【Hadoop大数据技术】——MapReduce经典案例实战(倒排索引、数据去重、TopN)
📖 前言:MapReduce是一种分布式并行编程模型,是Hadoop核心子项目之一。实验前需确保搭建好Hadoop 3.3.5环境、安装好Eclipse IDE
🔎 【Hadoop大数据技术】——Hadoop概述与搭建环境(学习笔记)
目录
- 🕒 1. 在Eclipse中搭建MapReduce环境
- 🕒 2. 倒排索引
- 🕘 2.1 案例分析
- 🕤 2.1.1 Map阶段
- 🕤 2.1.2 Combine阶段
- 🕤 2.1.3 Reduce阶段
- 🕘 2.2 案例实现
- 🕤 2.2.1 Map阶段实现
- 🕤 2.2.2 Combine阶段实现
- 🕤 2.2.3 Reduce阶段实现
- 🕤 2.2.4 Runner程序主类实现
- 🕒 3. 数据去重
- 🕘 3.1 案例分析
- 🕤 3.1.1 Map阶段
- 🕤 3.1.2 Reduce阶段
- 🕘 3.2 案例实现
- 🕤 3.2.1 Map阶段实现
- 🕤 3.2.2 Reduce阶段实现
- 🕤 3.2.3 Runner程序主类实现
- 🕒 4. TopN
- 🕘 4.1 案例分析
- 🕘 4.2 案例实现
- 🕤 4.2.1 Map阶段实现
- 🕤 4.2.2 Reduce阶段实现
- 🕤 4.2.3 Runner程序主类实现
🕒 1. 在Eclipse中搭建MapReduce环境
要在 Eclipse 上编译和运行 MapReduce 程序,需要安装 hadoop-eclipse-plugin
下载后,将插件复制到 Eclipse 安装目录的 plugins 文件夹中
🔎 点击获取软件 提取码: 09oy
sudo mv hadoop-eclipse-plugin-2.7.3.jar /opt/eclipse/plugins/
之后重启eclipse完成插件导入。
在继续配置前请确保已经开启了 Hadoop
hadoop@Hins-vm:/usr/local/hadoop$ ./sbin/start-dfs.sh
插件需要进一步的配置。
第一步:选择 Window 菜单下的 Preference。
此时会弹出一个窗口,窗口的左侧会多出 Hadoop Map/Reduce 选项,点击此选项,选择 Hadoop 的安装目录(如//usr/local/hadoop)。
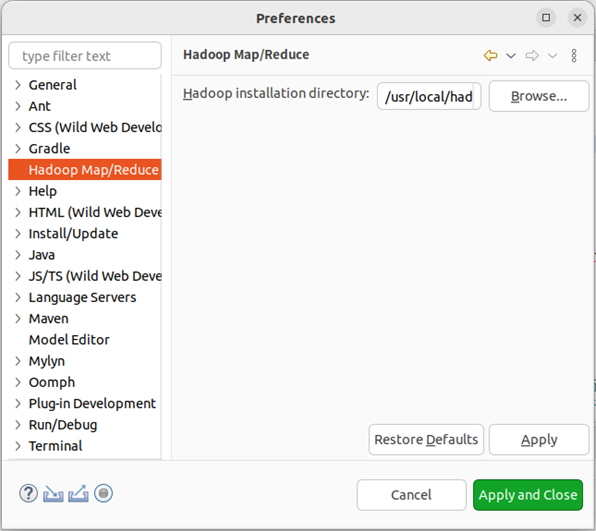
第二步:切换 Map/Reduce 开发视图,选择 Window 菜单下选择 Window -> Perspective -> Open Perspective -> Other,弹出一个窗口,从中选择 Map/Reduce 选项即可进行切换。
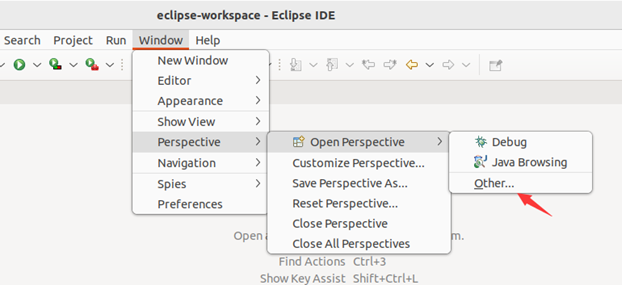
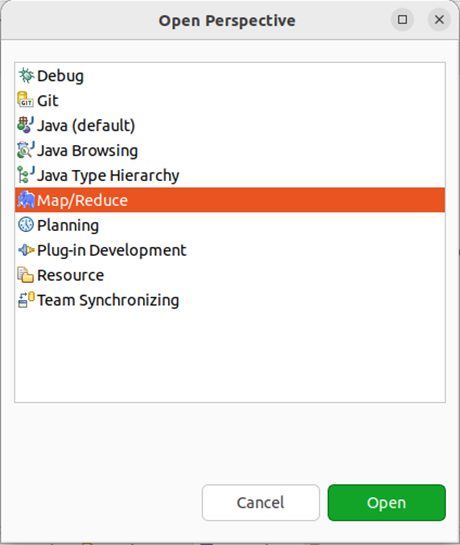
第三步:建立与 Hadoop 集群的连接,点击 Eclipse软件右下角的 Map/Reduce Locations 面板,在面板中单击右键,选择 New Hadoop Location。
在弹出来的 General 选项面板中,General 的设置要与 Hadoop 的配置一致。一般两个 Host 值是一样的,如果是伪分布式,填写 localhost 即可,本文使用Hadoop伪分布式配置,设置 fs.defaultFS 为 hdfs://localhost:9000,则 DFS Master 的 Port 要改为 9000。Map/Reduce(V2) Master 的 Port 用默认的即可,Location Name 随意填写。
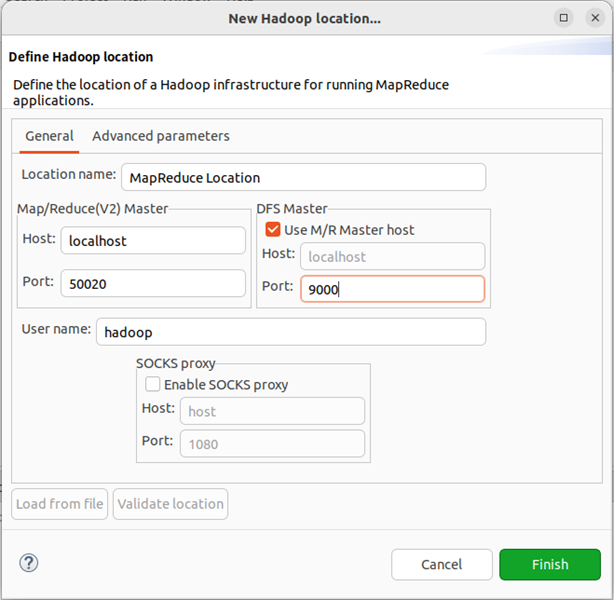
点击 finish,Map/Reduce Location 就创建好了。
在 Eclipse 中操作 HDFS 中的文件:
配置好后,点击左侧 Project Explorer 中的 MapReduce Location 就能直接查看 HDFS 中的文件列表了,双击可以查看内容,右键点击可以上传、下载、删除 HDFS 中的文件,无需再通过繁琐的 hdfs dfs -ls 等命令进行操作了。
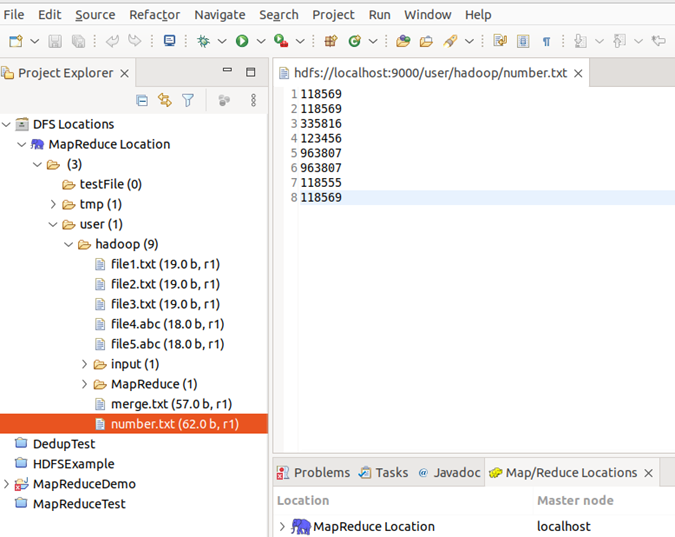
注:HDFS 中的内容变动后,Eclipse 不会同步刷新,需要右键点击 Project Explorer中的 MapReduce Location,选择 Refresh,才能看到变动后的文件。
🕒 2. 倒排索引
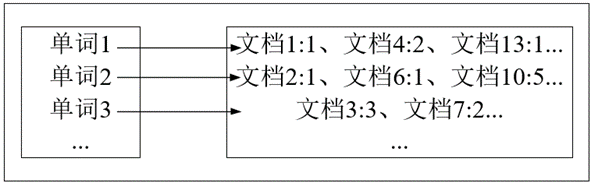
倒排索引是文档检索系统中最常用的数据结构,被广泛应用于全文搜索引擎。倒排索引主要用来存储某个单词或词组在一组文档中的存储位置的映射,提供了可以根据内容来查找文档的方式,而不是根据文档来确定内容,因此称为倒排索引(Inverted Index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(Inverted File)。
倒排文件由一个单词或词组和相关联的文档列表组成。
在实际应用中,还需要给每个文档添加一个权值,用来指出每个文档与搜索内容的相关度。最常用的是使用词频作为权重,即记录单词或词组在文档中出现的次数,用户在搜索相关文档时,就会把权重高的推荐给客户。
🕘 2.1 案例分析
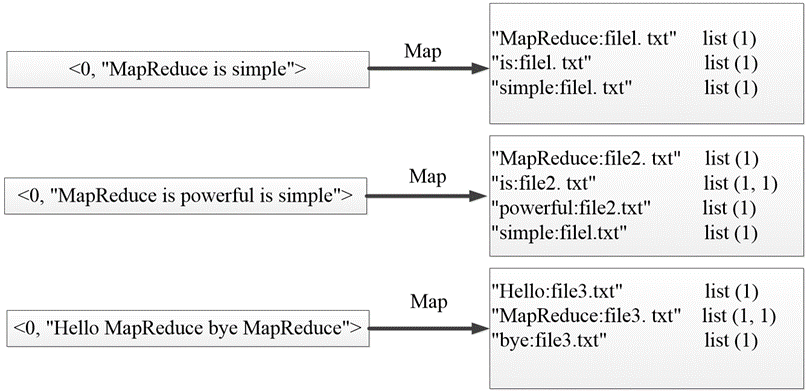
现有三个源文件file1.txt、file2.txt和file3.txt,需要使用倒排索引的方式对这三个源文件内容实现倒排索引,并将最后的倒排索引文件输出。
file1.txt
MapReduce is simple
file2.txt
MapReduce is powerful is simple
file3.txt
Hello MapReduce bye MapReduce
使用实现倒排索引的MapReduce程序统计文件file1.txt、file2.txt和file3.txt中每个单词所在文本的位置以及各文本中出现的次数。

🕤 2.1.1 Map阶段
MapTask使用默认的lnputFormat组件对每个文本文件进行处理,得到文本中的每行数据的起始偏移量及其内容,作为Map阶段输入的键值对,进一步得到倒排索引中需要的3个信息:单词、文档名称和词频。
🕤 2.1.2 Combine阶段
经过Map阶段数据转换后,同一个文档中相同的单词会出现多个的情况,单纯依靠后续ReduceTask同时完成词频统计和生成文档列表会耗费大量时间,因此可以通过Combiner组件先完成每一个文档中的词频统计。
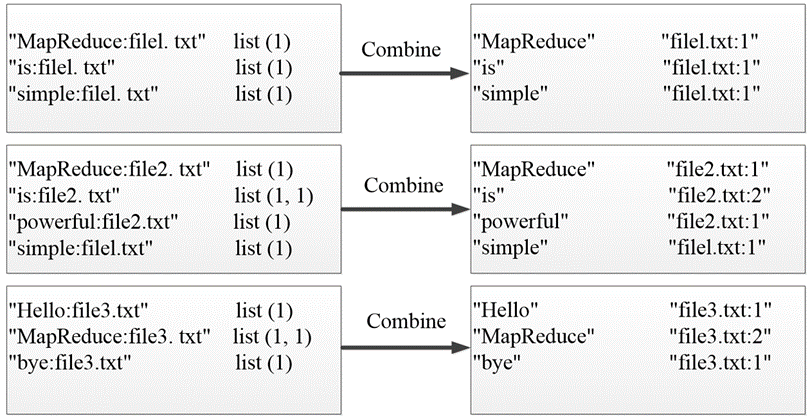
🕤 2.1.3 Reduce阶段
经过上述两个阶段的处理后,Reduce阶段只需将所有文件中相同key值的value值进行统计,并组合成倒排索引文件所需的格式即可。
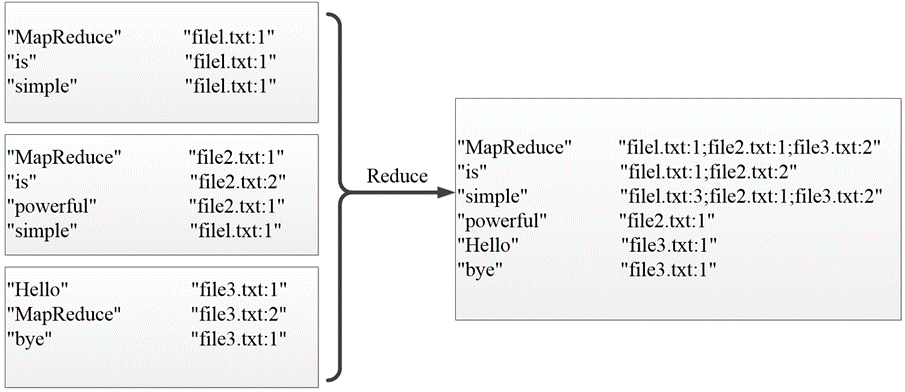
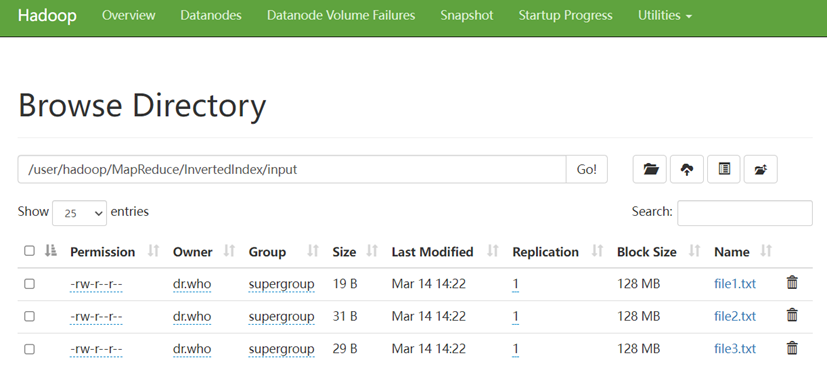
🕘 2.2 案例实现
首先,我们创建好这些源文件,设置好路径并上传至HDFS的input中。
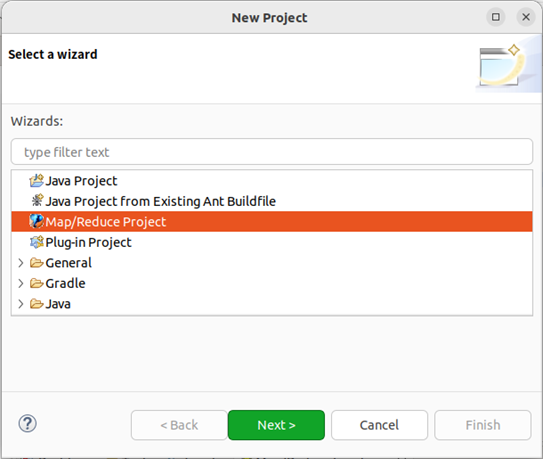
在 Eclipse 中创建项目,点击 File 菜单,选择 New -> Project,选择 Map/Reduce Project,点击 Next。
取名MapReduceDemo,点击 Finish。
此时在左侧的 Project Explorer 就能看到刚才建立的项目了。接着右键点击刚创建的 MapReduce 项目 src,选择 New -> Package,在 Package 处填写 com.mapreduce.invertedindex;
🕤 2.2.1 Map阶段实现
在 com.mapreduce.invertedindex包下新建自定义类Mapper类InvertedIndexMapper,该类继承Mapper类
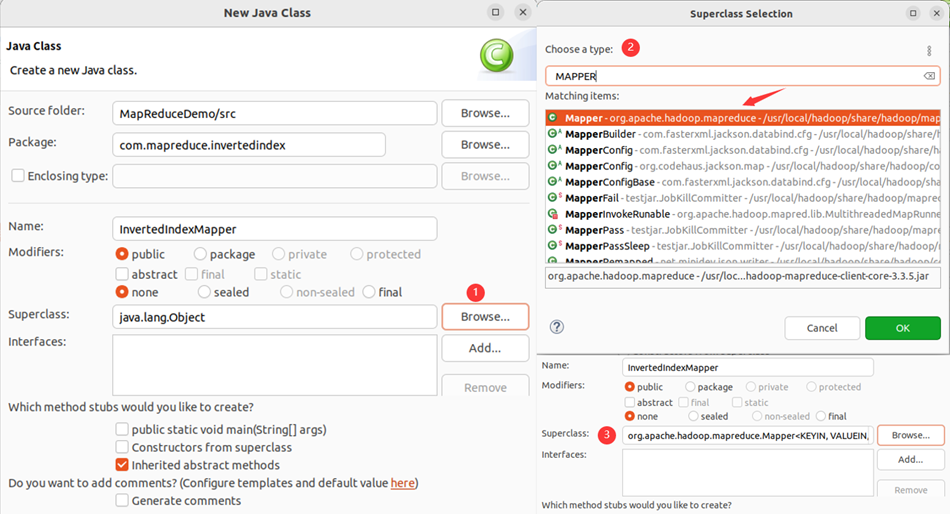
该类的作用:将文本中的单词按照空格进行切割,并以冒号拼接,“单词:文档名称”作为key,单词次数作为value,都以文本方式传输至Combine阶段。
package com.mapreduce.invertedindex;import java.io.IOException;import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;public class InvertedIndexMapper extends Mapper<LongWritable, Text, Text, Text> {private static Text keyInfo = new Text();// 存储单词和URL组合private static final Text valueInfo = new Text("1");// 存储词频,初始化为1// 重写map()方法,将文本中的单词进行切割,并通过write()将map()生成的键值对输出给Combine阶段。@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String[] fields = StringUtils.split(line, " ");// 得到字段数组FileSplit fileSplit = (FileSplit) context.getInputSplit();// 得到这行数据所在的文件切片String fileName = fileSplit.getPath().getName();// 根据文件切片得到文件名for (String field : fields) {// key值由单词和URL组成,如"MapReduce:file1"keyInfo.set(field + ":" + fileName);context.write(keyInfo, valueInfo);}}
}
🕤 2.2.2 Combine阶段实现
根据Map阶段的输出结果形式,在 com.mapreduce.invertedindex包下,自定义实现Combine阶段的类InvertedIndexCombiner,该类继承Reducer类,对每个文档的单词进行词频统计,如下图所示。
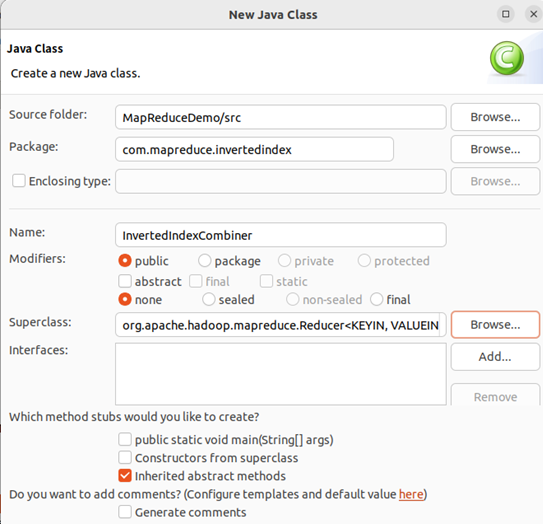
该类作用:对Map阶段的单词次数聚合处理,并重新设置key值为单词,value值由文档名称和词频组成。
package com.mapreduce.invertedindex;import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;public class InvertedIndexCombiner extends Reducer<Text, Text, Text, Text> {private static Text info = new Text();// 输入: <MapReduce:file3 {1,1..>// 输出: <MapReduce file3:2>// 重写reduce()方法对Map阶段的单词次数聚合处理。@Overrideprotected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {int sum = 0;// 统计词频for (Text value : values) {sum += Integer.parseInt(value.toString());}int splitIndex = key.toString().indexOf(":");// 重新设置value值由URL和词频组成info.set(key.toString().substring(splitIndex + 1) + ":" + sum);// 重新设置key值为单词key.set(key.toString().substring(0, splitIndex));context.write(key, info);}
}
🕤 2.2.3 Reduce阶段实现
根据Combine阶段的输出结果形式,在同一包下,自定义实现Reducer类InvertedIndexReducer,该类继承Reducer。
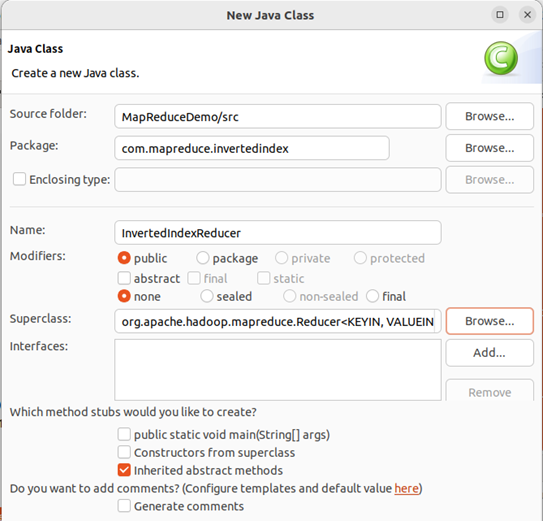
该类作用:接收Combine阶段输出的数据,按照最终案例倒排索引文件需求的样式,将单词作为key,多个文档名称和词频连接作为value,输出到目标目录。
package com.mapreduce.invertedindex;import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;public class InvertedIndexReducer extends Reducer<Text, Text, Text, Text> {private static Text result = new Text();// 输入: <MapReduce file3:2>// 输出: <MapReduce file1:1;file2:1;file3:2;>@Overrideprotected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {// 生成文档列表String fileList = new String();for (Text value : values) {fileList += value.toString() + ";";}result.set(fileList);context.write(key, result);}
}
🕤 2.2.4 Runner程序主类实现
在同一个包下编写MapReduce程序运行主类InvertedIndexDriver。
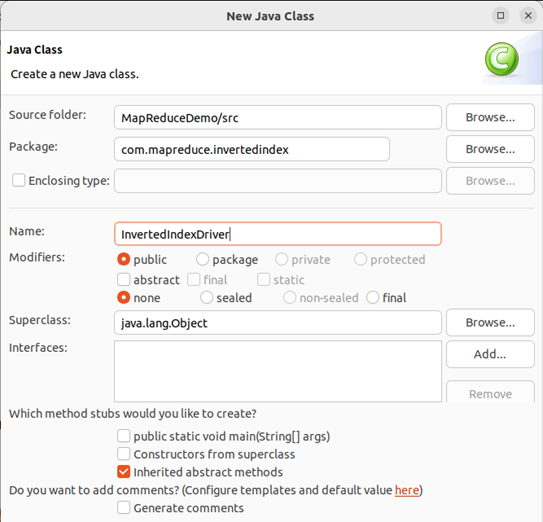
该类作用:设置MapReduce工作任务的相关参数,设置完毕,运行主程序即可。
package com.mapreduce.invertedindex;import java.io.IOException;import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.yarn.service.api.records.Configuration;public class InvertedIndexDriver {public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException {Configuration conf = new Configuration();Job job = Job.getInstance();job.setJarByClass(InvertedIndexDriver.class);job.setMapperClass(InvertedIndexMapper.class);job.setCombinerClass(InvertedIndexCombiner.class);job.setReducerClass(InvertedIndexReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);FileInputFormat.setInputPaths(job, new Path("hdfs://localhost:9000/user/hadoop/MapReduce/InvertedIndex/input"));// 指定处理完成之后的结果所保存的位置FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/user/hadoop/MapReduce/InvertedIndex/output"));// 向yarn集群提交这个jobboolean res = job.waitForCompletion(true);System.exit(res ? 0 : 1);}
}
注:运行结果处的报错可以无视。
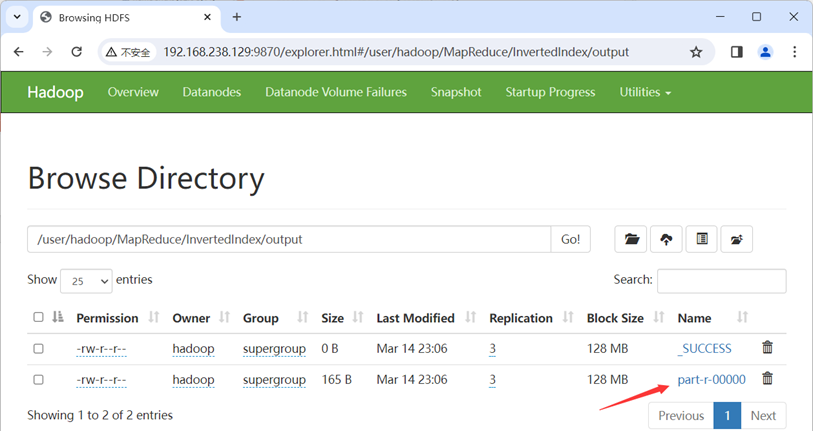
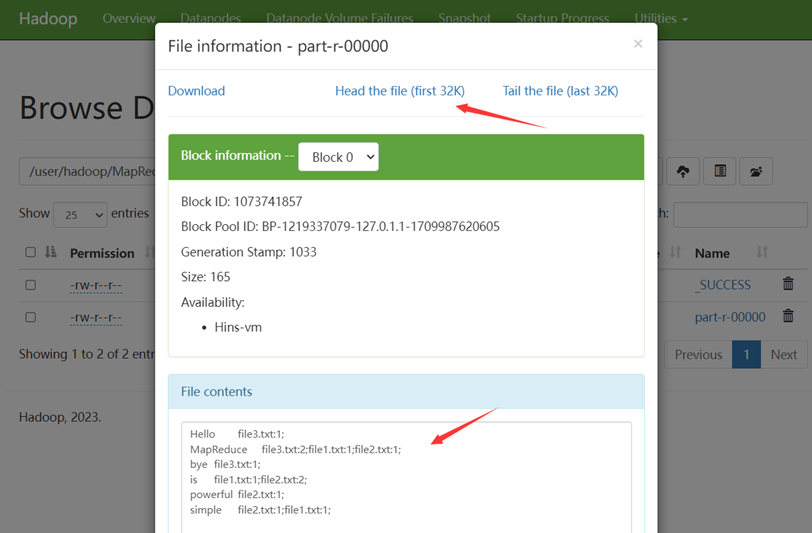
Web UI查看:
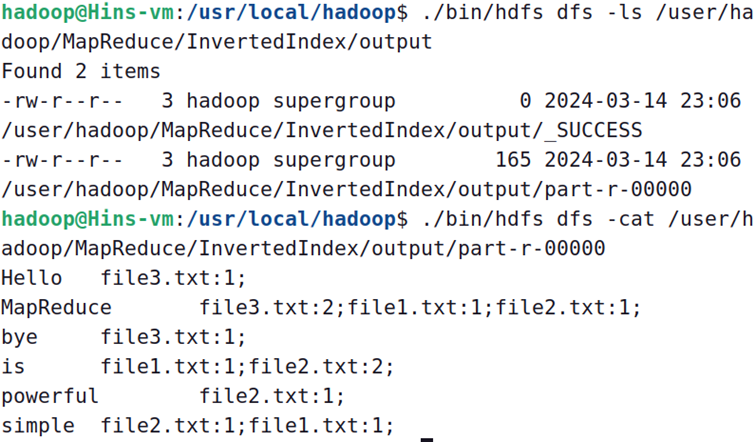
终端查看:
Eclipse IDE查看:
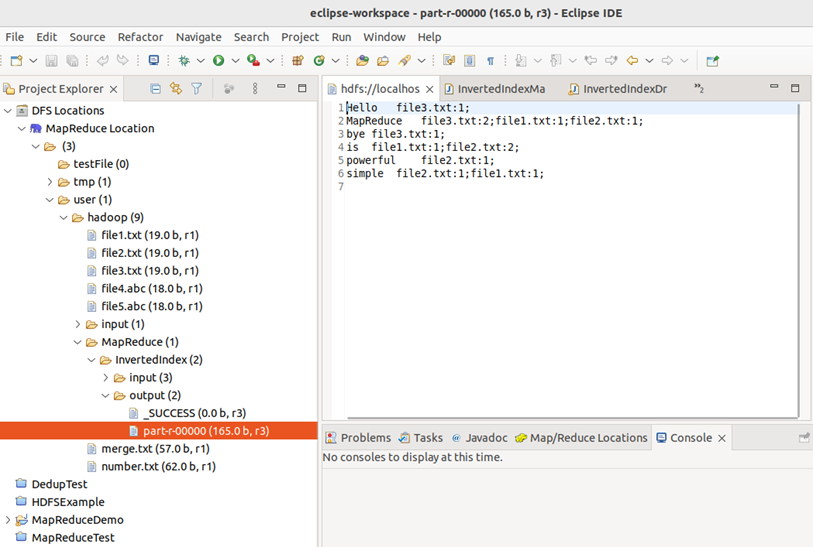
MapReduce的程序可以用Eclipse编译运行或使用命令行编译打包运行,下面是用命令行编译打包运行的方法:
将驱动类代码修改一下:
public class InvertedIndexDriver {public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException {......FileInputFormat.setInputPaths(job, new Path(args[0]));// 指定处理完成之后的结果所保存的位置FileOutputFormat.setOutputPath(job, new Path(args[1]));// 向yarn集群提交这个jobboolean res = job.waitForCompletion(true);System.exit(res ? 0 : 1);}
}
运行前如有output文件夹,需要先删了:
hadoop@Hins-vm:/usr/local/hadoop$ ./bin/hdfs dfs -rm -r /user/hadoop/MapReduce/InvertedIndex/output
打包为jar文件的操作详见HDFS分布式文件系统的 4.6节
🔎 传送门:HDFS分布式文件系统
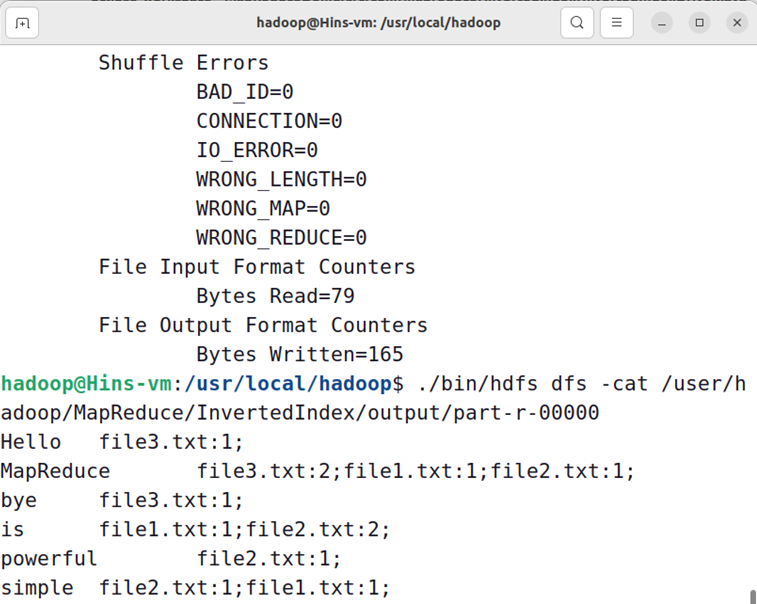
现在,就可以在Linux系统中,使用hadoop jar命令运行程序,并到HDFS中查看生成的文件:
hadoop@Hins-vm:/usr/local/hadoop$ ./bin/hadoop jar ./myapp/InvertedIndex.jar ./MapReduce/InvertedIndex/input ./MapReduce/InvertedIndex/output
🕒 3. 数据去重
数据去重主要是为了掌握利用并行化思想来对数据进行有意义的筛选,数据去重指去除重复数据的操作。在大数据开发中,统计大数据集上的多种数据指标,这些复杂的任务数据都会涉及数据去重。
🕘 3.1 案例分析
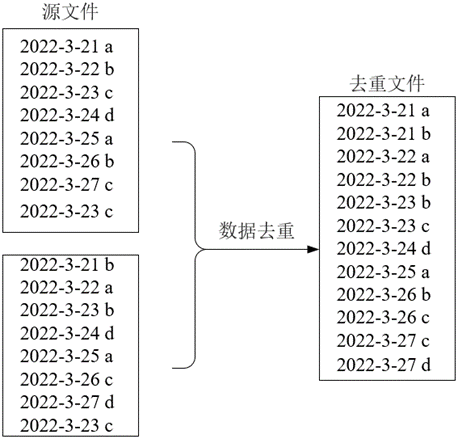
现有两个源文件file4.txt和file5.txt,内容分别如下,编程实现对两个文件合并后的数据内容去重:
file4.txt
2022-3-21 a
2022-3-22 b
2022-3-23 c
2022-3-24 d
2022-3-25 a
2022-3-26 b
2022-3-27 c
2022-3-23 c
file5.txt
2022-3-21 b
2022-3-22 a
2022-3-23 b
2022-3-24 d
2022-3-25 a
2022-3-26 c
2022-3-27 d
2022-3-23 c
🕤 3.1.1 Map阶段
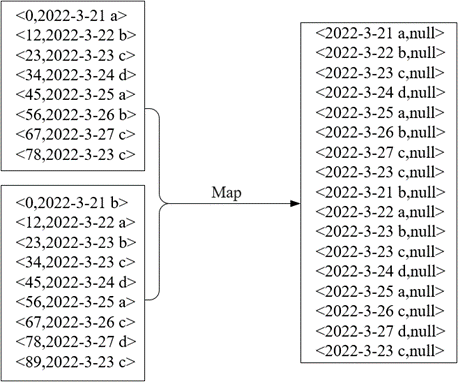
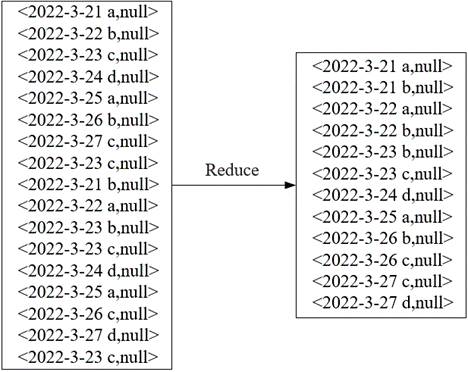
在Map阶段将读取的每一行数据作为键,如2022-3-21 a,由于MapReduce程序对数据去重是以键值对的形式解析数据,需要将每一行数据当作整体进行去重,所以将每一行数据作为键,而值在数据去重中作用不大,这里将值设置为null满足<Key,Value>的格式。
🕤 3.1.2 Reduce阶段
在Reduce阶段,将MapTask输出的键值对作为Reduce阶段输入的键值对,通过ReduceTask中的Shuffle对同一分区中键相同键值对合并,达到数据去重的效果。
🕘 3.2 案例实现
首先,我们创建好这些源文件,设置好路径并上传至HDFS的input中。
在MapReduceDemo项目下新建包 com.mapreduce.dedup
🕤 3.2.1 Map阶段实现
在 com.mapreduce.dedup包下新建自定义类Mapper类DedupMapper,该类继承Mapper类
该类作用:读取数据集文件将TextInputFormat默认组件解析的类似<0,2022-3-21 a>键值对修改为<2022-3-21 a,null>
package com.mapreduce.dedup;import java.io.IOException;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;public class DedupMapper extends Mapper<LongWritable, Text, Text, NullWritable> {private static Text field = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {field = value;context.write(field, NullWritable.get());}
}
🕤 3.2.2 Reduce阶段实现
在同一包下新建自定义类Reducer类DedupReducer,该类继承Reducer类
该类作用:仅接受Map阶段传递过来的数据,根据Shuffle工作原理,键值key相同的数据就会被合并,因此输出的数据就不会出现重复数据了。
package com.mapreduce.dedup;import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;public class DedupReducer extends Reducer<Text, NullWritable, Text, NullWritable> {@Overrideprotected void reduce(Text key, Iterable<NullWritable> values, Context context)throws IOException, InterruptedException {context.write(key, NullWritable.get());}
}
🕤 3.2.3 Runner程序主类实现
在同一个包下编写MapReduce程序运行主类DedupRunner。
package com.mapreduce.dedup;import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
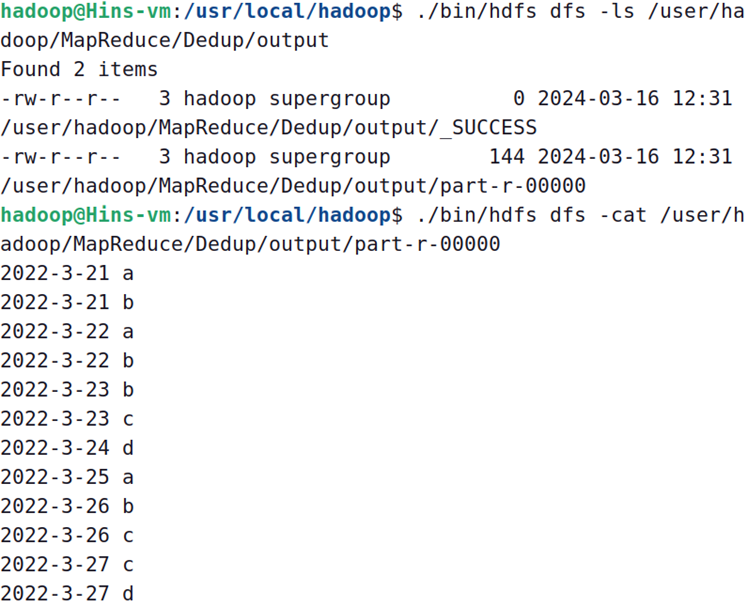
import org.apache.hadoop.yarn.service.api.records.Configuration;public class DedupRunner {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();Job job = Job.getInstance();job.setJarByClass(DedupRunner.class);job.setMapperClass(DedupMapper.class);job.setReducerClass(DedupReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);FileInputFormat.setInputPaths(job, new Path("hdfs://localhost:9000/user/hadoop/MapReduce/Dedup/input"));// 指定处理完成之后的结果所保存的位置FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/user/hadoop/MapReduce/Dedup/output"));job.waitForCompletion(true);}
}
🕒 4. TopN
TopN分析法是指从研究对象中按照某一个指标进行倒序或正序排列,取其中最大的N个数据,并对这N个数据以倒序或正序的方式进行输出分析的方法。
🕘 4.1 案例分析
假设有数据文件num.txt,要求以降序的方式获取文件内容中最大的5个数据,并将这5个数据保存到一个文件中。
10 3 8 7 6 5 1 2 9 4
11 12 17 14 15 20
19 18 13 16
(1)在Map阶段,可以使用TreeMap数据结构保存TopN的数据,TreeMap是一个有序的键值对集合,默认会根据键进行排序,也可以自行设定排序规则,TreeMap中的firstKey()可以用于返回当前集合最小值的键。
(2)在Reduce阶段,将MapTask输出的数据进行汇总,选出其中的最大的5个数据即可满足需求。
(3)要想提取文本中5个最大的数据并保存到一个文件中,需要将ReduceTask的数量设置为1,这样才不会把文件中的数据分发给不同的ReduceTask处理。
🕘 4.2 案例实现
首先,我们创建好这些源文件,设置好路径并上传至HDFS的input中。
在MapReduceDemo项目下新建包 com.mapreduce.topn
🕤 4.2.1 Map阶段实现
在 com.mapreduce.topn包下新建自定义类Mapper类TopNMapper,该类继承Mapper类
该类作用:先将文件中的每行数据进行切割提取,并把数据保存到TreeMap中,判断TreeMap是否大于5,如果大于5就需要移除最小的数据。由于数据是逐行读取,如果这时就向外写数据,那么TreeMap就保存了每一行的最大5个数,因此需要在cleanup()方法中编写context.write()方法,这样就保证了当前MapTask中TreeMap保存了当前文件最大的5条数据后,再输出到Reduce阶段。
package com.mapreduce.topn;import java.util.TreeMap;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;public class TopNMapper extends Mapper<LongWritable, Text, NullWritable, IntWritable> {private TreeMap<Integer, String> repToRecordMap = new TreeMap<Integer, String>();@Overridepublic void map(LongWritable key, Text value, Context context) {String line = value.toString();String[] nums = line.split(" ");for (String num : nums) {repToRecordMap.put(Integer.parseInt(num), " ");if (repToRecordMap.size() > 5) {repToRecordMap.remove(repToRecordMap.firstKey());}}}@Overrideprotected void cleanup(Context context) {for (Integer i : repToRecordMap.keySet()) {try {context.write(NullWritable.get(), new IntWritable(i));} catch (Exception e) {e.printStackTrace();}}}
}
🕤 4.2.2 Reduce阶段实现
在同一包下新建自定义类Reducer类TopNReducer,该类继承Reducer类
该类作用:首先TreeMap自定义排序规则,当需求取最大值时,只需要在compare()方法中返回正数即可满足倒序排序,reduce()方法依然要满足时刻判断TreeMap中存放数据是前5个数,并最终遍历输出最大的5个数。
package com.mapreduce.topn;import java.io.IOException;
import java.util.Comparator;
import java.util.TreeMap;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;public class TopNReducer extends Reducer<NullWritable, IntWritable, NullWritable, IntWritable> {private TreeMap<Integer, String> repToRecordMap = new TreeMap<Integer, String>(new Comparator<Integer>() {// 返回一个基本类型的整型,谁大谁排后面.// 返回负数表示:01小于02// 返回0表示:表示: 01和02相等// 返回正数表示: 01大于02。public int compare(Integer a, Integer b) {return b - a;}});public void reduce(NullWritable key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {for (IntWritable value : values) {repToRecordMap.put(value.get(), " ");if (repToRecordMap.size() > 5) {repToRecordMap.remove(repToRecordMap.firstKey());}}for (Integer i : repToRecordMap.keySet()) {context.write(NullWritable.get(), new IntWritable(i));}}
}
🕤 4.2.3 Runner程序主类实现
在同一个包下编写MapReduce程序运行主类TopNRunner。
package com.mapreduce.topn;import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.yarn.service.api.records.Configuration;public class TopNRunner {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance();job.setJarByClass(TopNRunner.class);job.setMapperClass(TopNMapper.class);job.setReducerClass(TopNReducer.class);job.setNumReduceTasks(1);job.setMapOutputKeyClass(NullWritable.class);job.setMapOutputValueClass(IntWritable.class);job.setOutputKeyClass(NullWritable.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.setInputPaths(job, new Path("hdfs://localhost:9000/user/hadoop/MapReduce/TopN/input"));FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/user/hadoop/MapReduce/TopN/output"));boolean res = job.waitForCompletion(true);System.exit(res ? 0 : 1);}
}

❗ 转载请注明出处
作者:HinsCoder
博客链接:🔎 作者博客主页
相关文章:
【Hadoop大数据技术】——MapReduce经典案例实战(倒排索引、数据去重、TopN)
📖 前言:MapReduce是一种分布式并行编程模型,是Hadoop核心子项目之一。实验前需确保搭建好Hadoop 3.3.5环境、安装好Eclipse IDE 🔎 【Hadoop大数据技术】——Hadoop概述与搭建环境(学习笔记) 目录 &#…...
02、字面量与变量
二、字面量与变量 文章目录 二、字面量与变量1、字面量字面量类型扩展:特殊字符 2、变量进制转换 3、数据类型 1、字面量 字面量又叫做常量,字面值常量,告诉程序员数据在程序中的书写格式。 字面量类型 整数类型(int):不带小数点…...

docker的常用指令
docker的常用指令 从docker镜像仓库,搜索所有和mysql有关的镜像 docker search mysql 从docker仓库拉取mysql docker pull mysql这里的mysql是指使用search搜索出来的所有容器的NAME 如果和我一样遇到以下问题: 我可以登录阿里云的官网,找…...
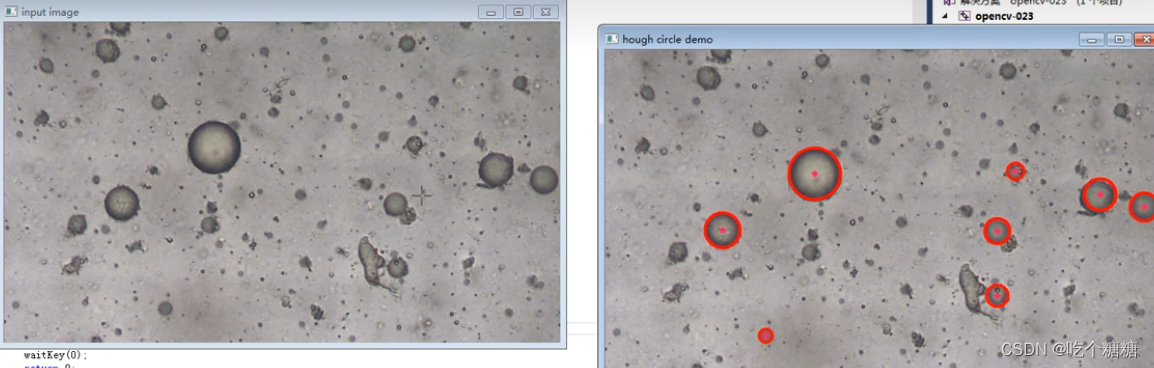
19 OpenCV 霍夫曼变换检测圆
文章目录 cv::HoughCircles算子参数示例 cv::HoughCircles 因为霍夫圆检测对噪声比较敏感,所以首先要对图像做中值滤波。 基于效率考虑,Opencv中实现的霍夫变换圆检测是基于图像梯度的实现,分为两步: 检测边缘,发现可能…...
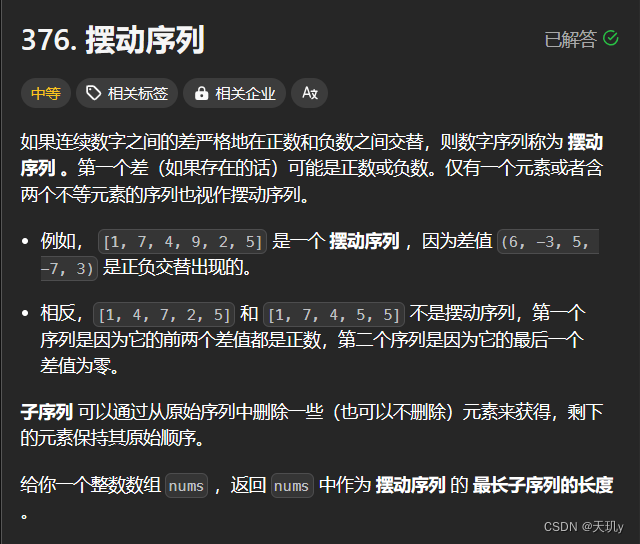
leetcode代码记录(摆动序列
目录 1. 题目:2. 我的代码:小结: 1. 题目: 如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为 摆动序列 。第一个差(如果存在的话)可能是正数或负数。仅有一个元素或者含两个不等…...

django学习笔记
django学习笔记 http://djangobook.py3k.cn/2.0/chapter05/ 文章目录 django学习笔记模型 models.py1、定义数据模型2、模型安装3、创建数据表4、数据表的增删改查4.1 增加4.2 删除4.3 修改4.4 查询4.5 模糊查询4.6 排序&连锁查询4.7 限制返回数据 5、模型使用实战 模型 m…...
Python环境安装及Selenium引入
Python环境安装 环境下载 Download Python | Python.org 环境安装 需使用管理员身份运行 查看环境是否安装成功 python --version 如果未成功则检查环境变量配置 安装 Selenium 库 pip install selenium Selenium 可以模拟用户在浏览器中的操作,如点击按钮、填写…...

【gpt实践】实用咒语分享
直接上咒语了,大家可以自行实践。 1、忽略先前所有的提示 有时候gpt会停留在之前的问题中,导致回答当前问题带着之前问题结论。 2、忽略所有的客套话 我们只是需要有用的信息,有时候gpt客套话会混淆视听。 3、给出非常简短明确的答案 同样…...

Linux用户和权限
一、root用户(超级管理员) 普通用户的权限,一般在其HOME目录内是不受限的 一旦出了HOME目录,大多数地方,普通用户仅有只读和执行权限,无修改权限 二、su 和 exit命令 语法:su [ - ] 【用户…...
git svn混用
背景 项目代码管理初始使用的svn, 由于svn代码操作,无法在本地暂存,有诸多不便,另外本人习惯使用git. 所以决定迁移至git管理 迁移要求: 保留历史提交记录 迁移流程 代码检出 git svn svn_project_url git代码提交 修改本…...
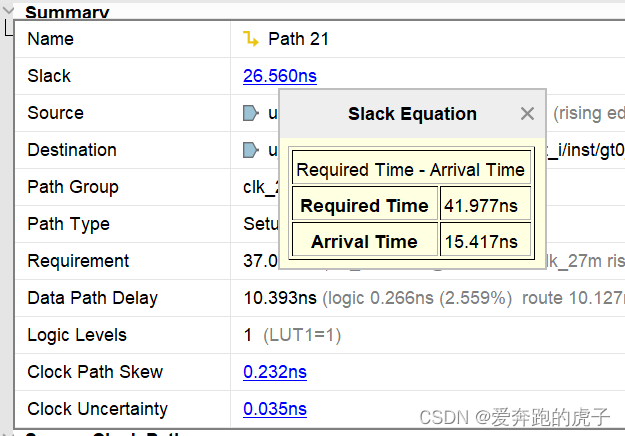
FPGA静态时序分析与约束(三)、读懂vivado时序报告
系列文章目录 FPGA静态时序分析与约束(一)、理解亚稳态 FPGA静态时序分析与约束(二)、时序分析 文章目录 系列文章目录前言一、时序分析回顾二、打开vivado任意工程2.1 工程布局路由成功后,点击vivado左侧**IMPLEMENT…...

鸿蒙Harmony应用开发—ArkTS声明式开发(容器组件:Badge)
可以附加在单个组件上用于信息标记的容器组件。 说明: 该组件从API Version 7开始支持。后续版本如有新增内容,则采用上角标单独标记该内容的起始版本。 子组件 支持单个子组件。 说明: 子组件类型:系统组件和自定义组件…...

Python程序设计基础——代码习题
1 __name__属性 import demodef main():if __name__ __main__:print(这个程序被直接运行。)elif __name__demo:print(这个程序作为模块被使用。) main()3.3 编写程序,生成包含1000个0~100之间的随机整数,并统计每个元素出现的次数。 import randomx[r…...
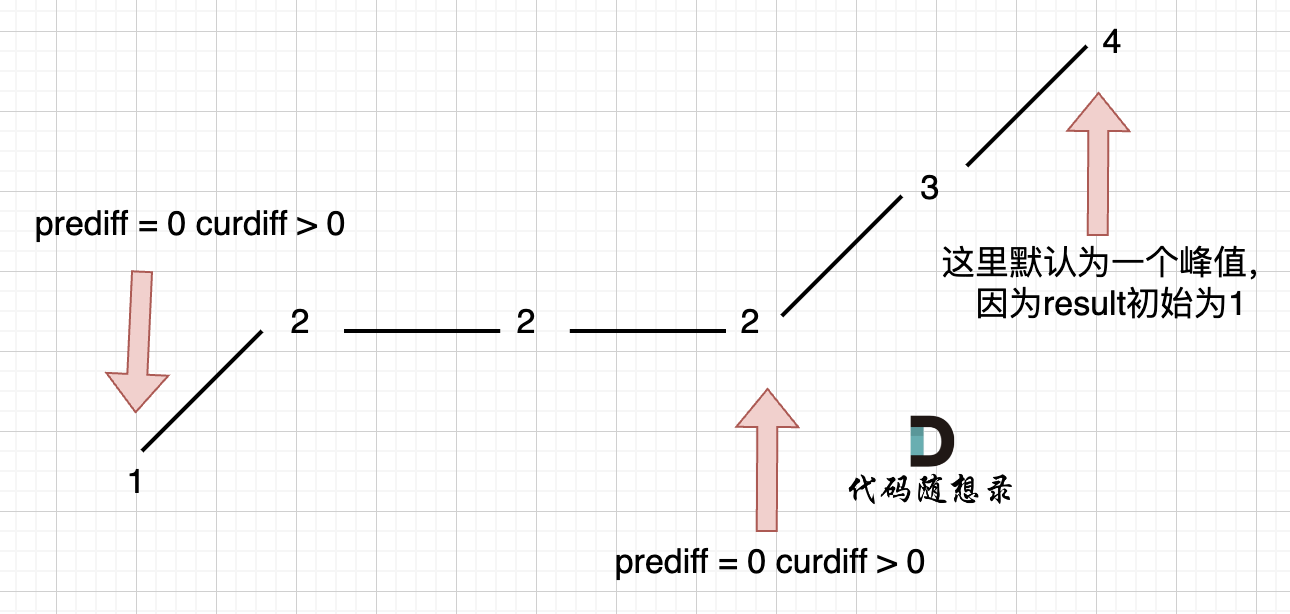
代码随想录 贪心算法-中等题目-序列问题
目录 376.摆动序列 738.单调递增的数字 376.摆动序列 376. 摆动序列 中等 如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为 摆动序列 。第一个差(如果存在的话)可能是正数或负数。仅有一个元素或者含两个不等元素的序列…...
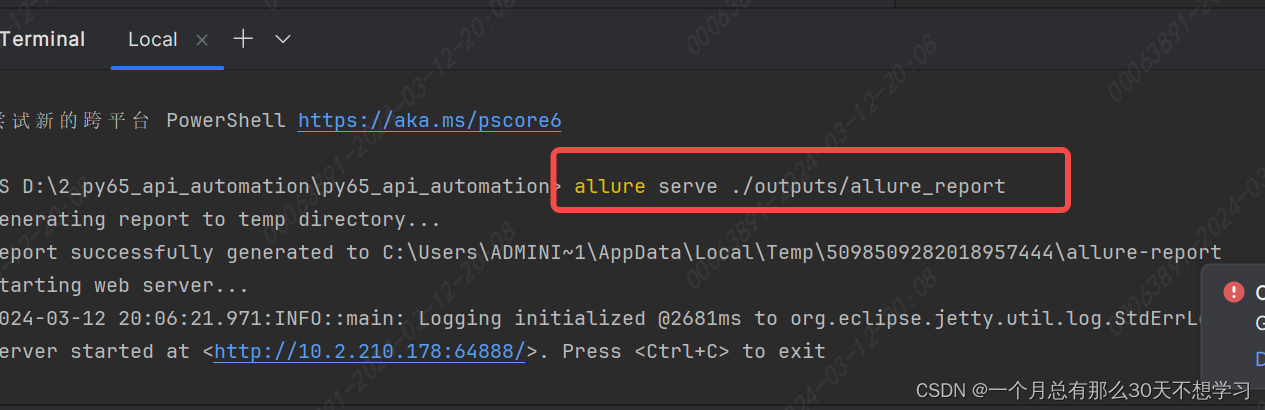
pytest生成allure的报告
首先要下载安装配置allure allure serve ./outputs/allure_report 可以生成html的文件自动在默认浏览器中打开...
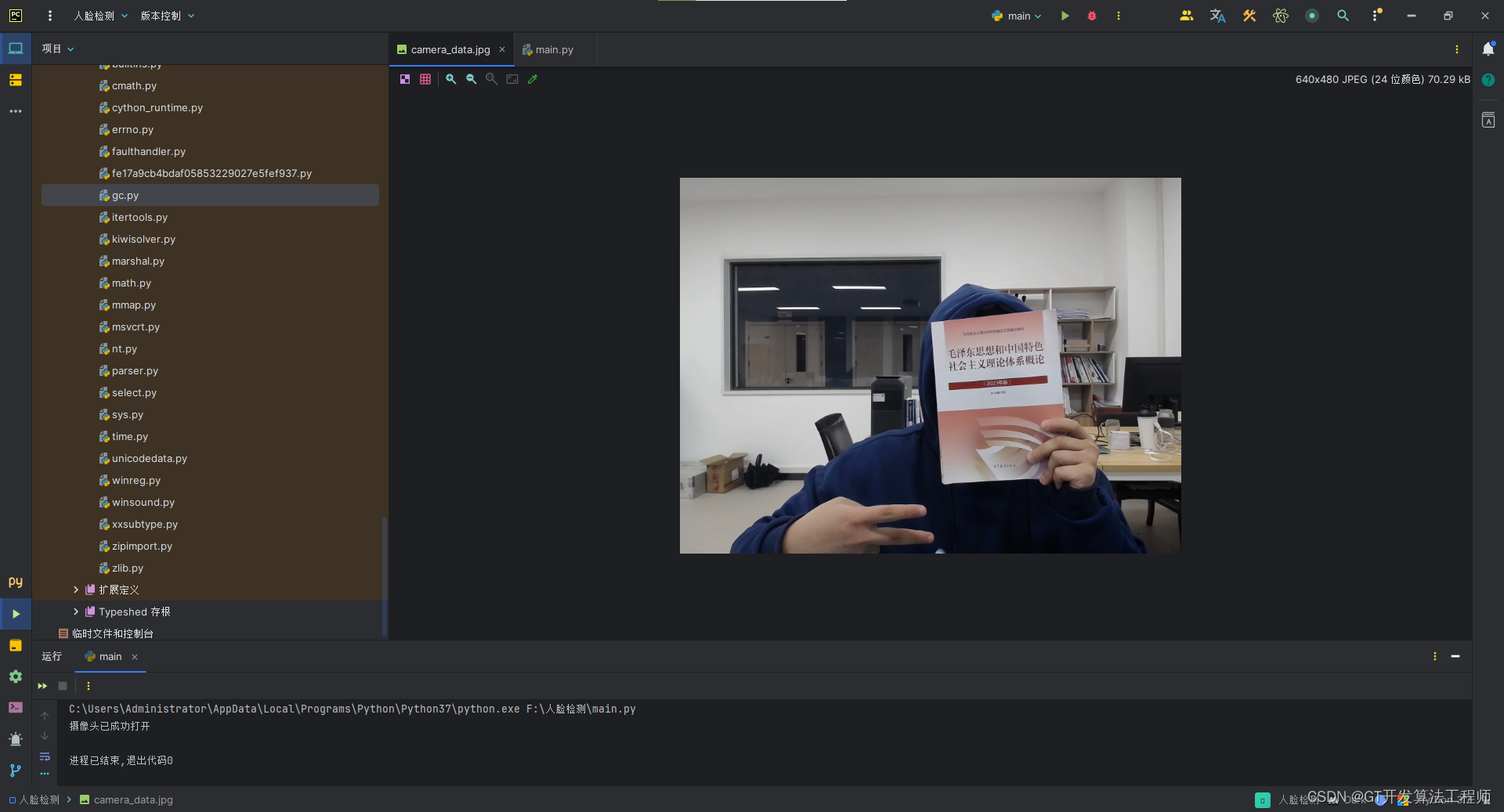
Python控制摄像头并获取数据文件
一、引言 摄像头作为计算机视觉领域的核心设备之一,广泛应用于视频监控、图像采集和数据处理等领域。通过Python编程语言,我们可以实现对摄像头的精确控制,包括摄像头的开启、关闭、参数设置以及数据获取等功能。 目录 一、引言 二、摄像头…...
免费分享一套SpringBoot+Vue自习室(预约)管理系统,帅呆了~~
大家好,我是java1234_小锋老师,看到一个不错的SpringBootVue自习室预约)管理系统,分享下哈。 项目视频演示 【免费】SpringBootVue自习室预约(预约)管理系统 Java毕业设计_哔哩哔哩_bilibili【免费】SpringBootVue自习室预约(预约)管理系统…...

mac删除带锁标识的app
一 、我们这里要删除FortiClient.app 带锁 常规方式删除不掉带锁的 app【如下图】 二、删除命令,依次执行即可。 /bin/ls -dleO /Applications/FortiClient.app sudo /usr/bin/chflags -R noschg /Applications/FortiClient.app /bin/ls -dleO /Applications/Forti…...
PHP异世界云商系统开源源码
系统更新与修复列表 1. 基于彩虹的二次开发 - 对彩虹系统进行了二次开发,增强了系统的功能和性能。2. 新增自定义输入框提示内容(支持批量修改) - 用户可以自定义输入框的提示内容,并支持批量修改,提升用户体验。3. 新…...

Vue生成Canvas二维码
npm install qrcode在Vue组件中引入QRCode库:import QRCode from qrcode;在Vue组件的methods中创建一个方法来生成二维码: generateQRCode() {const canvas this.$refs.qrCodeCanvas; // 获取canvas DOM元素的引用const text Hello, World!; // 要生成…...

Vue3 图片标框功能实现方案
基于 Vue3 组合式 API 的图片标框(画框、标注、选框)完整实现,核心逻辑封装在 GetBoxes 组件里,复制就能用 一、功能说明 ✅ 在图片上鼠标拖拽画矩形框 ✅ 实时显示框坐标(x, y, width, height) ✅ 支持多…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...

如何快速掌握Avidemux:新手完整入门指南与5个核心技巧
如何快速掌握Avidemux:新手完整入门指南与5个核心技巧 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款功能强大且完全开源的专业视频编辑工具,专为快速剪辑、…...

在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在模型广场灵活选型让我找到了更适合代码生成的Taotoken模型 开发代码辅助工具时,选择合适的模型是平衡效果与成本的关…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...

模式分层预测驱动推断:处理复杂缺失数据的统计新框架
1. 项目概述:当数据“缺胳膊少腿”时,如何做出靠谱的推断?在数据科学和统计建模的日常工作中,我们最怕遇到什么?不是复杂的算法,也不是海量的数据,而是数据本身“缺胳膊少腿”——也就是缺失值。…...

星露谷物语SMAPI模组加载器:从新手到专家的完整使用指南
星露谷物语SMAPI模组加载器:从新手到专家的完整使用指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 星露谷物语SMAPI模组加载器是官方推荐的模组API,它为玩家和开发者提供…...