应用开发—ArkTS声明式开发(容器组件:Grid)
网格容器,由“行”和“列”分割的单元格所组成,通过指定“项目”所在的单元格做出各种各样的布局。 说明: 该组件从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 子组件 仅支持GridItem…...

Docker使用(四)Docker常见问题分析和解决收集整理
Docker使用(四)Docker常见问题分析和解决收集整理 五、常见问题 1、 启动异常 【描述】: 【分析】:[rootlocalhost ~]# systemctl status docker 【解决】: (1)卸载后重新安装,不能解决这个问题。 …...
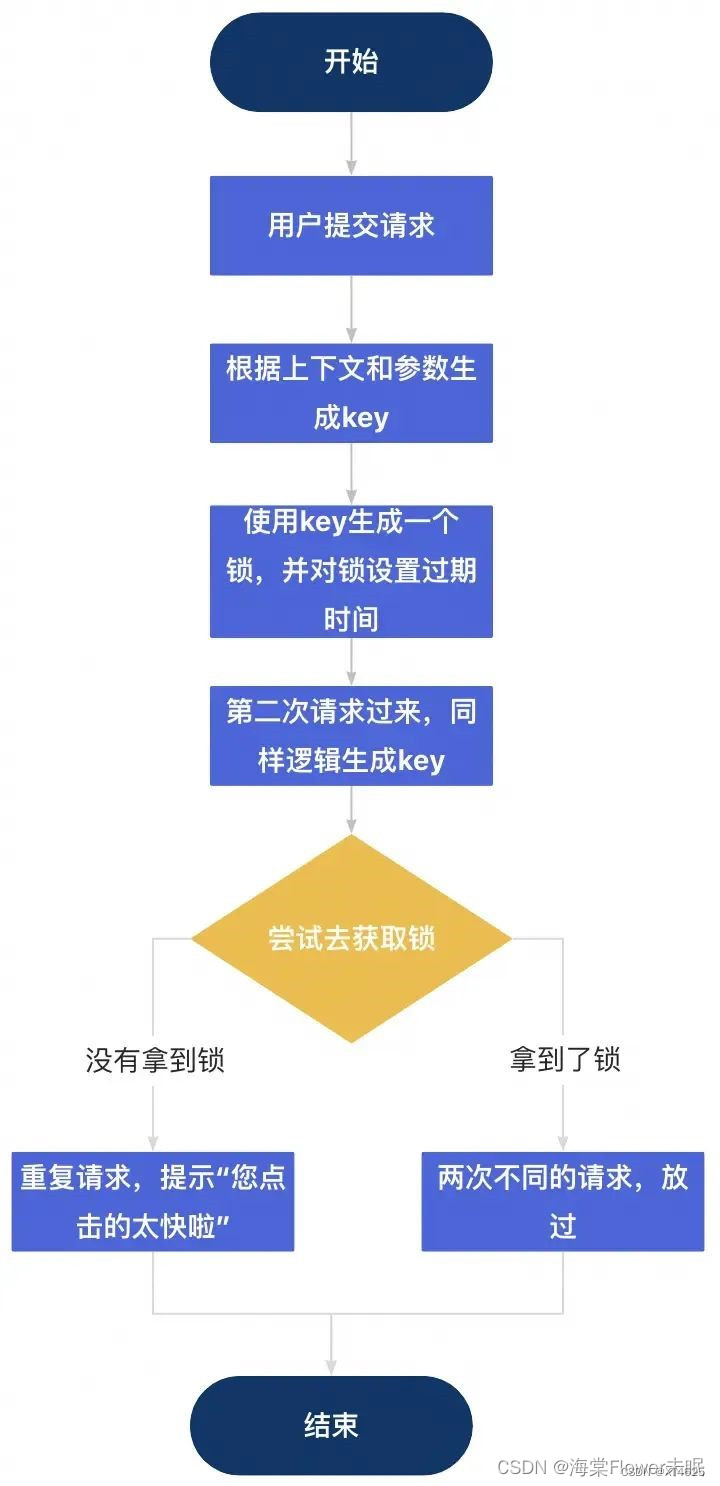
通过spring boot/redis/aspect 防止表单重复提交【防抖】
一、啥是防抖 所谓防抖,一是防用户手抖,二是防网络抖动。在Web系统中,表单提交是一个非常常见的功能,如果不加控制,容易因为用户的误操作或网络延迟导致同一请求被发送多次,进而生成重复的数据记录。要针…...
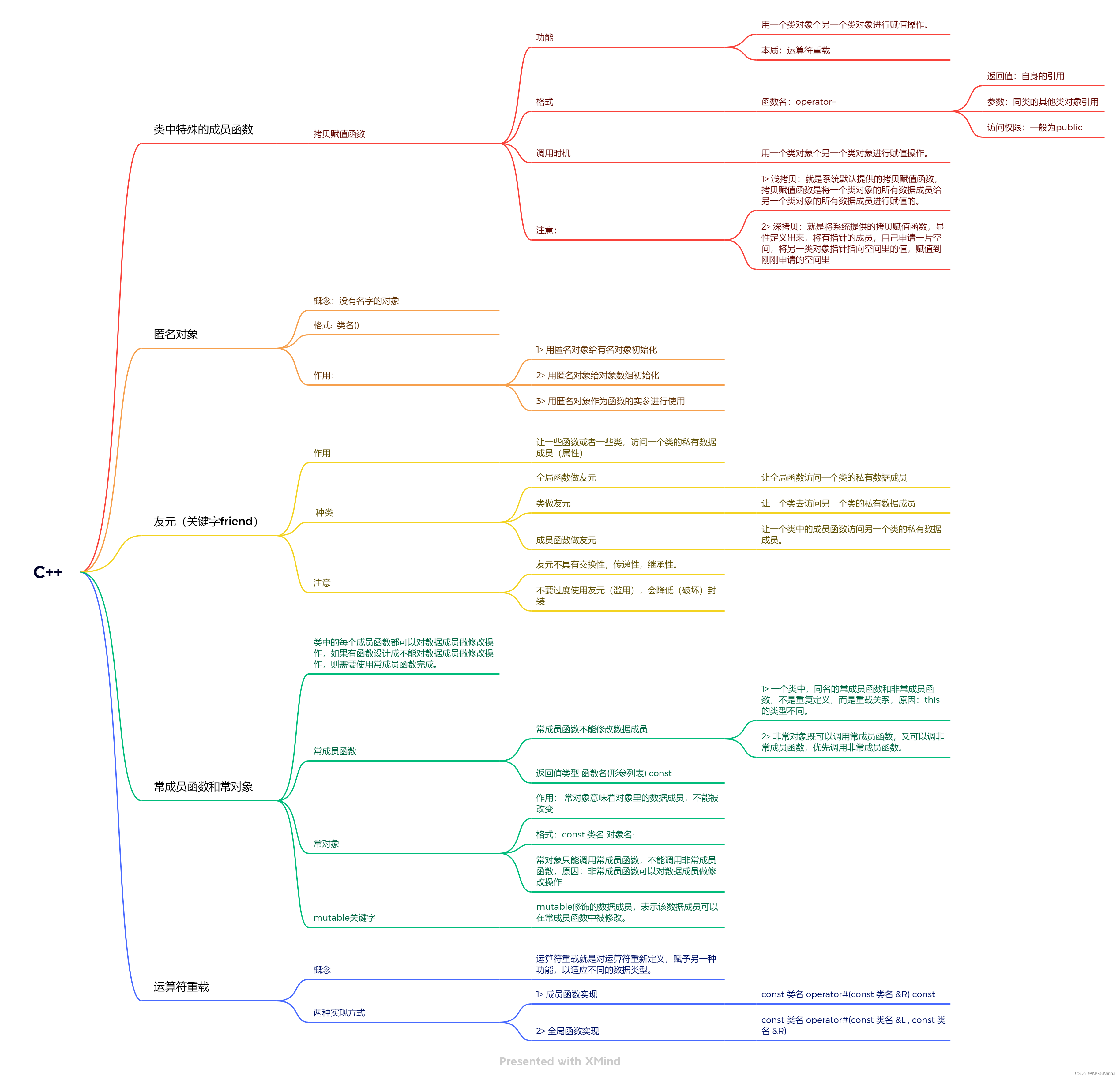
C++ 作业 24/3/14
1、成员函数版本实现算术运算符的重载;全局函数版本实现算术运算符的重载 #include <iostream>using namespace std;class Test {friend const Test operator-(const Test &L,const Test &R); private:int c;int n; public:Test(){}Test(int c,int n…...

新品牌推广怎么做?百度百科创建是第一站
创业企业的宣传推广怎么做?对于初创的企业、或者品牌来说,推广方式都有一个循序渐进的过程,但多数领导者都会做出同一选择,第一步就是给自己的企业创建一个百度百科词条。在百度百科建立自己的企业、或产品词条,不仅可以树立相关信…...

k8s系列-kubectl 命令快速参考
这些指令适用于 Kubernetes v1.29。要检查版本,请使用 kubectl version 命令。 我们经常用到 --all-namespaces 参数,你应该要知道它的简写: kubectl -AKubectl 上下文和配置 kubectl config view # 显示合并的 kubeconfig 配置# 同时使用多…...

微信小程序--开启下拉刷新页面
1、下拉刷新获取数据enablePullDownRefresh 开启下拉刷新: enablePullDownRefreshbooleanfalse是否开启当前页面下拉刷新 案例: 下拉刷新,获取新的列表数据,其实就是进行一次新的网络请求: 第一步:在.json文件中开…...
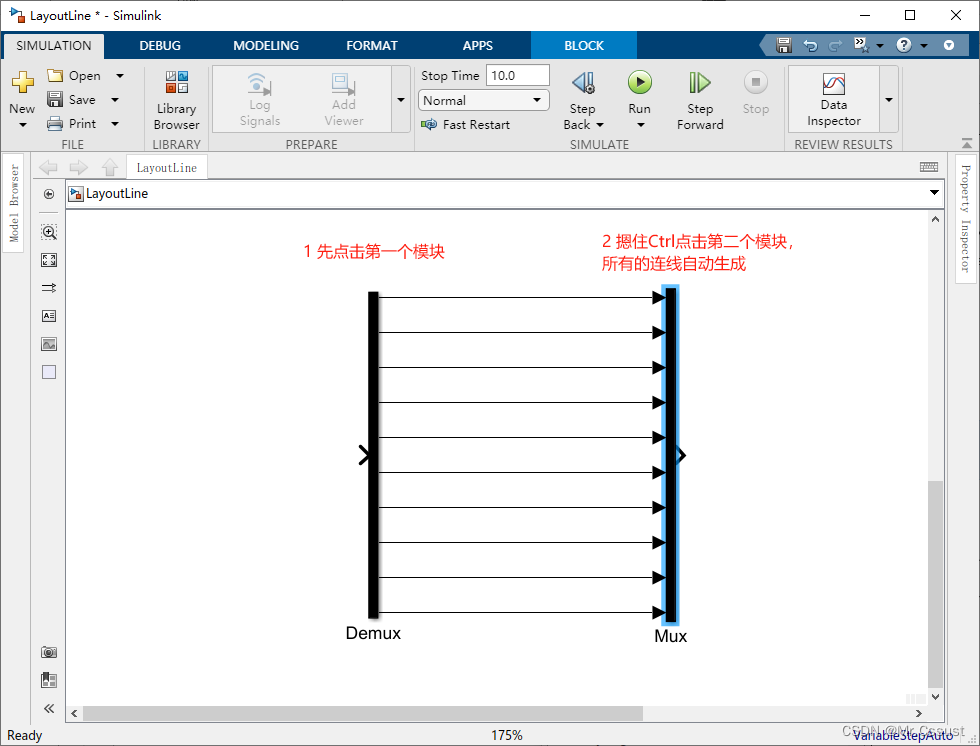
【研发日记】Matlab/Simulink技能解锁(五)——Simulink布线技巧
前言 见《【研发日记】Matlab/Simulink技能解锁(一)——在Simulink编辑窗口Debug》 见《【研发日记】Matlab/Simulink技能解锁(二)——在Function编辑窗口Debug》 见《【研发日记】Matlab/Simulink技能解锁(三)——在Stateflow编辑窗口Debug》 见《【研发日记】Matlab/Simulink…...

FPGA高端项目:FPGA基于GS2971+GS2972架构的SDI视频收发+OSD动态字符叠加,提供1套工程源码和技术支持
目录 1、前言免责声明 2、相关方案推荐本博已有的 SDI 编解码方案本方案的SDI接收发送本方案的SDI接收图像缩放应用本方案的SDI接收纯verilog图像缩放纯verilog多路视频拼接应用本方案的SDI接收HLS图像缩放HLS多路视频拼接应用本方案的SDI接收HLS多路视频融合叠加应用本方案的S…...

面向对象编程第二式:继承 (Java篇)
本篇会加入个人的所谓‘鱼式疯言’ ❤️❤️❤️鱼式疯言:❤️❤️❤️此疯言非彼疯言 而是理解过并总结出来通俗易懂的大白话, 小编会尽可能的在每个概念后插入鱼式疯言,帮助大家理解的. 🤭🤭🤭可能说的不是那么严谨.但小编初心是能让更多人…...
2024最新小狐狸AI 免授权源码
后台安装步骤: 1、在宝塔新建个站点,php版本使用7.2 、 7.3 或 7.4,把压缩包上传到站点根目录,运行目录设置为/public 2、导入数据库文件,数据库文件是 /db.sql 3、修改数据库连接配置,配置文件是/.env 4、…...

5.69 BCC工具之runqlen.py解读
一,工具简介 runqlen工具用于分析和报告运行队列(run queue)的长度,并以直方图的形式展示。它通过在所有CPU上以99赫兹的频率对运行队列长度进行采样来工作。 在操作系统中,运行队列是指内核用来管理待执行(runnable)进程的队列。当一个进程准备好执行,但由于某些原因…...

什么软件可以改变ip地址
什么软件可以修改ip地址,想必很多朋友都在寻找类似的软件,也想知道其中的答案,也能提高自己工作的效率。 经过小编在互联网摸爬滚打这些年,测试认证和整理后,发现一款名叫深度IP转换器的软件,这个确确实实能…...
C语言-strncmp strncat strncpy长度受限制的字符串函数
strncmp strncat strncpy长度受限制的字符串函数 首先 我们需要知道 这几个的语法格式差不多 这里传递的size_t的长度是传递的字节长度 不是个数 也就这里int*是四个字节 char*是一个字节 如果是整数进行交换 。此时也就需要20个字节,这样可以交换五个整数 这里差…...
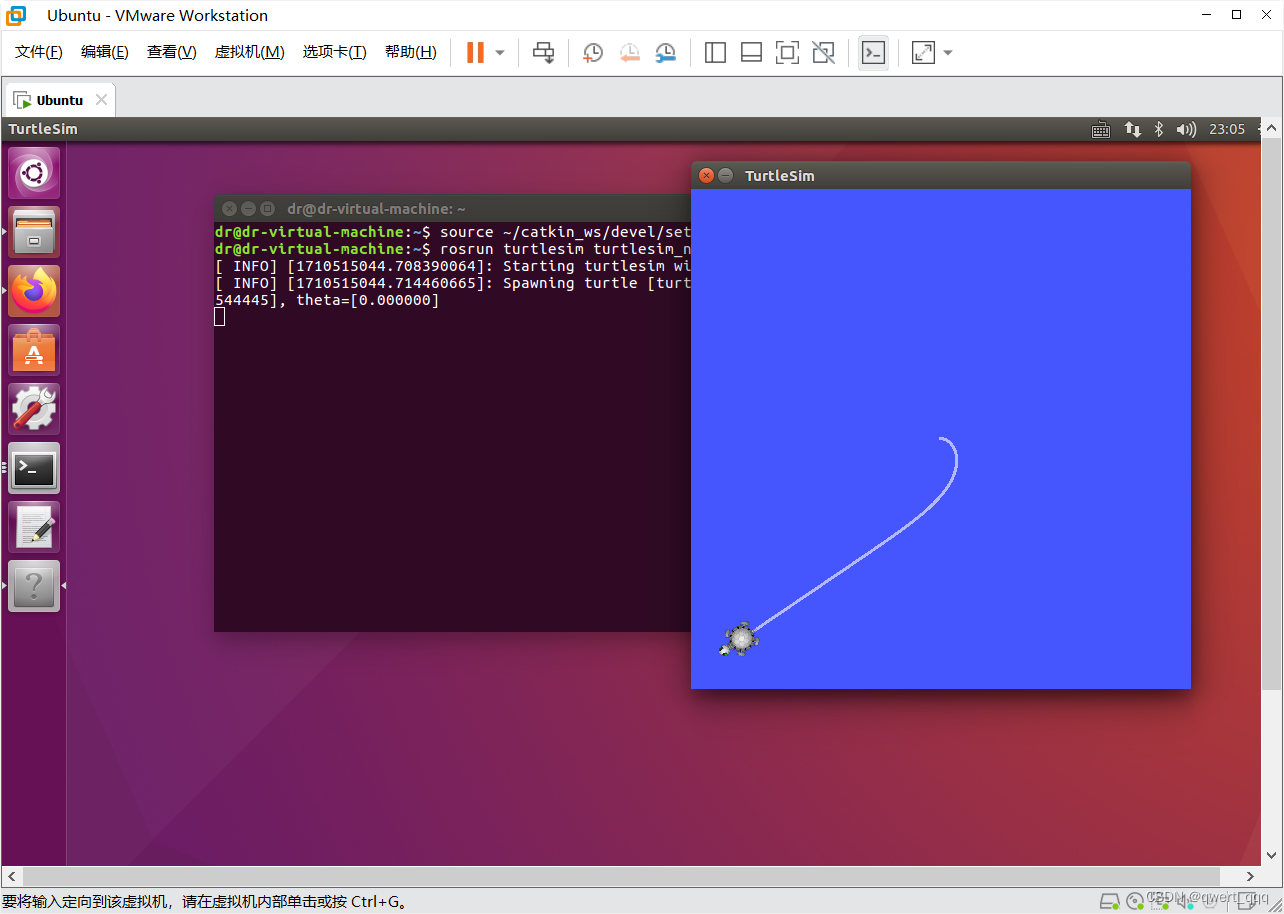
ROS Kinetic通信编程:话题、服务、动作编程
文章目录 一、话题编程二、服务编程三、动作编程 接上篇,继续学习ROS通信编程基础 一、话题编程 步骤: 创建发布者 初始化ROS节点向ROS Master注册节点信息,包括发布的话题名和话题中的消息类型按照一定频率循环发布消息 创建订阅者 初始化…...
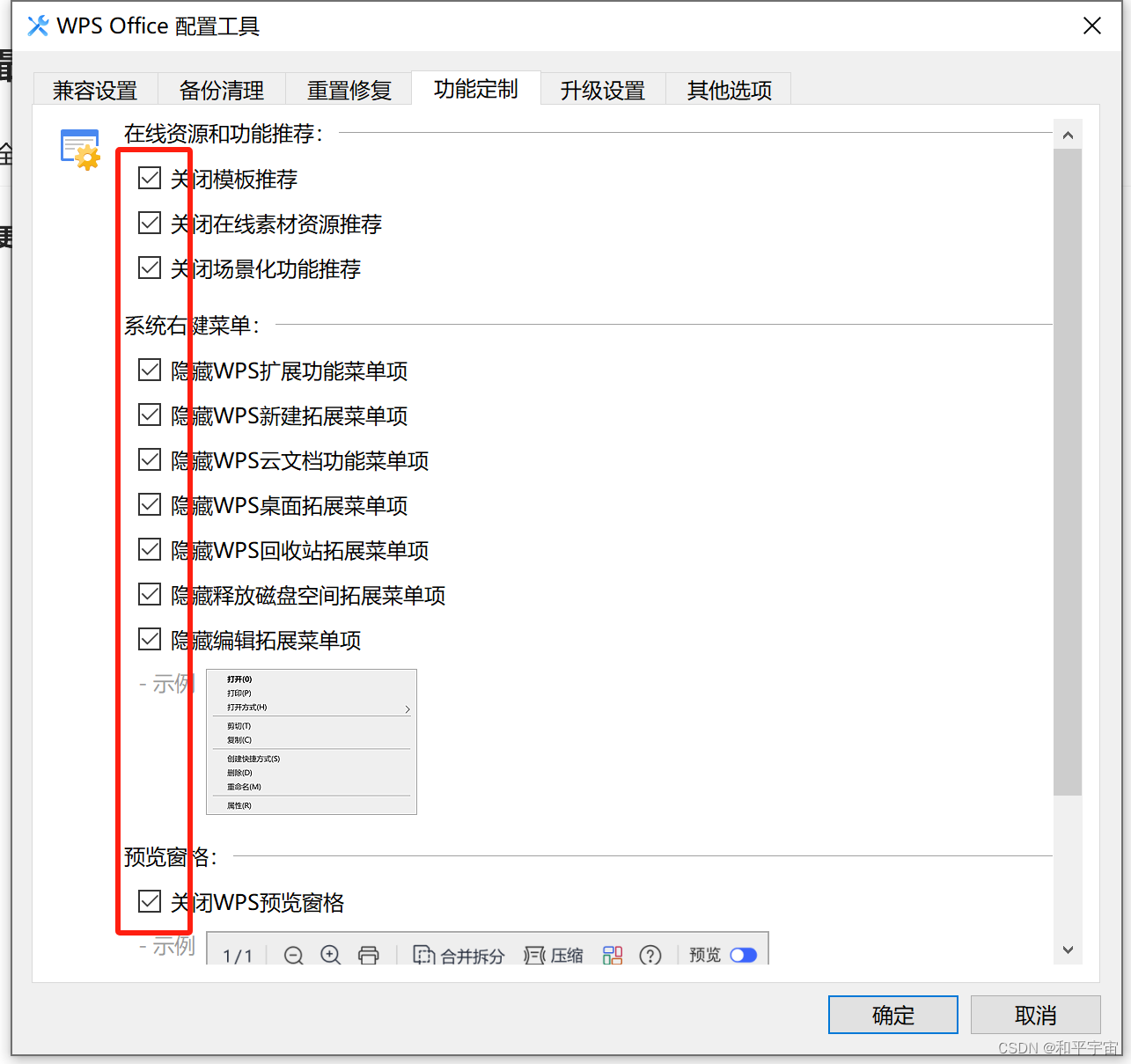
还原wps纯粹的编辑功能
1.关闭稻壳模板: 1.1. 启动wps(注意不要乱击稻壳模板,点了就找不到右键菜单了) 1.2. 在稻壳模板选项卡右击:选不再默认展示 2.关闭托盘中wps云盘图标:右击云盘图标/同步与设置: 2.1.关闭云文档同步 2.2.窗口选桌面应用…...

【烹饪】清炒菠菜的学习笔记
1 焯水:15s左右即可 Kimi教授 菠菜含有草酸,与含钙丰富的食物共煮时可能会形成草酸钙,影响钙的吸收,因此在烹饪时通常建议先用开水烫一下菠菜以减少草酸含量。 2 可选调料:鸡精...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

别再只比参数了!从插件生态到中文优化,聊聊ChatGPT和文心一言的“隐形”差异
超越参数之争:ChatGPT与文心一言的生态与本土化实战解析 当技术评测文章还在反复比较模型参数量与发布时间时,真正影响日常工作效率的往往是那些未被量化的"软实力"。本文将从插件生态构建与中文场景优化两个维度,带您重新认识这两…...
)
从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表)
更多请点击: https://codechina.net 第一章:从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表) 向事件驱动架构(EDA)演进不是功能迭代&…...

告别Selenium?手把手教你用Playwright录制脚本,5分钟搞定Web自动化测试
5分钟极速上手Playwright脚本录制:零代码实现Web自动化测试当产品经理突然丢给你一个刚上线的电商活动页,要求半小时内完成所有核心链路测试时,传统的手写Selenium脚本显然来不及。作为测试工程师,我最近发现微软开源的Playwright…...

UnityExplorer:如何在游戏运行时实时调试和修改Unity项目
UnityExplorer:如何在游戏运行时实时调试和修改Unity项目 【免费下载链接】UnityExplorer An in-game UI for exploring, debugging and modifying IL2CPP and Mono Unity games. 项目地址: https://gitcode.com/gh_mirrors/un/UnityExplorer UnityExplorer是…...

语音AI落地最后一公里卡点,PlayAI质量波动真相:采样率适配缺陷、韵律断层、情感衰减三大隐性陷阱
更多请点击: https://intelliparadigm.com 第一章:PlayAI语音质量评测报告总览 PlayAI语音质量评测体系基于客观指标与主观听感双维度构建,覆盖清晰度、自然度、时延、抗噪性及情感一致性五大核心能力。本报告汇总了在标准测试集(…...

Unity动态植被系统:实时天气与自然现象耦合方案
1. 这不是“贴图堆砌”,而是一套可交互的自然系统你有没有试过在Unity里拖进几棵树、铺点草地,结果运行起来——风一吹,所有树叶像被钉在空中一样纹丝不动;下雨时,雨滴垂直砸进地面,连个水花都没有…...